A deployment configuration is a manifest of the application. It defines the runtime behavior of the application. You can select one of the default deployment charts or custom deployment charts which are created by super admin.
To configure a deployment chart for your application, do the following steps:
Go to Applications and create a new application.
Go to App Configuration page and configure your application.
On the Base Deployment Template page, select the drop-down under Chart type.
You can select a default deployment chart from the following options:
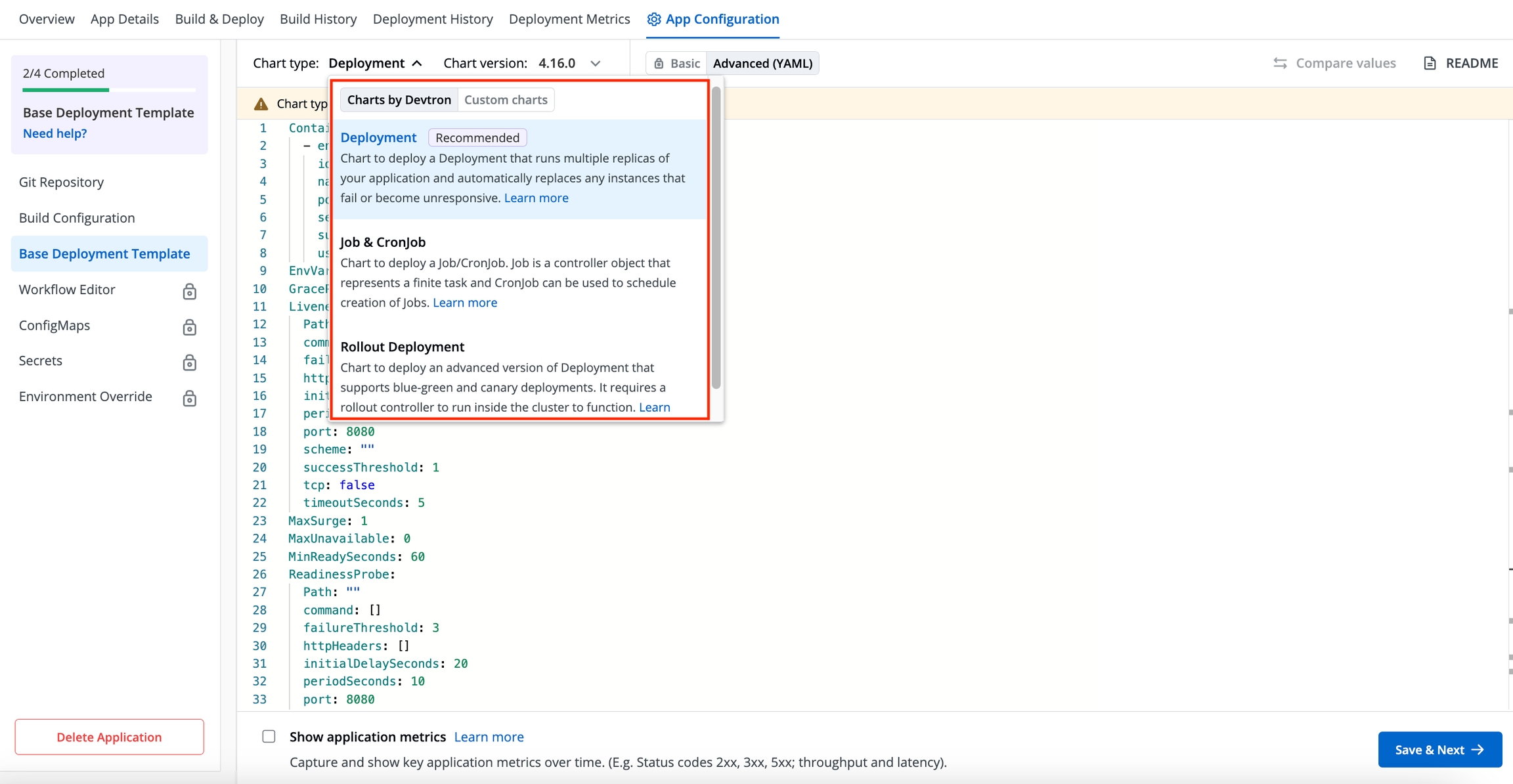
Deployment (Recommended)
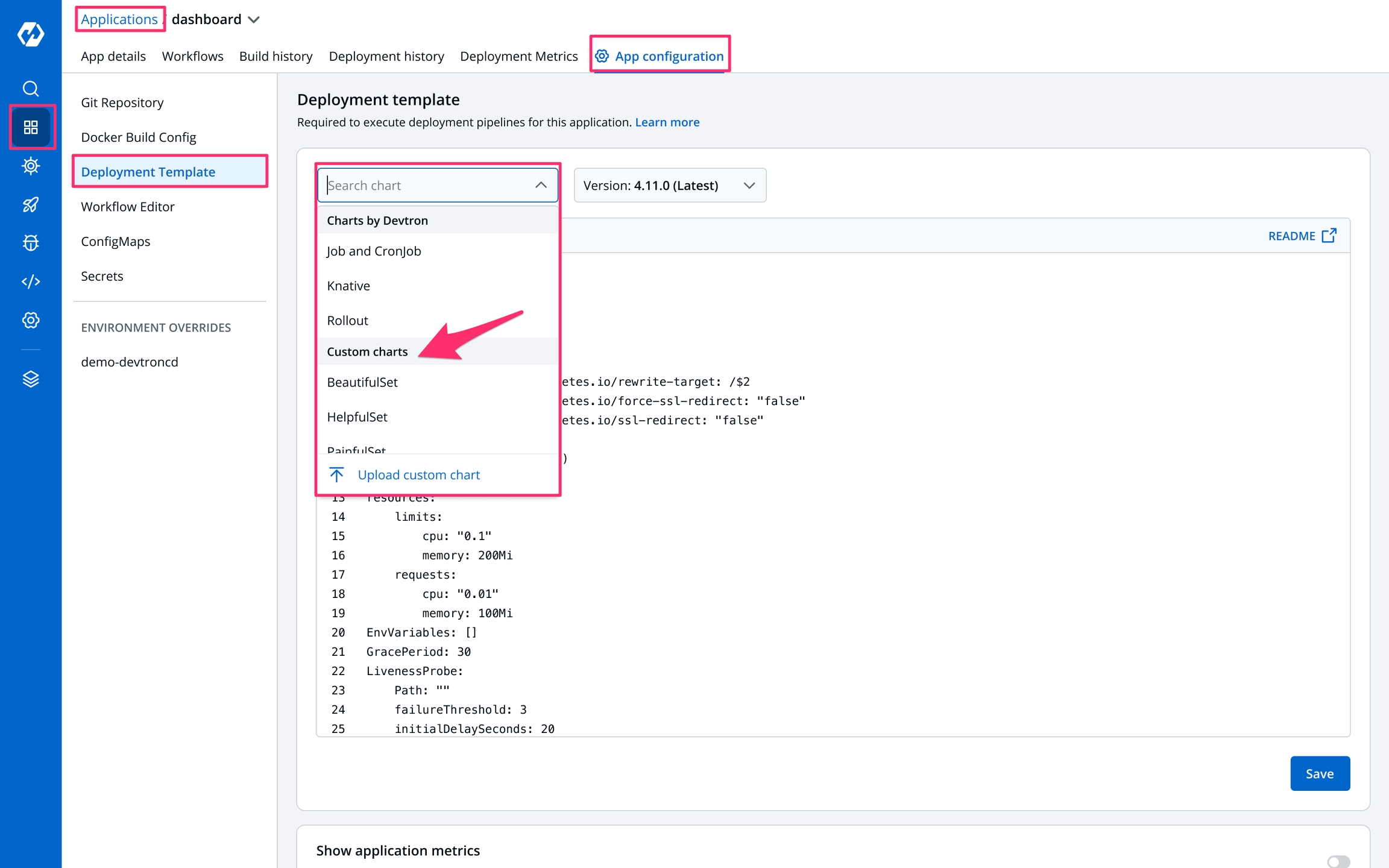
Custom charts are added by users with super admin permission from the Custom charts section.
You can select the available custom charts from the drop-down list. You can also view the description of the custom charts in the list.
A custom chart can be uploaded by a super admin.
Enable show application metrics toggle to view the application metrics on the App Details page.
IMPORTANT: Enabling Application metrics introduces a sidecar container to your main container which may require some additional configuration adjustments. We recommend you to do load test after enabling it in a non-production environment before enabling it in production environment.
Select Save & Next to save your configurations.
Super-admins can lock keys in base deployment template to prevent non-super-admins from modifying those locked keys. Refer Lock Deployment Configuration to know more.
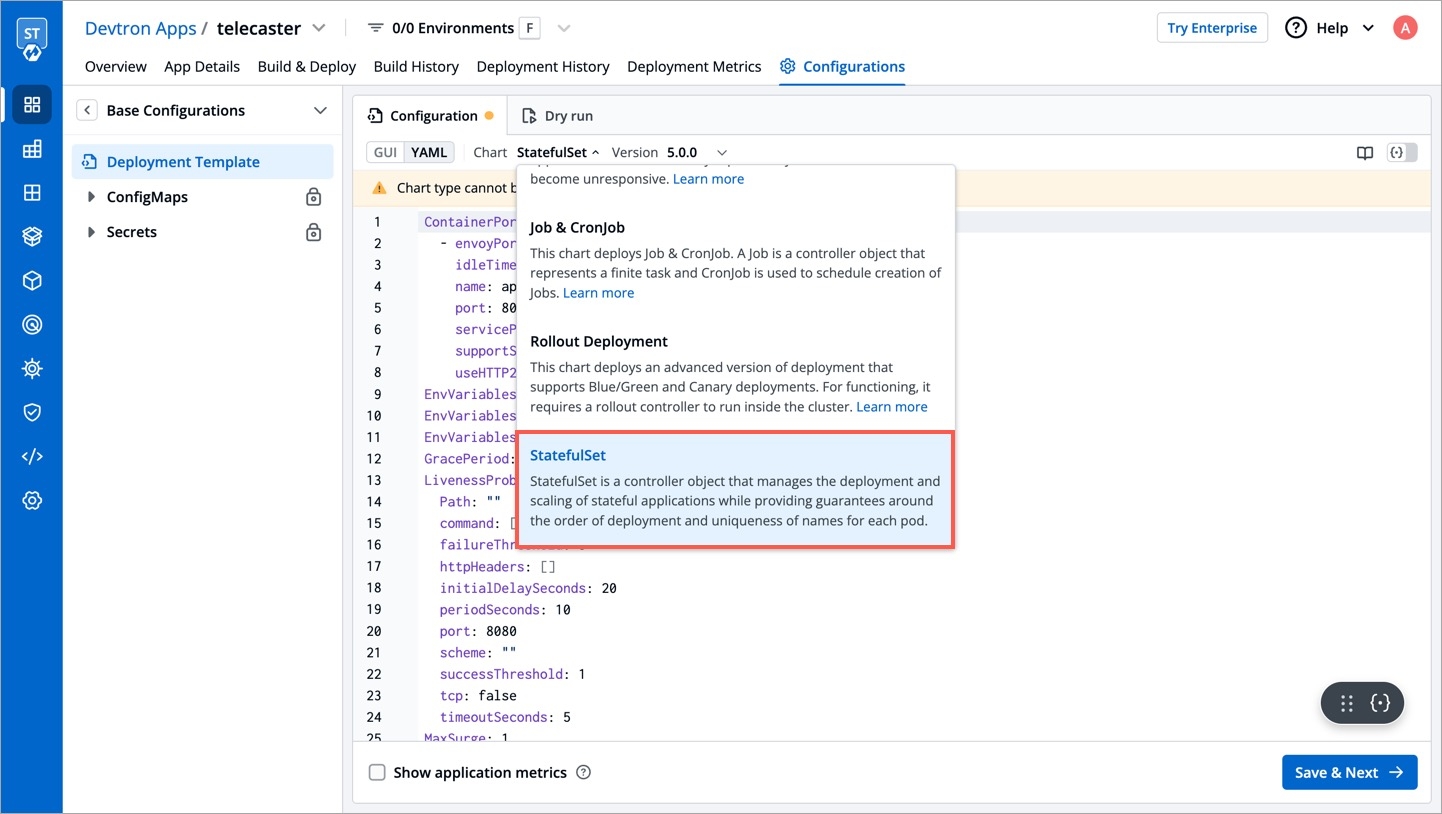
This chart deploys Job & CronJob. A Job is a controller object that represents a finite task and CronJob is used to schedule the creation of Jobs.
A Job creates one or more Pods and will continue to retry execution of the Pods until a specified number of them successfully terminate. As pods successfully complete, the Job tracks the successful completions. When a specified number of successful completions is reached, the task (ie, Job) is complete. Deleting a Job will clean up the Pods it created. Suspeding a Job will delete its active Pods until the Job is resumed again.
A CronJob creates jobs on a repeating schedule. One Cronjob object is like one line of a crontab (cron table) file. It runs a job periodically on a given schedule, written in Cron format. CronJobs are meant for performing regular scheduled actions such as backups, report generation, and so on. Each task must be configured to recur indefinitely (as an example: once a day / week / month). You can schedule the time within that interval when the job should start.
Super-admins can lock keys in Job & CronJob deployment template to prevent non-super-admins from modifying those locked keys. Refer to know more.
concurrencyPolicy
A CronJob is counted as missed if it has failed to be created at its scheduled time. For example, If concurrencyPolicy is set to Forbid and a CronJob was attempted to be scheduled when there was a previous schedule still running, then it would count as missed,Acceptable values: Allow / Forbid.
failedJobsHistoryLimit
The failedJobsHistoryLimit fields are optional. These fields specify how many completed and failed jobs should be kept. By default, they are set to 3 and 1 respectively. Setting a limit to 0 corresponds to keeping none of the corresponding kind of jobs after they finish.
restartPolicy
The spec of a Pod has a restartPolicy field with possible values Always, OnFailure, and Never. The default value is Always.The restartPolicy applies to all containers in the Pod. restartPolicy only refers to restarts of the containers by the kubelet on the same node. After containers in a Pod exit, the kubelet restarts them with an exponential back-off delay (10s, 20s, 40s, …), that is capped at five minutes. Once a container has executed for 10 minutes without any problems, the kubelet resets the restart backoff timer for that container, Acceptable values: Always / OnFailure / Never.
schedule
To generate Cronjob schedule expressions, you can also use web tools like https://crontab.guru/.
startingDeadlineSeconds
If startingDeadlineSeconds is set to a large value or left unset (the default) and if concurrencyPolicy is set to Allow, the jobs will always run at least once.
successfulJobsHistoryLimit
The successfulJobsHistoryLimit fields are optional. These fields specify how many completed and failed jobs should be kept. By default, they are set to 3 and 1 respectively. Setting a limit to 0 corresponds to keeping none of the corresponding kind of jobs after they finish.
suspend
The suspend field is also optional. If it is set to true, all subsequent executions are suspended. This setting does not apply to already started executions. Defaults to false.
kind
As with all other Kubernetes config, a Job and cronjob needs apiVersion, kind.cronjob and job also needs a section fields which is optional . these fields specify to deploy which job (conjob or job) should be kept. by default, they are set cronjob.
activeDeadlineSeconds
Another way to terminate a Job is by setting an active deadline. Do this by setting the activeDeadlineSeconds field of the Job to a number of seconds. The activeDeadlineSeconds applies to the duration of the job, no matter how many Pods are created. Once a Job reaches activeDeadlineSeconds, all of its running Pods are terminated and the Job status will become type: Failed with reason: DeadlineExceeded.
backoffLimit
There are situations where you want to fail a Job after some amount of retries due to a logical error in configuration etc. To do so, set backoffLimit to specify the number of retries before considering a Job as failed. The back-off limit is set by default to 6. Failed Pods associated with the Job are recreated by the Job controller with an exponential back-off delay (10s, 20s, 40s ...) capped at six minutes. The back-off count is reset when a Job's Pod is deleted or successful without any other Pods for the Job failing around that time.
completions
Jobs with fixed completion count - that is , jobs that have non null completions - can have a completion mode that is specified in completionMode.
parallelism
The requested parallelism can be set to any non-negative value. If it is unspecified, it defaults to 1. If it is specified as 0, then the Job is effectively paused until it is increased.
suspend
The suspend field is also optional. If it is set to true, all subsequent executions are suspended. This setting does not apply to already started executions. Defaults to false.
ttlSecondsAfterFinished
The TTL controller only supports Jobs for now. A cluster operator can use this feature to clean up finished Jobs (either Complete or Failed) automatically by specifying the ttlSecondsAfterFinished field of a Job, as in this example. The TTL controller will assume that a resource is eligible to be cleaned up TTL seconds after the resource has finished, in other words, when the TTL has expired. When the TTL controller cleans up a resource, it will delete it cascadingly, that is to say it will delete its dependent objects together with it. Note that when the resource is deleted, its lifecycle guarantees, such as finalizers, will be honored.
kind
As with all other Kubernetes config, a Job and cronjob needs apiVersion, kind.cronjob and job also needs a section fields which is optional . these fields specify to deploy which job (conjob or job) should be kept. by default, they are set job.
This chart creates a deployment that runs multiple replicas of your application and automatically replaces any instances that fail or become unresponsive. It does not support Blue/Green and Canary deployments.
This is the default deployment chart. You can select Deployment chart when you want to use only basic use cases which contain the following:
Create a Deployment to rollout a ReplicaSet. The ReplicaSet creates Pods in the background. Check the status of the rollout to see if it succeeds or not.
Declare the new state of the Pods. A new ReplicaSet is created and the Deployment manages moving the Pods from the old ReplicaSet to the new one at a controlled rate. Each new ReplicaSet updates the revision of the Deployment.
Rollback to an earlier Deployment revision if the current state of the Deployment is not stable. Each rollback updates the revision of the Deployment.
Scale up the Deployment to facilitate more load.
Use the status of the Deployment as an indicator that a rollout has stuck.
Clean up older ReplicaSets that you do not need anymore.
You can define application behavior by providing information in the following sections:
Chart version
Basic Configuration
Advanced (YAML)
Show application metrics
Super-admins can lock keys in deployment template to prevent non-super-admins from modifying those locked keys. Refer Lock Deployment Configuration to know more.
This defines ports on which application services will be exposed to other services
envoyPort
envoy port for the container
idleTimeout
the duration of time that a connection is idle before the connection is terminated
name
name of the port
port
port for the container
servicePort
port of the corresponding kubernetes service
nodePort
nodeport of the corresponding kubernetes service
supportStreaming
Used for high performance protocols like grpc where timeout needs to be disabled
useHTTP2
Envoy container can accept HTTP2 requests
To set environment variables for the containers that run in the Pod.
To set environment variables for the containers and fetching their values from pod-level fields.
If this check fails, kubernetes restarts the pod. This should return error code in case of non-recoverable error.
Path
It define the path where the liveness needs to be checked
initialDelaySeconds
It defines the time to wait before a given container is checked for liveliness
periodSeconds
It defines the time to check a given container for liveness
successThreshold
It defines the number of successes required before a given container is said to fulfill the liveness probe
timeoutSeconds
It defines the time for checking timeout
failureThreshold
It defines the maximum number of failures that are acceptable before a given container is not considered as live
httpHeaders
Custom headers to set in the request. HTTP allows repeated headers, you can override the default headers by defining .httpHeaders for the probe.
scheme
Scheme to use for connecting to the host (HTTP or HTTPS). Defaults to HTTP.
tcp
The kubelet will attempt to open a socket to your container on the specified port. If it can establish a connection, the container is considered healthy.
The maximum number of pods that can be unavailable during the update process. The value of "MaxUnavailable: " can be an absolute number or percentage of the replicas count. The default value of "MaxUnavailable: " is 25%.
The maximum number of pods that can be created over the desired number of pods. For "MaxSurge: " also, the value can be an absolute number or percentage of the replicas count. The default value of "MaxSurge: " is 25%.
This specifies the minimum number of seconds for which a newly created Pod should be ready without any of its containers crashing, for it to be considered available. This defaults to 0 (the Pod will be considered available as soon as it is ready).
If this check fails, kubernetes stops sending traffic to the application. This should return error code in case of errors which can be recovered from if traffic is stopped.
Path
It define the path where the readiness needs to be checked
initialDelaySeconds
It defines the time to wait before a given container is checked for readiness
periodSeconds
It defines the time to check a given container for readiness
successThreshold
It defines the number of successes required before a given container is said to fulfill the readiness probe
timeoutSeconds
It defines the time for checking timeout
failureThreshold
It defines the maximum number of failures that are acceptable before a given container is not considered as ready
httpHeaders
Custom headers to set in the request. HTTP allows repeated headers, you can override the default headers by defining .httpHeaders for the probe.
scheme
Scheme to use for connecting to the host (HTTP or HTTPS). Defaults to HTTP.
tcp
The kubelet will attempt to open a socket to your container on the specified port. If it can establish a connection, the container is considered healthy.
You can create PodDisruptionBudget for each application. A PDB limits the number of pods of a replicated application that are down simultaneously from voluntary disruptions. For example, an application would like to ensure the number of replicas running is never brought below the certain number.
or
You can specify either maxUnavailable or minAvailable in a PodDisruptionBudget and it can be expressed as integers or as a percentage.
minAvailable
Evictions are allowed as long as they leave behind 1 or more healthy pods of the total number of desired replicas.
maxUnavailable
Evictions are allowed as long as at most 1 unhealthy replica among the total number of desired replicas.
You can create ambassador mappings to access your applications from outside the cluster. At its core a Mapping resource maps a resource to a service.
enabled
Set true to enable ambassador mapping else set false
ambassadorId
used to specify id for specific ambassador mappings controller
cors
used to specify cors policy to access host for this mapping
weight
used to specify weight for canary ambassador mappings
hostname
used to specify hostname for ambassador mapping
prefix
used to specify path for ambassador mapping
labels
used to provide custom labels for ambassador mapping
retryPolicy
used to specify retry policy for ambassador mapping
corsPolicy
Provide cors headers on flagger resource
rewrite
used to specify whether to redirect the path of this mapping and where
tls
used to create or define ambassador TLSContext resource
extraSpec
used to provide extra spec values which not present in deployment template for ambassador resource
This is connected to HPA and controls scaling up and down in response to request load.
enabled
Set true to enable autoscaling else set false
MinReplicas
Minimum number of replicas allowed for scaling
MaxReplicas
Maximum number of replicas allowed for scaling
TargetCPUUtilizationPercentage
The target CPU utilization that is expected for a container
TargetMemoryUtilizationPercentage
The target memory utilization that is expected for a container
extraMetrics
Used to give external metrics for autoscaling
You can use flagger for canary releases with deployment objects. It supports flexible traffic routing with istio service mesh as well.
enabled
Set true to enable canary releases using flagger else set false
addOtherGateways
To provide multiple istio gateways for flagger
addOtherHosts
Add multiple hosts for istio service mesh with flagger
analysis
Define how the canary release should progress and at what interval
annotations
Annotation to add on flagger resource
labels
Labels to add on flagger resource
appProtocol
Protocol to use for canary
corsPolicy
Provide cors headers on flagger resource
createIstioGateway
Set to true if you want to create istio gateway as well with flagger
headers
Add headers if any
loadtest
Enable load testing for your canary release
fullnameOverride replaces the release fullname created by default by devtron, which is used to construct Kubernetes object names. By default, devtron uses {app-name}-{environment-name} as release fullname.
Image is used to access images in kubernetes, pullpolicy is used to define the instances calling the image, here the image is pulled when the image is not present,it can also be set as "Always".
imagePullSecrets contains the docker credentials that are used for accessing a registry.
regcred is the secret that contains the docker credentials that are used for accessing a registry. Devtron will not create this secret automatically, you'll have to create this secret using dt-secrets helm chart in the App store or create one using kubectl. You can follow this documentation Pull an Image from a Private Registry https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/ .
enabled
Determines whether to create a ServiceAccount for pods or not. If set to true, a ServiceAccount will be created.
name
Specifies the name of the ServiceAccount to use.
annotations
Specify annotations for the ServiceAccount.
the hostAliases field is used in a Pod specification to associate additional hostnames with the Pod's IP address. This can be helpful in scenarios where you need to resolve specific hostnames to the Pod's IP within the Pod itself.
This allows public access to the url, please ensure you are using right nginx annotation for nginx class, its default value is nginx
Legacy deployment-template ingress format
enabled
Enable or disable ingress
annotations
To configure some options depending on the Ingress controller
path
Path name
host
Host name
tls
It contains security details
This allows private access to the url, please ensure you are using right nginx annotation for nginx class, its default value is nginx
enabled
Enable or disable ingress
annotations
To configure some options depending on the Ingress controller
path
Path name
host
Host name
tls
It contains security details
Specialized containers that run before app containers in a Pod. Init containers can contain utilities or setup scripts not present in an app image. One can use base image inside initContainer by setting the reuseContainerImage flag to true.
To wait for given period of time before switch active the container.
These define minimum and maximum RAM and CPU available to the application.
Resources are required to set CPU and memory usage.
Limits make sure a container never goes above a certain value. The container is only allowed to go up to the limit, and then it is restricted.
Requests are what the container is guaranteed to get.
This defines annotations and the type of service, optionally can define name also.
It is required when some values need to be read from or written to an external disk.
It is used to provide mounts to the volume.
Spec is used to define the desire state of the given container.
Node Affinity allows you to constrain which nodes your pod is eligible to schedule on, based on labels of the node.
Inter-pod affinity allow you to constrain which nodes your pod is eligible to be scheduled based on labels on pods.
Key part of the label for node selection, this should be same as that on node. Please confirm with devops team.
Value part of the label for node selection, this should be same as that on node. Please confirm with devops team.
Taints are the opposite, they allow a node to repel a set of pods.
A given pod can access the given node and avoid the given taint only if the given pod satisfies a given taint.
Taints and tolerations are a mechanism which work together that allows you to ensure that pods are not placed on inappropriate nodes. Taints are added to nodes, while tolerations are defined in the pod specification. When you taint a node, it will repel all the pods except those that have a toleration for that taint. A node can have one or many taints associated with it.
This is used to give arguments to command.
It contains the commands for the server.
enabled
To enable or disable the command
value
It contains the commands
Containers section can be used to run side-car containers along with your main container within same pod. Containers running within same pod can share volumes and IP Address and can address each other @localhost. We can use base image inside container by setting the reuseContainerImage flag to true.
Container lifecycle hooks are mechanisms that allow users to define custom actions to be performed at specific stages of a container's lifecycle i.e. PostStart or PreStop.
containerSpec
containerSpec to define container lifecycle hooks configuration
lifecycle
Lifecycle hooks for the container
enabled
Set true to enable lifecycle hooks for the container else set false
postStart
The postStart hook is executed immediately after a container is created
httpsGet
Sends an HTTP GET request to a specific endpoint on the container
host
Specifies the host (example.com) to which the HTTP GET request will be sent
path
Specifies the path (/example) of the endpoint to which the HTTP GET request will be sent
port
Specifies the port (90) on the host where the HTTP GET request will be sent
preStop
The preStop hook is executed just before the container is stopped
exec
Executes a specific command, such as pre-stop.sh, inside the cgroups and namespaces of the container
command
The command to be executed is sleep 10, which tells the container to sleep for 10 seconds before it is stopped
It is a kubernetes monitoring tool and the name of the file to be monitored as monitoring in the given case. It describes the state of the Prometheus.
Accepts an array of Kubernetes objects. You can specify any kubernetes yaml here and it will be applied when your app gets deployed.
Kubernetes waits for the specified time called the termination grace period before terminating the pods. By default, this is 30 seconds. If your pod usually takes longer than 30 seconds to shut down gracefully, make sure you increase the GracePeriod.
A Graceful termination in practice means that your application needs to handle the SIGTERM message and begin shutting down when it receives it. This means saving all data that needs to be saved, closing down network connections, finishing any work that is left, and other similar tasks.
There are many reasons why Kubernetes might terminate a perfectly healthy container. If you update your deployment with a rolling update, Kubernetes slowly terminates old pods while spinning up new ones. If you drain a node, Kubernetes terminates all pods on that node. If a node runs out of resources, Kubernetes terminates pods to free those resources. It’s important that your application handle termination gracefully so that there is minimal impact on the end user and the time-to-recovery is as fast as possible.
It is used for providing server configurations.
It gives the details for deployment.
image_tag
It is the image tag
image
It is the URL of the image
It gives the set of targets to be monitored.
It is used to configure database migration.
These Istio configurations collectively provide a comprehensive set of tools for controlling access, authenticating requests, enforcing security policies, and configuring traffic behavior within a microservices architecture. The specific settings you choose would depend on your security and traffic management requirements.
istio
Istio enablement. When istio.enable set to true, Istio would be enabled for the specified configurations
authorizationPolicy
It allows you to define access control policies for service-to-service communication.
action
Determines whether to ALLOW or DENY the request based on the defined rules.
provider
Authorization providers are external systems or mechanisms used to make access control decisions.
rules
List of rules defining the authorization policy. Each rule can specify conditions and requirements for allowing or denying access.
destinationRule
It allows for the fine-tuning of traffic policies and load balancing for specific services. You can define subsets of a service and apply different traffic policies to each subset.
subsets
Specifies subsets within the service for routing and load balancing.
trafficPolicy
Policies related to connection pool size, outlier detection, and load balancing.
gateway
Allowing external traffic to enter the service mesh through the specified configurations.
host
The external domain through which traffic will be routed into the service mesh.
tls
Traffic to and from the gateway should be encrypted using TLS.
secretName
Specifies the name of the Kubernetes secret that contains the TLS certificate and private key. The TLS certificate is used for securing the communication between clients and the Istio gateway.
peerAuthentication
It allows you to enforce mutual TLS and control the authentication between services.
mtls
Mutual TLS. Mutual TLS is a security protocol that requires both client and server, to authenticate each other using digital certificates for secure communication.
mode
Mutual TLS mode, specifying how mutual TLS should be applied. Modes include STRICT, PERMISSIVE, and DISABLE.
portLevelMtls
Configures port-specific mTLS settings. Allows for fine-grained control over the application of mutual TLS on specific ports.
selector
Configuration for selecting workloads to apply PeerAuthentication.
requestAuthentication
Defines rules for authenticating incoming requests.
jwtRules
Rules for validating JWTs (JSON Web Tokens). It defines how incoming JWTs should be validated for authentication purposes.
selector
Specifies the conditions under which the RequestAuthentication rules should be applied.
virtualService
Enables the definition of rules for how traffic should be routed to different services within the service mesh.
gateways
Specifies the gateways to which the rules defined in the VirtualService apply.
hosts
List of hosts (domains) to which this VirtualService is applied.
http
Configuration for HTTP routes within the VirtualService. It define routing rules based on HTTP attributes such as URI prefixes, headers, timeouts, and retry policies.
KEDA is a Kubernetes-based Event Driven Autoscaler. With KEDA, you can drive the scaling of any container in Kubernetes based on the number of events needing to be processed. KEDA can be installed into any Kubernetes cluster and can work alongside standard Kubernetes components like the Horizontal Pod Autoscaler(HPA).
Example for autosccaling with KEDA using Prometheus metrics is given below:
Example for autosccaling with KEDA based on kafka is given below :
Kubernetes NetworkPolicies control pod communication by defining rules for incoming and outgoing traffic.
enabled
Enable or disable NetworkPolicy.
annotations
Additional metadata or information associated with the NetworkPolicy.
labels
Labels to apply to the NetworkPolicy.
podSelector
Each NetworkPolicy includes a podSelector which selects the grouping of pods to which the policy applies. The example policy selects pods with the label "role=db". An empty podSelector selects all pods in the namespace.
policyTypes
Each NetworkPolicy includes a policyTypes list which may include either Ingress, Egress, or both.
Ingress
Controls incoming traffic to pods.
Egress
Controls outgoing traffic from pods.
Winter Soldier can be used to
cleans up (delete) Kubernetes resources
reduce workload pods to 0
NOTE: After deploying this we can create the Hibernator object and provide the custom configuration by which workloads going to delete, sleep and many more. for more information check the main repo
Given below is template values you can give in winter-soldier:
enabled
false,true
decide the enabling factor
apiVersion
pincher.devtron.ai/v1beta1, pincher.devtron.ai/v1alpha1
specific api version
action
sleep,delete, scale
This specify the action need to perform.
timeRangesWithZone:timeZone
eg:- "Asia/Kolkata","US/Pacific"
timeRangesWithZone:timeRanges
array of [ timeFrom, timeTo, weekdayFrom, weekdayTo]
It use to define time period/range on which the user need to perform the specified action. you can have multiple timeRanges.
These settings will take action on Sat and Sun from 00:00 to 23:59:59,
targetReplicas
[n] : n - number of replicas to scale.
These is mandatory field when the action is scale
Default value is [].
fieldSelector
- AfterTime(AddTime( ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z'), '5m'), Now())
These value will take a list of methods to select the resources on which we perform specified action .
here is an example,
Above settings will take action on Sat and Sun from 00:00 to 23:59:59, and on Mon-Fri from 00:00 to 08:00 and 20:00 to 23:59:59. If action:sleep then runs hibernate at timeFrom and unhibernate at timeTo. If action: delete then it will delete workloads at timeFrom and timeTo. Here the action:scale thus it scale the number of resource replicas to targetReplicas: [1,1,1]. Here each element of targetReplicas array is mapped with the corresponding elements of array timeRangesWithZone/timeRanges. Thus make sure the length of both array is equal, otherwise the cnages cannot be observed.
The above example will select the application objects which have been created 10 hours ago across all namespaces excluding application's namespace. Winter soldier exposes following functions to handle time, cpu and memory.
ParseTime - This function can be used to parse time. For eg to parse creationTimestamp use ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z')
AddTime - This can be used to add time. For eg AddTime(ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z'), '-10h') ll add 10h to the time. Use d for day, h for hour, m for minutes and s for seconds. Use negative number to get earlier time.
Now - This can be used to get current time.
CpuToNumber - This can be used to compare CPU. For eg any({{spec.containers.#.resources.requests}}, { MemoryToNumber(.memory) < MemoryToNumber('60Mi')}) will check if any resource.requests is less than 60Mi.
A security context defines privilege and access control settings for a Pod or Container.
To add a security context for main container:
To add a security context on pod level:
You can use topology spread constraints to control how Pods are spread across your cluster among failure-domains such as regions, zones, nodes, and other user-defined topology domains. This can help to achieve high availability as well as efficient resource utilization.
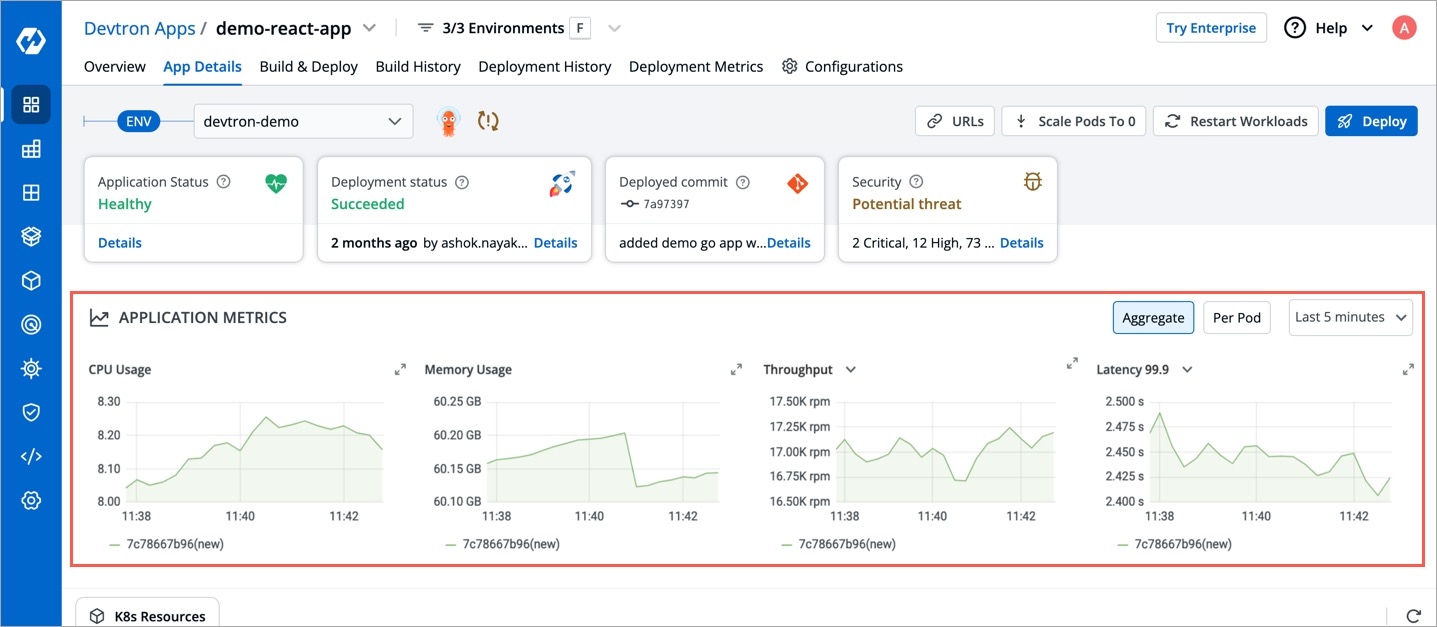
It gives the realtime metrics of the deployed applications
Deployment Frequency
It shows how often this app is deployed to production
Change Failure Rate
It shows how often the respective pipeline fails
Mean Lead Time
It shows the average time taken to deliver a change to production
Mean Time to Recovery
It shows the average time taken to fix a failed pipeline
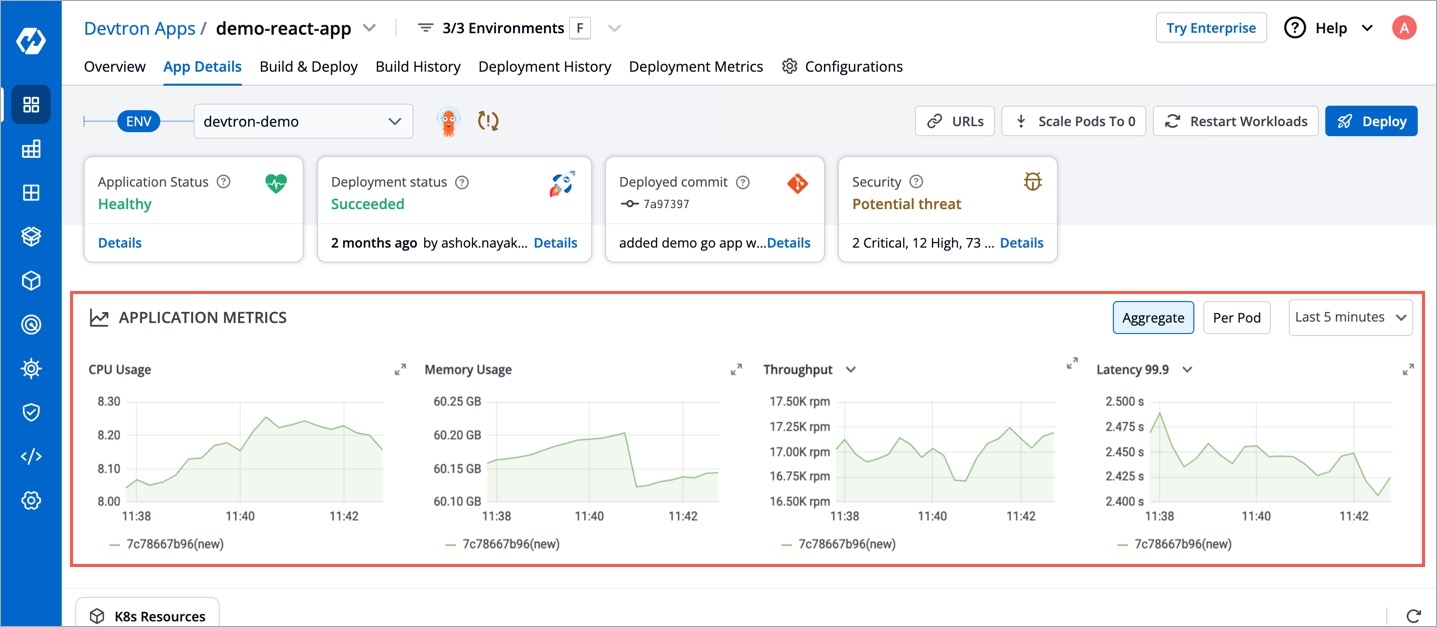
If you want to see application metrics like different HTTP status codes metrics, application throughput, latency, response time. Enable the Application metrics from below the deployment template Save button. After enabling it, you should be able to see all metrics on App detail page. By default it remains disabled.
Once all the Deployment template configurations are done, click on Save to save your deployment configuration. Now you are ready to create Workflow to do CI/CD.
Helm Chart json schema is used to validate the deployment template values.
The values of CPU and Memory in limits must be greater than or equal to in requests respectively. Similarly, In case of envoyproxy, the values of limits are greater than or equal to requests as mentioned below.
Select the Chart Version using which you want to deploy the application. Refer section for more detail.
You can select the basic deployment configuration for your application on the Basic GUI section instead of configuring the YAML file. Refer section for more detail.
If you want to do additional configurations, then click Advanced (YAML) for modifications. Refer section for more detail.
You can enable Show application metrics to see your application's metrics-CPU Service Monitor usage, Memory Usage, Status, Throughput and Latency.
Refer for more detail.
It use to specify the timeZone used. (It uses standard format. please refer )
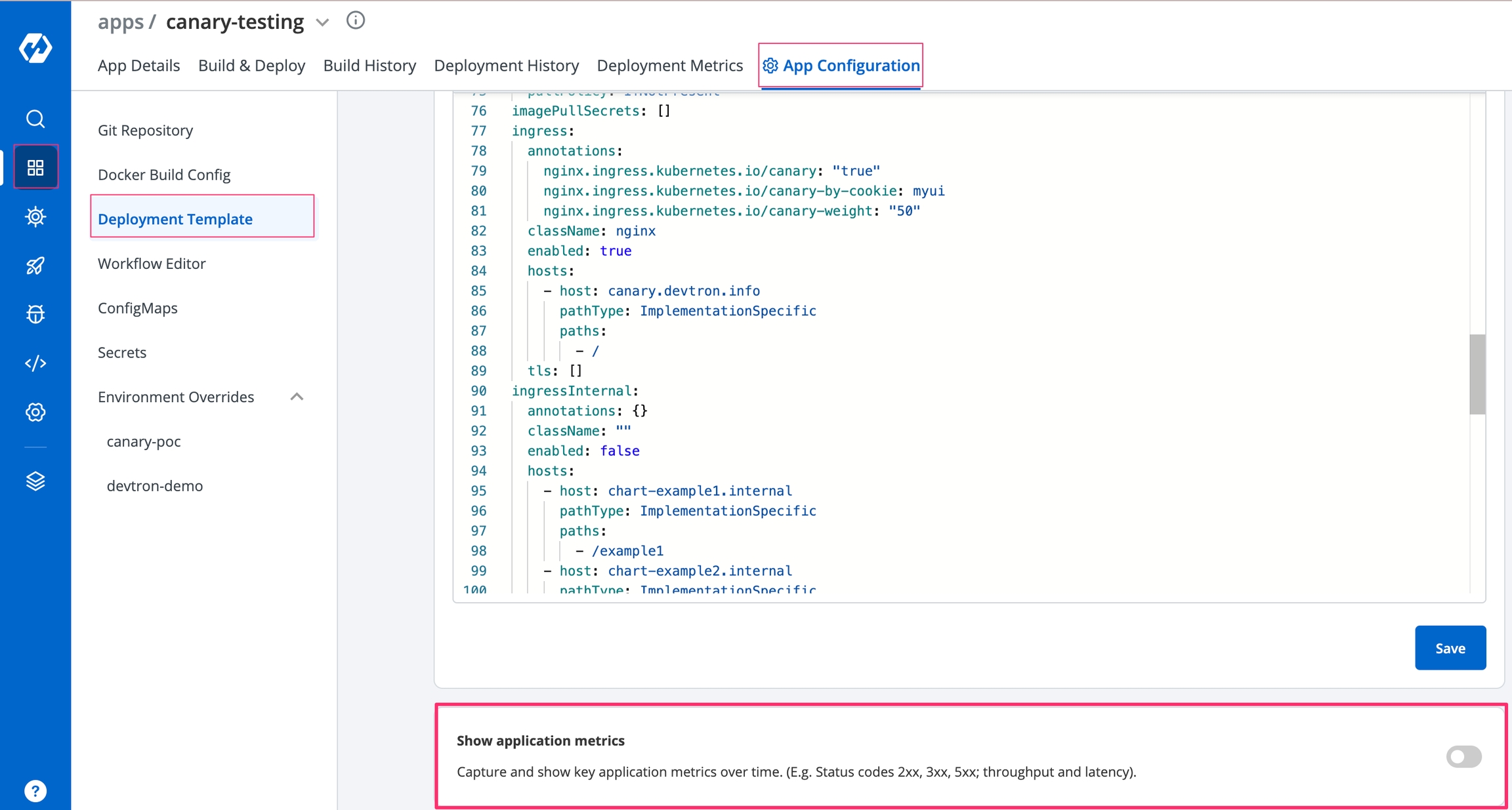
The Rollout Deployment chart deploys an advanced version of deployment that supports Blue/Green and Canary deployments. For functioning, it requires a rollout controller to run inside the cluster.
You can define application behavior by providing information in the following sections:
Super-admins can lock keys in rollout deployment template to prevent non-super-admins from modifying those locked keys. Refer Lock Deployment Configuration to know more.
Chart Version
Select the Chart Version using which you want to deploy the application.
Devtron uses helm charts for the deployments. And we are having multiple chart versions based on features it is supporting with every chart version.
One can see multiple chart version options available in the drop-down. you can select any chart version as per your requirements. By default, the latest version of the helm chart is selected in the chart version option.
Every chart version has its own YAML file. Helm charts are used to provide specifications for your application. To make it easy to use, we have created templates for the YAML file and have added some variables inside the YAML. You can provide or change the values of these variables as per your requirement.
If you want to see Application Metrics (as an example, Status codes 2xx, 3xx, 5xx; throughput, and latency etc.) for your application, then you need to select the latest chart version.
Note: Application Metrics are not supported for the Chart version older than 3.7 version.
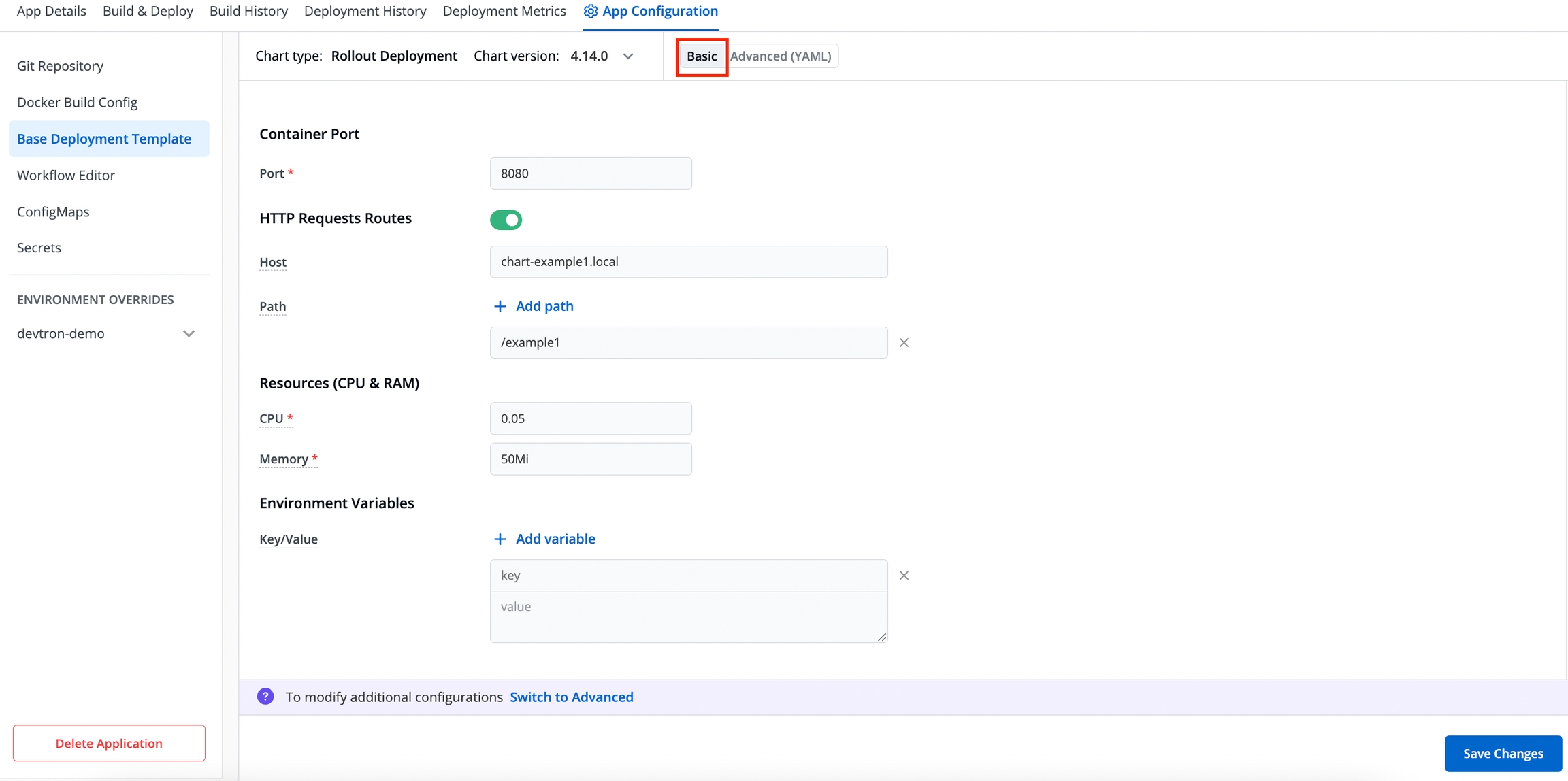
Some of the use-cases which are defined on the Deployment Template (YAML file) may not be applicable to configure for your application. In such cases, you can do the basic deployment configuration for your application on the Basic GUI section instead of configuring the YAML file.
The following fields are provided on the Basic GUI section:
Port
The internal HTTP port.
HTTP Request Routes
Enable the HTTP Request Routes to define Host and Path. By default, it is in disabled state.
Host: Domain name of the server.
Path: Path of the specific component in the host that the HTTP wants to access.
You can define multiple paths as required by clicking Add path.
CPU
The CPU resource as per the application.
RAM
The RAM resource as per the application.
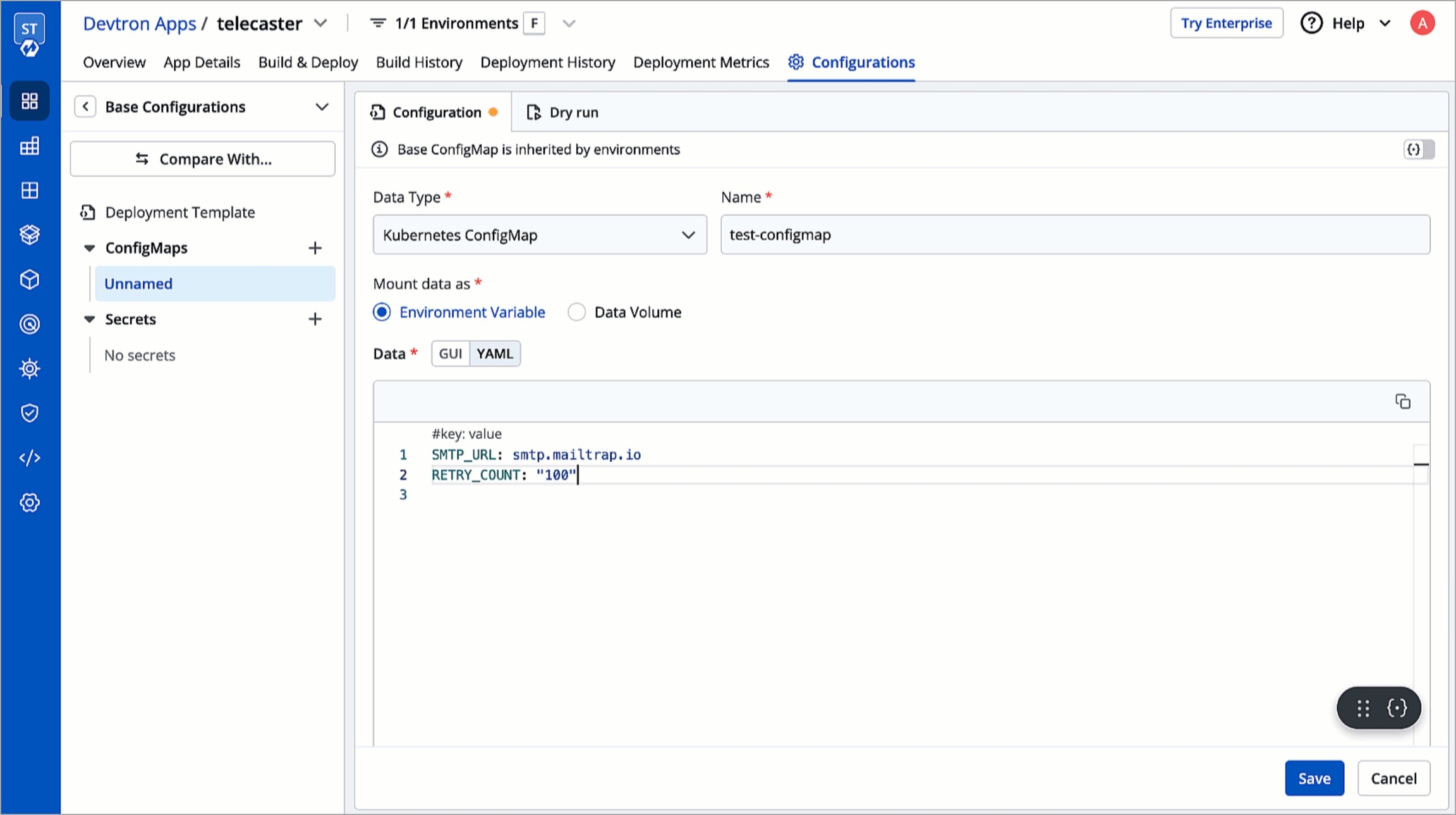
Environment Variables (Key/Value)
Define key/value by clicking Add variable.
Key: Define the key of the environment.
Value: Define the value of the environment.
You can define multiple env variables by clicking Add variable.
Click Save Changes.
If you want to do additional configurations, then click Advanced (YAML) for modifications.
Note: If you change any values in the Basic GUI, then the corresponding values will be changed in YAML file also.
This defines the ports on which application services will be exposed to other services.
envoyPort
envoy port for the container.
envoyTimeout
envoy Timeout for the container,envoy supports a wide range of timeouts that may need to be configured depending on the deployment.By default the envoytimeout is 15s.
idleTimeout
the duration of time that a connection is idle before the connection is terminated.
name
name of the port.
port
port for the container.
servicePort
port of the corresponding kubernetes service.
supportStreaming
Used for high performance protocols like grpc where timeout needs to be disabled.
useHTTP2
Envoy container can accept HTTP2 requests.
EnvVariables provide run-time information to containers and allow to customize how the application works and the behavior of the applications on the system.
Here we can pass the list of env variables , every record is an object which contain the name of variable along with value.
To set environment variables for the containers that run in the Pod.
IMP Docker image should have env variables, whatever we want to set.
But ConfigMap and Secret are the preferred way to inject env variables. You can create this in App Configuration Section.
It is a centralized storage, specific to k8s namespace where key-value pairs are stored in plain text.
It is a centralized storage, specific to k8s namespace where we can store the key-value pairs in plain text as well as in encrypted(Base64) form.
IMP All key-values of Secret and CofigMap will reflect to your application.
If this check fails, kubernetes restarts the pod. This should return error code in case of non-recoverable error.
Path
It define the path where the liveness needs to be checked.
initialDelaySeconds
It defines the time to wait before a given container is checked for liveliness.
periodSeconds
It defines how often (in seconds) to perform the liveness probe.
successThreshold
It defines the number of successes required before a given container is said to fulfil the liveness probe.
timeoutSeconds
The maximum time (in seconds) for the probe to complete.
failureThreshold
The number of consecutive failures required to consider the probe as failed.
command
The mentioned command is executed to perform the livenessProbe. If the command returns a non-zero value, it's equivalent to a failed probe.
httpHeaders
Custom headers to set in the request. HTTP allows repeated headers,You can override the default headers by defining .httpHeaders for the probe.
scheme
Scheme to use for connecting to the host (HTTP or HTTPS). Defaults to HTTP.
tcp
The kubelet will attempt to open a socket to your container on the specified port. If it can establish a connection, the container is considered healthy.
The maximum number of pods that can be unavailable during the update process. The value of "MaxUnavailable: " can be an absolute number or percentage of the replicas count. The default value of "MaxUnavailable: " is 25%.
The maximum number of pods that can be created over the desired number of pods. For "MaxSurge: " also, the value can be an absolute number or percentage of the replicas count. The default value of "MaxSurge: " is 25%.
This specifies the minimum number of seconds for which a newly created Pod should be ready without any of its containers crashing, for it to be considered available. This defaults to 0 (the Pod will be considered available as soon as it is ready).
If this check fails, kubernetes stops sending traffic to the application. This should return error code in case of errors which can be recovered from if traffic is stopped.
Path
It define the path where the readiness needs to be checked.
initialDelaySeconds
It defines the time to wait before a given container is checked for readiness.
periodSeconds
It defines how often (in seconds) to perform the readiness probe.
successThreshold
It defines the number of successes required before a given container is said to fulfill the readiness probe.
timeoutSeconds
The maximum time (in seconds) for the probe to complete.
failureThreshold
The number of consecutive failures required to consider the probe as failed.
command
The mentioned command is executed to perform the readinessProbe. If the command returns a non-zero value, it's equivalent to a failed probe.
httpHeaders
Custom headers to set in the request. HTTP allows repeated headers,You can override the default headers by defining .httpHeaders for the probe.
scheme
Scheme to use for connecting to the host (HTTP or HTTPS). Defaults to HTTP.
tcp
The kubelet will attempt to open a socket to your container on the specified port. If it can establish a connection, the container is considered healthy.
Startup Probe in Kubernetes is a type of probe used to determine when a container within a pod is ready to start accepting traffic. It is specifically designed for applications that have a longer startup time.
Path
It define the path where the startup needs to be checked.
initialDelaySeconds
It defines the time to wait before a given container is checked for startup.
periodSeconds
It defines how often (in seconds) to perform the startup probe.
successThreshold
The number of consecutive successful probe results required to mark the container as ready.
timeoutSeconds
The maximum time (in seconds) for the probe to complete.
failureThreshold
The number of consecutive failures required to consider the probe as failed.
command
The mentioned command is executed to perform the startup probe. If the command returns a non-zero value, it's equivalent to a failed probe.
httpHeaders
Custom headers to set in the request. HTTP allows repeated headers,You can override the default headers by defining .httpHeaders for the probe.
tcp
The kubelet will attempt to open a socket to your container on the specified port. If it can establish a connection, the container is considered healthy.
This is connected to HPA and controls scaling up and down in response to request load.
enabled
Set true to enable autoscaling else set false.
MinReplicas
Minimum number of replicas allowed for scaling.
MaxReplicas
Maximum number of replicas allowed for scaling.
TargetCPUUtilizationPercentage
The target CPU utilization that is expected for a container.
TargetMemoryUtilizationPercentage
The target memory utilization that is expected for a container.
extraMetrics
Used to give external metrics for autoscaling.
fullnameOverride replaces the release fullname created by default by devtron, which is used to construct Kubernetes object names. By default, devtron uses {app-name}-{environment-name} as release fullname.
Image is used to access images in kubernetes, pullpolicy is used to define the instances calling the image, here the image is pulled when the image is not present,it can also be set as "Always".
enabled
Determines whether to create a ServiceAccount for pods or not. If set to true, a ServiceAccount will be created.
name
Specifies the name of the ServiceAccount to use.
annotations
Specify annotations for the ServiceAccount.
imagePullSecrets contains the docker credentials that are used for accessing a registry.
regcred is the secret that contains the docker credentials that are used for accessing a registry. Devtron will not create this secret automatically, you'll have to create this secret using dt-secrets helm chart in the App store or create one using kubectl. You can follow this documentation Pull an Image from a Private Registry https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/ .
the hostAliases field is used in a Pod specification to associate additional hostnames with the Pod's IP address. This can be helpful in scenarios where you need to resolve specific hostnames to the Pod's IP within the Pod itself.
This allows public access to the url. Please ensure you are using the right nginx annotation for nginx class. The default value is nginx.
Legacy deployment-template ingress format
enabled
Enable or disable ingress
annotations
To configure some options depending on the Ingress controller
host
Host name
pathType
Path in an Ingress is required to have a corresponding path type. Supported path types are ImplementationSpecific, Exact and Prefix.
path
Path name
tls
It contains security details
This allows private access to the url, please ensure you are using right nginx annotation for nginx class, its default value is nginx
enabled
Enable or disable ingress
annotations
To configure some options depending on the Ingress controller
host
Host name
pathType
Path in an Ingress is required to have a corresponding path type. Supported path types are ImplementationSpecific, Exact and Prefix.
path
Path name
pathType
Supported path types are ImplementationSpecific, Exact and Prefix.
tls
It contains security details
Specialized containers that run before app containers in a Pod. Init containers can contain utilities or setup scripts not present in an app image. One can use base image inside initContainer by setting the reuseContainerImage flag to true.
To wait for given period of time before switch active the container.
These define minimum and maximum RAM and CPU available to the application.
Resources are required to set CPU and memory usage.
Limits make sure a container never goes above a certain value. The container is only allowed to go up to the limit, and then it is restricted.
Requests are what the container is guaranteed to get.
This defines annotations and the type of service, optionally can define name also.
type
Select the type of service, default ClusterIP
annotations
Annotations are widely used to attach metadata and configs in Kubernetes.
name
Optional field to assign name to service
loadBalancerSourceRanges
If service type is LoadBalancer, Provide a list of whitelisted IPs CIDR that will be allowed to use the Load Balancer.
Note - If loadBalancerSourceRanges is not set, Kubernetes allows traffic from 0.0.0.0/0 to the LoadBalancer / Node Security Group(s).
It is required when some values need to be read from or written to an external disk.
It is used to provide mounts to the volume.
Spec is used to define the desire state of the given container.
Node Affinity allows you to constrain which nodes your pod is eligible to schedule on, based on labels of the node.
Inter-pod affinity allow you to constrain which nodes your pod is eligible to be scheduled based on labels on pods.
Key part of the label for node selection, this should be same as that on node. Please confirm with devops team.
Value part of the label for node selection, this should be same as that on node. Please confirm with devops team.
Taints are the opposite, they allow a node to repel a set of pods.
A given pod can access the given node and avoid the given taint only if the given pod satisfies a given taint.
Taints and tolerations are a mechanism which work together that allows you to ensure that pods are not placed on inappropriate nodes. Taints are added to nodes, while tolerations are defined in the pod specification. When you taint a node, it will repel all the pods except those that have a toleration for that taint. A node can have one or many taints associated with it.
This is used to give arguments to command.
It contains the commands to run inside the container.
enabled
To enable or disable the command.
value
It contains the commands.
workingDir
It is used to specify the working directory where commands will be executed.
Containers section can be used to run side-car containers along with your main container within same pod. Containers running within same pod can share volumes and IP Address and can address each other @localhost. We can use base image inside container by setting the reuseContainerImage flag to true.
It is a kubernetes monitoring tool and the name of the file to be monitored as monitoring in the given case.It describes the state of the prometheus.
Accepts an array of Kubernetes objects. You can specify any kubernetes yaml here and it will be applied when your app gets deployed.
Kubernetes waits for the specified time called the termination grace period before terminating the pods. By default, this is 30 seconds. If your pod usually takes longer than 30 seconds to shut down gracefully, make sure you increase the GracePeriod.
A Graceful termination in practice means that your application needs to handle the SIGTERM message and begin shutting down when it receives it. This means saving all data that needs to be saved, closing down network connections, finishing any work that is left, and other similar tasks.
There are many reasons why Kubernetes might terminate a perfectly healthy container. If you update your deployment with a rolling update, Kubernetes slowly terminates old pods while spinning up new ones. If you drain a node, Kubernetes terminates all pods on that node. If a node runs out of resources, Kubernetes terminates pods to free those resources. It’s important that your application handle termination gracefully so that there is minimal impact on the end user and the time-to-recovery is as fast as possible.
It is used for providing server configurations.
It gives the details for deployment.
image_tag
It is the image tag
image
It is the URL of the image
It gives the set of targets to be monitored.
It is used to configure database migration.
These Istio configurations collectively provide a comprehensive set of tools for controlling access, authenticating requests, enforcing security policies, and configuring traffic behavior within a microservices architecture. The specific settings you choose would depend on your security and traffic management requirements.
These Istio configurations collectively provide a comprehensive set of tools for controlling access, authenticating requests, enforcing security policies, and configuring traffic behavior within a microservices architecture. The specific settings you choose would depend on your security and traffic management requirements.
istio
Istio enablement. When istio.enable set to true, Istio would be enabled for the specified configurations
authorizationPolicy
It allows you to define access control policies for service-to-service communication.
action
Determines whether to ALLOW or DENY the request based on the defined rules.
provider
Authorization providers are external systems or mechanisms used to make access control decisions.
rules
List of rules defining the authorization policy. Each rule can specify conditions and requirements for allowing or denying access.
destinationRule
It allows for the fine-tuning of traffic policies and load balancing for specific services. You can define subsets of a service and apply different traffic policies to each subset.
subsets
Specifies subsets within the service for routing and load balancing.
trafficPolicy
Policies related to connection pool size, outlier detection, and load balancing.
gateway
Allowing external traffic to enter the service mesh through the specified configurations.
host
The external domain through which traffic will be routed into the service mesh.
tls
Traffic to and from the gateway should be encrypted using TLS.
secretName
Specifies the name of the Kubernetes secret that contains the TLS certificate and private key. The TLS certificate is used for securing the communication between clients and the Istio gateway.
peerAuthentication
It allows you to enforce mutual TLS and control the authentication between services.
mtls
Mutual TLS. Mutual TLS is a security protocol that requires both client and server, to authenticate each other using digital certificates for secure communication.
mode
Mutual TLS mode, specifying how mutual TLS should be applied. Modes include STRICT, PERMISSIVE, and DISABLE.
portLevelMtls
Configures port-specific mTLS settings. Allows for fine-grained control over the application of mutual TLS on specific ports.
selector
Configuration for selecting workloads to apply PeerAuthentication.
requestAuthentication
Defines rules for authenticating incoming requests.
jwtRules
Rules for validating JWTs (JSON Web Tokens). It defines how incoming JWTs should be validated for authentication purposes.
selector
Specifies the conditions under which the RequestAuthentication rules should be applied.
virtualService
Enables the definition of rules for how traffic should be routed to different services within the service mesh.
gateways
Specifies the gateways to which the rules defined in the VirtualService apply.
hosts
List of hosts (domains) to which this VirtualService is applied.
http
Configuration for HTTP routes within the VirtualService. It define routing rules based on HTTP attributes such as URI prefixes, headers, timeouts, and retry policies.
Application metrics can be enabled to see your application's metrics-CPU Service Monitor usage, Memory Usage, Status, Throughput and Latency.
It gives the realtime metrics of the deployed applications
Deployment Frequency
It shows how often this app is deployed to production
Change Failure Rate
It shows how often the respective pipeline fails.
Mean Lead Time
It shows the average time taken to deliver a change to production.
Mean Time to Recovery
It shows the average time taken to fix a failed pipeline.
A service account provides an identity for the processes that run in a Pod.
When you access the cluster, you are authenticated by the API server as a particular User Account. Processes in containers inside pod can also contact the API server. When you are authenticated as a particular Service Account.
When you create a pod, if you do not create a service account, it is automatically assigned the default service account in the namespace.
You can create PodDisruptionBudget for each application. A PDB limits the number of pods of a replicated application that are down simultaneously from voluntary disruptions. For example, an application would like to ensure the number of replicas running is never brought below the certain number.
or
You can specify either maxUnavailable or minAvailable in a PodDisruptionBudget and it can be expressed as integers or as a percentage.
minAvailable
Evictions are allowed as long as they leave behind 1 or more healthy pods of the total number of desired replicas.
maxUnavailable
Evictions are allowed as long as at most 1 unhealthy replica among the total number of desired replicas.
Envoy is attached as a sidecar to the application container to collect metrics like 4XX, 5XX, Throughput and latency. You can now configure the envoy settings such as idleTimeout, resources etc.
Alerting rules allow you to define alert conditions based on Prometheus expressions and to send notifications about firing alerts to an external service.
In this case, Prometheus will check that the alert continues to be active during each evaluation for 1 minute before firing the alert. Elements that are active, but not firing yet, are in the pending state.
Labels are key/value pairs that are attached to pods. Labels are intended to be used to specify identifying attributes of objects that are meaningful and relevant to users, but do not directly imply semantics to the core system. Labels can be used to organize and to select subsets of objects.
Pod Annotations are widely used to attach metadata and configs in Kubernetes.
HPA, by default is configured to work with CPU and Memory metrics. These metrics are useful for internal cluster sizing, but you might want to configure wider set of metrics like service latency, I/O load etc. The custom metrics in HPA can help you to achieve this.
Wait for given period of time before scaling down the container.
If you want to see application metrics like different HTTP status codes metrics, application throughput, latency, response time. Enable the Application metrics from below the deployment template Save button. After enabling it, you should be able to see all metrics on App detail page. By default it remains disabled.
Once all the Deployment template configurations are done, click on Save to save your deployment configuration. Now you are ready to create Workflow to do CI/CD.
Helm Chart json schema is used to validate the deployment template values.
reference-chart_3-12-0
reference-chart_3-11-0
reference-chart_3-10-0
reference-chart_3-9-0
The values of CPU and Memory in limits must be greater than or equal to in requests respectively. Similarly, In case of envoyproxy, the values of limits are greater than or equal to requests as mentioned below.
Prerequisite: KEDA controller should be installed in the cluster. To install KEDA controller using Helm, navigate to chart store and search for keda chart and deploy it. You can follow this documentation for deploying a Helm chart on Devtron.
KEDA Helm repo : https://kedacore.github.io/charts
KEDA is a Kubernetes-based Event Driven Autoscaler. With KEDA, you can drive the scaling of any container in Kubernetes based on the number of events needing to be processed. KEDA can be installed into any Kubernetes cluster and can work alongside standard Kubernetes components like the Horizontal Pod Autoscaler(HPA).
Example for autoscaling with KEDA using Prometheus metrics is given below:
Example for autosccaling with KEDA based on kafka is given below :
Kubernetes NetworkPolicies control pod communication by defining rules for incoming and outgoing traffic.
enabled
Enable or disable NetworkPolicy.
annotations
Additional metadata or information associated with the NetworkPolicy.
labels
Labels to apply to the NetworkPolicy.
podSelector
Each NetworkPolicy includes a podSelector which selects the grouping of pods to which the policy applies. The example policy selects pods with the label "role=db". An empty podSelector selects all pods in the namespace.
policyTypes
Each NetworkPolicy includes a policyTypes list which may include either Ingress, Egress, or both.
Ingress
Controls incoming traffic to pods.
Egress
Controls outgoing traffic from pods.
Winter Soldier can be used to
cleans up (delete) Kubernetes resources
reduce workload pods to 0
NOTE: After deploying this we can create the Hibernator object and provide the custom configuration by which workloads going to delete, sleep and many more. for more information check the main repo
Given below is template values you can give in winter-soldier:
enabled
false,true
decide the enabling factor
apiVersion
pincher.devtron.ai/v1beta1, pincher.devtron.ai/v1alpha1
specific api version
action
sleep,delete, scale
This specify the action need to perform.
timeRangesWithZone:timeZone
eg:- "Asia/Kolkata","US/Pacific"
timeRangesWithZone:timeRanges
array of [ timeFrom, timeTo, weekdayFrom, weekdayTo]
It use to define time period/range on which the user need to perform the specified action. you can have multiple timeRanges.
These settings will take action on Sat and Sun from 00:00 to 23:59:59,
targetReplicas
[n] : n - number of replicas to scale.
These is mandatory field when the action is scale
Default value is [].
fieldSelector
- AfterTime(AddTime( ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z'), '5m'), Now())
These value will take a list of methods to select the resources on which we perform specified action .
here is an example,
Above settings will take action on Sat and Sun from 00:00 to 23:59:59, and on Mon-Fri from 00:00 to 08:00 and 20:00 to 23:59:59. If action:sleep then runs hibernate at timeFrom and unhibernate at timeTo. If action: delete then it will delete workloads at timeFrom and timeTo. Here the action:scale thus it scale the number of resource replicas to targetReplicas: [1,1,1]. Here each element of targetReplicas array is mapped with the corresponding elements of array timeRangesWithZone/timeRanges. Thus make sure the length of both array is equal, otherwise the cnages cannot be observed.
The above example will select the application objects which have been created 10 hours ago across all namespaces excluding application's namespace. Winter soldier exposes following functions to handle time, cpu and memory.
ParseTime - This function can be used to parse time. For eg to parse creationTimestamp use ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z')
AddTime - This can be used to add time. For eg AddTime(ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z'), '-10h') ll add 10h to the time. Use d for day, h for hour, m for minutes and s for seconds. Use negative number to get earlier time.
Now - This can be used to get current time.
CpuToNumber - This can be used to compare CPU. For eg any({{spec.containers.#.resources.requests}}, { MemoryToNumber(.memory) < MemoryToNumber('60Mi')}) will check if any resource.requests is less than 60Mi.
A security context defines privilege and access control settings for a Pod or Container.
To add a security context for main container:
To add a security context on pod level:
You can use topology spread constraints to control how Pods are spread across your cluster among failure-domains such as regions, zones, nodes, and other user-defined topology domains. This can help to achieve high availability as well as efficient resource utilization.
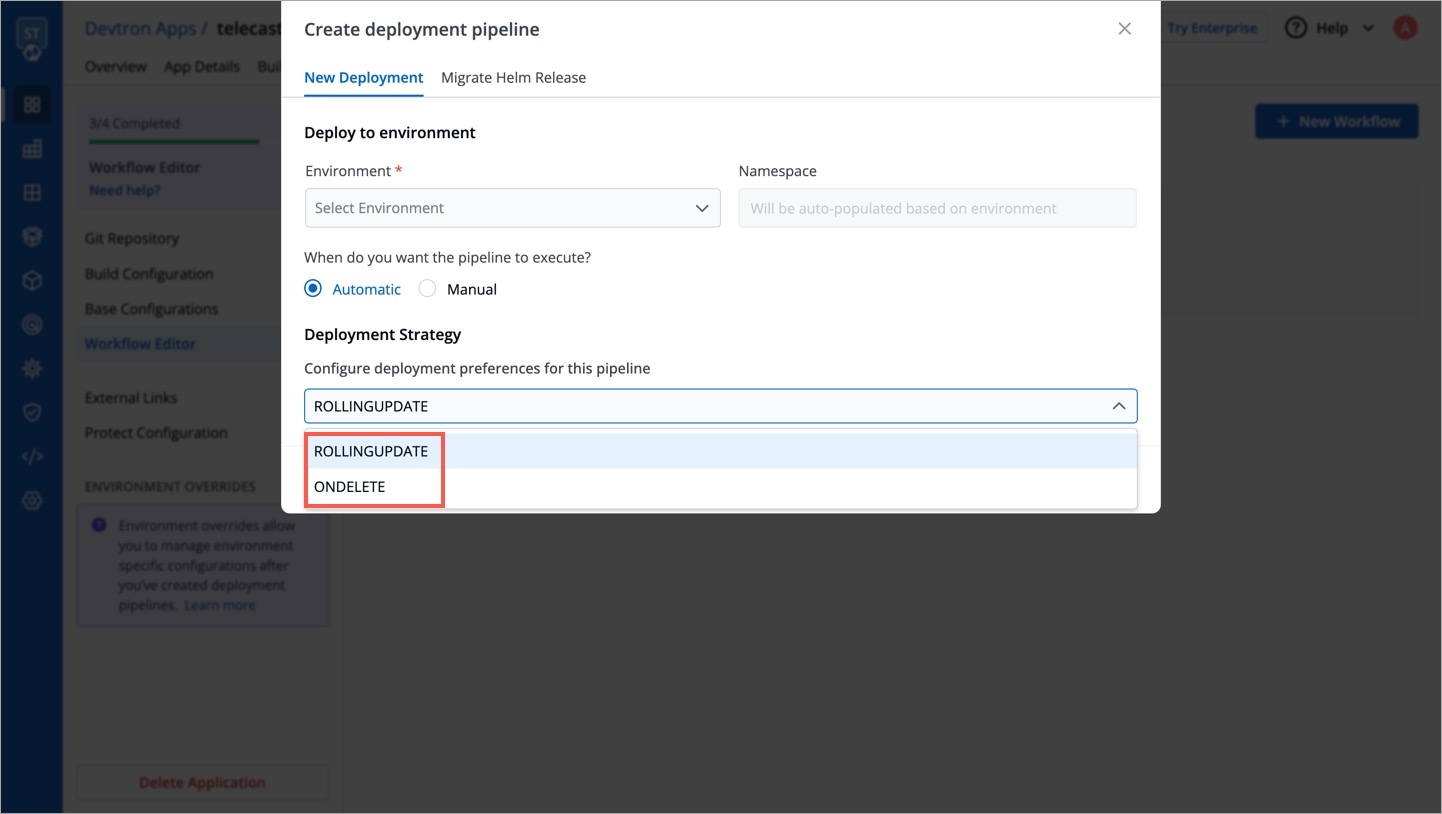
The StatefulSet chart in Devtron allows you to deploy and manage stateful applications. StatefulSet is a Kubernetes resource that provides guarantees about the ordering and uniqueness of Pods during deployment and scaling.
It supports only ONDELETE and ROLLINGUPDATE deployment strategy.
You can select StatefulSet chart when you want to use only basic use cases which contain the following:
Managing Stateful Applications: StatefulSets are ideal for managing stateful applications, such as databases or distributed systems, that require stable network identities and persistent storage for each Pod.
Ordered Pod Management: StatefulSets ensure ordered and predictable management of Pods by providing each Pod with a unique and stable hostname based on a defined naming convention and ordinal index.
Updating and Scaling Stateful Applications: StatefulSets support updating and scaling stateful applications by creating new versions of the StatefulSet and performing rolling updates or scaling operations in a controlled manner, ensuring minimal disruption to the application.
Persistent Storage: StatefulSets have built-in mechanisms for handling persistent volumes, allowing each Pod to have its own unique volume claim and storage. This ensures data persistence even when Pods are rescheduled or restarted.
Maintaining Pod Identity: StatefulSets guarantee consistent identity for each Pod throughout its lifecycle. This stability is maintained even if the Pods are rescheduled, allowing applications to rely on stable network identities.
Rollback Capability: StatefulSets provide the ability to rollback to a previous version in case the current state of the application is unstable or encounters issues, ensuring a known working state for the application.
Status Monitoring: StatefulSets offer status information that can be used to monitor the deployment, including the current version, number of replicas, and the readiness of each Pod. This helps in tracking the health and progress of the StatefulSet deployment.
Resource Cleanup: StatefulSets allow for easy cleanup of older versions by deleting StatefulSets and their associated Pods and persistent volumes that are no longer needed, ensuring efficient resource utilization.
Super-admins can lock keys in StatefulSet deployment template to prevent non-super-admins from modifying those locked keys. Refer Lock Deployment Configuration to know more.
This defines ports on which application services will be exposed to other services
envoyPort
envoy port for the container.
idleTimeout
the duration of time that a connection is idle before the connection is terminated.
name
name of the port.
port
port for the container.
servicePort
port of the corresponding kubernetes service.
nodePort
nodeport of the corresponding kubernetes service.
supportStreaming
Used for high performance protocols like grpc where timeout needs to be disabled.
useHTTP2
Envoy container can accept HTTP2 requests.
It is used to get the name of Environment Variable name, Secret name and the Key name from which we are using the value in that corresponding Environment Variable.
It is used to get the name of Environment Variable name, Config Map name and the Key name from which we are using the value in that corresponding Environment Variable.
To set environment variables for the containers that run in the Pod.
These are all the configuration settings for the StatefulSet.
Mandatoryfields in statefulSetConfig is
Here is an explanation of each field in the statefulSetConfig :
labels
set of key-value pairs used to identify the StatefulSet .
annotations
A map of key-value pairs that are attached to the stateful set as metadata.
serviceName
The name of the Kubernetes Service that the StatefulSet should create.
podManagementPolicy
A policy that determines how Pods are created and deleted by the StatefulSet. In this case, the policy is set to "Parallel", which means that all Pods are created at once.
revisionHistoryLimit
The number of revisions that should be stored for each replica of the StatefulSet.
updateStrategy
The update strategy used by the StatefulSet when rolling out changes.
mountPath
The path where the volume should be mounted in the container.
volumeClaimTemplates: An array of volume claim templates that are used to create persistent volumes for the StatefulSet. Each volume claim template specifies the storage class, access mode, storage size, and other details of the persistent volume.
apiVersion
The API version of the PVC .
kind
The type of object that the PVC is.
metadata
Metadata that is attached to the resource being created.
labels
A set of key-value pairs used to label the object for identification and selection.
spec
The specification of the object, which defines its desired state and behavior.
accessModes
A list of access modes for the PersistentVolumeClaim, such as "ReadWriteOnce" or "ReadWriteMany".
dataSource
A data source used to populate the PersistentVolumeClaim, such as a Snapshot or a StorageClass.
kind
specifies the kind of the snapshot, in this case Snapshot.
apiGroup
specifies the API group of the snapshot API, in this case snapshot.storage.k8s.io.
name
specifies the name of the snapshot, in this case my-snapshot.
dataSourceRef
A reference to a data source used to create the persistent volume. In this case, it's a secret.
updateStrategy
The update strategy used by the StatefulSet when rolling out changes.
resources
The resource requests and limits for the PersistentVolumeClaim, which define the minimum and maximum amount of storage it can use.
requests
The amount of storage requested by the PersistentVolumeClaim.
limits
The maximum amount of storage that the PersistentVolumeClaim can use.
storageClassName
The name of the storage class to use for the persistent volume.
selector
The selector used to match a persistent volume to a persistent volume claim.
matchLabels
a map of key-value pairs to match the labels of the corresponding PersistentVolume.
matchExpressions
A set of requirements that the selected object must meet to be considered a match.
key
The key of the label or annotation to match.
operator
The operator used to compare the key-value pairs (in this case, "In" specifies a set membership test).
values
A list of values that the selected object's label or annotation must match.
volumeMode
The mode of the volume, either "Filesystem" or "Block".
volumeName
The name of the PersistentVolume that is created for the PersistentVolumeClaim.
If this check fails, kubernetes restarts the pod. This should return error code in case of non-recoverable error.
Path
It define the path where the liveness needs to be checked.
initialDelaySeconds
It defines the time to wait before a given container is checked for liveliness.
periodSeconds
It defines the time to check a given container for liveness.
successThreshold
It defines the number of successes required before a given container is said to fulfil the liveness probe.
timeoutSeconds
It defines the time for checking timeout.
failureThreshold
It defines the maximum number of failures that are acceptable before a given container is not considered as live.
httpHeaders
Custom headers to set in the request. HTTP allows repeated headers,You can override the default headers by defining .httpHeaders for the probe.
scheme
Scheme to use for connecting to the host (HTTP or HTTPS). Defaults to HTTP.
tcp
The kubelet will attempt to open a socket to your container on the specified port. If it can establish a connection, the container is considered healthy.
The maximum number of pods that can be unavailable during the update process. The value of "MaxUnavailable: " can be an absolute number or percentage of the replicas count. The default value of "MaxUnavailable: " is 25%.
The maximum number of pods that can be created over the desired number of pods. For "MaxSurge: " also, the value can be an absolute number or percentage of the replicas count. The default value of "MaxSurge: " is 25%.
This specifies the minimum number of seconds for which a newly created Pod should be ready without any of its containers crashing, for it to be considered available. This defaults to 0 (the Pod will be considered available as soon as it is ready).
If this check fails, kubernetes stops sending traffic to the application. This should return error code in case of errors which can be recovered from if traffic is stopped.
Path
It define the path where the readiness needs to be checked.
initialDelaySeconds
It defines the time to wait before a given container is checked for readiness.
periodSeconds
It defines the time to check a given container for readiness.
successThreshold
It defines the number of successes required before a given container is said to fulfill the readiness probe.
timeoutSeconds
It defines the time for checking timeout.
failureThreshold
It defines the maximum number of failures that are acceptable before a given container is not considered as ready.
httpHeaders
Custom headers to set in the request. HTTP allows repeated headers,You can override the default headers by defining .httpHeaders for the probe.
scheme
Scheme to use for connecting to the host (HTTP or HTTPS). Defaults to HTTP.
tcp
The kubelet will attempt to open a socket to your container on the specified port. If it can establish a connection, the container is considered healthy.
You can create ambassador mappings to access your applications from outside the cluster. At its core a Mapping resource maps a resource to a service.
enabled
Set true to enable ambassador mapping else set false.
ambassadorId
used to specify id for specific ambassador mappings controller.
cors
used to specify cors policy to access host for this mapping.
weight
used to specify weight for canary ambassador mappings.
hostname
used to specify hostname for ambassador mapping.
prefix
used to specify path for ambassador mapping.
labels
used to provide custom labels for ambassador mapping.
retryPolicy
used to specify retry policy for ambassador mapping.
corsPolicy
Provide cors headers on flagger resource.
rewrite
used to specify whether to redirect the path of this mapping and where.
tls
used to create or define ambassador TLSContext resource.
extraSpec
used to provide extra spec values which not present in deployment template for ambassador resource.
This is connected to HPA and controls scaling up and down in response to request load.
enabled
Set true to enable autoscaling else set false.
MinReplicas
Minimum number of replicas allowed for scaling.
MaxReplicas
Maximum number of replicas allowed for scaling.
TargetCPUUtilizationPercentage
The target CPU utilization that is expected for a container.
TargetMemoryUtilizationPercentage
The target memory utilization that is expected for a container.
extraMetrics
Used to give external metrics for autoscaling.
fullnameOverride replaces the release fullname created by default by devtron, which is used to construct Kubernetes object names. By default, devtron uses {app-name}-{environment-name} as release fullname.
Image is used to access images in kubernetes, pullpolicy is used to define the instances calling the image, here the image is pulled when the image is not present,it can also be set as "Always".
imagePullSecrets contains the docker credentials that are used for accessing a registry.
regcred is the secret that contains the docker credentials that are used for accessing a registry. Devtron will not create this secret automatically, you'll have to create this secret using dt-secrets helm chart in the App store or create one using kubectl. You can follow this documentation Pull an Image from a Private Registry https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/ .
This allows public access to the url, please ensure you are using right nginx annotation for nginx class, its default value is nginx
Legacy deployment-template ingress format
enabled
Enable or disable ingress
annotations
To configure some options depending on the Ingress controller
path
Path name
host
Host name
tls
It contains security details
This allows private access to the url, please ensure you are using right nginx annotation for nginx class, its default value is nginx
enabled
Enable or disable ingress
annotations
To configure some options depending on the Ingress controller
path
Path name
host
Host name
tls
It contains security details
Specialized containers that run before app containers in a Pod. Init containers can contain utilities or setup scripts not present in an app image. One can use base image inside initContainer by setting the reuseContainerImage flag to true.
Istio is a service mesh which simplifies observability, traffic management, security and much more with it's virtual services and gateways.
istio
Istio enablement. When istio.enable set to true, Istio would be enabled for the specified configurations
gateway
Allowing external traffic to enter the service mesh through the specified configurations.
host
The external domain through which traffic will be routed into the service mesh.
tls
Traffic to and from the gateway should be encrypted using TLS.
secretName
Specifies the name of the Kubernetes secret that contains the TLS certificate and private key. The TLS certificate is used for securing the communication between clients and the Istio gateway.
virtualService
Enables the definition of rules for how traffic should be routed to different services within the service mesh.
gateways
Specifies the gateways to which the rules defined in the VirtualService apply.
hosts
List of hosts (domains) to which this VirtualService is applied.
http
Configuration for HTTP routes within the VirtualService. It define routing rules based on HTTP attributes such as URI prefixes, headers, timeouts, and retry policies.
corsPolicy
Cross-Origin Resource Sharing (CORS) policy configuration.
headers
Additional headers to be added to the HTTP request.
match
Conditions that need to be satisfied for this route to be used.
uri
This specifies a match condition based on the URI of the incoming request.
prefix
It specifies that the URI should have the specified prefix.
retries
Retry configuration for failed requests.
attempts
It specifies the number of retry attempts for failed requests.
perTryTimeout
sets the timeout for each individual retry attempt.
rewriteUri
Rewrites the URI of the incoming request.
route
List of destination rules for routing traffic.
To wait for given period of time before switch active the container.
These define minimum and maximum RAM and CPU available to the application.
Resources are required to set CPU and memory usage.
Limits make sure a container never goes above a certain value. The container is only allowed to go up to the limit, and then it is restricted.
Requests are what the container is guaranteed to get.
This defines annotations and the type of service, optionally can define name also.
It is required when some values need to be read from or written to an external disk.
It is used to provide mounts to the volume.
Spec is used to define the desire state of the given container.
Node Affinity allows you to constrain which nodes your pod is eligible to schedule on, based on labels of the node.
Inter-pod affinity allow you to constrain which nodes your pod is eligible to be scheduled based on labels on pods.
Key part of the label for node selection, this should be same as that on node. Please confirm with devops team.
Value part of the label for node selection, this should be same as that on node. Please confirm with devops team.
Taints are the opposite, they allow a node to repel a set of pods.
A given pod can access the given node and avoid the given taint only if the given pod satisfies a given taint.
Taints and tolerations are a mechanism which work together that allows you to ensure that pods are not placed on inappropriate nodes. Taints are added to nodes, while tolerations are defined in the pod specification. When you taint a node, it will repel all the pods except those that have a toleration for that taint. A node can have one or many taints associated with it.
This is used to give arguments to command.
It contains the commands for the server.
enabled
To enable or disable the command.
value
It contains the commands.
Containers section can be used to run side-car containers along with your main container within same pod. Containers running within same pod can share volumes and IP Address and can address each other @localhost. We can use base image inside container by setting the reuseContainerImage flag to true.
It is a kubernetes monitoring tool and the name of the file to be monitored as monitoring in the given case.It describes the state of the prometheus.
Accepts an array of Kubernetes objects. You can specify any kubernetes yaml here and it will be applied when your app gets deployed.
Kubernetes waits for the specified time called the termination grace period before terminating the pods. By default, this is 30 seconds. If your pod usually takes longer than 30 seconds to shut down gracefully, make sure you increase the GracePeriod.
A Graceful termination in practice means that your application needs to handle the SIGTERM message and begin shutting down when it receives it. This means saving all data that needs to be saved, closing down network connections, finishing any work that is left, and other similar tasks.
There are many reasons why Kubernetes might terminate a perfectly healthy container. If you update your deployment with a rolling update, Kubernetes slowly terminates old pods while spinning up new ones. If you drain a node, Kubernetes terminates all pods on that node. If a node runs out of resources, Kubernetes terminates pods to free those resources. It’s important that your application handle termination gracefully so that there is minimal impact on the end user and the time-to-recovery is as fast as possible.
It is used for providing server configurations.
It gives the details for deployment.
image_tag
It is the image tag
image
It is the URL of the image
It gives the set of targets to be monitored.
It is used to configure database migration.
KEDA is a Kubernetes-based Event Driven Autoscaler. With KEDA, you can drive the scaling of any container in Kubernetes based on the number of events needing to be processed. KEDA can be installed into any Kubernetes cluster and can work alongside standard Kubernetes components like the Horizontal Pod Autoscaler(HPA).
Example for autosccaling with KEDA using Prometheus metrics is given below:
Example for autosccaling with KEDA based on kafka is given below :
Winter Soldier can be used to
cleans up (delete) Kubernetes resources
reduce workload pods to 0
NOTE: After deploying this we can create the Hibernator object and provide the custom configuration by which workloads going to delete, sleep and many more. for more information check the main repo
Given below is template values you can give in winter-soldier:
Here,
enable
false,true
decide the enabling factor
apiVersion
pincher.devtron.ai/v1beta1, pincher.devtron.ai/v1alpha1
specific api version
action
sleep,delete, scale
This specify the action need to perform.
timeRangesWithZone:timeZone
eg:- "Asia/Kolkata","US/Pacific"
timeRangesWithZone:timeRanges
array of [ timeFrom, timeTo, weekdayFrom, weekdayTo]
It use to define time period/range on which the user need to perform the specified action. you can have multiple timeRanges.
These settings will take action on Sat and Sun from 00:00 to 23:59:59,
targetReplicas
[n] : n - number of replicas to scale.
These is mandatory field when the action is scale
Default value is [].
fieldSelector
- AfterTime(AddTime( ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z'), '5m'), Now())
These value will take a list of methods to select the resources on which we perform specified action .
here is an example,
Above settings will take action on Sat and Sun from 00:00 to 23:59:59, and on Mon-Fri from 00:00 to 08:00 and 20:00 to 23:59:59. If action:sleep then runs hibernate at timeFrom and unhibernate at timeTo. If action: delete then it will delete workloads at timeFrom and timeTo. Here the action:scale thus it scale the number of resource replicas to targetReplicas: [1,1,1]. Here each element of targetReplicas array is mapped with the corresponding elements of array timeRangesWithZone/timeRanges. Thus make sure the length of both array is equal, otherwise the cnages cannot be observed.
The above example will select the application objects which have been created 10 hours ago across all namespaces excluding application's namespace. Winter soldier exposes following functions to handle time, cpu and memory.
ParseTime - This function can be used to parse time. For eg to parse creationTimestamp use ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z')
AddTime - This can be used to add time. For eg AddTime(ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z'), '-10h') ll add 10h to the time. Use d for day, h for hour, m for minutes and s for seconds. Use negative number to get earlier time.
Now - This can be used to get current time.
CpuToNumber - This can be used to compare CPU. For eg any({{spec.containers.#.resources.requests}}, { MemoryToNumber(.memory) < MemoryToNumber('60Mi')}) will check if any resource.requests is less than 60Mi.
A security context defines privilege and access control settings for a Pod or Container.
To add a security context for main container:
To add a security context on pod level:
You can use topology spread constraints to control how Pods are spread across your cluster among failure-domains such as regions, zones, nodes, and other user-defined topology domains. This can help to achieve high availability as well as efficient resource utilization.
It gives the realtime metrics of the deployed applications
Deployment Frequency
It shows how often this app is deployed to production
Change Failure Rate
It shows how often the respective pipeline fails.
Mean Lead Time
It shows the average time taken to deliver a change to production.
Mean Time to Recovery
It shows the average time taken to fix a failed pipeline.
If you want to see application metrics like different HTTP status codes metrics, application throughput, latency, response time. Enable the Application metrics from below the deployment template Save button. After enabling it, you should be able to see all metrics on App detail page. By default it remains disabled.
Once all the Deployment template configurations are done, click on Save to save your deployment configuration. Now you are ready to create Workflow to do CI/CD.
Helm Chart json schema is used to validate the deployment template values.
The values of CPU and Memory in limits must be greater than or equal to in requests respectively. Similarly, In case of envoyproxy, the values of limits are greater than or equal to requests as mentioned below.
It use to specify the timeZone used. (It uses standard format. please refer )
It use to specify the timeZone used. (It uses standard format. please refer )