Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Devtron is a tool integration platform for Kubernetes.
Devtron deeply integrates with products across the lifecycle of microservices i.e., CI/CD, security, cost, debugging, and observability via an intuitive web interface. Devtron helps you to deploy, observe, manage & debug the existing Helm apps in all your clusters.
Workflow which understands the domain of Kubernetes, testing, CD, SecOps so that you don't have to write scripts
Reusable and composable components so that workflows are easy to construct and reason through
Deploy to multiple Kubernetes clusters on multiple cloud/on-prem from one Devtron setup
Works for all cloud providers and on-premise Kubernetes clusters
Multi-level security policy at global, cluster, environment, and application-level for efficient hierarchical policy management
Behavior-driven security policy
Define policies and exceptions for Kubernetes resources
Define policies for events for faster resolution
One place for all historical Kubernetes events
Access all manifests securely, such as secret obfuscation
Application metrics for CPU, RAM, HTTP status code, and latency with a comparison between new and old
Advanced logging with grep and JSON search
Intelligent correlation between events, logs for faster triangulation of issue
Auto issue identification
Fine-grained access control; control who can edit the configuration and who can deploy.
Audit log to know who did what and when
History of all CI and CD events
Kubernetes events impacting application
Relevant cloud events and their impact on applications
Advanced workflow policies like blackout window, branch environment relationship to secure build and deployment pipelines
GitOps exposed through API and UI so that you don't have to interact with git CLI
GitOps backed by Postgres for easy analysis
Enforce finer access control than Git
Deployment metrics to measure the success of the agile process. It captures MTTR, change failure rate, deployment frequency, and deployment size out of the box.
Audit log to understand the failure causes
Monitor changes across deployments and reverts easily
Devtron uses a modified version of Argo Rollout.
Application metrics only work for K8s version 1.16+
Check out our contributing guidelines. Directions for opening issues, coding standards, and notes on our development processes are all included.
Get updates on Devtron's development and chat with the project maintainers, contributors, and community members.
Join the Discord Community
Follow @DevtronL on Twitter
Raise feature requests, suggest enhancements, report bugs at GitHub issues
Read the Devtron blog
We, at Devtron, take security and our users' trust very seriously. If you believe you have found a security issue in Devtron, please responsibly disclose it by contacting us at [email protected].
To uninstall Devtron, run the following command:
This command will remove all the namespaces related to Devtron (devtroncd, devtron-cd, devtron-ci etc.).
helm uninstall devtron --namespace devtroncd
kubectl delete -n devtroncd -f https://raw.githubusercontent.com/devtron-labs/charts/main/charts/devtron/crds/crd-devtron.yaml
kubectl delete -n argo -f https://raw.githubusercontent.com/devtron-labs/devtron/main/manifests/yamls/workflow.yaml
kubectl delete ns devtroncd devtron-cd devtron-ci devtron-demo argo
Note: If you have questions, please let us know on our discord channel.
Here we have demonstrated the installation of Devtron on popular cloud providers. The videos are easy to follow and provide step-by-step instructions.
Cloud Provider: Amazon Web Services (AWS)
Cloud Provider: Microsoft Azure
Cloud Provider: Google Cloud Platform (GCP)
Devtron is installed over a Kubernetes cluster. Once you create a Kubernetes cluster, Devtron can be installed standalone or along with CI/CD integration.
Choose one of the options as per your requirements:
Devtron installation with the CI/CD integration is used to perform CI/CD, security scanning, GitOps, debugging, and observability.
Use this option to install Devtron with Build and Deploy CI/CD integration.
The Helm Dashboard by Devtron which is a standalone installation includes functionalities to deploy, observe, manage, and debug existing Helm applications in multiple clusters. You can also install integrations from .
Use this option if you are managing the applications via Helm and you want to use Devtron to deploy, observe, manage, and debug the Helm applications.
With this option, you can install Devtron with CI/CD by enabling GitOps during the installation. You can also install other integrations from .
Use this option to install Devtron with CI/CD by enabling GitOps, which is the most scalable method in terms of version control, collaboration, compliance and infrastructure automation.
Note: If you have questions, please let us know on our discord channel.
Regular backups for Devtron PostgreSQL and ArgoCD are crucial components of a disaster recovery plan, as they protect against potential data loss due to unforeseen circumstances. This documentation provides instructions on how to take backups of Devtron and store them either on AWS S3 or Azure containers.
Go to the devtron chart store and search for devtron-backups chart.
Select the devtron-backups and click Configure & Deploy.
Now follow either of the options described below according to your Cloud provider.
To store Devtron backups on AWS S3, please follow these steps:
Create an S3 bucket to store the Devtron backup, you can configure the bucket to delete all the objects older than 15/30 days.
Create a user with sufficient permissions to push to the S3 bucket created in step 1.
Obtain the access key and secret access key for the created user.
Configure the devtron-backups chart for AWS S3 by selecting the appropriate options:
Deploy the chart, and the Devtron backup will be automatically uploaded to the AWS S3 bucket at the scheduled intervals.
To store Devtron backups on Azure Containers, please follow these steps:
Create a storage account in Azure.
Within the storage account, create two containers for the Devtron backup.
Navigate to Security + Networking > Access Key section in Azure and copy the Access Key:
Configure the devtron-backups chart for Azure Containers by providing the Access Key:
Before deploying the backup chart, ensure that AWS.enabled is set to false. This will ensure that Devtron backup will be automatically uploaded to the configured Azure containers on the scheduled intervals.
By following these steps, you can ensure that your Devtron data is securely backed up and protected against any potential data loss, enabling you to recover quickly in case of emergencies.
You can configure Devtron by using configuration files. Configuration files are YAML files which are user-friendly. The configuration allows you to quickly roll back a configuration change if necessary. It also aids cluster re-creation and restoration.
There are two ways you can perform configurations while setting up Devtron dashboard:
You can also setup ingress while setting up Devtron dashboard. Refer here for ingress setup.
Please configure Global Configurations before creating an application or cloning an existing application.
This section includes information about the minimum requirements you need to install and use Devtron.
Devtron is installed over a Kubernetes cluster. Once you create a Kubernetes cluster, Devtron can be installed standalone or along with CI/CD integration:
Devtron with CI/CD: Devtron installation with the CI/CD integration is used to perform CI/CD, security scanning, GitOps, debugging, and observability.
Helm Dashboard by Devtron: The Helm Dashboard by Devtron, which is a standalone installation, includes functionalities to deploy, observe, manage, and debug existing Helm applications in multiple clusters. You can also install integrations from Devtron Stack Manager.
In this section, we will cover the basic details on how you can quickly get started with Devtron. First, lets see what are the prerequisite requirements before you install Devtron.
You can create any Kubernetes cluster (preferably K8s version 1.16 or higher) for installing Devtron.
You can create a cluster using one of the following cloud providers as per your requirements:
AWS EKS
Create a cluster using .
Note: You can also refer our customized documentation for installing Devtron with CI/CD on AWS EKS .
Google Kubernetes Engine (GKE)
Create a cluster using .
Azure Kubernetes Service (AKS)
Create a cluster using .
k3s - Lightweight Kubernetes
Create a cluster using .
Note: You can also refer our customized documentation for installing Helm Dashboard by Devtron on Minikube, Microk8s, K3s, Kind .
Make sure to install helm.
The minimum requirements for installing Helm Dashboard by Devtron and Devtron with CI/CD as per the number of applications you want to manage on Devtron are provided below:
For configuring small resources (to manage not more than 5 apps on Devtron):
Devtron with CI/CD
2
6 GB
Helm Dashboard by Devtron
1
1 GB
For configuring medium/larger resources (to manage more than 5 apps on Devtron):
Devtron with CI/CD
6
13 GB
Helm Dashboard by Devtron
2
3 GB
Refer to the Override Configurations section for more information.
Note:
Please make sure that the recommended resources are available on your Kubernetes cluster before you proceed with Devtron installation.
It is NOT recommended to use brustable CPU VMs (T series in AWS, B Series in Azure and E2/N1 in GCP) for Devtron installation to experience consistency in performance.
You can install Devtron standalone (Helm Dashboard by Devtron) or along with CI/CD integration. Or, you can upgrade Devtron to the latest version.
Choose one of the options as per your requirements:
Devtron installation with the CI/CD integration is used to perform CI/CD, security scanning, GitOps, debugging, and observability.
The Helm Dashboard by Devtron which is a standalone installation includes functionalities to deploy, observe, manage, and debug existing Helm applications in multiple clusters. You can also install integrations from .
With this option, you can install Devtron with CI/CD by enabling GitOps during the installation. You can also install other integrations from .
Upgrade Devtron to latest version
You can upgrade Devtron in one of the following ways:
Note: If you have questions, please let us know on our discord channel.
In this section, we describe on how you can install Helm Dashboard by Devtron without any integrations. Integrations can be added later using .
If you want to install Devtron on Minikube, Microk8s, K3s, Kind, refer this .
Install if you have not installed it.
Note: This installation command will not install CI/CD integration. For CI/CD, refer section.
Run the following command to install Helm Dashboard by Devtron:
To install Devtron on clusters with the multi-architecture nodes (ARM and AMD), append the Devtron installation command with --set installer.arch=multi-arch.
Run the following command to get the dashboard URL:
You will get the result something as shown below:
The hostname aaff16e9760594a92afa0140dbfd99f7-305259315.us-east-1.elb.amazonaws.com as mentioned above is the Loadbalancer URL where you can access the Devtron dashboard.
You can also do a CNAME entry corresponding to your domain/subdomain to point to this Loadbalancer URL to access it at a custom domain.
When you install Devtron for the first time, it creates a default admin user and password (with unrestricted access to Devtron). You can use that credentials to log in as an administrator.
After the initial login, we recommend you set up any SSO service like Google, GitHub, etc., and then add other users (including yourself). Subsequently, all the users can use the same SSO (let's say, GitHub) to log in to Devtron's dashboard.
The section below will help you understand the process of getting the administrator credentials.
Username: admin
Password: Run the following command to get the admin password:
Note: If you want to uninstall Devtron or clean Devtron helm installer, refer our .
To use the CI/CD capabilities with Devtron, you can Install the or .
Still facing issues, please reach out to us on .
Devtron provides a sample configuration out of the box. There are some values that you need to either get from your SSO provider or give to your SSO provider.
clientID
clientSecret
redirectURI (provided in SSO Login Services by Devtron)
Devtron provides a sample configuration out of the box. Here are some values you need to fetch from your LDAP.
bindDN
bindPW
baseDN
Since LDAP supports creation of User Groups, this feature simplifies the onboarding process of organizations having a large headcount of users. It also eliminates repetitive permission assignment by automatically mapping your LDAP User groups to Devtron's during single sign-on (SSO) login.
If you've created user groups in LDAP, you can create corresponding permission groups in Devtron with the same names. When members of those user groups first log in to Devtron, they'll automatically inherit the permissions from their Devtron permission group. This means you can't manually adjust or add mapped to a permission group.
SSO login requires exact matching between Devtron permission group names and LDAP user groups. Any discrepancies or missing groups will prevent successful login.
Once you save the configuration with this auto-assign feature enabled, existing user permissions will be cleared and the future permissions will be managed through linked to LDAP user groups.
Devtron provides a sample configuration out of the box. There are some values that you need to either get from your SSO provider or give to your SSO provider.
clientID
clientSecret
redirectURI (provided in SSO Login Services by Devtron)
If you want to check the current version of Devtron you are using, please use the following command.
Please ignore any errors you encounter while running the upgrade script
kubectl -n devtroncd get installers installer-devtron -o jsonpath='{.status.sync.data}' | grep "^LTAG=" | cut -d"=" -f2-helm list --namespace devtroncdexport RELEASE_NAME=devtronwget https://raw.githubusercontent.com/devtron-labs/utilities/main/scripts/shell/upgrade-devtron-v6.shsh upgrade-devtron-v6.shhelm repo add devtron https://helm.devtron.aihelm repo update devtronhelm install devtron devtron/devtron-operator \
--create-namespace --namespace devtroncdkubectl get svc -n devtroncd devtron-service -o jsonpath='{.status.loadBalancer.ingress}'[test2@server ~]$ kubectl get svc -n devtroncd devtron-service -o jsonpath='{.status.loadBalancer.ingress}'
[map[hostname:aaff16e9760594a92afa0140dbfd99f7-305259315.us-east-1.elb.amazonaws.com]]devtron.yourdomain.com
CNAME
aaff16e9760594a92afa0140dbfd99f7-305259315.us-east-1.elb.amazonaws.com
kubectl -n devtroncd get secret devtron-secret \
-o jsonpath='{.data.ADMIN_PASSWORD}' | base64 -dkubectl -n devtroncd get secret devtron-secret \
-o jsonpath='{.data.ACD_PASSWORD}' | base64 -dkubectl -n devtroncd get installers installer-devtron -o jsonpath='{.status.sync.status}'pod=$(kubectl -n devtroncd get po -l app=inception -o jsonpath='{.items[0].metadata.name}')&& kubectl -n devtroncd logs -f $podcd devtron-installation-script/
kubectl delete -n devtroncd -f yamls/
kubectl -n devtroncd patch installer installer-devtron --type json -p '[{"op": "remove", "path": "/status"}]'If you want to check the current version of Devtron you are using, please use the following command.
kubectl -n devtroncd get installers installer-devtron -o jsonpath='{.status.sync.data}' | grep "^LTAG=" | cut -d"=" -f2-If you are using rawYaml in deployment template, this update can introduce breaking changes. We recommend you to update the Chart Version of your app to v4.13.0 to make rawYaml section compatible to new argocd version v2.4.0.
Or
We have released a argocd-v2.4.0 patch job to fix the compatibilities issues. Please apply this job in your cluster and wait for completion and then only upgrade to Devtron v0.5.x.
kubectl apply -f https://raw.githubusercontent.com/devtron-labs/utilities/main/scripts/jobs/argocd-2.4.0-prerequisites-patch-job.yamlhelm list --namespace devtroncdRELEASE_NAME=devtronhelm repo update5.1 Upgrade Devtron to latest version
helm upgrade devtron devtron/devtron-operator --namespace devtroncd \
-f https://raw.githubusercontent.com/devtron-labs/devtron/main/charts/devtron/devtron-bom.yaml \
--set installer.modules={cicd} --reuse-valuesOR
5.2 Upgrade Devtron to a custom version
You can find the latest releases from Devtron on Github https://github.com/devtron-labs/devtron/releases
DEVTRON_TARGET_VERSION=v0.5.x
helm upgrade devtron devtron/devtron-operator --namespace devtroncd \
-f https://raw.githubusercontent.com/devtron-labs/devtron/$DEVTRON_TARGET_VERSION/charts/devtron/devtron-bom.yaml \
--set installer.modules={cicd} --reuse-valuesIf you want to check the current version of Devtron you are using, please use the following command.
kubectl -n devtroncd get installers installer-devtron -o jsonpath='{.status.sync.data}' | grep "^LTAG=" | cut -d"=" -f2-Fetch the latest Devtron helm chart
helm repo updateInput the target Devtron version that you want to upgrade to. You can find the latest releases from Devtron on Github https://github.com/devtron-labs/devtron/releases
DEVTRON_TARGET_VERSION=v0.3.xUpgrade Devtron
helm upgrade devtron devtron/devtron-operator --namespace devtroncd --set installer.release=$DEVTRON_TARGET_VERSIONInput the target Devtron version that you want to upgrade to. You can find the latest releases from Devtron on Github https://github.com/devtron-labs/devtron/releases
DEVTRON_TARGET_VERSION=v0.3.xPatch Devtron Installer
kubectl patch -n devtroncd installer installer-devtron --type='json' -p='[{"op": "add", "path": "/spec/reSync", "value": true },{"op": "replace", "path": "/spec/url", "value": "https://raw.githubusercontent.com/devtron-labs/devtron/'$DEVTRON_TARGET_VERSION'/manifests/installation-script"}]'Authorization section describes how to authenticate and authorize access to resources, also managing role-based access levels in Devtron.
Access can be granted to a user via:
Delete the respective resources i.e, nats-operator , nats-streaming and nats-server using the following commands.
kubectl delete -f https://raw.githubusercontent.com/devtron-labs/devtron/v0.2.37/manifests/yamls/nats-operator.yaml
kubectl -n devtroncd delete -f https://raw.githubusercontent.com/devtron-labs/devtron/v0.2.37/manifests/yamls/nats-streaming.yaml
kubectl -n devtroncd delete -f https://raw.githubusercontent.com/devtron-labs/devtron/v0.2.37/manifests/yamls/nats-server.yamlVerify the deletion of resources using the following commands.
kubectl -n devtroncd get pods
kubectl -n devtroncd get serviceaccount
kubectl -n devtroncd get clusterroleSet reSync: true in the installer object, this will initiate upgrade of the entire Devtron stack, you can use the following command to do this.
kubectl patch -n devtroncd installer installer-devtron --type='json' -p='[{"op": "add", "path": "/spec/reSync", "value": true }]'Devtron can be upgraded in one of the following ways:
Versions Upgrade
For the Jobs, you must configure the following sections before you run and trigger the job:
A global configuration allows you to easily share common configuration between multiple repositories without copy/pasting it to these repositories.
Before you start creating an application, we recommend to provide basic information in different sections of Global Configurations available in Devtron.
You can also refer our YouTube video provided here.
You can add more chart repositories to Devtron. Once added, they will be available in the All Charts section of the Chart Store.
Note: After the successful installation of Devtron, click Refetch Charts to sync and download all the default charts listed on the dashboard.
To add chart repository, go to the Chart Repositories section of Global Configurations. Click Add repository.
Note: Only public chart repositories can be connected as of now via Devtron.
Provide below information in the following fields:
Name
Provide a Name of your chart repository. This name is added as prefix to the name of the chart in the listing on the helm chart section of application.
URL
This is the URL of your chart repository. E.g. https://charts.bitnami.com/bitnami
You can also update your saved chart repository settings.
Click the chart repository which you want to update.
Modify the required changes and click Update to save you changes.
Note:
You can perform a dry run to validate the below chart repo configurations by clicking Validate.
You can enable or disable your chart repository. If you enable it, then you will be able to see the enabled chart in All Charts section of the Chart Store.
Devtron provides a sample configuration out of the box. There are some values that you need to either get from your SSO provider or give to your SSO provider.
clientID
clientSecret
redirectURI (provided in SSO Login Services by Devtron)
Devtron offers the option to pull container images using digest. Refer CD Pipeline - Image Digest to know the purpose it serves.
Though it can be enabled by an application-admin for a given CD Pipeline, Devtron also allows super-admins to enable pull image digest at environment level.
This helps in better governance and less repetitiveness if you wish to manage pull image digest for multiple applications across environments.
Users need to have super-admin permission to enable pull image digest at environment level.
From the left sidebar, go to Global Configurations → Pull Image Digest.
As a super-admin, you can decide whether you wish to enable pull image digest for all environments or for specific environments.
This is for enabling pull image digest for deployment to all environments.
Enable the toggle button next to Pull image digest for all existing & future environments.
Click Save Changes.
This is for enabling pull image digest for specific environments. Therefore, only those applications deploying to selected environment(s) will have pull image digest enabled in its CD pipeline.
Use the checkbox to choose one or more environments present within the list of clusters you have on Devtron.
Click Save Changes.
Once you enable pull image digest for a given environment in Global Configurations, users won't be able to modify the image digest setting in the CD pipeline. The toggle button would appear disabled for that environment as shown below.
Devtron provides a sample configuration out of the box. There are some values that you need to either get from your SSO provider or give to your SSO provider.
clientID
clientSecret
redirectURI (already provided in SSO Login Services by Devtron)
Devtron provides a sample configuration out of the box. There are some values that you need to either get from your SSO provider or give to your SSO provider.
clientID
clientSecret
redirectURI (provided in SSO Login Services by Devtron)
On the Devtron dashboard, select Applications.
On the upper-right corner of the screen, click Create.
Select Custom app from the drop-down list.
A new application can be created from one of the following options:
Custom App
To create a new application from the custom app, select Custom app.
In the Create application window, enter an App Name and select a Project.
Select either:
Create from scratch to create an application from scratch, or
Clone existing application to clone an existing application.
If you select Create from scratch, select the project from the drop-down list.
Note: You have to add project under Global Configurations. Only then, it will appear in the drop-down list here.
If you select Clone existing application, select an app you want to clone from and the project from the drop-down list.
Note: You have to add project under Global Configurations. Only then, it will appear in the drop-down list here.
Tags are key-value pairs. You can add one or multiple tags in your application.
Propagate Tags When tags are propagated, they are considered as labels to Kubernetes resources. Kubernetes offers integrated support for using these labels to query objects and perform bulk operations e.g., consolidated billing using labels. You can use these tags to filter/identify resources via CLI or in other Kubernetes tools.
Click + Add tag to add a new tag.
Click the symbol on the left side of your tag to propagate a tag.
Note: Dark grey colour in symbol specifies that the tags are propagated.
To remove the tags from propagation, click the symbol again.
Click Save.
Within the same application, you can override a container registry, container image and target platform during the build pipeline, which means the images built for non-production environment can be included to the non-production registry and the images for production environment can be included to the production registry.
To override a container registry, container image or target platform:
Go to Applications and select your application from the Devtron Apps tabs.
On the App Configuration tab, select Workflow Editor.
Open the build pipeline of your application.
Click Allow Override to:
Select the new container registry from the drop-down list.
Or, create and build the new container image with different options.
Or, set a new target platform from the drop-down list or enter a new target platform.
Click Update Pipeline.
The overridden container registry/container image location/target platform will be reflected on the Build Configuration page. You can also see the number of build pipelines for which the container registry/container image location/target platform is overridden.
Click on Create New and the select Custom app to create a new application.
As soon you click on Custom app, you will get a popup window on screen where you have to enter app name and project for the application. there are two radio buttons present on the popup window, one is for Blank app and another one is for Clone an existing app. For cloning an existing application, select the second one. After this, one more drop-down will appear on the window from which you can select the application that you want to clone. For this, you will have to type minimum three character to see the matching results in the drop-down. After typing the matching characters, select the application that you want to clone. You also can add additional information about the application (eg. created by, Created on) using tags (only key:value allowed).
App Name
Name of the new app you want to Create
Project
Project name
Select an app to clone
Select the application that you want to clone
Tags
Additional information about the application
Now click on Clone App to clone the selected application.
New application with a duplicate template is created.
When cloning an application with GitOps configuration, the configuration itself is not copied. To set up the configuration for your new application, refer GitOps Configuration guide.
Projects are the logical grouping of your applications so that you can manage and control the access level of users.
Refer user access for more detail.
To add a project name, go to the Projects section of Global Configurations.
Click Add Project.
Provide a project name in the field and click Save.
Delete the Application, when you are sure you no longer need it.
Clicking on Delete Application will not delete your application if you have workflows in the application.
If your Application contains workflows in the Workflow Editor. So, when you click on Delete Application, you will see the following prompt.
Click on View Workflows to view and delete your workflows in the application.
To delete the workflows in your application, you must first delete all the pipelines (CD Pipeline, CI Pipeline or Linked CI Pipeline or External CI Pipeline if there are any).
After you have deleted all the pipelines in the workflow, you can delete that particular workflow.
Similarly, delete all the workflows in the application.
Now, Click on Delete Application to delete the application.
Job allows manual and automated execution of your source code. Job pipeline will not have CI/CD pipeline as the job is limited to your source code only. You can also configure preset plugins in your job pipeline.
With job, you can execute your source code quickly and easily without going through CI/CD pipelines, which also optimize time.
There are two main steps in executing Job:
In the next section, we will learn on how to create, configure, trigger a job. You can also view the details on the Overview tab and Run History.
You can install and try Devtron on a high-end machine or a Cloud VM. If you install it on a laptop/PC, it may start to respond slowly, so it is recommended to uninstall Devtron from your system before shutting it down.
2 vCPUs
4GB+ of free memory
20GB+ free disk space
Before you get started, you must set up a cluster in your server and finish the following actions:
Create a cluster using or or .
Install .
Install .
To install devtron on Minikube/kind cluster, run the following command:
To install devtron on k3s cluster, run the following command:
To access Devtron dashboard when using Minikube as cluster, run the following command:
To access Devtron dashboard when using Kind/k3s as cluster, run the following command to port forward the devtron service to port 8000:
Dashboard: .
When you install Devtron for the first time, it creates a default admin user and password (with unrestricted access to Devtron). You can use that credentials to log in as an administrator.
After the initial login, we recommend you set up any SSO service like Google, GitHub, etc., and then add other users (including yourself). Subsequently, all the users can use the same SSO (let's say, GitHub) to log in to Devtron's dashboard.
The section below will help you understand the process of getting the administrator credentials.
Username: admin
Password: Run the following command to get the admin password:
It is recommended to use Cloud VM with 2vCPU+, 4GB+ free memory, 20GB+ storage, Compute Optimized VM type & Ubuntu Flavoured OS.
Make sure that the port on which the devtron-service runs remain open in the VM's security group or network security group.
If you have questions, please let us know on our discord channel.
Please configure Global Configurations before moving ahead with App Configuration
Parts of Documentation
Devtron provides a sample configuration out of the box. There are some values that you need to either get from your SSO provider or give to your SSO provider.
clientID
tenantID (required only if you want to use Azure AD for auto-assigning permissions)
clientSecret
redirectURI (provided in SSO Login Services by Devtron)
Since Microsoft supports , this feature further simplifies the onboarding process of organizations having a large headcount of users. It also eliminates repetitive permission assignment by automatically mapping your Azure AD groups to Devtron's during single sign-on (SSO) login.
If you've defined groups in your Active Directory, you can create corresponding permission groups in Devtron with the same names. When members of those Active Directory groups first log in to Devtron, they'll automatically inherit the permissions from their Devtron permission group. This means you can't manually adjust or add mapped to a permission group.
SSO login requires exact matching between Devtron permission group names and AD groups. Any discrepancies or missing groups will prevent successful login.
Once you save the configuration with this feature enabled, existing user permissions will be cleared and the future permissions will be managed through linked to Azure Active Directory (Microsoft Entra ID) groups.
If you want to check the current version of Devtron you are using, please use the following command.
4.1 Upgrade Devtron to latest version
OR
4.2 Upgrade Devtron to a custom version. You can find the latest releases from Devtron on Github https://github.com/devtron-labs/devtron/releases
Devtron's Tags Policy feature enables you to assign tags to your applications. Devtron also offers the option to propagate the tags assigned to an application as labels within the associated Kubernetes resources.
To add tags, follow these steps:
From the left pane, navigate to the Global Configuration section.
Select Tags within the Global Configuration section.
Once you are in the Tags section, locate the Add Tag button in the upper-right corner of the screen and click it.
Within the Add Tag section, you will find two options for tags:
Suggested tags: These tags appear as suggestions when adding tags to applications.
Mandatory tags: These tags are required for applications within the selected project.
To create mandatory tags, choose the second option: Mandatory tags. This ensures that the specified tags are mandatory for the applications within the selected project.
Next, choose the project(s) for which you want to create mandatory tags. You can select multiple projects at once (if required).
After selecting the projects, proceed to add the mandatory tags for the selected projects.
By default, tags assigned to applications in Devtron are not automatically propagated to Kubernetes resources as labels. However, Devtron provides the flexibility to enable this feature if desired.
When the propagation is enabled for tags from the global configuration, the tags will be automatically propagated as labels for all applications within the projects where these tags are used. Even if tag propagation is disabled from the global configuration in Devtron, you still have the option to enable propagation at the application level.
In a project where mandatory tags are enabled, it is required to provide values for those tags when creating new applications. Without providing values for the mandatory tags, it is not possible to create a new application within that project.
When mandatory tags are enabled, Devtron enforces the requirement to specify values for these tags during the application creation process. This ensures that all applications within the project adhere to the specified tag values.
If tag propagation for a project is disabled globally, you can still enable it for individual applications. During the application creation process, you have the option to enable tag propagation specifically for that application. By doing so, the tags assigned to that application will be propagated as labels to the associated Kubernetes resources.
Git Accounts allow you to connect your code source with Devtron. You will be able to use these git accounts to build the code using the CI pipeline.
To add git account, go to the Git accounts section of Global Configurations. Click Add git account.
Provide the information in the following fields to add your git account:
To update the git account:
Click the git account which you want to update.
Update the required changes.
Click Update to save the changes.
Updates can only be made within one Authentication type or one protocol type, i.e. HTTPS (Anonymous or User Auth) & SSH. You can update from Anonymous to User Auth & vice versa, but not from Anonymous or User Auth to SSH and vice versa.
Note:
You can enable or disable a git account. Enabled git accounts will be available on the App Configuration > .
Prerequisites: Chart version should be > 4.14.0
External Secrets Operator is a Kubernetes operator that integrates external secret management systems like AWS Secrets Manager, HashiCorp Vault, Google Secrets Manager, Azure Key Vault and many more. The operator reads information from external APIs and automatically injects the values into a Kubernetes Secret.
Before creating any external secrets on Devtron, External Secret Operator must be installed on the target cluster. External Secret Operator allows you to use external secret management systems (e.g., AWS Secrets Manager, Hashicorp Vault, Azure Secrets Manager, Google Secrets Manager etc.) to securely inject secrets in Kubernetes.
You can install External Secrets Operator using charts store:
Go to charts store.
Search chart with name external-secrets.
If you don't find any chart with this name i.e external-secrets, add chart repository using repository url https://charts.external-secrets.io. Please follow this for adding chart repository.
Deploy the chart.
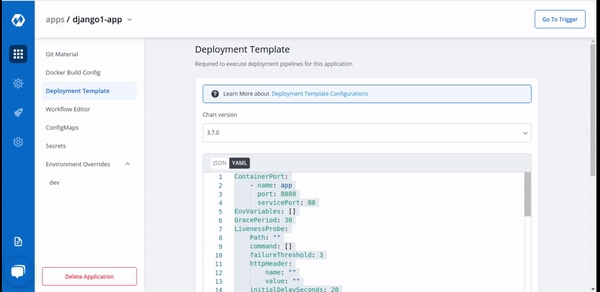
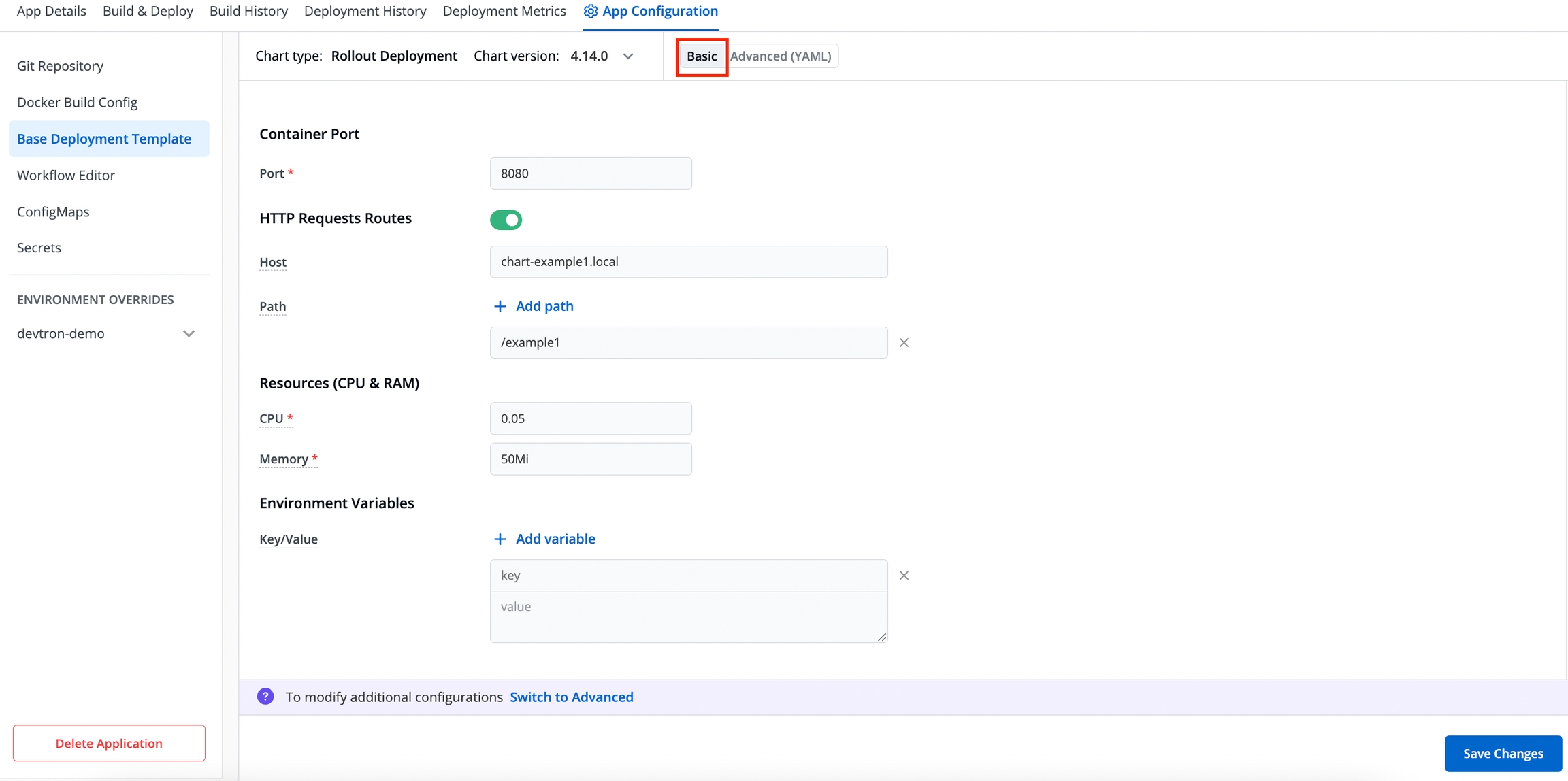
A deployment configuration is a manifest of the application. It defines the runtime behavior of the application. You can select one of the default deployment charts or custom deployment charts which are created by super admin.
To configure a deployment chart for your application, do the following steps:
Go to Applications and create a new application.
Go to App Configuration page and configure your application.
On the Base Deployment Template page, select the drop-down under Chart type.
You can select a default deployment chart from the following options:
(Recommended)
Custom charts are added by users with super admin permission from the section.
You can select the available custom charts from the drop-down list. You can also view the description of the custom charts in the list.
A can be uploaded by a super admin.
Enable show application metrics toggle to view the application metrics on the App Details page.
IMPORTANT: Enabling Application metrics introduces a sidecar container to your main container which may require some additional configuration adjustments. We recommend you to do load test after enabling it in a non-production environment before enabling it in production environment.
Select Save & Next to save your configurations.
Super-admins can lock keys in base deployment template to prevent non-super-admins from modifying those locked keys. Refer to know more.
Each time you push a change to your application through GitHub, your application goes through a process to be built and deployed.
There are two main steps for building and deploying applications:
You can also rollback the deployment. Refer for detail.
Devtron can be updated from the Devtron Stack Manager > About Devtron section.
Select Update to Devtron
The update process may show one of the following statuses, with details available for tracking, troubleshooting, and additional information:
Updating Devtron also updates the installed integrations.
kubectl -n devtroncd get installers installer-devtron -o jsonpath='{.status.sync.data}' | grep "^LTAG=" | cut -d"=" -f2-helm list --namespace devtroncdRELEASE_NAME=devtronhelm repo updatehelm upgrade devtron devtron/devtron-operator --namespace devtroncd \
-f https://raw.githubusercontent.com/devtron-labs/devtron/main/charts/devtron/devtron-bom.yaml \
--set installer.modules={cicd} --reuse-valuesDEVTRON_TARGET_VERSION=v0.4.x
helm upgrade devtron devtron/devtron-operator --namespace devtroncd \
-f https://raw.githubusercontent.com/devtron-labs/devtron/$DEVTRON_TARGET_VERSION/charts/devtron/devtron-bom.yaml \
--set installer.modules={cicd} --reuse-valuesIf you want to check the current version of Devtron you are using, please use the following command.
kubectl -n devtroncd get installers installer-devtron -o jsonpath='{.status.sync.data}' | grep "^LTAG=" | cut -d"=" -f2-helm list --namespace devtroncdRELEASE_NAME=devtronkubectl -n devtroncd label all --all "app.kubernetes.io/managed-by=Helm"
kubectl -n devtroncd annotate all --all "meta.helm.sh/release-name=$RELEASE_NAME" "meta.helm.sh/release-namespace=devtroncd"
kubectl -n devtroncd label secret --all "app.kubernetes.io/managed-by=Helm"
kubectl -n devtroncd annotate secret --all "meta.helm.sh/release-name=$RELEASE_NAME" "meta.helm.sh/release-namespace=devtroncd"
kubectl -n devtroncd label cm --all "app.kubernetes.io/managed-by=Helm"
kubectl -n devtroncd annotate cm --all "meta.helm.sh/release-name=$RELEASE_NAME" "meta.helm.sh/release-namespace=devtroncd"
kubectl -n devtroncd label sa --all "app.kubernetes.io/managed-by=Helm"
kubectl -n devtroncd annotate sa --all "meta.helm.sh/release-name=$RELEASE_NAME" "meta.helm.sh/release-namespace=devtroncd"
kubectl label clusterrole devtron "app.kubernetes.io/managed-by=Helm"
kubectl annotate clusterrole devtron "meta.helm.sh/release-name=$RELEASE_NAME" "meta.helm.sh/release-namespace=devtroncd"
kubectl label clusterrolebinding devtron "app.kubernetes.io/managed-by=Helm"
kubectl annotate clusterrolebinding devtron "meta.helm.sh/release-name=$RELEASE_NAME" "meta.helm.sh/release-namespace=devtroncd"
kubectl -n devtroncd label role --all "app.kubernetes.io/managed-by=Helm"
kubectl -n devtroncd annotate role --all "meta.helm.sh/release-name=$RELEASE_NAME" "meta.helm.sh/release-namespace=devtroncd"
kubectl -n devtroncd label rolebinding --all "app.kubernetes.io/managed-by=Helm"
kubectl -n devtroncd annotate rolebinding --all "meta.helm.sh/release-name=$RELEASE_NAME" "meta.helm.sh/release-namespace=devtroncd"helm repo update5.1 Upgrade Devtron to latest version
helm upgrade devtron devtron/devtron-operator --namespace devtroncd \
-f https://raw.githubusercontent.com/devtron-labs/devtron/main/charts/devtron/devtron-bom.yaml \
--set installer.modules={cicd} --reuse-valuesOR
5.2 Upgrade Devtron to a custom version. You can find the latest releases from Devtron on Github https://github.com/devtron-labs/devtron/releases
DEVTRON_TARGET_VERSION=v0.4.x
helm upgrade devtron devtron/devtron-operator --namespace devtroncd \
-f https://raw.githubusercontent.com/devtron-labs/devtron/$DEVTRON_TARGET_VERSION/charts/devtron/devtron-bom.yaml \
--set installer.modules={cicd} --reuse-valueshelm repo add devtron https://helm.devtron.ai
helm repo update devtron
helm install devtron devtron/devtron-operator \
--create-namespace --namespace devtroncd \
--set components.devtron.service.type=NodePort --set installer.arch=multi-arch
kubectl apply -f https://raw.githubusercontent.com/rancher/local-path-provisioner/master/deploy/local-path-storage.yaml
helm repo add devtron https://helm.devtron.ai
helm repo update devtron
helm install devtron devtron/devtron-operator \
--create-namespace --namespace devtroncd \
--set components.devtron.service.type=NodePort
minikube service devtron-service --namespace devtroncdkubectl -n devtroncd port-forward service/devtron-service 8000:80kubectl -n devtroncd get secret devtron-secret \
-o jsonpath='{.data.ADMIN_PASSWORD}' | base64 -dkubectl -n devtroncd get secret devtron-secret \
-o jsonpath='{.data.ACD_PASSWORD}' | base64 -dsudo snap install microk8s --classic --channel=1.22
sudo usermod -a -G microk8s $USER
sudo chown -f -R $USER ~/.kube
newgrp microk8s
microk8s enable dns storage helm3
echo "alias kubectl='microk8s kubectl '" >> .bashrc
echo "alias helm='microk8s helm3 '" >> .bashrc
source .bashrchelm repo add devtron https://helm.devtron.ai
helm repo update devtron
helm install devtron devtron/devtron-operator \
--create-namespace --namespace devtroncd \
--set components.devtron.service.type=NodePort
kubectl get svc -n devtroncd devtron-service -o jsonpath='{.spec.ports[0].nodePort}'Name
Provide a name to your Git provider. Note: This name will be available on the App Configuration > Git repository drop-down list.
Git host
It is the git provider on which corresponding application git repository is hosted.
Note: By default, Bitbucket and GitHub are available in the drop-down list. You can add many as you want by clicking [+ Add Git Host].
URL
Provide the Git host URL.
As an example: https://github.com for Github, https://gitlab.com for GitLab etc.
Authentication Type
Devtron supports three types of authentications:
User auth: If you select User auth as an authentication type, then you must provide the Username and Passwordor Auth token for the authentication of your version control account.
Anonymous: If you select Anonymous as an authentication type, then you do not need to provide the Username and Password.
Note: If authentication type is set as Anonymous, only public git repository will be accessible.
SSH Key: If you choose SSH Key as an authentication type, then you must provide the Private SSH Key corresponding to the public key added in your version control account.

Initializing
The update is being initialized.
Updating
Devtron is being updated to the latest version.
Failed
Update failed. You may retry the upgrade or contact support.
Unknown
Status is unknown at the moment and will be updated shortly.
Request timed out
The request to install has hit the maximum number of retries. You may retry the installation or contact support for further assistance.
To add secrets from AWS Secrets Manager, we need to create a generic Kubernetes secret for AWS authentication.
Create a Kubernetes secret in the namespace in which the application is to be deployed using base64 encoded AWS access-key and secret-access-key. You can use a Devtron generic chart for it.
Note: You don't have to create the Kubernetes secret every time you create external secret for the respective namespace.
After creating the generic secret, navigate to Secrets section of the application and follow the steps mentioned below :
1. Click Add Secret to add a new secret
2. Select AWS Secret Manager under External Secret Operator (ESO) from the dropdown of Data type
3. Configure the secret
region
AWS region in which secret is created
accessKeyIDSecretRef.name
Name of secret created that would be used for authentication
accessKeyIDSecretRef.key
In generic secret created for AWS authentication, variable name in which base64 encoded AWS access-key is stored
secretAccessKeySecretRef.name
Name of secret created that would be used for authentication
secretAccessKeySecretRef.key
In generic secret created for AWS authentication, variable name in which base64 encoded secret-access-key is stored
secretKey
Key name to store secret
key
AWS Secrets Manager secret name
property
AWS Secrets Manager secret key
4. Save the secret
ClusterSecretStore provides a secure and centralized storage solution for managing and accessing sensitive information, such as passwords, API keys, certificates, and other credentials, within a cluster or application environment.
Requirement: Devtron deployment template chart version should be 4.17 and above.
To setup ESO AWS secrets manager with Devtron using ClusterSecretsStore, follow the mentined steps:
1. Create a secret for AWS authentication
Create a Kubernetes secret in any namespace using base64 encoded AWS access-key and secret-access-key. You can use the devtron generic chart for this.
2. Create a ClusterSecretStore
Create a ClusterSecretStore using the secret created for AWS authentication in step 1.
3. Create a secret in the application using ESO AWS Secrets Manager
Go to the application where you want to create an external secret. Navigate to secrets section under application configuration and create a secret using ESO AWS Secrets Manager.
Workflow is a logical sequence of different stages used for continuous integration and continuous deployment of an application.
Click on New Build Pipeline to create a new workflow
On clicking New Build Pipeline, three options appear as mentioned below:
Continuous Integration: Choose this option if you want Devtron to build the image of source code.
Linked CI Pipeline: Choose this option if you want to use an image created by an existing CI pipeline in Devtron.
Incoming Webhook: Choose this if you want to build your image outside Devtron, it will receive a docker image from an external source via the incoming webhook.
Then, create CI/CD Pipelines for your application.
To know how to create the CI pipeline for your application, click on: Create CI Pipelines
To know how to create the CD pipeline for your application, click on: Create CD Pipelines
The Job Pipeline can be triggered by selecting Select Material
Job Pipelines that are set as automatic are always triggered as soon as a new commit is made to the git branch they're sensing. However, Job pipelines can always be manually triggered as and if required.
Various commits done in the repository can be seen here along with details like Author, Date etc. Select the commit that you want to trigger and then click on Run Job to trigger the job pipeline.
Refresh icon, refreshes Git Commits in the job Pipeline and fetches the latest commits from the Git Repository.
Ignore Cache : This option will ignore the previous build cache and create a fresh build. If selected, will take a longer build time than usual.
It can be seen that the job pipeline is triggered here and is the Running state.
Click your job pipeline or click Run History to get the details about the job pipeline such as logs, reports etc.
Click Source code to view the details such as commit id, Author and commit message of the Git Material that you have selected for the job.
Click Artifacts to download the reports of the job, if any.
If you have multiple job pipelines, you can select a pipeline from the drop-down list to view th details of logs, source code, or artifacts.
The Overview section contains the brief information of the job, any added tags, and deployment details of the particular job. In this section, you can also change project of your job and manage tags if you added them while creating job.
The following details are provided on the Overview page:
Job Name
Displays the name of the job.
Created on
Displays the day, date and time the job was created.
Created by
Displays the email address of a user who created the job.
Project
Displays the current project of the job. You can change the project by selecting a different project from the drop-down list.
You can change the project of your job by clicking Project on the Overview section.
Click Project.
On the Change project dialog box, select the different project you want to change from the drop-down list.
Click Save. The job will be moved to the selected project.
Tags are key-value pairs. You can add one or multiple tags in your application. When tags are propagated, they are considered as labels to Kubernetes resources. Kubernetes offers integrated support for using these labels to query objects and perform bulk operations e.g., consolidated billing using labels. You can use these tags to filter/identify resources via CLI or in other Kubernetes tools.
Manage tags is the central place where you can create, edit, and delete tags. You can also propagate tags as labels to Kubernetes resources for the application.
Click Edit tags.
On the Manage tags page, click + Add tag to add a new tag.
Click X to delete a tag.
Click the symbol on the left side of your tag to propagate a tag.
Note: Dark grey colour in symbol specifies that the tags are propagated.
To remove the tags from propagation, click the symbol again.
Click Save.
The changes in the tags will be reflected in the Tags on the Overview section.
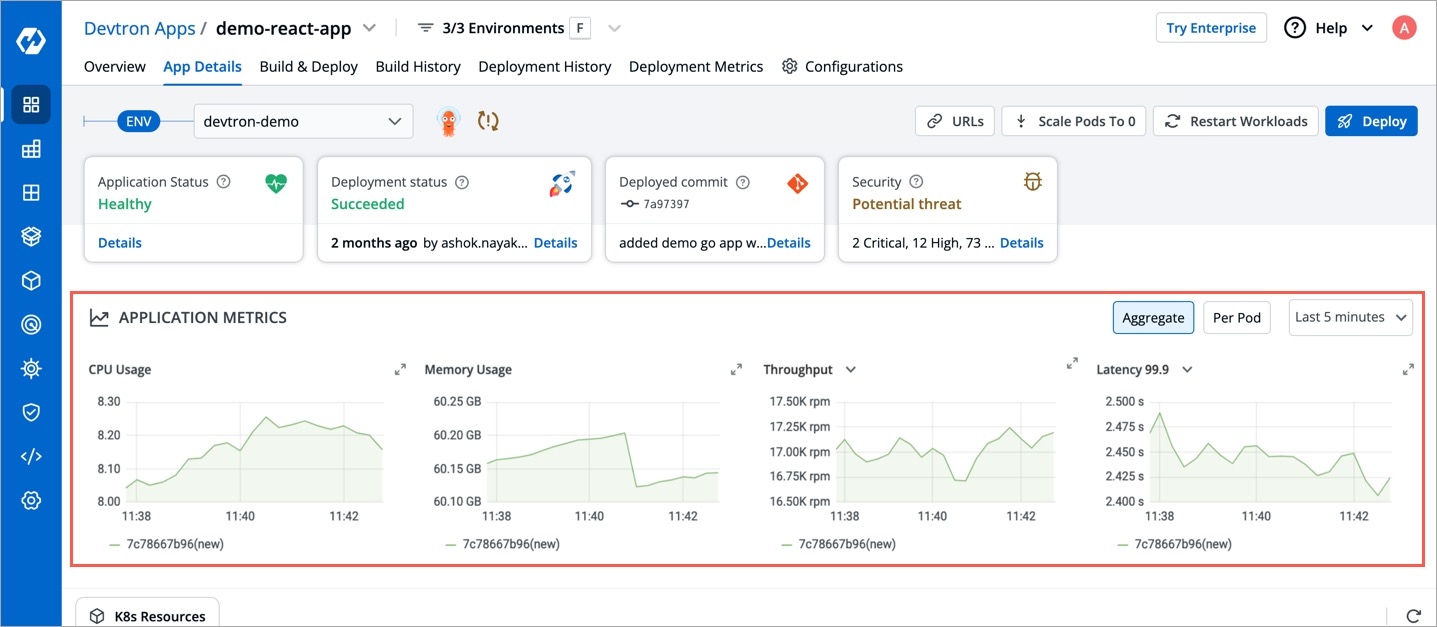
Application metrics can be enabled to see your application's metrics.
Devtron provides certain metrics (CPU and Memory utilization) for each application by default i.e. you do not need to enable “Application metrics”. However, prometheus needs to be present in the cluster and the endpoint of the same should be updated in Global Configurations --> Clusters & Environments section.
There are certain advanced metrics (like Latency, Throughput, 4xx, 5xx, 2xx) which are only available when "Application metrics" is enabled from the Deployment Template. When you enable these advanced metrics, devtron attaches a envoy sidecar container to your main container which runs as a transparent proxy and passes each request through it to measure the advanced metrics.
Note: Since, all the requests are passed through envoy, any misconfiguration in envoy configs can bring your application down, so please test the configurations in a non-production environment extensively.
envoyproxy:
image: envoyproxy/envoy:v1.14.1
configMapName: ""
resources:
limits:
cpu: "50m"
memory: "50Mi"
requests:
cpu: "50m"
memory: "50Mi"CPU usage is a utilization metric that shows the overall utilization of cpu by an application. It is available as both, aggregated or per pod.
Memory usage is a utilization metric that shows the overall utilization of memory by an application. It is available as both, aggregated or per pod.
This application metrics indicates the number of request processed by an application per minute.
This metrics indicates the application’s response to client’s request with a specific status code i.e 1xx(Communicate transfer protocol-level information), 2xx(Client’s request was accepted successfully), 3xx(Client must take some additional action to complete their request), 4xx(Client side error) or 5xx(Server side error).
Latency metrics shows the latency for an application. Latency measures the delay between an action and a response.
99.9th percentile latency: The maximum latency, in seconds, for the fastest 99.9% of requests.
99th percentile latency: The maximum latency, in seconds, for the fastest 99% of requests.
95th percentile latency: The maximum latency, in seconds, for the fastest 95% of requests.
Note: We also support custom percentile input inside the dropdown .A latency measurement based on a single request is not meaningful.

Ideally, all resources such as microservices, clusters, jobs, pods, etc. should contain detailed information so that its users know what each of those resources do, how to use them, as well as all their technical specs. Access to such data makes it easier for engineers to quickly discover and understand the relevant resources.
To achieve this, Devtron supports a feature known as Catalog Framework. Using this, you as a can decide the data you expect from the managers of different resource types. In other words, you can create a custom that would ultimately render a form for the resource owners to fill. Once the form is filled, a GUI output will appear as shown below.
Currently, Devtron supports catalog framework for the following resource types (a.k.a. resource kind):
There are two parts involved in the creation of a desirable resource catalog:
Go to Global Configurations → Catalog Framework.
Choose a resource type, for which you wish to define a schema, for e.g., Devtron applications.
You can edit the schema name and description.
There is a sample schema available for you to create your own customized schema. Using this schema, you can decide the input types that renders within the form, for e.g., a dropdown of enum values, a boolean toggle button, text field, label, and many more.
After defining your schema, click Review Changes.
You get a side-by-side comparison (diff) highlighting the changes you made.
Click Save.
Similarly, you can define schemas for other resource types.
Note: If you edit a field (of an existing schema) for which users have already filled the data, that data will be erased. You will receive a prompt (as shown below) to confirm whether you want to proceed with the changes.
Once a catalog schema exists for a resource type, its corresponding form would be available in the overview section of that resource type.
Since we defined a schema for Devtron applications in the above example, go to the Overview tab of your application (any Devtron application). Click the Edit button within the About section.
The schema created for Devtron applications would render into an empty form as shown below.
Fill as many details as an application owner to the best of your knowledge and click Save.
Your saved data would be visible in a GUI format (and also in JSON format) as shown below.
This catalog data would be visible to all the users who have access to the application, but its data can be edited only by the resource owners (in this case, application admin/managers).
API tokens are the access tokens for authentication. Instead of using username and password, it can be used for programmatic access to API. It allows users to generate API tokens with the desired access. Only super admin users can generate API tokens and see the generated tokens.
To generate API tokens, go to Global Configurations -> Authorization -> API tokens and click Generate New Token.
Enter a name for the token.
Add Description.
Select an expiration date for the token (7 days, 30 days, 60 days, 90 days, custom and no expiration).
To select a custom expiration date, select Custom from the drop-down list. In the adjacent field, you can select your custom expiration date for the API token.
You can assign permission to the token either with:
Super admin permission: To generate a token with super admin permission, select Super admin permission.
Specific permissions: Selecting Specific permissions option allows you to generate a token with a specific role for:
Devtron Apps
Helm Apps
Kubernetes Resources
Chart Groups
Click Generate Token.
A pop-up window will appear on the screen from where you can copy the API token.
Once Devtron API token has been generated, you can use this token to request Devtron APIs using any API testing tool like Jmeter, Postman, Citrus. Using Postman here as an example.
Open Postman. Enter the request URL with POST method and under HEADERS, enter the API token as shown in the image below.
In the Body section, provide the API payload as shown below and click Send.
As soon as you click Send, the created application API will be triggered and a new Devtron app will be created as provided in the payload.
To set a new expiration date or to make changes in permissions assigned to the token, we need to update the API token in Devtron. To update the API token, click the token name or click on the edit icon.
To set a new expiration date, you can regenerate the API token. Any scripts or applications using this token must be updated. To regenerate a token, click Regenerate token.
A pop-up window will appear on the screen from where you can select a new expiration date.
Select a new expiration date and click Regenerate token.
This will generate a new token with a new expiration date.
To update API token permissions, give the permissions as you want to and click Update Token.
To delete an API token, click delete icon. Any applications or scripts using this token will no longer be able to access the Devtron API.
Ephemeral container is a special type of container that runs temporarily in an existing Pod to accomplish user-initiated actions such as troubleshooting. It is especially useful when kubectl exec is insufficient because a container has crashed or a container image doesn't include debugging utilities.
For instance, ephemeral containers help you execute a curl request from within pods that typically lack this utility.
Wherever you can access pod resources in Devtron, you can launch an ephemeral container as shown below.
In the left sidebar, go to Applications.
Search and click your application from the list of Devtron Apps.
Go to the App Details tab.
Under the K8 Resources tab, select Pod inside Workloads.
Locate the pod you wish to debug. Hover and choose click Terminal.
Click Launch Ephemeral Container as shown below.
You get 2 tabs:
Basic - It provides the bare minimum configurations required to launch an ephemeral container.
It contains 3 mandatory fields:
Container name prefix - Type a prefix to give to your ephemeral container, for e.g., debug. Your container name would look like debug-jndvs.
Image - Choose an image to run from the dropdown. Ephemeral containers need an image to run and provide the capability to debug, such as curl. You can use a custom image too.
Target Container name - Since a pod can have one or more containers, choose a target container you wish to debug, from the dropdown.
Advanced - It is particularly useful for advanced users that wish to use labels or annotations since it provides additional key-value options. Refer to view the supported options.
Click Launch Container.
Click to know more.
(This is not a recommended method. This option is available only if you are an admin.)
You can launch an ephemeral container from Kubernetes CLI. For this, you need access to the cluster terminal on Devtron.
You can remove an ephemeral container using either App Details or Resource Browser (from the same screen you used to create the ephemeral container).
Deployments can be rolled back manually. After a deployment is completed, you can manually rollback to a previously deployed image by retaining the same configuration or changing the configuration.
As an example, You have deployed four different releases as follows:
If you want to roll back from V3 image to V2 image, then you have the following options:
Select Rollback in your deployed pipeline.
On the Rollback page, select a configuration to deploy from the list:
Once you select the previously deployed image and the configuration, review the difference between Last Deployed Configuration and the selected configuration.
Click Deploy.
The selected previously deployed image will be deployed.
Note:
There will be no difference in the configuration if you select Last deployed config from the list.
When you select Config deployed with selected image and if the configuration is missing in the selected previously deployed image, it will show as Config Not Available. In such cases, you can select either Last saved config or Last deployed config.
To incorporate secrets from HashiCorp Vault, you need to create a generic Kubernetes secret that will be used for vault authentication. This involves creating a Kubernetes secret in the specific namespace where your application will be deployed. The secret should store the base64-encoded password or token obtained from vault. To simplify the process, you can utilize the Devtron generic chart. An example yaml is given below:
Note: Please note that you don't need to create the Kubernetes secret every time you create an External Secret for the corresponding namespace.
Once you have created the generic secret, follow these steps in the application's Secrets section:
1. Create a new secret
To add a new secret to the application, go to the App Configuration section of the application. Then, navigate to the left pane and select the Secrets option and click the Add Secret button.
2. Select HashiCorp Vault as the External Secret Operator
After clicking the Add Secret button, select HashiCorp Vault from the dropdown menu for the Data type option. Provide a name for the secret you are creating, and then proceed to configure the external secret as described in the next step.
3. Configure the secret
To configure the external secret that will be fetched from HashiCorp Vault for your application, you will need to provide specific details using the following key-value pairs:
4. Save the secret
After configuring the external secret from HashiCorp Vault, proceed to save the secret by clicking the Save button.
By following the steps mentioned above and configuring these values correctly, you can seamlessly fetch and utilize external secrets from HashiCorp Vault within your application environment by deploying the application.
The users can access the on the App Details page.
Select Applications from the left navigation pane.
After selecting a configured application, select the App Details tab.
Note: If you enable
App admins can editon theExternal Linkspage, then only non-super admin users can view the selected links on theApp-Detailspage.
As shown in the screenshot, the external links appear on the App-Details level:
You can hover around an external link (e.g. Grafana) to view the description.
The link opens in a new tab with the context you specified as env variables in the section.
On the App Configuration page, select External Links from the navigation pane. You can see the configured external links which can be searched, edited or deleted.
You can also Add Link to add a new external link.
You can view the Ingress Host URL and the Load Balancer URL on the URLs section on the App Details. You can also copy the Ingress Host URL from the URLs instead of searching in the Manifest.
Select Applications from the left navigation pane.
After selecting your configured application, select the App Details.
Click URLs.
You can view or copy the URL of the Ingress Host.
Note:
The Ingress Host URL will point to the load balancer of your application.
You can also view the Service name with the load balancer detail.
To add secrets from Google Secrets Manager, follow the steps mentioned below :
1. Go to Google cloud console and create a Service Account.
2. Assign roles to the service account.
3. Add and create a new key.
5. Create a Kubernetes secret in the namespace in which the application is to be deployed using base64 encoded service account key.
You can use devtron generic chart for this.
6. After creating the generic secret, navigate to Secrets section of the application and click Add Secret to add a new secret.
7. Select Google Secrets Manager under External Secret Operator (ESO) from the dropdown of Data type.
8. Configure secret:
9. Save secret.
On the Devtron dashboard, select Jobs.
On the upper-right corner of the screen, click Create.
Select Job from the drop-down list.
Create job page opens.
Provide below information on the Create job page:
Note: Do not forget to modify git repositories and corresponding branches to be used for each Job Pipeline if required.
Tags are key-value pairs. You can add one or multiple tags in your application.
Propagate Tags When tags are propagated, they are considered as labels to Kubernetes resources. Kubernetes offers integrated support for using these labels to query objects and perform bulk operations e.g., consolidated billing using labels. You can use these tags to filter/identify resources via CLI or in other Kubernetes tools.
Click + Add tag to add a new tag.
Click the symbol on the left side of your tag to propagate a tag.
Note: Dark grey colour in symbol specifies that the tags are propagated.
To remove the tags from propagation, click the symbol again.
Click Save.

After Devtron is installed, Devtron is accessible through service devtron-service. If you want to access Devtron through ingress, edit devtron-service and change the loadbalancer to ClusterIP. You can do this using kubectl patch command:
kubectl patch -n devtroncd svc devtron-service -p '{"spec": {"ports": [{"port": 80,"targetPort": "devtron","protocol": "TCP","name": "devtron"}],"type": "ClusterIP","selector": {"app": "devtron"}}}'After this, create ingress by applying the ingress yaml file. You can use this yaml file to create ingress to access Devtron:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/app-root: /dashboard
labels:
app: devtron
release: devtron
name: devtron-ingress
namespace: devtroncd
spec:
ingressClassName: nginx
rules:
- http:
paths:
- backend:
service:
name: devtron-service
port:
number: 80
path: /orchestrator
pathType: ImplementationSpecific
- backend:
service:
name: devtron-service
port:
number: 80
path: /dashboard
pathType: ImplementationSpecific
- backend:
service:
name: devtron-service
port:
number: 80
path: /grafana
pathType: ImplementationSpecific You can access Devtron from any host after applying this yaml. For k8s versions <1.19, apply this yaml:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/app-root: /dashboard
labels:
app: devtron
release: devtron
name: devtron-ingress
namespace: devtroncd
spec:
rules:
- http:
paths:
- backend:
serviceName: devtron-service
servicePort: 80
path: /orchestrator
- backend:
serviceName: devtron-service
servicePort: 80
path: /dashboard
pathType: ImplementationSpecific Optionally, you also can access Devtron through a specific host by running the following YAML file:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/app-root: /dashboard
labels:
app: devtron
release: devtron
name: devtron-ingress
namespace: devtroncd
spec:
ingressClassName: nginx
rules:
- host: devtron.example.com
http:
paths:
- backend:
service:
name: devtron-service
port:
number: 80
path: /orchestrator
pathType: ImplementationSpecific
- backend:
service:
name: devtron-service
port:
number: 80
path: /dashboard
pathType: ImplementationSpecific
- backend:
service:
name: devtron-service
port:
number: 80
path: /grafana
pathType: ImplementationSpecificOnce ingress setup for devtron is done and you want to run Devtron over https, you need to add different annotations for different ingress controllers and load balancers.
In case of nginx ingress controller, add the following annotations under service.annotations under nginx ingress controller to run devtron over https.
(i) Amazon Web Services (AWS)
If you are using AWS cloud, add the following annotations under service.annotations under nginx ingress controller.
annotations:
service.beta.kubernetes.io/aws-load-balancer-backend-protocol: "http"
service.beta.kubernetes.io/aws-load-balancer-ssl-ports: "443"
nginx.ingress.kubernetes.io/force-ssl-redirect: "true"
service.beta.kubernetes.io/aws-load-balancer-ssl-cert: "<acm-arn-here>"(ii) Digital Ocean
If you are using Digital Ocean cloud, add the following annotations under service.annotations under nginx ingress controller.
annotations:
service.beta.kubernetes.io/do-loadbalancer-protocol: "http"
service.beta.kubernetes.io/do-loadbalancer-tls-ports: "443"
service.beta.kubernetes.io/do-loadbalancer-certificate-id: "<your-certificate-id>"
service.beta.kubernetes.io/do-loadbalancer-redirect-http-to-https: "true"In case of AWS application load balancer, add following annotations under ingress.annotations to run devtron over https.
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}, {"HTTPS": 443}]'
alb.ingress.kubernetes.io/certificate-arn: "<acm-arn-here>"In case of AWS application load balancer, the following annotations need to be added under ingress.annotations to run devtron over https.
annotations:
kubernetes.io/ingress.class: "azure/application-gateway"
appgw.ingress.kubernetes.io/backend-protocol: "http"
appgw.ingress.kubernetes.io/ssl-redirect: "true"
appgw.ingress.kubernetes.io/appgw-ssl-certificate: "<name-of-appgw-installed-certificate>"For an Ingress resource to be observed by AGIC (Application Gateway Ingress Controller) must be annotated with kubernetes.io/ingress.class: azure/application-gateway. Only then AGIC will work with the Ingress resource in question.
Note: Make sure NOT to use port 80 with HTTPS and port 443 with HTTP on the Pods.
Devtron ignores the `command` field while launching an ephemeral containerV1
C1
R1
V2
C2
R2
V3
C2
R3
V3
C3
R4
V3
C4 (saved but not deployed)
-
Config deployed with selected image
V2
C2
Last deployed config
V2
C3
Last saved config
V2
C4
Last saved config
Deploy the image with the latest saved configuration.
Last deployed config
Deploy the image with the last deployed configuration. As an example: The configuration C3.
Config deployed with selected image
Deploy the configuration which was deployed with the selected image. As an example: The configuration C2.
apiVersion: v1
kind: Secret
type: Opaque
data:
token: <vault-password>
metadata:
name: vault-token
namespace: <namespace>vault.server
Server is the connection address for the Vaultserver, e.g: "https://vault.example.com:8200"
vault.path
Specify the path where the secret is stored in Vault
tokenSecretRef.name
Enter the name of the secret that will be used for authentication
tokenSecretRef.key
Specify the key name within the secret that contains the token
secretKey
Provide a name for the secret in Kubernetes
key
Enter the name of the secret in Vault
property
Specify the key within the Vault secret
secretAccessKeySecretRef.name
Name of secret created that would be used for authentication.
secretAccessKeySecretRef.key
In generic secret created for GCP authentication, variable name in which base64 encoded service account key is stored.
ProjectID
GCP Project ID where secret is created.
secretKey
Key name to store secret.
key
GCP Secrets Manager secret name.
Job Name
User-defined name for the job in Devtron.
Description
Enter the description of a job.
Registry URL
This is the URL of your private registry in Quay. E.g. quay.io
Select one of them
Create from scratch :Select the project from the drop-down list.
Note: You have to add project under Global Configurations. Only then, it will appear in the drop-down list here.
Clone existing application: Select an app you want to clone from and the project from the drop-down list.
Note: You have to add project under Global Configurations. Only then, it will appear in the drop-down list here.
In this section, we describe the steps in detail on how you can install Devtron with CI/CD by enabling GitOps during the installation.
Install Helm if you have not installed it.
Run the following command to install the latest version of Devtron with CI/CD along with GitOps (Argo CD) module:
helm repo add devtron https://helm.devtron.ai
helm repo update devtron
helm install devtron devtron/devtron-operator \
--create-namespace --namespace devtroncd \
--set installer.modules={cicd} \
--set argo-cd.enabled=trueNote: If you want to configure Blob Storage during the installation, refer configure blob storage duing installation.
To install Devtron on clusters with the multi-architecture nodes (ARM and AMD), append the Devtron installation command with --set installer.arch=multi-arch.
Note:
If you want to install Devtron for production deployments, please refer to our recommended overrides for Devtron Installation.
Configuring Blob Storage in your Devtron environment allows you to store build logs and cache. In case, if you do not configure the Blob Storage, then:
You will not be able to access the build and deployment logs after an hour.
Build time for commit hash takes longer as cache is not available.
Artifact reports cannot be generated in pre/post build and deployment stages.
Choose one of the options to configure blob storage:
Run the following command to install Devtron along with MinIO for storing logs and cache.
helm repo add devtron https://helm.devtron.ai
helm repo update devtron
helm install devtron devtron/devtron-operator \
--create-namespace --namespace devtroncd \
--set installer.modules={cicd} \
--set minio.enabled=true \
--set argo-cd.enabled=trueNote: Unlike global cloud providers such as AWS S3 Bucket, Azure Blob Storage and Google Cloud Storage, MinIO can be hosted locally also.
Refer to the AWS specific parameters on the Storage for Logs and Cache page.
Run the following command to install Devtron along with AWS S3 buckets for storing build logs and cache:
Install using S3 IAM policy.
Note: Please ensure that S3 permission policy to the IAM role attached to the nodes of the cluster if you are using below command.
helm repo add devtron https://helm.devtron.ai
helm repo update devtron
helm install devtron devtron/devtron-operator \
--create-namespace --namespace devtroncd \
--set installer.modules={cicd} \
--set configs.BLOB_STORAGE_PROVIDER=S3 \
--set configs.DEFAULT_CACHE_BUCKET=demo-s3-bucket \
--set configs.DEFAULT_CACHE_BUCKET_REGION=us-east-1 \
--set configs.DEFAULT_BUILD_LOGS_BUCKET=demo-s3-bucket \
--set configs.DEFAULT_CD_LOGS_BUCKET_REGION=us-east-1 \
--set argo-cd.enabled=trueInstall using access-key and secret-key for AWS S3 authentication:
helm repo add devtron https://helm.devtron.ai
helm repo update devtron
helm install devtron devtron/devtron-operator \
--create-namespace --namespace devtroncd \
--set installer.modules={cicd} \
--set configs.BLOB_STORAGE_PROVIDER=S3 \
--set configs.DEFAULT_CACHE_BUCKET=demo-s3-bucket \
--set configs.DEFAULT_CACHE_BUCKET_REGION=us-east-1 \
--set configs.DEFAULT_BUILD_LOGS_BUCKET=demo-s3-bucket \
--set configs.DEFAULT_CD_LOGS_BUCKET_REGION=us-east-1 \
--set secrets.BLOB_STORAGE_S3_ACCESS_KEY=<access-key> \
--set secrets.BLOB_STORAGE_S3_SECRET_KEY=<secret-key> \
--set argo-cd.enabled=trueInstall using S3 compatible storages:
helm repo add devtron https://helm.devtron.ai
helm repo update devtron
helm install devtron devtron/devtron-operator \
--create-namespace --namespace devtroncd \
--set installer.modules={cicd} \
--set configs.BLOB_STORAGE_PROVIDER=S3 \
--set configs.DEFAULT_CACHE_BUCKET=demo-s3-bucket \
--set configs.DEFAULT_CACHE_BUCKET_REGION=us-east-1 \
--set configs.DEFAULT_BUILD_LOGS_BUCKET=demo-s3-bucket \
--set configs.DEFAULT_CD_LOGS_BUCKET_REGION=us-east-1 \
--set secrets.BLOB_STORAGE_S3_ACCESS_KEY=<access-key> \
--set secrets.BLOB_STORAGE_S3_SECRET_KEY=<secret-key> \
--set configs.BLOB_STORAGE_S3_ENDPOINT=<endpoint> \
--set argo-cd.enabled=trueRefer to the Azure specific parameters on the Storage for Logs and Cache page.
Run the following command to install Devtron along with Azure Blob Storage for storing build logs and cache:
helm repo add devtron https://helm.devtron.ai
helm repo update devtron
helm install devtron devtron/devtron-operator \
--create-namespace --namespace devtroncd \
--set installer.modules={cicd} \
--set secrets.AZURE_ACCOUNT_KEY=xxxxxxxxxx \
--set configs.BLOB_STORAGE_PROVIDER=AZURE \
--set configs.AZURE_ACCOUNT_NAME=test-account \
--set configs.AZURE_BLOB_CONTAINER_CI_LOG=ci-log-container \
--set configs.AZURE_BLOB_CONTAINER_CI_CACHE=ci-cache-container \
--set argo-cd.enabled=trueRefer to the Google Cloud specific parameters on the Storage for Logs and Cache page.
Run the following command to install Devtron along with Google Cloud Storage for storing build logs and cache:
helm repo add devtron https://helm.devtron.ai
helm repo update devtron
helm install devtron devtron/devtron-operator \
--create-namespace --namespace devtroncd \
--set installer.modules={cicd} \
--set configs.BLOB_STORAGE_PROVIDER=GCP \
--set secrets.BLOB_STORAGE_GCP_CREDENTIALS_JSON=eyJ0eXBlIjogInNlcnZpY2VfYWNjb3VudCIsInByb2plY3RfaWQiOiAiPHlvdXItcHJvamVjdC1pZD4iLCJwcml2YXRlX2tleV9pZCI6ICI8eW91ci1wcml2YXRlLWtleS1pZD4iLCJwcml2YXRlX2tleSI6ICI8eW91ci1wcml2YXRlLWtleT4iLCJjbGllbnRfZW1haWwiOiAiPHlvdXItY2xpZW50LWVtYWlsPiIsImNsaWVudF9pZCI6ICI8eW91ci1jbGllbnQtaWQ+IiwiYXV0aF91cmkiOiAiaHR0cHM6Ly9hY2NvdW50cy5nb29nbGUuY29tL28vb2F1dGgyL2F1dGgiLCJ0b2tlbl91cmkiOiAiaHR0cHM6Ly9vYXV0aDIuZ29vZ2xlYXBpcy5jb20vdG9rZW4iLCJhdXRoX3Byb3ZpZGVyX3g1MDlfY2VydF91cmwiOiAiaHR0cHM6Ly93d3cuZ29vZ2xlYXBpcy5jb20vb2F1dGgyL3YxL2NlcnRzIiwiY2xpZW50X3g1MDlfY2VydF91cmwiOiAiPHlvdXItY2xpZW50LWNlcnQtdXJsPiJ9Cg== \
--set configs.DEFAULT_CACHE_BUCKET=cache-bucket \
--set configs.DEFAULT_BUILD_LOGS_BUCKET=log-bucket \
--set argo-cd.enabled=trueNote: The installation takes about 15 to 20 minutes to spin up all of the Devtron microservices one by one.
Run the following command to check the status of the installation:
kubectl -n devtroncd get installers installer-devtron \
-o jsonpath='{.status.sync.status}'The command executes with one of the following output messages, indicating the status of the installation:
Downloaded
The installer has downloaded all the manifests, and the installation is in progress.
Applied
The installer has successfully applied all the manifests, and the installation is completed.
Run the following command to check the installer logs:
kubectl logs -f -l app=inception -n devtroncdRun the following command to get the Devtron dashboard URL:
kubectl get svc -n devtroncd devtron-service \
-o jsonpath='{.status.loadBalancer.ingress}'You will get an output similar to the example shown below:
[map[hostname:aaff16e9760594a92afa0140dbfd99f7-305259315.us-east-1.elb.amazonaws.com]]Use the hostname aaff16e9760594a92afa0140dbfd99f7-305259315.us-east-1.elb.amazonaws.com (Loadbalancer URL) to access the Devtron dashboard.
Note: If you do not get a hostname or receive a message that says "service doesn't exist," it means Devtron is still installing. Please wait until the installation is completed.
Note: You can also use a CNAME entry corresponding to your domain/subdomain to point to the Loadbalancer URL to access at a customized domain.
devtron.yourdomain.com
CNAME
aaff16e9760594a92afa0140dbfd99f7-305259315.us-east-1.elb.amazonaws.com
When you install Devtron for the first time, it creates a default admin user and password (with unrestricted access to Devtron). You can use that credentials to log in as an administrator.
After the initial login, we recommend you set up any SSO service like Google, GitHub, etc., and then add other users (including yourself). Subsequently, all the users can use the same SSO (let's say, GitHub) to log in to Devtron's dashboard.
The section below will help you understand the process of getting the administrator credentials.
Username: admin
Password: Run the following command to get the admin password:
kubectl -n devtroncd get secret devtron-secret \
-o jsonpath='{.data.ADMIN_PASSWORD}' | base64 -dIf you want to uninstall Devtron or clean Devtron helm installer, refer our uninstall Devtron.
Related to installation, please also refer FAQ section also.
Note: If you have questions, please let us know on our discord channel.
The Deployment Template might contain certain configurations intended for the DevOps team (e.g., ingress), and not meant for developers to modify.
Therefore, Devtron allows super-admins to restrict such fields from modification or deletion.
This stands true for deployment templates in:
How is this different from the Protect Configuration feature?
The 'protect configuration' feature is meant to verify the edits by introducing an approval flow for any changes made to the configuration files, i.e., Deployment template, ConfigMaps, and Secrets. This is performed at application-level.
Whereas, the 'lock deployment configuration' feature goes one step further. It is meant to prevent any edits to specific keys by non-super-admins. This applies only to deployment templates and is performed at global-level.
Go to Global Configurations → Lock Deployment Config. Click Configure Lock.
(Optional) Click Refer Values.YAML to check which keys you wish to lock.
Enter the keys inside the editor on the left-hand side, e.g., autoscaling.MaxReplicas. Use JSONpath expressions to enter specific keys, lists, or objects to lock.
Click Save.
A confirmation dialog box would appear. Read it and click Confirm.
While super-admins can directly edit the locked keys, let's look at a scenario where a user (non-super-admin) tries to edit the same in an unprotected base deployment template.
User can hide/unhide the locked keys as shown below.
Let's assume the user edits one of the locked keys...
...and saves the changes.
A modal window will appear on the right highlighting the non-eligible edits.
Let's assume the user edits a key that is not locked or adds a new key.
The modal window will highlight the eligible edits. However, it will not let the user save those eligible edits unless the user clicks the checkbox: Save changes which are eligible for update.
Only a super-admin, manager, or application admin can edit the configuration values.
Once the user clicks the Update button, the permissible changes will reflect in the deployment template.
However, if it's a protected template, the user will require the approval of a configuration approver as shown below.
The same result can be seen if the user tries to edit environment-specific deployment templates.
External Links allow you to connect to the third-party applications within your Devtron dashboard for seamlessly monitoring/debugging/logging/analyzing your applications. You can select from the pre-defined third-party applications such as Grafana to link to your application for quick access.
Configured external links will be available on the App details page. You can also integrate Document or Folder using External Links.
Some of the third-party applications which are pre-defined on Devtron Dashboard are:
Grafana
Kibana
Newrelic
Coralogix
Datadog
Loki
Cloudwatch
Swagger
Jira etc.
To monitor/debug an application using a specific Monitoring Tool (such as Grafana, Kibana, etc.), you may need to navigate to the tool's page, then to the respective app/resource page.
External Links can take you directly to the tool's page, which includes the context of the application, environment, pod, and container.
Before you begin, configure an application in the Devtron dashboard.
Super admin access
Monitoring tool URL
Note: External links can only be added/managed by a super admin, but non-super admin users can access the configured external links on the App Configuration page.
On the Devtron dashboard, go to the Global Configurations from the left navigation pane.
Select External links.
Select Add Link.
On the Add Link page, select the external link (e.g. Grafana) which you want to link to your application from Webpage.
The following fields are provided on the Add Link page:
Link name
Provide name of the link.
Description
Description of the link name.
Show link in
All apps in specific clusters: Select this option to select the cluster.
Specific applications: Select this option to select the application.
Clusters
Choose the clusters for which you want to configure the selected external link with.
Select one or more than one cluster to enable the link on the specified clusters.
Select All Clusters to enable the link on all the clusters.
Applications
Choose the application for which you want to configure the selected external link with.
Select one or more than one application to enable the link on the specified application.
Select All applications to enable the link on all the applications. Note: If you enable `App admins can edit`, then you can view the selected links on the App-Details page.
URL Template
The configured URL Template is used by apps deployed on the selected clusters/applications. By combining one or more of the env variables, a URL with the structure shown below can be created: http://www.domain.com/{namespace}/{appName}/details/{appId}/env/{envId}/details/{podName} If you include the variables {podName} and {containerName} in the URL template, then the configured links (e.g. Grafana) will be visible only on the pod level and container level respectively. The env variables:
{appName}
{appId}
{envId}
{namespace}
{podName}: If used, the link will only be visible at the pod level on the page.
{containerName}: If used, the link will only be visible at the container level on the page.
Note: The env variables will be dynamically replaced by the values that you used to configure the link.
Note: To add multiple links, select + Add another at the top-left corner.
Click Save.
The users (admin and others) can access the configured external link on the App Details page.
Note: If you enable App admins can edit on the External Links page, then only non-super admin users can view the selected links on the App Details page.
On the External Links page, the configured external links can be filtered/searched, as well as edited/deleted.
Select Global Configurations > External links.
Filter and search the links based on the link's name or a user-defined name.
Edit a link by selecting the edit icon next to an external link.
Delete an external link by selecting the delete icon next to a link. The bookmarked link will be removed in the clusters for which it was configured.
Once Devtron is installed, it has a built-in admin user with super admin privileges with unrestricted access to all Devtron resources. We recommended to use a user with super admin privileges for initial and global configurations only and then switch to local users or configure SSO integration.
Only users with super-admin privileges can create SSO configuration. Devtron uses Dex for authenticating a user against the identity provider.
To add/edit SSO configuration, go to the SSO Login Services section of Global Configurations.
Below are the SSO providers which are available in Devtron. Select one of the SSO providers (e.g., GitHub) to configure SSO:
Google GitHub GitLab Microsoft LDAP OpenID Connect OpenShift
Dex implements connectors that target specific identity providers for each connector configuration. You must have a created account for the corresponding identity provider and registered an app for client key and secret.
Refer the following documents for more detail.
https://dexidp.io/docs/connectors/
https://dexidp.io/docs/connectors/google/
Make sure that you have a super admin access.
Go to the Global Configurations → SSO Login Services and click any SSO Provider of your choice.
In the URL field, enter the valid Devtron application URL where it is hosted.
For providing redirectURI or callbackURI registered with the SSO provider, you can either select Configuration or Sample Script.
Provide the client ID and client Secret of your SSO provider (e.g. If you select Google as SSO provider, then you must enter $GOOGLE_CLIENT_ID and $GOOGLE_CLIENT_SECRET in the client ID and client Secret respectively.)
Select Save to create and activate SSO Login Service.
Note:
Only single SSO login configuration can be active at one time. Whenever you create or update any SSO configuration, it will be activated and used by Devtron and previous configurations will be deleted.
Except for the domain substring, URL and redirectURI remains same.
You can change SSO configuration anytime by updating the configuration and click Update. Note: In case of configuration change, all users will be logged out of Devtron and will have to login again.
type : Any platform name such as (Google, GitLab, GitHub etc.)
name : Identity provider platform name
id : Identity provider platform which is a unique ID in string. (Refer to dexidp.io
config : User can put connector details for this key. Platforms may not have same structure but common configurations are clientID, clientSecret, redirectURI.
hostedDomains : Domains authorized for SSO login.
After configuring an SSO for authentication, you need to add users in Devtron, else your users won't be able to log in via SSO.
In case you have enabled auto-assign permissions in Microsoft or LDAP, relevant permission groups must also exist in Devtron for a successful login.
The 'GitOps Configuration' page appears only if the super-admin has enabled 'Allow changing git repository for application' in Global Configurations → GitOps.
This configuration is an extension of the GitOps settings present in Global Configurations of Devtron. Therefore, make sure you read it before making any changes to your app configuration.
The application-level GitOps configuration offers the flexibility to add a custom Git repo (as opposed to Devtron auto-creating a repo for your application).
Users need to have Admin permission or above (along with access to the environment and application) to configure user-defined Git repo.
Go to Applications → Devtron Apps (tab) → (choose your app) → App Configuration (tab) → GitOps Configuration.
Assuming a GitOps repo was not added to your application earlier, you get 2 options:
Auto-create repository - Select this option if you wish to proceed with the default behavior. It will create a repository automatically, named after your application with a prefix. Thus saving you the trouble of creating one manually.
Commit manifests to a desired repository - Select this option if you wish to add a custom repo that is already created with your Git provider. Enter its link in the Git Repo URL field.
GitOps repositories, whether auto-created by Devtron or added manually, are immutable. This means they cannot be modified after creation. The same is true if you have an existing CD pipeline that uses/used GitOps for deployment.
Click Save.
Note: In case you skipped the GitOps configuration for your application and proceeded towards the creation of a new CD pipeline(that uses GitOps), you will be prompted to configure GitOps as shown below:
You can deploy a helm chart using either Helm or GitOps. Let's assume you wish to deploy airflow chart.
Select the helm chart from the Chart Store.
Click Configure & Deploy.
After you enter the App Name, Project, and Environment; an option to choose the deployment approach (i.e., Helm or GitOps) would appear.
Select GitOps.
A modal window will appear for you to enter a Git repository. Just like Devtron Apps (step 2), you get two options:
Auto-create repository
Commit manifests to a desired repository
Enter your custom Git Repo URL, and click Save.
Next, you may proceed to deploy the chart.
Once you deploy a helm app with GitOps, you cannot change its GitOps repo.
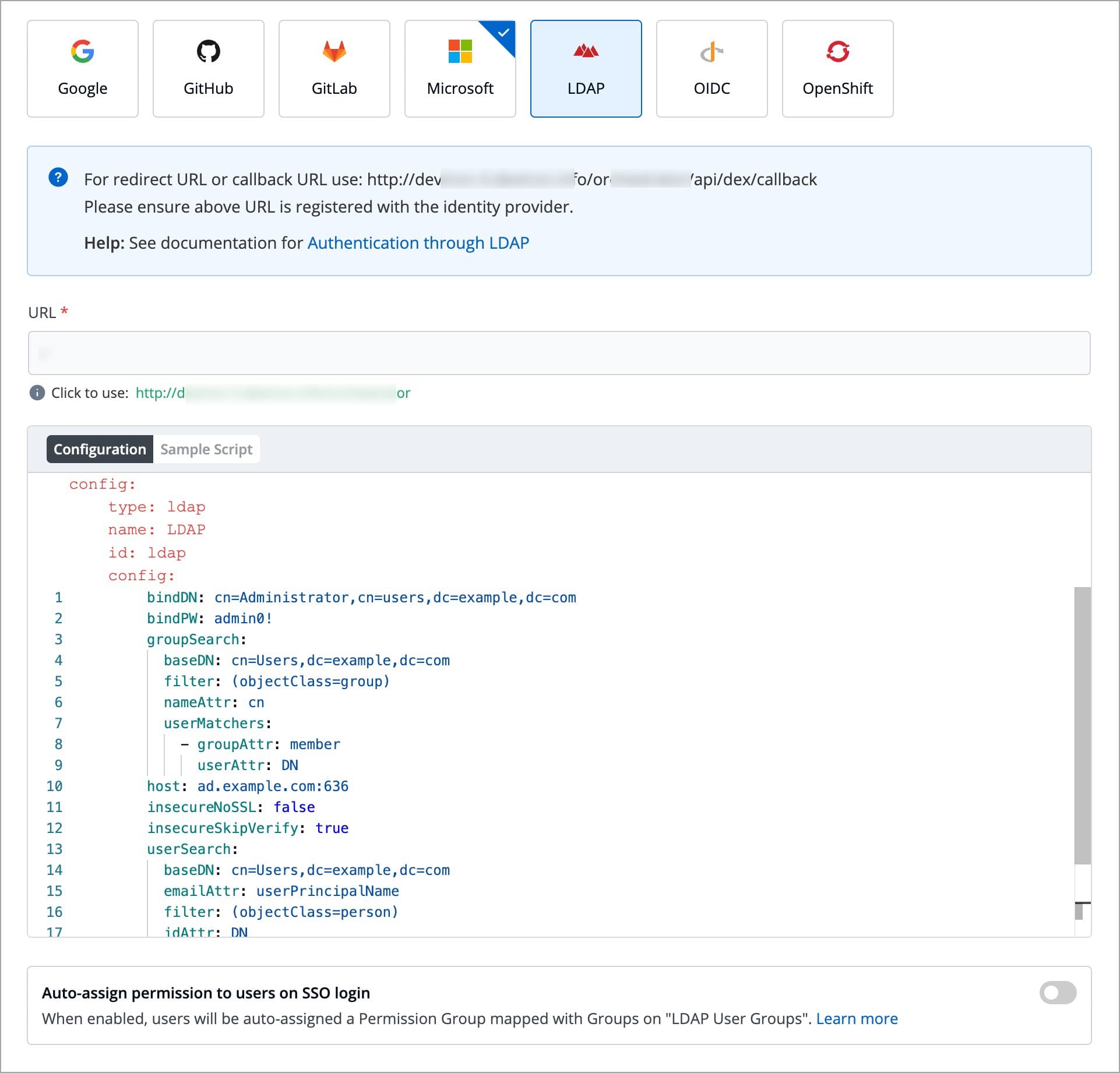
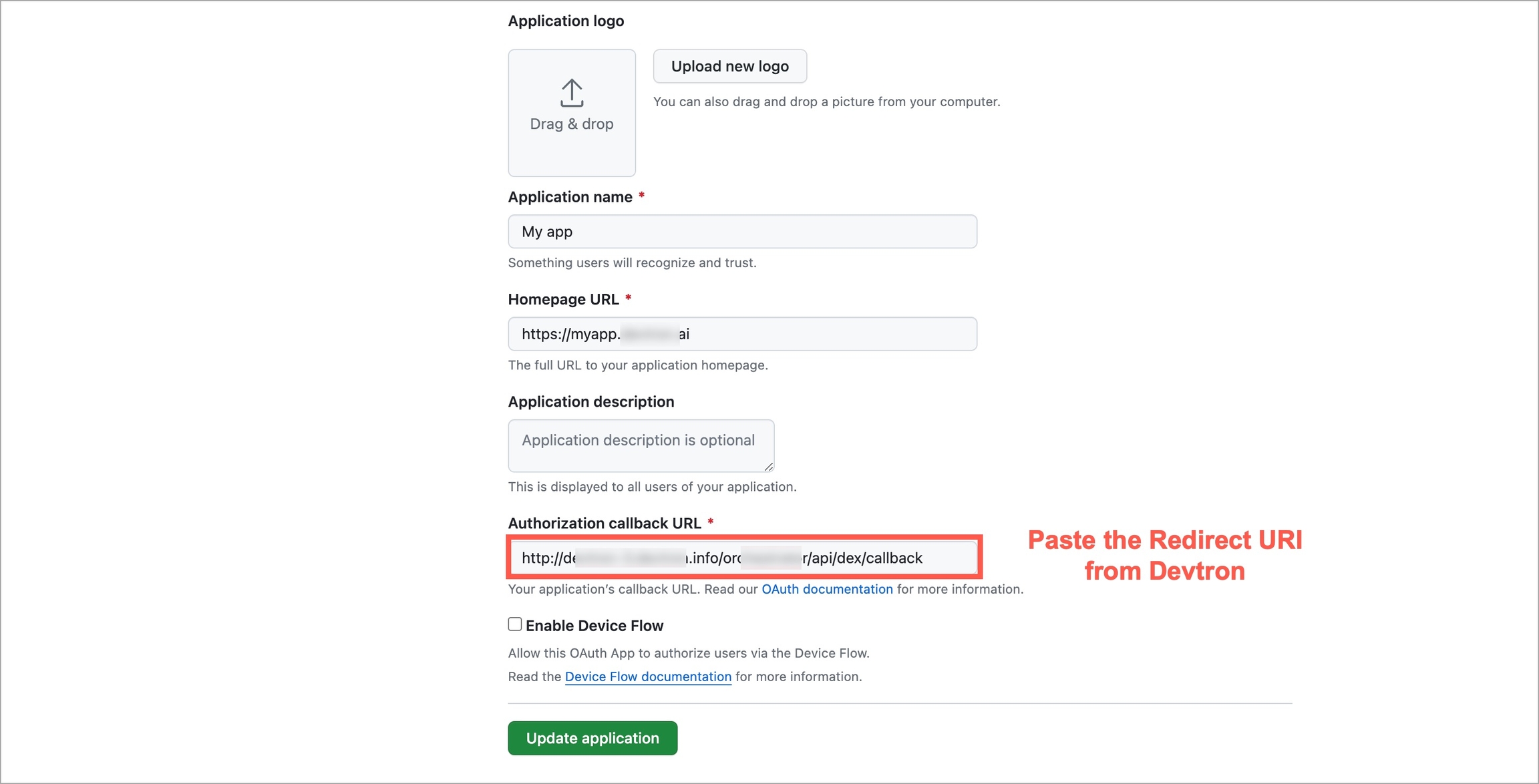
In this section, we describe the steps in detail on how you can install Devtron with CI/CD integration.
Install , if you have not installed it already.
Run the following command to install the latest version of Devtron along with the CI/CD module:
To install Devtron on clusters with the multi-architecture nodes (ARM and AMD), append the Devtron installation command with --set installer.arch=multi-arch.
Configuring Blob Storage in your Devtron environment allows you to store build logs and cache. In case, if you do not configure the Blob Storage, then:
You will not be able to access the build and deployment logs after an hour.
Build time for commit hash takes longer as cache is not available.
Artifact reports cannot be generated in pre/post build and deployment stages.
Choose one of the options to configure blob storage:
Run the following command to install Devtron along with MinIO for storing logs and cache.
Note: Unlike global cloud providers such as AWS S3 Bucket, Azure Blob Storage and Google Cloud Storage, MinIO can be hosted locally also.
Refer to the AWS specific parameters on the page.
Run the following command to install Devtron along with AWS S3 buckets for storing build logs and cache:
Install using S3 IAM policy.
Note: Please ensure that S3 permission policy to the IAM role attached to the nodes of the cluster if you are using below command.
Install using access-key and secret-key for AWS S3 authentication:
Install using S3 compatible storages:
Refer to the Azure specific parameters on the page.
Run the following command to install Devtron along with Azure Blob Storage for storing build logs and cache:
Refer to the Google Cloud specific parameters on the page.
Run the following command to install Devtron along with Google Cloud Storage for storing build logs and cache:
Run the following command to check the status of the installation:
The command executes with one of the following output messages, indicating the status of the installation:
Run the following command to check the installer logs:
Run the following command to get the Devtron dashboard URL:
You will get an output similar to the example shown below:
Use the hostname aaff16e9760594a92afa0140dbfd99f7-305259315.us-east-1.elb.amazonaws.com (Loadbalancer URL) to access the Devtron dashboard.
When you install Devtron for the first time, it creates a default admin user and password (with unrestricted access to Devtron). You can use that credentials to log in as an administrator.
After the initial login, we recommend you set up any SSO service like Google, GitHub, etc., and then add other users (including yourself). Subsequently, all the users can use the same SSO (let's say, GitHub) to log in to Devtron's dashboard.
The sections below will help you understand the process of getting the administrator password.
Username: admin
Password: Run the following command to get the admin password:
If you want to uninstall Devtron or clean Devtron helm installer, refer our .
Related to installaltion, please also refer section also.
The Kubernetes client by Devtron is a very lightweight dashboard that can be installed on arm64/amd64-based architectures. It comes with the features such as Kubernetes Resources Browser and Cluster Management that can provide control and observability for resources across clouds and clusters.
Devtron Kubernetes client is an intuitive Kubernetes Dashboard or a command line utility installed outside a Kubernetes cluster. The client can be installed on a desktop running on any Operating Systems and interact with all your Kubernetes clusters and workloads through an API server. It is a binary, packaged in a bash script that you can download and install by using the following set of commands.
By installing Devtron Kubernetes Client, you can access:
Managing Kubernetes Resources at scale: Clusters vary on business and architectural needs. Organizations tend to build smaller clusters for more decentralization. This practice leads to the creation of multiple clusters and more nodes. Managing them on a CLI requires multiple files, making it difficult to perform resource operations. But with the Devtron Kubernetes Client, you can gain more visibility into K8s resources easily.
Unifying information in one place: When information is scattered across clusters, and you have to type commands with arguments to fetch desired output, the process becomes slow and error-prone. Without a single point of configuration source, the configurations of different config. files diverge, making them even more challenging to restore and track. The Devtron Kubernetes Client unifies all the information and tools into one interface to perform various contextual tasks.
Accessibility during an outage for troubleshooting: As the Devtron Kubernetes Client runs outside a cluster, you can exercise basic control over their failed resources when there is a cluster-level outage. The Client helps to gather essential logs and data to pinpoint the root cause of the issue and reduce the time to restore service.
Avoiding Kubeconfig version mismatch errors: With the Devtron Kubernetes Client, you can be relieved from maintaining the Kubeconfig versions for the respective clusters (v1.16 - 1.26 i.e, current version) as the Devtron Kubernetes Client performs self kubeconfig version control. Instead of managing multiple kubectl versions manually, it eliminates the chances of errors occurring due to the mismatch in configuration.
Download the bash script using the below URL: https://cdn.devtron.ai/k8s-client/devtron-install.bash
To automatically download the executable file and to open the dashboard in the respective browser, run the following command:
Note: Make sure you place Devtron-install.bash in your current directory before you execute the command.
Devtron Kubernetes Client opens in your browser automatically.
You must add your cluster to make your cluster visible on the Kubernetes Resource Browser and Clusters section. To add a cluster, go to the Global Configurations and click Add Cluster. .
Note: You do not need to have a super admin permission to add a cluster if you install Devtron Kubernetes Client. You can add more than one cluster.
Kubernetes Resource Browser provides a graphical user interface for interacting and managing all your Kubernetes (k8s) resources across clusters. It also helps you to deploy and manage Kubernetes resources and allows pod operations such as:
View real-time logs
Check manifest and edit live manifests of k8s resources
Executable via terminal
View Events
Or, delete a resource
With Kubernetes Resource browser, you can also perform the following:
Check the real-time health status
Search for any workloads
Manage multiple clusters and change cluster contexts
Deploy multiple K8s manifests through Create UI option.
Perform resource grouping at the cluster level.
After your cluster is added via Global Configurations, go to the Kubernetes Resource Browser page and select your cluster. .
Note: You do not need to have a super admin permission to access Kubernetes Resource Browser if you install Devtron Kubernetes Client.
With the Devtron Kubernetes Client, you can manage all your clusters running on-premises or on a cloud. It is a cluster and cloud agnostic platform where you can add as many clusters as you want, be it a lightweight cluster such as k3s/ microk8s or cloud managed clusters like Amazon EKS.
It enables you to observe and monitor the cluster health and real-time node conditions. The Cluster management feature provides a summary of nodes with all available labels, annotations, taints, and other parameters such as resource usage. In addition to that, it helps you to perform node operations such as:
Debug a node
Cordon a node
Drain a node
Taint a node
Edit a node config
Delete a node
With its rich features and intuitive interface, you can easily manage and and use any CLI debugging tools like busybox, kubectl, netshoot or any custom CLI tools like k9s.
After your cluster is added via Global Configurations, go to the Clusters page and search or select your cluster. .
In case if you close the browser by mistake, you can open the dashboard by executing the following command. It will open the dashboard through a port in the available web browser and store the Kubernetes client's state.
To stop the dashboard, you can execute the following command:
To update the Devtron Kubernetes Client, use the following command. It will stop the running dashboard and download the latest executable file and open it in the browser.
You can add your existing Kubernetes clusters and environments on the Clusters and Environments section. You must have a access to add a cluster.
To add cluster, go to the Clusters & Environments section of Global Configurations. Click Add cluster.
To add a Kubernetes cluster on Devtron using server url and the bearer token, provide the information in the following fields:
Prerequisites:
kubectlmust be installed on the bastion.
Note: We recommend to use a self-hosted URL instead of cloud hosted URL. Refer the benefits of .
You can get the Server URL & Bearer Token by running the following command depending on the cluster provider:
If you are using EKS, AKS, GKE, Kops, Digital Ocean managed Kubernetes, run the following command to generate the server URL and bearer token:
If you are using a microk8s cluster, run the following command to generate the server URL and bearer token:
Disaster Recovery:
It is not possible to edit the server URL of a cloud specific provider. If you're using an EKS URL (e.g. *****.eu-west-1.elb.amazonaws.com), it will be a tedious task to add a new cluster and migrate all the services one by one.
But in case of using a self-hosted URL (e.g. clear.example.com), you can just point to the new cluster's server URL in DNS manager and update the new cluster token and sync all the deployments.
Easy Cluster Migrations:
In case of managed Kubernetes clusters (like EKS, AKS, GKE etc) which is a cloud provider specific, migrating your cluster from one provider to another will result in waste of time and effort.
On the other hand, migration for a self-hosted URL is easy as the URL is of single hosted domain independent of the cloud provider.
To add clusters using kubeconfig, follow these steps:
First, navigate to the global configurations menu, and then go to "clusters and environment" section.
Click on the Add cluster button. In the options provided, choose the From kubeconfig option.
Next, either paste the kubeconfig file or browse for it and select the appropriate file.
Afterward, click on the Get cluster button. This action will display the cluster details alongside the kubeconfig.
Select the desired cluster and click on Save to successfully add the cluster to Devtron.
Note: Please ensure that the kubeconfig file you use has admin permissions. It is crucial for Devtron to have the necessary administrative privileges; otherwise, it may encounter failures or disruptions during deployments and other operations. Admin permission is essential to ensure the smooth functioning of Devtron and to prevent any potential issues that may arise due to insufficient privileges.
If you want to see application metrics against the applications deployed in the cluster, Prometheus must be deployed in the cluster. Prometheus is a powerful tool to provide graphical insight into your application behavior.
Note: Make sure that you install
Monitoring (Grafana)from theDevtron Stack Managerto configure prometheus. If you do not installMonitoring (Grafana), then the option to configure prometheus will not be available.
Enable the application metrics to configure prometheus and provide the information in the following fields:
Now, click Save Cluster to save your cluster on Devtron.
Your Kubernetes cluster gets mapped with Devtron when you save the cluster configurations. Now, the Devtron agent must be installed on the added cluster so that you can deploy your applications on that cluster.
When the Devtron agent starts installing, click Details to check the installation status.
A new window pops up displaying all the details about the Devtron agent.
Once you have added your cluster in the Clusters & Environments, you can add the environment by clicking Add environment.
A new environment window pops up.
Click Save and your environment will be created.
You can also update an environment by clicking the environment.
You can change Production and Non-Production options only.
You cannot change the Environment Name and Namespace Name.
Make sure to click Update to update your environment.
The you create in Devtron for managing the CI-CD of your application can be made flexible or restricting with the help of CD filter conditions, for e.g., not all events (such as image builds) generated during the CI stage require progression to the CD stage. Therefore, instead of creating multiple workflows that cater to complex requirements, Devtron provides you the option of defining filters to tailor your workflow according to your specific needs.
Using filter conditions, you can control the progression of events. Here are a few general examples:
Images containing the label "test" should not be eligible for deployment in production environment
Only images having tag versions greater than v0.7.4 should be eligible for deployment
Images hosted on Docker Hub should be eligible but not the rest
From the left sidebar, go to Global Configurations → Filter Condition.
Add a filter condition.
In the Define Filter condition section, you get the following fields:
Filter For: Choose the pipeline upon which the filter should apply. Currently, you can use filter conditions for CD pipelines only. Support for CI pipelines is underway.
Filter Name: Give a name to the filter.
Description: (Optional) Add a description to the filter, preferably explaining what it does.
Filter Condition: You can specify either a pass condition, fail condition, or both the conditions:
Pass Condition: Events that satisfy the pass condition are eligible to trigger your CD pipeline.
Fail Condition: Events that satisfy the fail condition are not eligible to trigger your CD pipeline.
Use CEL Expression: You can use Common Expression Language (CEL) to define the conditions. Currently, you can create conditions with the help of following variables:
containerImage: Package that contains all the necessary files and instructions to run an application in a container, e.g., gcr.io/k8s-minikube/kicbase:v0.0.39. It returns a string value in the following format: <registry>/<repository>:<tag>
containerRepository: Storage location for container images, e.g., kicbase
containerImageTag: Versioning of image to indicate its release, e.g., v0.0.39
imageLabels: The label(s) you assign to an image in the CD pipeline, e.g., ["PROD","Stage"]. It returns an array of strings.
Click View filter criteria to check the supported criteria. You get a copy button and a description of each criterion upon hovering. Moreover, you can go to CEL expression to learn more about the rules and supported syntax. Check to know more.
Click Next.
In the Apply to section, you get the following fields:
Application: Choose one or more applications to which your filter condition must apply.
Environment: Choose one or more environments to which your filter condition must apply.
Click Save. You have successfully created a filter.
Here's a sample pipeline we will be using for our explanation of and .
Consider a scenario where you wish to make an image eligible for deployment only if its tag version is greater than v0.0.7
The CEL Expression should be containerImageTag > "v0.0.7"
Go to the Build & Deploy tab. The filter condition was created specifically for test environment, therefore the filter condition would be evaluated only at the relevant CD pipeline, i.e., test
Click Select Image for the test CD pipeline. The first tab Eligible images shows the list and count of images that have satisfied the pass condition since their tag versions were greater than v0.0.7. Hence, they are marked eligible for deployment.
The second tab Latest images shows the latest builds (up to 10 images) irrespective of whether they have satisfied the filter condition(s) or not. The ones that have not satisfied the filter conditions get marked as Excluded. In other words, they are not eligible for deployment.
Clicking the filter icon at the top-left shows the filter condition(s) applied to the test CD pipeline.
Consider a scenario where you wish to exclude an image from deployment if its tag starts with the word trial or ends with the word testing
The CEL Expression should be containerImageTag.startsWith("trial") || containerImageTag.endsWith("testing")
Go to the Build & Deploy tab. The filter condition was created specifically for devtron-demo environment, therefore the filter condition would be evaluated only at the relevant CD pipeline, i.e., devtron-demo
Click Select Image for the devtron-demo CD pipeline. The first tab Eligible images shows the list and count of images that have not met the fail condition. Hence, they are marked eligible for deployment.
The second tab Latest images shows the latest builds (up to 10 images) irrespective of whether they have satisfied the filter condition(s) or not. The ones that have satisfied the filter conditions get marked as Excluded. In other words, they are not eligible for deployment.
Clicking the filter icon at the top-left shows the filter condition(s) applied to the devtron-demo CD pipeline.
This chart deploys Job & CronJob. A Job is a controller object that represents a finite task and CronJob is used to schedule the creation of Jobs.
A Job creates one or more Pods and will continue to retry execution of the Pods until a specified number of them successfully terminate. As pods successfully complete, the Job tracks the successful completions. When a specified number of successful completions is reached, the task (ie, Job) is complete. Deleting a Job will clean up the Pods it created. Suspeding a Job will delete its active Pods until the Job is resumed again.
A CronJob creates jobs on a repeating schedule. One Cronjob object is like one line of a crontab (cron table) file. It runs a job periodically on a given schedule, written in Cron format. CronJobs are meant for performing regular scheduled actions such as backups, report generation, and so on. Each task must be configured to recur indefinitely (as an example: once a day / week / month). You can schedule the time within that interval when the job should start.
Super-admins can lock keys in Job & CronJob deployment template to prevent non-super-admins from modifying those locked keys. Refer to know more.
After the is complete, you can trigger the CD pipeline.
Go to the Build & Deploy tab of your application and click Select Image in the CD pipeline.
Select an image to deploy and then click Deploy to trigger the CD pipeline.
However, if an image is already deployed, you can identify it by the tag Active on <Environment name>.
When for the deployment pipeline configured in the workflow, you are expected to request for an image approval before each deployment. Alternatively, you can deploy images that have already been approved once.
If no approved images are available or the current image is already deployed, you won't see any images for deployment when clicking Select Image.
Users need to have or above (along with access to the environment and application) to request for an image approval.
To request an image approval, follow these steps:
Navigate to the Build & Deploy page, and click the Approval for deployment icon.
Click the Request Approval button present on the image for which you want to request an approval and click Submit Request.
In case you have configured , you can directly choose the approver(s) from the list of approvers as shown below.
The users you selected will receive an approval request via email. Any user with 'Image approver' permission alongwith access to the given application and given environment would be able to approve the image.
In case you wish to cancel the image approval request, you can do so from the Approval pending tab as shown in the below image.
If you've received an approval but no longer want the image to be deployable, you can let the approval expire.
By default, super-admin users are considered as the default approvers. Users who build the image and/or request for its approval, cannot self-approve it even if they have super-admin privileges.
Users with Approver permission (for the specific application and environment) can also approve a deployment. This permission can be granted to users from present in .
In case or was configured in Devtron, and the user chose the approvers while raising an image approval request, the approvers would receive an email notification as shown below:
To approve an image approval request, follow these steps:
Go to the Build & Deploy page and click the Approval for deployment button.
Switch to the Approval pending tab. Here, you will get a list of images that are awaiting approval.
Click Approve followed by Approve Request button.
Users need to have or above (along with access to the respective environment and application) to select and deploy an approved image.
In case the super-admin has set the minimum number of approval to more than 1 (in ), you must wait for all approvals before deploying the image. In other words, partially approved image will not be eligible for deployment.
To deploy an approved image, follow these steps:
Navigate to the Build & Deploy tab and click Select Image.
You will find all the approved images listed under the Approved images section. From the list, you can select the desired image and deploy it to your environment.
You can view the status of current deployment in the App Details tab.
The status initially appears as Progressing for approximately 1-2 minutes, and then gradually transitions to Healthy state based on the deployment strategy.
Here, our CD pipeline trigger was successful and the deployment is in Healthy state.
To further diagnose the deployments,
The Overview section contains the brief information of the application, any added tags, configured external links and deployment details of the particular application. In this section, you can also and if you added them while creating application.
The following details are provided on the Overview page:
You can change the project of your application by clicking Project on the Overview section.
Click Project.
On the Change project dialog box, select the different project you want to change from the drop-down list.
Click Save. The application will be moved to the selected project.
The current users will lose the access to the application.
The users who already have an access to the selected project, will get an access to the application automatically.
Tags are key-value pairs. You can add one or multiple tags in your application. When tags are propagated, they are considered as labels to Kubernetes resources. Kubernetes offers integrated support for using these labels to query objects and perform bulk operations e.g., consolidated billing using labels. You can use these tags to filter/identify resources via CLI or in other Kubernetes tools.
Manage tags is the central place where you can create, edit, and delete tags. You can also propagate tags as labels to Kubernetes resources for the application.
Click Edit.
On the Manage tags page, click + Add tag to add a new tag.
Click X to delete a tag.
Click the symbol on the left side of your tag to propagate a tag.
To remove the tags from propagation, click the symbol again.
Click Save.
The changes in the tags will be reflected in the Tags on the Overview section.
A PersistentVolumeClaim (PVC) volume is a request for storage, which is used to mount a PersistentVolume (PV) into a Pod. In order to optimize build time, you can configure PVC in your application.
If you want to optimize build time for the multiple target platforms (e.g., arm64, amd64), mounting a PVC will provide volume directly to a pod which helps in shorter build time by storing build cache. Mounting a PVC into a pod will provide storage for build cache which will not impact the normal build where the image is built on the basis of architecture and operating system of the K8s node on which CI is running.
The following configuration file describes persistent volume claim e.g.,cache-pvc.yaml, where you have to define the metadata name and storageClassname.
Create the PersistentVolumeClaim by running the following command:
For more detail, refer .
In order to configure PVC:
Go to the Overview section of your application.
On the right-corner, click Edit.
For app level PVC mounting, enter the following:
key:devtron.ai/ci-pvc-all
value: metadata name (e.g., cache-pvc) which you define on the .
Note: This PVC mounting will impact all the build pipelines of the application.
For pipeline level, enter the following:
key:devtron.ai/ci-pvc-{pipelinename}
value: metadata name which you define on the .
Note: This PVC mounting will impact only the particular build pipeline.
To know the pipelinename detail, go to the App Configuration, click Workflow Editor the pipeline name will be on the Build pipeline as shown below.
Click Save.
To trigger the CI pipeline, first you need to select a Git commit. To select a Git commit, click the Select Material button present on the CI pipeline.
Once clicked, a list will appear showing various commits made in the repository, it includes details such as the author name, commit date, time, etc. Choose the desired commit for which you want to trigger the pipeline, and then click Start Build to initiate the CI pipeline.
CI Pipelines with automatic trigger enabled are triggered immediately when a new commit is made to the git branch. If the trigger for a build pipeline is set to manual, it will not be automatically triggered and requires a manual trigger.
CI builds can be time-consuming for large repositories, especially for enterprises. However, Devtron's partial cloning feature significantly increases cloning speed, reducing the time it takes to clone your source code and leading to faster build times.
Advantages
Smaller image sizes
Reduced resource usage and costs
Faster software releases
Improved productivity
Get in touch with us if you are looking for a way to improve the efficiency of your software development process.
The Refresh icon updates the Git Commits section in the CI Pipeline by fetching the latest commits from the repository. Clicking on the refresh icon ensures that you have the most recent commit available.
The Ignore Cache option ignores the previous build cache and creates a fresh build. If selected, will take a longer build time than usual.
Users need to have or above (along with access to the environment and application) to pass build parameters.
If you wish to pass runtime parameters for a build job, you can provide key-value pairs before triggering the build. Thereafter, you can access those passed values by referencing the corresponding keys in the environment variable dictionary.
Steps
Go to the Parameters tab available on the screen where you select the commit.
Click + Add parameter.
Enter your key-value pair as shown below.
Similarly, you may add more than one key-value pair by using the + Add Parameter button.
Click Start Build.
Click the CI Pipeline or navigate to the Build History to get the CI pipeline details such as build logs, source code details, artifacts, and vulnerability scan reports.
To access the logs of the CI Pipeline, simply click Logs.
To view specific details of the Git commit you've selected for the build, click on Source. This will provide you with information like the commit ID, author, and commit message associated with that particular commit.
By selecting the Artifacts option, you can download reports related to the tasks performed in the Pre-CI and Post-CI stages. This will allow you to access and retrieve the generated reports, if any, related to these stages. Additionally, you have the option to add tags or comments to the image directly from this section.
To check for any vulnerabilities in the build image, click on Security. Please note that vulnerabilities will only be visible if you have enabled the Scan for vulnerabilities option in the advanced options of the CI pipeline before building the image. For more information about this feature, please refer to this .
Since resources are created according to the configurations you enter, it's essential to restrict such configurations from direct modifications. For critical environments like production, it becomes necessary to introduce an approval flow for any edits made to the configuration files.
In Devtron, these configurations are present in the App Configuration tab of your application.
Any changes made to the following configurations will require approval if enabled:
Deployment Template
ConfigMaps
Secrets
This stands true for both: base configuration and respective environment-level configuration.
Let's assume you are the application admin and you wish to edit the deployment template of your environment (as an override).
Go to the App Configuration tab.
In Environment Overrides → (choose your environment) → Deployment Template
You can change the value of a key to a desired value as shown below. Once done, click the Save Changes… button.
If the configuration is protected, your changes won't be published right away. You can do either of the following:
Save as draft : Selecting this option will save your file as a draft. You and other users can view and edit the saved draft and propose it further for approval.
Save & Propose Changes : Selecting this option will propose your changes to a configuration approver for a review.
Since we are proposing the changes immediately, click Propose Changes.
You can also view the approver(s) if you wish.
Only one draft can exist at time and you cannot create multiple drafts. In the top-right corner, you have the option to discard the draft if you don't wish to proceed with the edits you made.
Go to the edited configuration file to review and approve the changes as shown below.
A super-admin can check whether a user has approval rights by going to Global Configurations → Authorization (dropdown) → User Permissions.
Once the approver validates and approves your configuration changes, you can proceed to deploy your application with the updated configuration.
Go to the Build & Deploy tab of your application.
Click Select Image in the deployment flow.
You can view an indicator at the bottom Config Diff from Last Deployed. Click Review to view the changes.
Once you have verified the changes, you can click Deploy.
Go to the App Configuration tab.
Click Protect Configuration.
Use the toggle button to enable the protection for the configuration of your choice (base/environment level). A protection badge would appear next to the chosen configuration.
Alternatively, unprotecting the configuration will lead to the discarding of unapproved drafts (if any).
In the Workflow Editor section, you can configure a job pipeline to be executed. Pipelines can be configured to be triggered automatically or manually based on code change or time.
After adding Git repo in the Source Code section, go to the Workflow Editor.
Click Job Pipeline.
Provide the information in the following fields on the Create job pipeline page:
Click Create Pipeline.
The job pipeline is created.
To trigger job pipeline, go to the section.
Note: You can create more than one job pipeline by clicking + Job Pipeline.
The Source type - "Branch Fixed" allows you to trigger a CI build whenever there is a code change on the specified branch.
Select the Source type as "Branch Fixed" and enter the Branch Name.
Branch Regex allows users to easily switch between branches matching the configured Regex before triggering the build pipeline. In case of Branch Fixed, users cannot change the branch name in ci-pipeline unless they have admin access for the app. So, if users with Build and Deploy access should be allowed to switch branch name before triggering ci-pipeline, Branch Regex should be selected as source type by a user with Admin access.
For example if the user sets the Branch Regex as feature-*, then users can trigger from branches such as feature-1450, feature-hot-fix etc.
The Source type - "Pull Request" allows you to configure the CI Pipeline using the PR raised in your repository.
Before you begin, for either GitHub or Bitbucket.
The "Pull Request" source type feature only works for the host GitHub or Bitbucket cloud for now. To request support for a different Git host, please create a github issue .
To trigger the build from specific PRs, you can filter the PRs based on the following keys:
Select the appropriate filter and pass the matching condition as a regular expression (regex).
Devtron uses regexp library, view . You can test your custom regex from .
The Source type - "Tag Creation" allows you to build the CI pipeline from a tag.
Before you begin, for either GitHub or Bitbucket.
To trigger the build from specific tags, you can filter the tags based on the author and/or the tag name.
Select the appropriate filter and pass the matching condition as a regular expression (regex).
You can also add preset plugins in your job pipeline to execute some standard tasks, such as Code analysis, Load testing, Security scanning etc. Click Add Task to add .
You can update the configurations of an existing Job Pipeline except for the pipeline's name. To update a pipeline, select your job pipeline. In the Edit job pipeline window, edit the required fields and select Update Pipeline.
You can only delete a job pipeline in your workflow.
To delete a job pipeline, go to Configurations > Workflow Editor and select Delete Pipeline.
If the deployment of your application is not successful, then debugging needs to be done to check the cause of the error.
This can be done through App Details section which you can access in the following way:-
Applications->AppName->App Details
Over here, you can see the status of the app as Healthy. If there are some errors with deployment then the status would not be in a Healthy state.
Events of the application are accessible from the bottom left corner.
Events section displays you the events that took place during the deployment of an app. These events are available until 15 minutes of deployment of the application.
Logs contain the logs of the Pods and Containers deployed which you can use for the process of debugging.
The Manifest shows the critical information such as Container-image, restartCount, state, phase, podIP, startTime etc. and status of the pods deployed.
You might run into a situation where you need to delete Pods. You may need to bounce or restart a pod.
Deleting a Pod is not an irksome task, it can simply be deleted by Clicking on Delete Pod.
Suppose you want to setup a new environment, you can delete a pod and thereafter a new pod will be created automatically depending upon the replica count.
You can view Application Objects in this section of App Details, such as:
You can monitor the application in the App Details section.
Metrics like CPU Usage, Memory Usage, Throughput and Latency can be viewed here.
kind: Job
jobConfigs:
activeDeadlineSeconds: 120
backoffLimit: 6
completions: 1
parallelism: 1
suspend: false
ttlSecondsAfterFinished: 100activeDeadlineSeconds
Another way to terminate a Job is by setting an active deadline. Do this by setting the activeDeadlineSeconds field of the Job to a number of seconds. The activeDeadlineSeconds applies to the duration of the job, no matter how many Pods are created. Once a Job reaches activeDeadlineSeconds, all of its running Pods are terminated and the Job status will become type: Failed with reason: DeadlineExceeded.
backoffLimit
There are situations where you want to fail a Job after some amount of retries due to a logical error in configuration etc. To do so, set backoffLimit to specify the number of retries before considering a Job as failed. The back-off limit is set by default to 6. Failed Pods associated with the Job are recreated by the Job controller with an exponential back-off delay (10s, 20s, 40s ...) capped at six minutes. The back-off count is reset when a Job's Pod is deleted or successful without any other Pods for the Job failing around that time.
completions
Jobs with fixed completion count - that is , jobs that have non null completions - can have a completion mode that is specified in completionMode.
parallelism
The requested parallelism can be set to any non-negative value. If it is unspecified, it defaults to 1. If it is specified as 0, then the Job is effectively paused until it is increased.
suspend
The suspend field is also optional. If it is set to true, all subsequent executions are suspended. This setting does not apply to already started executions. Defaults to false.
ttlSecondsAfterFinished
The TTL controller only supports Jobs for now. A cluster operator can use this feature to clean up finished Jobs (either Complete or Failed) automatically by specifying the ttlSecondsAfterFinished field of a Job, as in this example. The TTL controller will assume that a resource is eligible to be cleaned up TTL seconds after the resource has finished, in other words, when the TTL has expired. When the TTL controller cleans up a resource, it will delete it cascadingly, that is to say it will delete its dependent objects together with it. Note that when the resource is deleted, its lifecycle guarantees, such as finalizers, will be honored.
kind
As with all other Kubernetes config, a Job and cronjob needs apiVersion, kind.cronjob and job also needs a section fields which is optional . these fields specify to deploy which job (conjob or job) should be kept. by default, they are set job.
kind: CronJob
cronjobConfigs:
concurrencyPolicy: Allow
failedJobsHistoryLimit: 1
restartPolicy: OnFailure
schedule: 32 8 * * *
startingDeadlineSeconds: 100
successfulJobsHistoryLimit: 3
suspend: falseconcurrencyPolicy
A CronJob is counted as missed if it has failed to be created at its scheduled time. For example, If concurrencyPolicy is set to Forbid and a CronJob was attempted to be scheduled when there was a previous schedule still running, then it would count as missed,Acceptable values: Allow / Forbid.
failedJobsHistoryLimit
The failedJobsHistoryLimit fields are optional. These fields specify how many completed and failed jobs should be kept. By default, they are set to 3 and 1 respectively. Setting a limit to 0 corresponds to keeping none of the corresponding kind of jobs after they finish.
restartPolicy
The spec of a Pod has a restartPolicy field with possible values Always, OnFailure, and Never. The default value is Always.The restartPolicy applies to all containers in the Pod. restartPolicy only refers to restarts of the containers by the kubelet on the same node. After containers in a Pod exit, the kubelet restarts them with an exponential back-off delay (10s, 20s, 40s, …), that is capped at five minutes. Once a container has executed for 10 minutes without any problems, the kubelet resets the restart backoff timer for that container, Acceptable values: Always / OnFailure / Never.
schedule
To generate Cronjob schedule expressions, you can also use web tools like https://crontab.guru/.
startingDeadlineSeconds
If startingDeadlineSeconds is set to a large value or left unset (the default) and if concurrencyPolicy is set to Allow, the jobs will always run at least once.
successfulJobsHistoryLimit
The successfulJobsHistoryLimit fields are optional. These fields specify how many completed and failed jobs should be kept. By default, they are set to 3 and 1 respectively. Setting a limit to 0 corresponds to keeping none of the corresponding kind of jobs after they finish.
suspend
The suspend field is also optional. If it is set to true, all subsequent executions are suspended. This setting does not apply to already started executions. Defaults to false.
kind
As with all other Kubernetes config, a Job and cronjob needs apiVersion, kind.cronjob and job also needs a section fields which is optional . these fields specify to deploy which job (conjob or job) should be kept. by default, they are set cronjob.
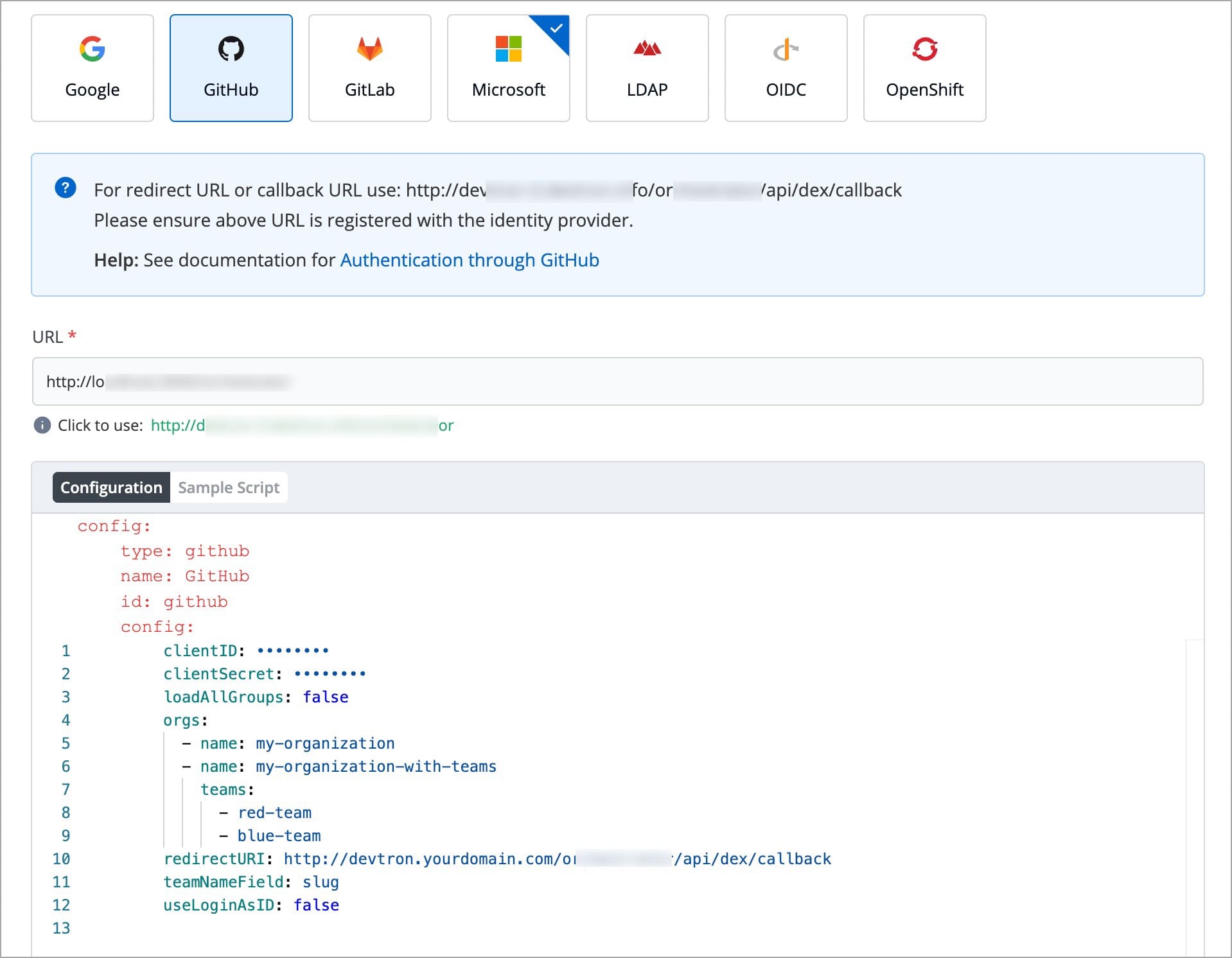
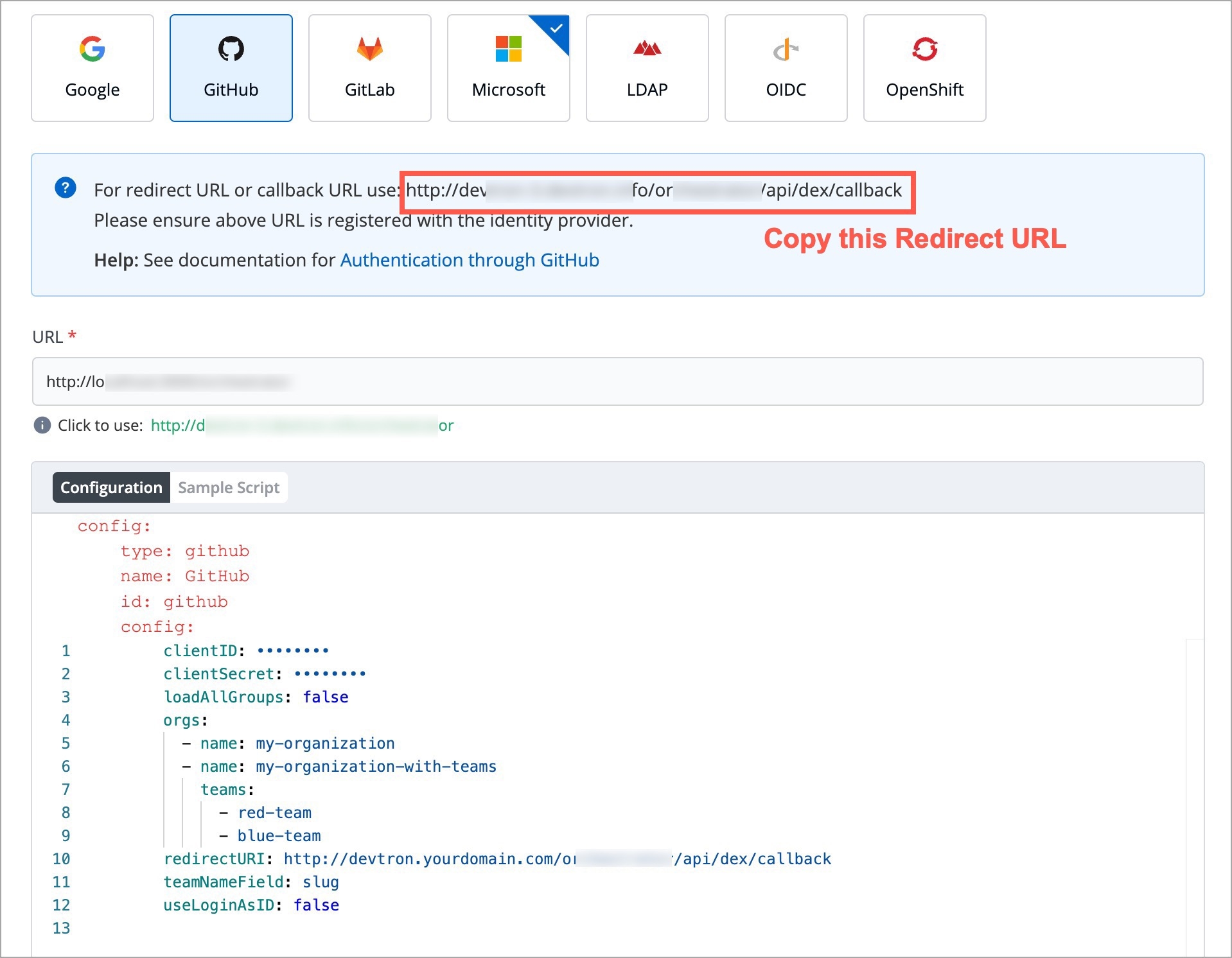
In certain cases, you may want to override default configurations provided by Devtron. For example, for deployments or statefulsets you may want to change the memory or CPU requests or limit or add node affinity or taint tolerance. Say, for ingress, you may want to add annotations or host. Samples are available inside the manifests/updates directory.
To modify a particular object, it looks in namespace devtroncd for the corresponding configmap as mentioned in the mapping below:
argocd
argocd-override-cm
GitOps
clair
clair-override-cm
container vulnerability db
clair
clair-config-override-cm
Clair configuration
dashboard
dashboard-override-cm
UI for Devtron
gitSensor
git-sensor-override-cm
microservice for Git interaction
guard
guard-override-cm
validating webhook to block images with security violations
postgresql
postgresql-override-cm
db store of Devtron
imageScanner
image-scanner-override-cm
image scanner for vulnerability
kubewatch
kubewatch-override-cm
watches changes in ci and cd running in different clusters
lens
lens-override-cm
deployment metrics analysis
natsOperator
nats-operator-override-cm
operator for nats
natsServer
nats-server-override-cm
nats server
natsStreaming
nats-streaming-override-cm
nats streaming server
notifier
notifier-override-cm
sends notification related to CI and CD
devtron
devtron-override-cm
core engine of Devtron
devtronIngress
devtron-ingress-override-cm
ingress configuration to expose Devtron
workflow
workflow-override-cm
component to run CI workload
externalSecret
external-secret-override-cm
manage secret through external stores like vault/AWS secret store
grafana
grafana-override-cm
Grafana config for dashboard
rollout
rollout-override-cm
manages blue-green and canary deployments
minio
minio-override-cm
default store for CI logs and image cache
minioStorage
minio-storage-override-cm
db config for minio
Let's take an example to understand how to override specific values. Say, you want to override annotations and host in the ingress, i.e., you want to change devtronIngress, copy the file devtron-ingress-override.yaml. This file contains a configmap to modify devtronIngress as mentioned above. Please note the structure of this configmap, data should have the key override with a multiline string as a value.
apiVersion, kind, metadata.name in the multiline string is used to match the object which needs to be modified. In this particular case it will look for apiVersion: extensions/v1beta1, kind: Ingress and metadata.name: devtron-ingress and will apply changes mentioned inside update: as per the example inside the metadata: it will add annotations owner: app1 and inside spec.rules.http.host it will add http://change-me.
In case you want to change multiple objects, for eg in argocd you want to change the config of argocd-dex-server as well as argocd-redis then follow the example in devtron-argocd-override.yaml.
Once we have made these changes in our local system we need to apply them to a Kubernetes cluster on which Devtron is installed currently using the below command:
kubectl apply -f file-name -n devtroncdRun the following command to make these changes take effect:
kubectl patch -n devtroncd installer installer-devtron --type='json' -p='[{"op": "add", "path": "/spec/reSync", "value": true }]'Our changes would have been propagated to Devtron after 20-30 minutes.
To use Devtron for production deployments, use our recommended production overrides located in manifests/updates/production. This configuration should be enough for handling up to 200 microservices.
The overall resources required for the recommended production overrides are:
cpu
6
memory
13GB
The production overrides can be applied as pre-devtron installation as well as post-devtron installation in the respective namespace.
If you want to install a new Devtron instance for production-ready deployments, this is the best option for you.
Create the namespace and apply the overrides files as stated above:
kubectl create ns devtroncdAfter files are applied, you are ready to install your Devtron instance with production-ready resources.
If you have an existing Devtron instance and want to migrate it for production-ready deployments, this is the right option for you.
In the existing namespace, apply the production overrides as we do it above.
kubectl apply -f prod-configs -n devtroncd
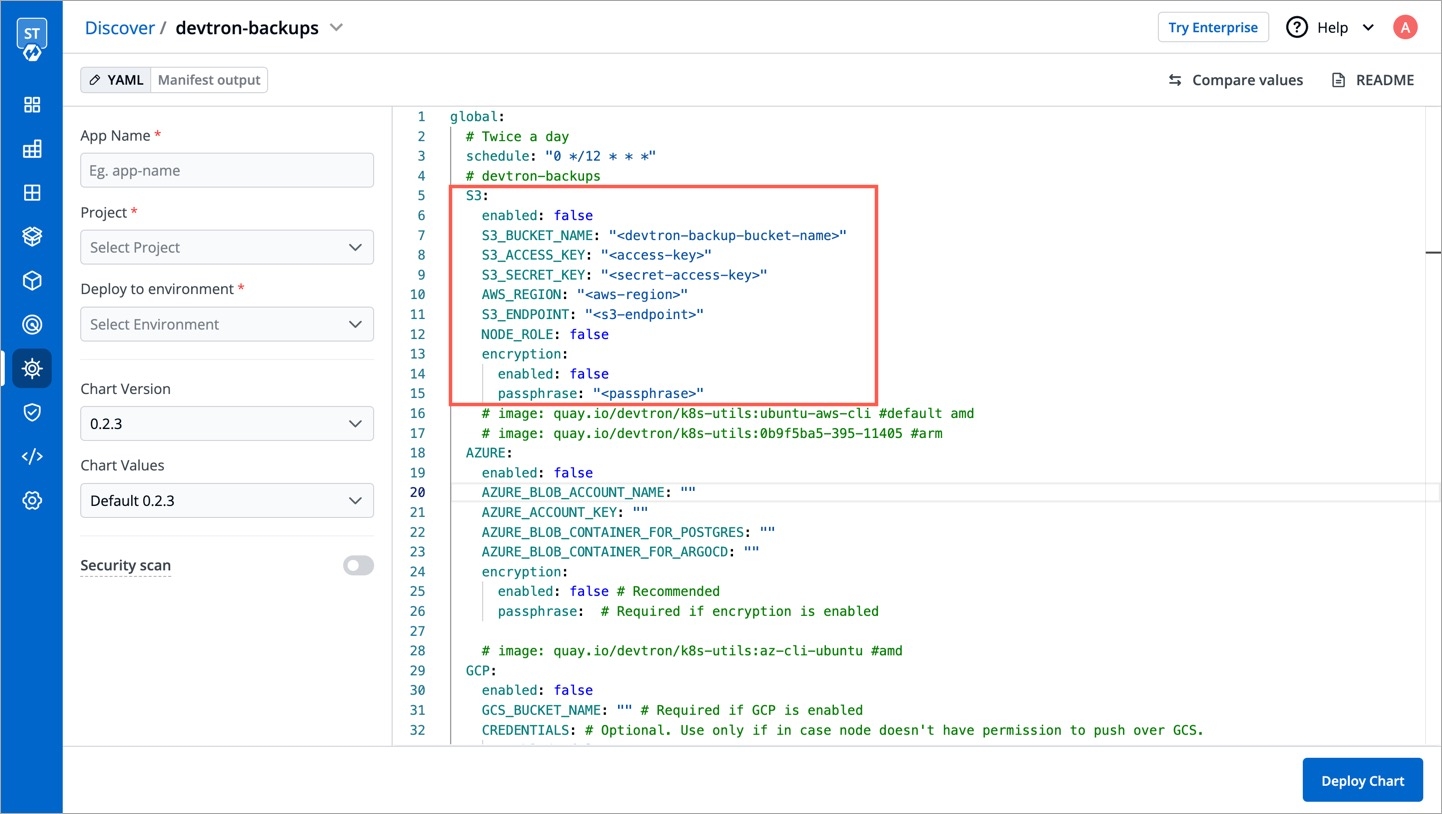
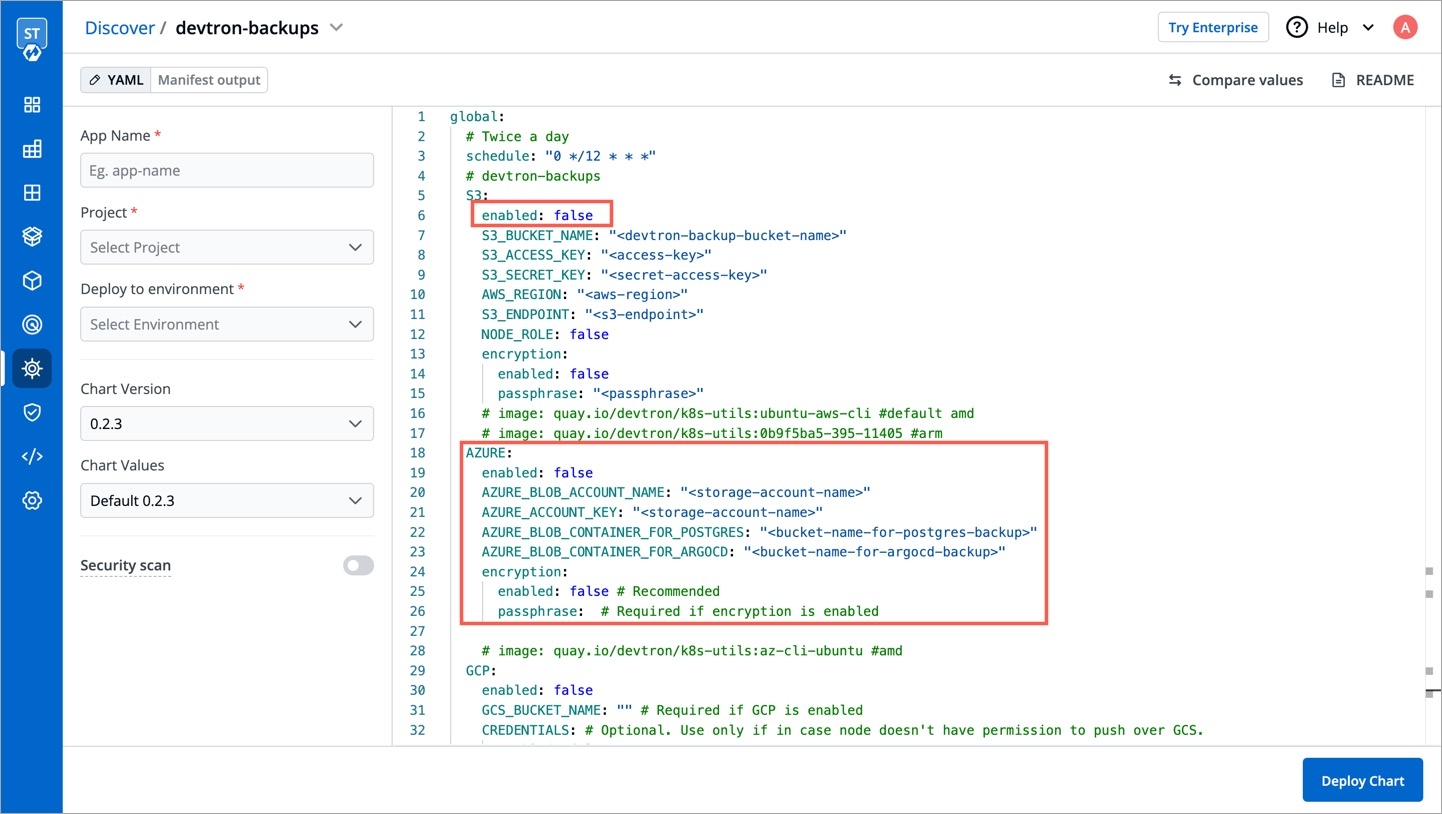
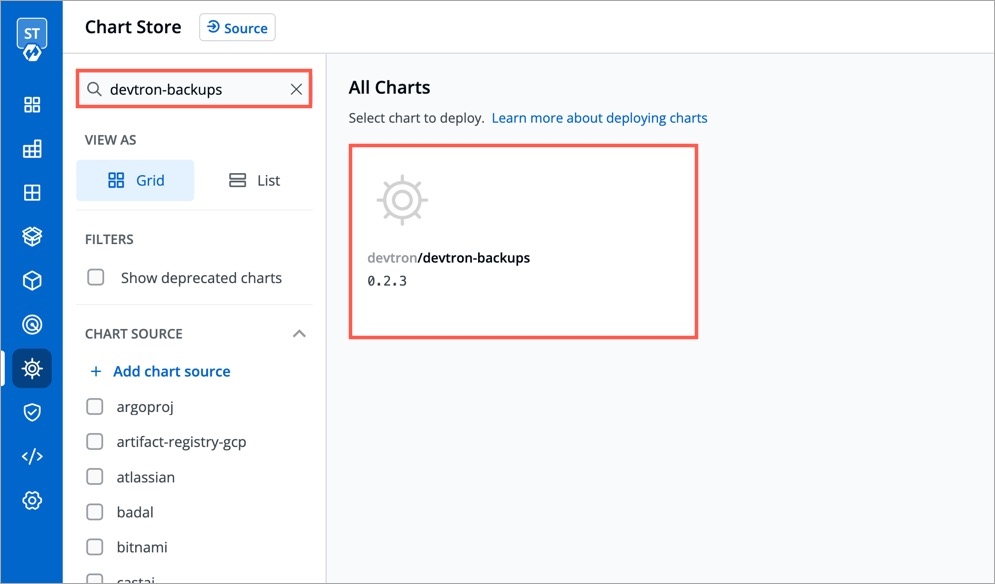
helm repo add aws-ebs-csi-driver \
https://kubernetes-sigs.github.io/aws-ebs-csi-driver \
helm repo update \
helm upgrade --install aws-ebs-csi-driver \
--namespace kube-system aws-ebs-csi-driver/aws-ebs-csi-driverhelm repo add devtron https://helm.devtron.ai
helm repo update devtron
helm install devtron devtron/devtron-operator \
--create-namespace --namespace devtroncd \
--set installer.modules={cicd}helm repo add devtron https://helm.devtron.ai
helm repo update devtron
helm install devtron devtron/devtron-operator \
--create-namespace --namespace devtroncd \
--set installer.modules={cicd} \
--set minio.enabled=truehelm repo add devtron https://helm.devtron.ai
helm repo update devtron
helm install devtron devtron/devtron-operator \
--create-namespace --namespace devtroncd \
--set installer.modules={cicd} \
--set configs.BLOB_STORAGE_PROVIDER=S3 \
--set configs.DEFAULT_CACHE_BUCKET=demo-s3-bucket \
--set configs.DEFAULT_CACHE_BUCKET_REGION=us-east-1 \
--set configs.DEFAULT_BUILD_LOGS_BUCKET=demo-s3-bucket \
--set configs.DEFAULT_CD_LOGS_BUCKET_REGION=us-east-1helm repo add devtron https://helm.devtron.ai
helm repo update devtron
helm install devtron devtron/devtron-operator \
--create-namespace --namespace devtroncd \
--set installer.modules={cicd} \
--set configs.BLOB_STORAGE_PROVIDER=S3 \
--set configs.DEFAULT_CACHE_BUCKET=demo-s3-bucket \
--set configs.DEFAULT_CACHE_BUCKET_REGION=us-east-1 \
--set configs.DEFAULT_BUILD_LOGS_BUCKET=demo-s3-bucket \
--set configs.DEFAULT_CD_LOGS_BUCKET_REGION=us-east-1 \
--set secrets.BLOB_STORAGE_S3_ACCESS_KEY=<access-key> \
--set secrets.BLOB_STORAGE_S3_SECRET_KEY=<secret-key>helm repo add devtron https://helm.devtron.ai
helm repo update devtron
helm install devtron devtron/devtron-operator \
--create-namespace --namespace devtroncd \
--set installer.modules={cicd} \
--set configs.BLOB_STORAGE_PROVIDER=S3 \
--set configs.DEFAULT_CACHE_BUCKET=demo-s3-bucket \
--set configs.DEFAULT_CACHE_BUCKET_REGION=us-east-1 \
--set configs.DEFAULT_BUILD_LOGS_BUCKET=demo-s3-bucket \
--set configs.DEFAULT_CD_LOGS_BUCKET_REGION=us-east-1 \
--set secrets.BLOB_STORAGE_S3_ACCESS_KEY=<access-key> \
--set secrets.BLOB_STORAGE_S3_SECRET_KEY=<secret-key> \
--set configs.BLOB_STORAGE_S3_ENDPOINT=<endpoint>helm repo add devtron https://helm.devtron.ai
helm repo update devtron
helm install devtron devtron/devtron-operator \
--create-namespace --namespace devtroncd \
--set installer.modules={cicd} \
--set secrets.AZURE_ACCOUNT_KEY=xxxxxxxxxx \
--set configs.BLOB_STORAGE_PROVIDER=AZURE \
--set configs.AZURE_ACCOUNT_NAME=test-account \
--set configs.AZURE_BLOB_CONTAINER_CI_LOG=ci-log-container \
--set configs.AZURE_BLOB_CONTAINER_CI_CACHE=ci-cache-containerhelm repo add devtron https://helm.devtron.ai
helm repo update devtron
helm install devtron devtron/devtron-operator \
--create-namespace --namespace devtroncd \
--set installer.modules={cicd} \
--set configs.BLOB_STORAGE_PROVIDER=GCP \
--set secrets.BLOB_STORAGE_GCP_CREDENTIALS_JSON=eyJ0eXBlIjogInNlcnZpY2VfYWNjb3VudCIsInByb2plY3RfaWQiOiAiPHlvdXItcHJvamVjdC1pZD4iLCJwcml2YXRlX2tleV9pZCI6ICI8eW91ci1wcml2YXRlLWtleS1pZD4iLCJwcml2YXRlX2tleSI6ICI8eW91ci1wcml2YXRlLWtleT4iLCJjbGllbnRfZW1haWwiOiAiPHlvdXItY2xpZW50LWVtYWlsPiIsImNsaWVudF9pZCI6ICI8eW91ci1jbGllbnQtaWQ+IiwiYXV0aF91cmkiOiAiaHR0cHM6Ly9hY2NvdW50cy5nb29nbGUuY29tL28vb2F1dGgyL2F1dGgiLCJ0b2tlbl91cmkiOiAiaHR0cHM6Ly9vYXV0aDIuZ29vZ2xlYXBpcy5jb20vdG9rZW4iLCJhdXRoX3Byb3ZpZGVyX3g1MDlfY2VydF91cmwiOiAiaHR0cHM6Ly93d3cuZ29vZ2xlYXBpcy5jb20vb2F1dGgyL3YxL2NlcnRzIiwiY2xpZW50X3g1MDlfY2VydF91cmwiOiAiPHlvdXItY2xpZW50LWNlcnQtdXJsPiJ9Cg== \
--set configs.DEFAULT_CACHE_BUCKET=cache-bucket \
--set configs.DEFAULT_BUILD_LOGS_BUCKET=log-bucketkubectl -n devtroncd get installers installer-devtron \
-o jsonpath='{.status.sync.status}'Downloaded
The installer has downloaded all the manifests, and the installation is in progress.
Applied
The installer has successfully applied all the manifests, and the installation is completed.
kubectl logs -f -l app=inception -n devtroncdkubectl get svc -n devtroncd devtron-service \
-o jsonpath='{.status.loadBalancer.ingress}'[map[hostname:aaff16e9760594a92afa0140dbfd99f7-305259315.us-east-1.elb.amazonaws.com]]devtron.yourdomain.com
CNAME
aaff16e9760594a92afa0140dbfd99f7-305259315.us-east-1.elb.amazonaws.com
kubectl -n devtroncd get secret devtron-secret \
-o jsonpath='{.data.ADMIN_PASSWORD}' | base64 -dkubectl -n devtroncd get secret devtron-secret \
-o jsonpath='{.data.ACD_PASSWORD}' | base64 -d sh devtron-install.bash start sh devtron-install.bash open sh devtron-install.bash stopsh devtron-install.bash upgradeName
Enter a name of your cluster.
Server URL
Server URL of a cluster. Note: We recommended to use a self-hosted URL instead of cloud hosted URL.
Bearer Token
Bearer token of a cluster.
curl -O https://raw.githubusercontent.com/devtron-labs/utilities/main/kubeconfig-exporter/kubernetes_export_sa.sh && bash kubernetes_export_sa.sh cd-user devtroncdcurl -O https://raw.githubusercontent.com/devtron-labs/utilities/main/kubeconfig-exporter/kubernetes_export_sa.sh && sed -i 's/kubectl/microk8s kubectl/g' \
kubernetes_export_sa.sh && bash kubernetes_export_sa.sh cd-user \
devtroncdPrometheus endpoint
Provide the URL of your prometheus.
Authentication Type
Prometheus supports two authentication types:
Basic: If you select the Basic authentication type, then you must provide the Username and Password of prometheus for authentication.
Anonymous: If you select the Anonymous authentication type, then you do not need to provide the Username and Password.
Note: The fields Username and Password will not be available by default.
TLS Key & TLS Certificate
TLS Key and TLS Certificate are optional, these options are used when you use a customized URL.
Environment Name
Enter a name of your environment.
Enter Namespace
Enter a namespace corresponding to your environment. Note: If this namespace does not already exist in your cluster, Devtron will create it. If it exists already, Devtron will map the environment to the existing namespace.
Environment Type
Select your environment type:
Production
Non-production
Note: Devtron shows deployment metrics (DORA metrics) for environments tagged as Production only.
Since an application can have more than one environment, the filter conditions apply only to the environment you chose in the **Apply to** section. If you create a filter condition without choosing an application or environment, it will not apply to any of your pipelines.If you create filters using CEL expressions that result in a conflict (i.e., passing and failing of the same image), fail will have higher precedenceApp Name
Displays the name of the application.
Created on
Displays the day, date and time the application was created.
Created by
Displays the email address of a user who created the application.
Project
Displays the current project of the application. You can change the project by selecting a different project from the drop-down list.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cache-pvc # here comes the name of PVC
spec:
accessModes:
- ReadWriteOnce
storageClassName: # here comes storage class name
resources:
requests:
storage: 30Gikubectl apply -f https://k8s.io/examples/pods/storage/pv-claim.yaml -n {namespace}Pipeline Name
Required
A name for the pipeline
Source type
Required
Source type to trigger the job pipeline. Available options: Branch Fixed | Branch Regex |Pull Request | Tag Creation
Branch Name
Required
Branch that triggers the job pipeline.
Author
Author of the PR
Source branch name
Branch from which the Pull Request is generated
Target branch name
Branch to which the Pull request will be merged
Title
Title of the Pull Request
State
State of the PR. Default is "open" and cannot be changed
Author
The one who created the tag
Tag name
Name of the tag for which the webhook will be triggered
Workloads
ReplicaSet(ensures how many replica of pod should be running), Status of Pod(status of the Pod)
Networking
Service(an abstraction which defines a logical set of Pods), Endpoints(names of the endpoints that implement a Service), Ingress(API object that manages external access to the services in a cluster)
Config & Storage
ConfigMap( API object used to store non-confidential data in key-value pairs)
Custom Resource
Rollout(new Pods will be scheduled on Nodes with available resources), ServiceMonitor(specifies how groups of services should be monitored)
CPU Usage
Percentage of CPU's cycles used by the app.
Memory Usage
Amount of memory used by app.
Throughput
Performance of the app.
Latency
Delay caused while transmitting the data.
With the Manage Notification feature, you can manage the notifications for your build and deployment pipelines. You can receive the notifications on Slack or via e-mail.
Go to the Global Configurations -> Notifications
Click Configurations to add notification configuration in one of the following options:
You can manage the SES configuration to receive e-mails by entering the valid credentials. Make sure your e-mail is verified by SES.
Click Add and configure SES.
Configuration Name
Provide a name to the SES Configuration.
Access Key ID
Valid AWS Access Key ID.
Secret Access Key
Valid AWS Secret Access Key.
AWS Region
Select the AWS Region from the drop-down menu.
E-mail
Enter the SES verified e-mail id on which you wish to receive e-mail notifications.
Click Save to save your SES configuration or e-mail ID
You can manage the SMTP configuration to receive e-mails by entering the valid credentials. Make sure your e-mail is verified by SMTP.
Click Add and configure SMTP.
Configuration Name
Provide a name to the SMTP Configuration
SMTP Host
Host of the SMTP.
SMTP Port
Port of the SMTP.
SMTP Username
Username of the SMTP.
SMTP Password
Password of the SMTP.
E-mail
Enter the SMTP verified e-mail id on which you wish to receive e-mail notifications.
Click Save to save your SMTP configuration or e-mail ID
You can manage the Slack configurations to receive notifications on your preferred Slack channel.
Click Add to add new Slack Channel.
Slack Channel
Name of the Slack channel on which you wish to receive notifications.
Webhook URL
Enter the valid .
Project
Select the project name to control user access.
Click Save and your slack channel will be added.
Click Add New to receive new notification.
Send To
When you click on the Send to box, a drop-down will appear, select your slack channel name if you have already configured Slack Channel. If you have not yet configured the Slack Channel, Configure Slack Channel
Select Pipelines
Then, to fetch pipelines of an application, project and environment.
Choose a filter type(environment, project or application)
You will see a list of pipelines corresponding to your selected filter type, you can select any number of pipelines. For each pipeline, there are 3 types of events Trigger, Success, and Failure. Click on the checkboxes for the events, on which you want to receive notifications.
Click Save when you are done with your Slack notification configuration.
Send To
Click Send To box, select your e-mail address/addresses on which you want to send e-mail notifications. Make sure e-mail id are SES Verified.
If you have not yet configured SES, Configure SES.
Select Pipelines
To fetch pipelines of an application, project and environment.
Choose a filter type(environment, project or application)
You will see a list of pipelines corresponding to your selected filter type, you can select any number of pipelines. For each pipeline, there are 3 types of events Trigger, Success, and Failure. Click on the checkboxes for the events, on which you want to receive notifications.
Click Save once you have configured the SES notification.
Send To
Click Send To box, select your e-mail address/addresses on which you want to send e-mail notifications. Make sure e-mail IDs are SMTP Verified.
If you have not yet configured SMTP, Configure SMTP.
Select Pipelines
To fetch pipelines of an application, project and environment.
Choose a filter type(environment, project or application)
You will see a list of pipelines corresponding to your selected filter type, you can select any number of pipelines. For each pipeline, there are 3 types of events Trigger, Success, and Failure. Click on the checkboxes for the events, on which you want to receive notifications.
Click Save once you have configured the SMTP notification.
The ConfigMap API resource holds key-value pairs of the configuration data that can be consumed by pods or used to store configuration data for system components such as controllers. ConfigMap is similar to Secrets, but designed to more conveniently support working with strings that do not contain sensitive information.
Click on Add ConfigMap to add a config map to your application.
You can configure a configmap in two ways-
(a) Using data type Kubernetes ConfigMap
(b) Using data type Kubernetes External ConfigMap
Data Type (Kubernetes ConfigMap)
Select your preferred data type for Kubernetes ConfigMap or Kubernetes External ConfigMap
Name
Provide a name to this ConfigMap.
Use configmap as Environment Variable
Select this option if you want to inject Environment Variables in pods using ConfigMap.
Use configmap as Data Volume
Select this option, if you want to configure a Data Volume that is accessible to Containers running in a pod and provide a Volume mount path.
Key-Value
Provide the actual key-value configuration data here. Key and corresponding value to the provided key.
1. Data Type
Select the Data Type as Kubernetes ConfigMap, if you wish to use the ConfigMap created by Devtron.
2. Name
Provide a name to your configmap.
3. Use ConfigMap as
Here we are providing two options, one can select any of them as per your requirement
-Environment Variable as part of your configMap or you want to add Data Volume to your container using Config Map.
Environment Variable
Select this option if you want to add Environment Variables as a part of configMap. You can provide Environment Variables in key-value pairs, which can be seen and accessed inside a pod.
Data Volume
Select this option if you want to add a Data Volume to your container using the Config Map.
Key-value pairs that you provide here, are provided as a file to the mount path. Your application will read this file and collect the required data as configured.
4. Data
In the Data section, you provide your configmap in key-value pairs. You can provide one or more than one environment variable.
You can provide variables in two ways-
YAML (raw data)
GUI (more user friendly)
Once you have provided the config, You can click on any option-YAML or GUI to view the key and Value parameters of the ConfigMap.
Kubernetes ConfigMap using Environment Variable:
If you select Environment Variable in 3rd option, then you can provide your environment variables in key-value pairs in the Data section using YAML or GUI.
Data in YAML (please Check below screenshot)
Now, Click on Save ConfigMap to save your configmap configuration.
Kubernetes ConfigMap using Data Volume
Provide the Volume Mount folder path in Volume Mount Path, a path where the data volume needs to be mounted, which will be accessible to the Containers running in a pod.
You can add Configuration data as in YAML or GUI format as explained above.
You can click on YAML or GUI to view the key and Value parameters of the ConfigMap that you have created.
You can click on Save ConfigMap to save the configMap.
For multiple files mount at the same location you need to check sub path bool field, it will use the file name (key) as sub path. Sub Path feature is not applicable in case of external configmap.
File permission will be provide at the configmap level not on the each key of the configmap. It will take 3 digit standard permission for the file.
You can select Kubernetes External ConfigMap in the data type field if you have created a ConfigMap using the kubectl command.
By default, the data type is set to Kubernetes ConfigMap.
Kubernetes External ConfigMap is created using the kubectl create configmap command. If you are using Kubernetes External ConfigMap, make sure you give the name of ConfigMap the same as the name that you have given using kubectl create Configmap <configmap-name> <data source> command, otherwise, it might result in an error during the built.
You have to ensure that the External ConfigMap exists and is available to the pod.
The config map is created.
You can update your configmap anytime later but you cannot change the name of your configmap. If you want to change the name of the configmap then you have to create a new configmap. To update configmap, click on the configmap you have created make changes as required.
Click on Update Configmap to update your configmap.
You can delete your configmap. Click on your configmap and click on the delete sign to delete your configmap.
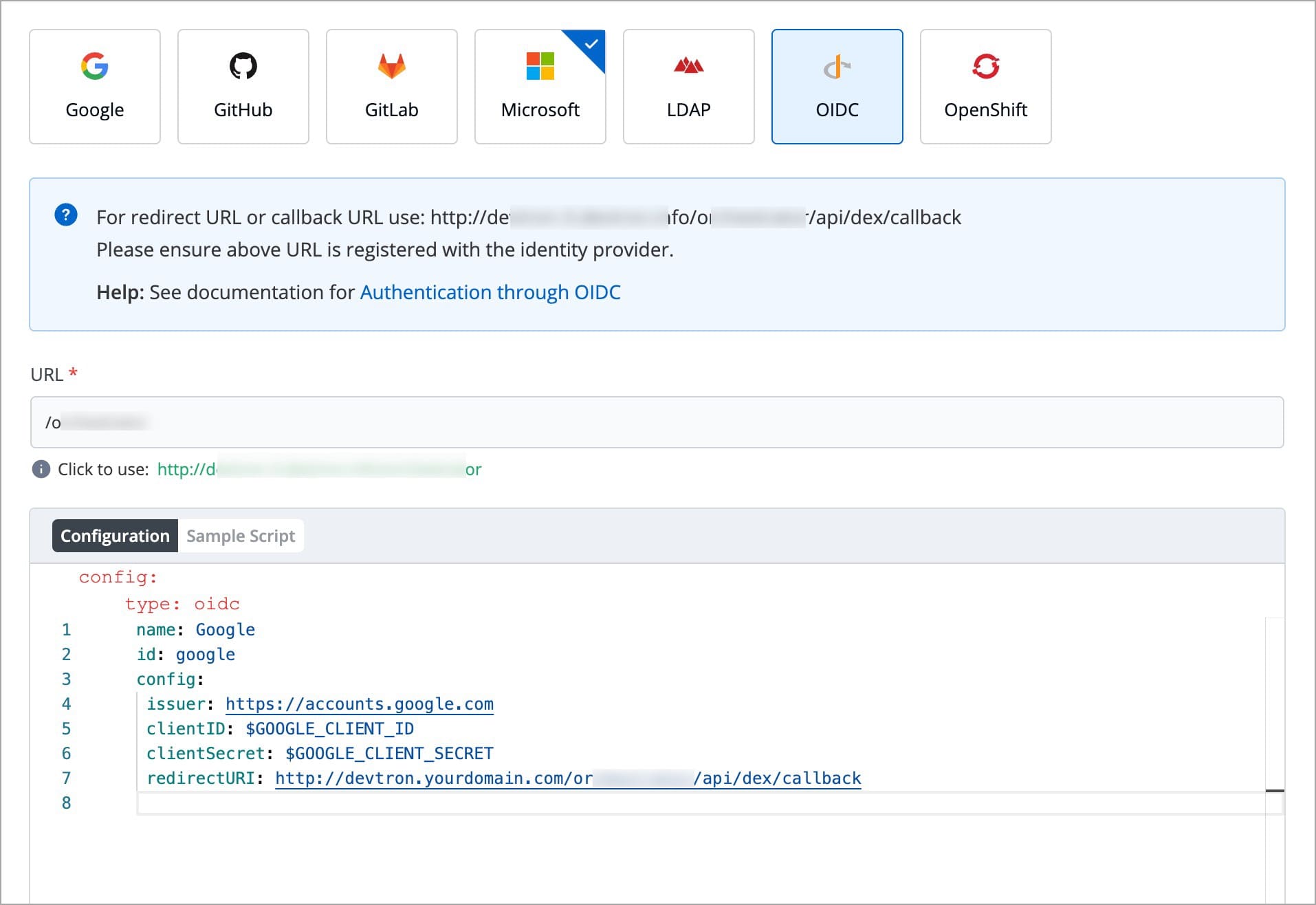
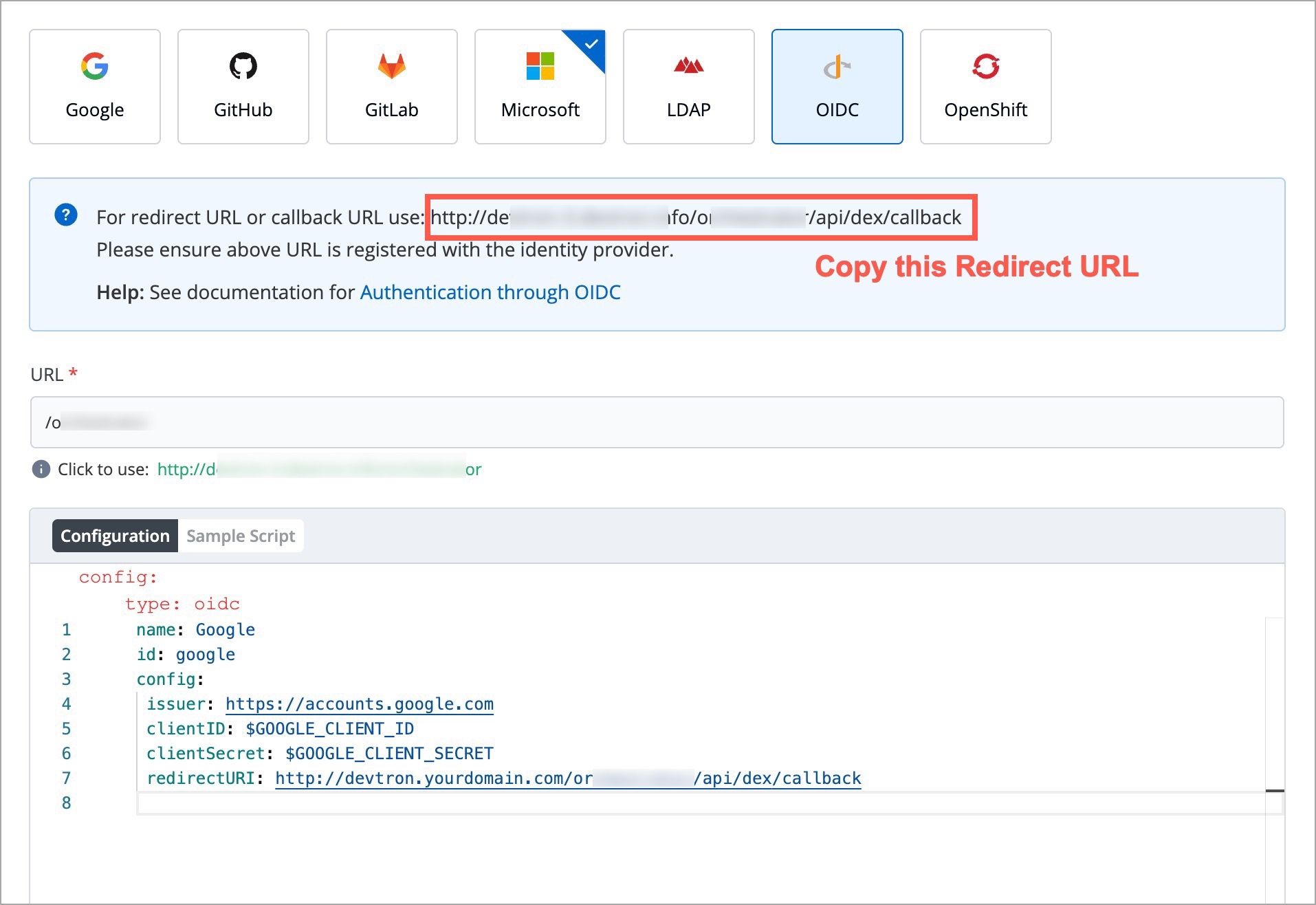
During the , the application source code is pulled from your .
Devtron also supports multiple Git repositories (be it from one Git account or multiple Git accounts) in a single deployment.
Therefore, this doc is divided into 2 sections, read the one that caters to your application:
Follow the below steps if the source code of your application is hosted on a single Git repository.
In your application, go to App Configuration → Git Repository. You will get the following fields and options:
(Checkboxes)
This is a dropdown that shows the list of Git accounts added to your organization on Devtron. If you haven't done already, we recommend you to first (especially when the repository is private).
In this field, you have to provide your code repository’s URL, for e.g., https://github.com/devtron-labs/django-repo.
You can find this URL by clicking on the Code button available on your repository page as shown below:
Not all repository changes are worth triggering a new . If you enable this checkbox, you can define the file(s) or folder(s) whose commits you wish to use in the CI build.
In other words, if a given commit contains changes only in file(s) present in your exclusion rule, the commit won't show up while selecting the , which means it will not be eligible for build. However, if a given commit contains changes in other files too (along with the excluded file), the commit won't be excluded and it will definitely show up in the list of commits.
Devtron allows you to create either an exclusion rule, an inclusion rule, or a combination of both. In case of multiple files or folders, you can list them in new lines.
To exclude a path, use ! as the prefix, e.g. !path/to/file
To include a path, don't use any prefix, e.g. path/to/file
You may use the Learn how link (as shown below) to understand the syntax of defining an exclusion or inclusion rule.
Since file paths can be long, Devtron supports regex too for writing the paths. To understand it better, you may click the How to use link as shown below.
As we saw earlier in fig. 4 and 5, commits containing the changes of only README.md file were not displayed, since the file was in the exclusion list.
However, Devtron gives you the option to view the excluded commits too. There's a döner menu at the top-right (beside the Search by commit hash search bar).
The EXCLUDED label (in red) indicates that the commits contain changes made only to the excluded file, and hence they are unavailable for build.
After clicking the checkbox, a field titled clone directory path appears. It is the directory where your code will be cloned for the repository you specified in the previous step.
This field is optional for a single Git repository application and you can leave the path as default. Devtron assigns a directory by itself when the field is left blank. The default value of this field is ./
This checkbox is optional and is used for pulling present in a repo. The submodules will be pulled recursively, and the auth method used for the parent repo will be used for submodules too.
As discussed earlier, Devtron also supports multiple git repositories in a single application. To add multiple repositories, click Add Git Repository and repeat all the steps as mentioned in . However, ensure that the clone directory paths are unique for each repo.
Repeat the process for every new git repository you add. The clone directory path is used by Devtron to assign a directory to each of your Git repositories. Devtron will clone your code at those locations and those paths can be referenced in the Docker file to create a Docker image of the application.
Whenever a change is pushed to any of the configured repositories, CI will be triggered and a new Docker image file will be built (based on the latest commits of the configured repositories). Next, the image will be pushed to the container registry you configured in Devtron.
Let’s look at this with an example:
Due to security reasons, you want to keep sensitive configurations like third-party API keys in separate access-restricted git repositories, and the source code in a Git repository that every developer has access to. To deploy this application, code from both the repositories are required. A Multi-Git support helps you achieve it.
Other examples where you might need Multi-Git support:
To make code modularized, where front-end and back-end code are in different repos
Common library extracted out in a different repo so that other projects can use it
Devtron includes predefined helm charts that cover the majority of use cases. For any use case not addressed by the default helm charts, you can upload your own helm chart and use it as a custom chart in Devtron.
Who can upload a custom chart - Super admins
Who can use the custom chart - All users
A super admin can upload multiple versions of a custom helm chart.
A valid helm chart, which contains Chart.yaml file with name and version fields.
Image descriptor template file .image_descriptor_template.json.
Custom chart packaged in the *.tgz format.
You can use the following command to create the Helm chart:
Note:
Chart.yamlis the metadata file that gets created when you create a .
Please see the following example:
.image_descriptor_template.jsonIt's a GO template file that should produce a valid JSON file upon rendering. This file is passed as the last argument in helm install -f myvalues.yaml -f override.yaml command.
Place the .image_descriptor_template.json file in the root directory of your chart.
You can use the following variables in the helm template (all the placeholders are optional):
The values from the CD deployment pipeline are injected at the placeholder specified in the
.image_descriptor_template.jsontemplate file.
For example:
To create a template file to allow Devtron to only render the repository name and the tag from the CI/CD pipeline that you created, edit the
.image_descriptor_template.jsonfile as:
*.tgz formatBefore you begin, ensure that your helm chart includes both
Chart.yaml(withnameandversionfields) and.image_descriptor_template.jsonfiles.
The helm chart to be uploaded must be packaged as a versioned archive file in the format <helm-chart-name>-vx.x.x.tgz.
The above command will create a my-custom-chart-0.1.0.tgz file.
A custom chart can only be uploaded by a super admin.
On the Devtron dashboard, select Global Configurations > Custom charts.
Select Import Chart.
Select tar.gz file... and upload the packaged custom chart in the *.tgz format.
The chart is being uploaded and validated. You may also Cancel upload if required.
The uploaded archive will be validated against:
Supported archive template should be in *.tgz format.
Content of values.yaml should be there in app-values.yaml file.
release-values.yaml file is required.
ConfigMap/Secret template should be same as that of our .
Chart.yaml must include the name and the version number.
..image_descriptor_template.json file should be present and the field format must match the format listed in the image builder template section.
The following are the validation results:
All users can view the custom charts.
To view a list of available custom charts, go to Global Configurations > Custom charts page.
The charts can be searched with their name, version, or description.
New by selecting Upload chart.
The custom charts can be used from the section.
Info:
The deployment strategy for a custom chart is fetched from the custom chart template and cannot be configured in the .
An ideal deployment workflow may consist of multiple stages (e.g., SIT, UAT, Prod environment).
If you have built such a , your CI image will sequentially traverse and deploy to each environment until it reaches the target environment. However, if there's a critical issue you wish to address urgently (through a hotfix) on production, navigating the standard workflow might feel slow and cumbersome.
Therefore, Devtron offers a feature called 'Image Promotion Policy' that allows you to directly promote an image to the target environment, bypassing the intermediate stages in your workflow including:
and of the intermediate stages
All of the intermediate stages
Users need to have super-admin permission to create an image promotion policy.
You can create a policy using our APIs or through Devtron CLI. To get the latest version of the devtctl binary, please contact your enterprise POC or reach out to us directly for further assistance.
Here is the CLI approach:
Syntax:
Arguments:
--name (required): The name of the image promotion policy.
--description (optional): A brief description of the policy, preferably explaining what it does.
--passCondition (optional): Specify a condition using . Images that match this condition will be eligible for promotion to the target environment.
--failCondition (optional): Images that match this condition will NOT be eligible for promotion to the target environment.
--approverCount (optional): The number of approvals required to promote an image (0-6). Defaults to 0 (no approvals).
--allowRequestFromApprove (optional): (Boolean) If true, user who raised the image promotion request can approve it. Defaults to false.
--allowImageBuilderFromApprove (optional): (Boolean) If true, user who triggered the build can approve the image promotion request. Defaults to false.
--allowApproverFromDeploy (optional): (Boolean) If true, user who approved the image promotion request can deploy that image. Defaults to false.
--applyPath (optional): Specify the path to the YAML file that contains the list of applications and environments to which the policy should be applicable.
Users need to have super-admin permission to apply an image promotion policy.
You can apply a policy using our APIs or through Devtron CLI. Here is the CLI approach:
Create a YAML file and give it a name (say applyPolicy.yaml). Within the file, define the applications and environments to which the image promotion policy should apply, as shown below.
Apply the policy using the following CLI command:
Users with build & deploy permission or above (for the application and target environment) can promote an image if the image promotion policy is enabled.
Here, you can promote images to the target environment(s).
Go to the Build & Deploy tab of your application.
Click the Promote button next to the workflow in which the you wish to promote the image. Please note, the button will appear only if image promotion is allowed for any environment used in that workflow.
In the Select Image tab, you will see a list of images. Use the Show Images from dropdown to filter the list and choose the image you wish to promote. This can be either be an image from the CI pipeline or one that has successfully passed all stages (e.g., pre, post, if any) of that particular environment.
Use the SELECT button on the image, and click Promote to...
Select one or more target environments using the checkbox.
Click Promote Image.
The image's promotion to the target environment now depends on the approval settings in the image promotion policy. If the super-admin has enforced an approval process, the image requires the necessary number of approvals before promotion. On the other hand, if the super-admin has not enforced approval, the image will be automatically promoted since there is no request phase involved.
In case you have configured , an email notification will be sent to the approvers.
If approval(s) are required for image promotion, you may check the status of your request in the Approval Pending tab.
Only the users having role (for the application and environment) or superadmin permissions will be able to approve the image promotion request.
Go to the Build & Deploy tab of your application.
Click the Promote button next to the workflow.
Go to the Approval Pending tab to see the list of images requiring approval. By default, it shows a list of all images whose promotion request is pending with you.
Click Approve for... to choose the target environments to which it can be promoted.
Click Approve.
You can also use the Show requests dropdown to filter the image promotion requests for a specific target environment.
If there are pending promotion requests, you can approve them as shown below:
Users with build & deploy permission or above for the application and environment can deploy the promoted image.
If a user has approved the promotion request for an image, they may or may not be able to deploy depending upon the .
However, a promoted image does not automatically qualify as a deployable image. It must fulfill all configured requirements (, , etc.) of the target environment for it to be deployed.
In the Build & Deploy tab of your application, click Select Image for the CD pipeline, and choose your promoted image for deployment.
You can check the deployment of promoted images in the Deployment History of your application. It will also indicate the pipeline from which the image was promoted and deployed to the target environment.
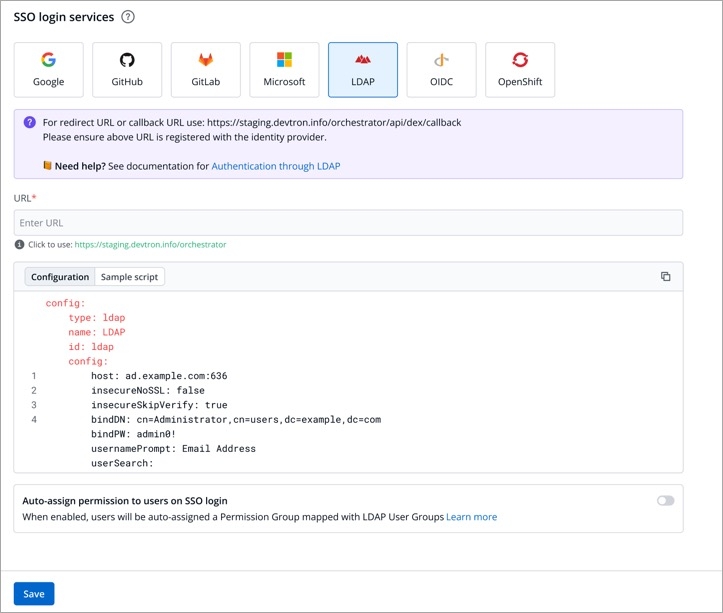
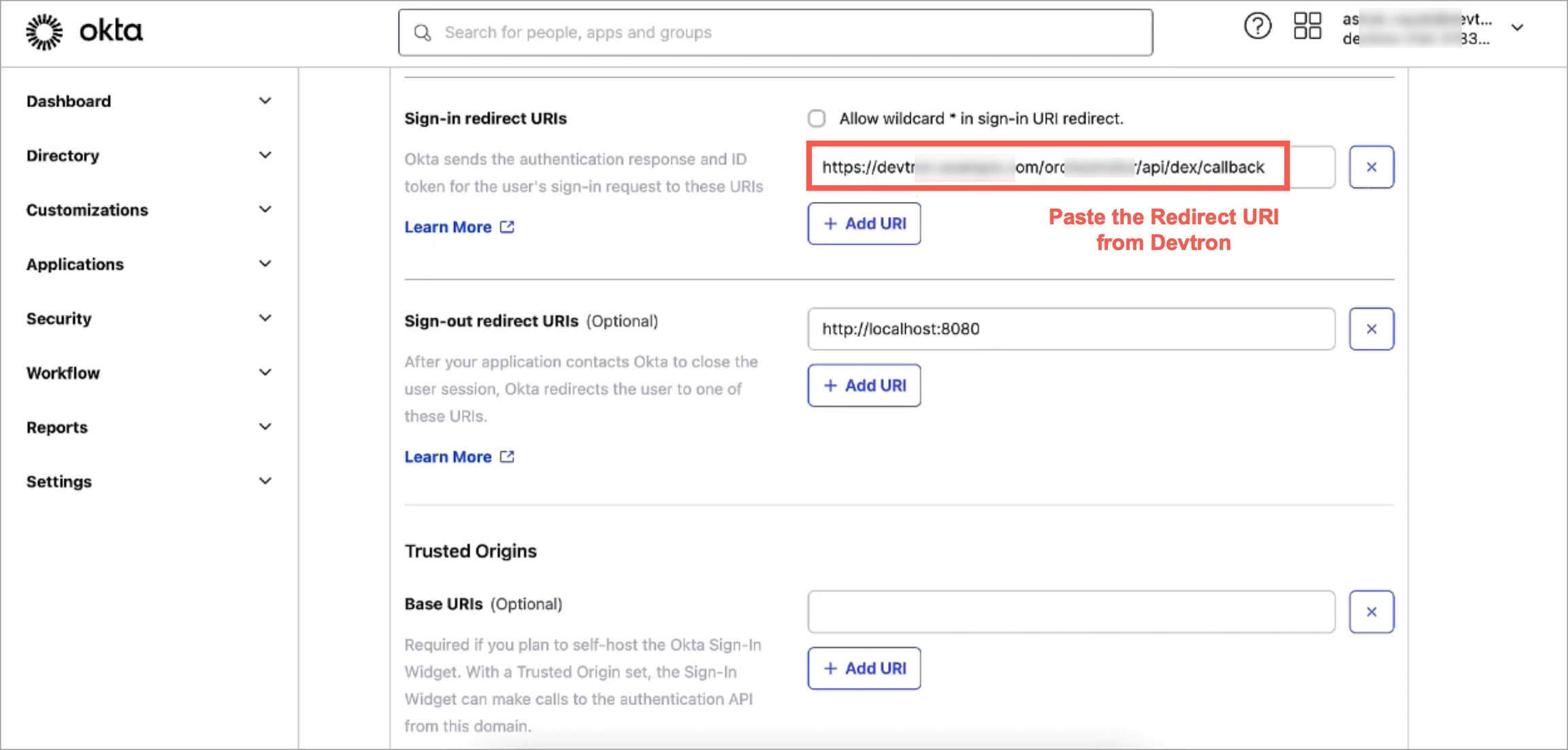
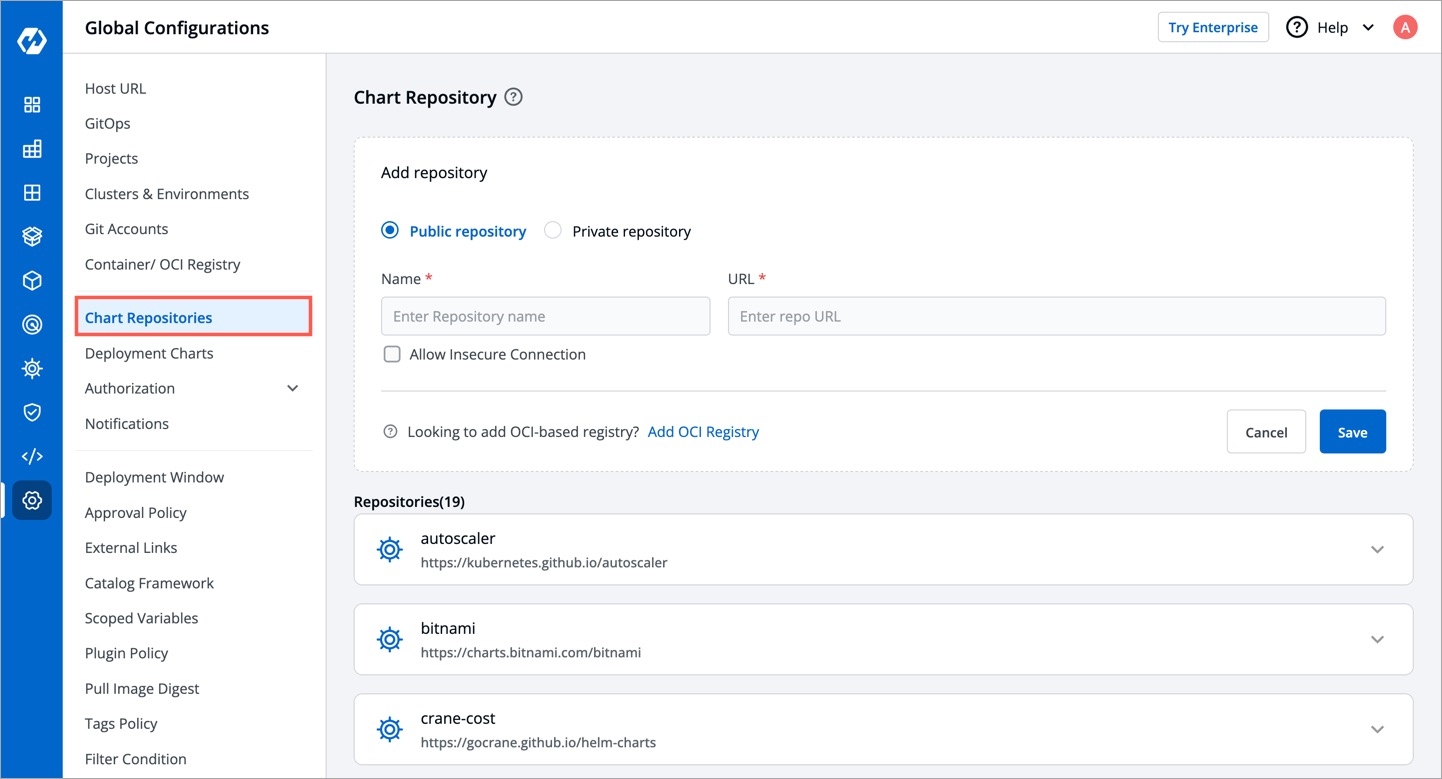
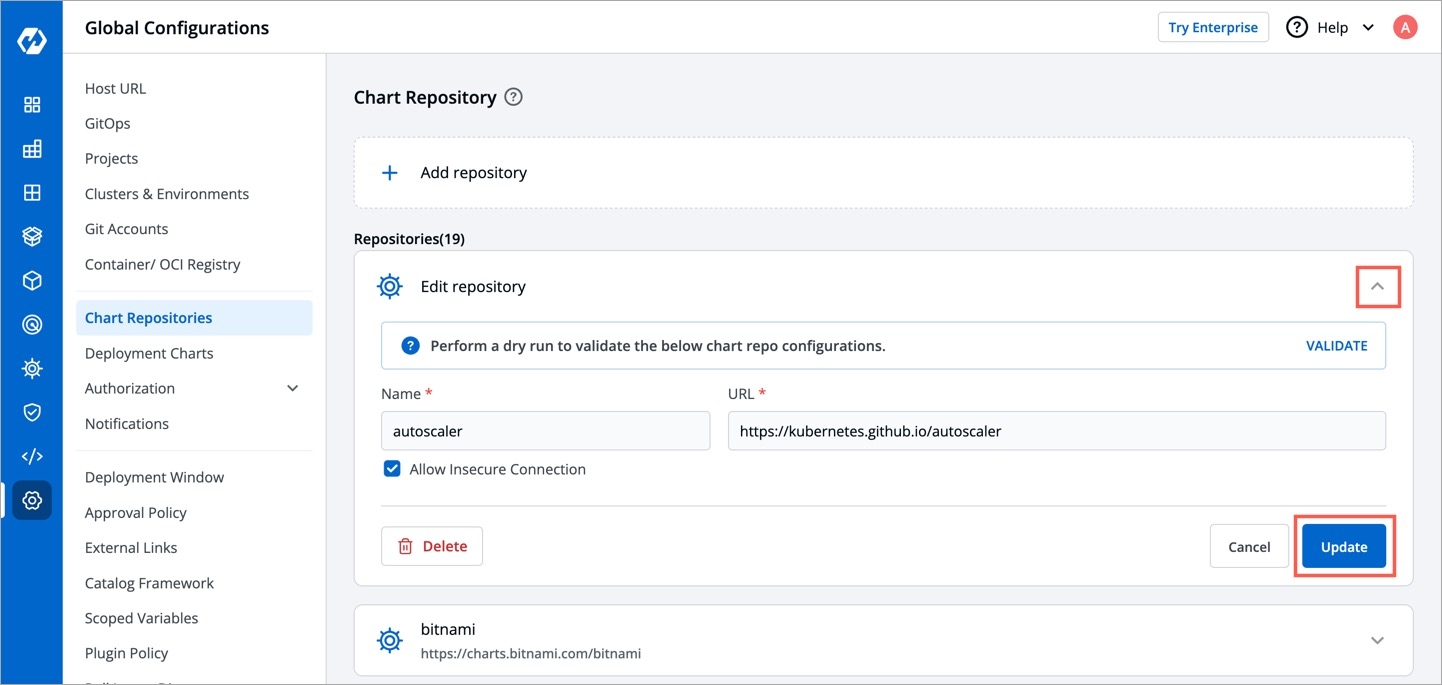
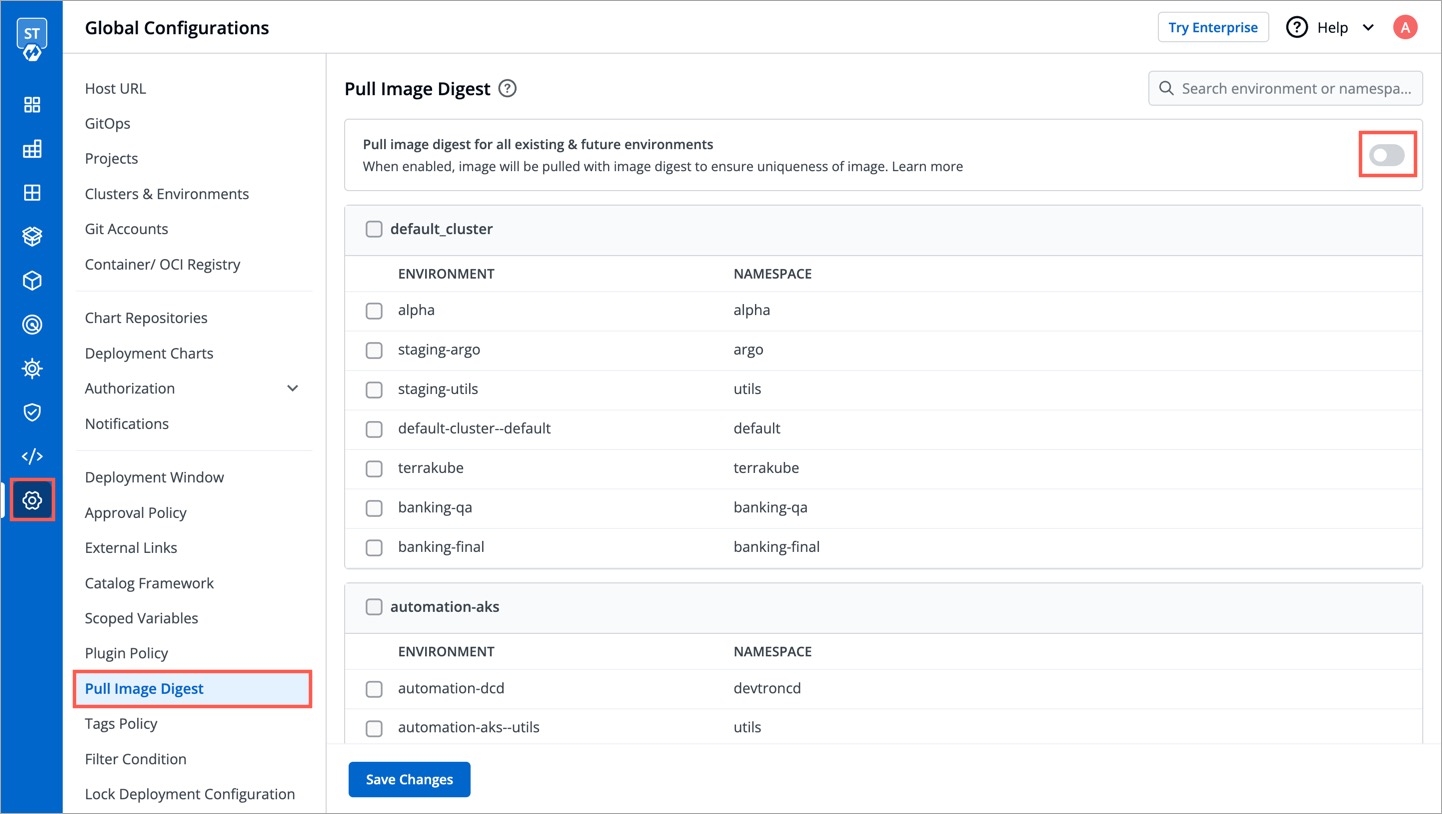
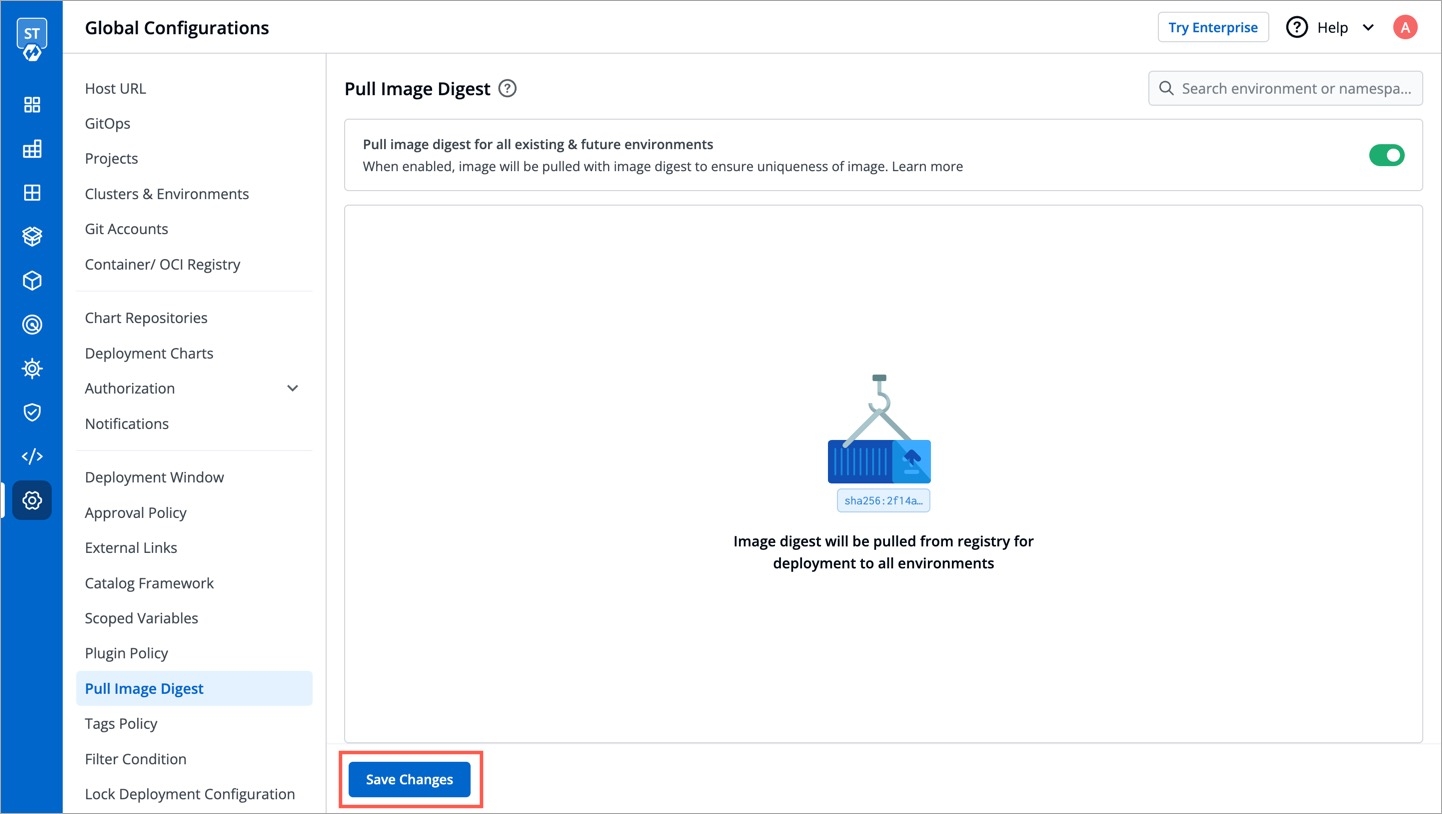
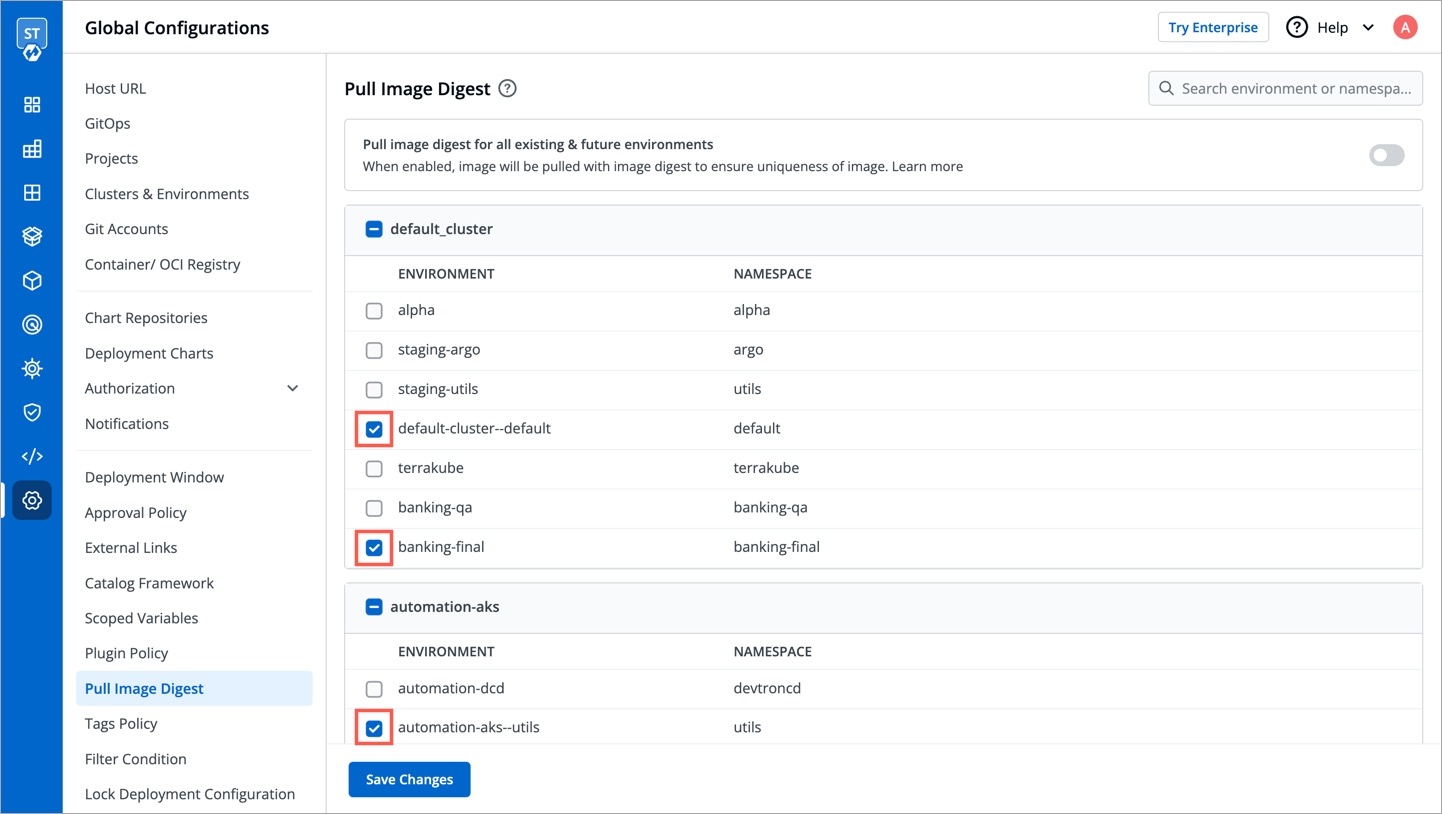
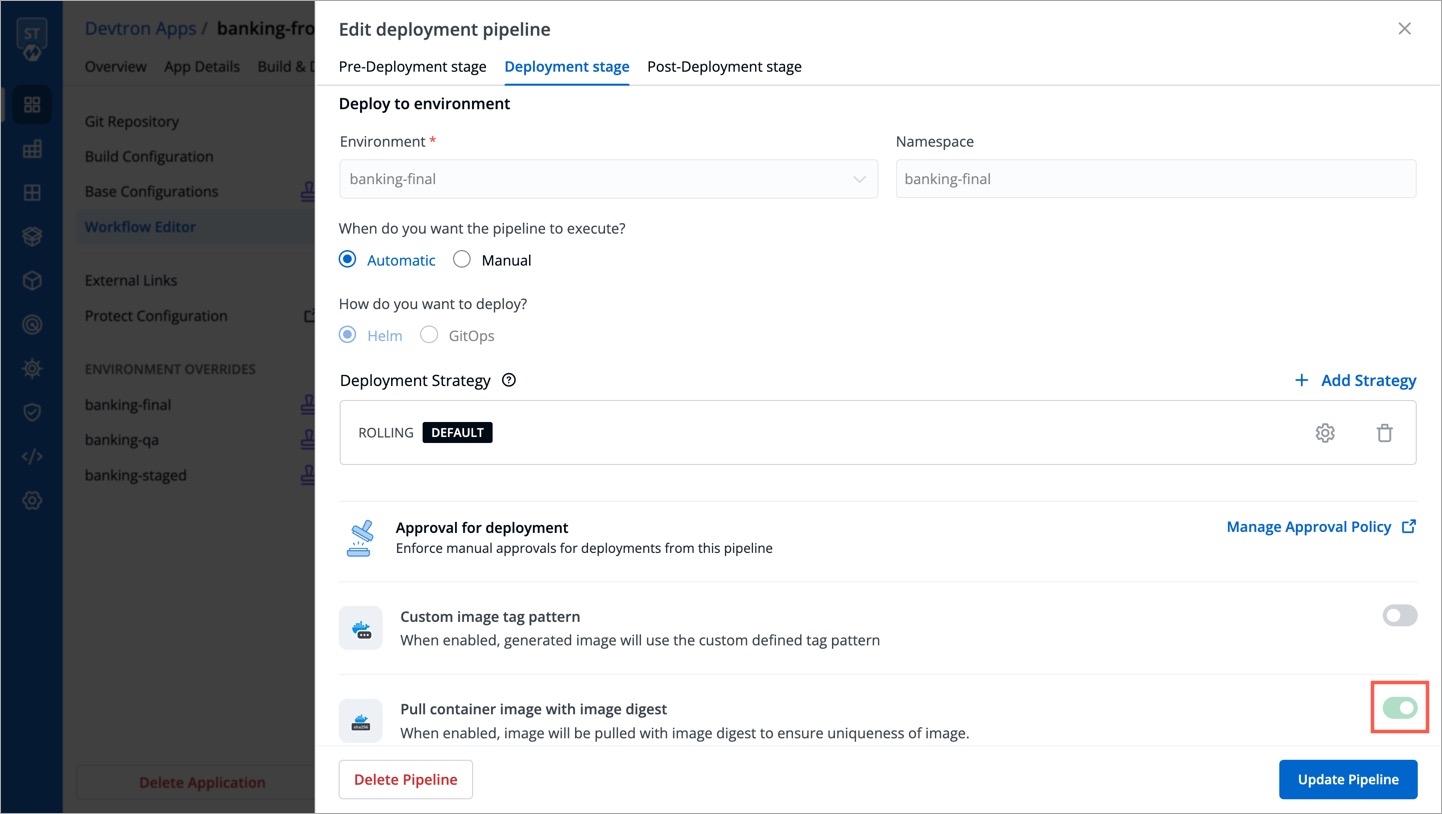
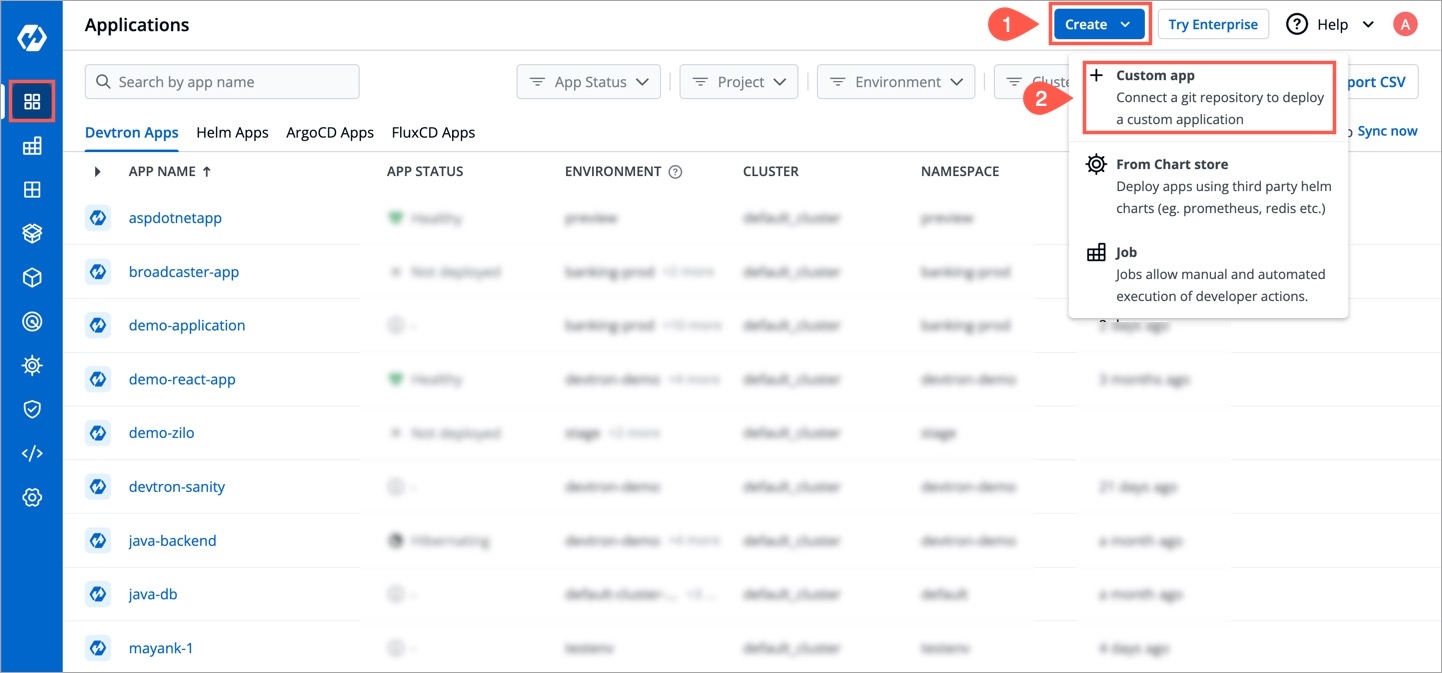
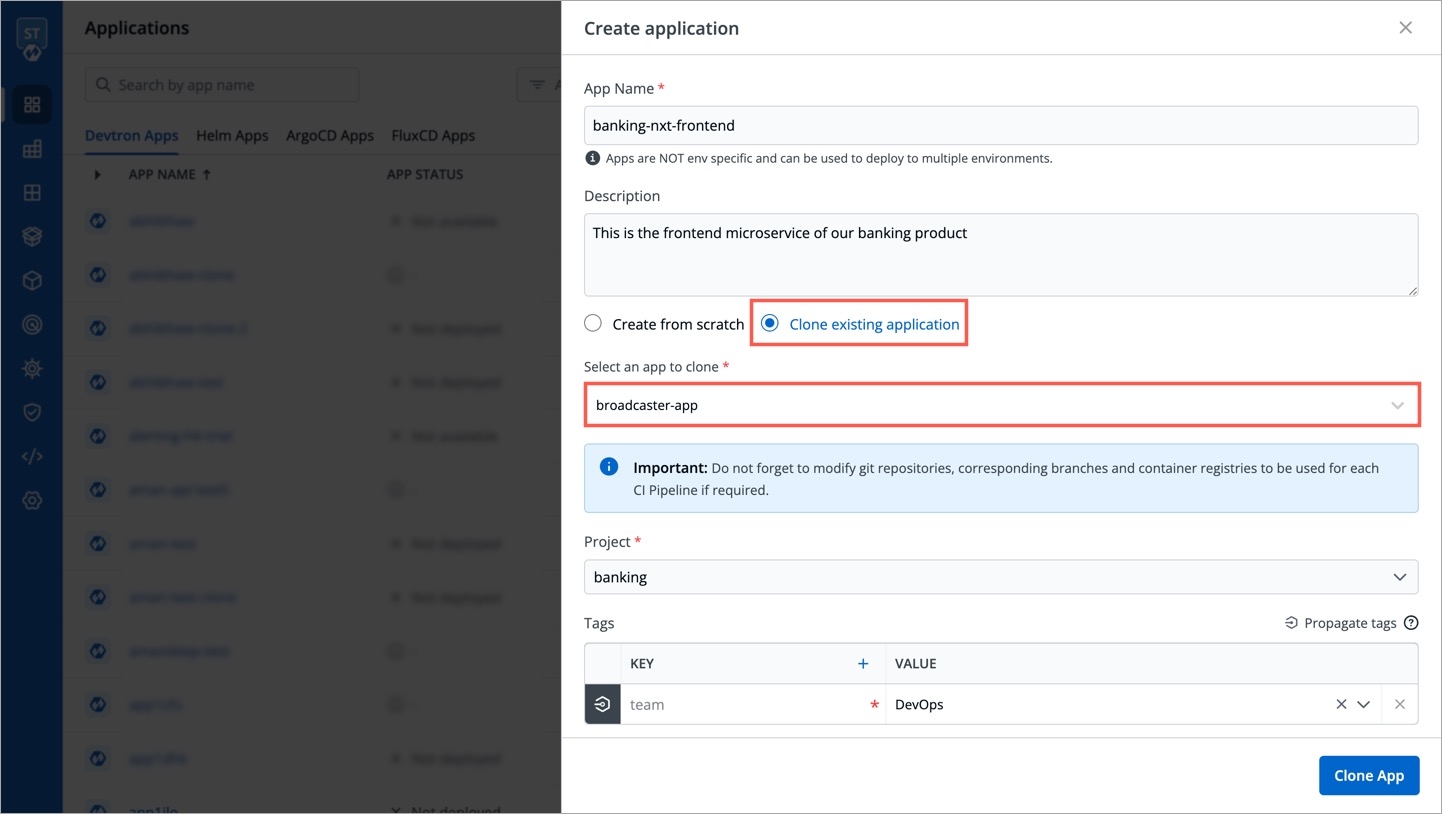
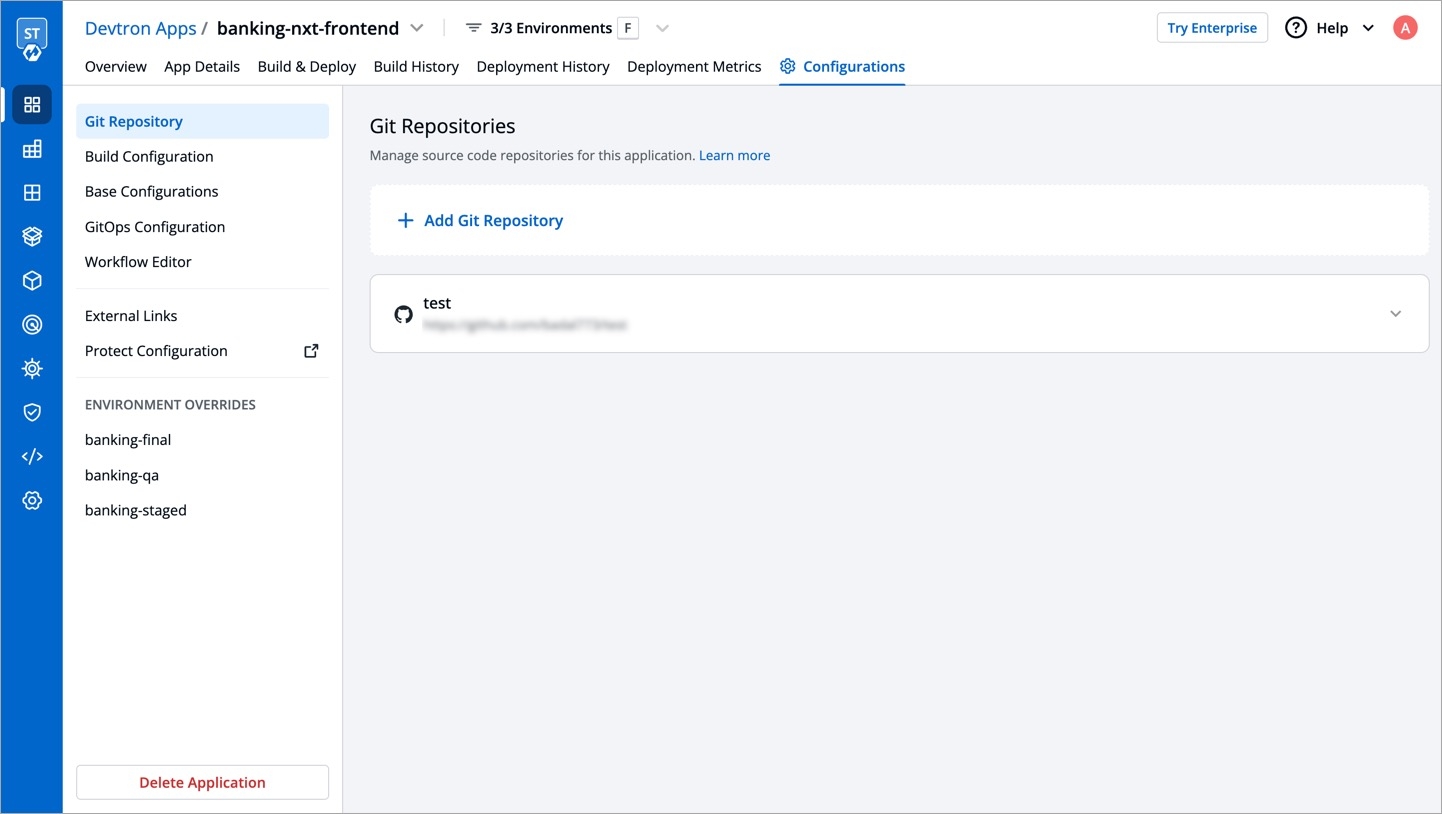
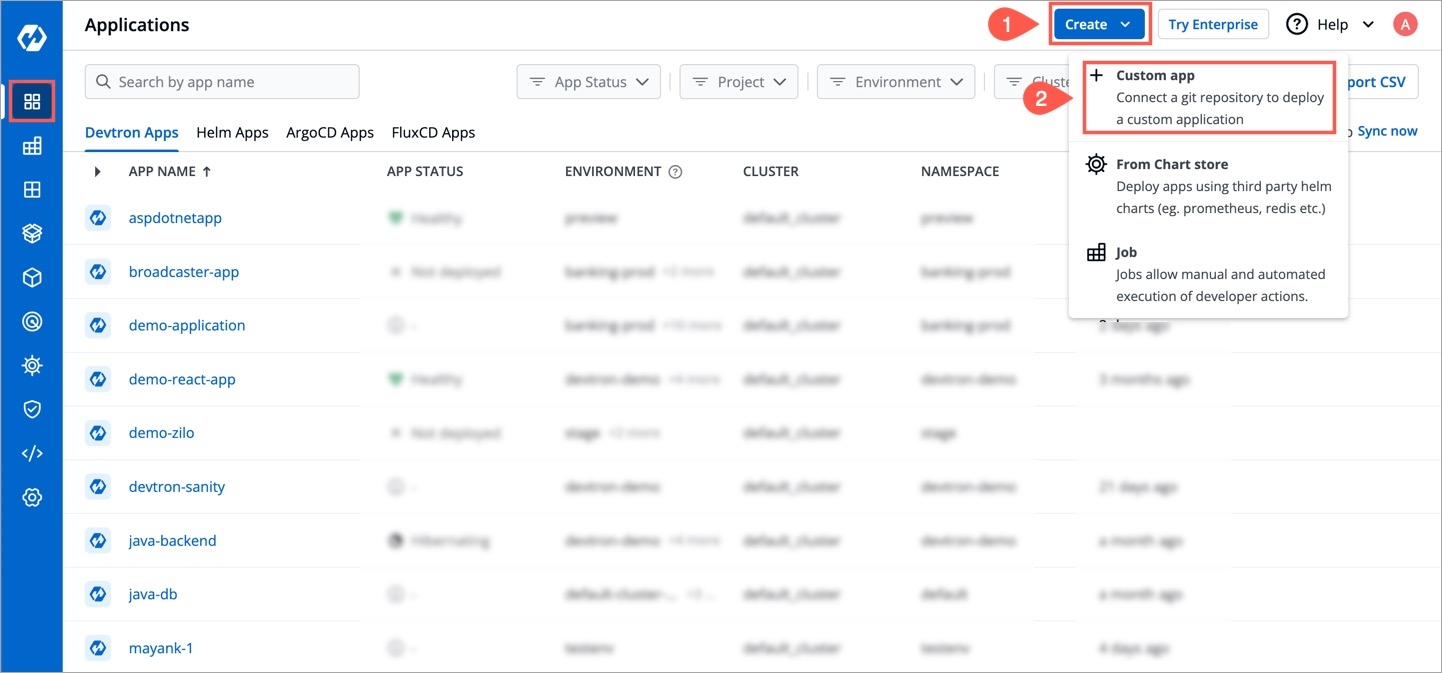
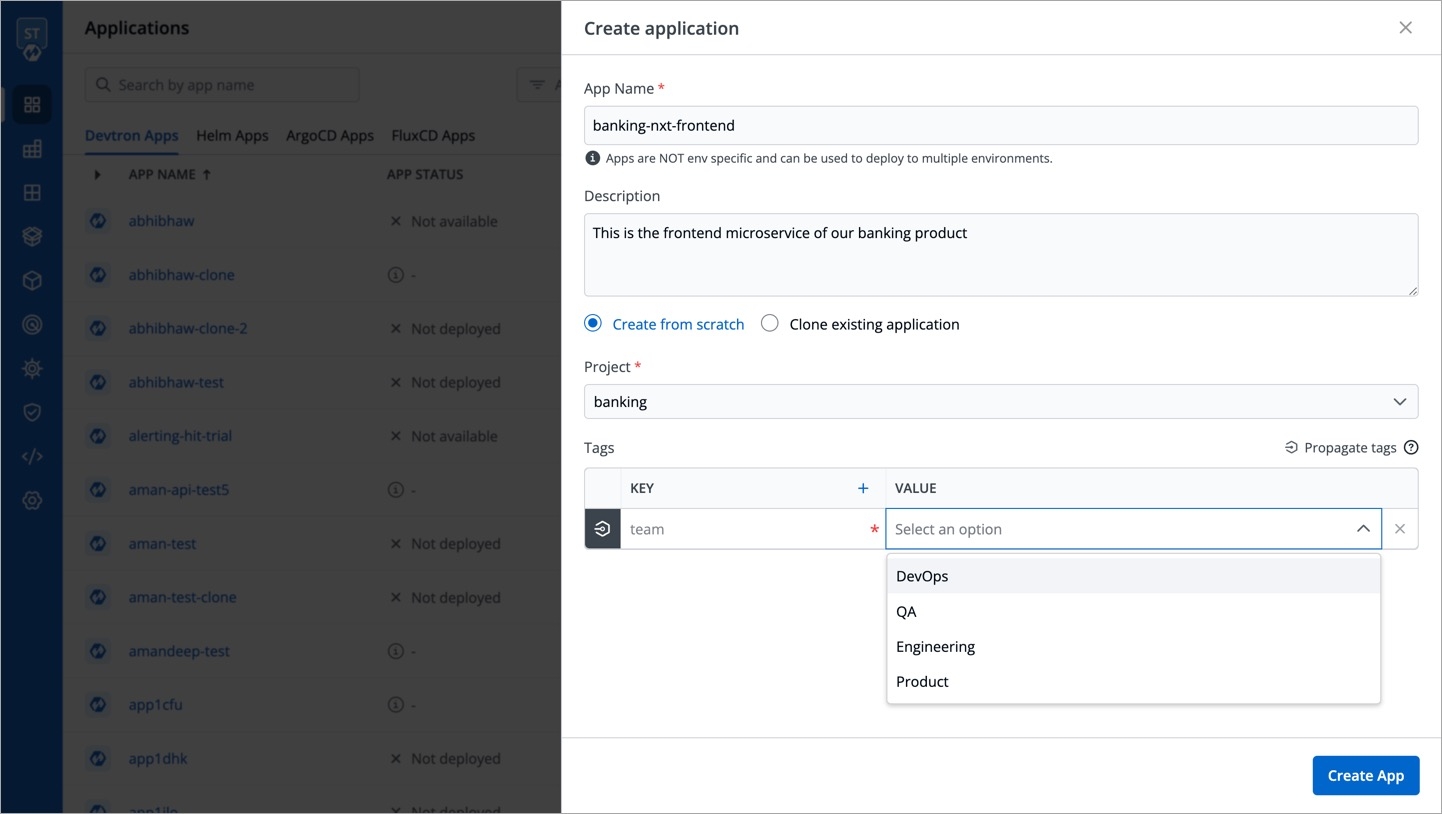
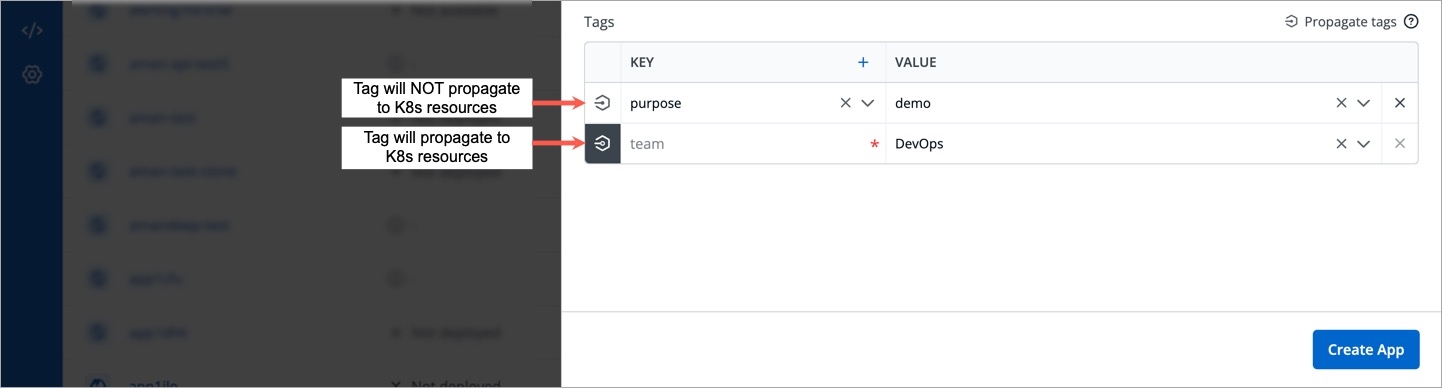
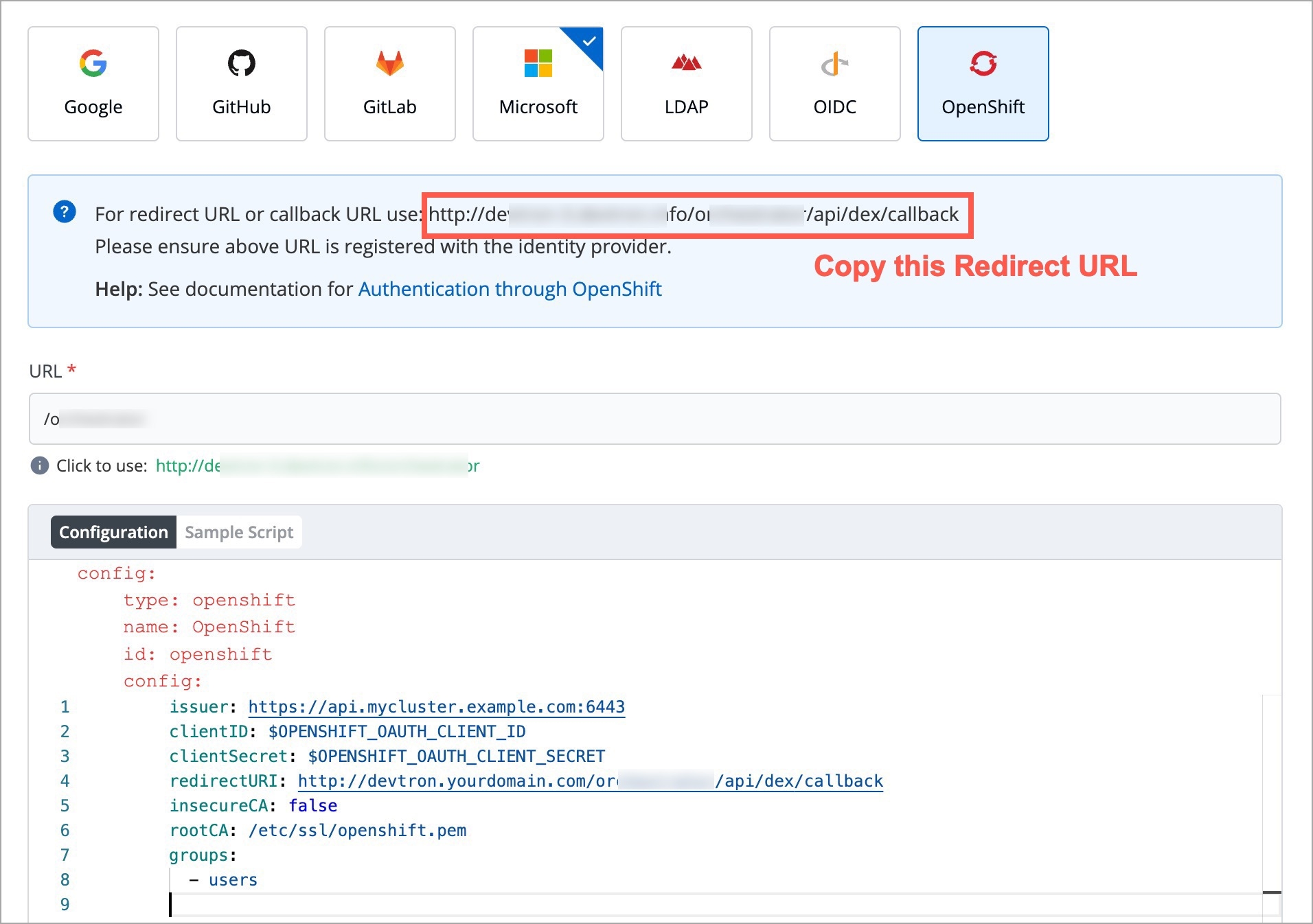
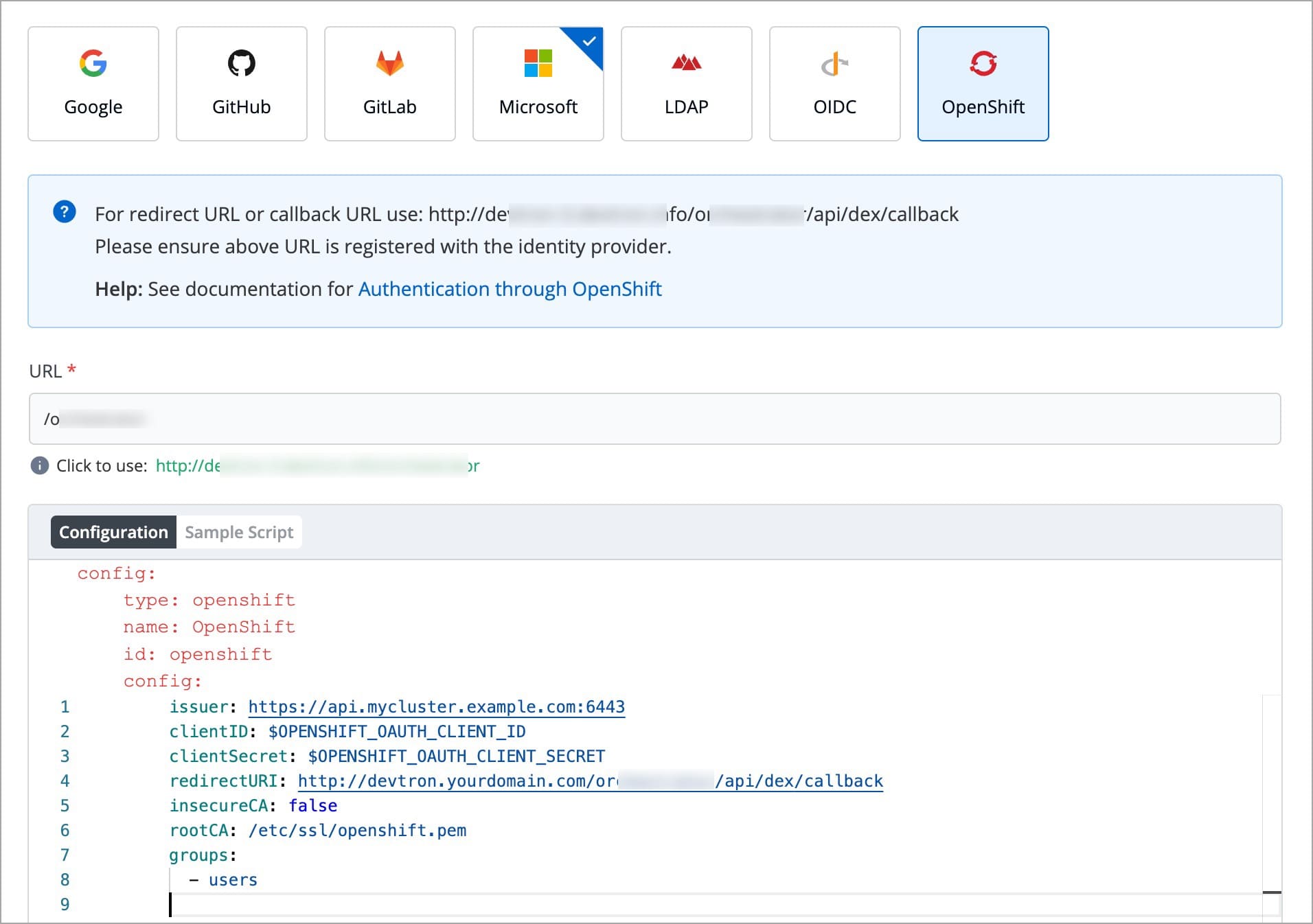
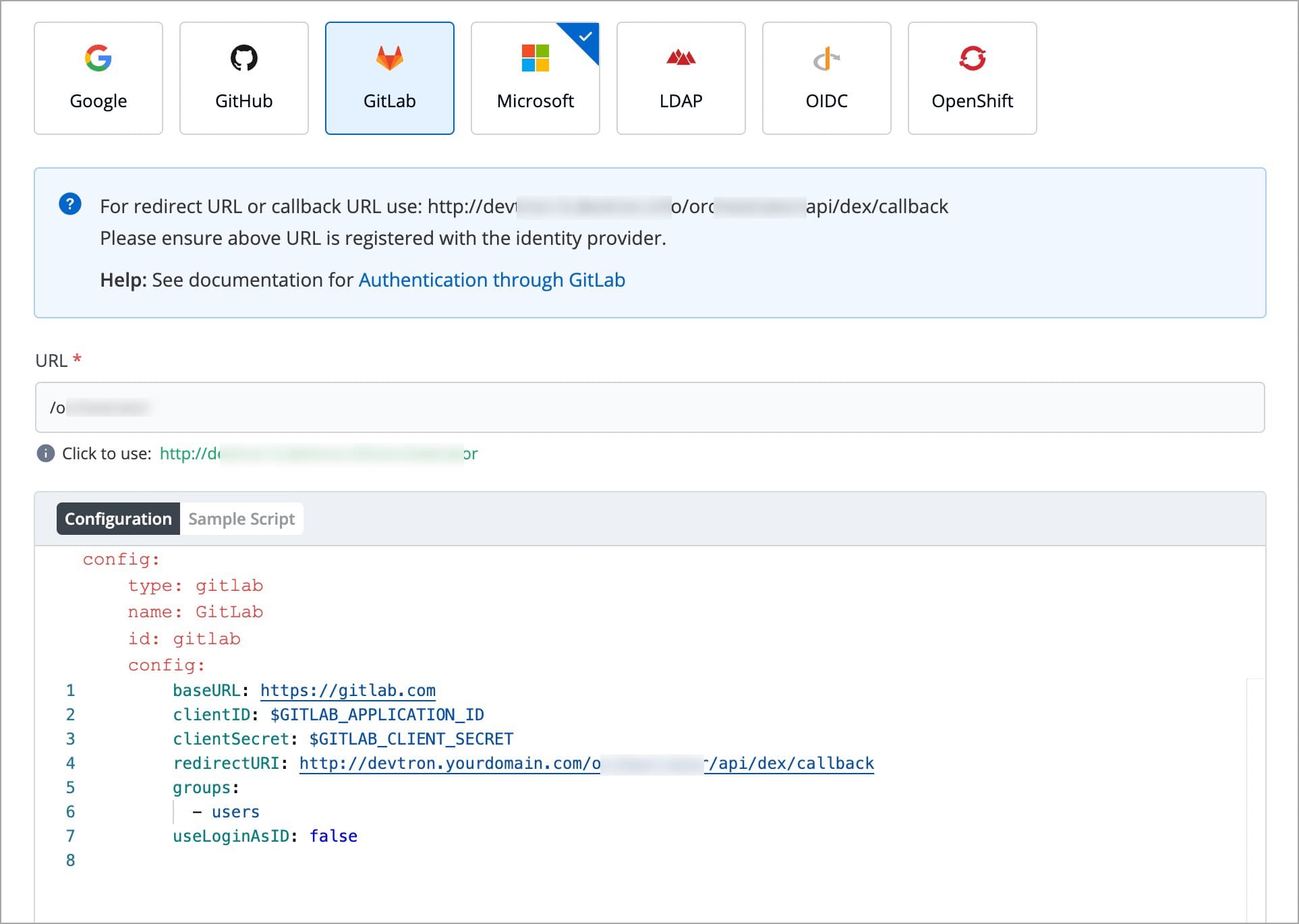
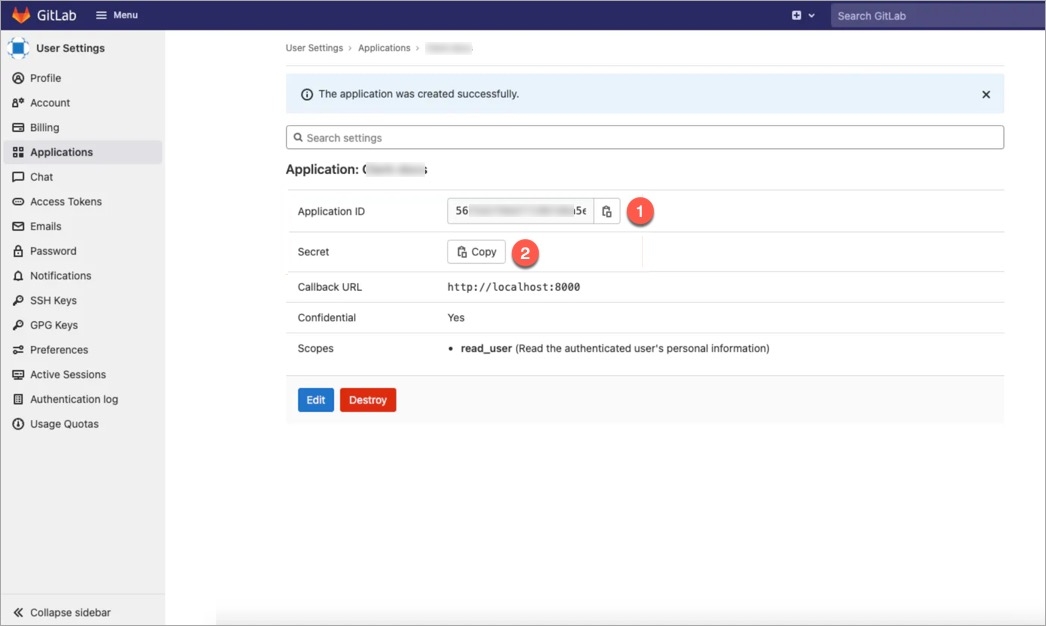
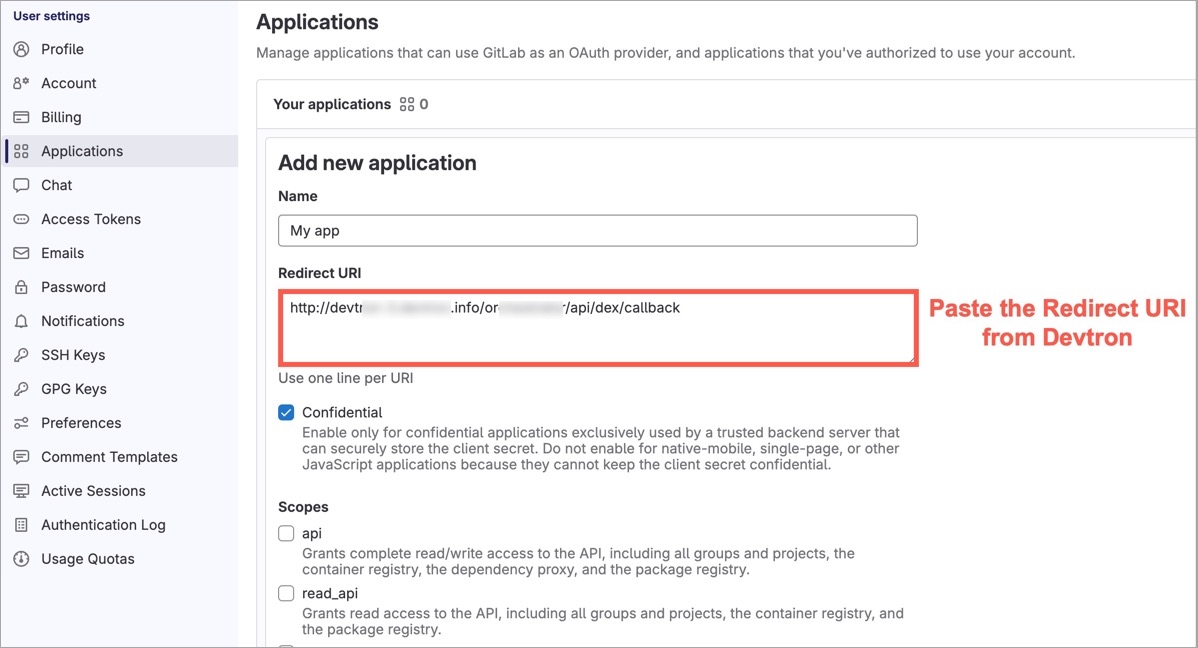
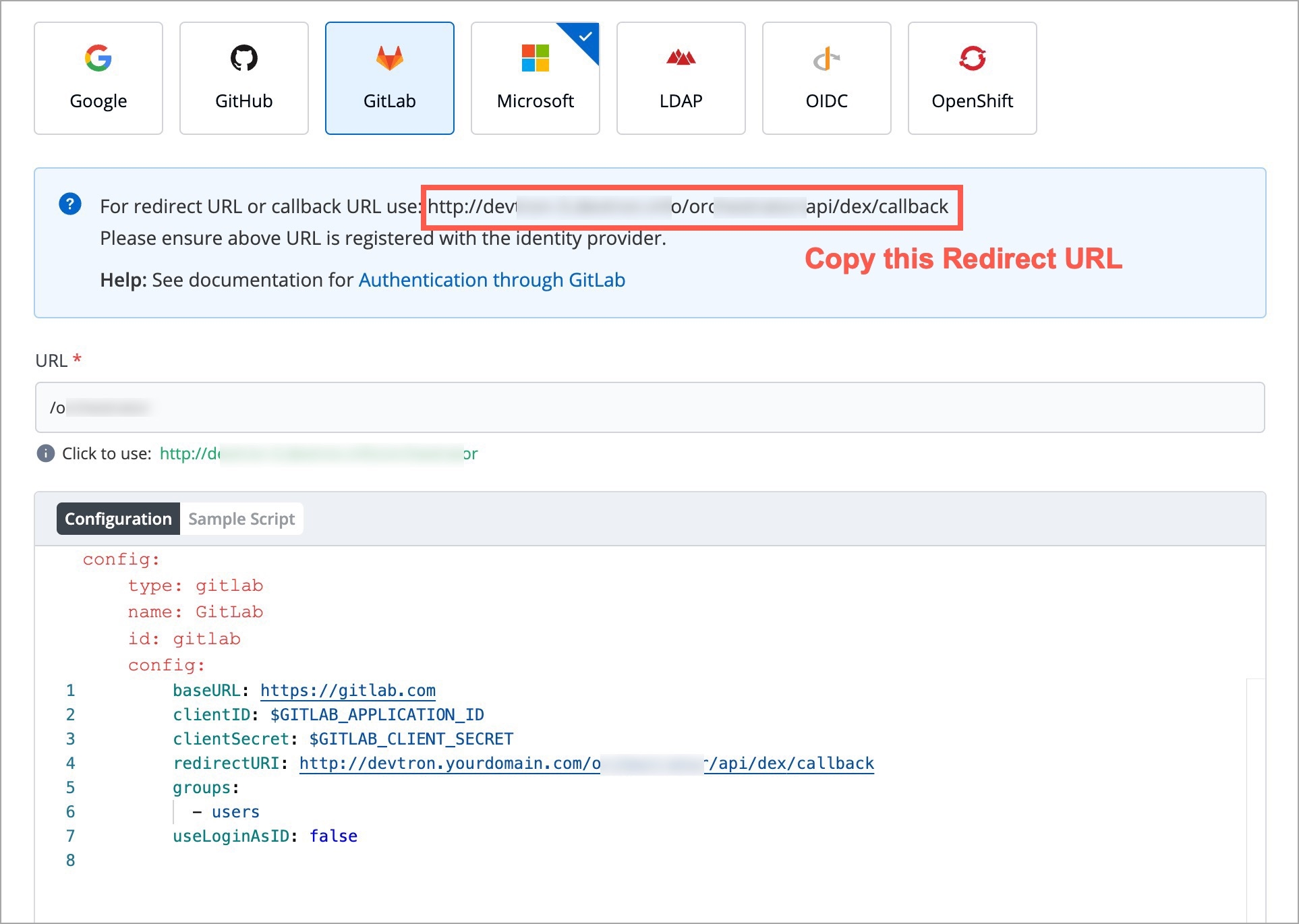
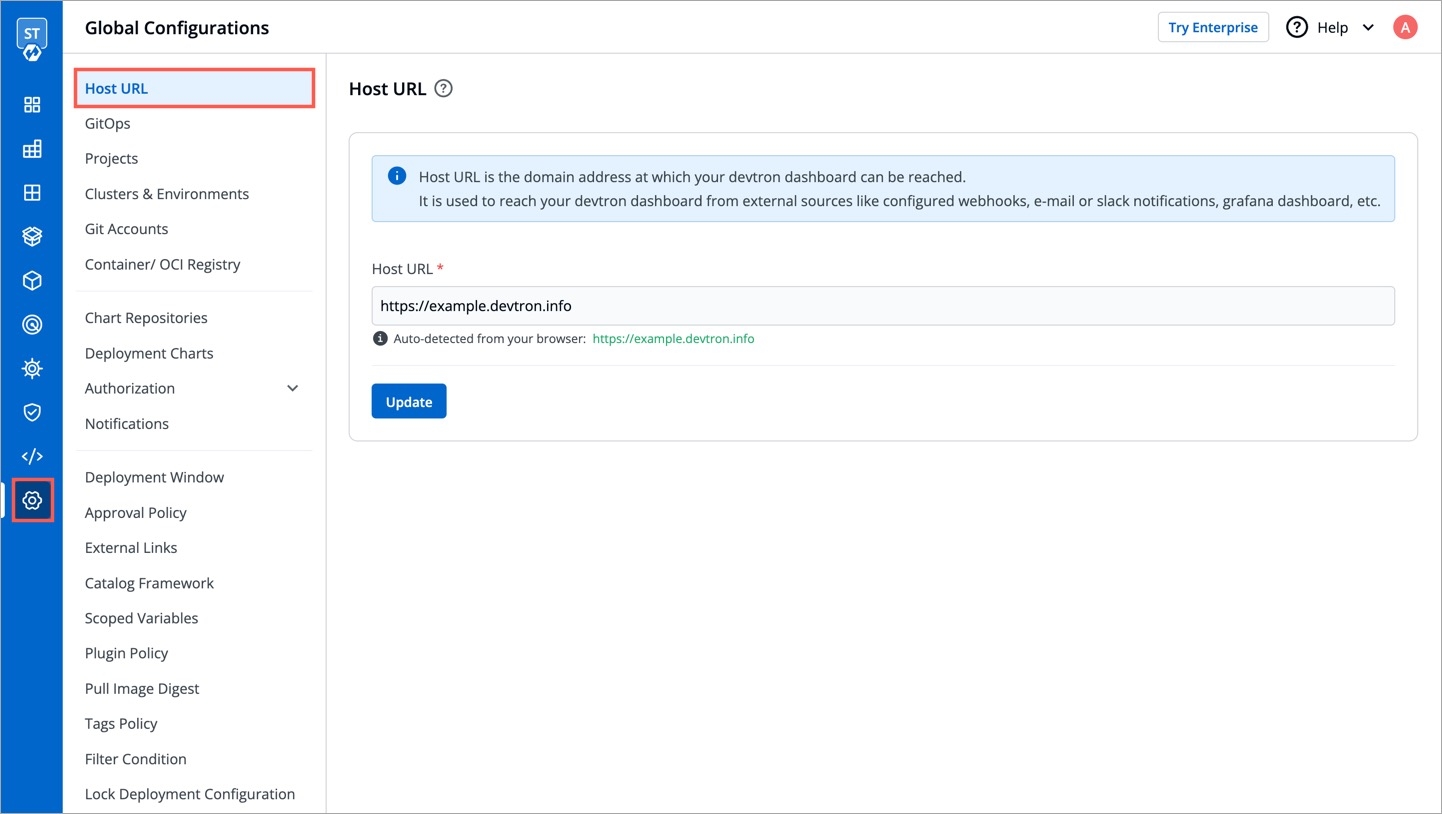
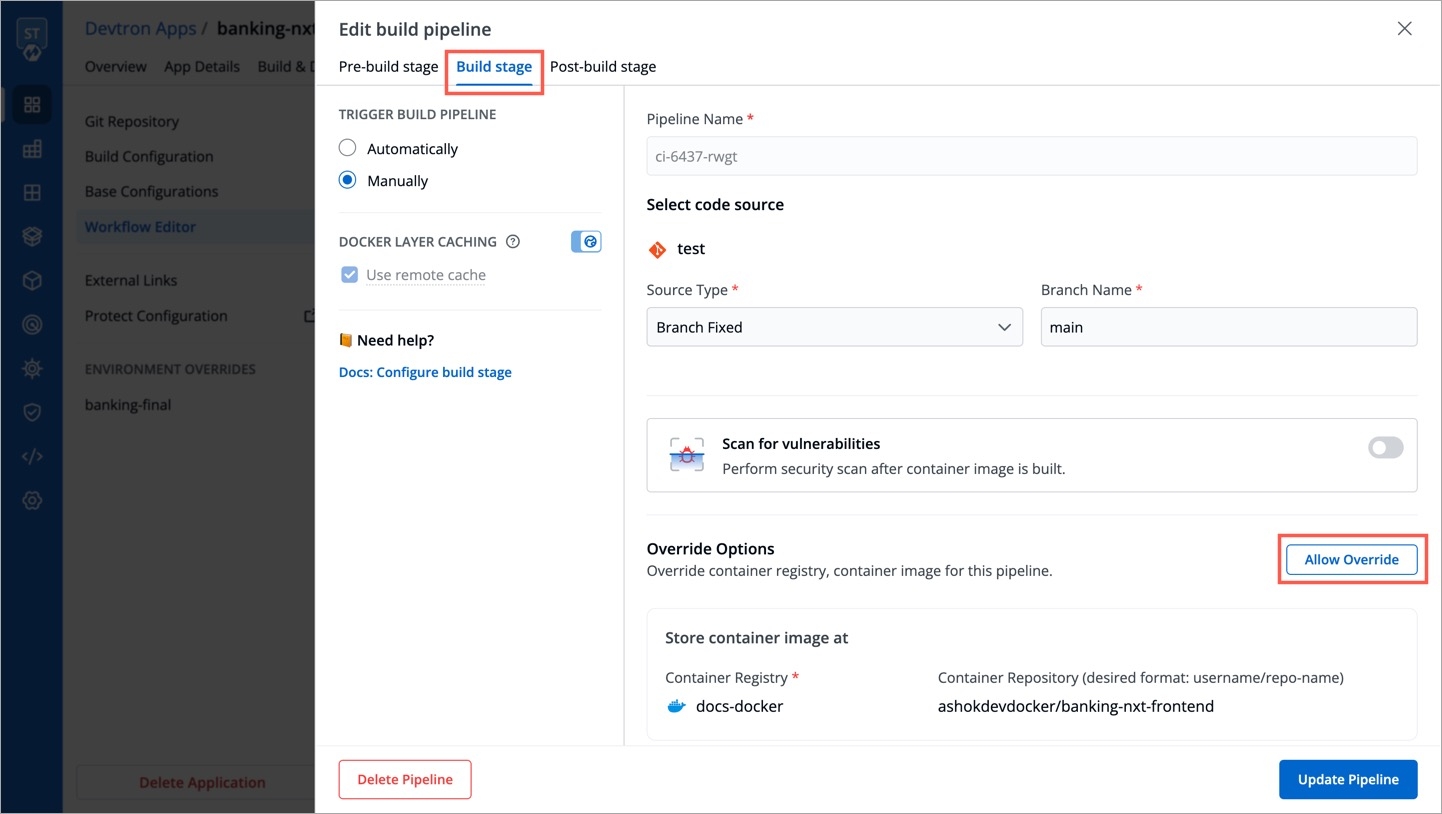
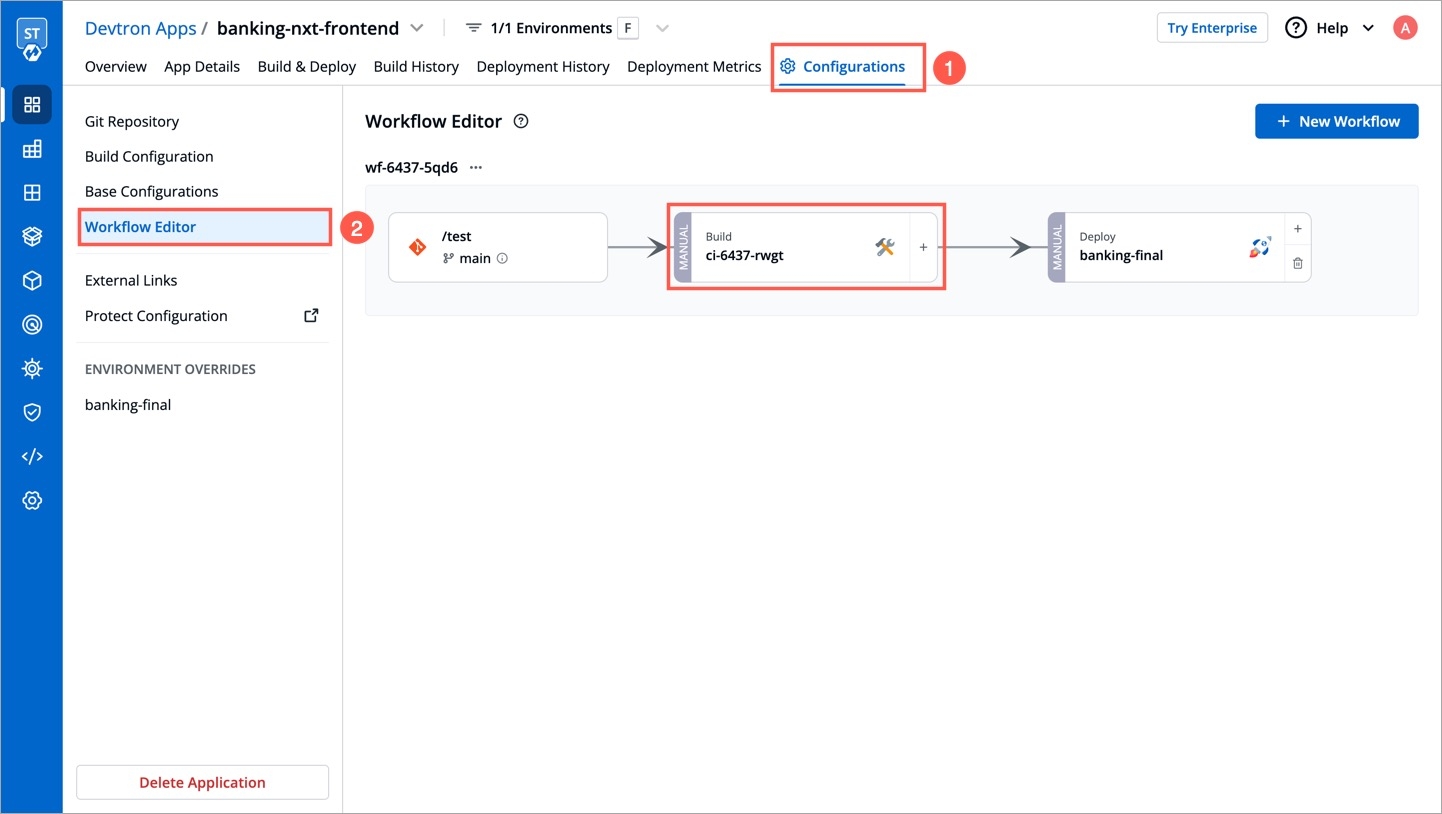
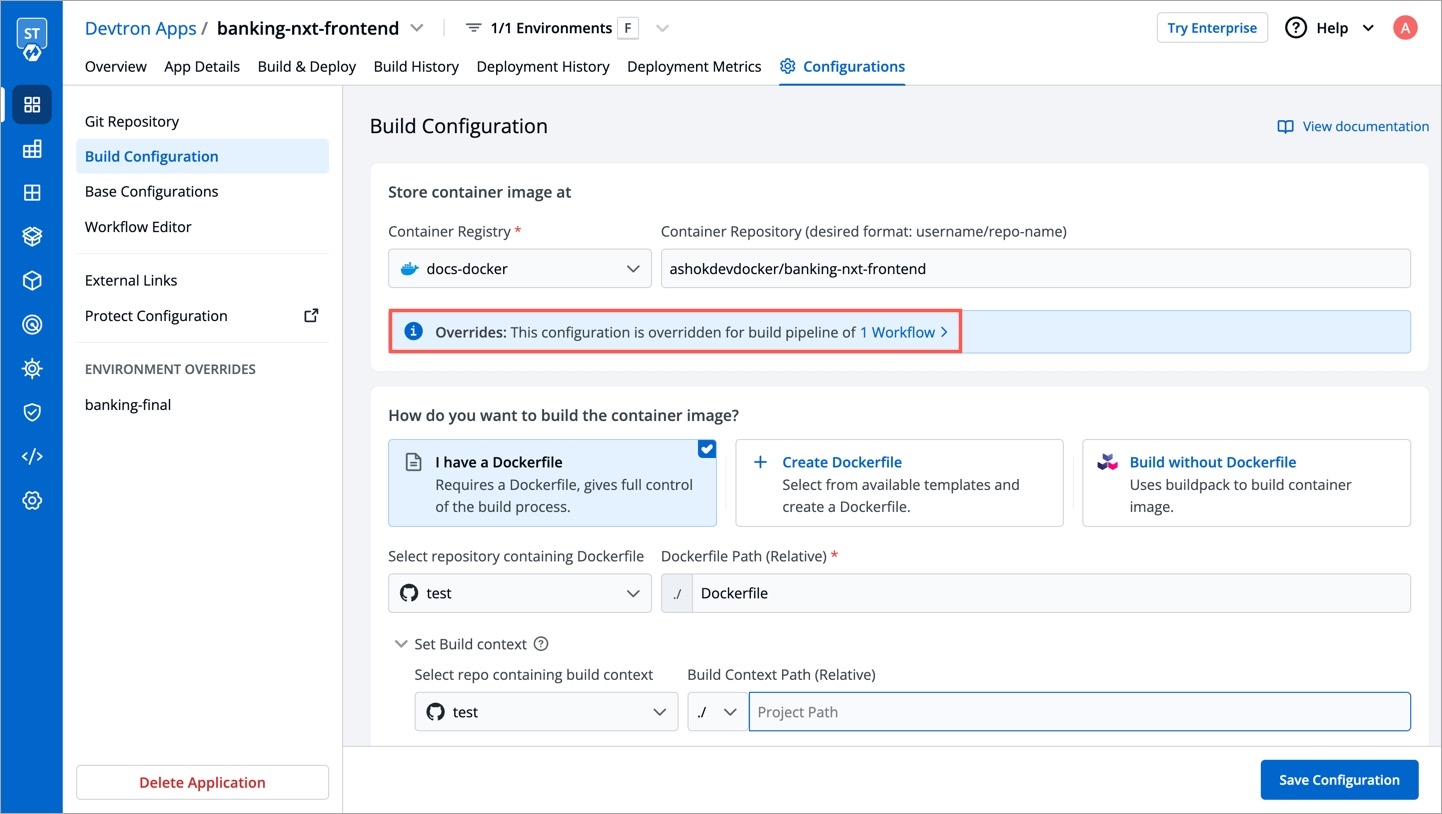
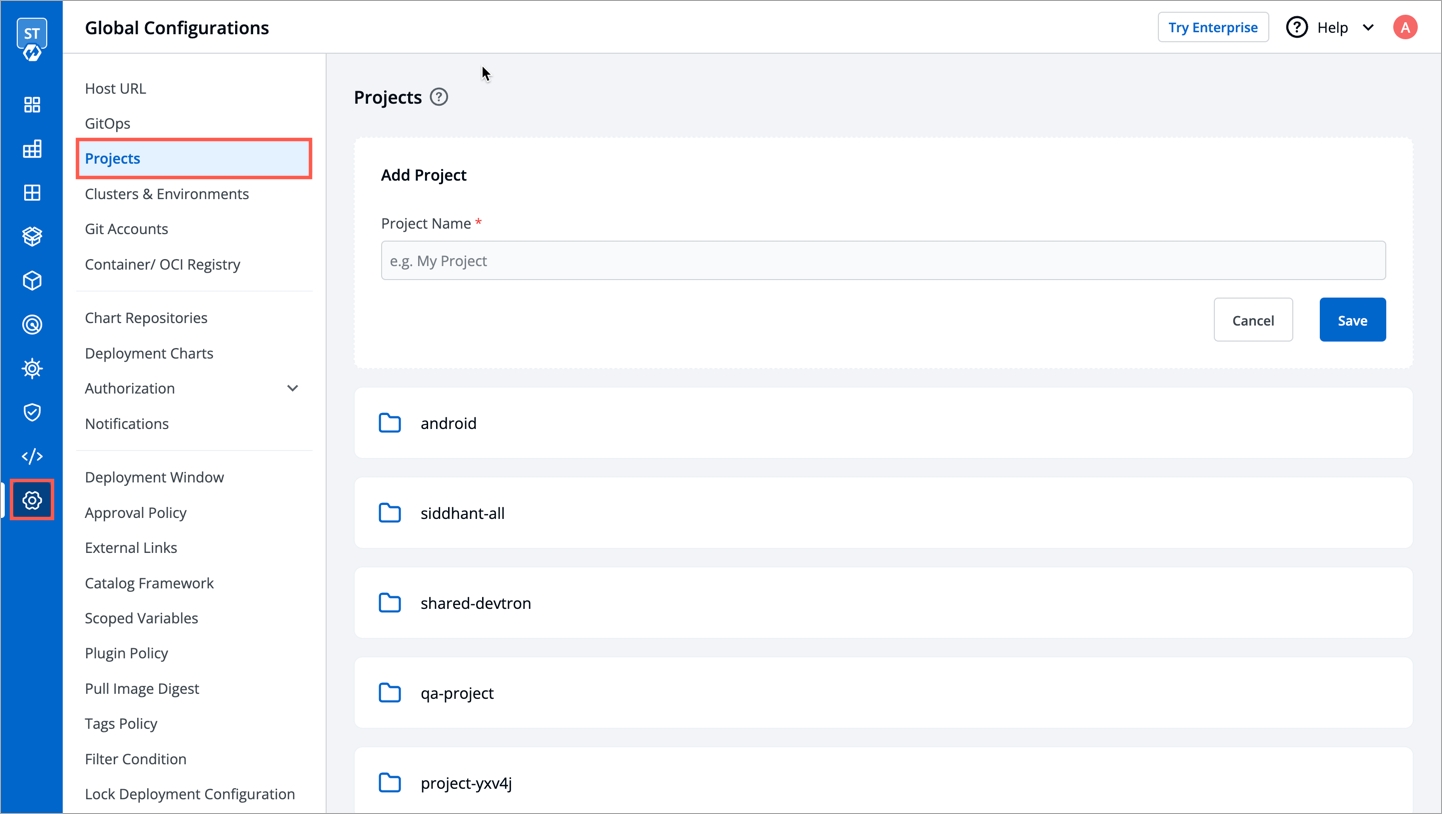
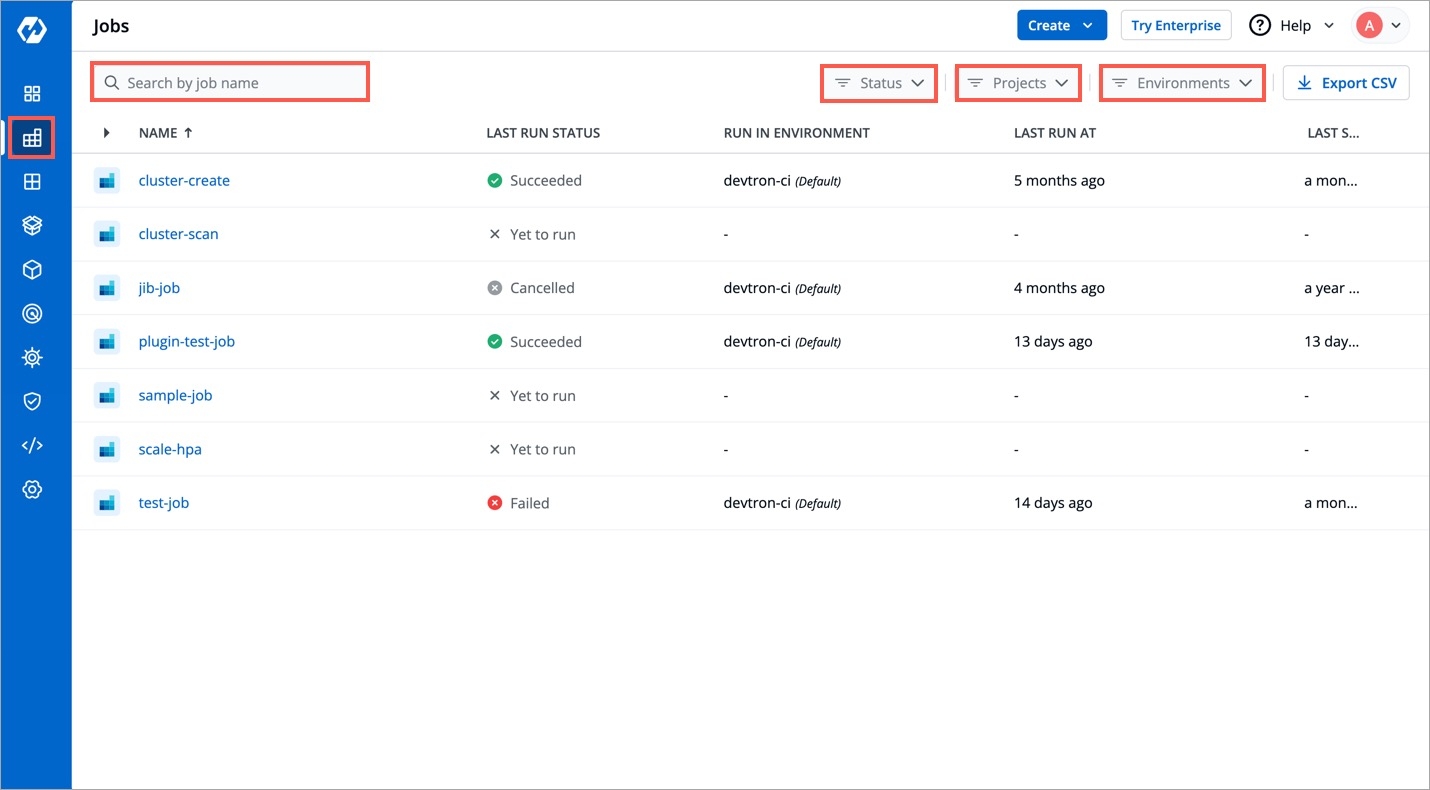
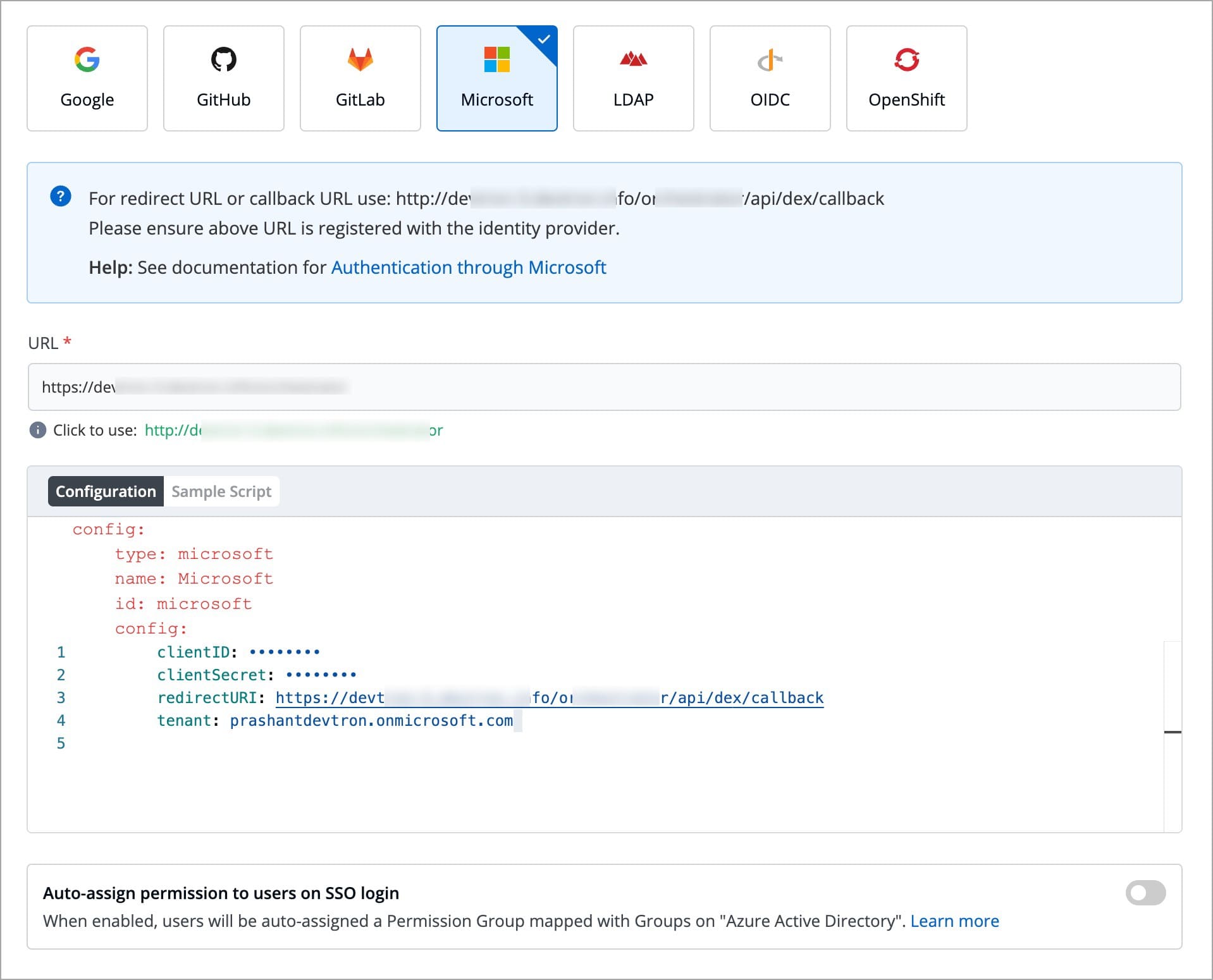
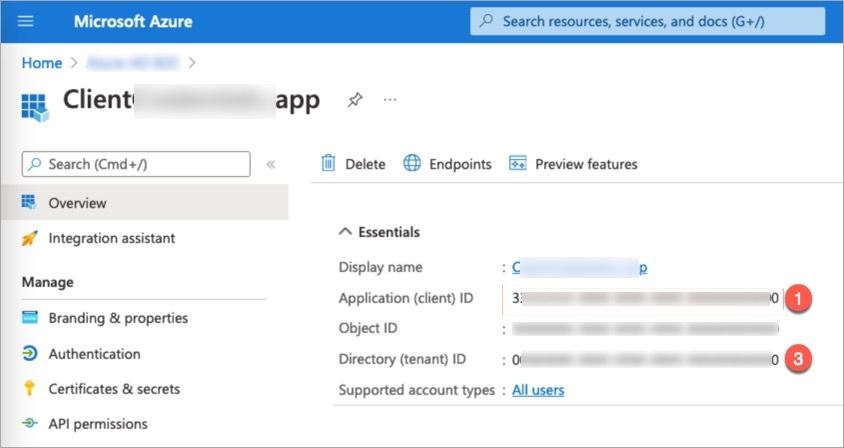
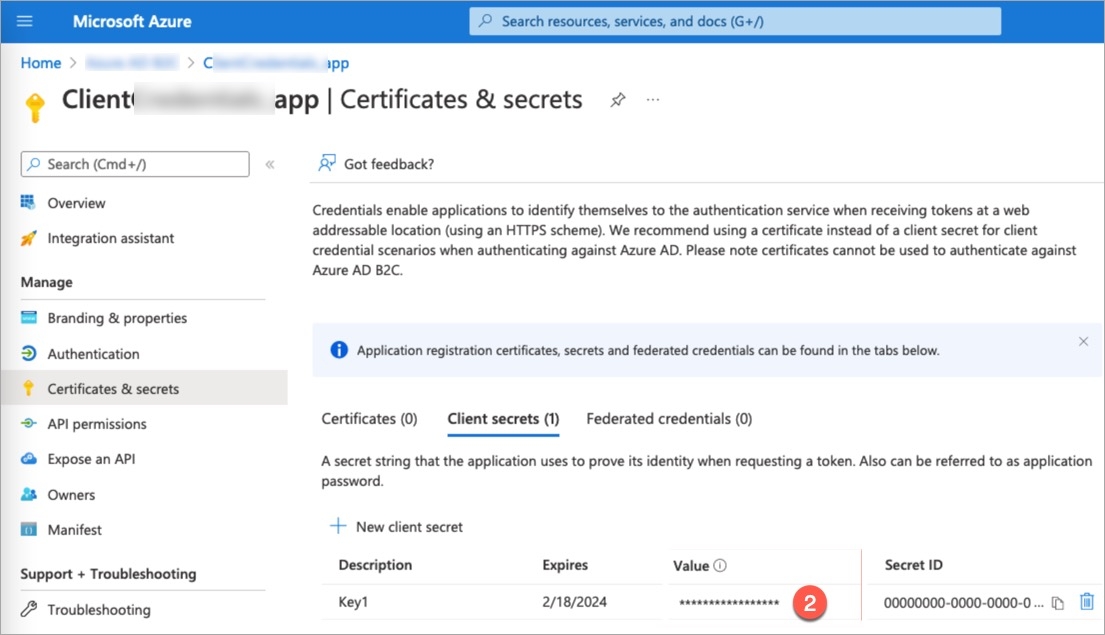
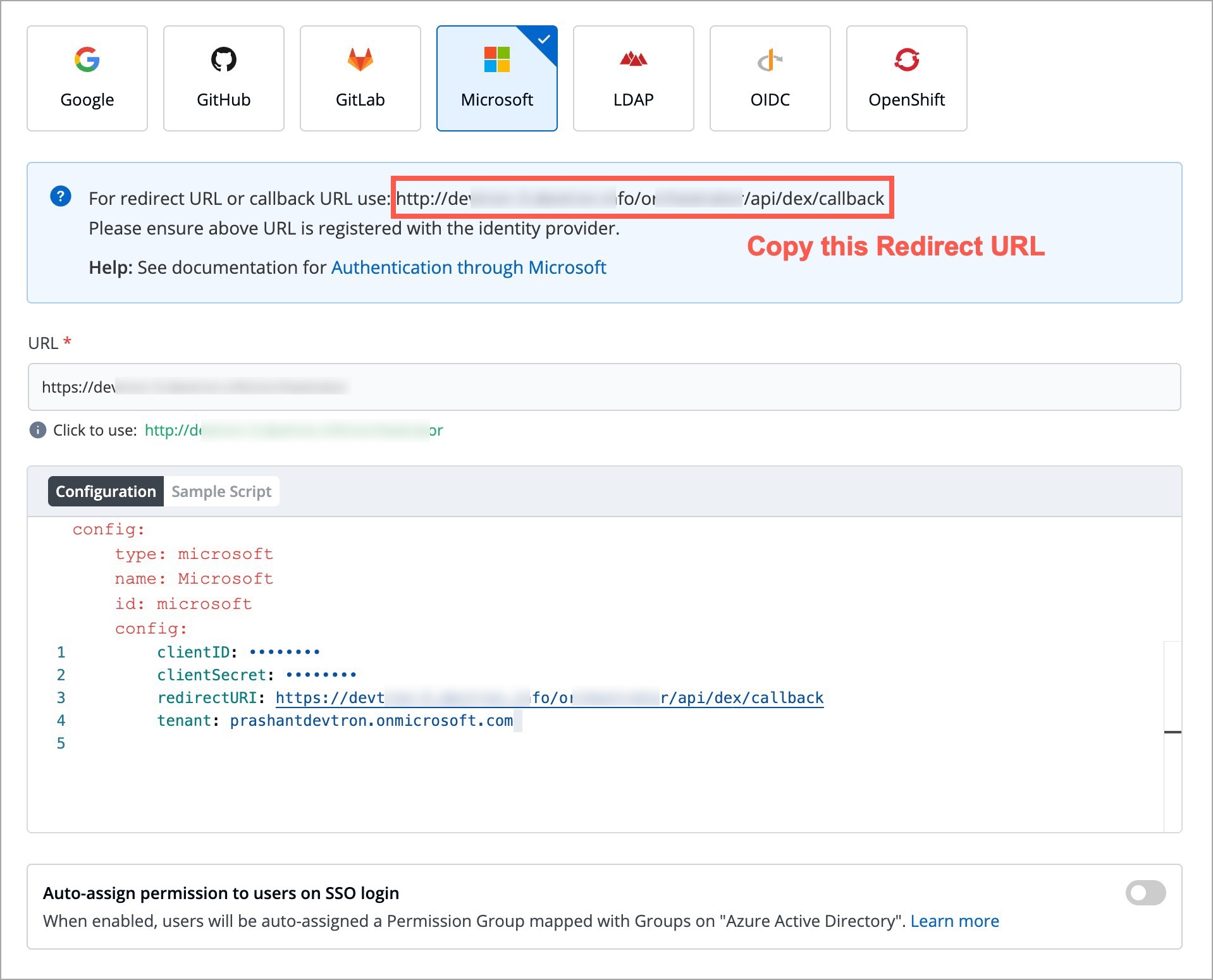
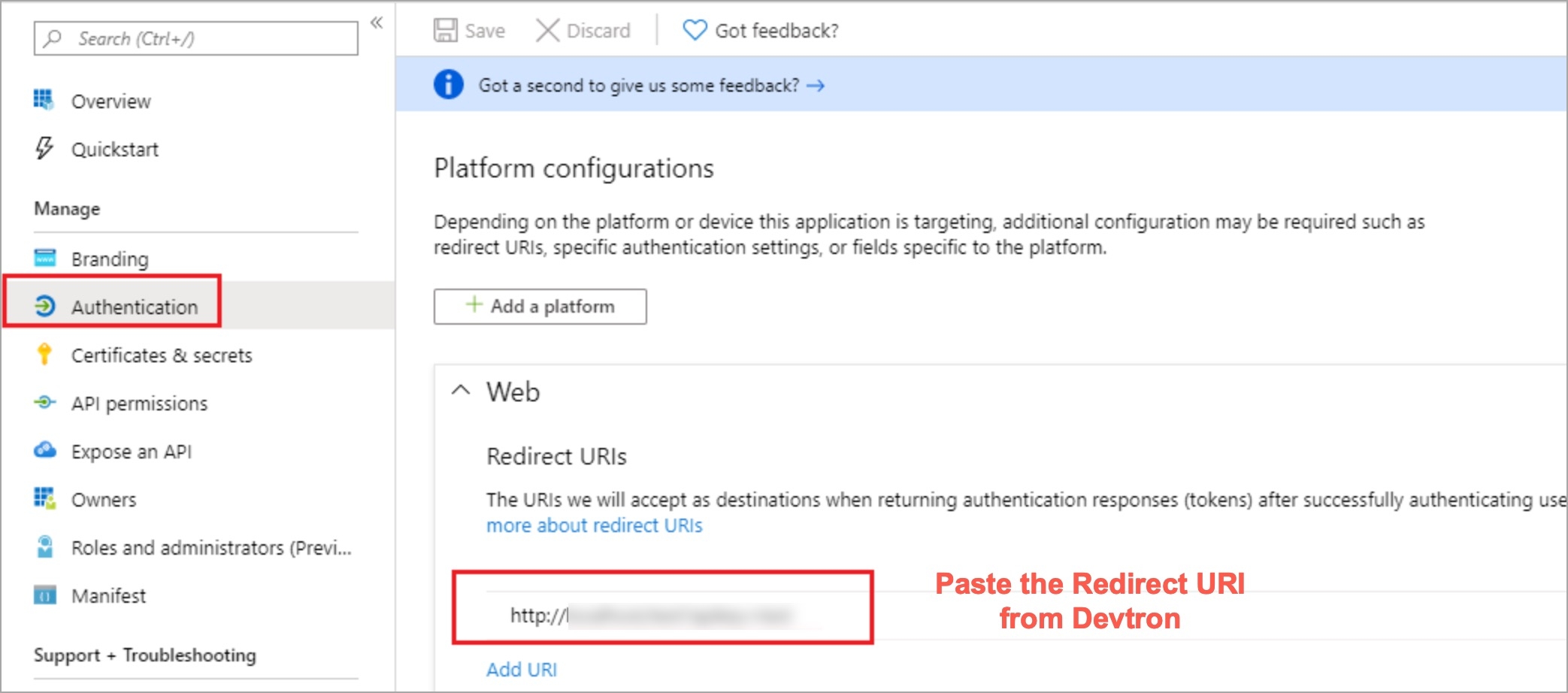
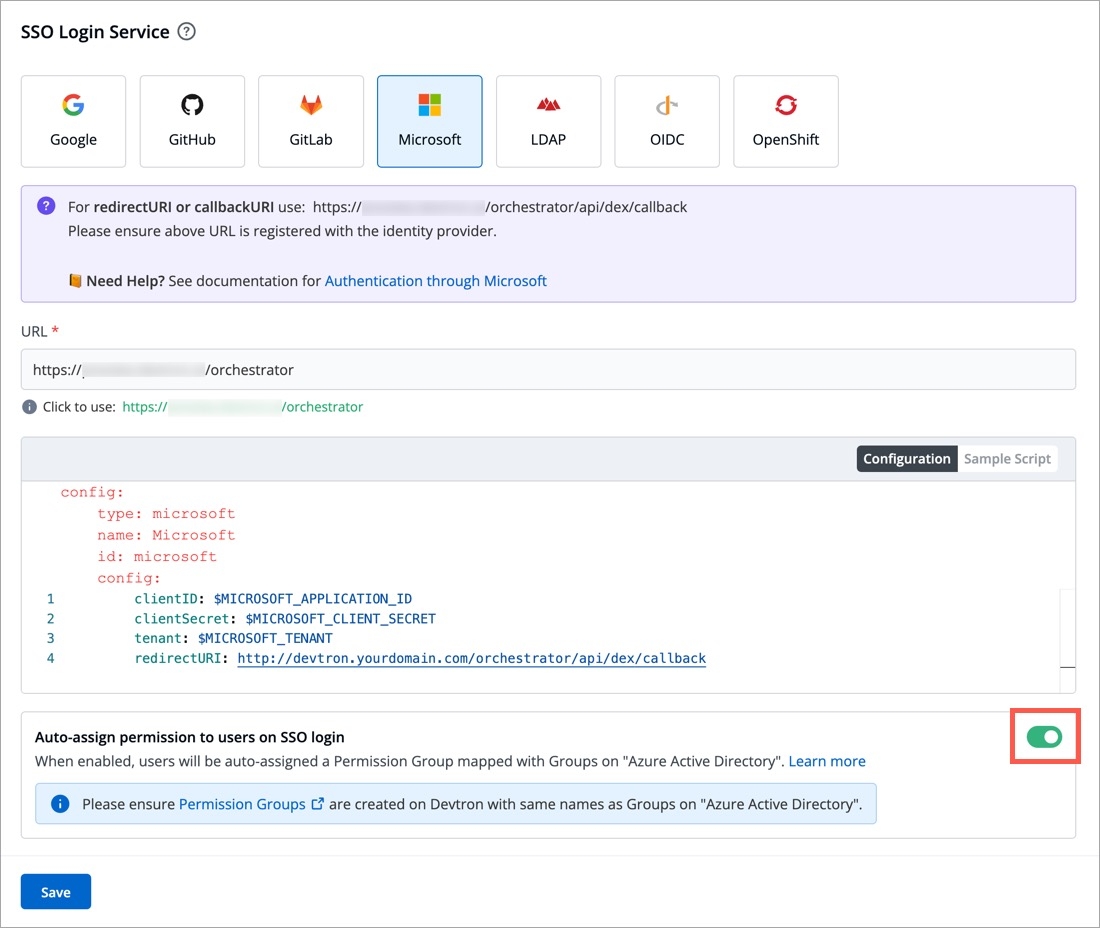
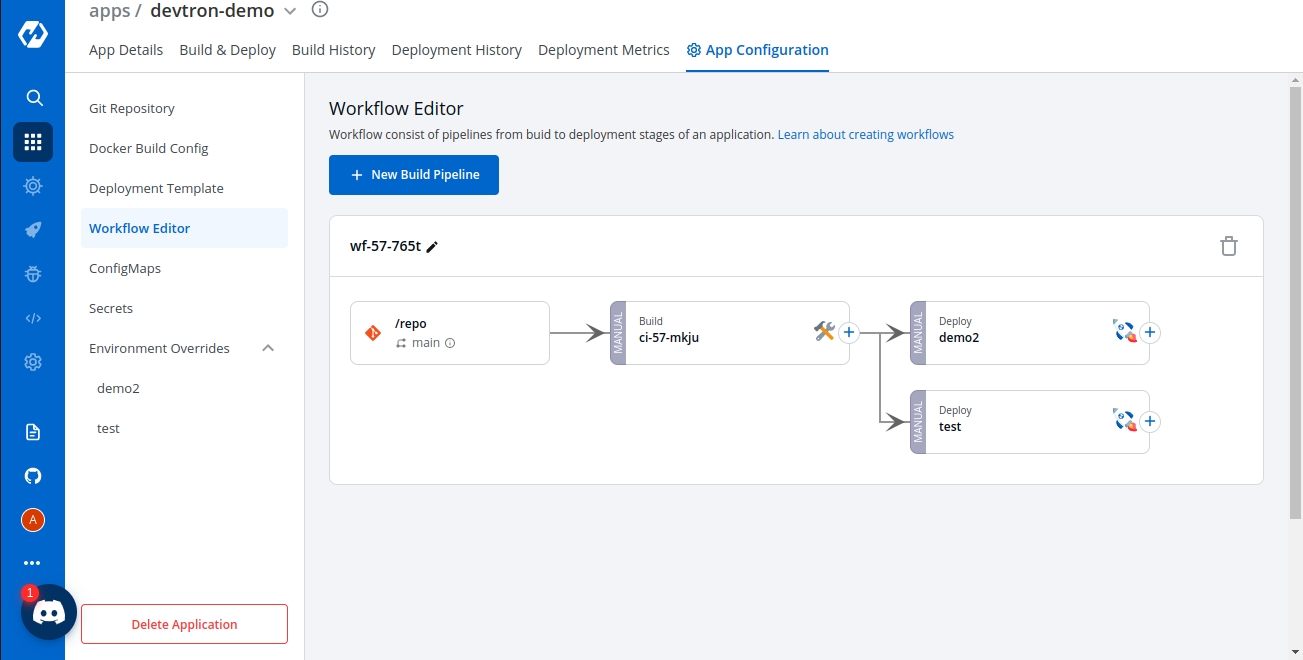
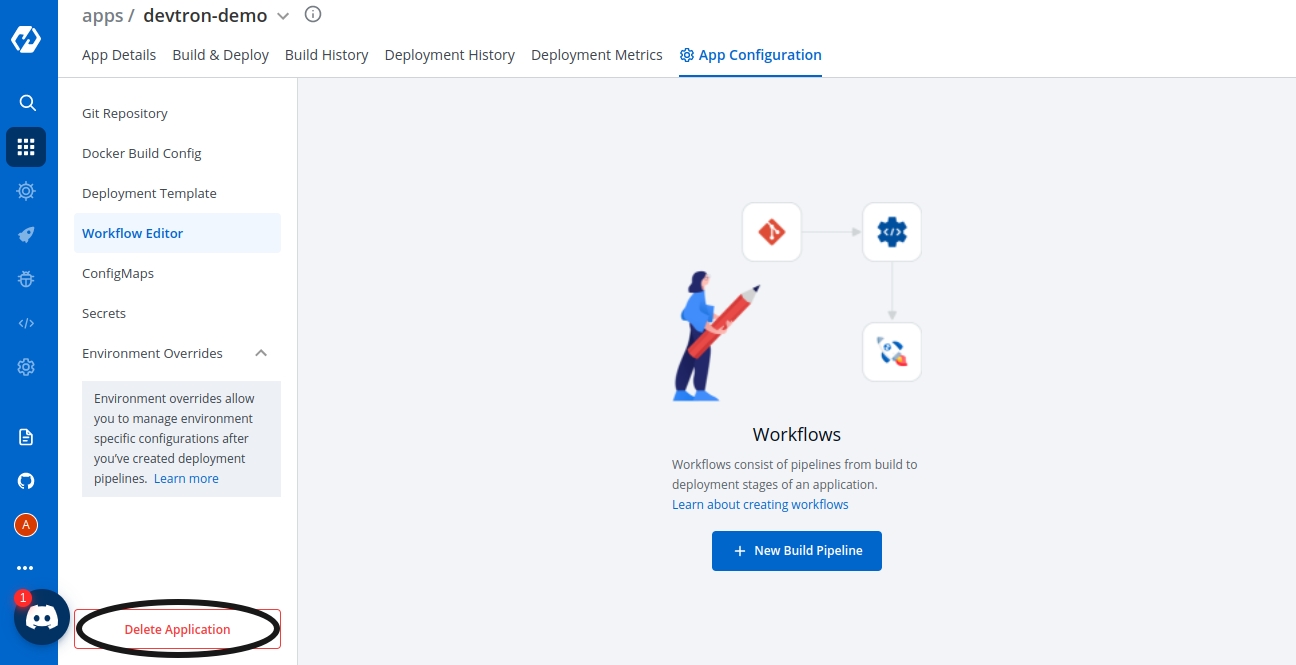
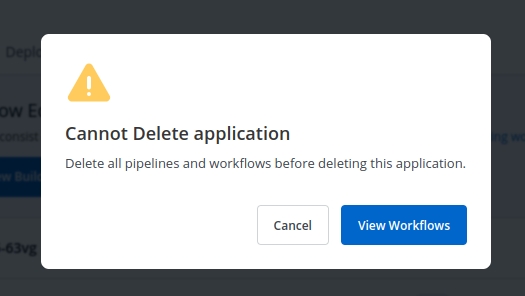
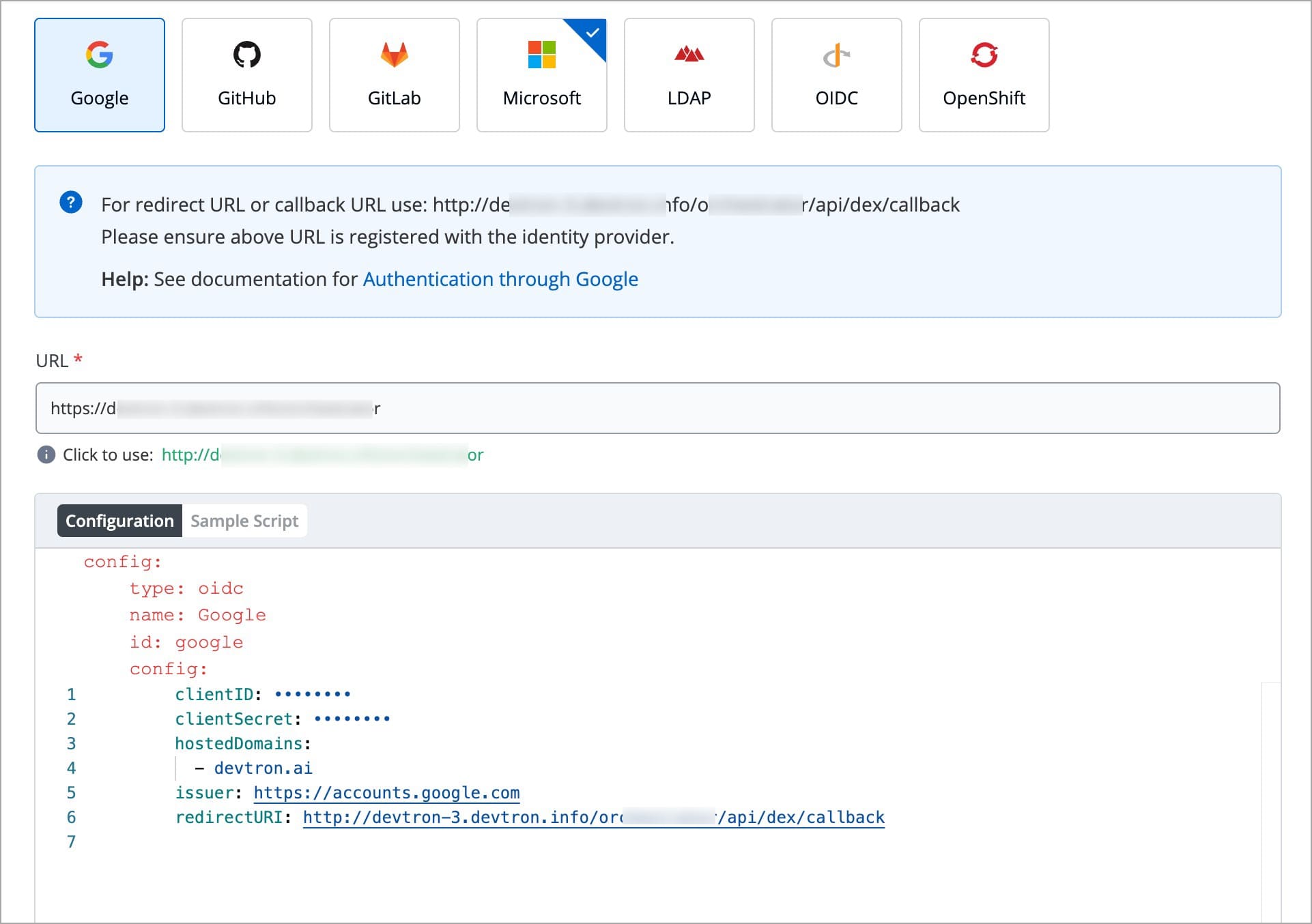
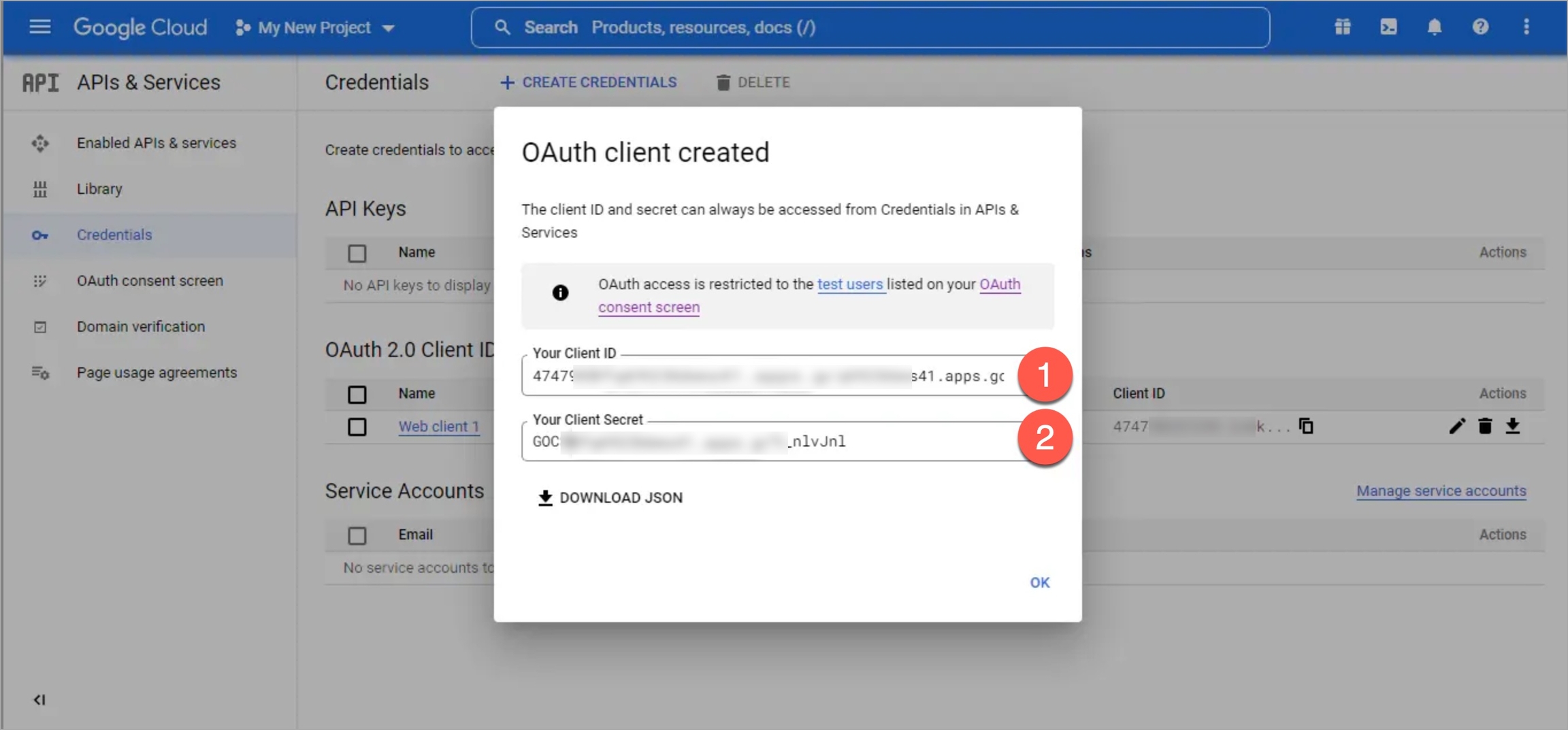
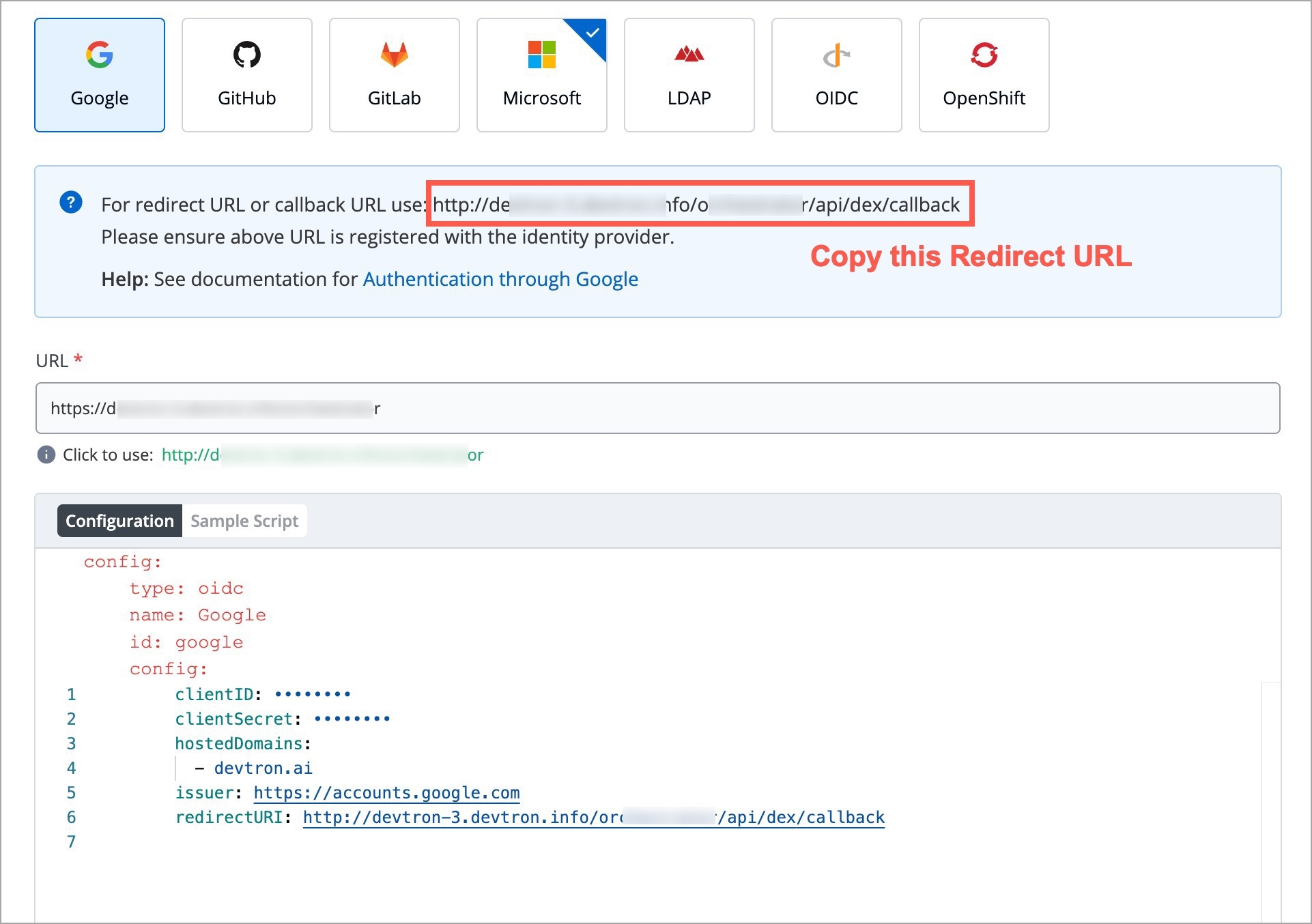
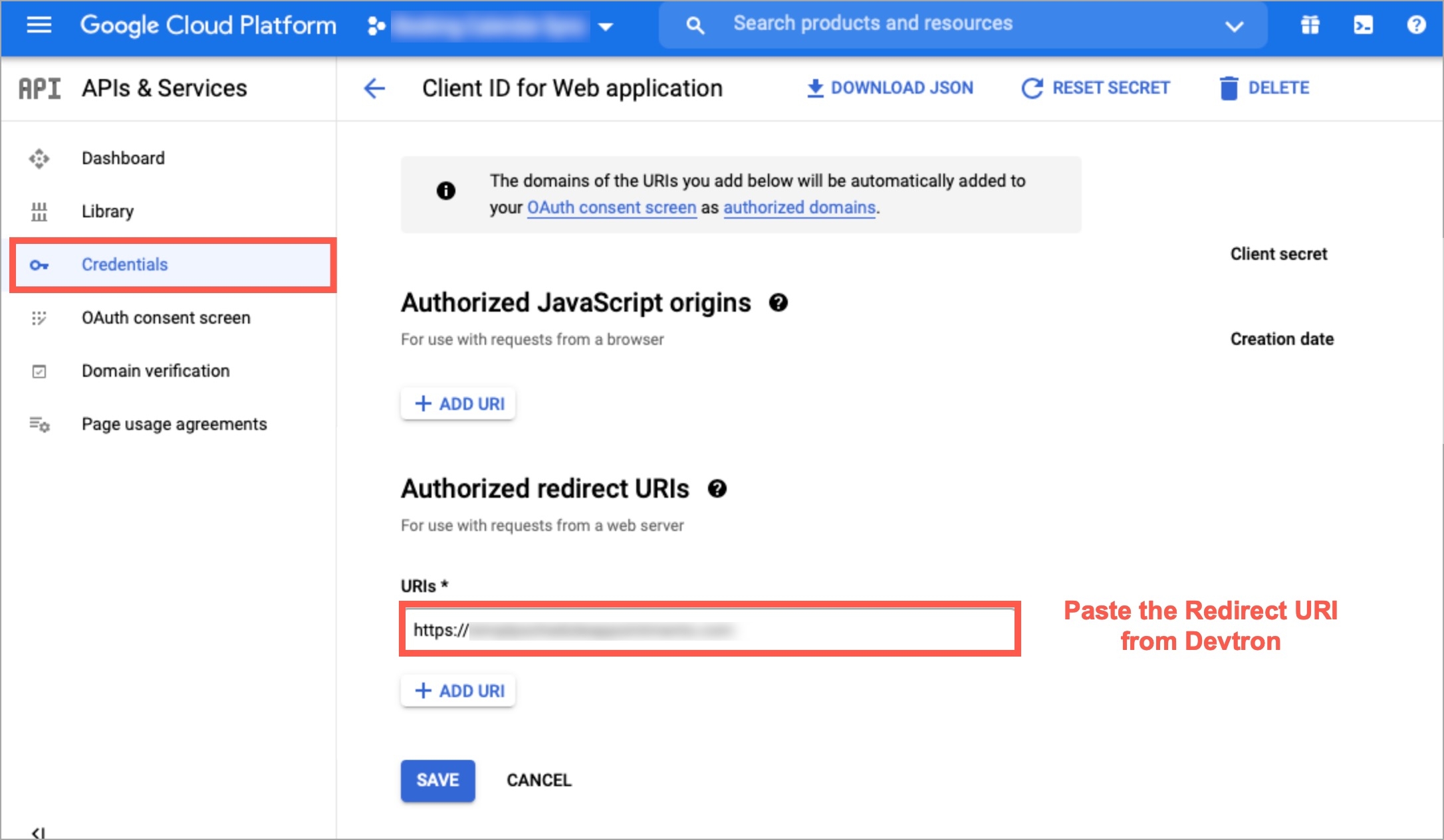
!README.md
Exclusion of a single file in root folder: Commits containing changes made only in README.md file will not be shown
!README.md
!index.js
Exclusion of multiple files in root folder: Commits containing changes made only in README.md or/and index.js files will not be shown
README.md
Inclusion of a single file in root folder: Commits containing changes made only in README.md file will be shown. Rest all will be excluded.
!src/extensions/printer/code2.py
Exclusion of a single file in a folder tree: Commits containing changes made specifically to code2.py file will not be shown
!src/*
Exclusion of a single folder and all its files: Commits containing changes made specifically to files within src folder will not be shown
!README.md
index.js
Exclusion and inclusion of files: Commits containing changes made only in README.md will not be shown, but commits made in index.js file will be shown. All other commits apart from the aforementioned files will be excluded.
!README.md
README.md
Exclusion and inclusion of conflicting files: If conflicting paths are defined in the rule, the one defined later will be considered. In this case, commits containing changes made only in README.md will be shown.
helm create my-custom-chartName
Name of the helm chart (Required).
Version
This is the chart version. Update this value for each new version of the chart (Required).
Description
Description of the chart (Optional).
{
"server": {
"deployment": {
"image_tag": "{{.Tag}}",
"image": "{{.Name}}"
}
},
"pipelineName": "{{.PipelineName}}",
"releaseVersion": "{{.ReleaseVersion}}",
"deploymentType": "{{.DeploymentType}}",
"app": "{{.App}}",
"env": "{{.Env}}",
"appMetrics": {{.AppMetrics}}
}image_tag
The build image tag
image
Repository name
pipelineName
The CD pipeline name created in Devtron
releaseVersion
Devtron's internal release number
deploymentType
Deployment strategy used in the pipeline
app
Application's ID within the Devtron ecosystem
env
Environment used to deploy the chart
appMetrics
For the App metrics UI feature to be effective, include the appMetrics placeholder.
{
"image": {
"repository": "{{.Name}}",
"tag": "{{.Tag}}"
}
}helm package my-custom-chartSuccess
The files uploaded are validated.
Enter a description for the chart and select Save or Cancel upload.
Unsupported template
The archive file do not match the required template.
Upload another chart or Cancel upload.
New version detected
You are uploading a newer version of an existing chart
Enter a Description and select Save to continue uploading, or Cancel upload.
Already exists
There already exists a chart with the same version.
Edit the version and re-upload the same chart using Upload another chart.
Upload a new chart with a new name using Upload another chart.
Cancel upload.
devtctl create imagePromotionPolicy \
--name="example-policy" \
--description="This is a sample policy that promotes an image to production environment" \
--passCondition="true" \
--failCondition="false" \
--approverCount=0 \
--allowRequestFromApprove=false \
--allowImageBuilderFromApprove=false \
--allowApproverFromDeploy=false \
--applyPath="path/to/applyPolicy.yaml"```yaml
apiVersion: v1
kind: artifactPromotionPolicy
spec:
payload:
applicationEnvironments:
- appName: "app1"
envName: "env-demo"
- appName: "app1"
envName: "env-staging"
- appName: "app2"
envName: "env-demo"
applyToPolicyName: "example-policy"
```Here, `applicationEnvironments` is a dictionary that contains the application names (app1, app2) and the corresponding environment names (env-demo/env-staging) where the policy will apply. In the `applyToPolicyName` key, enter the value of the `name` argument you used earlier while [creating the policy](#creating-an-image-promotion-policy).devtctl apply policy -p="path/to/applyPolicy.yaml"

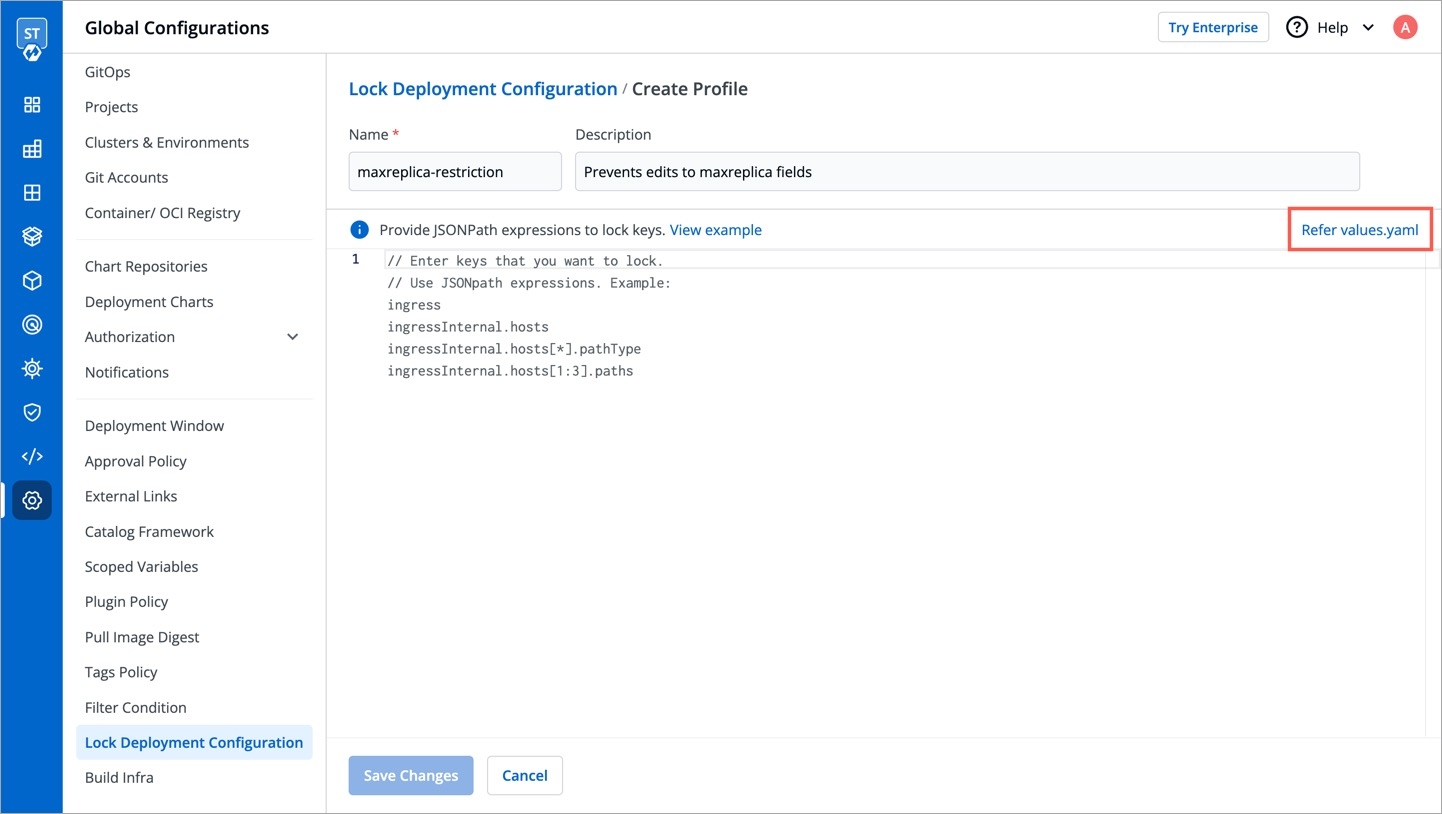
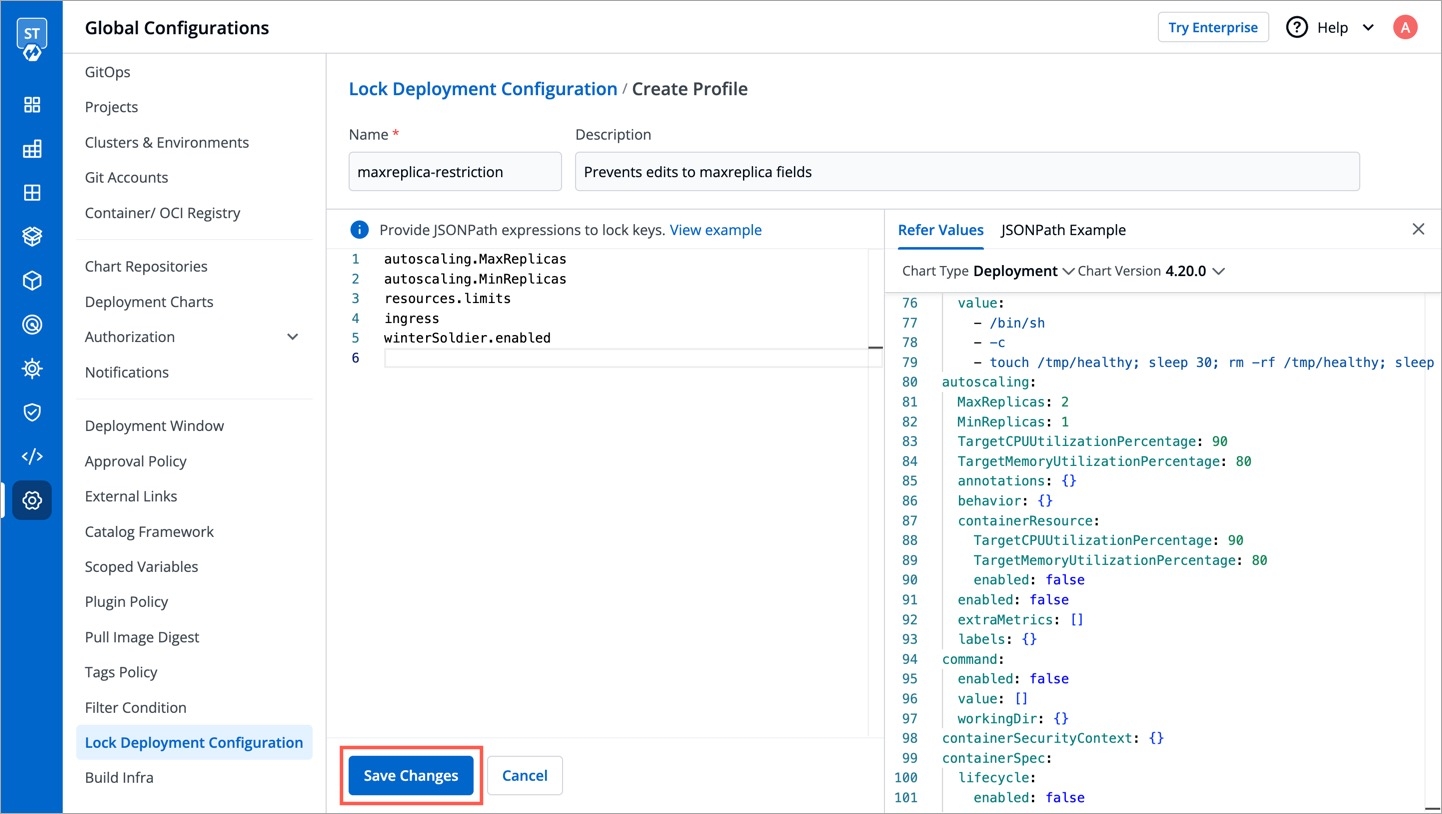
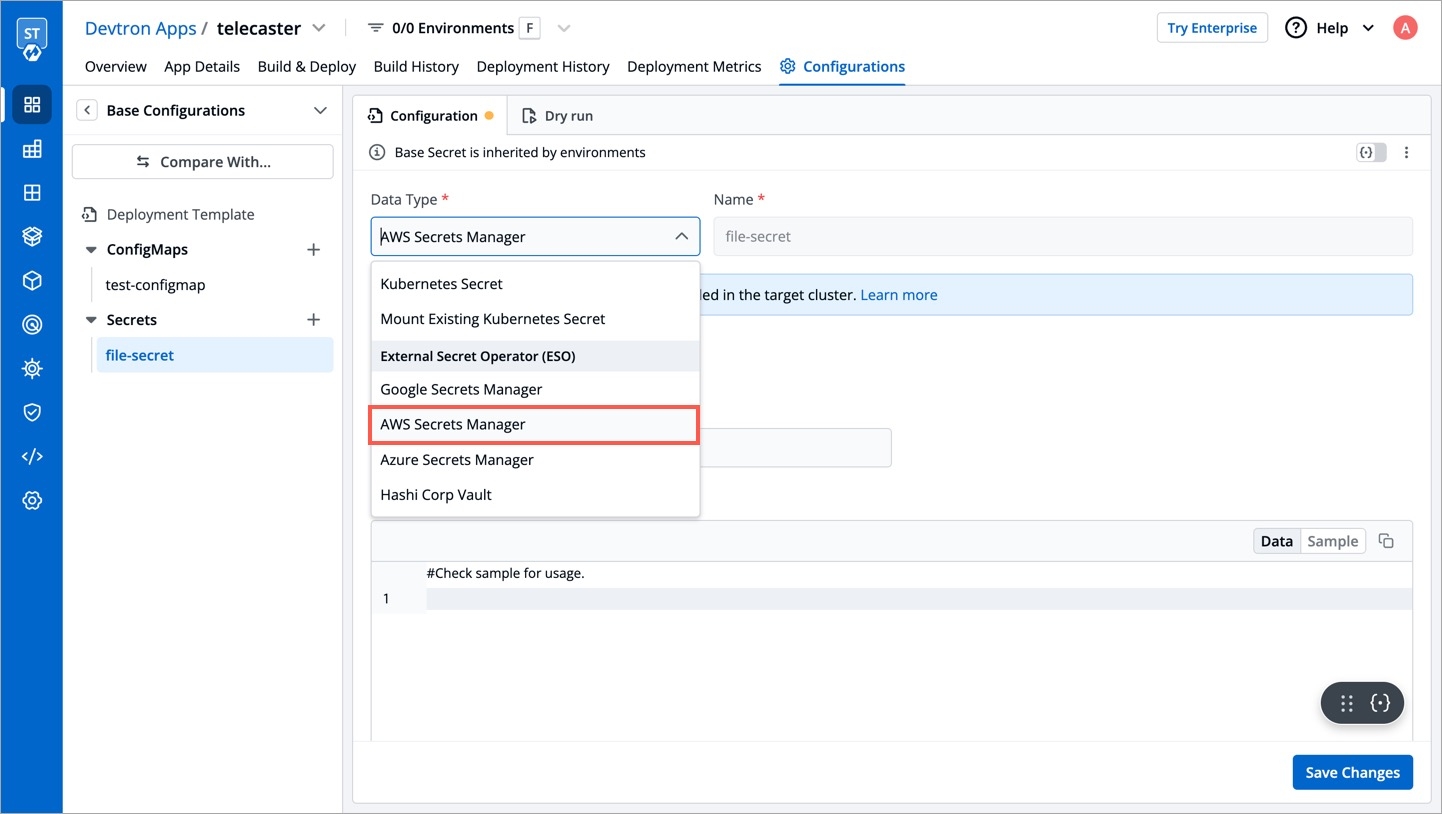
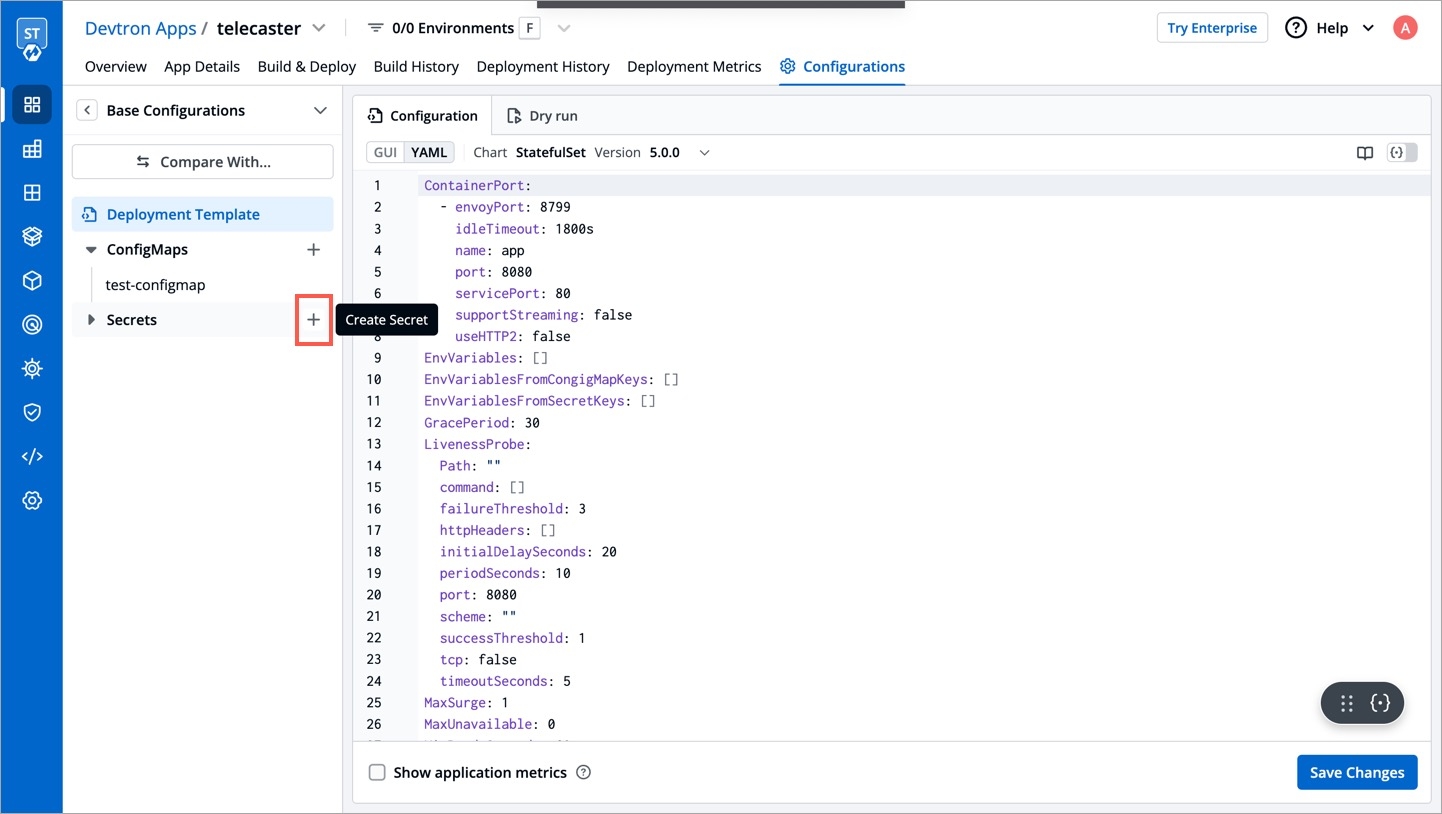
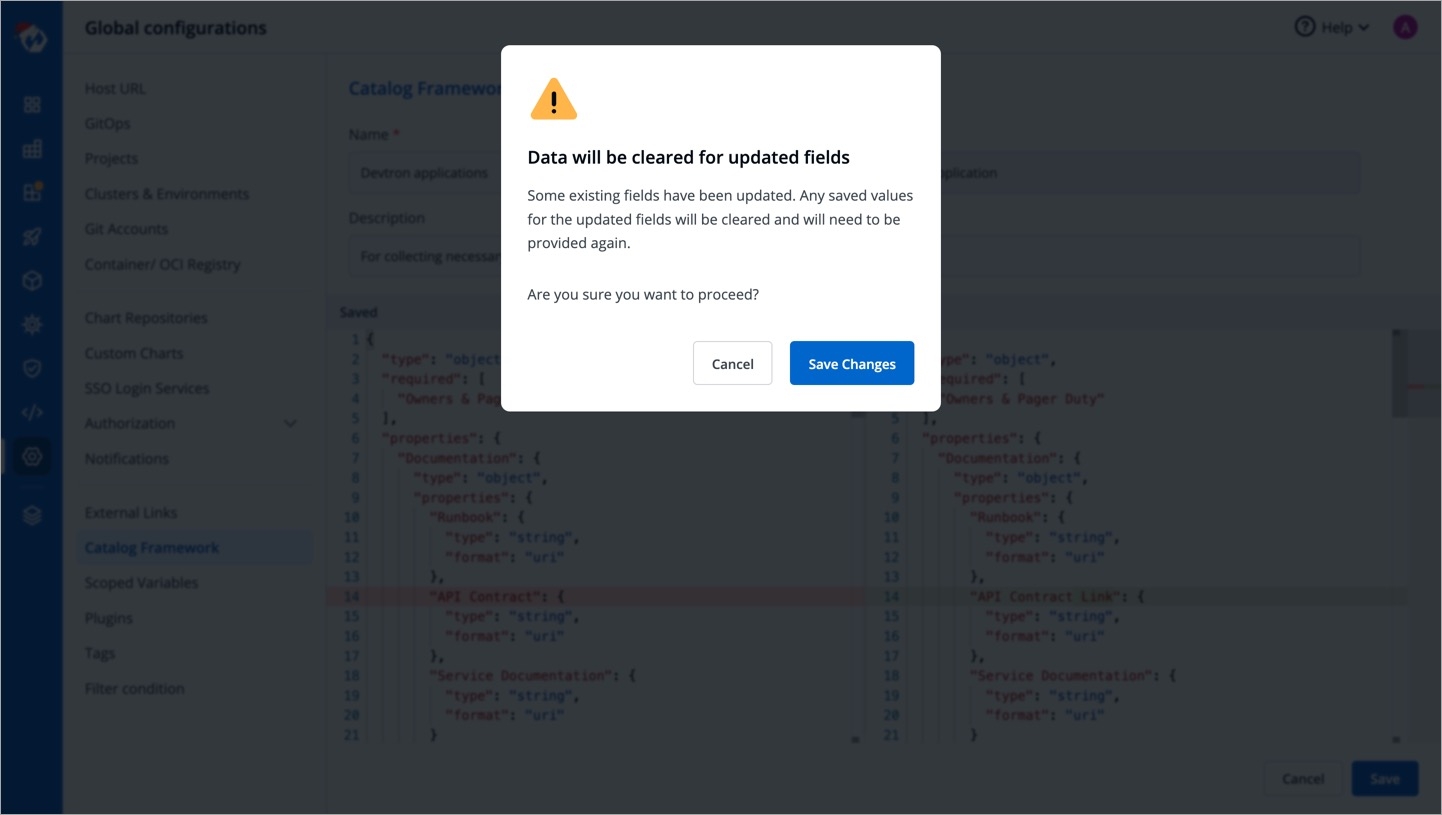
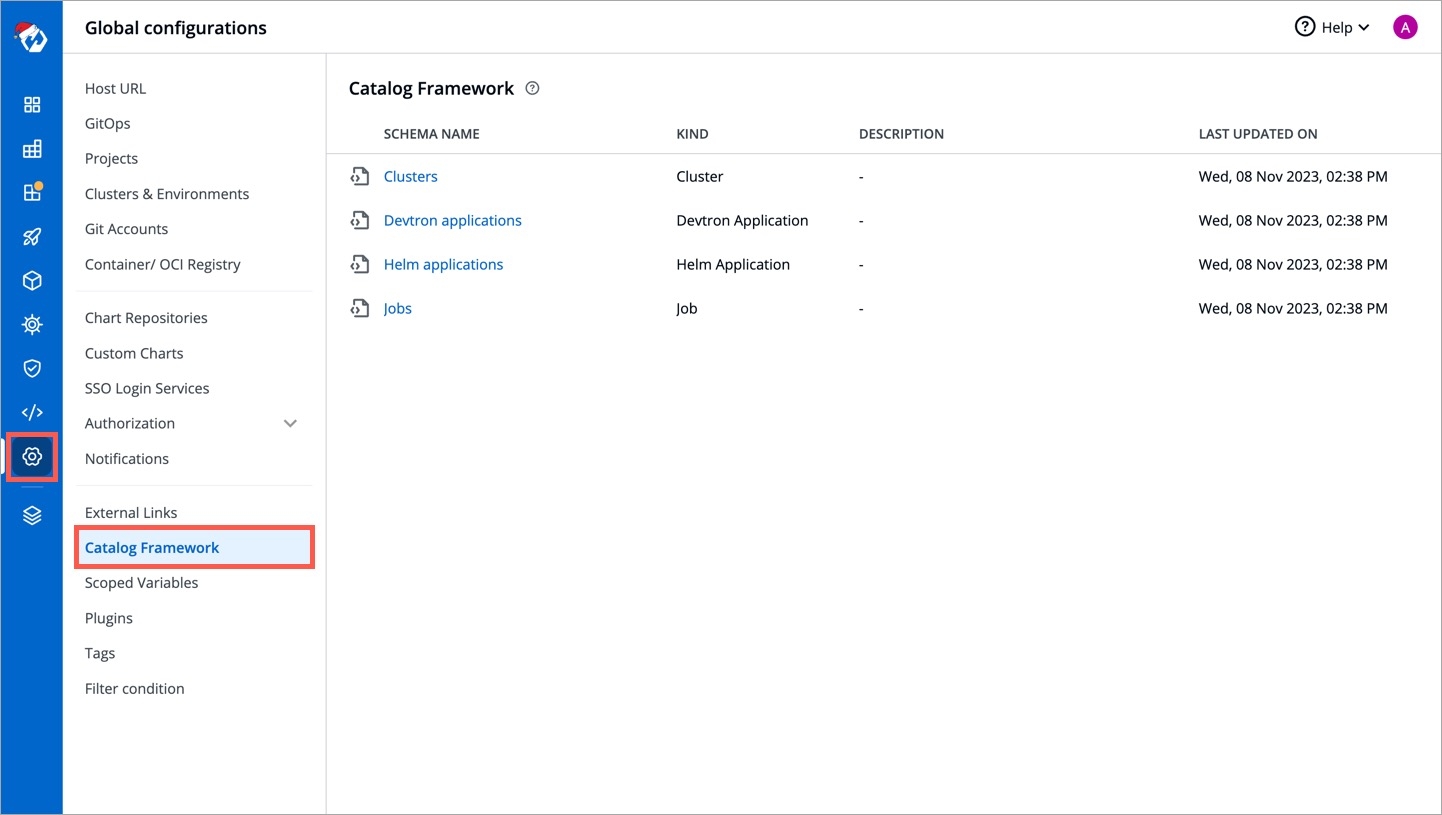
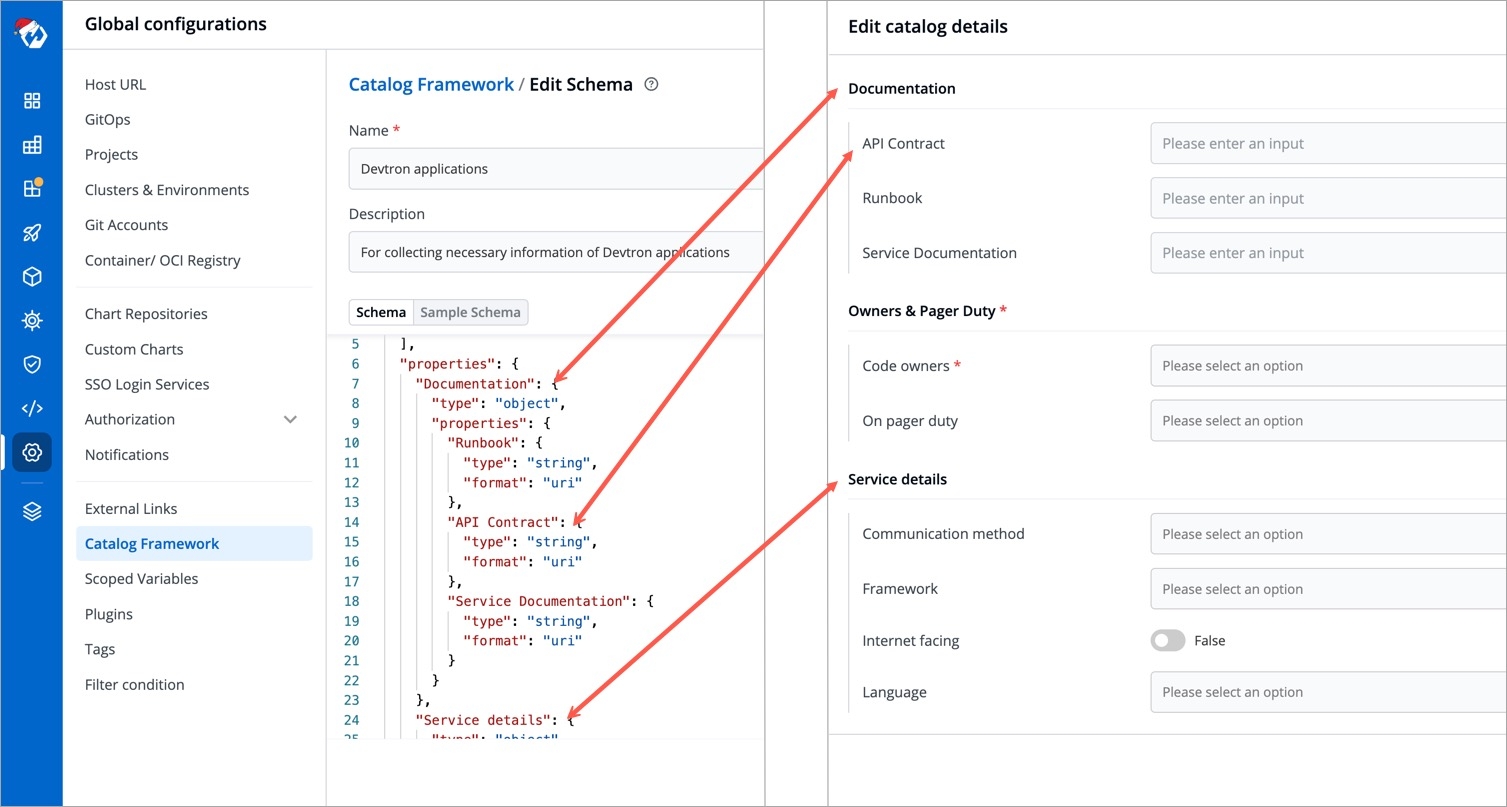
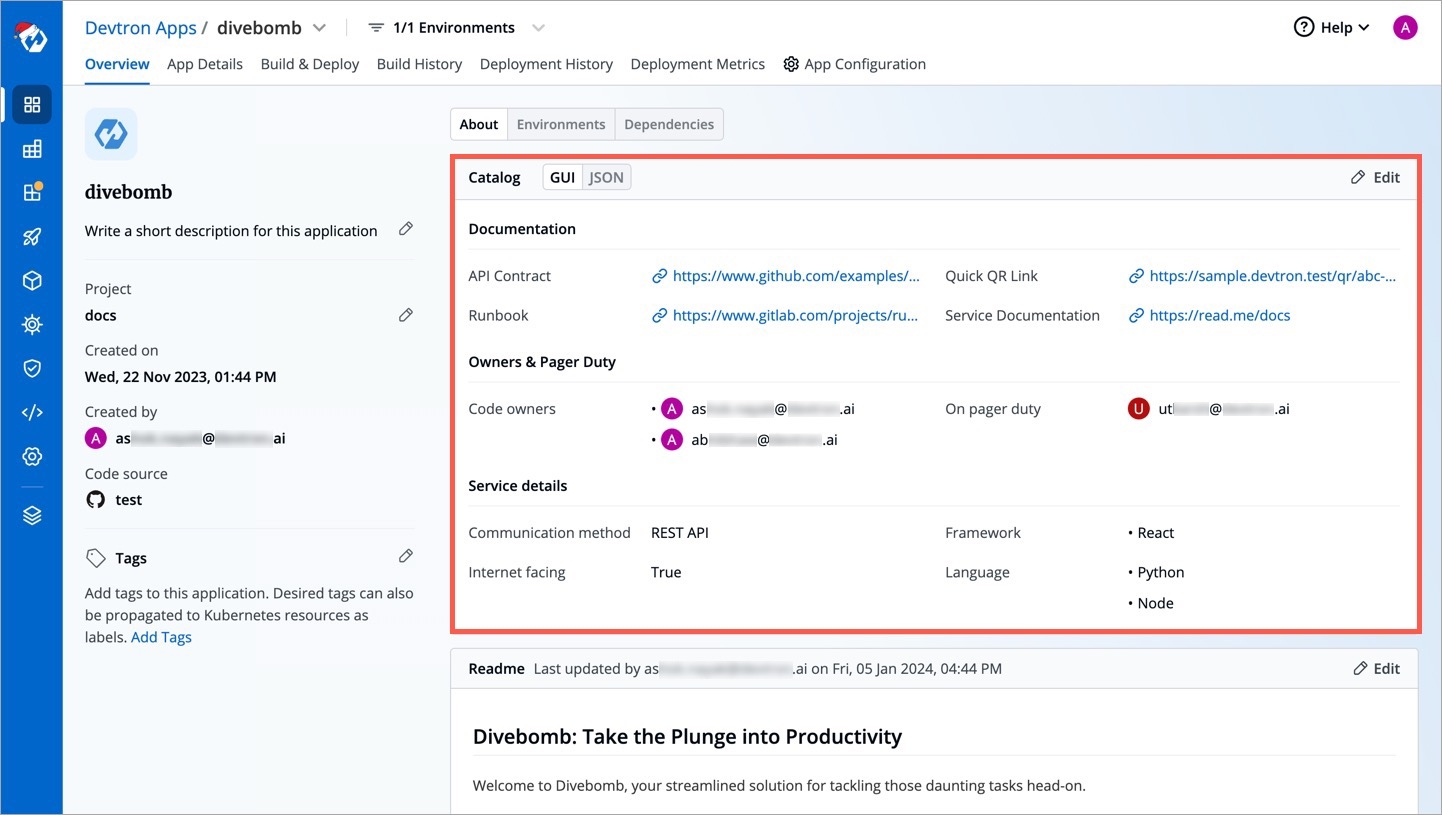
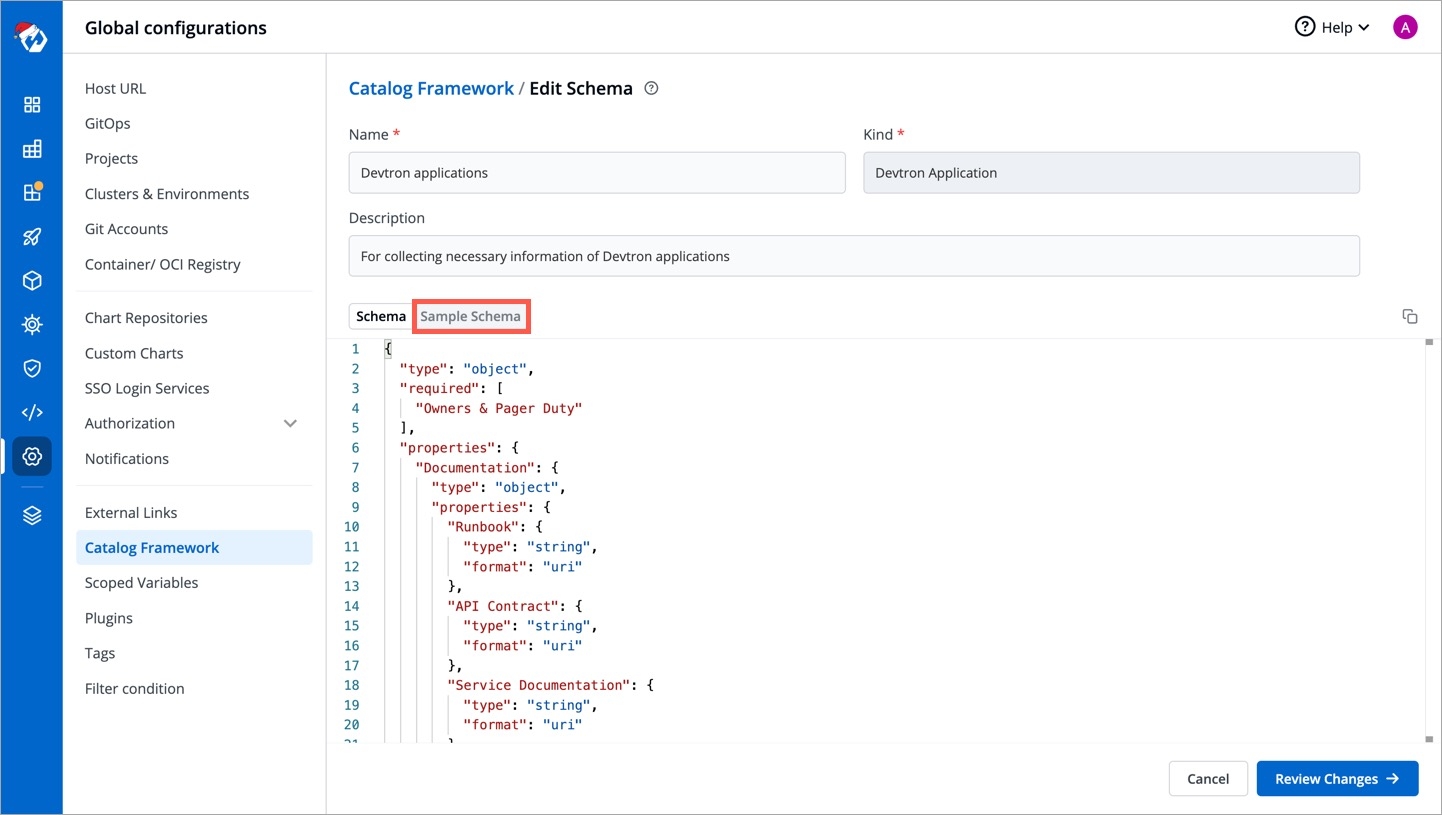
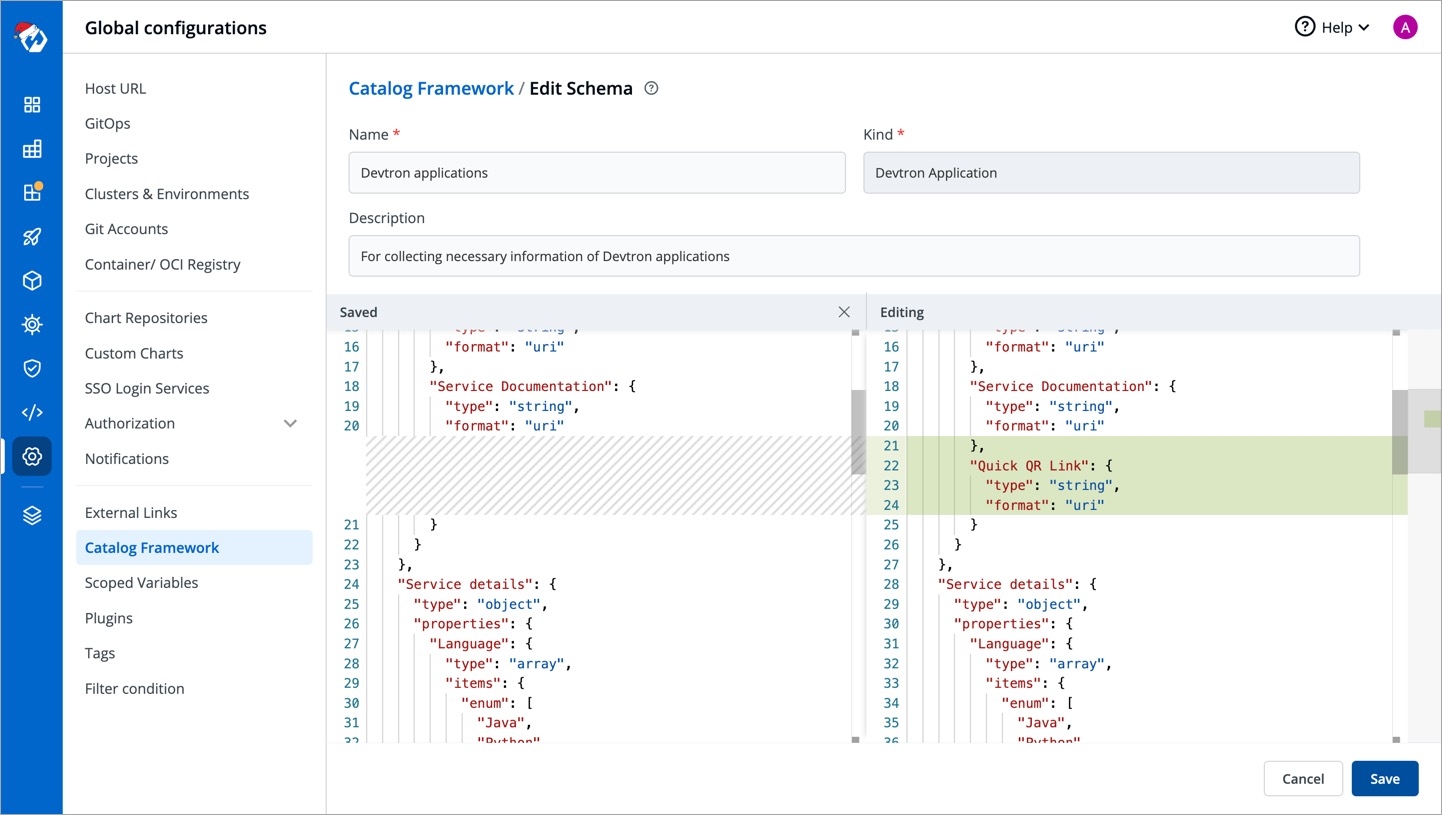
The CI process involves activities that require infra resources such as CPU, memory (RAM), and many more. The amount of resources required depends on the complexity of the application. In other words, large applications require more resources compared to small applications.
Therefore, applying a common infra configuration to all applications is not optimal. Since resources incur heavy costs, it's wise to efficiently allocate resources (not more, not less).
With the 'Build Infra' feature, Devtron makes it possible for you to tweak the resources as per the needs of your applications. The build (ci-runner) pod will be scheduled on an available node (considering applied taints and tolerations) in the cluster on which 'Devtron' is installed.
From the left sidebar, go to Global Configurations → Build Infra.
You will see the Default Profile and a list of Custom Profiles (if they exist). Setting up profiles makes it easier for you to manage the build infra configurations, ensuring its reusability in the long term.
This contains the default infra configuration applicable to all the applications, be it large or small.
You may click it to modify the following:
CPU - Processor core allocated to the build process. See CPU units.
Memory - RAM allocated to the build process. See memory units.
Build Timeout - Max. time limit allocated to the build process. See timeout units.
Furthermore, CPU and Memory have 2 fields each:
Request - Use this field to specify the minimum guaranteed amount of CPU/Memory resources your application needs for its CI build. In our example, we required 1500m or 1.5 cores CPU along with 6 GB of RAM.
Limit - Use this field to set the maximum amount of CPU/Memory resources the build process can use, even if there is a lot available in the cluster.
Instead of default profile, you can create custom profiles having different infra configurations. Example: One profile for Python apps, a second profile for large apps, and a third profile for small apps, and many more.
Click Create Profile.
Give a name to the profile along with a brief description, and select the configurations to specify the values.
Click Save. Your custom profile will appear under the list of custom profiles as shown below.
Once you create a profile, attach it to the intended applications, or else the default profile will remain applied.
Go to the Applications tab.
Choose an application and click the dropdown below it.
Choose the profile you wish to apply from the dropdown.
Click Change to apply the profile to your application.
Tip: If you missed creating a profile but selected your application(s), you can use the 'Create Profile' button. This will quickly open a new tab for creating a profile. Once done, you can return and click the refresh icon as shown below.
If you wish to apply a profile to multiple applications at once, you can do that too.
Simply use the checkboxes to select the applications. You can do this even if there are many applications spanning multiple pages. You will see a draggable floating widget as shown below.
Select the profile you wish to apply from the dropdown and confirm the changes.
Once you apply a profile, it will show the count of applications attached to it.
You can edit or delete a custom profile using the respective icons as shown below.
If you delete a profile attached to one or more applications, the default profile will apply from the next build.
If you need extra control on the build infra configuration apart from CPU, memory, and build timeout, feel free to open a GitHub issue for us to help you.
CPU resources are measured in millicore. 1000m or 1000 millicore is equal to 1 core. If a node has 4 cores, the node's CPU capacity would be represented as 4000m.
Memory is measured in bytes. You can enter memory with suffixes (E, P, T, G, M, K, and Ei, Pi, Ti, Gi, Mi, Ki).
m
-
0.001 byte
byte
-
1 byte
k
Kilo
1,000 bytes
Ki
Kibi
1,024 bytes
M
Mega
1,000,000 bytes
Mi
Mebi
1,048,576 bytes
G
Giga
1,000,000,000 bytes
Gi
Gibi
1,073,741,824 bytes
T
Tera
1,000,000,000,000 bytes
Ti
Tebi
1,099,511,627,776 bytes
P
Peta
1,000,000,000,000,000 bytes
Pi
Petabi
1,125,899,906,842,624 bytes
E
Exa
1,000,000,000,000,000,000 bytes
Ei
Exabi
1,152,921,504,606,846,976 bytes
You can specify timeouts in the following units, beyond which the build process would be marked as failed:
seconds
minutes
hours
Secrets and configmaps both are used to store environment variables but there is one major difference between them: Configmap stores key-values in normal text format while secrets store them in base64 encrypted form. Devtron hides the data of secrets for the normal users and it is only visible to the users having edit permission.
Secret objects let you store and manage sensitive information, such as passwords, authentication tokens, and ssh keys. Embedding this information in secrets is safer and more flexible than putting it verbatim in a Pod definition or in a container image.
Click Add Secret to add a new secret.
Name
Provide a name to your Secret
Data Type
Provide the Data Type of your secret. To know about different Data Types available click on
Data Volume
Specify if there is a need to add a volume that is accessible to the Containers running in a pod.
Use secrets as Environment Variable
Select this option if you want to inject Environment Variables in your pods using Secrets.
Use secrets as Data Volume
Select this option if you want to configure a Data Volume that is accessible to Containers running in a pod. Ensure that you provide a Volume mount path for the same.
Key-Value
Provide a key and the corresponding value of the provided key.
Specify the volume mount folder path in Volume Mount Path, a path where the data volume needs to be mounted. This volume will be accessible to the containers running in a pod.
For multiple files mount at the same location you need to check sub path bool field, it will use the file name (key) as sub path. Sub Path feature is not applicable in case of external configmap except AWS Secret Manager, AWS System Manager and Hashi Corp Vault, for these cases Name (Secret key) as sub path will be picked up automatically.
File permission will be provide at the configmap level not on the each key of the configmap. it will take 3 digit standard permission for the file.
Click Save Secret to save the secret.
You can see the Secret is added.
You can update your secrets anytime later, but you cannot change the name of your secrets. If you want to change your name of secrets then you have to create a new secret.
To update secrets, click the secret you wish to update.
Click Update Secret to update your secret.
You can delete your secret. Click your secret and click the delete sign to delete your secret.
There are five Data types that you can use to save your secret.
Kubernetes Secret: The secret that you create using Devtron.
Kubernetes External Secret: The secret data of your application is fetched by Devtron externally. Then the Kubernetes External Secret is converted to Kubernetes Secret.
AWS Secret Manager: The secret data of your application is fetched from AWS Secret Manager and then converted to Kubernetes Secret from AWS Secret.
AWS System Manager: The secret data for your application is fetched from AWS System Secret Manager and all the secrets stored in AWS System Manager are converted to Kubernetes Secret.
HashiCorp Vault: The secret data for your application is fetched from HashiCorp Vault and the secrets stored in HashiCorp Vault are converted to Kubernetes Secret.
Note: The conversion of secrets from various data types to Kubernetes Secrets is done within Devtron and irrespective of the data type, after conversion, the Pods access secrets normally.
Use this option to mount an existing Kubernetes Secret in your application pods. A Secret will not be created by system so please ensure that the secret already exist within the namespace else the deployment will fail.
The secret that is already created and stored in the environment and being used by Devtron externally is referred here as Kubernetes External Secret. For this option, Devtron will not create any secret by itself but they can be used within the pods. Before adding secret from kubernetes external secret, please make sure that secret with the same name is present in the environment. To add secret from kubernetes external secret, follow the steps mentioned below:
Navigate to Secrets of the application.
Click Add Secret to add a new secret.
Select Kubernetes External Secret from dropdown of Data type.
Provide a name to your secret. Devtron will search secret in the environment with the same name that you mention here.
Before adding any external secrets on Devtron, kubernetes-external-secrets must be installed on the target cluster. Kubernetes External Secrets allows you to use external secret management systems (e.g., AWS Secrets Manager, Hashicorp Vault, etc) to securely add secrets in Kubernetes.
To install the chart with the release named my-release:
$ helm install my-release external-secrets/kubernetes-external-secretsTo install the chart with AWS IAM Roles for Service Accounts:
$ helm install my-release external-secrets/kubernetes-external-secrets --set securityContext.fsGroup=65534 --set serviceAccount.annotations."eks\.amazonaws\.com/role-arn"='arn:aws:iam::111111111111:role/ROLENAME'To add secrets from AWS secret manager, navigate to Secrets of the application and follow the steps mentioned below :
Click Add Secret to add a new secret.
Select AWS Secret Manager from dropdown of Data type.
Provide a name to your secret.
Select how you want to use the secret. You may leave it selected as environment variable and also you may leave Role ARN empty.
In Data section, you will have to provide data in key-value format.
All the required field to pass your data to fetch secrets on Devtron are described below :
key
Secret key in backend
name
Name for this key in the generated secret
property
Property to extract if secret in backend is a JSON object
isBinary
Set this to true if configuring an item for a binary file stored else set false
To add secrets in AWS secret manager, do the following steps :
Go to AWS secret manager console.
Click Store a new secret.
Add and save your secret.
Using the Permission groups, you can assign a user to a particular group and a user inherits all the permissions granted to the group.
The advantage of the Permission groups is to define a set of privileges like create, edit, or delete for the given set of resources that can be shared among the users within the group.
Go to Global Configurations → Authorization → Permissions groups → Add group.
Enter the Group Name and Description.
You can either grant super-admin permission to a user group or specific permissions to manage access for:
In Devtron Apps option, you can provide access to a group to manage permission for custom apps created using Devtron.
Provide the information in the following fields:
Project
Select a project from the drop-down list to which you want to give permission to the group. You can select only one project at a time.
Note: If you want to select more than one project, then click Add row.
Environment
Select the specific environment or all environments from the drop-down list.
Note: If you select All environments option, then a user gets access to all the current environments including any new environment which gets associated with the application later.
Application
Select the specific applications or all applications from the drop-down list corresponding to your selected Environments.
Note: If you select All applications option, then a user gets access to all the current applications including any new application which gets associated with the project later
.
Role
Select one of the to which you want to give permission to the user:
View only
Build and Deploy
Admin
Manager
You can add multiple rows for Devtron Apps permission.
Once you have finished assigning the appropriate permissions for the groups, Click Save.
In Helm Apps option, you can provide access to a group to manage permission for Helm apps deployed from Devtron or outside Devtron.
Provide the information in the following fields:
Project
Select a project from the drop-down list to which you want to give permission to the group. You can select only one project at a time.
Note: If you want to select more than one project, then click Add row.
Environment or cluster/namespace
Select the specific environment or all existing environments in default cluster from the drop-down list.
Note: If you select all existing + future environments in default cluster option, then a user gets access to all the current environments including any new environment which gets associated with the application later.
Application
Select the specific application or all applications from the drop-down list corresponding to your selected Environments.
Note: If All applications option is selected, then a user gets access to all the current applications including any new application which gets associated with the project later
.
Role
Select one of the to which you want to give permission to the user:
View only
View & Edit
Admin
You can add multiple rows for Devtron app permission.
Once you have finished assigning the appropriate permissions for the groups, Click Save.
In Jobs option, you can provide access to a group to manage permission for jobs created using Devtron.
Provide the information in the following fields:
Project
Select a project from the drop-down list to which you want to give permission to the group. You can select only one project at a time.
Note: If you want to select more than one project, then click Add row.
Job Name
Select the specific job name or all jobs from the drop-down list.
Note: If you select All Jobs option, then the user gets access to all the current jobs including any new job which gets associated with the project later.
Workflow
Select the specific workflow or all workflows from the drop-down list.
Note: If you select All Workflows option, then the user gets access to all the current workflows including any new workflow which gets associated with the project later.
Environment
Select the specific environment or all environments from the drop-down list.
Note: If you select All environments option, then the user gets access to all the current environments including any new environment which gets associated with the project later.
Role
Select one of the to which you want to give permission to the user:
View only
Run job
Admin
You can add multiple rows for Jobs permission.
Once you have finished assigning the appropriate permissions for the groups, Click Save.
In Kubernetes Resources option, you can provide permission to view, inspect, manage, and delete resources in your clusters from Kubernetes Resource Browser page in Devtron. You can also create resources from the Kubernetes Resource Browser page.
To provide Kubernetes resource permission, click Add permission.
On the Kubernetes resource permission, provide the information in the following fields:
Cluster
Select a cluster from the drop-down list to which you want to give permission to the user. You can select only one cluster at a time.
Note: To add another cluster, then click Add another.
Namespace
Select the namespace from the drop-down list.
API Group
Select the specific API group or All API groups from the drop-down list corresponding to the K8s resource.
Kind
Select the kind or All kind from the drop-down list corresponding to the K8s resource.
Resource name
Select the resource name or All resources from the drop-down list to which you want to give permission to the user.
Role
Select one of the to which you want to give permission to the user and click Done:
View
Admin
You can add multiple rows for Kubernetes resource permission.
Once you have finished assigning the appropriate permissions for the groups, Click Save.
In Chart group permission option, you can manage the access of groups for Chart Groups in your project.
View
Enable View to view chart groups only.
Create
Enable Create if you want the users to create, view, edit or delete the chart groups.
Edit
Deny: Select Deny option from the drop-down list to restrict the users to edit the chart groups.
Specific chart groups: Select the Specific Charts Groups option from the drop-down list and then select the chart group for which you want to allow users to edit.
Click Save once you have configured all the required permissions for the groups.
You can edit the permission groups by clicking the downward arrow.
Edit the permission group.
Once you are done editing the permission group, click Save.
If you want to delete the groups with particular permission group, click Delete.
In this section, we will provide information on the Build Configuration.
Build configuration is used to create and push docker images in the container registry of your application. You will provide all the docker related information to build and push docker images on the Build Configuration page.
Only one docker image can be created for multi-git repository applications as explained in the Git Repository section.
For build configuration, you must provide information in the sections as given below:
The following fields are provided on the Store Container Image section:
Container Registry
Select the container registry from the drop-down list or you can click Add Container Registry. This registry will be used to .
Container Repository
Enter the name of your container repository, preferably in the format username/repo-name. The repository that you specify here will store a collection of related docker images. Whenever an image is added here, it will be stored with a new tag version.
If you are using docker hub account, you need to enter the repository name along with your username. For example - If my username is kartik579 and repo name is devtron-trial, then enter kartik579/devtron-trial instead of only devtron-trial.
In order to deploy the application, we must build the container images to configure a fully operational container environment.
You can choose one of the following options to build your container image:
I have a Dockerfile
Create Dockerfile
Build without Dockerfile
A Dockerfile is a text document that contains all the commands which you can call on the command line to build an image.
Select repository containing Dockerfile
Select the Git checkout path of your repository. This repository is the same which you defined on the section.
Dockerfile Path (Relative)
Enter a relative file path where your docker file is located in Git repository. Ensure that the dockerfile is available on this path. This is a mandatory field.
With the option Create Dockerfile, you can create a Dockerfile from the available templates. You can edit any selected Dockerfile template as per your build configuration requirements.
Language
Select the programming language (e.g., Java, Go, Python, Node etc.) from the drop-down list you want to create a dockerfile as per compatibility to your system.
Note We will be adding other programming languages in the future releases.
Framework
Select the framework (e.g., Maven, Gradle etc.) of the selected programming language.
Note We will be adding other frameworks in the future releases.
With the option Build without Dockerfile, you can use Buildpacks to automatically build the image for your preferred language and framework.
Select repository containing code
Select your code repository. This repository is the same which you defined on the section.
Project Path (Relative)
In case of monorepo, specify the path of the project from your Git repository.
Language
Select the programming language (e.g., Java, Go, Python, Node, Ruby, PHP etc.) from the drop-down list you want to build your container image as per the compatibility to your system.
Note: We will be adding other programming languages in the future releases.
Version
Select a language version from the drop-down list. If you do not find the version you need, then you can update the language version in Build Env Arguments. You can also select Autodetect in case if you want Builder to detect version by itself or its default version.
Select a builder
A builder is an image that contains a set of buildpacks which provide your app's dependencies, a stack, and the OS layer for your app image. Select a buildpack provider from the following options:
Heroku: It compiles your deployed code and creates a slug, which is a compressed and pre-packaged copy of your app and also the runtime which is optimized for distribution to the dyno (Linux containers) manager. .
GCR: GCR builder is a general purpose builder that creates container images designed to run on most platforms (e.g. Kubernetes / Anthos, Knative / Cloud Run, Container OS, etc.). It auto-detects the language of your source code, and can also build functions compatible with the Google Cloud Function Framework. .
Paketo: Paketo buildpacks provide production-ready buildpacks for the most popular languages and frameworks to easily build your apps. Based on your application needs, you can select from Full, Base and Tiny. .
You can add Key/Value pair by clicking Add argument.
Key
Define the key parameter as per your selected language and builder. E.g., By default GOOGLE_RUNTIME_VERSION for GCR buildpack.
Note: If you want to define env arguments for PHP and Ruby languages after selecting Heroku builder, please make sure to refer respective and documentation for runtime information.
Value
Define the value for the specified key. E.g. Version no.
Note This fields are optional. If required, it can be overridden at CI step.
Using this option, you can build images for a specific or multiple architectures and operating systems (target platforms). You can select the target platform from the drop-down list or can type to select a customized target platform.
Before selecting a customized target platform, please ensure that the architecture and the operating system are supported by the registry type you are using, otherwise build will fail. Devtron uses BuildX to build images for multiple target Platforms, which requires higher CI worker resources. To allocate more resources, you can increase value of the following parameters in the devtron-cm configmap in devtroncd namespace.
LIMIT_CI_CPU
REQ_CI_CPU
REQ_CI_MEM
LIMIT_CI_MEM
To edit the devtron-cm configmap in devtroncd namespace:
kubectl edit configmap devtron-cm -n devtroncd If target platform is not set, Devtron will build image for architecture and operating system of the k8s node on which CI is running.
The Target Platform feature might not work in minikube & microk8s clusters as of now.
It is is a collapsed view including the following parameters:
Key
Value
These fields will contain the key parameter and the value for the specified key for your docker build. This field is Optional. If required, this can be overridden at CI step.
Click Save Configuration.
You will see all your environments associated with an application under the Environment Overrides section.
You can customize your Deployment template, ConfigMap, Secrets in Environment Overrides section to add separate customizations for different environments such as dev, test, integration, prod, etc.
If you want to deploy an application in a non-production environment and then in production environment, once testing is done in the non-production environment, then you do not need to create a new application for production environment. Your existing pipeline(non-production env) will work for both the environments with little customization in your deployment template under Environment overrides.
In a Non-production environment, you may have specified 100m CPU resources in the deployment template but in the Production environment, you may want to have 500m CPU resources as the traffic on Pods will be higher than traffic on non-production env.
Configuring the Deployment template inside Environment Overrides for a specific environment will not affect the other environments because Environment Overrides will configure deployment templates on environment basis. And at the time of deployment, it will always pick the overridden deployment template if any.
If there are no overrides specified for an environment in the Environment Overrides section, the deployment template will be the one you specified in the deployment template section of the app creation.
(Note: This example is meant only for a representational purpose. You can choose to add any customizations you want in your deployment templates in the Environment Overrides tab)
Any changes in the configuration will not be added to the template, instead, it will make a copy of the template and lets you customize it for each particular environment. And now this overridden template will be used only for the specified Environment.
This will save you the trouble to manually create deployment files separately for each environment. Instead, all you have to do is to change the required variables in the deployment template.
In the Environment Overrides section, click on Allow Override and make changes to your Deployment template and click on Save to save your changes of the Deployment template.
The basic deployment configuration which you specified on the Basic GUI section will be visible for you to customize for your environment.
If you want to configure Basic GUI at the application level, then you can provide the required information in the Basic Configuration.
If Basic is locked, you can modify the configurations on Advanced (YAML) which will be the default page.
Super-admins can lock keys in deployment template to prevent non-super-admins from modifying those locked keys. Refer Lock Deployment Configuration to know more.
Note: Delete Override will discard the current overrides and the base configuration will be applicable to the environment.
The same goes for ConfigMap and Secrets. You can also create an environment-specific configmap and Secrets inside the Environment override section.
If you want to configure your ConfigMap and secrets at the application level then you can provide them in ConfigMaps and Secrets, but if you want to have environment-specific ConfigMap and secrets then provide them under the Environment override Section. At the time of deployment, it will pick both of them and provide them inside your cluster.
Click on Update ConfigMap to update Configmaps.
Click on Update Secrets to update Secrets.
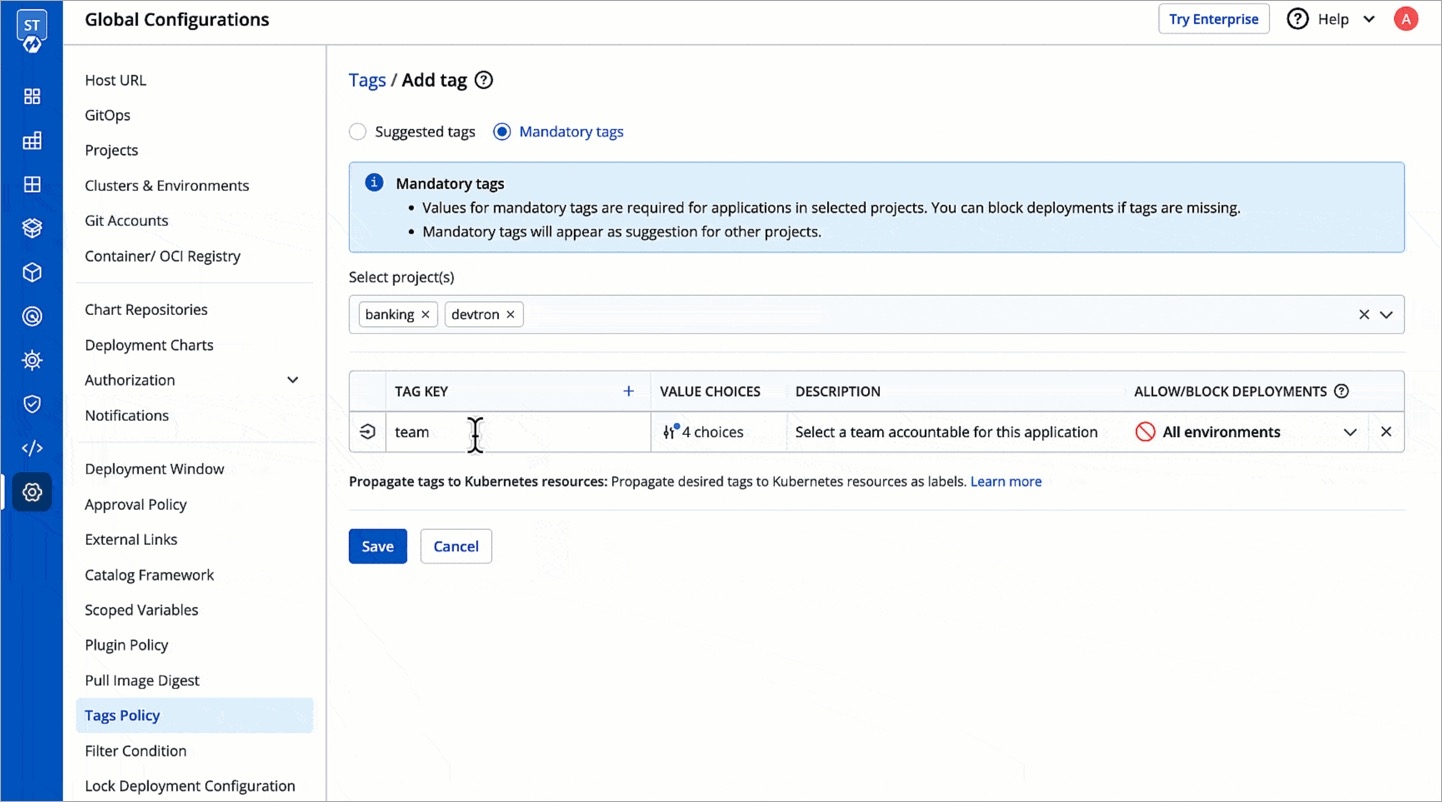
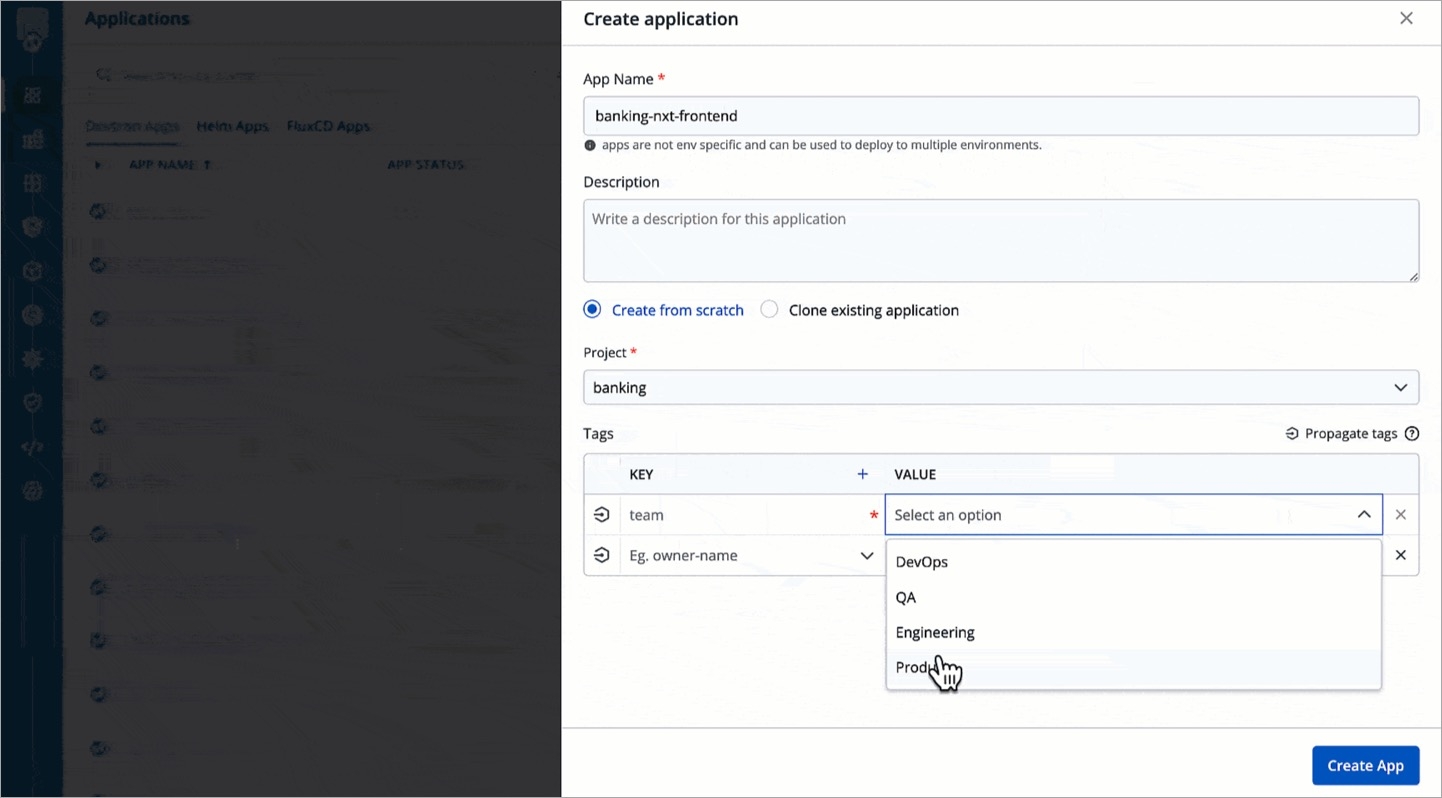

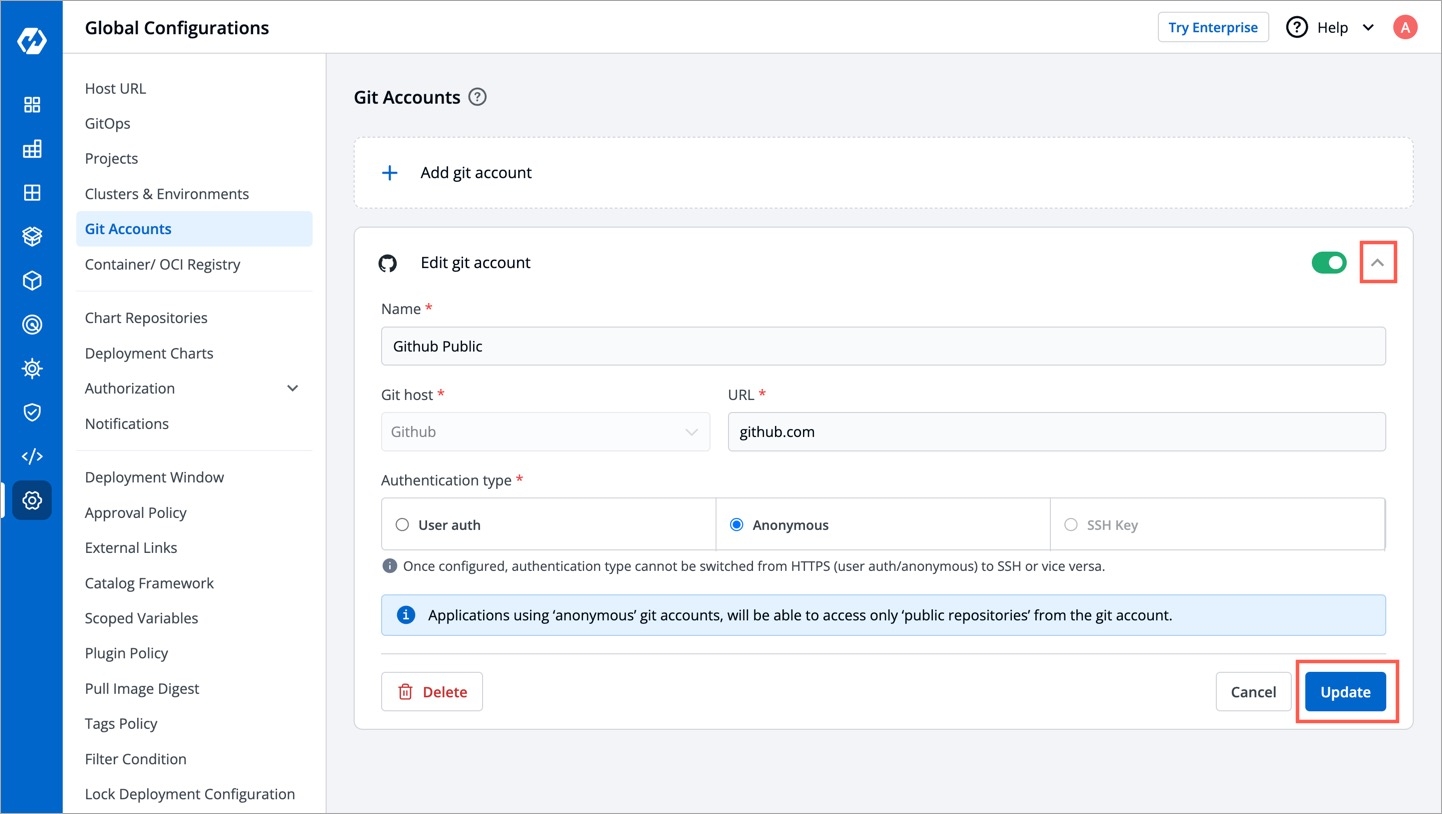
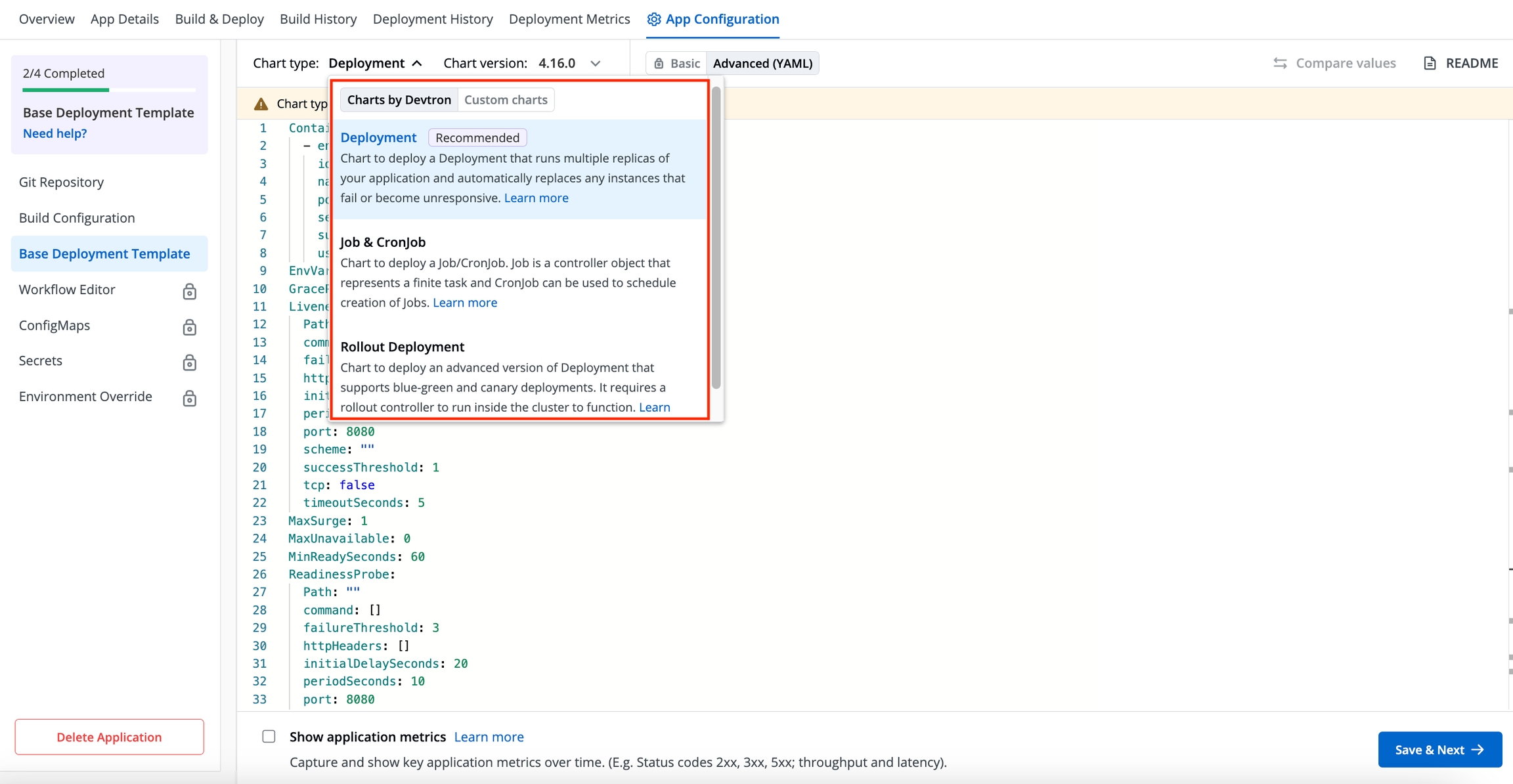
While are typically used for storing built by the CI Pipeline, an OCI registry can store container images as well as other artifacts such as . In other words, all container registries are OCI registries, but not all OCI registries are container registries.
You can configure a container registry using any registry provider of your choice. It allows you to build, deploy, and manage your container images or charts with easy-to-use UI.
From the left sidebar, go to Global Configurations → Container/OCI Registry.
Click Add Registry.
Choose a provider from the Registry provider dropdown. View the .
Choose the Registry type:
Private Registry: Choose this if your images or artifacts are hosted or should be hosted on a private registry restricted to authenticated users of that registry. Selecting this option requires you to enter your registry credentials (username and password/token).
Public Registry: Unlike private registry, this doesn't require your registry credentials. Only the registry URL and repository name(s) would suffice.
Assuming your registry type is private, here are few of the common fields you can expect:
Click Save.
Amazon ECR is an AWS-managed container image registry service. The ECR provides resource-based permissions to the private repositories using AWS Identity and Access Management (IAM). ECR allows both Key-based and Role-based authentications.
Before you begin, create an and attach the ECR policy according to the authentication type.
Provide the following additional information apart from the common fields:
Provide the following additional information apart from the common fields:
For Azure, the service principal authentication method can be used to authenticate with username and password. Visit this to get the username and password for this registry.
Provide the following additional information apart from the common fields:
JSON key file authentication method can be used to authenticate with username and service account JSON file. Visit this to get the username and service account JSON file for this registry.
Remove all the white spaces from JSON key and wrap it in a single quote before pasting it in Service Account JSON File field
Provide the following additional information apart from the common fields:
JSON key file authentication method can be used to authenticate with username and service account JSON file. Please follow to get the username and service account JSON file for this registry.
Remove all the white spaces from JSON key and wrap it in single quote before pasting it in Service Account JSON File field
Provide the following additional information apart from the common fields:
Provide below information if you select the registry type as Other.
You can create a Pod that uses a to pull an image from a private container registry. You can use any private container registry of your choice, for e.g., .
Super-admin users can decide if they want to auto-inject registry credentials or use a secret to pull an image for deployment to environments on specific clusters.
To manage the access of registry credentials, click Manage.
There are two options to manage the access of registry credentials:
You can choose one of the two options for defining credentials:
If you select Use Registry Credentials, the clusters will be auto-injected with the registry credentials of your registry type. As an example, If you select Docker as Registry Type, then the clusters will be auto-injected with the username and password/token which you use on the Docker Hub account.
Click Save.
You can create a Secret by providing credentials on the command line.
Create this Secret and name it regcred (let's say):
where,
namespace is your sub-cluster, e.g., devtron-demo
your-registry-server is your Private Docker Registry FQDN. Use https://index.docker.io/v1/ for Docker Hub.
your-name is your Docker username
your-pword is your Docker password
your-email is your Docker email
You have successfully set your Docker credentials in the cluster as a Secret called regcred.
Typing secrets on the command line may store them in your shell history unprotected, and those secrets might also be visible to other users on your PC during the time when kubectl is running.
Enter the Secret name in the field and click Save.
A verified account on . Okta activates your account only if email verification is successful.
Here's a reference guide to set up your Okta org and application:
Once your Okta org is set up, create an app integration on Okta to get a Client ID and Client Secret.
In the Admin Console, go to Applications → Applications.
Click Create App Integration.
Select OIDC - OpenID Connect as the Sign-in method.
Select Web as the application type and click Next.
On the App Integration page:
Give a name to your application.
Select the Interaction Code and Refresh Token checkbox.
Now go to Devtron's Global Configurations → SSO Login Services → OIDC.
Copy the redirect URI given in the helper text (might look like: https://xxx.xxx.xxx/xxx/callback).
Return to the Okta screen, and remove the prefilled value in Sign-in redirect URIs.
Paste the copied URI in Sign-in redirect URIs.
Click Save.
On the General tab:
Note the Client ID value.
Click the Edit option.
In Client Authentication, choose Client Secret.
Click Save.
Click Generate new secret.
Note the Client Secret value.
Go to the Global Configurations → SSO Login Services → OIDC.
In the URL field, enter the Devtron application URL (a valid https link) where it is hosted.
Under Configuration tab, locate the config object, and provide the clientID and clientSecret of the app integration you created on Okta.
Add a key insecureSkipEmailVerified: true. Note that this key is only required for Okta SSO. For other types of OIDC SSO, refer .
Provide issuer value as https://${yourOktaDomain}. Replace ${yourOktaDomain} with your domain on Okta as shown in the video.
For providing redirectURI or callbackURI registered with the SSO provider, you can either select Configuration or Sample Script. Note that the redirect URI is already given in the helper text (as seen in the previous section).
Click Save to create and activate Okta SSO login.
Now your users will be able to log in to Devtron using the Okta authentication method. Note that existing signed-in users will be logged out and they have to log in again using their OIDC account.
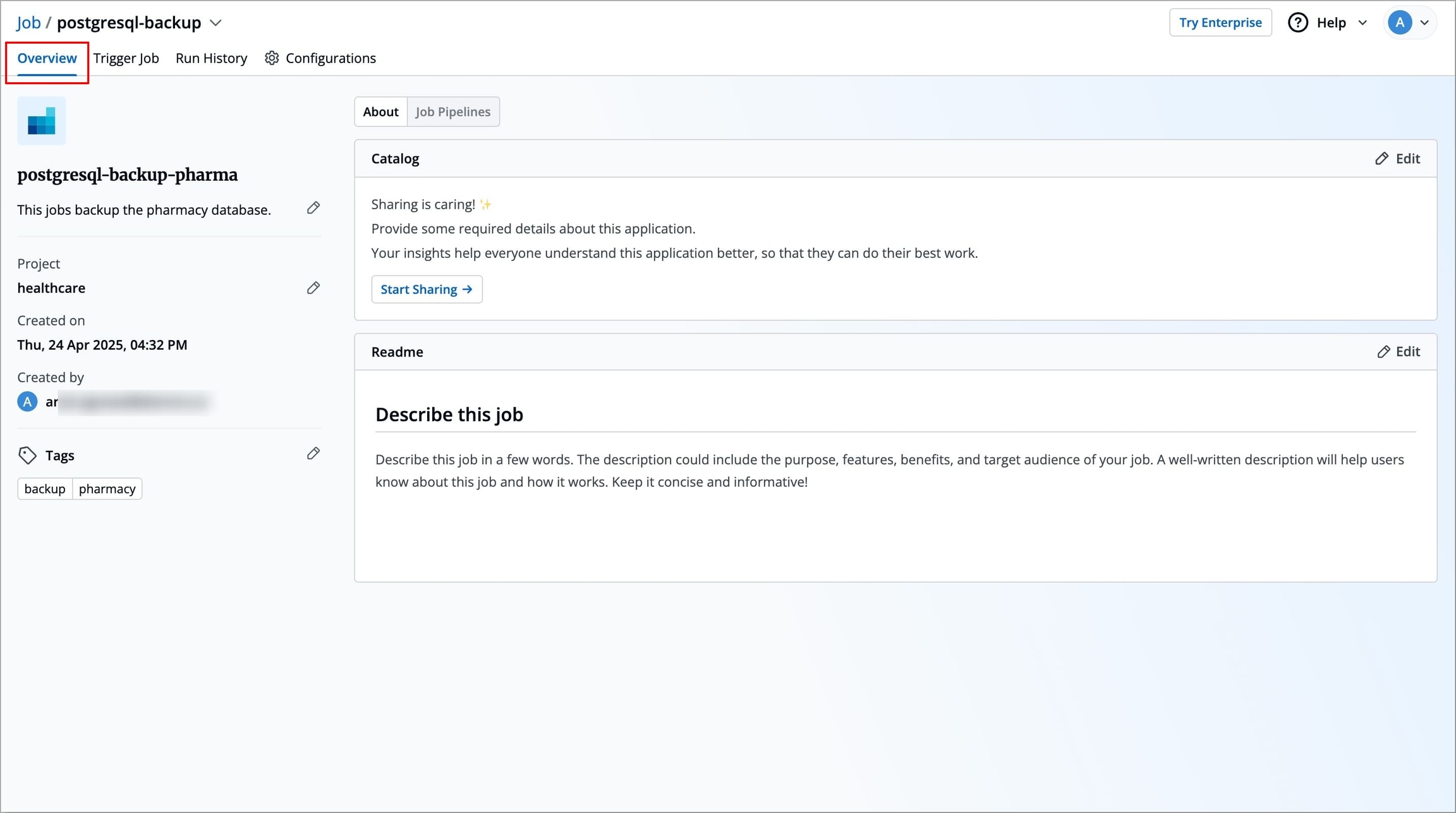
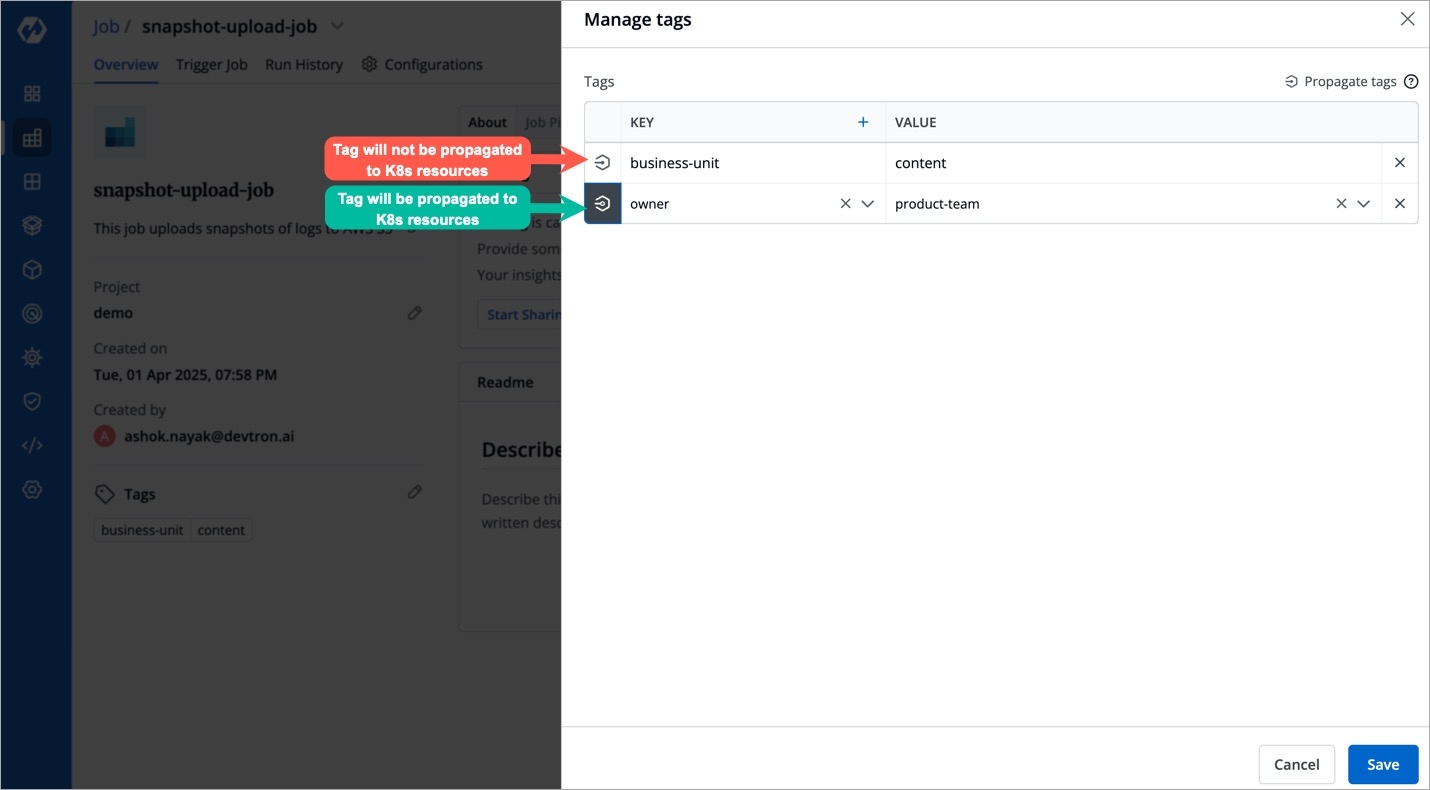
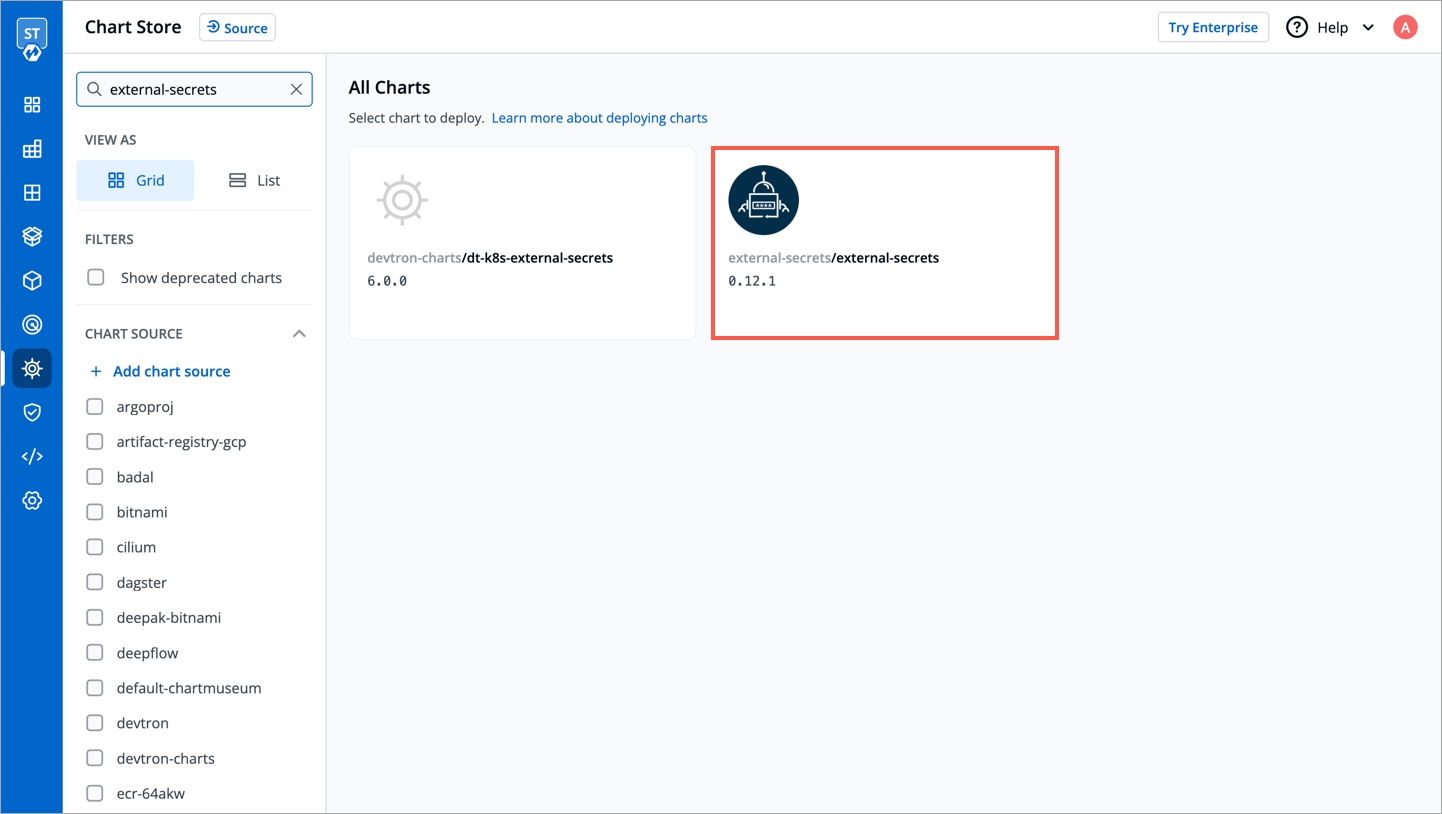
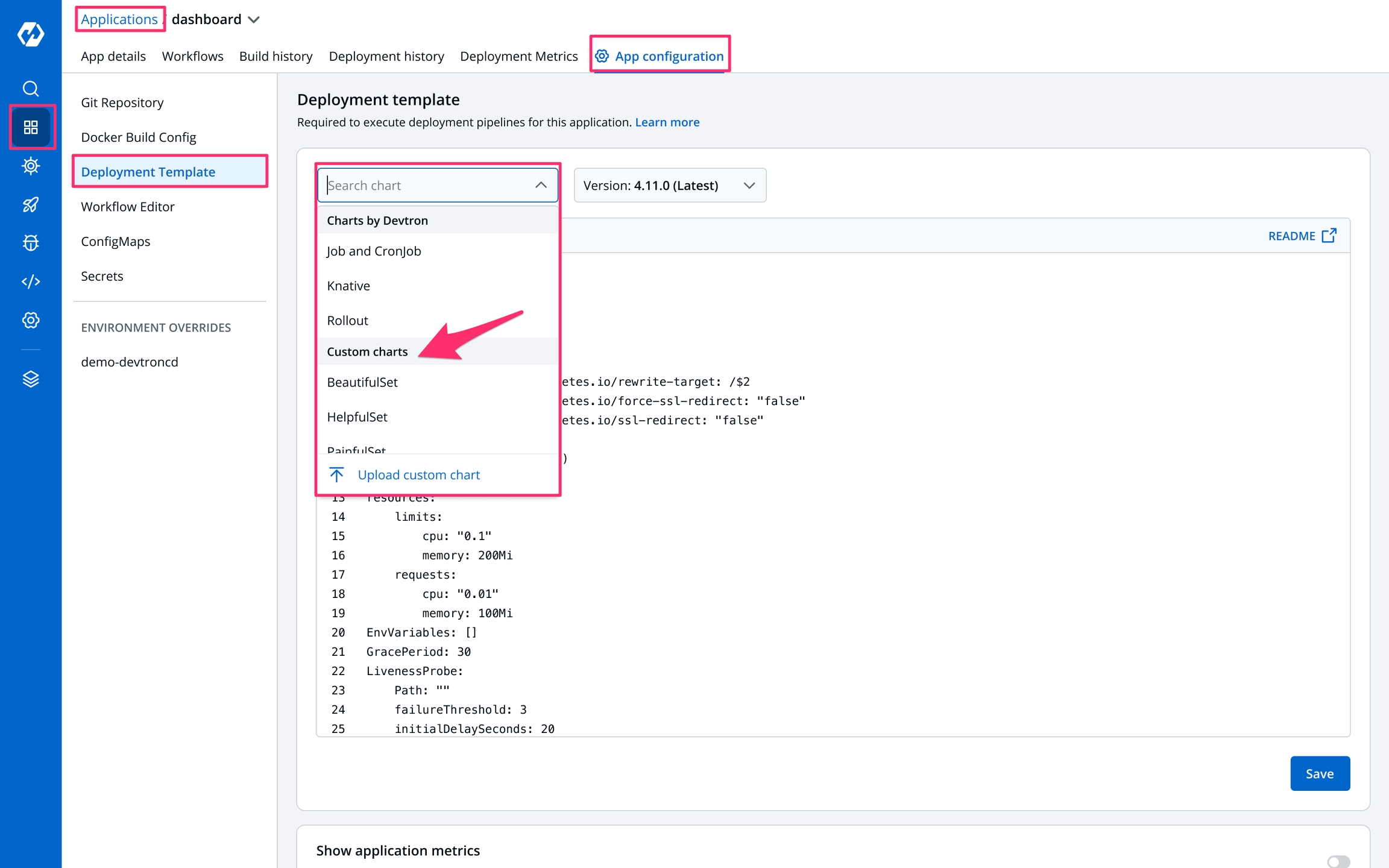
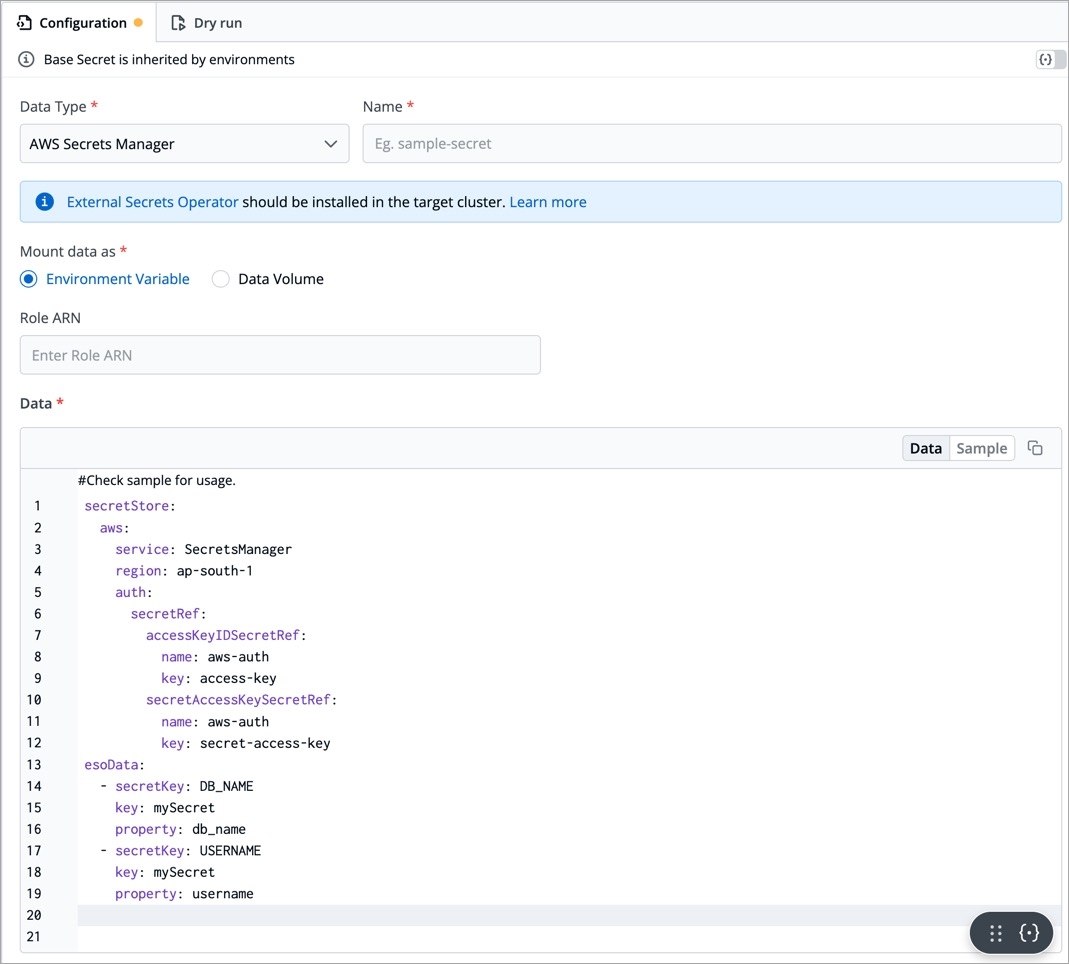
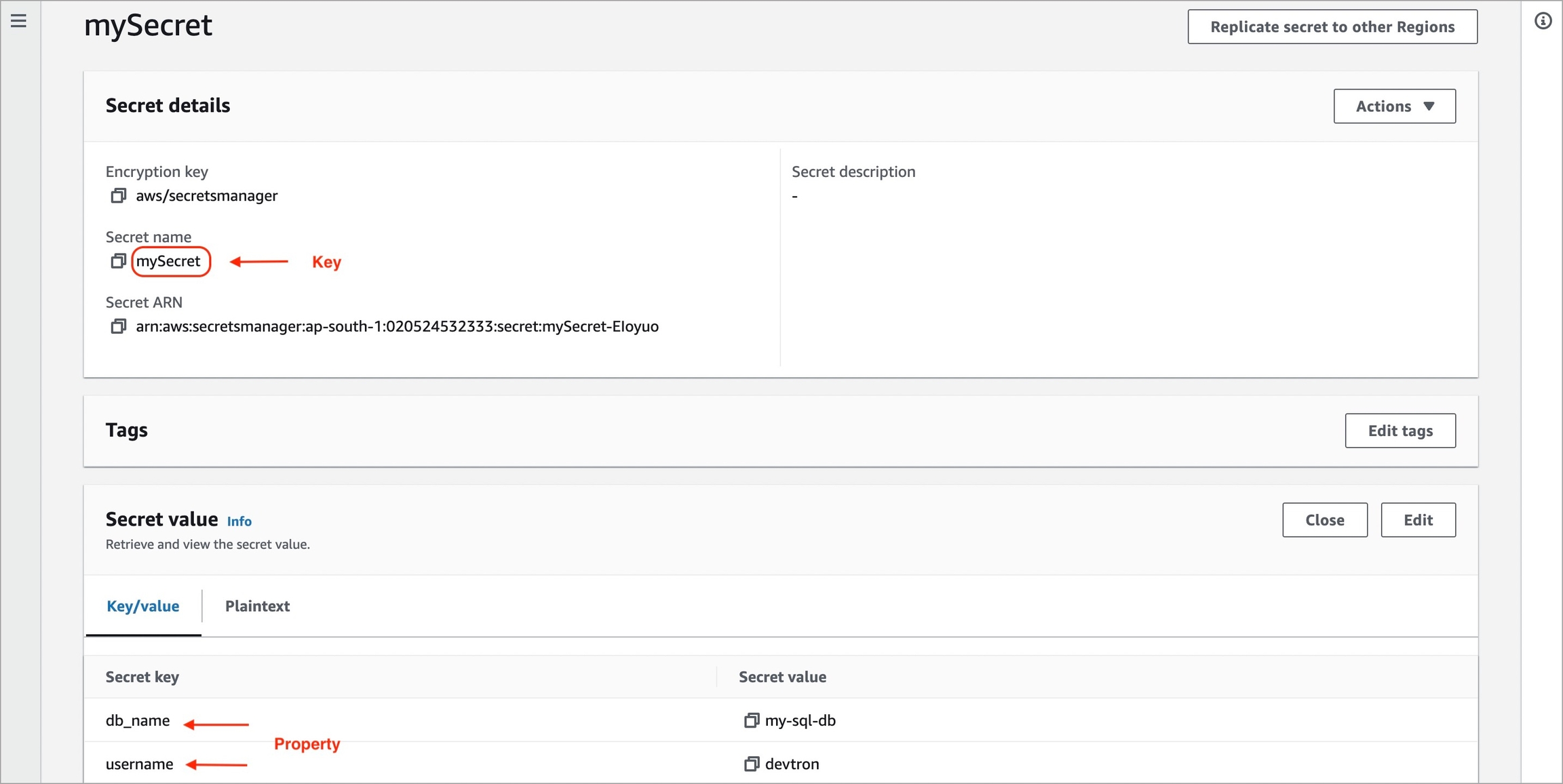
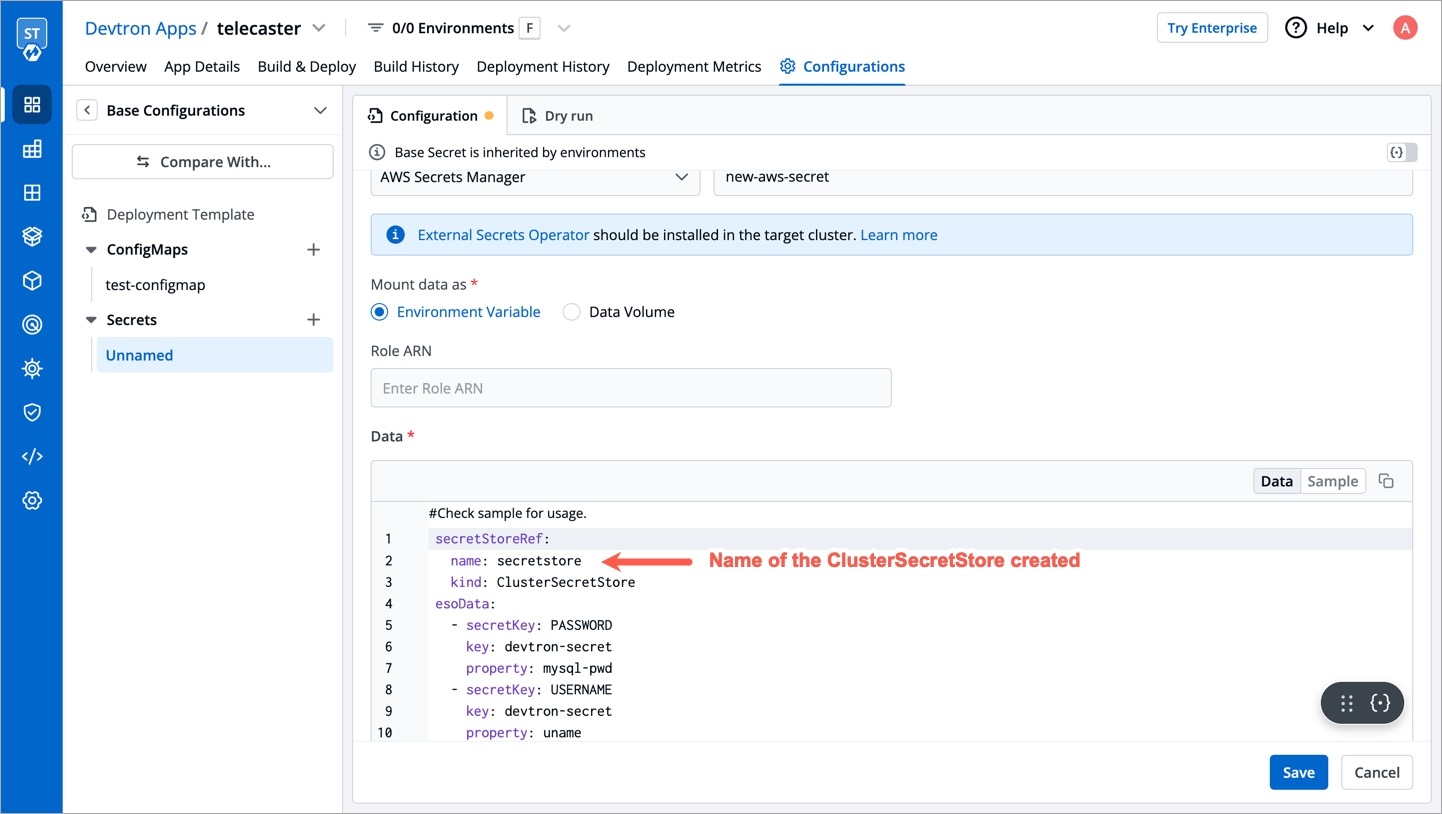
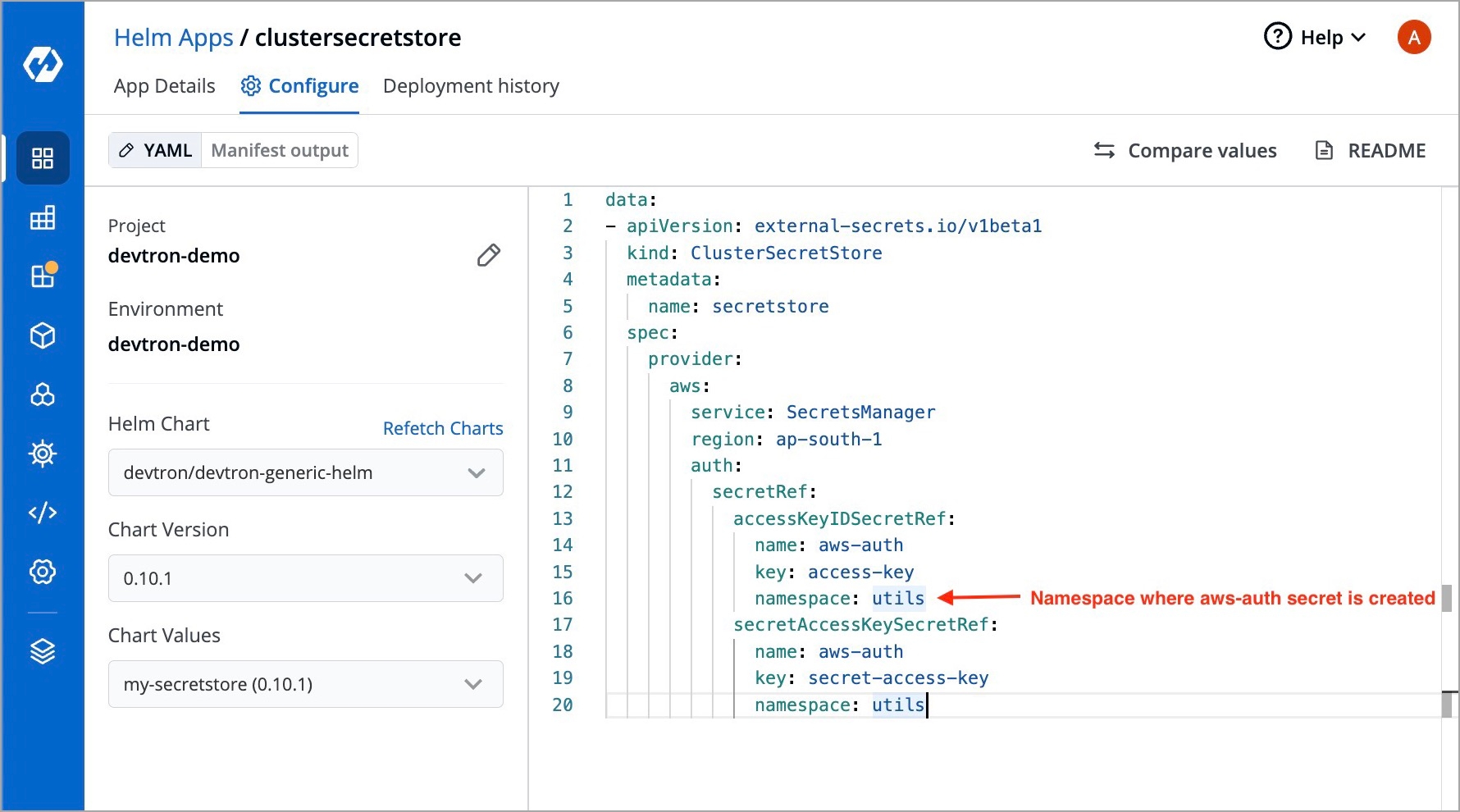
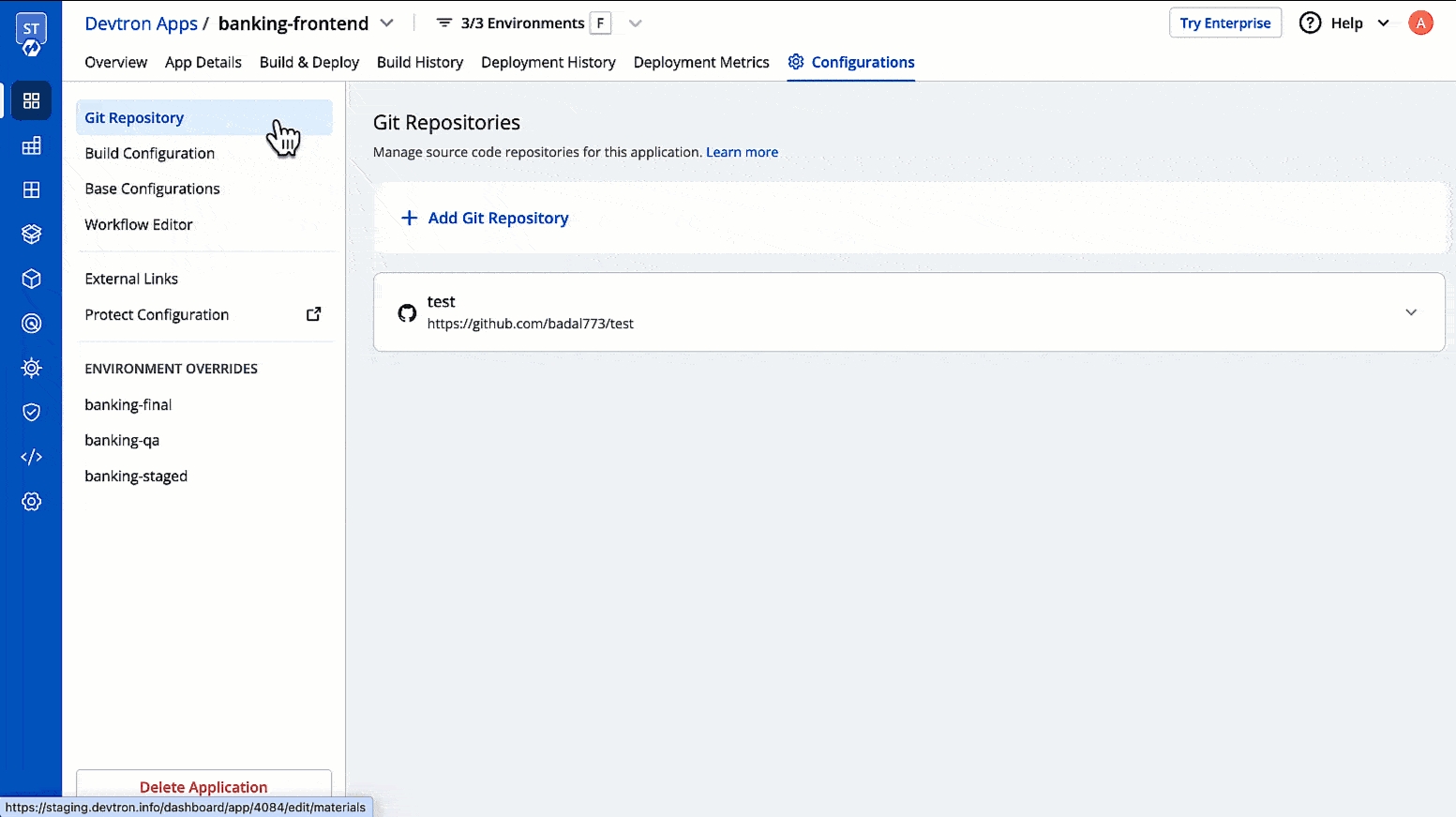
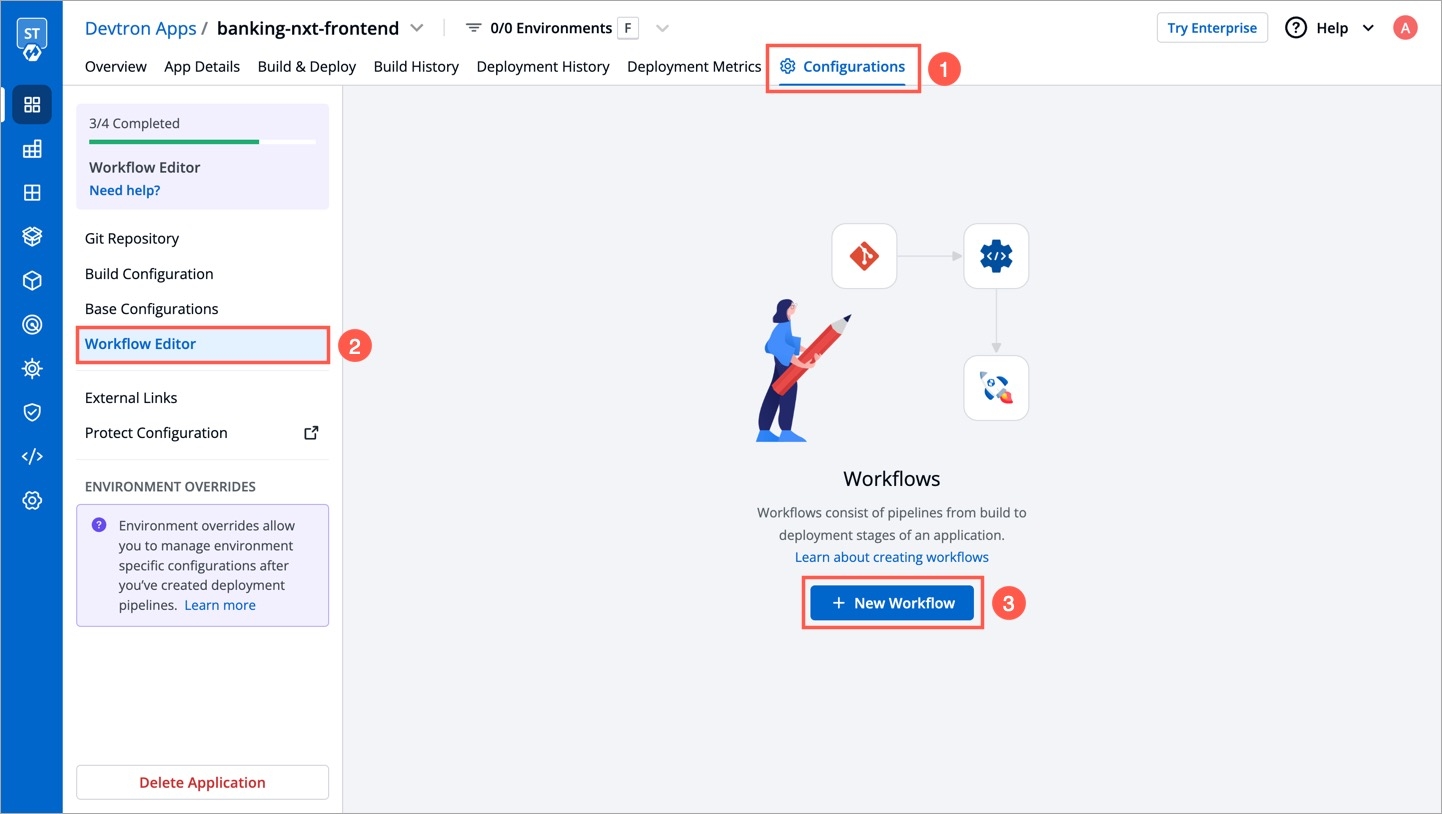
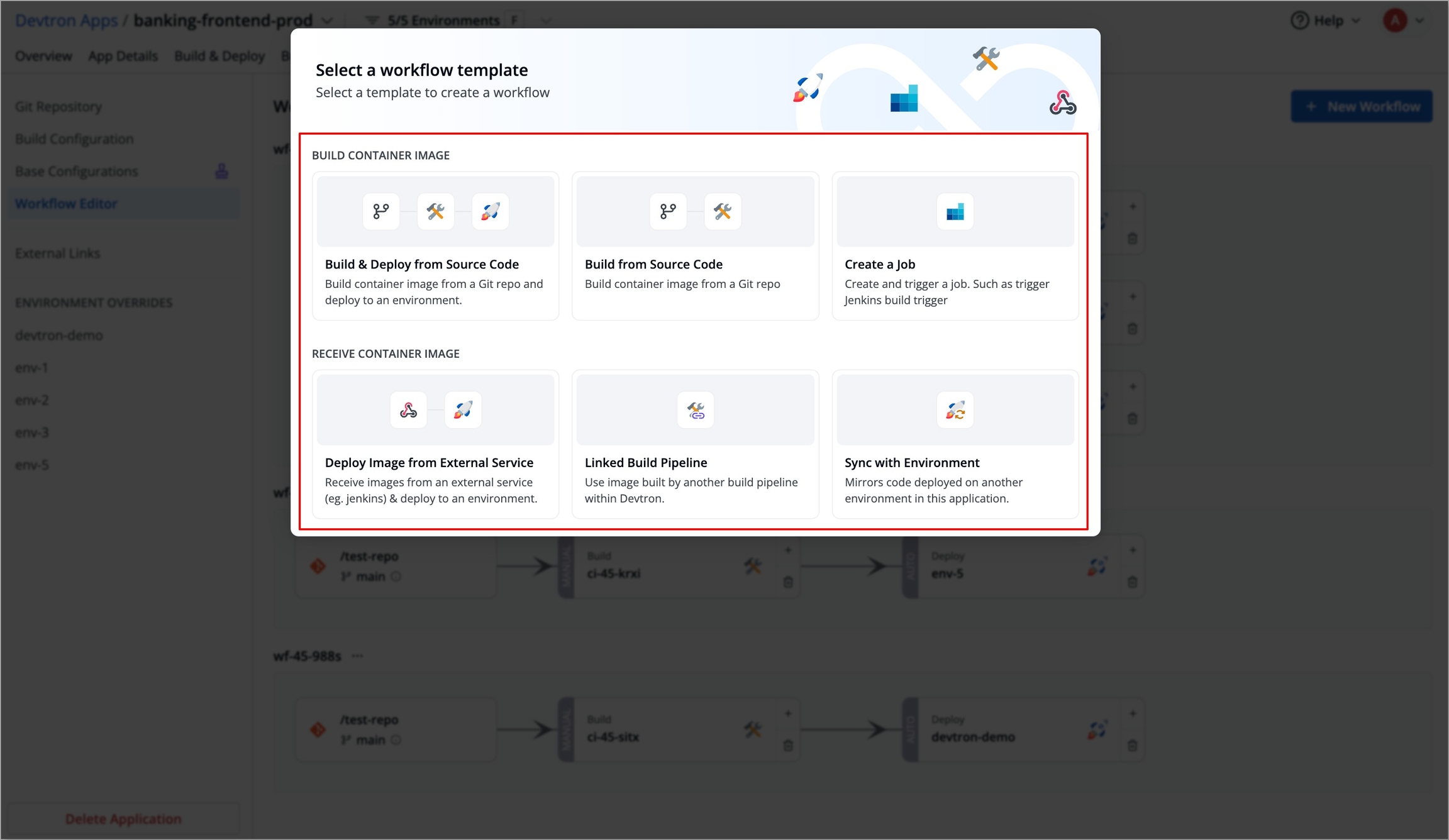
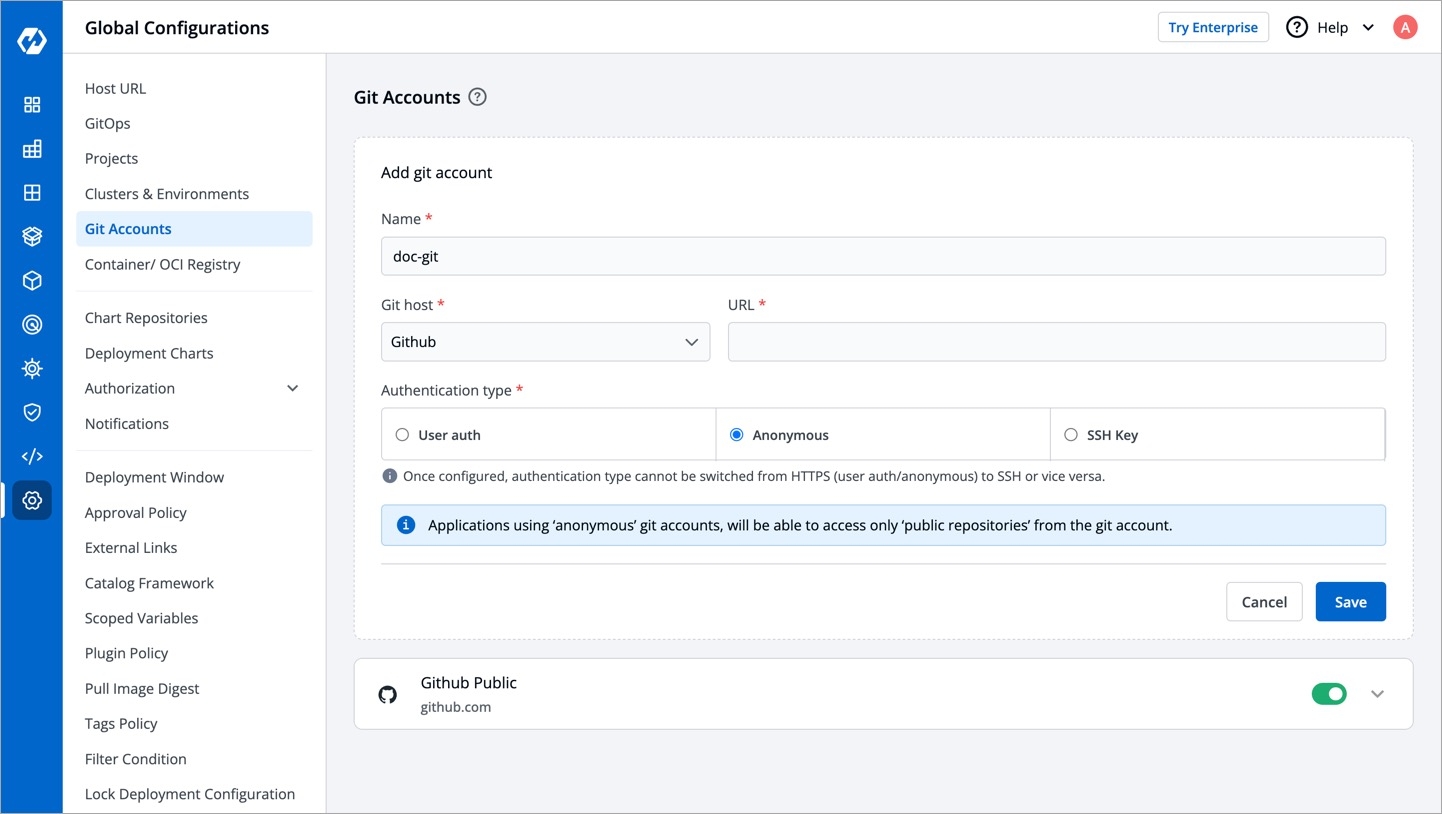
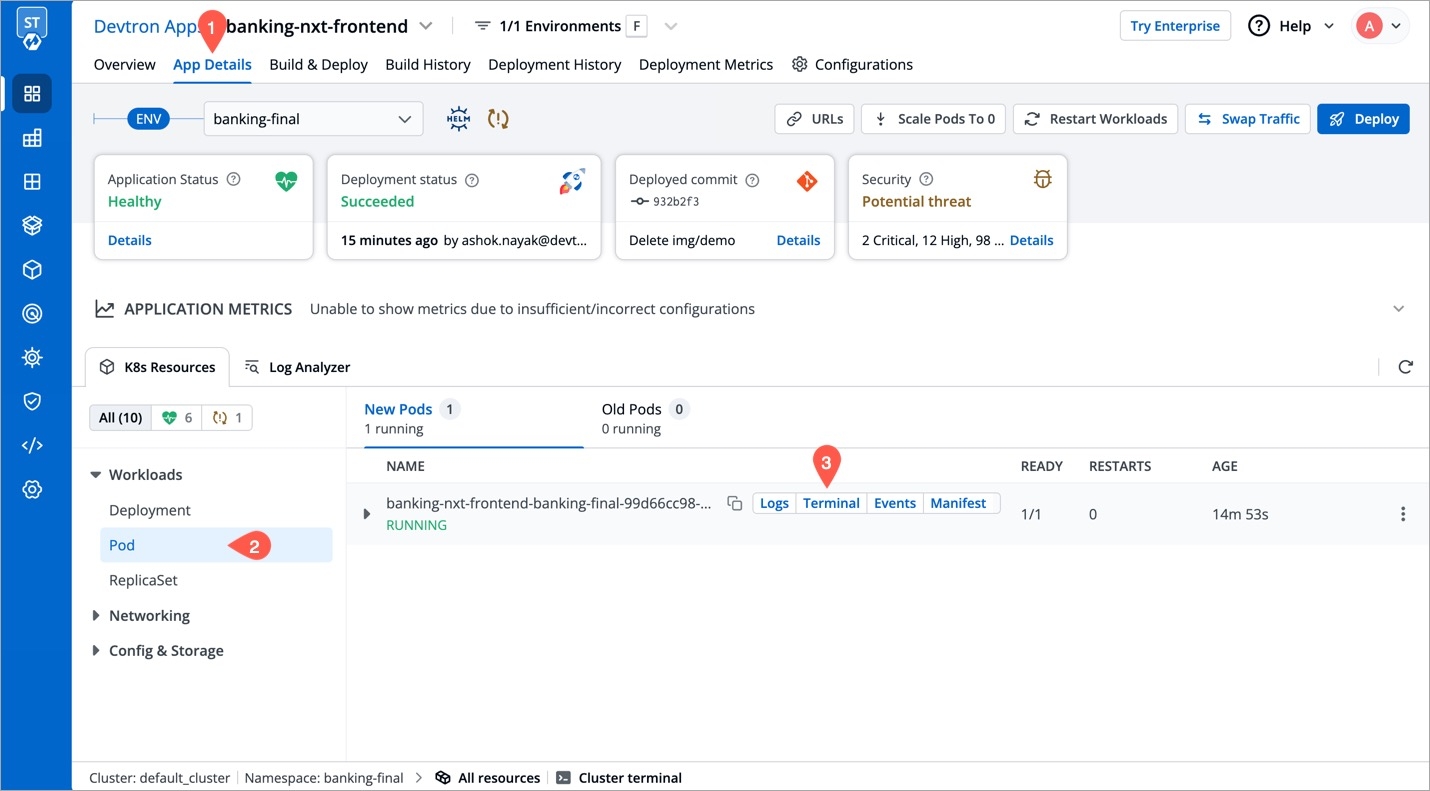
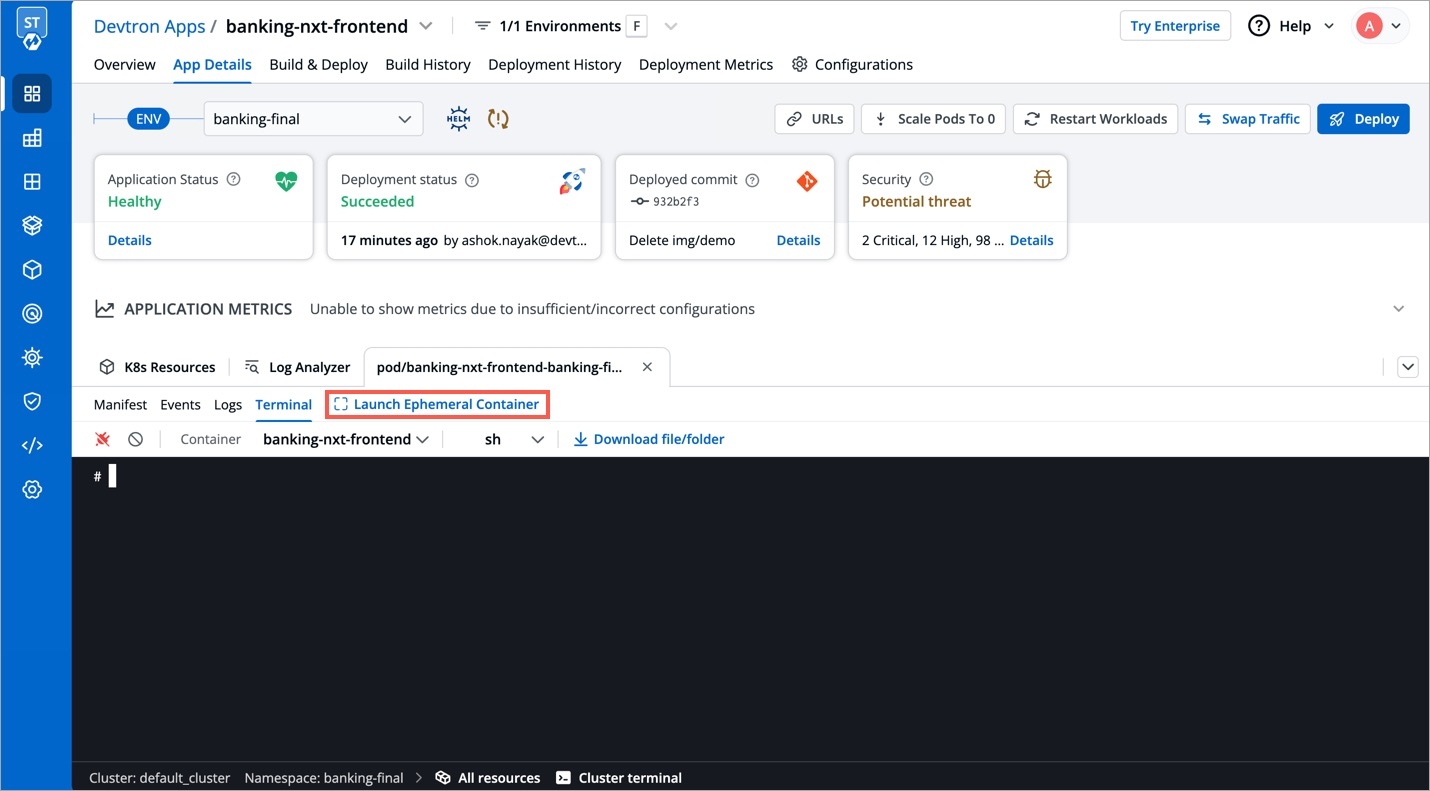
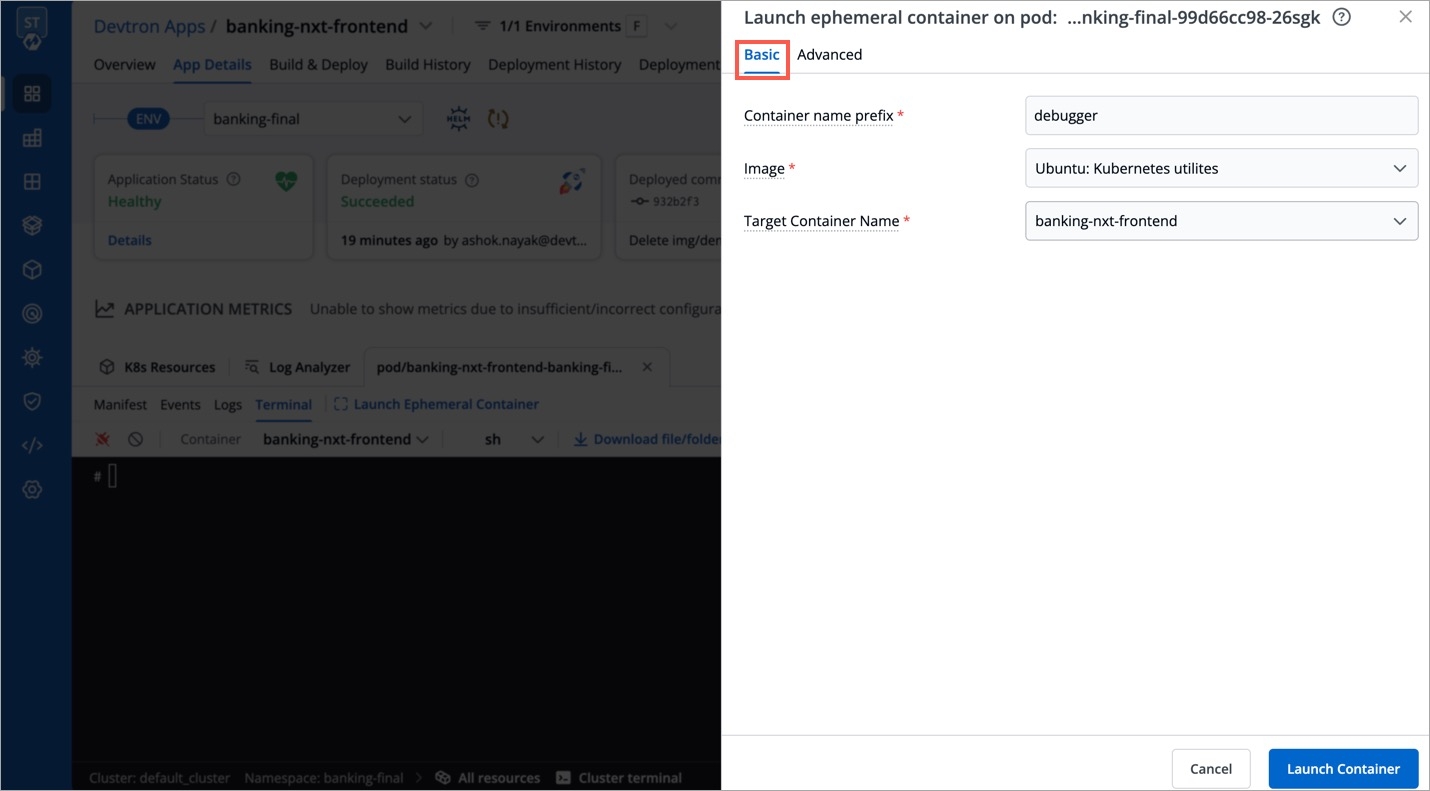
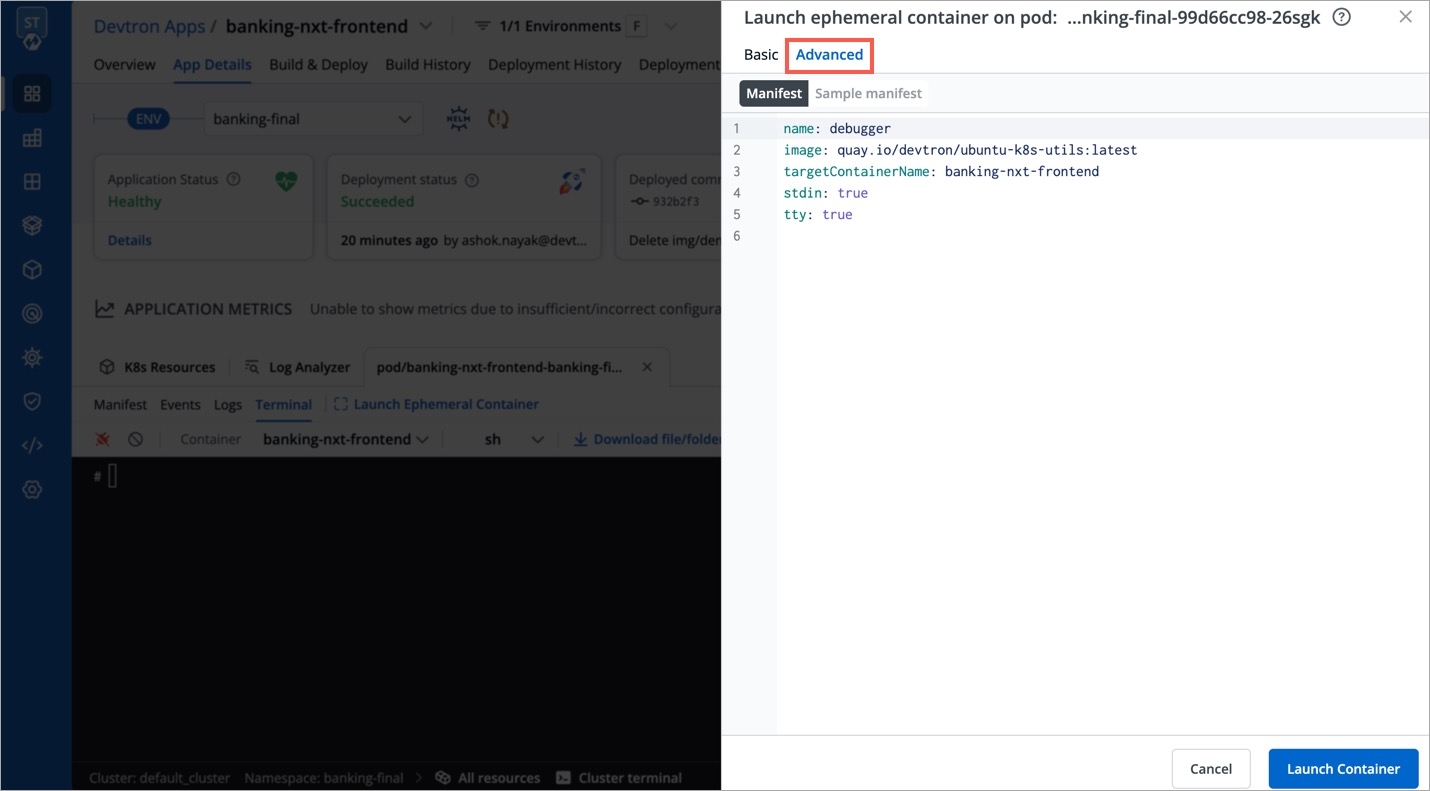
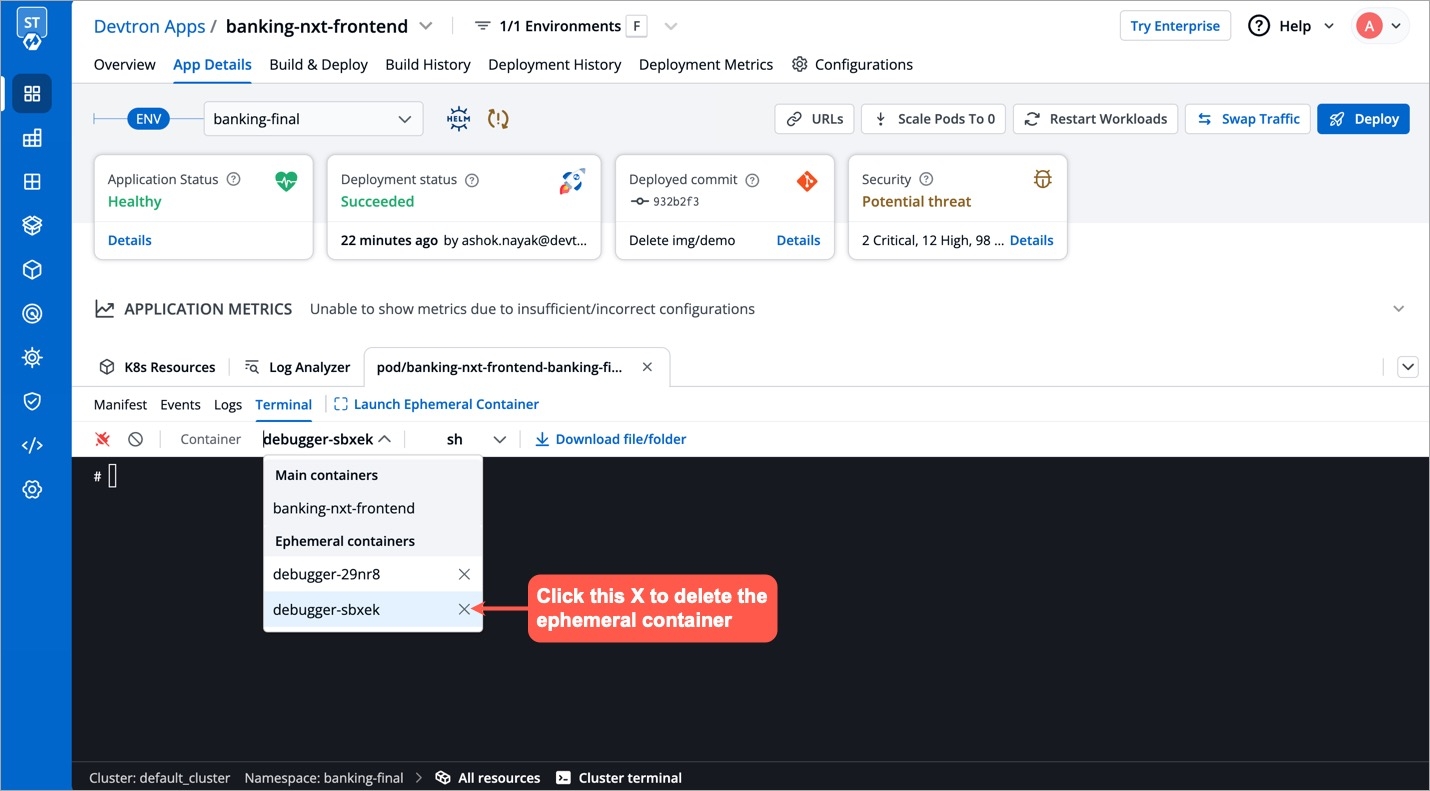
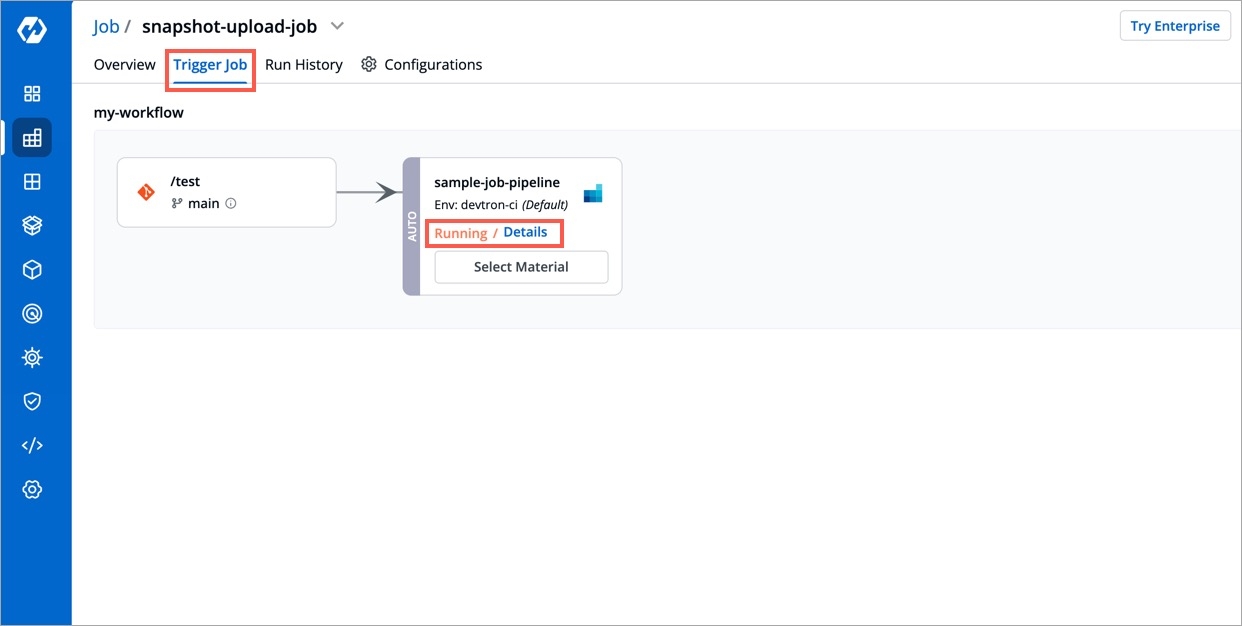
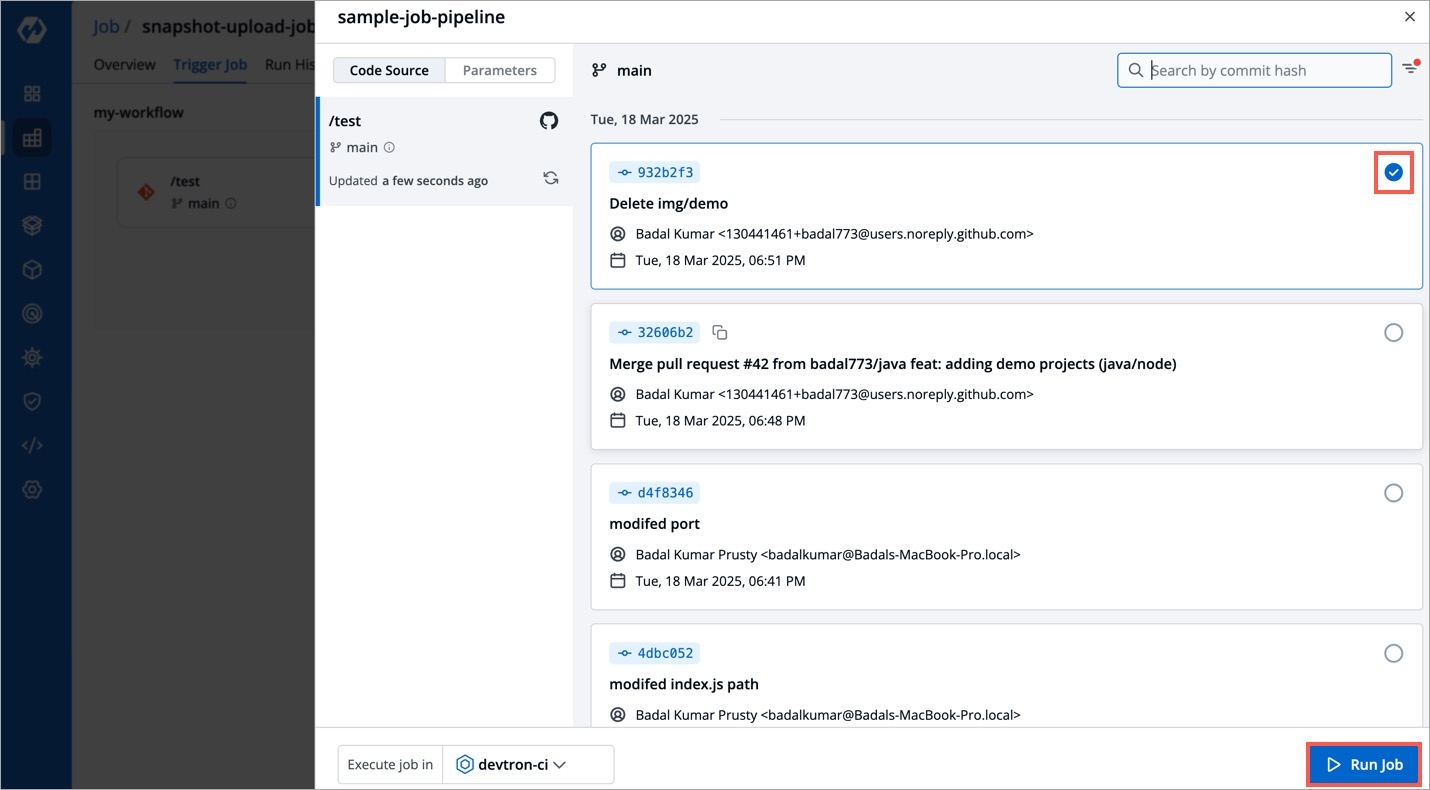
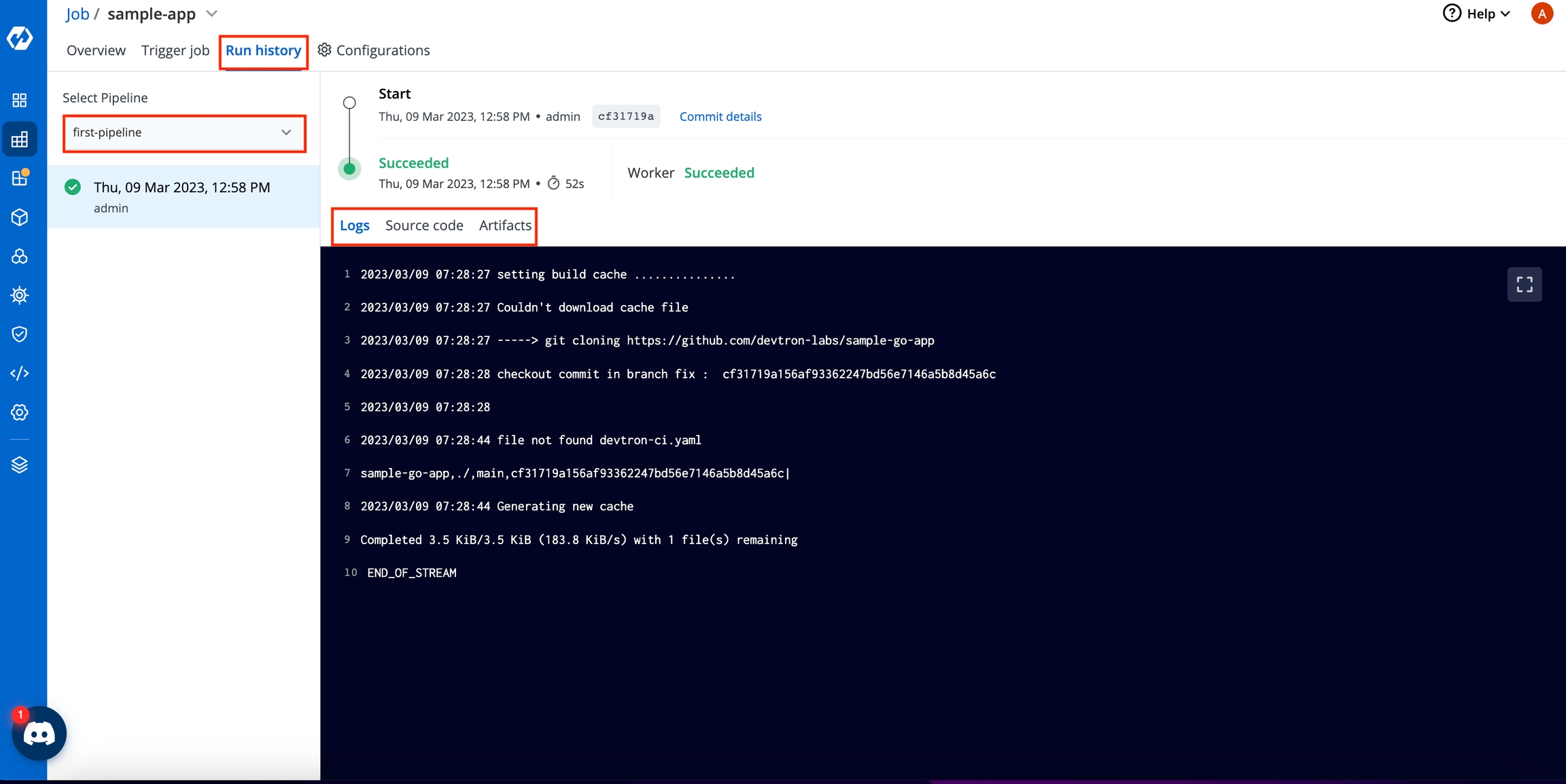
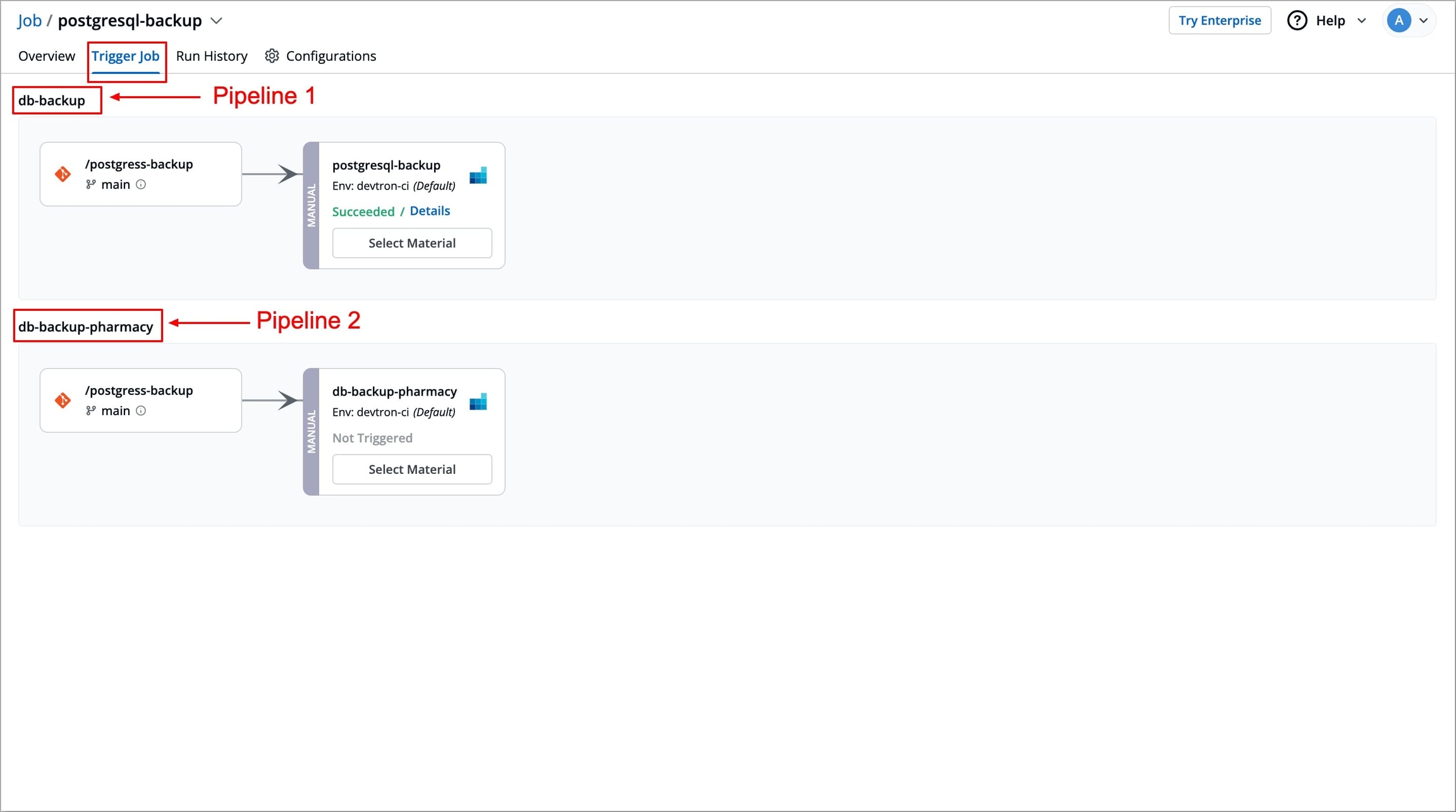
Name
Provide a name to your registry, this name will appear in the Container Registry drop-down list available within the Build Configuration section of your application
Registry URL
Provide the URL of your registry in case it doesn't come prefilled (do not include oci://, http://, or /https:// in the URL)
Authentication Type
The credential input fields may differ depending on the registry provider, check Registry Providers
Push container images
Tick this checkbox if you wish to use the repository to push container images. This comes selected by default and you may untick it if you don't intend to push container images after a CI build. If you wish to to use the same repository to pull container images too, read Registry Credential Access.
Push helm packages
Tick this checkbox if you wish to push helm charts to your registry
Use as chart repository
Tick this checkbox if you want Devtron to pull helm charts from your registry and display them on its chart store. Also, you will have to provide a list of repositories (present within your registry) for Devtron to successfully pull the helm charts.
Set as default registry
Tick this checkbox to set your registry as the default registry hub for your images or artifacts
Registry URL
Example of URL format: xxxxxxxxxxxx.dkr.ecr.<region>.amazonaws.com where xxxxxxxxxxxx is your 12-digit AWS account ID
Authentication Type
Select one of the authentication types:
EC2 IAM Role: Authenticate with workernode IAM role and attach the ECR policy (AmazonEC2ContainerRegistryFullAccess) to the cluster worker nodes IAM role of your Kubernetes cluster.
User Auth: It is a key-based authentication, attach the ECR policy (AmazonEC2ContainerRegistryFullAccess) to the IAM user.
Access key ID: Your AWS access key
Secret access key: Your AWS secret access key ID
Username
Provide the username of the Docker Hub account you used for creating your registry.
Password/Token
Provide the password/Token corresponding to your docker hub account. It is recommended to use Token for security purpose.
Registry URL/Login Server
Example of URL format: xxx.azurecr.io
Username/Registry Name
Provide the username of your Azure container registry
Password
Provide the password of your Azure container registry
Registry URL
Example of URL format: region-docker.pkg.dev
Service Account JSON File
Paste the content of the service account JSON file
Username
Provide the username of your Quay account
Token
Provide the password of your Quay account
Registry URL
Enter the URL of your private registry
Username
Provide the username of your account where you have created your registry
Password/Token
Provide the password or token corresponding to the username of your registry
Advanced Registry URL Connection Options
Allow Only Secure Connection: Tick this option for the registry to allow only secure connections
Allow Secure Connection With CA Certificate: Tick this option for the registry to allow secure connection by providing a private CA certificate (ca.crt)
Allow Insecure Connection: Tick this option to make an insecure communication with the registry (for e.g., when SSL certificate is expired)
Do not inject credentials to clusters
Select the clusters for which you do not want to inject credentials
Auto-inject credentials to clusters
Select the clusters for which you want to inject credentials
kubectl create -n <namespace> secret docker-registry regcred --docker-server=<your-registry-server> --docker-username=<your-name> --docker-password=<your-pword> --docker-email=<your-email>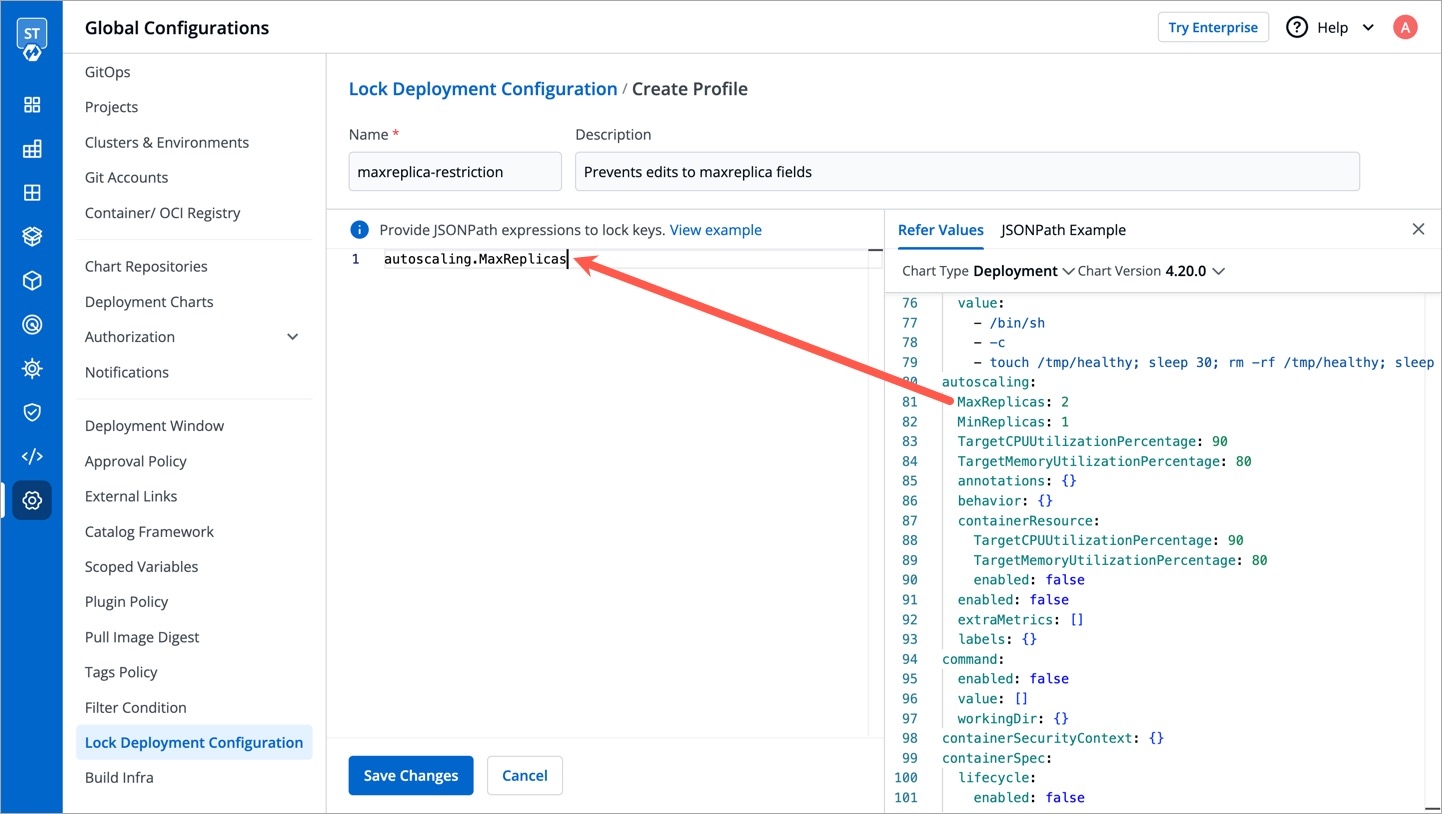
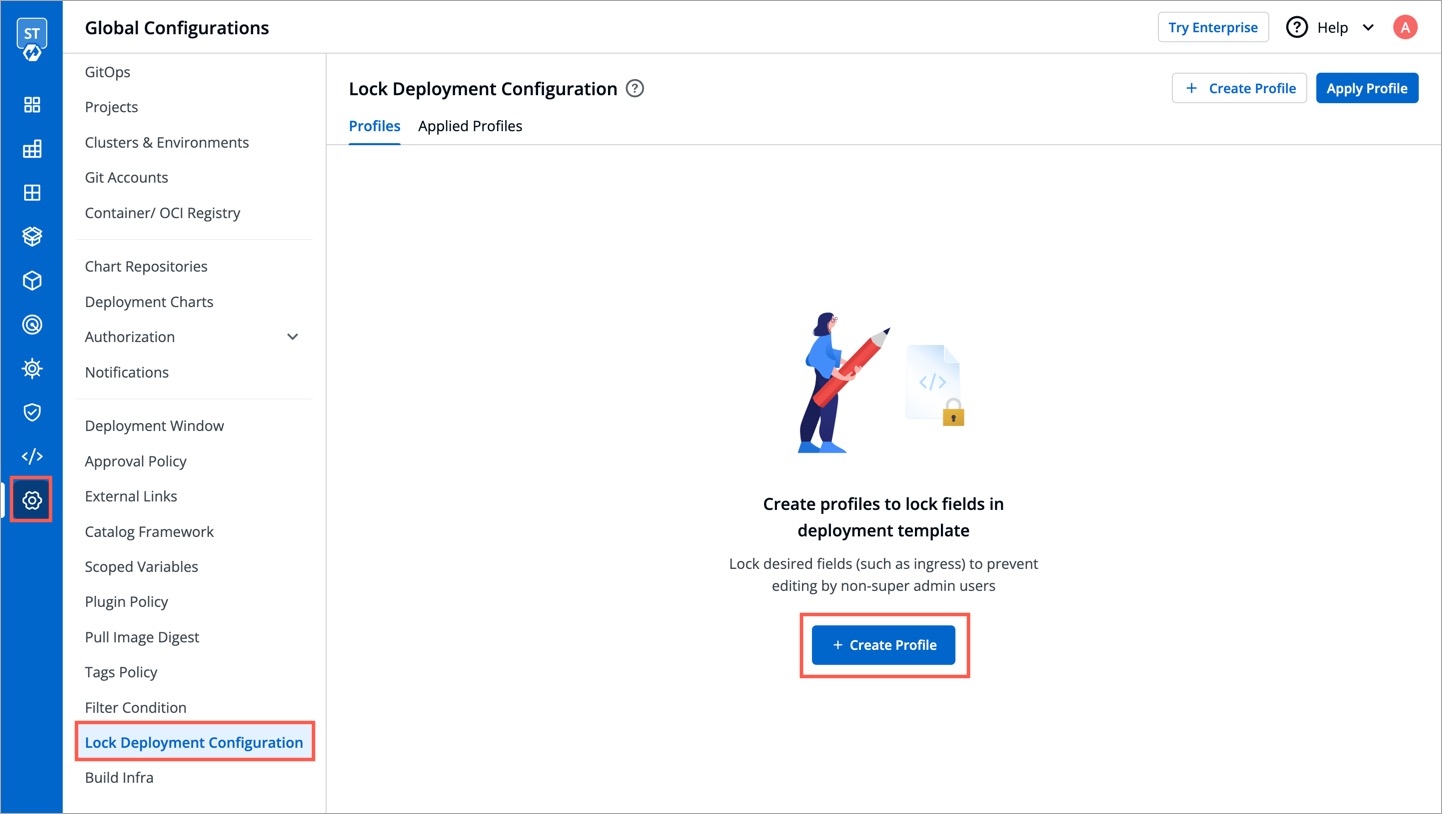
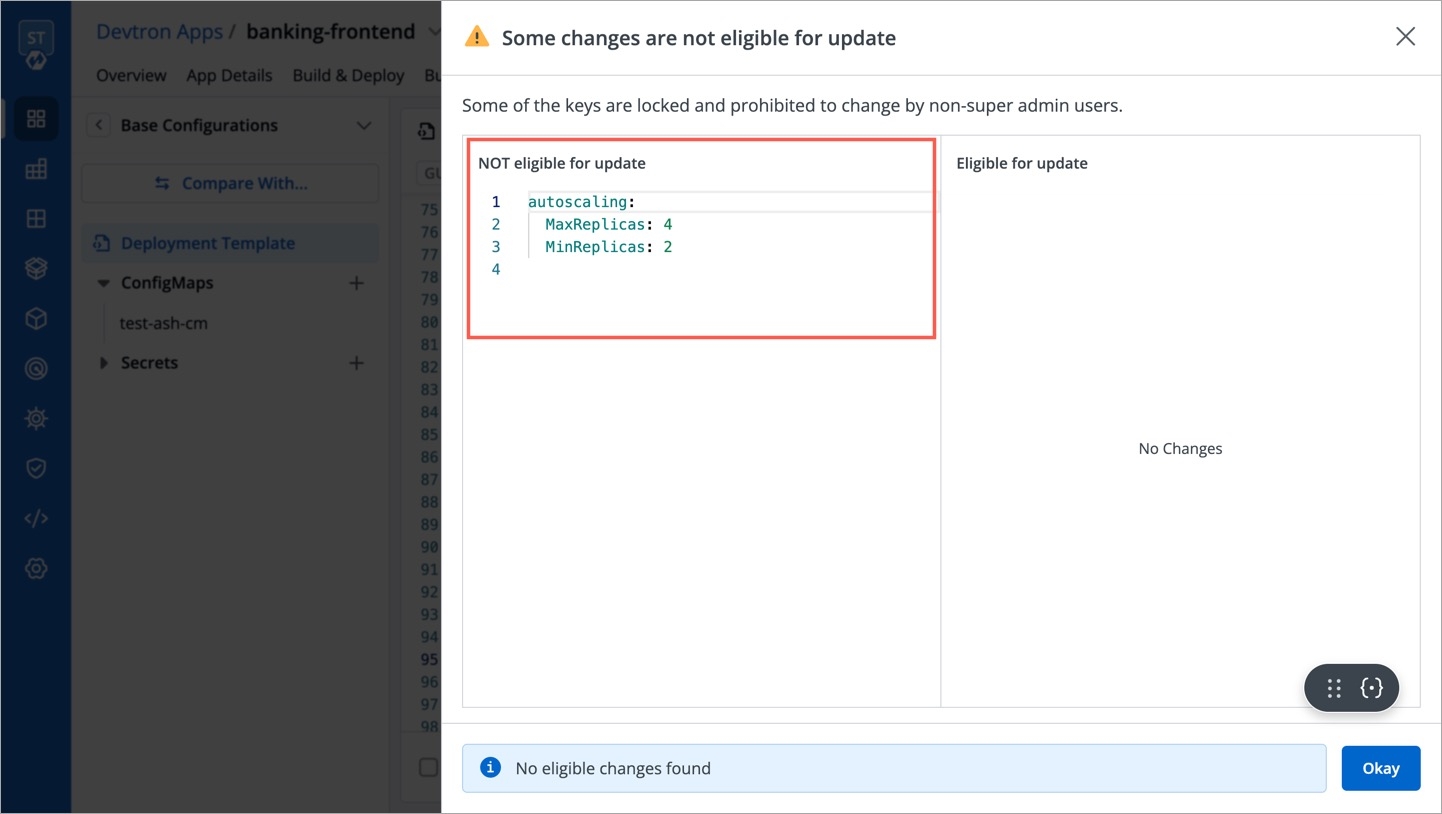
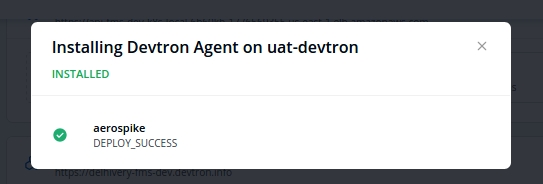
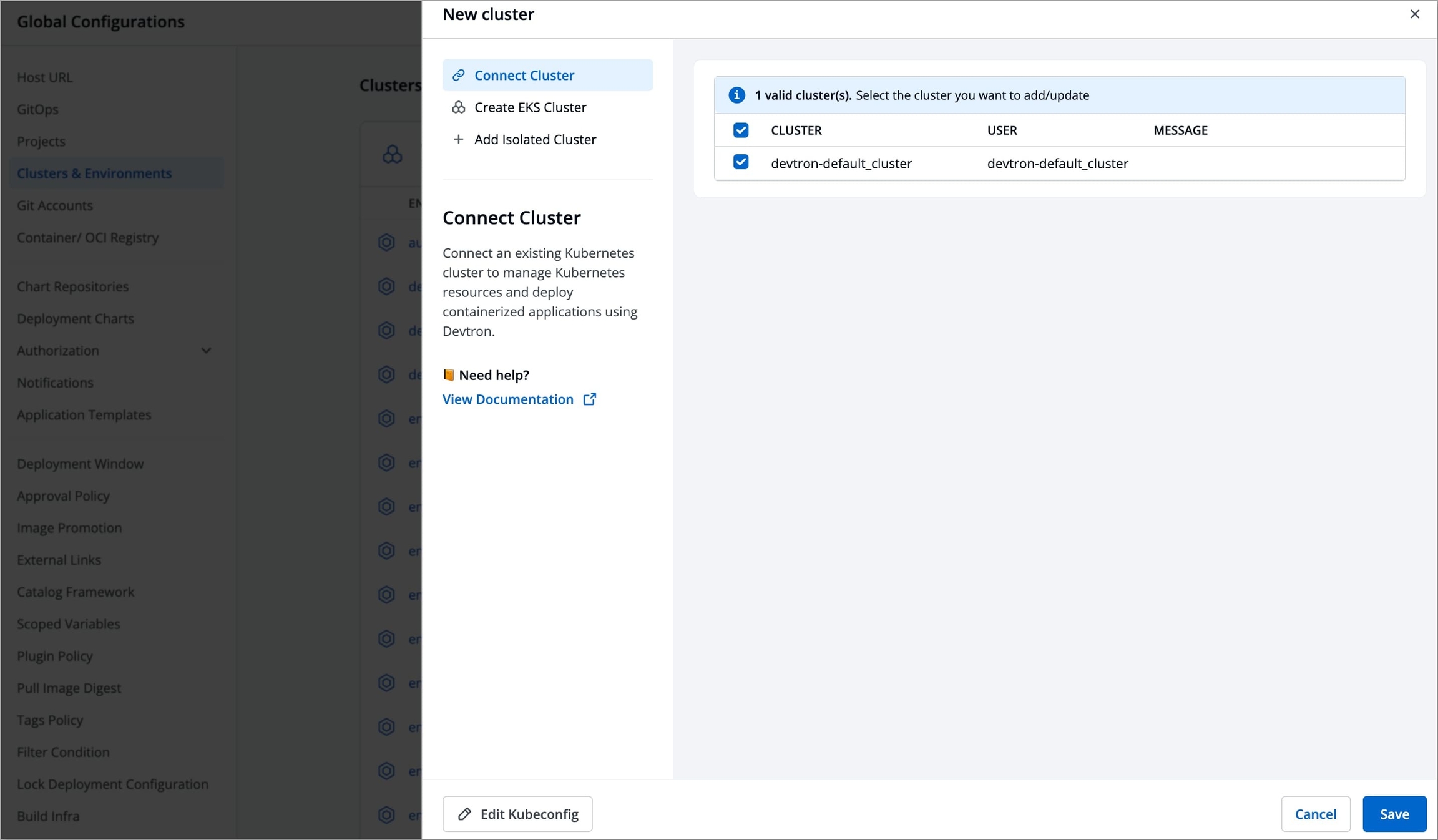
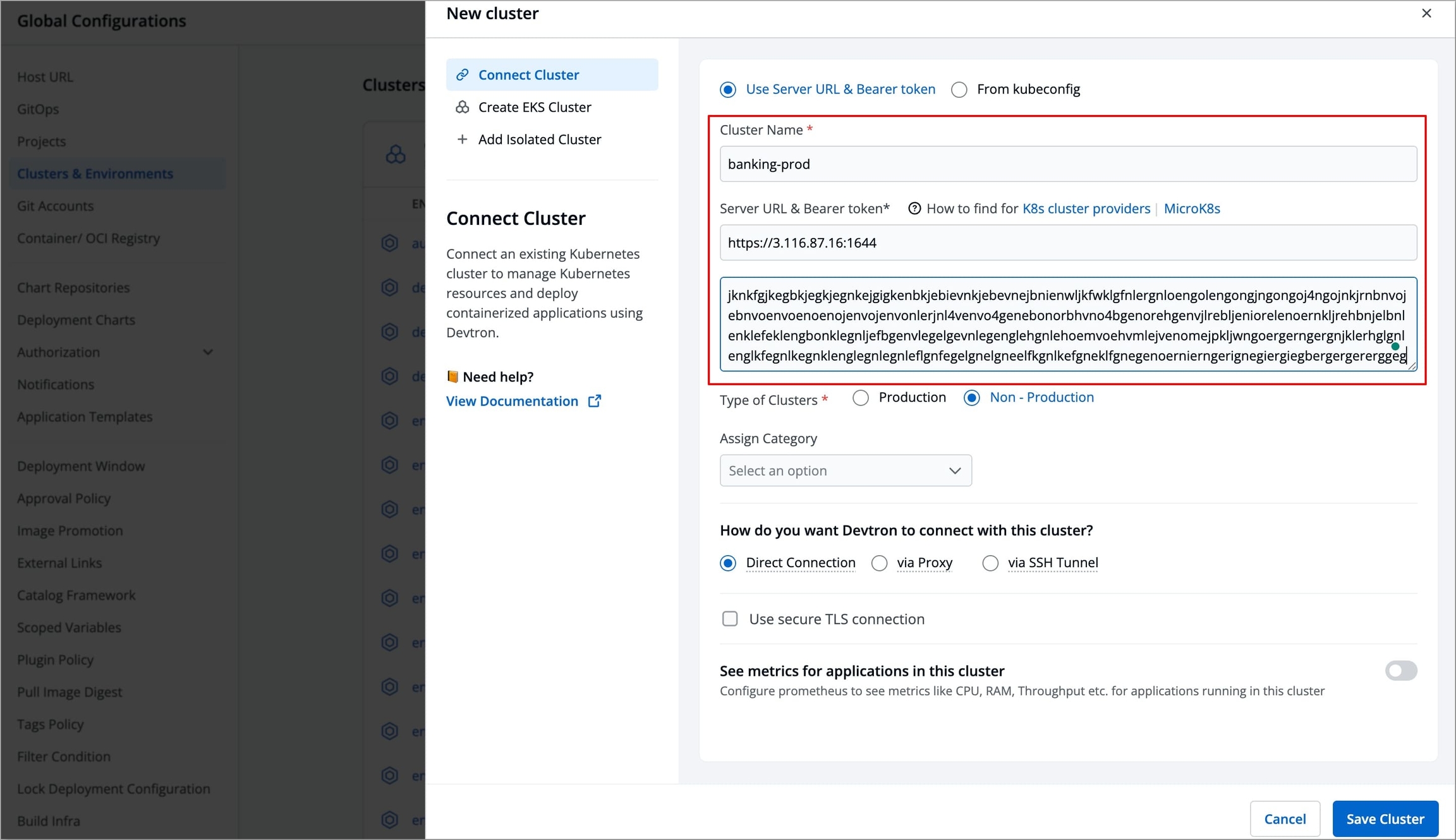
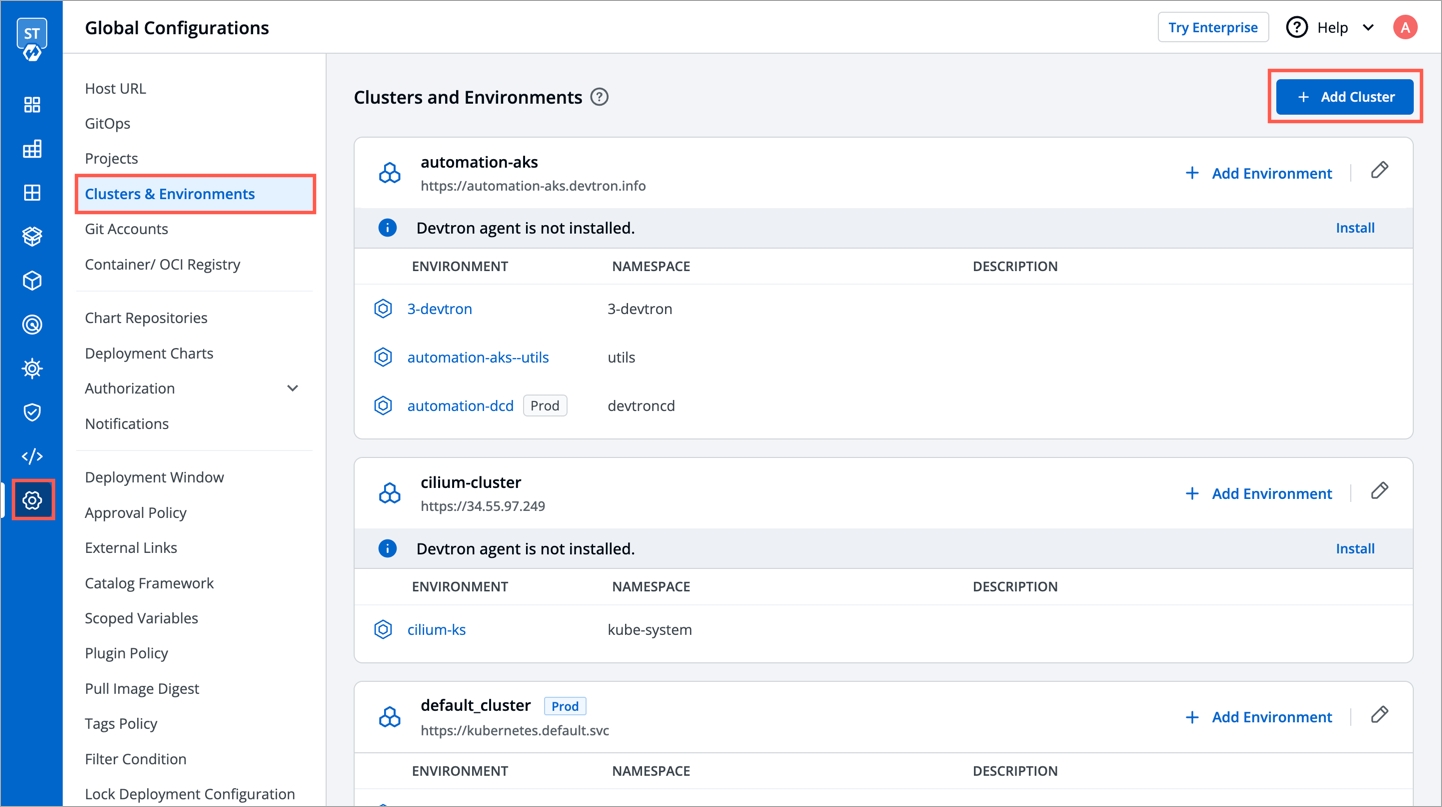
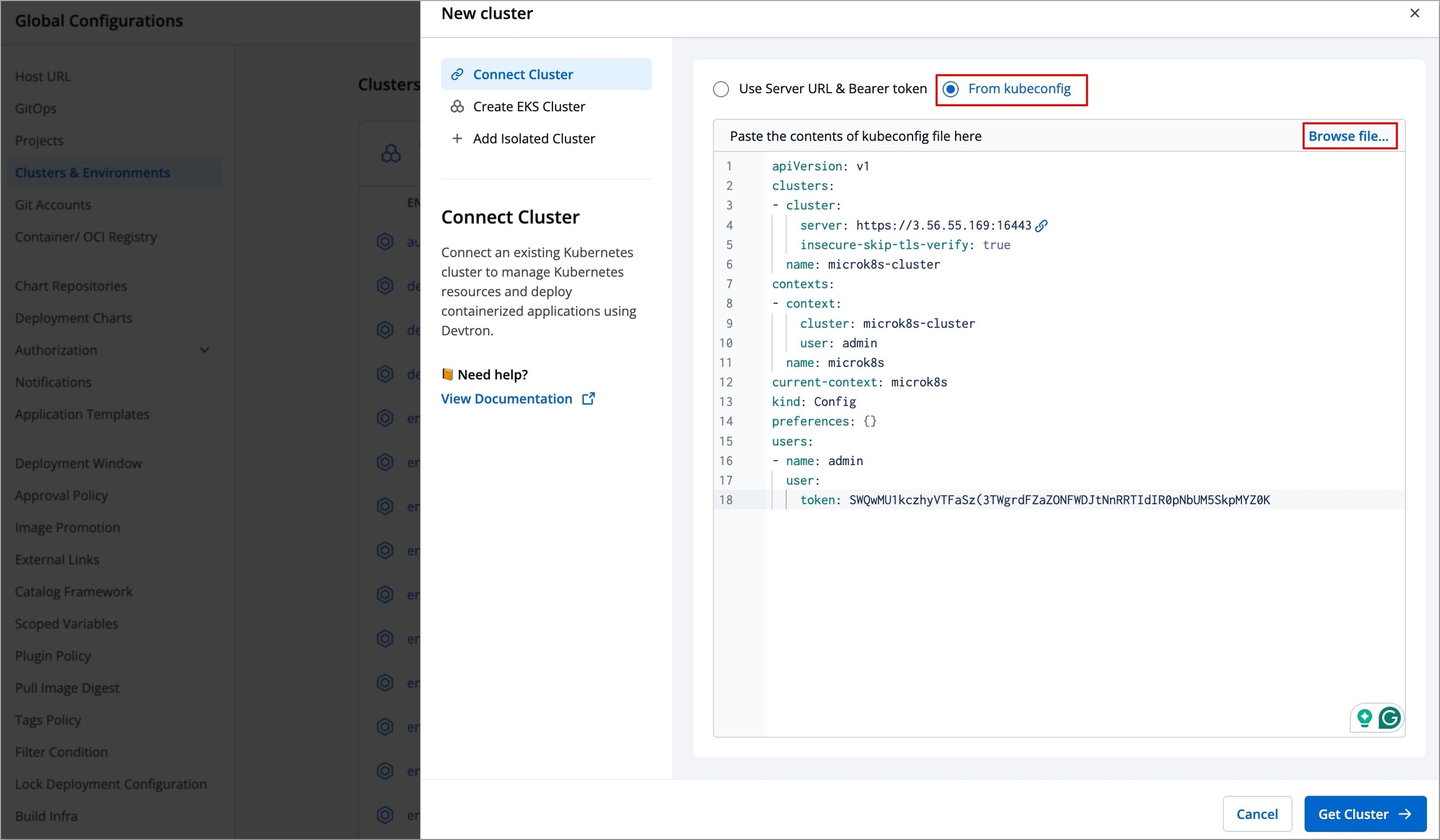
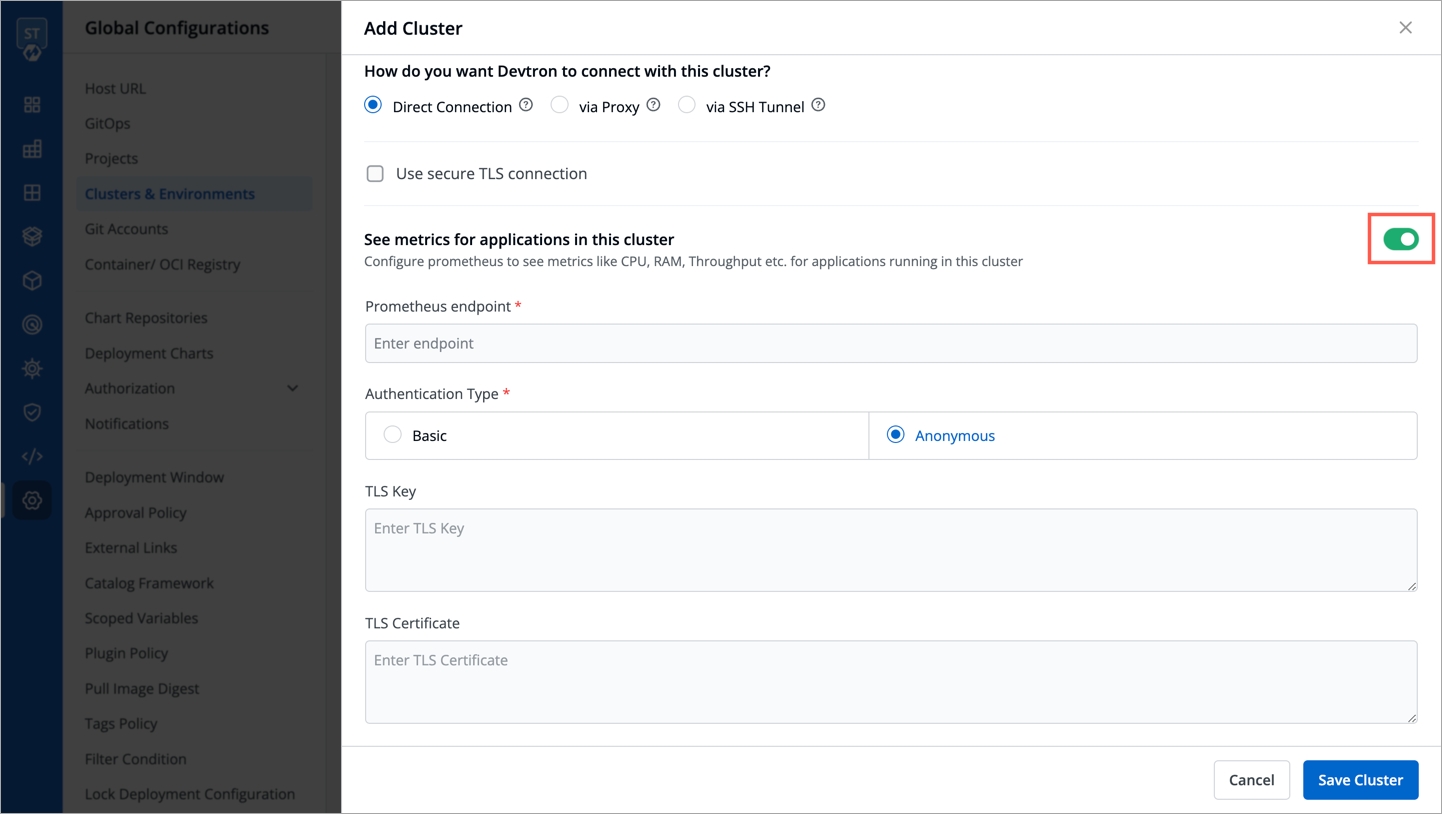
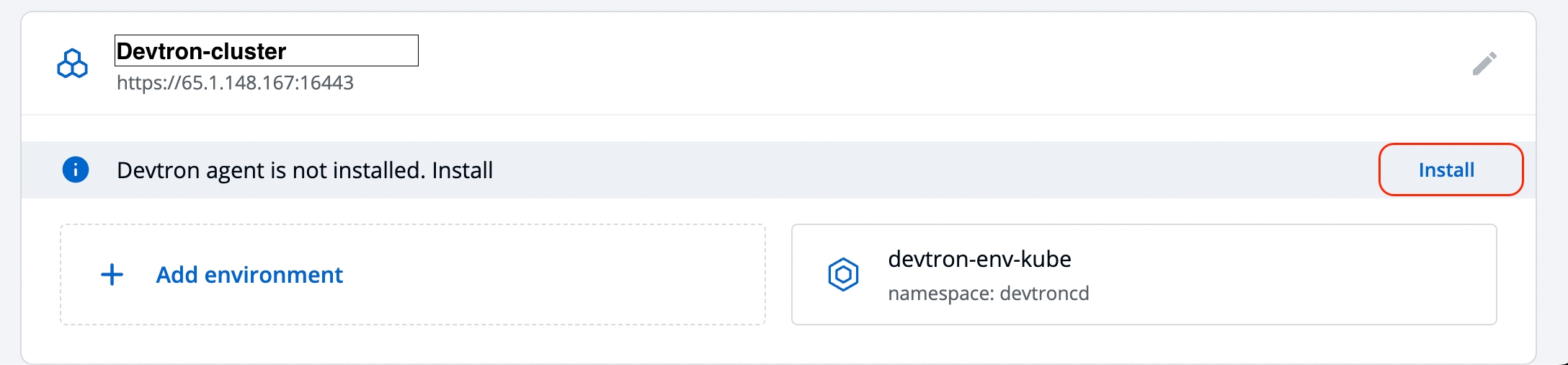
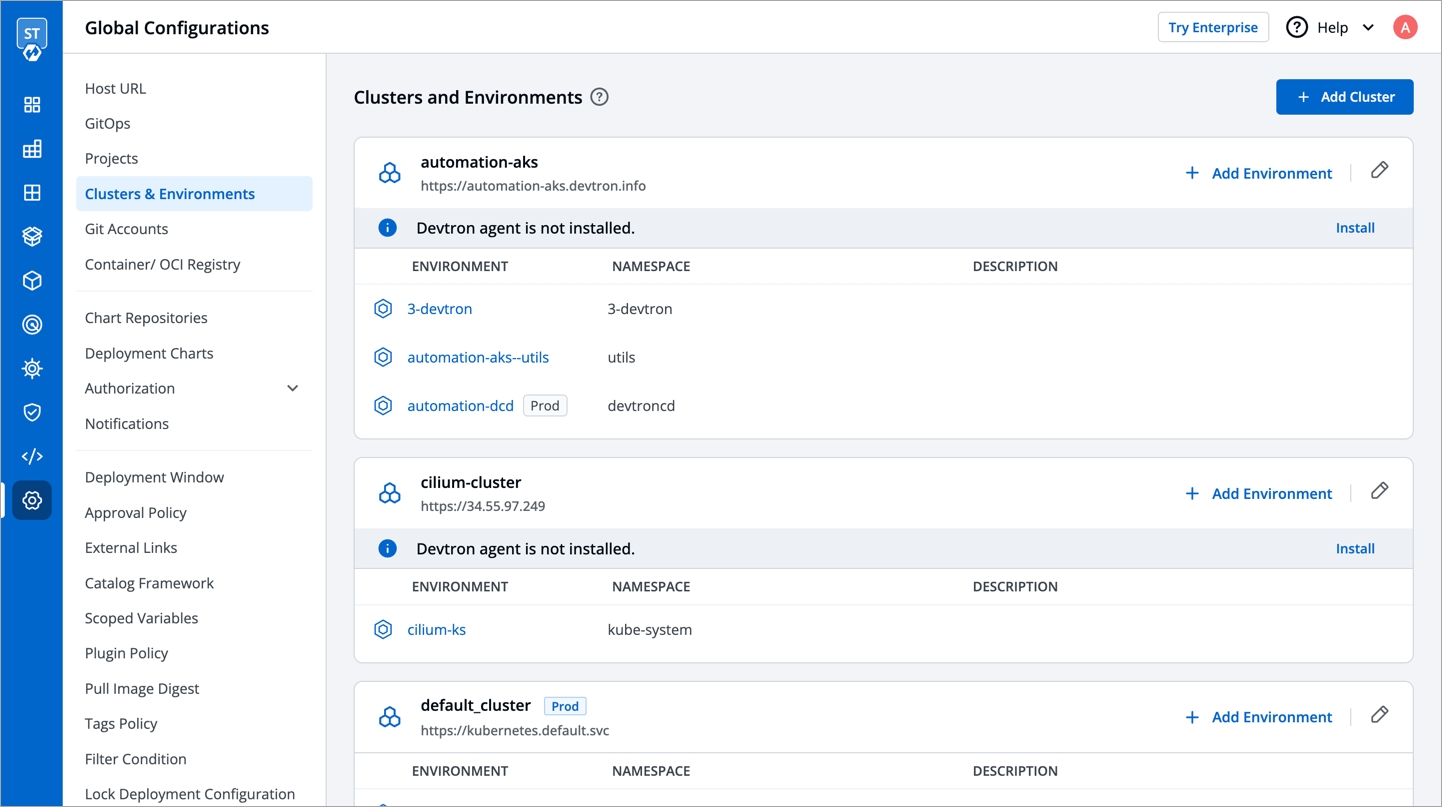
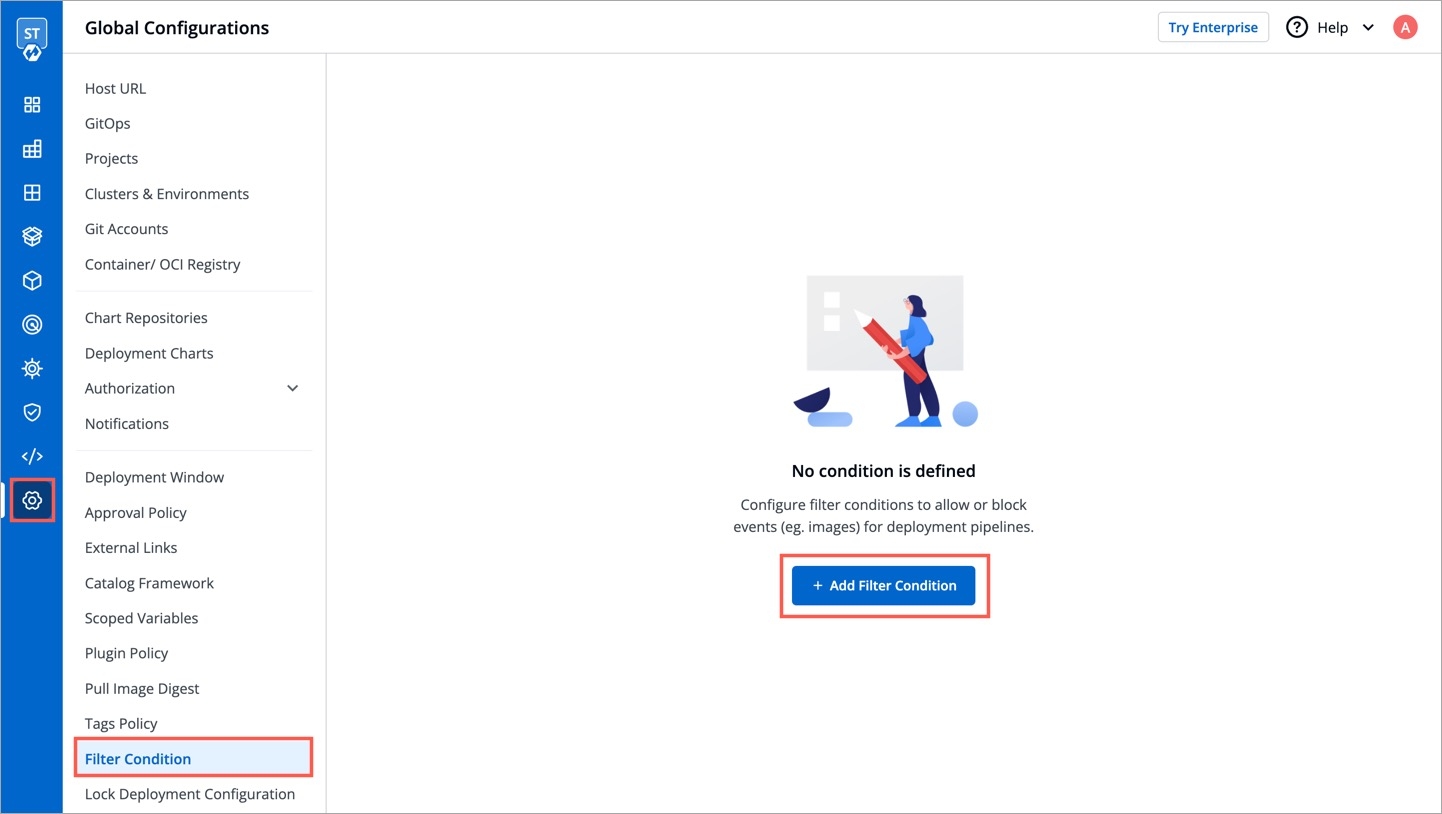
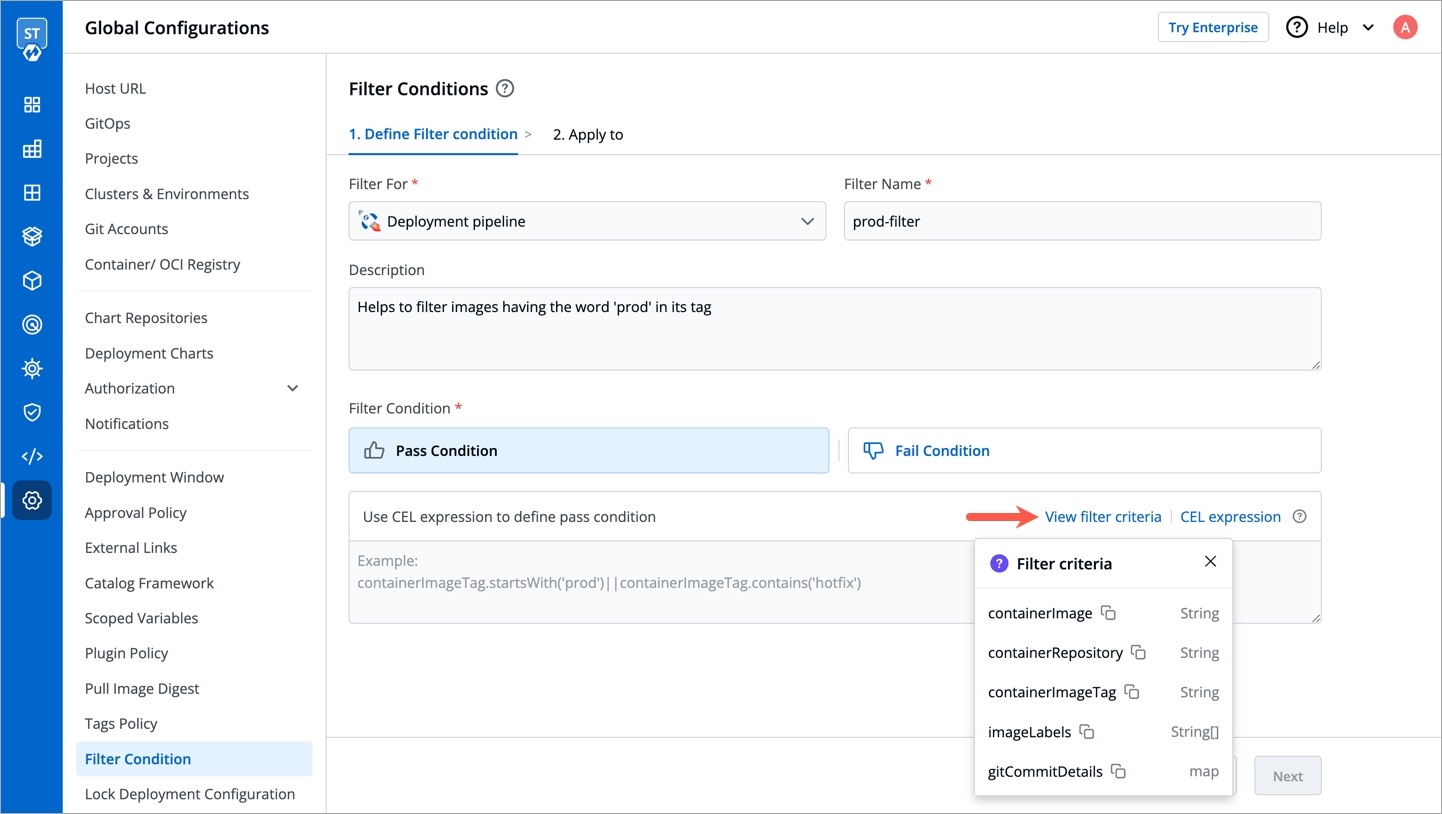
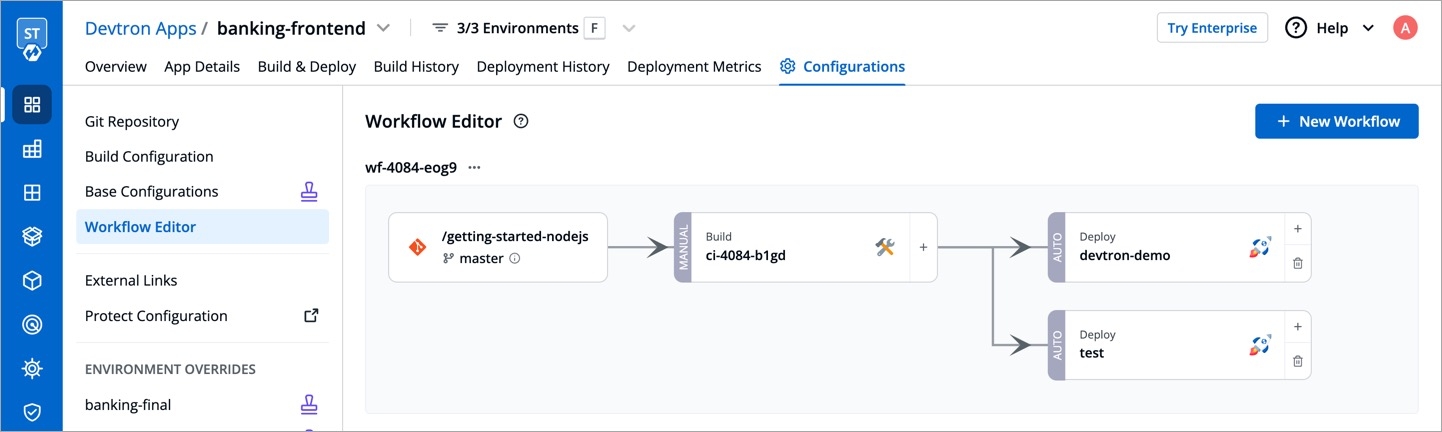
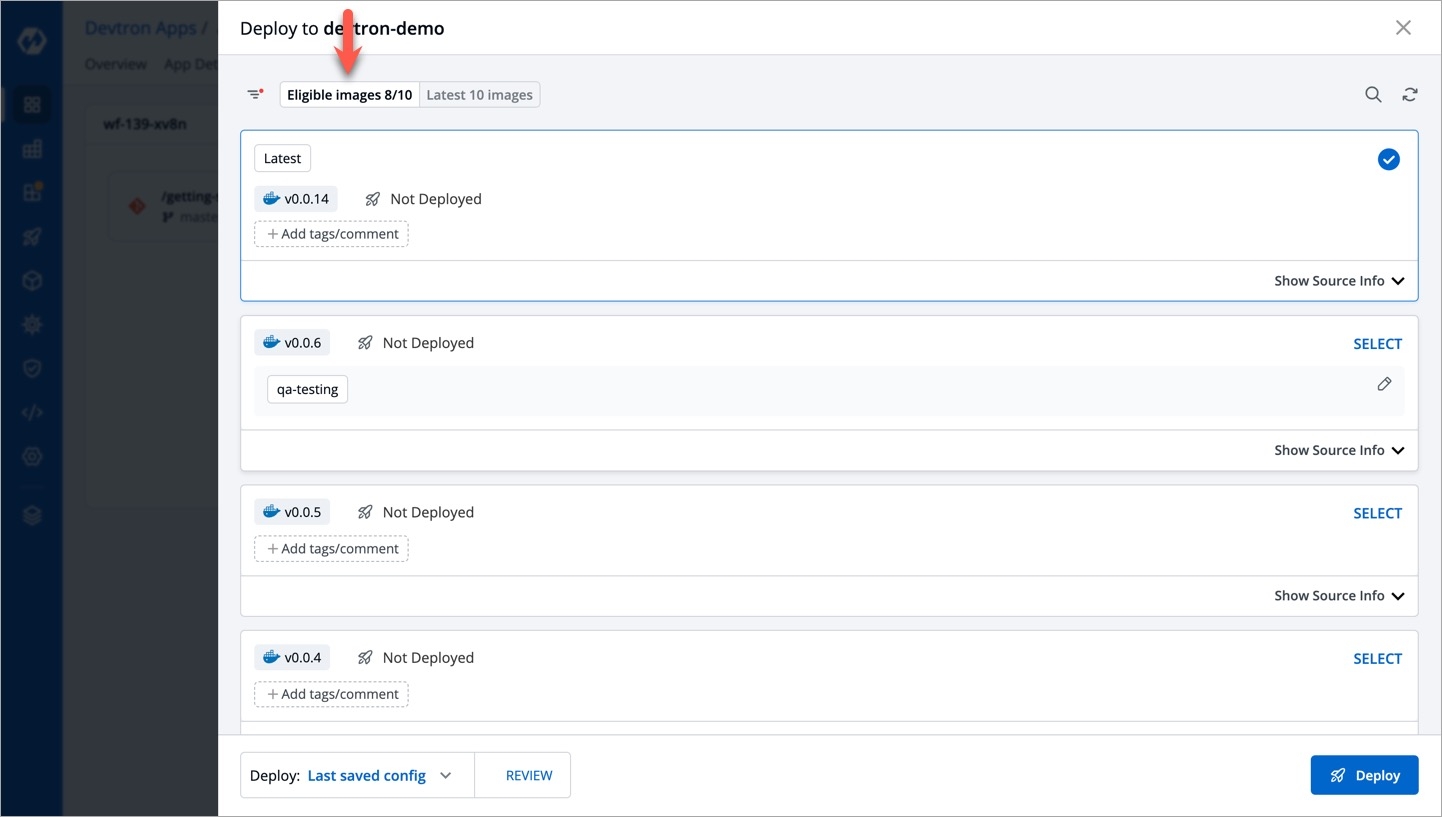
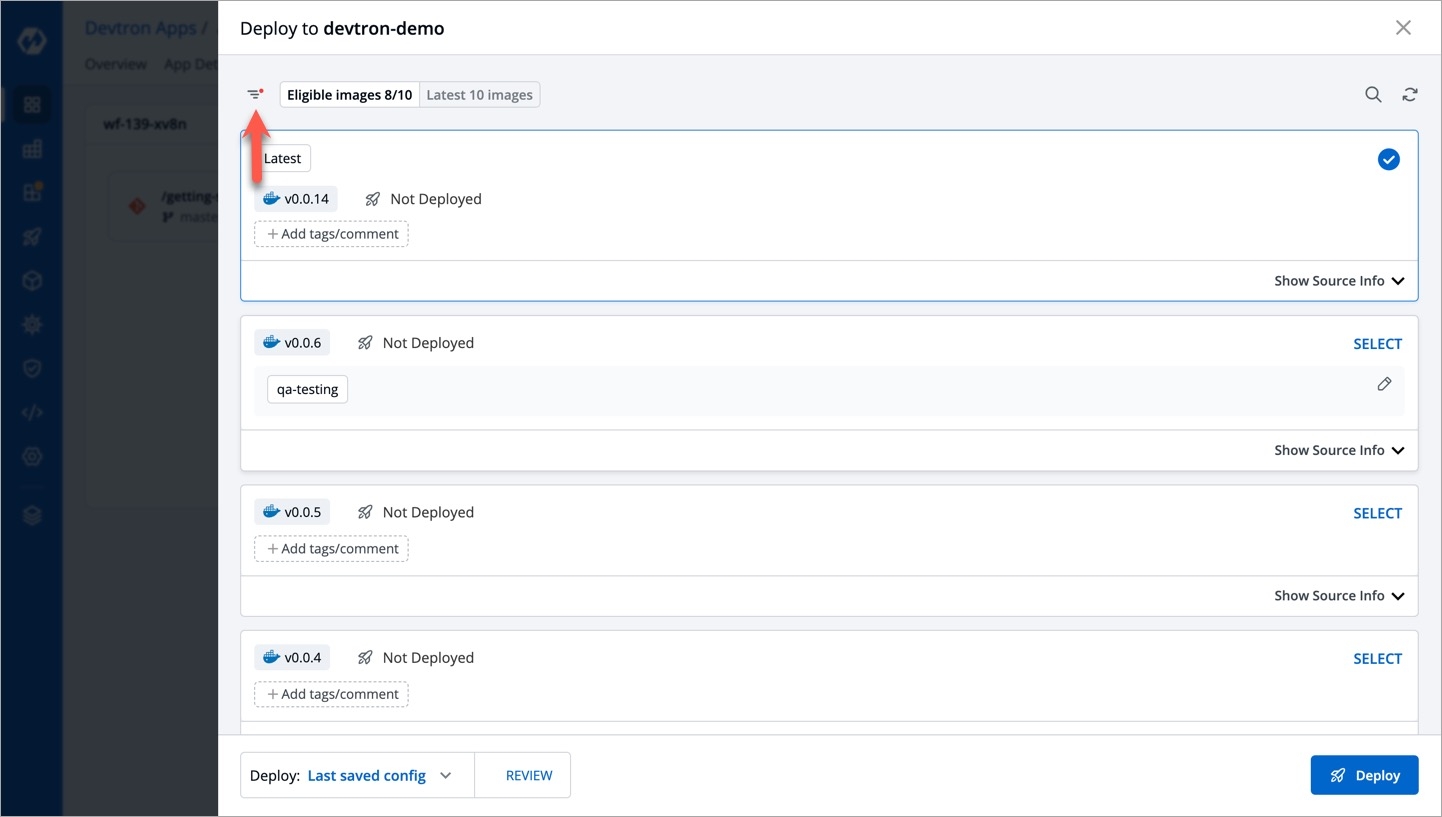
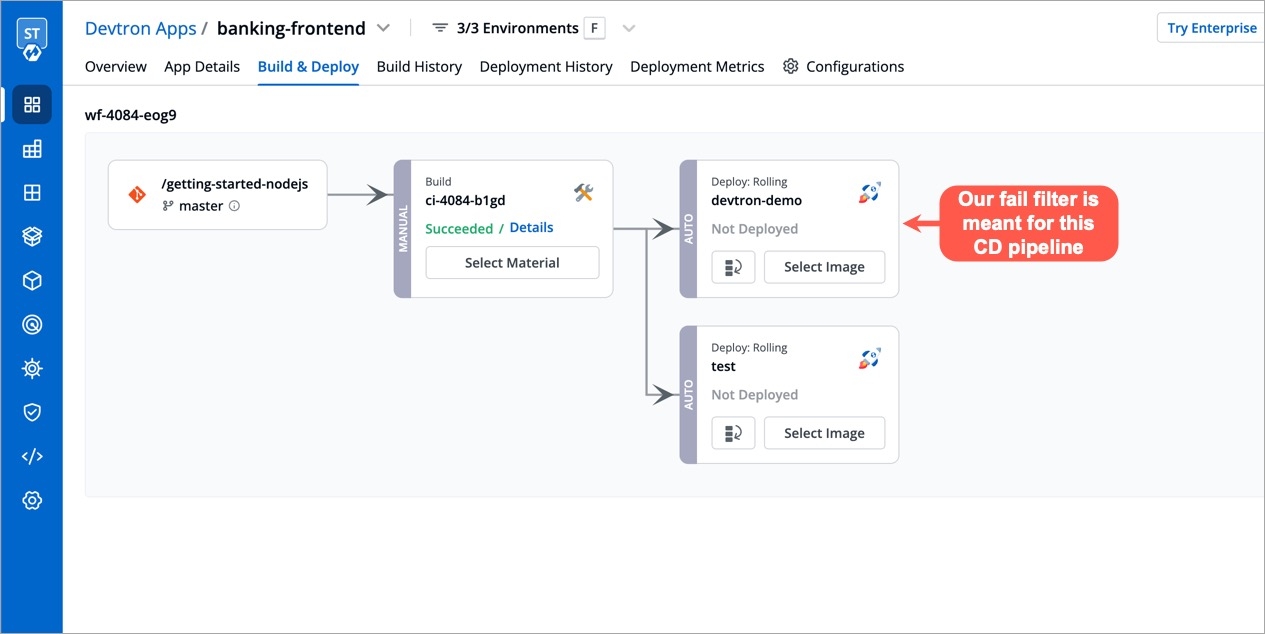
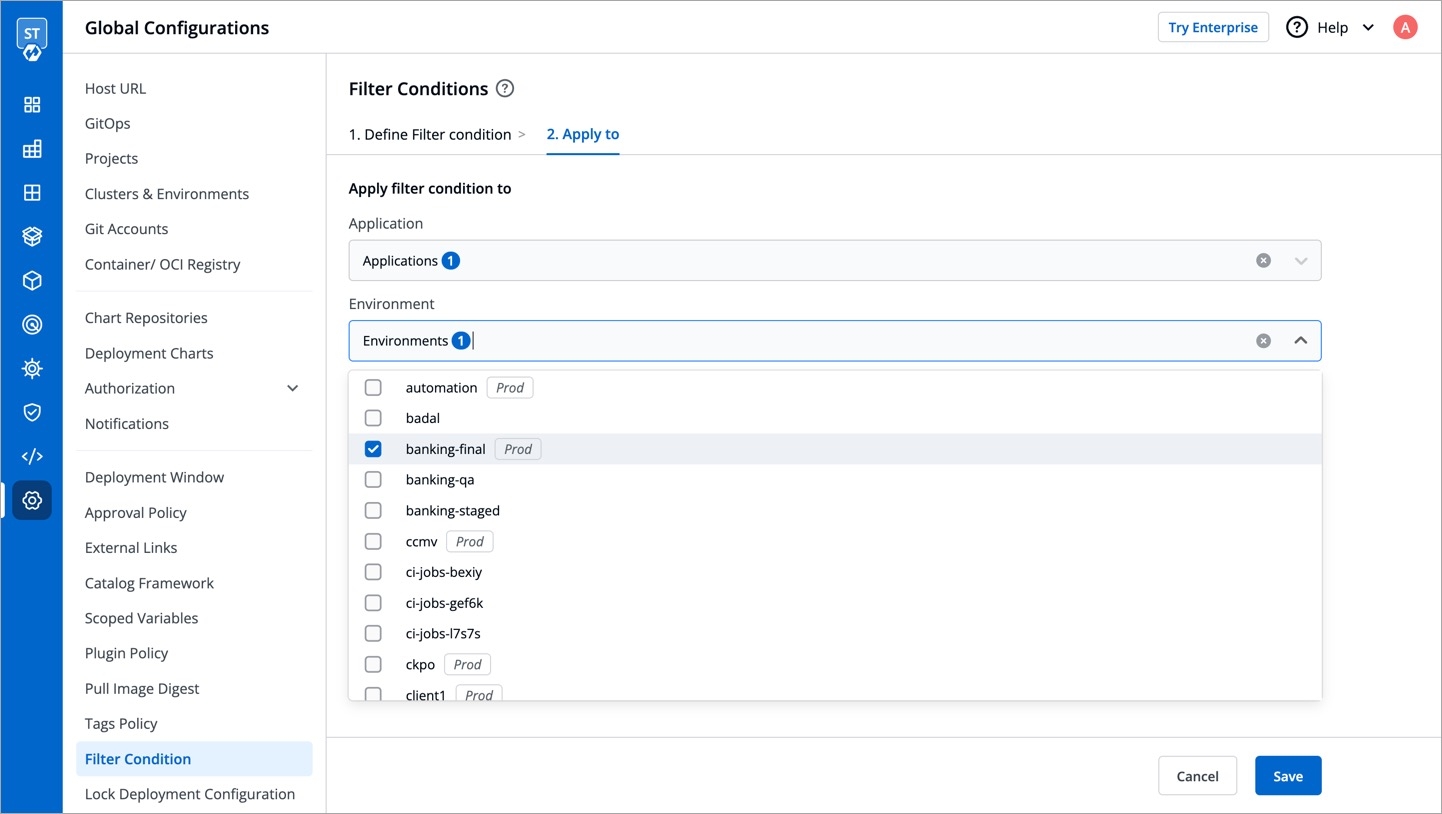
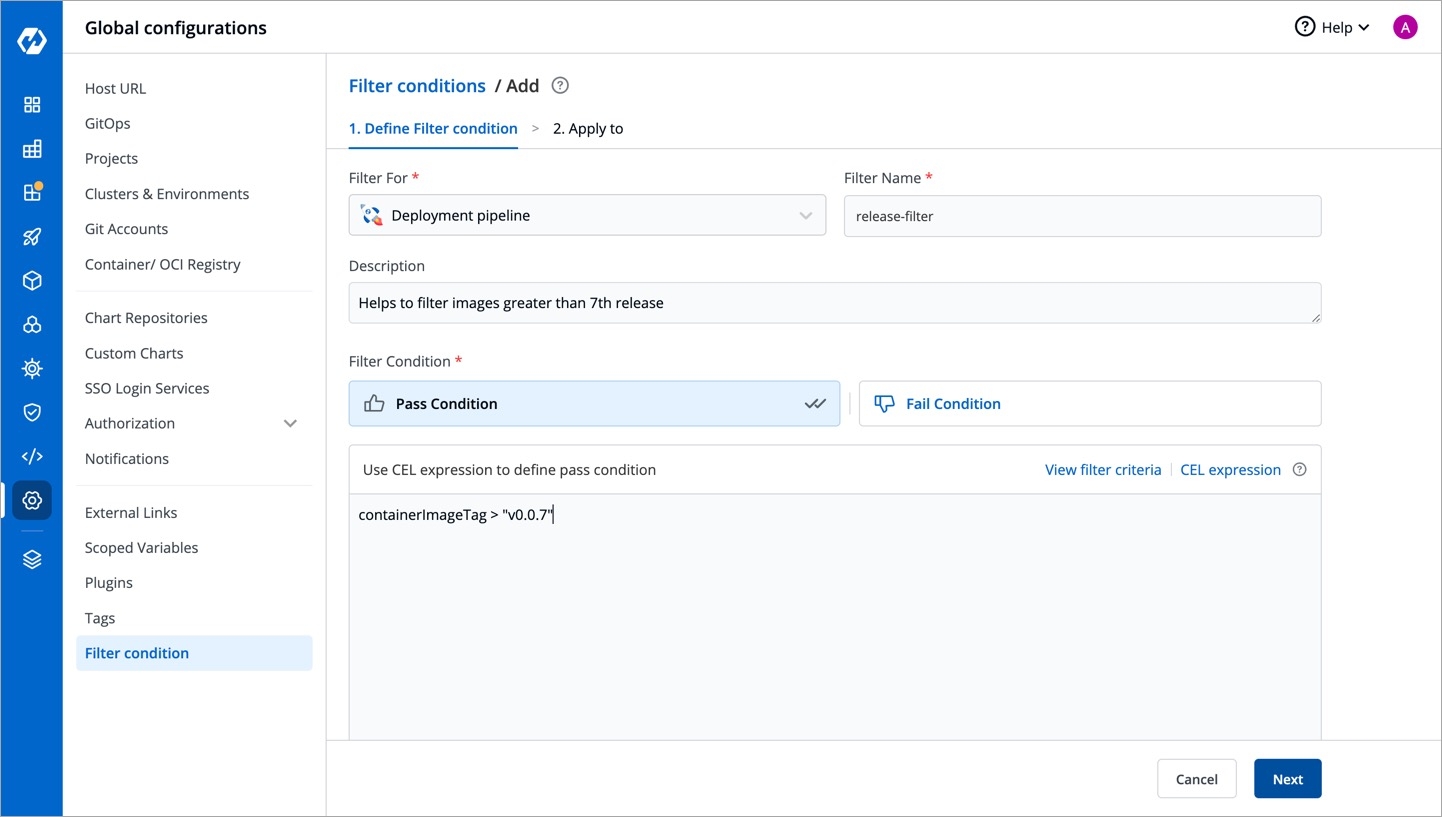
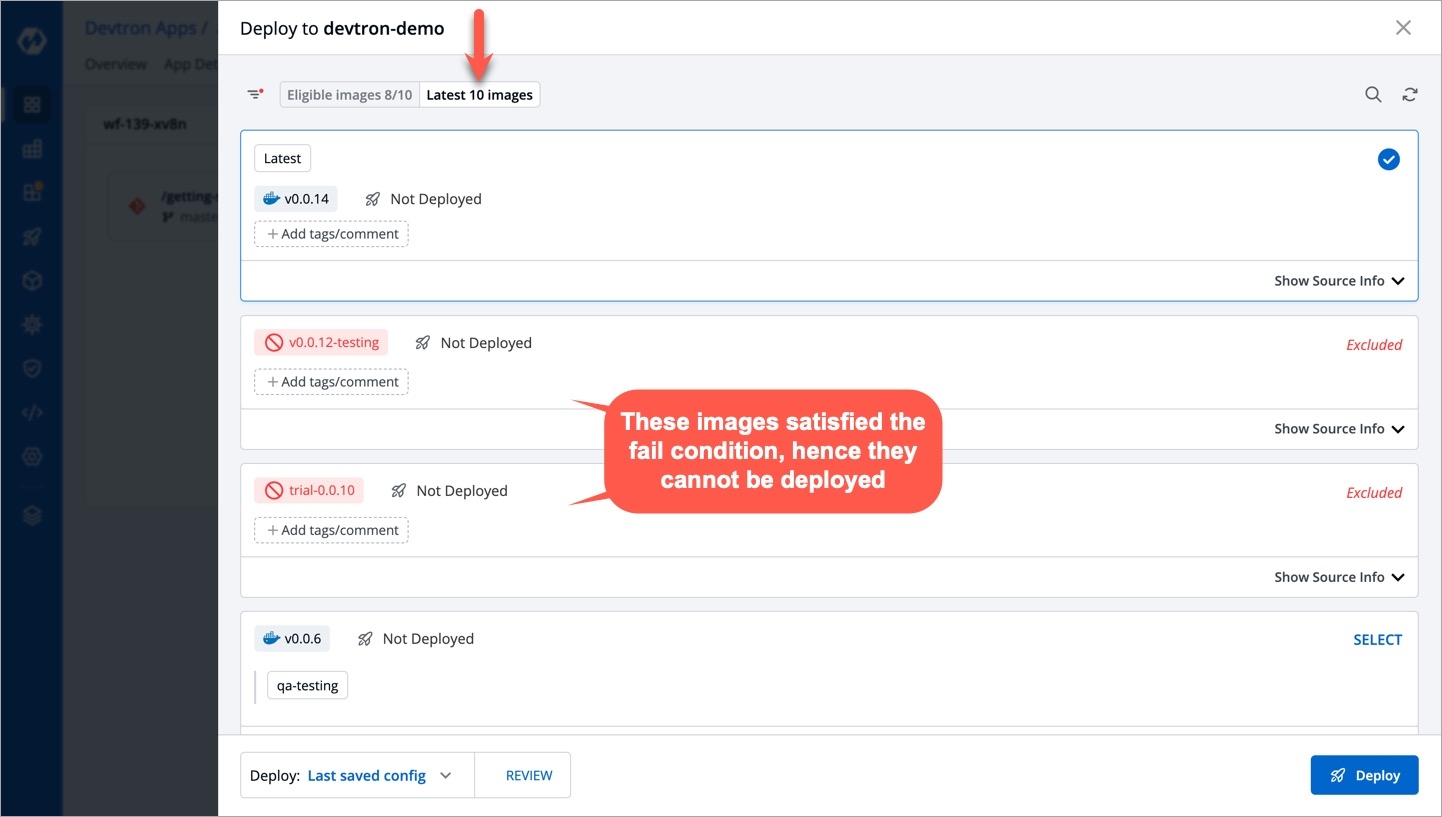
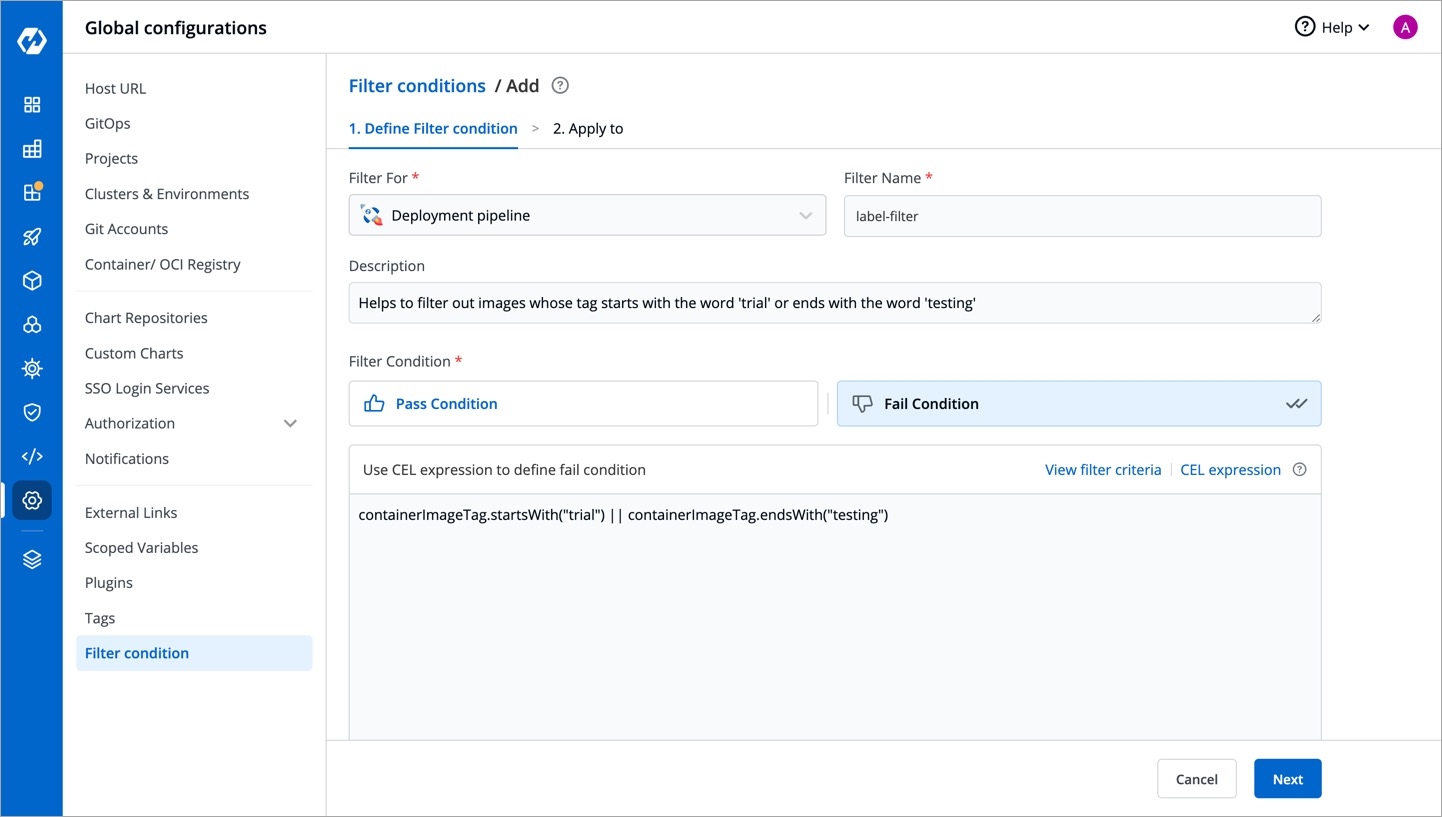
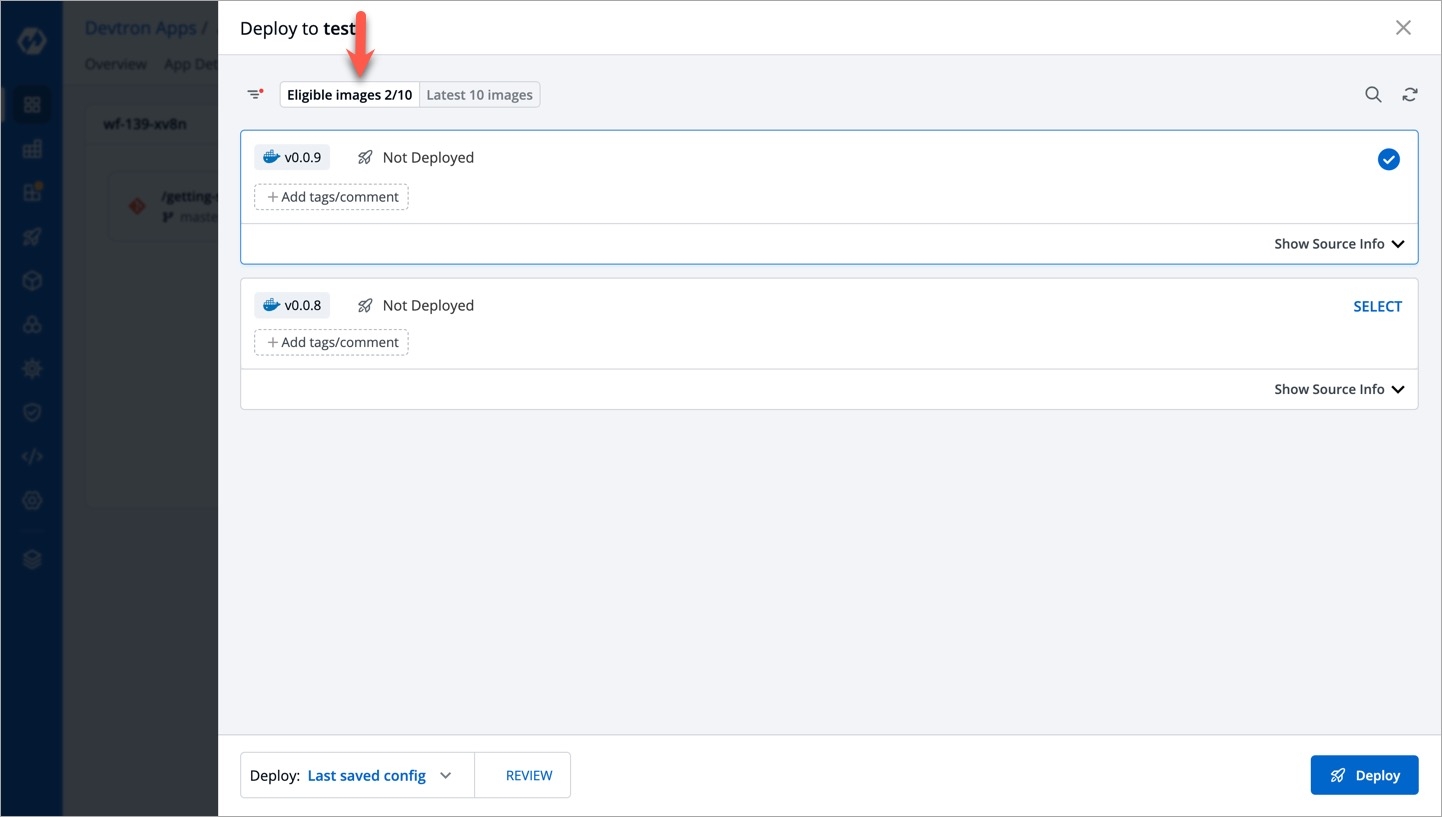
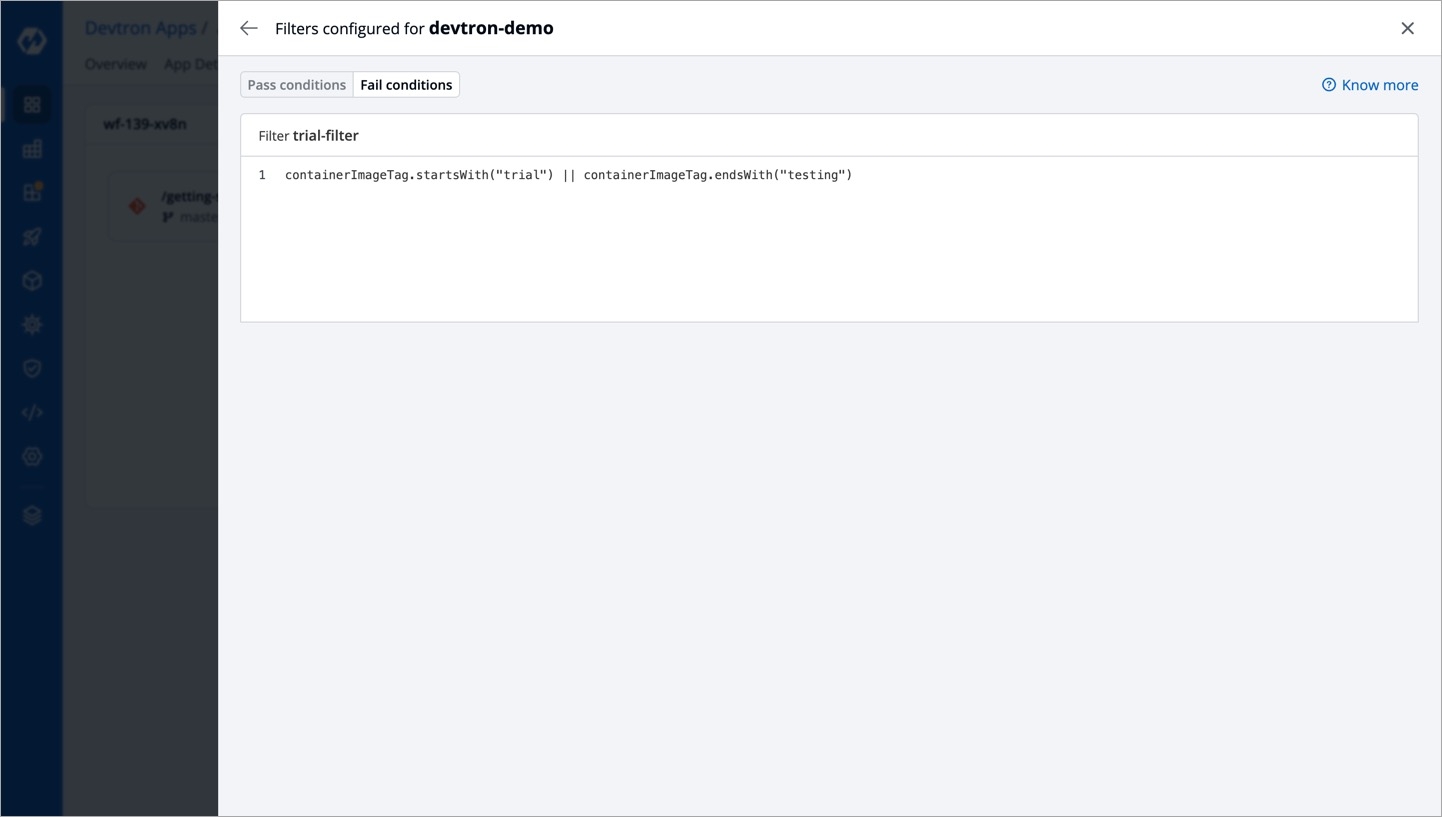
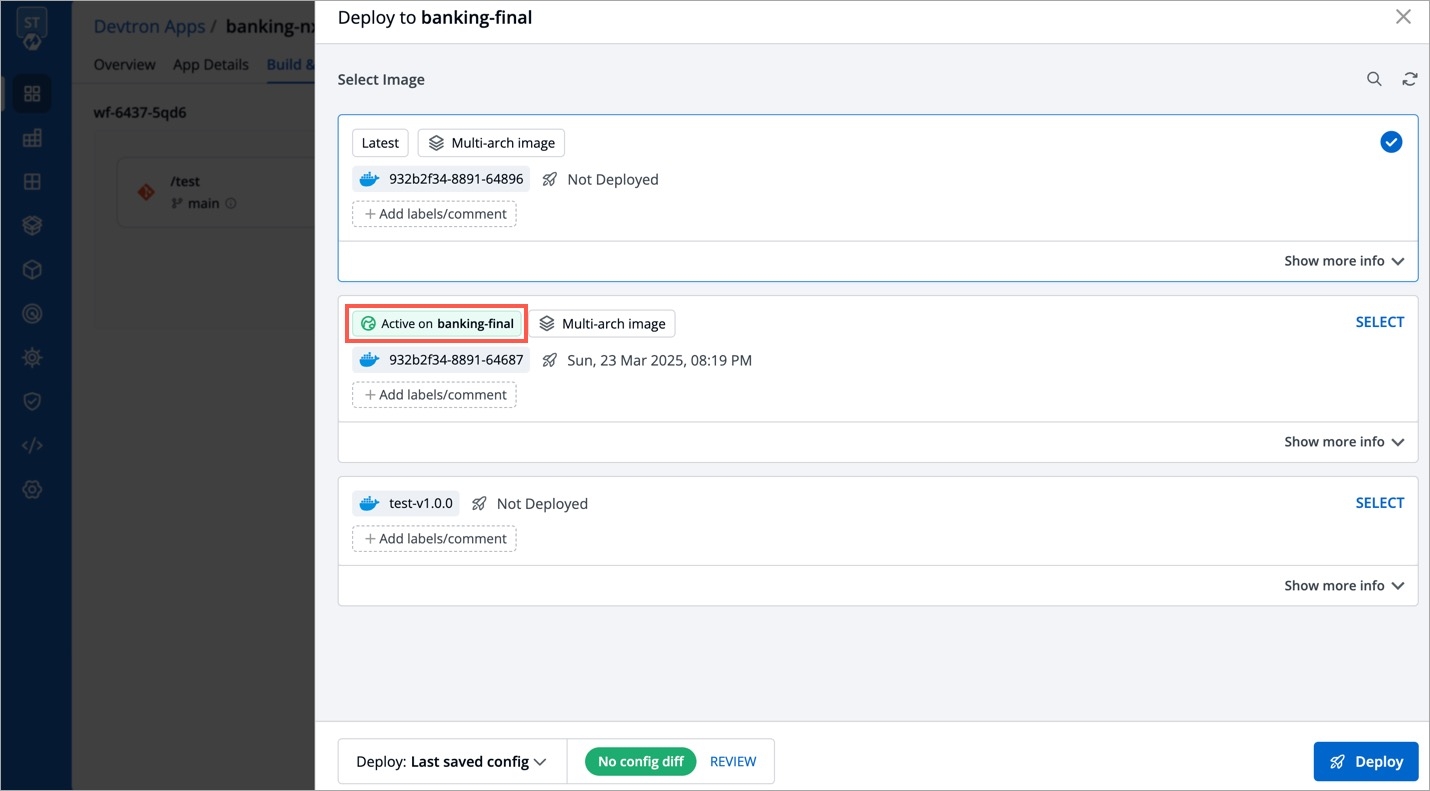
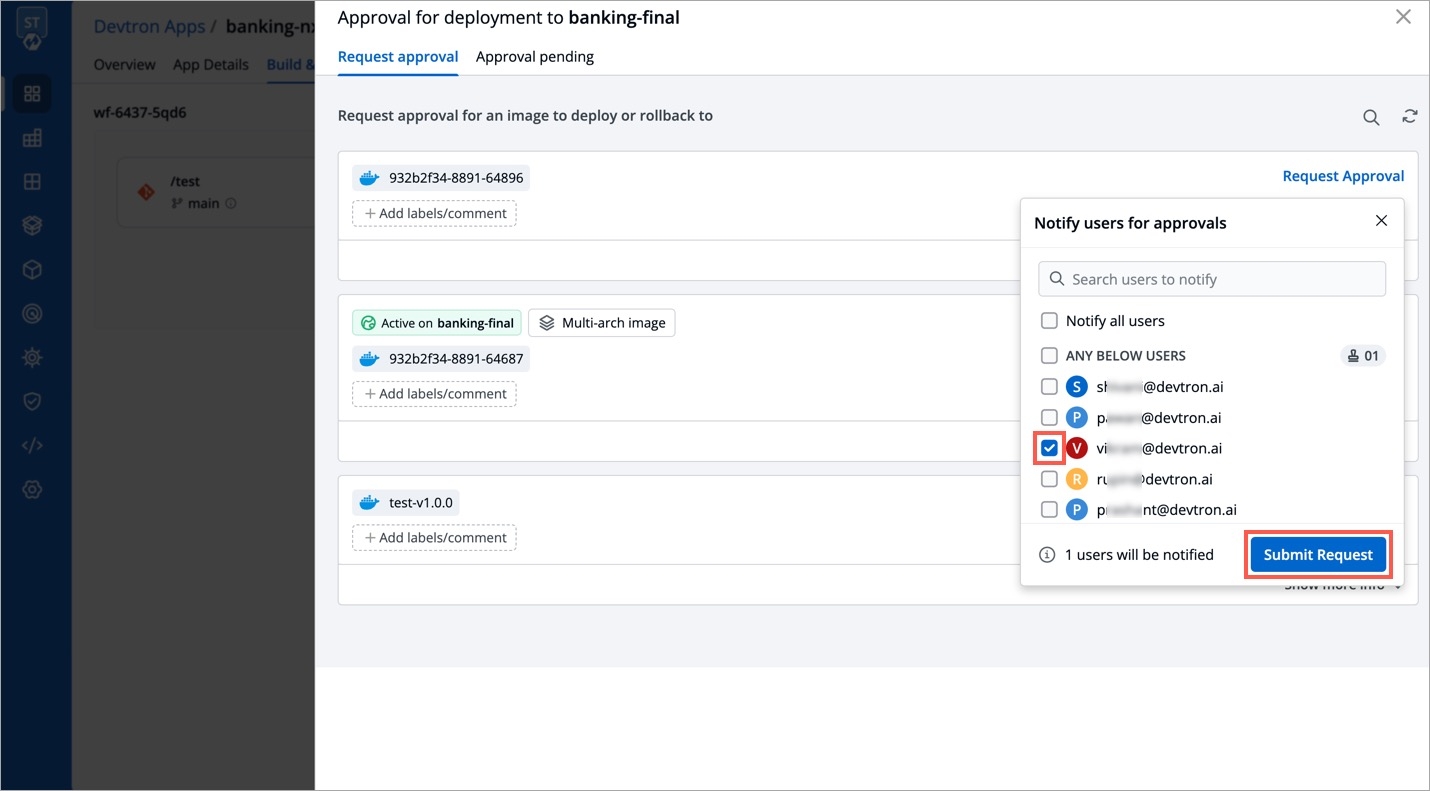
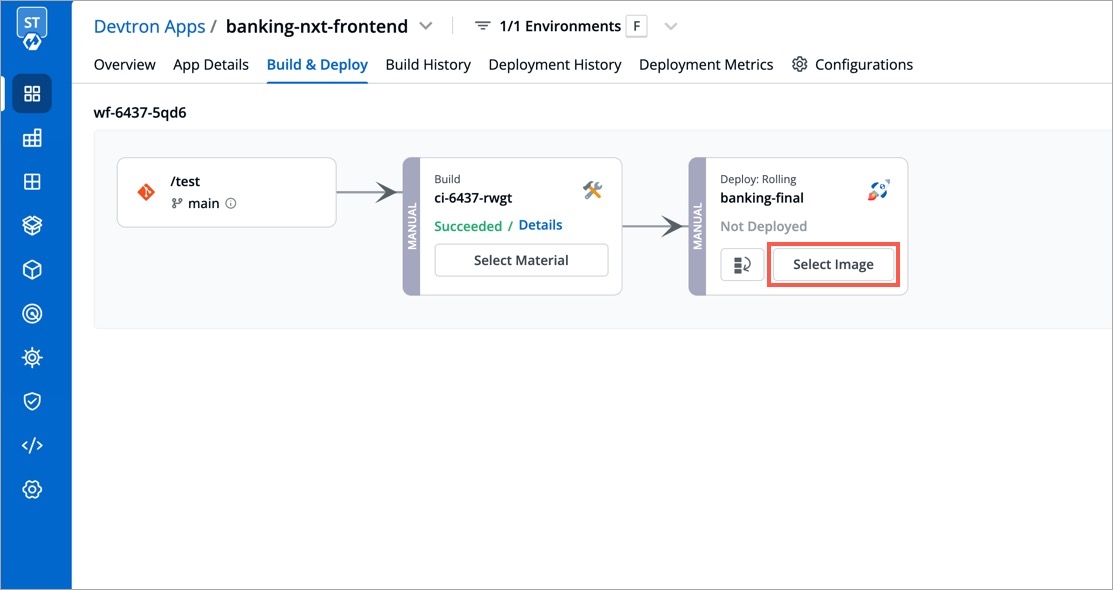
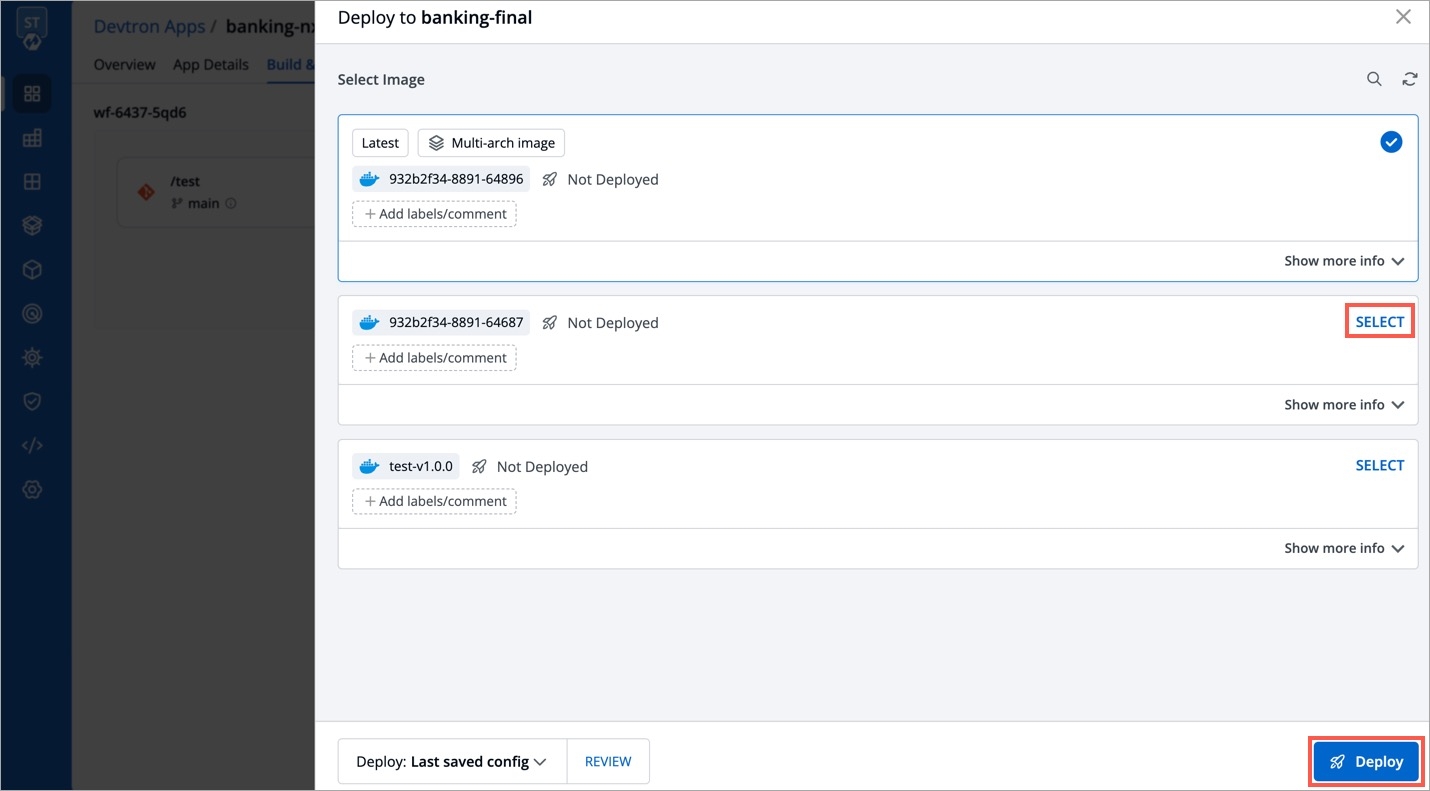
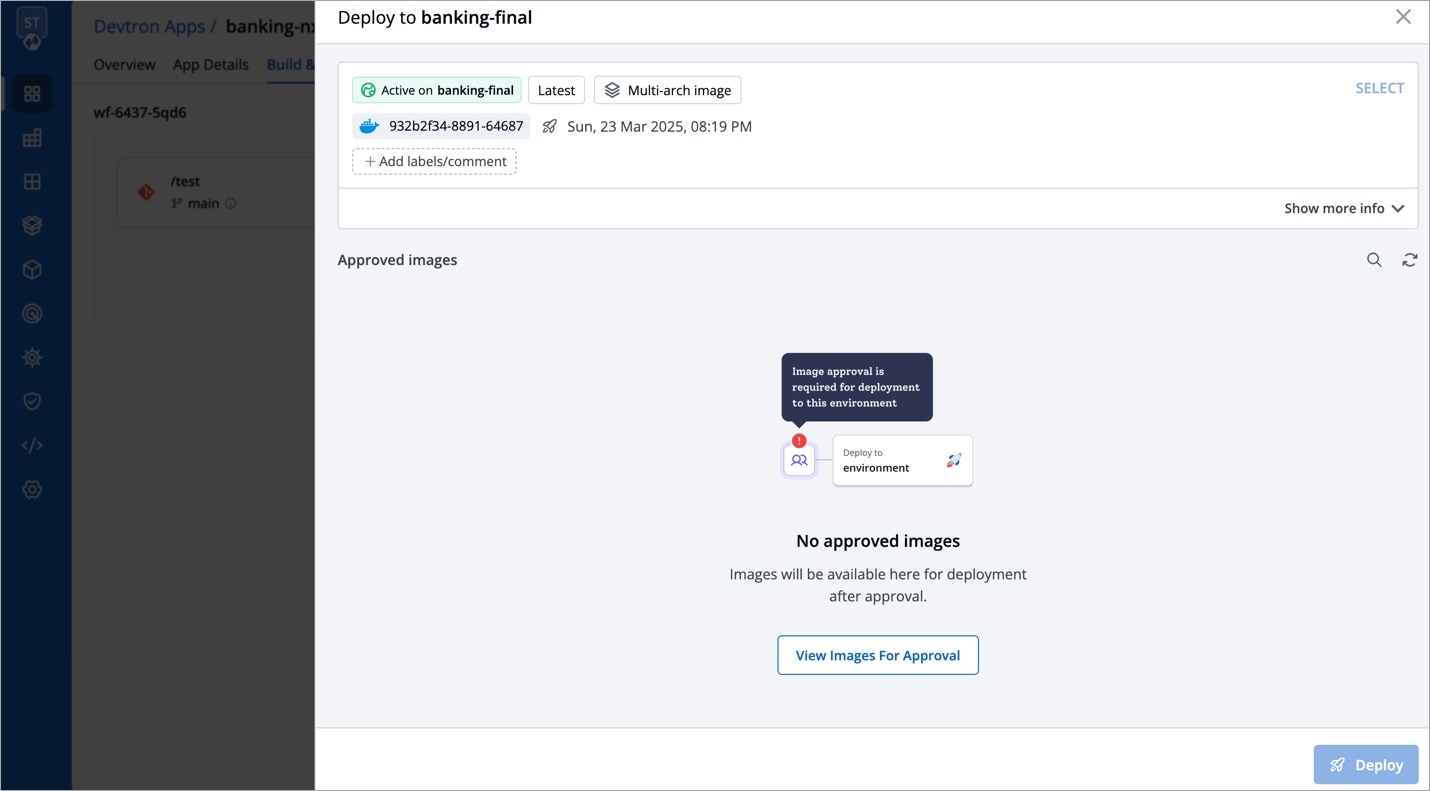
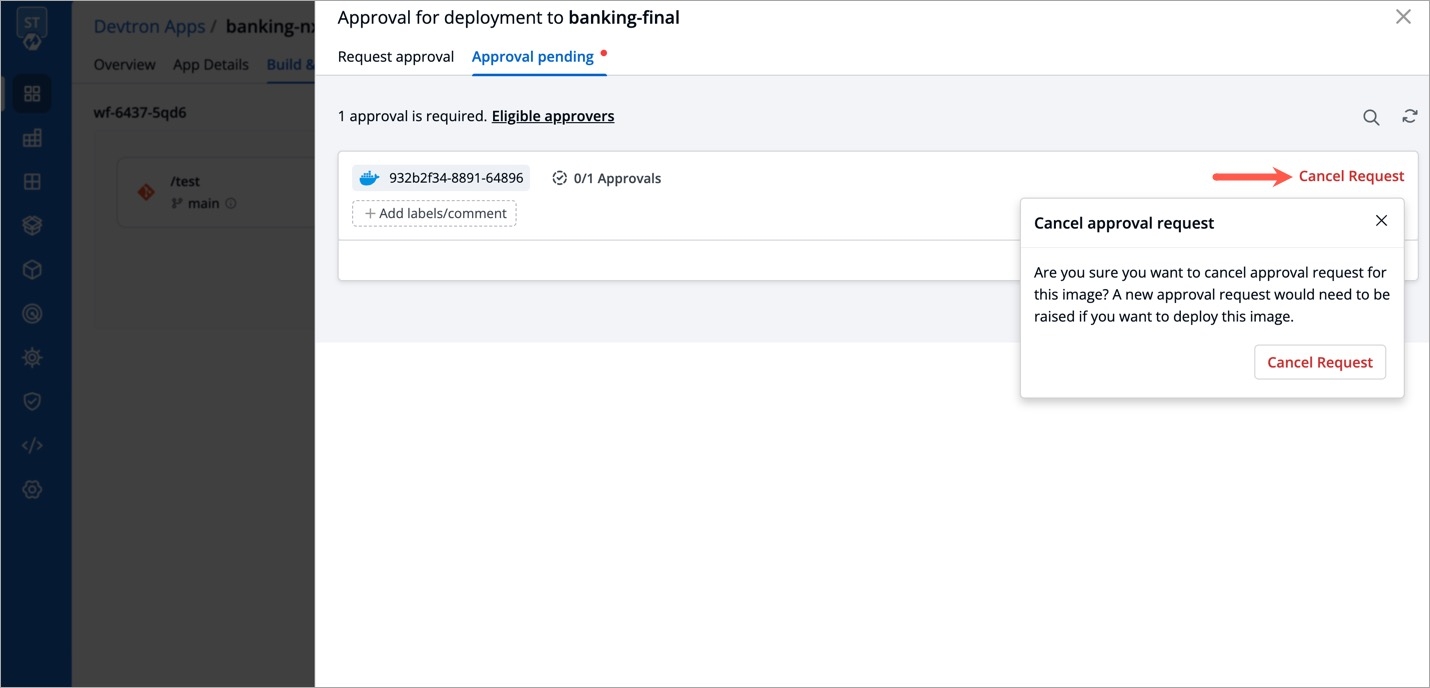
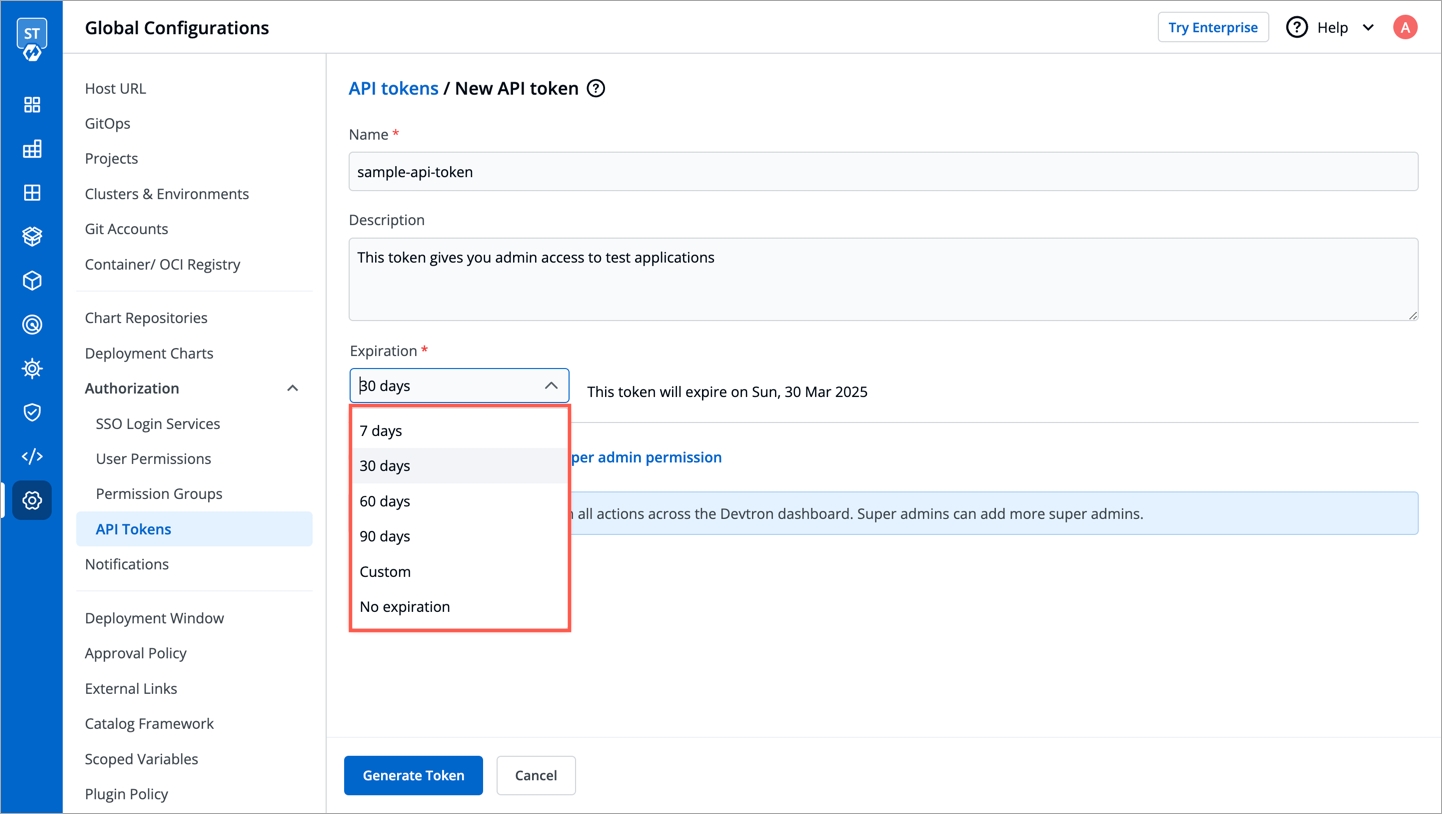
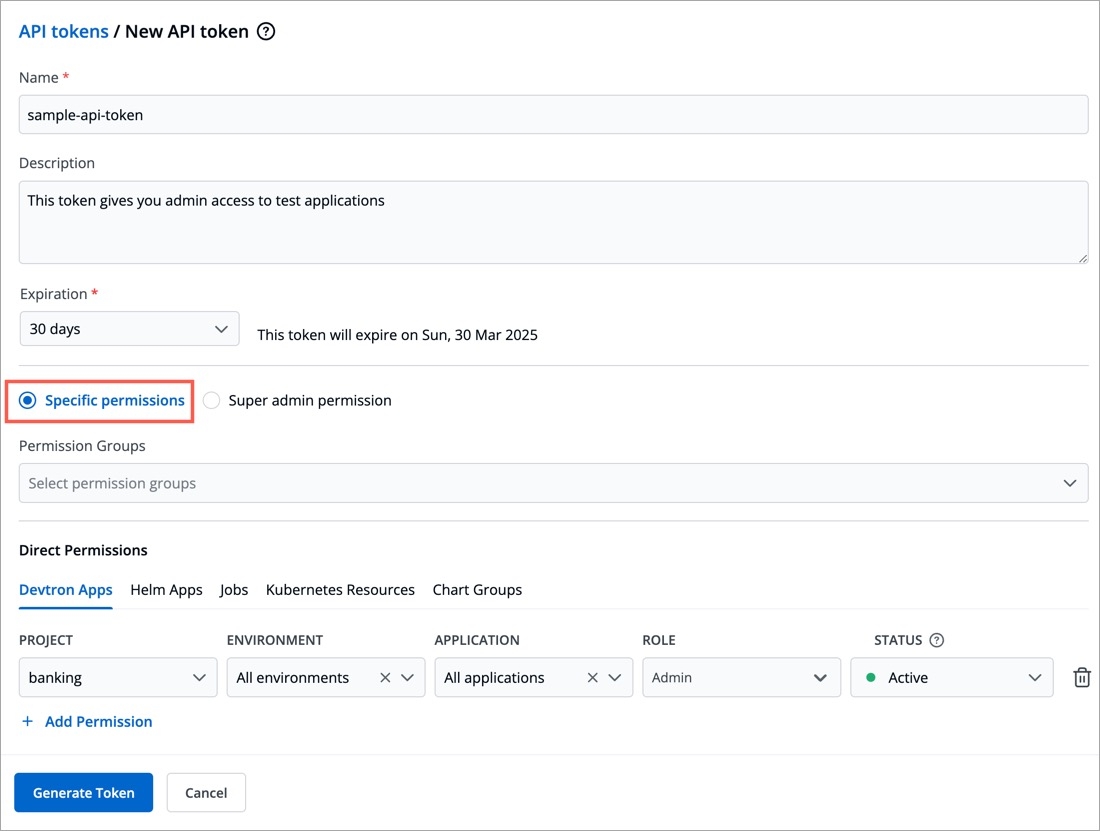
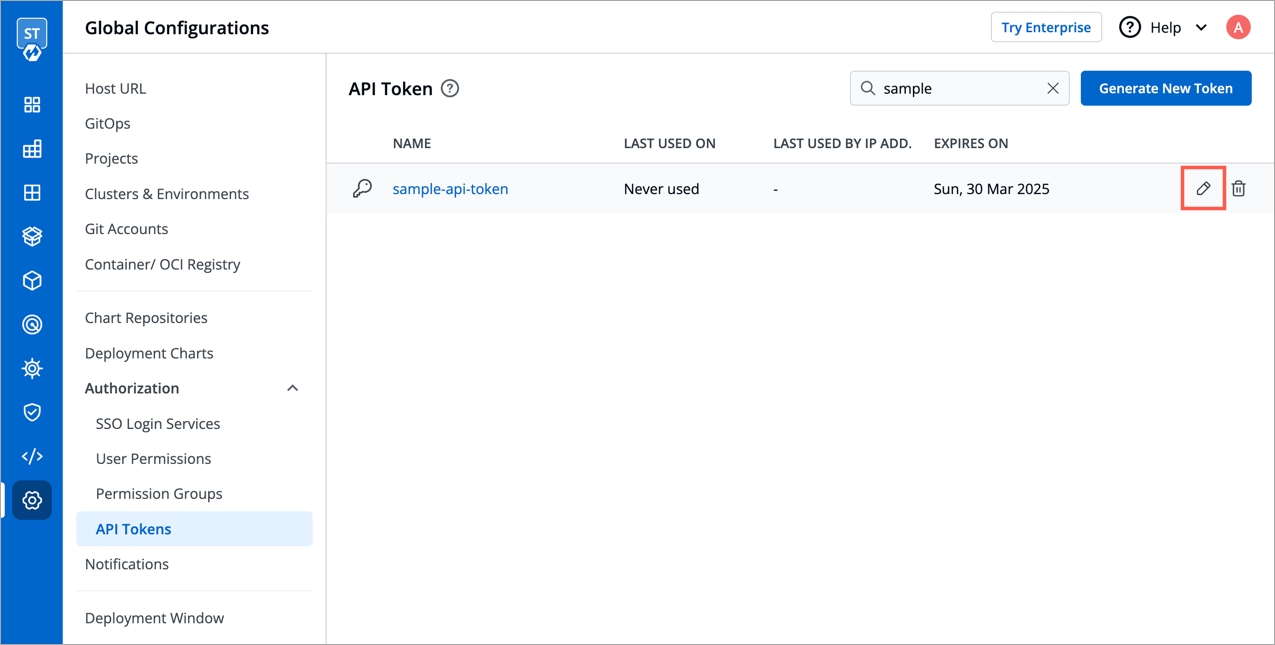
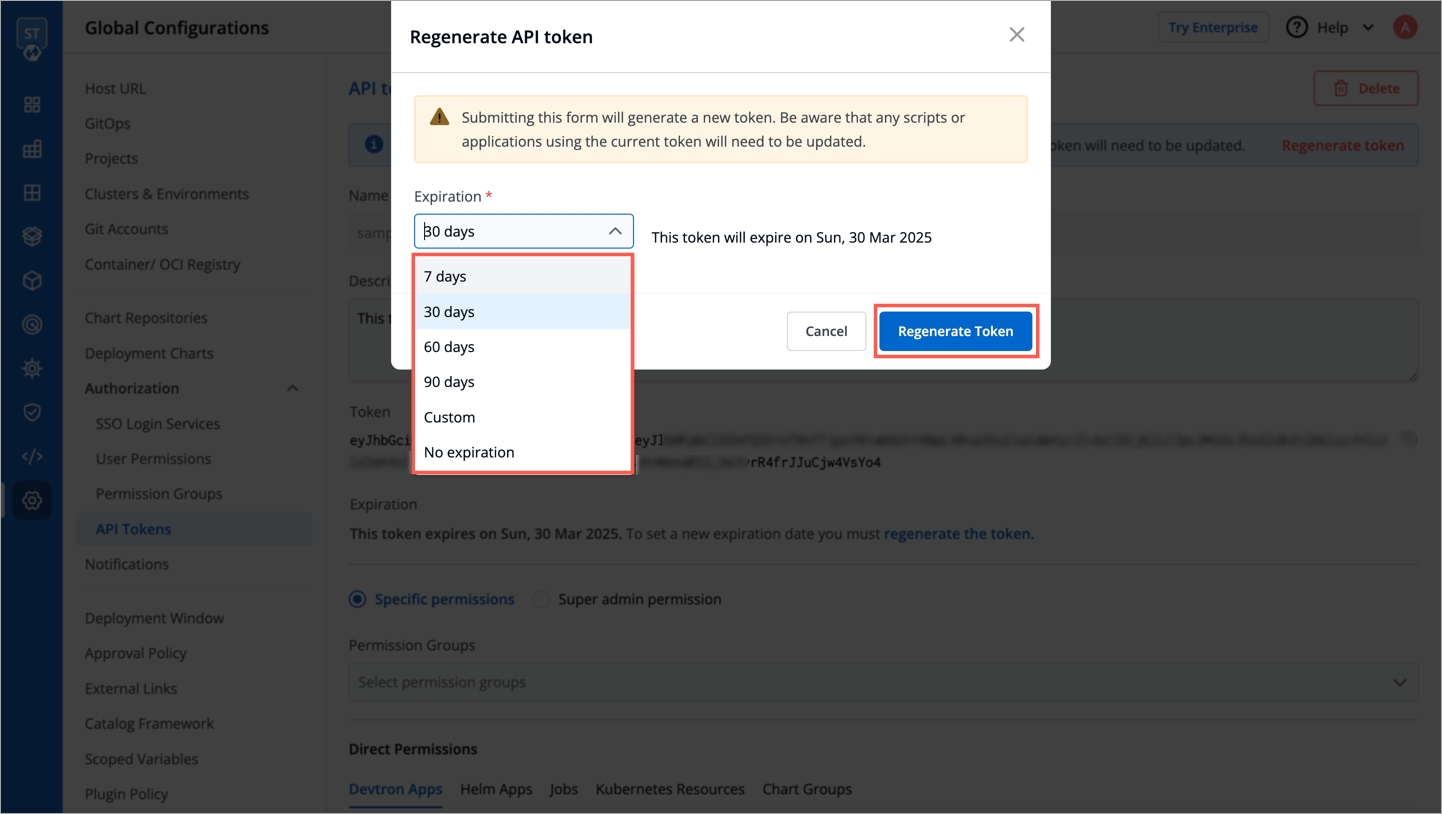
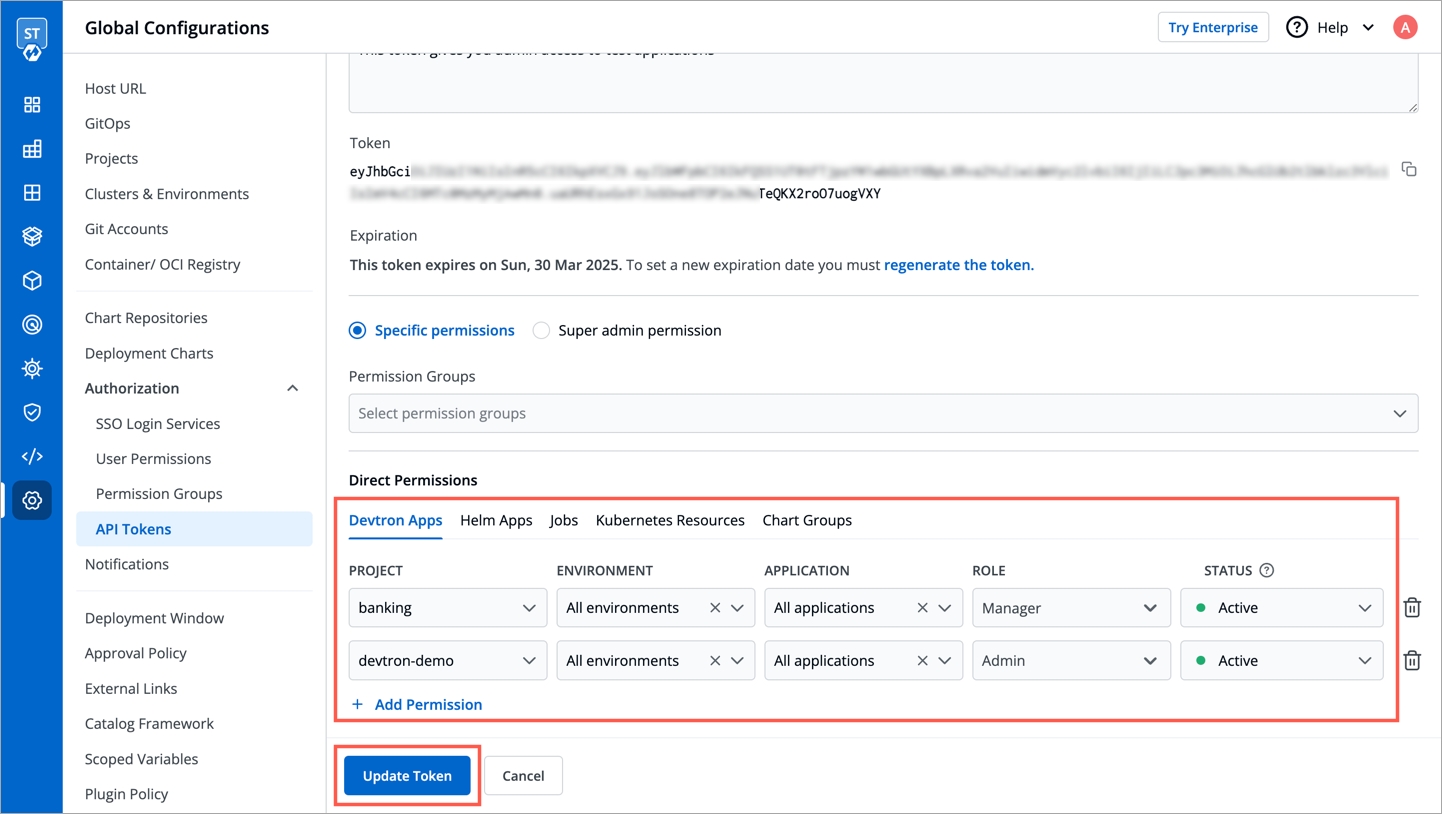
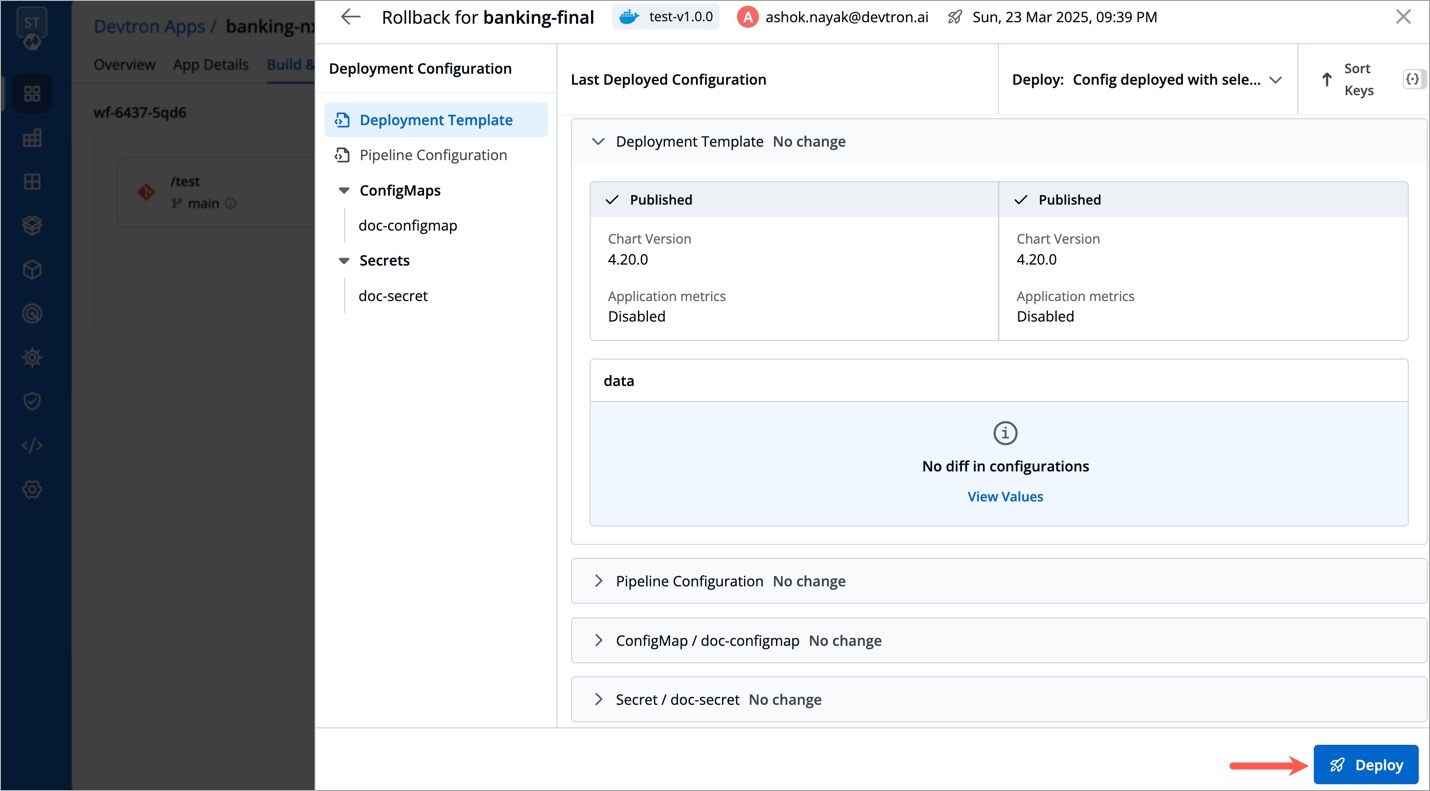
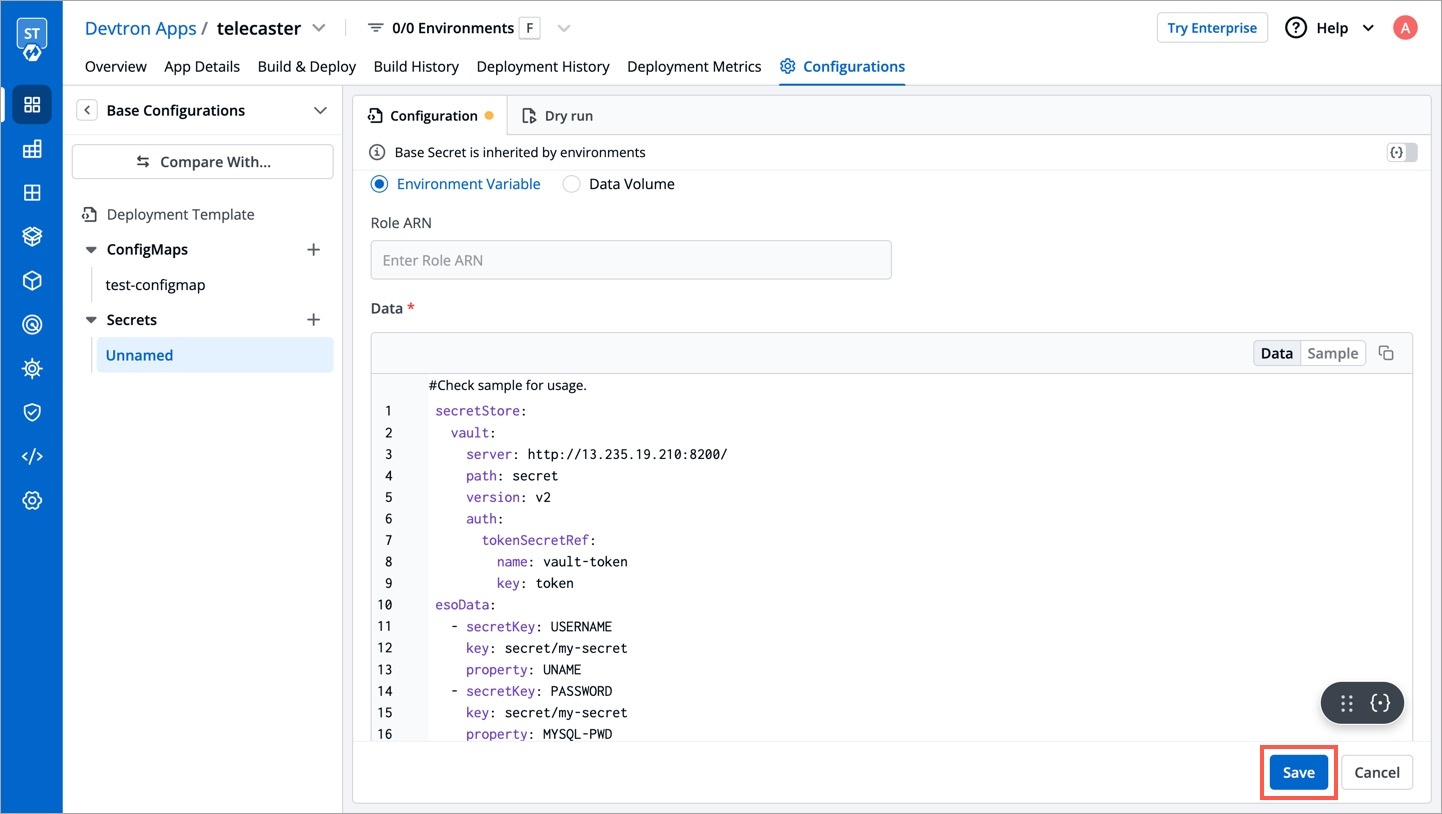
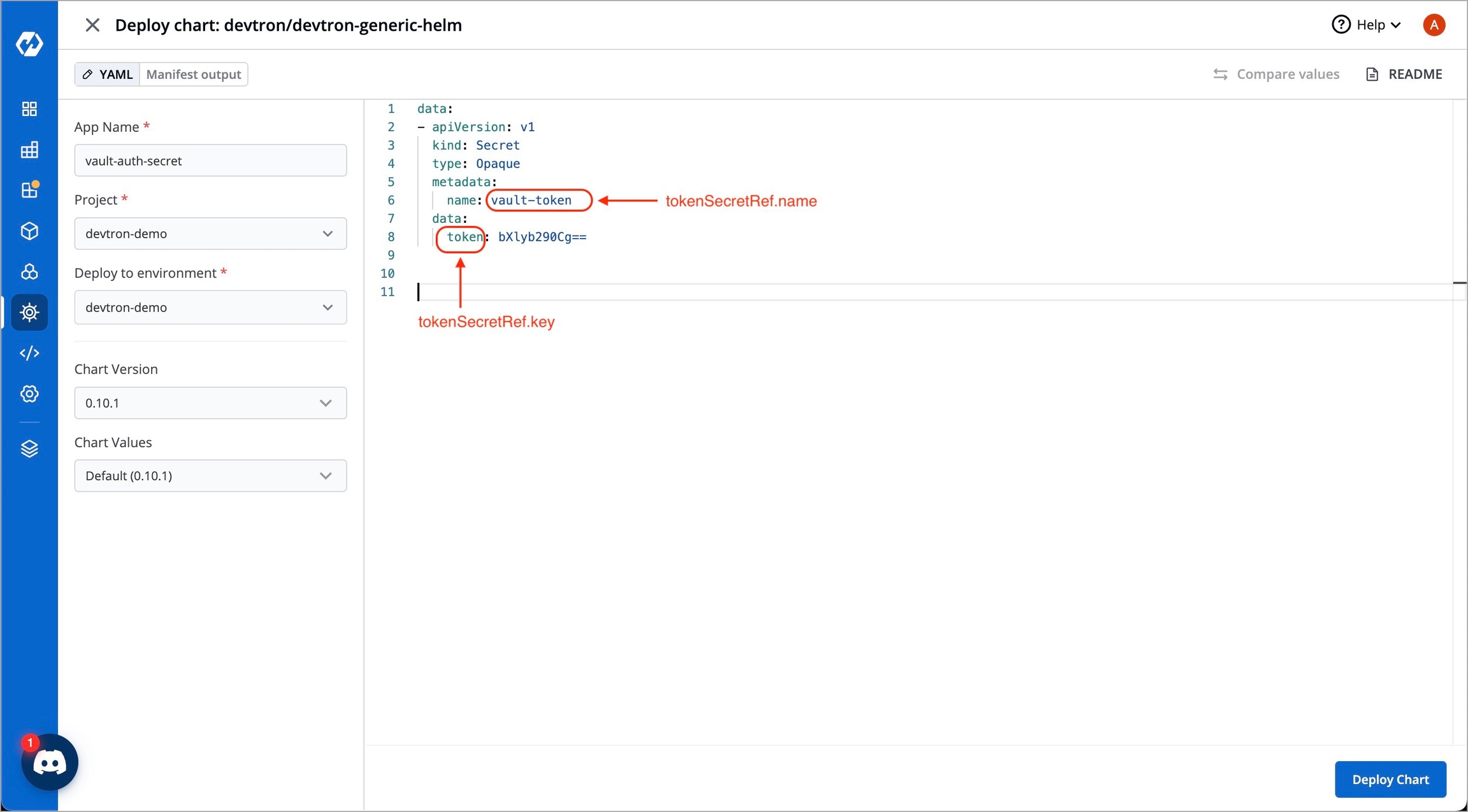
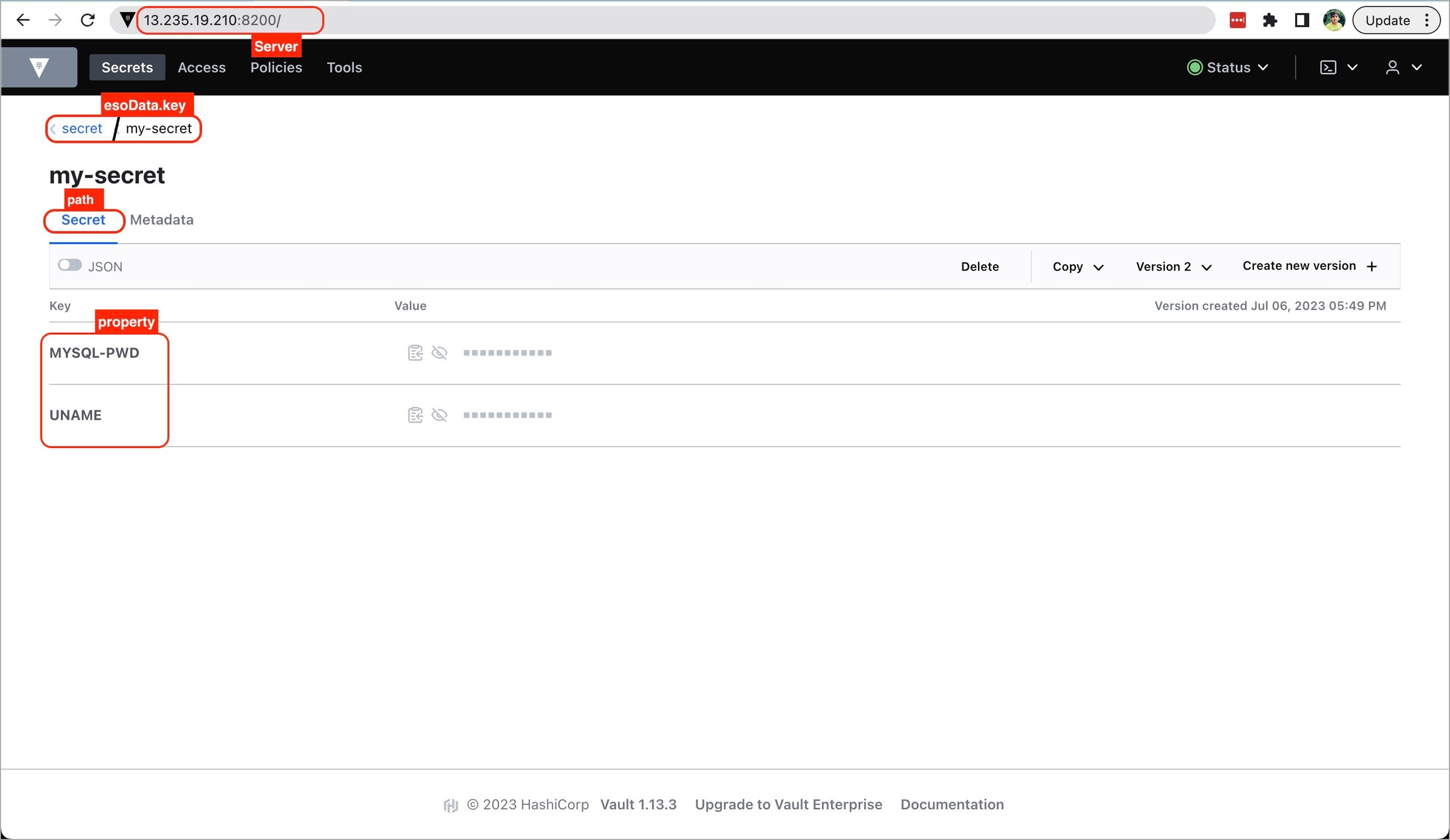
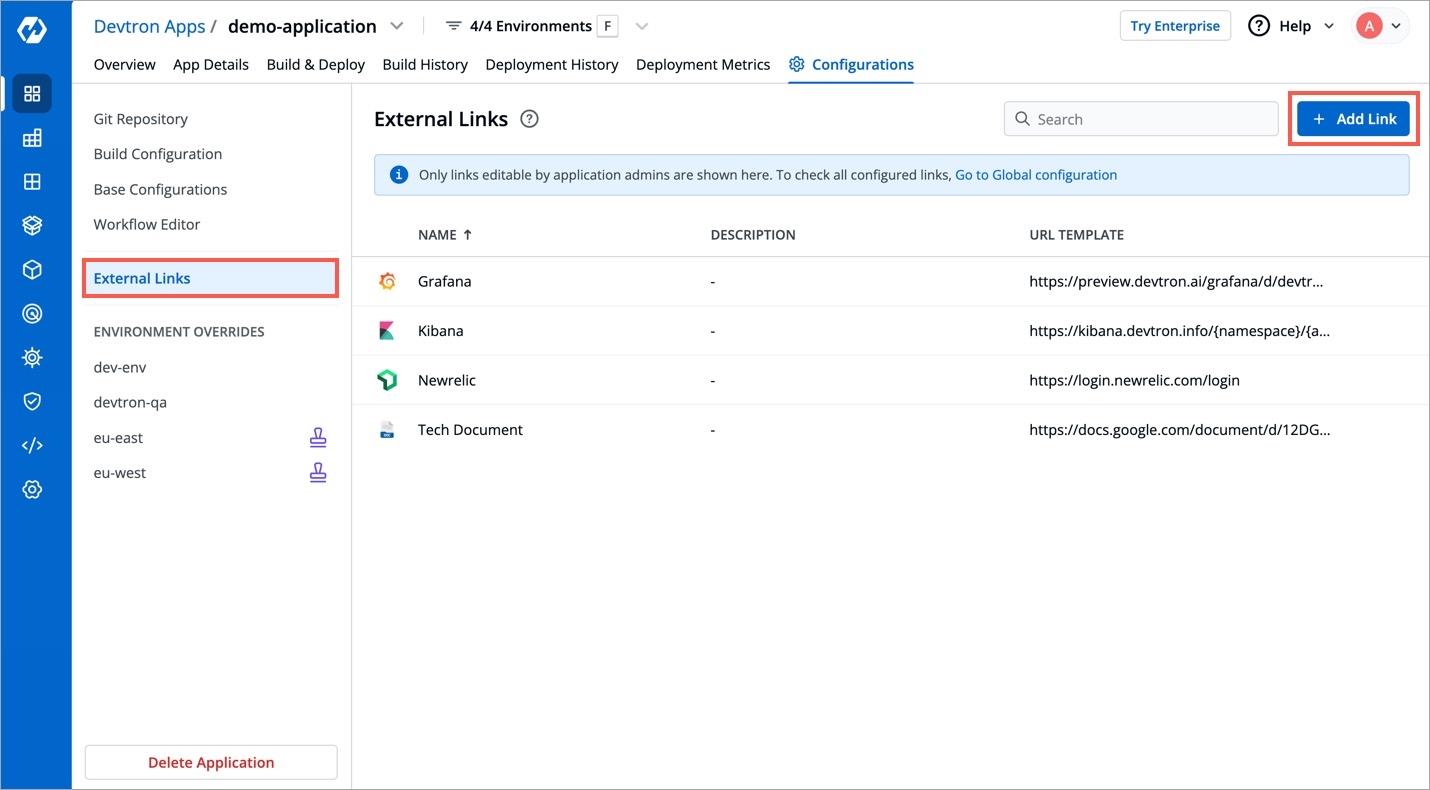
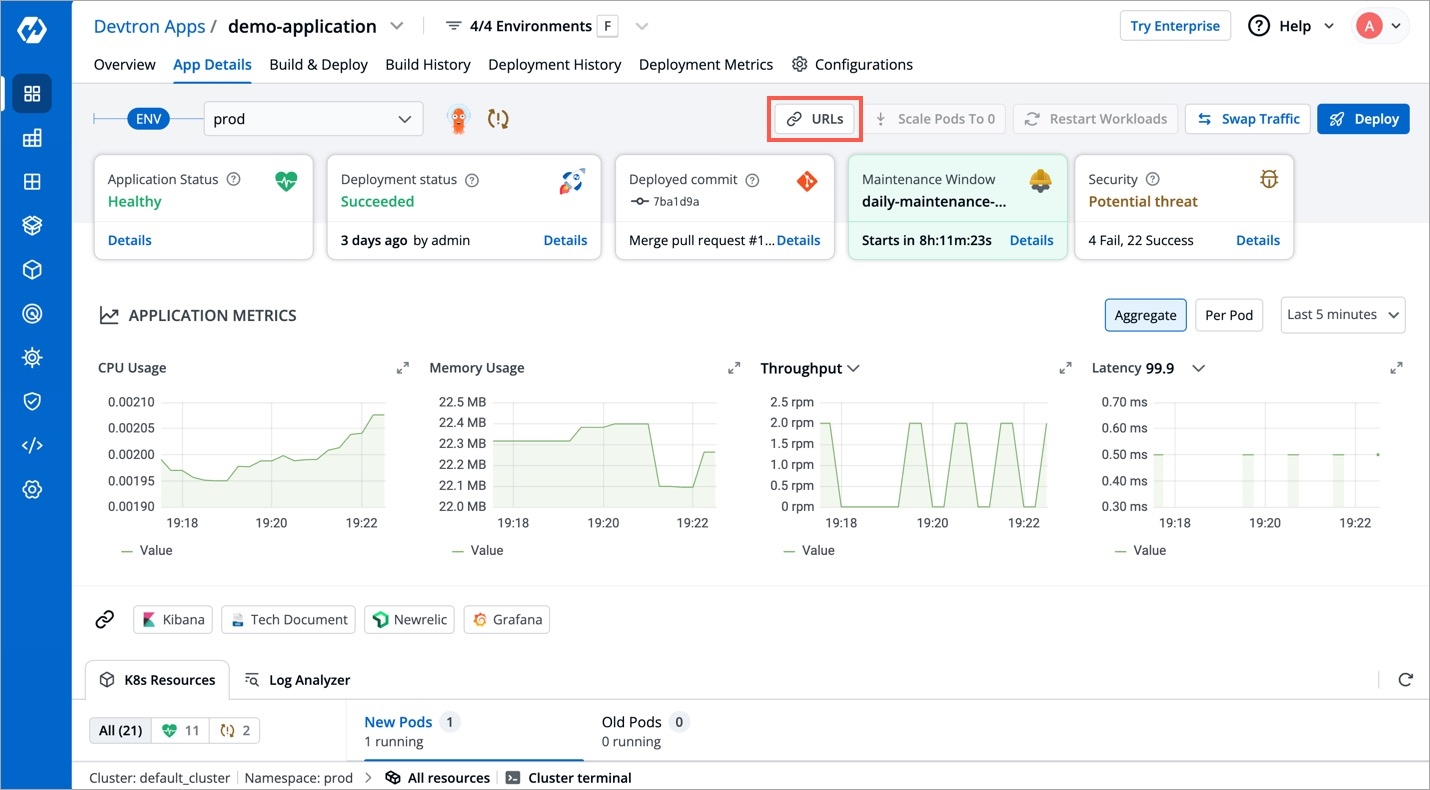
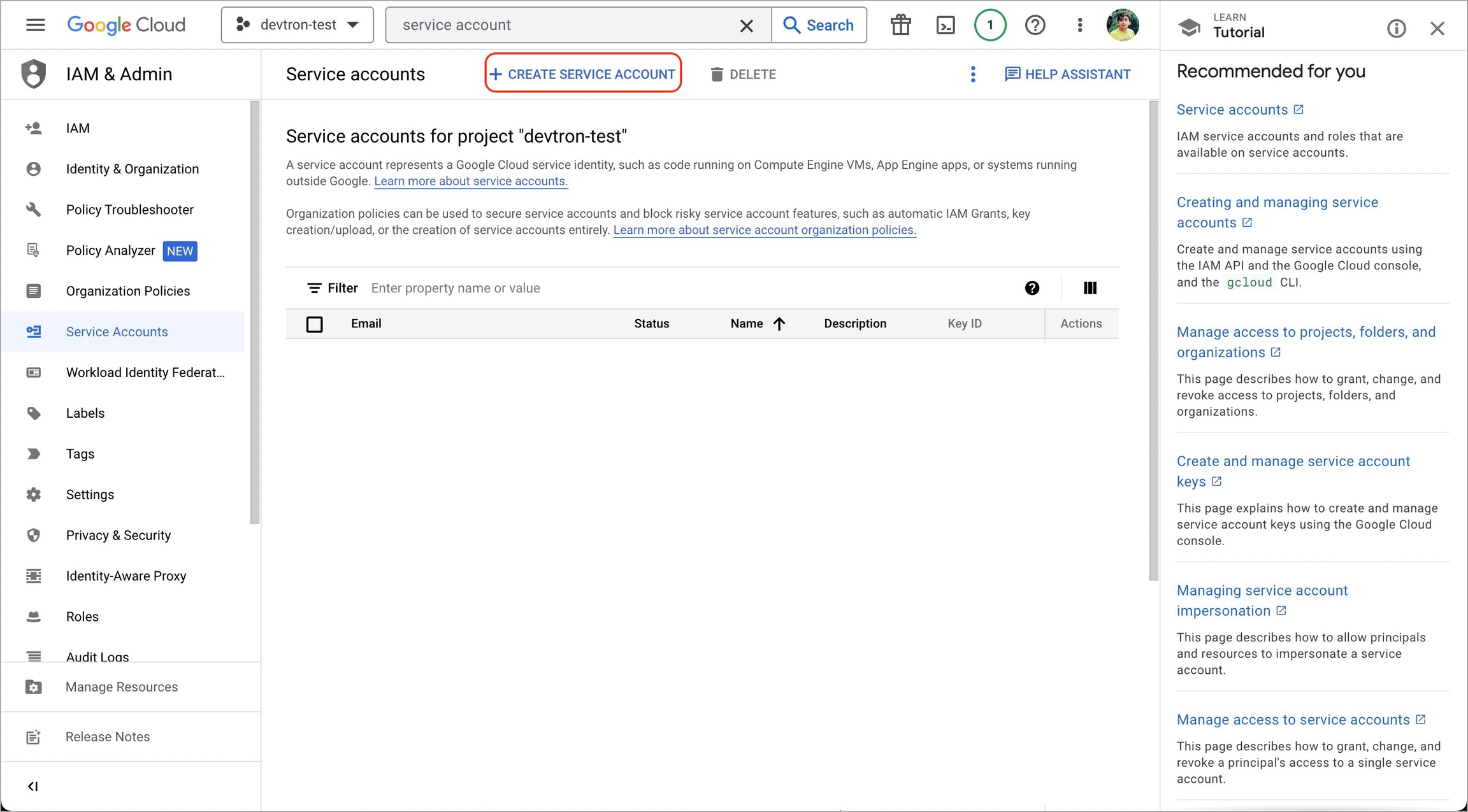
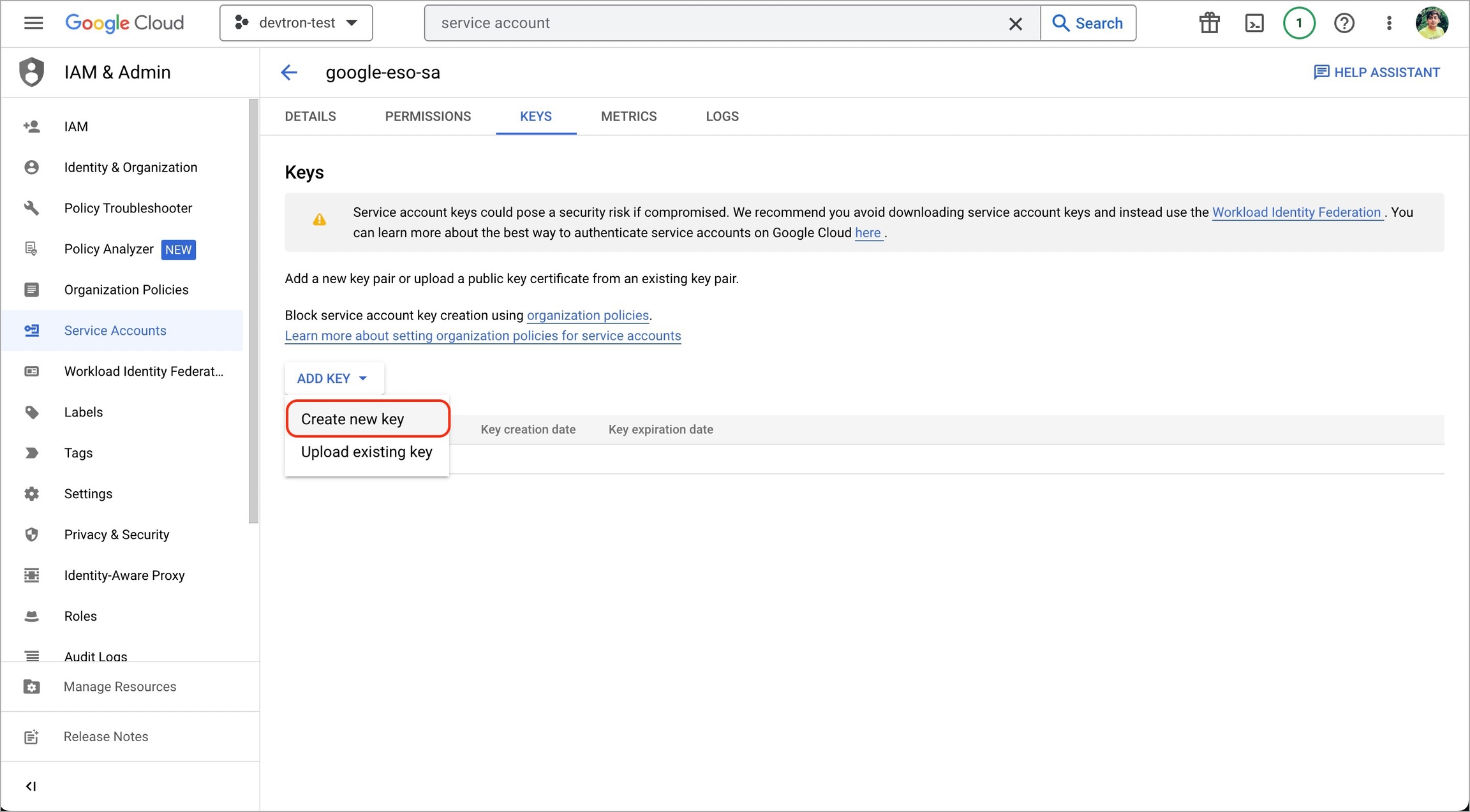
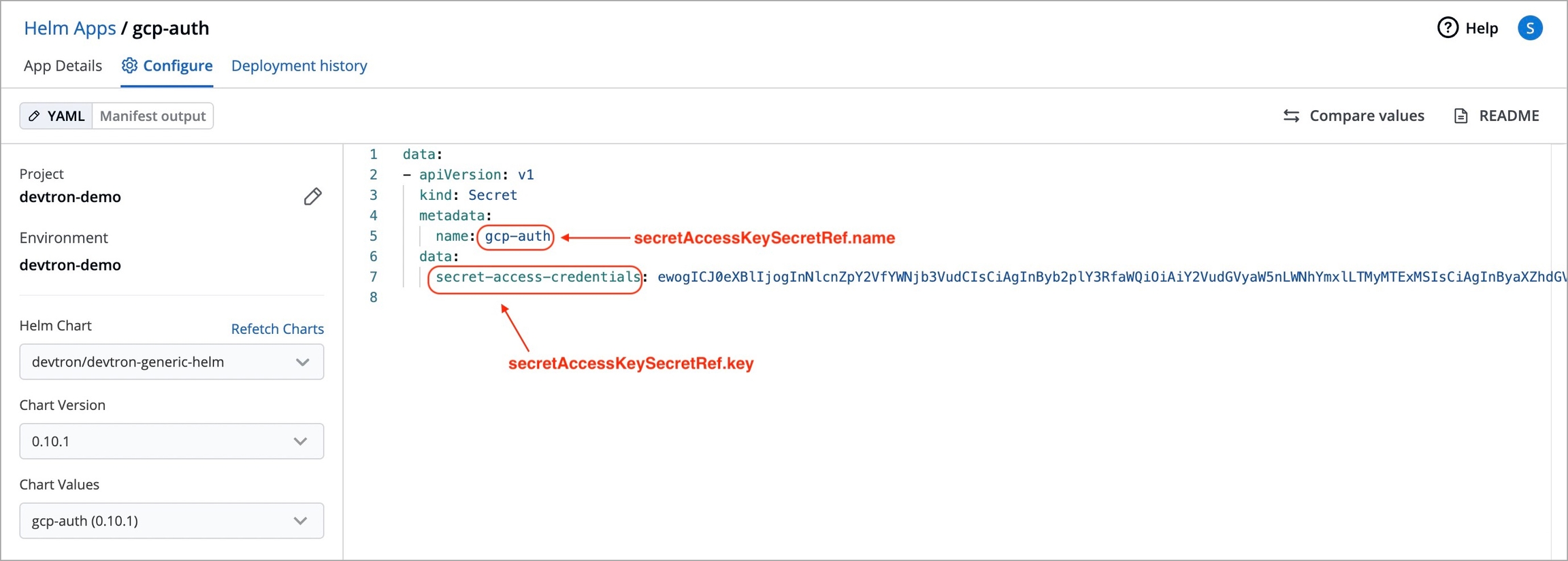
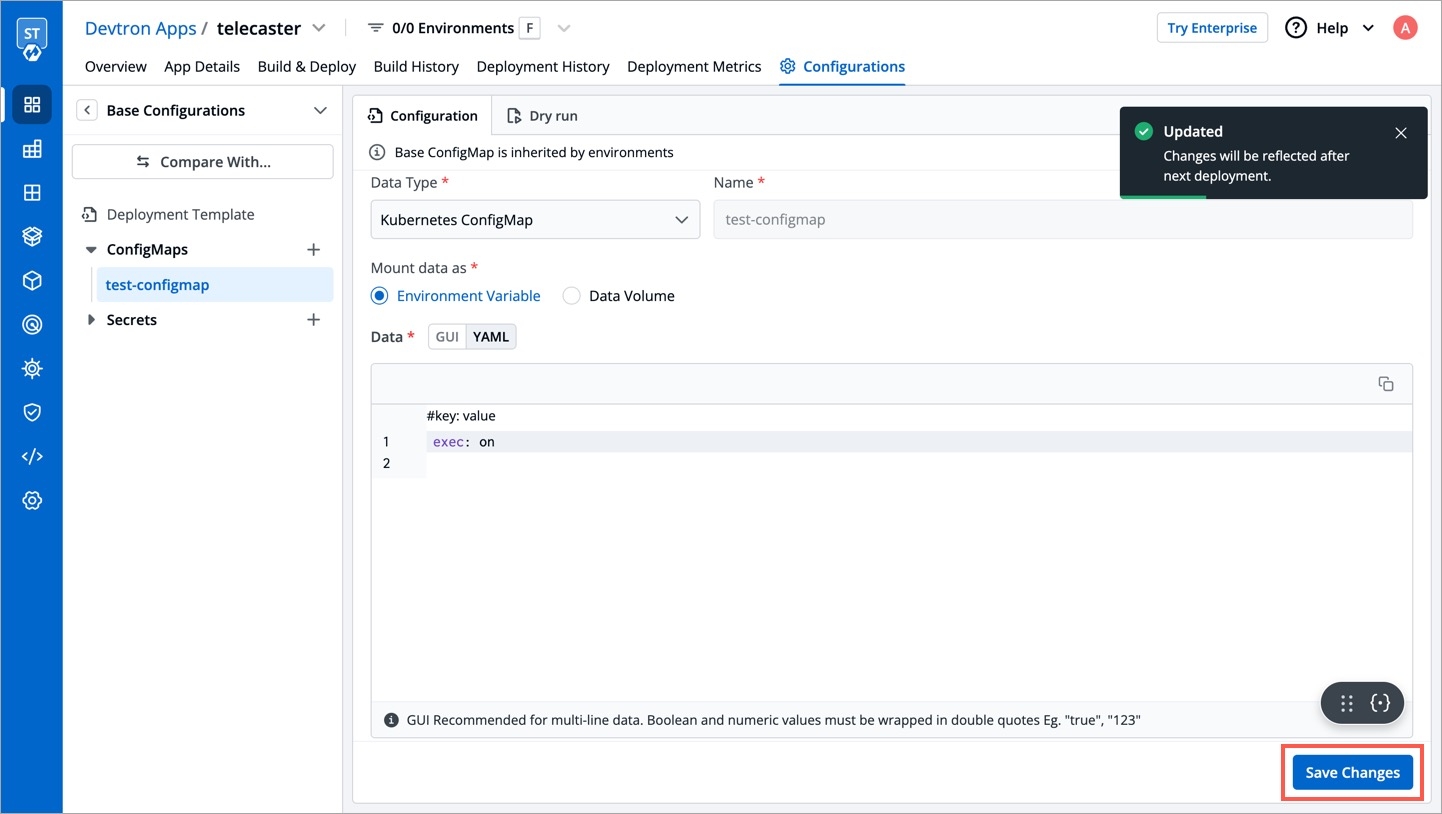
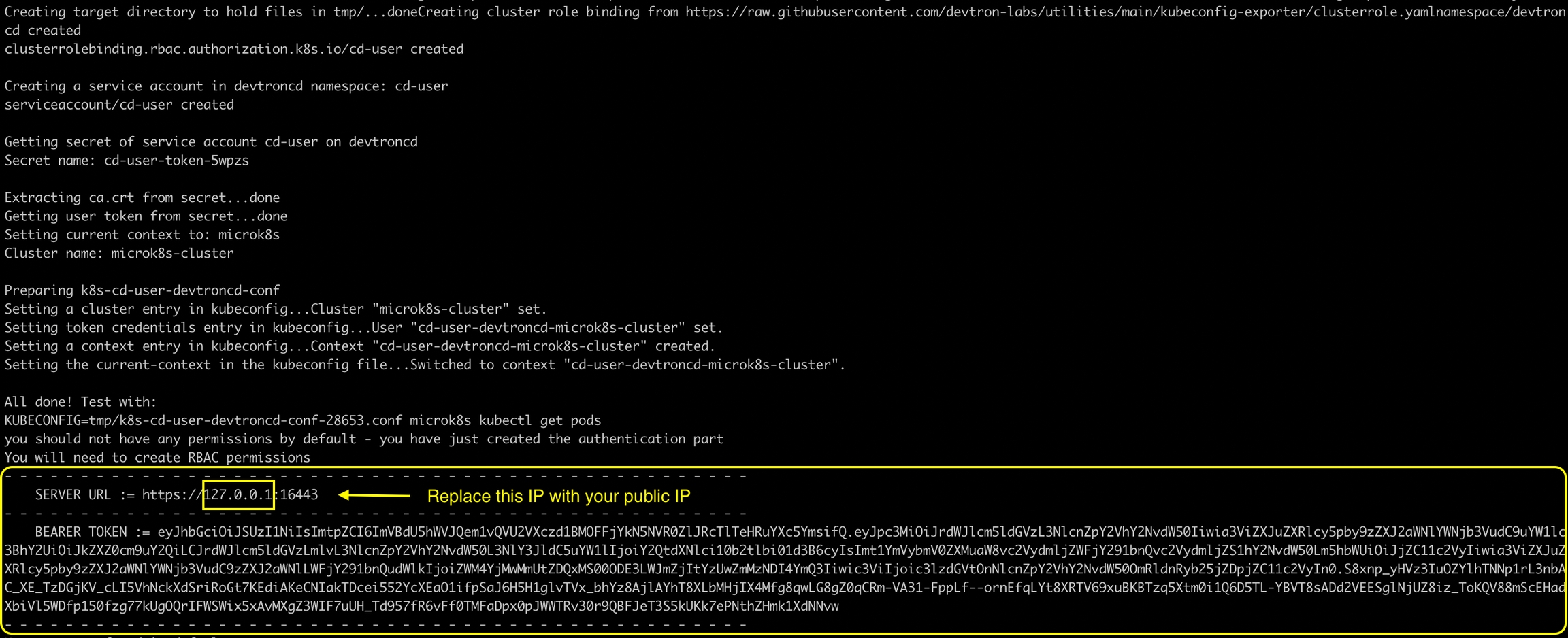
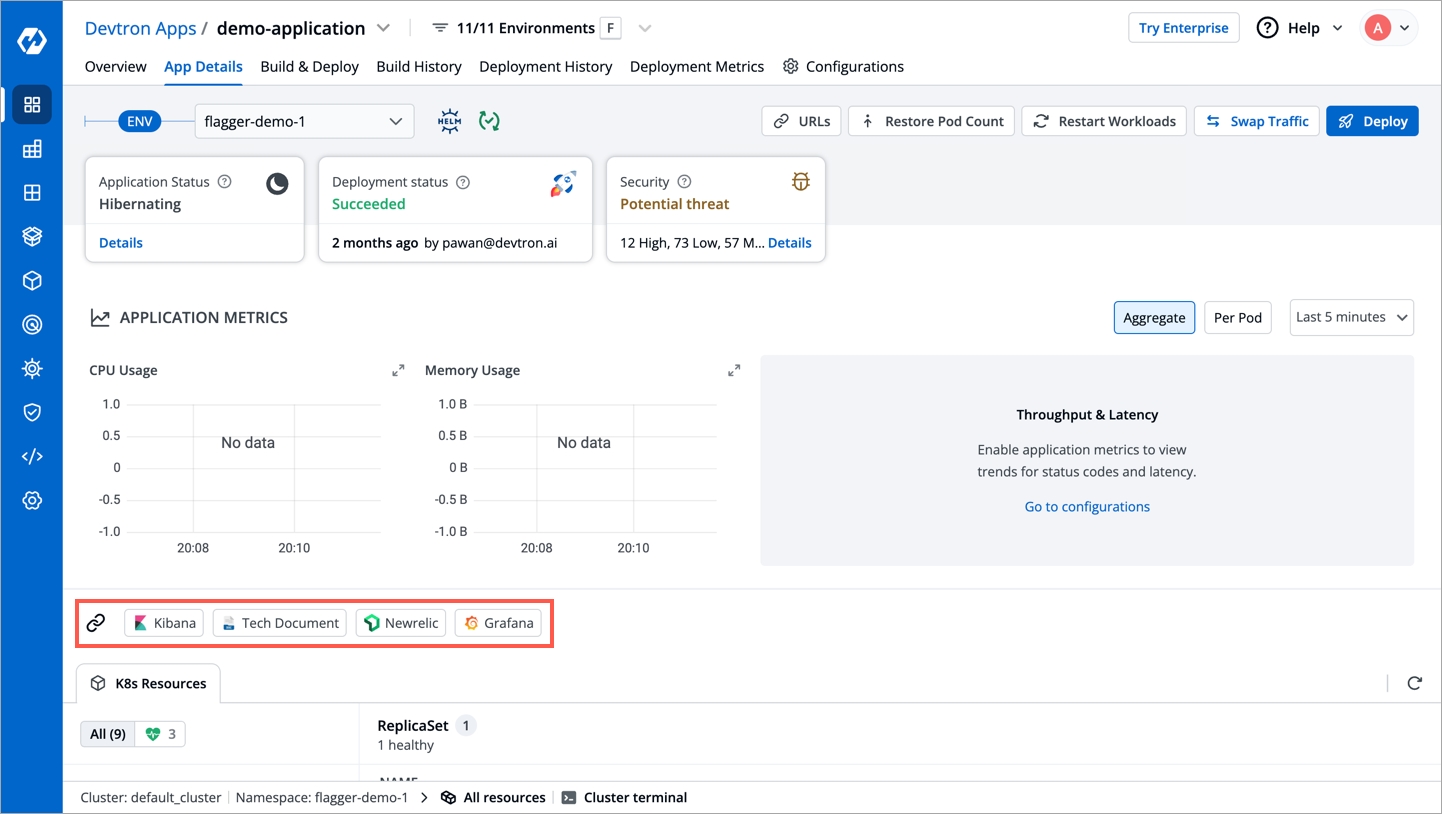
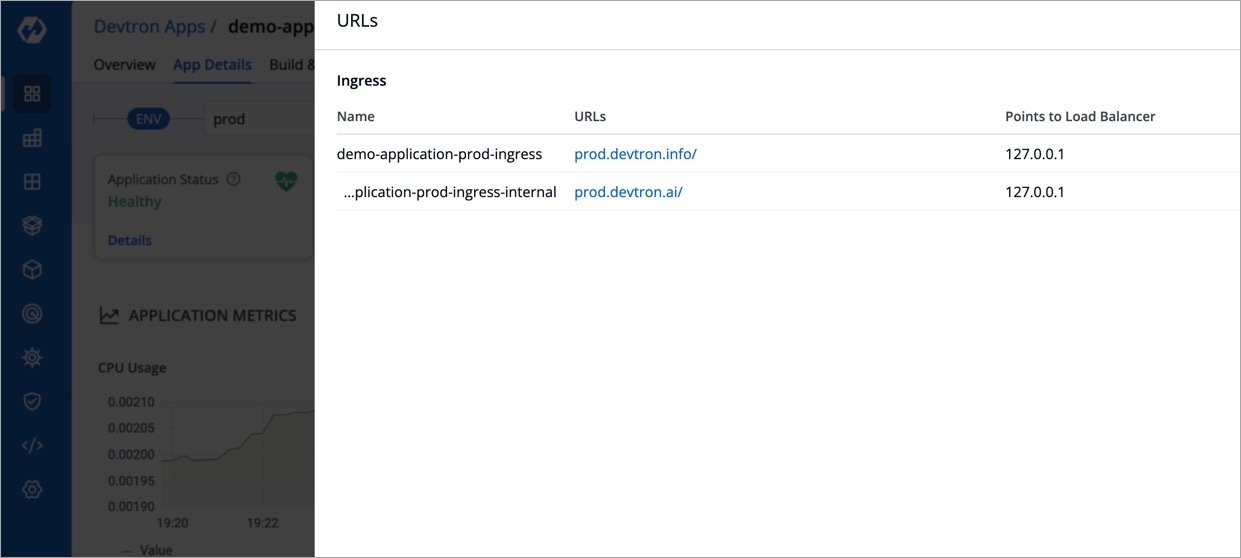
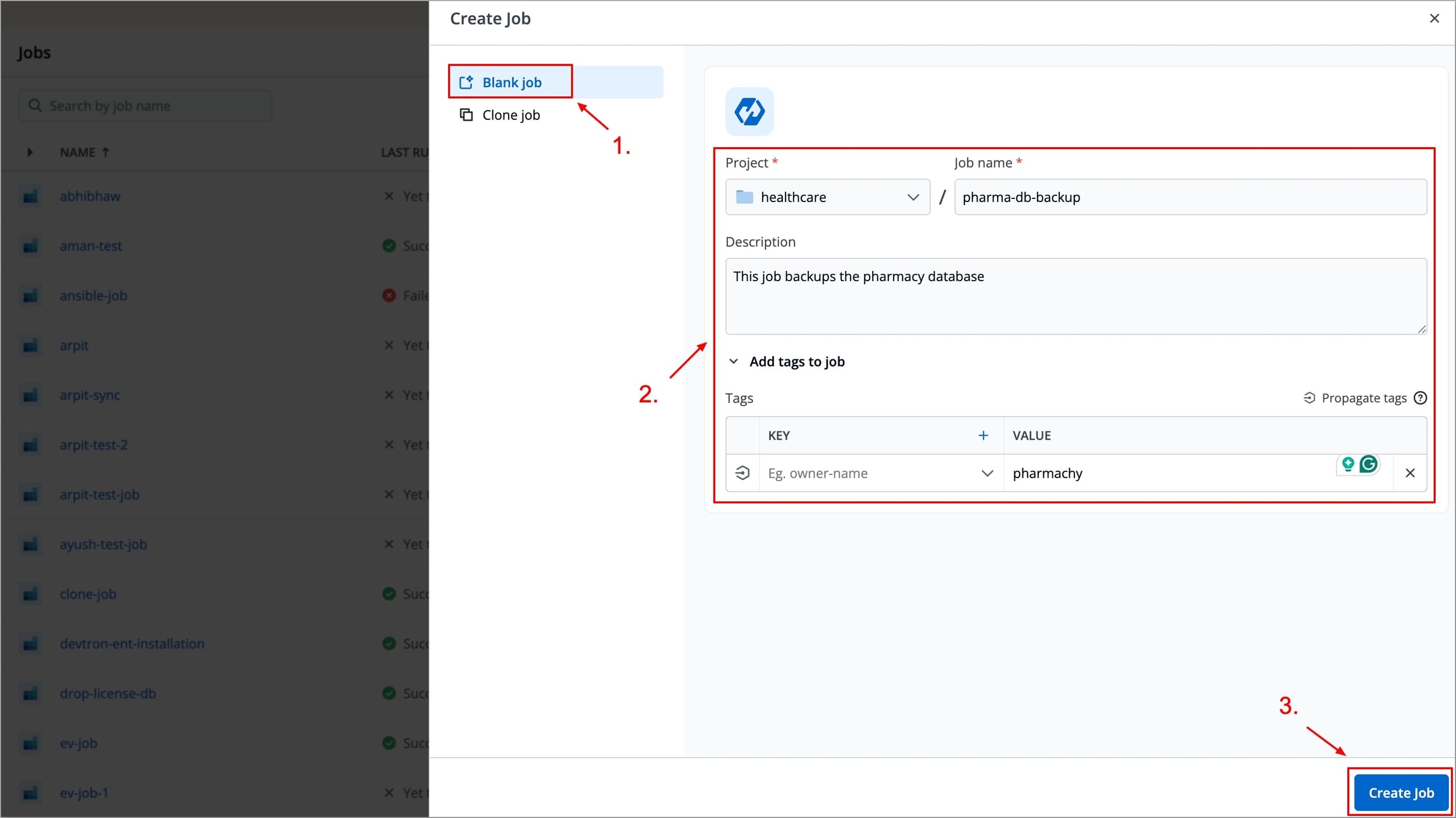
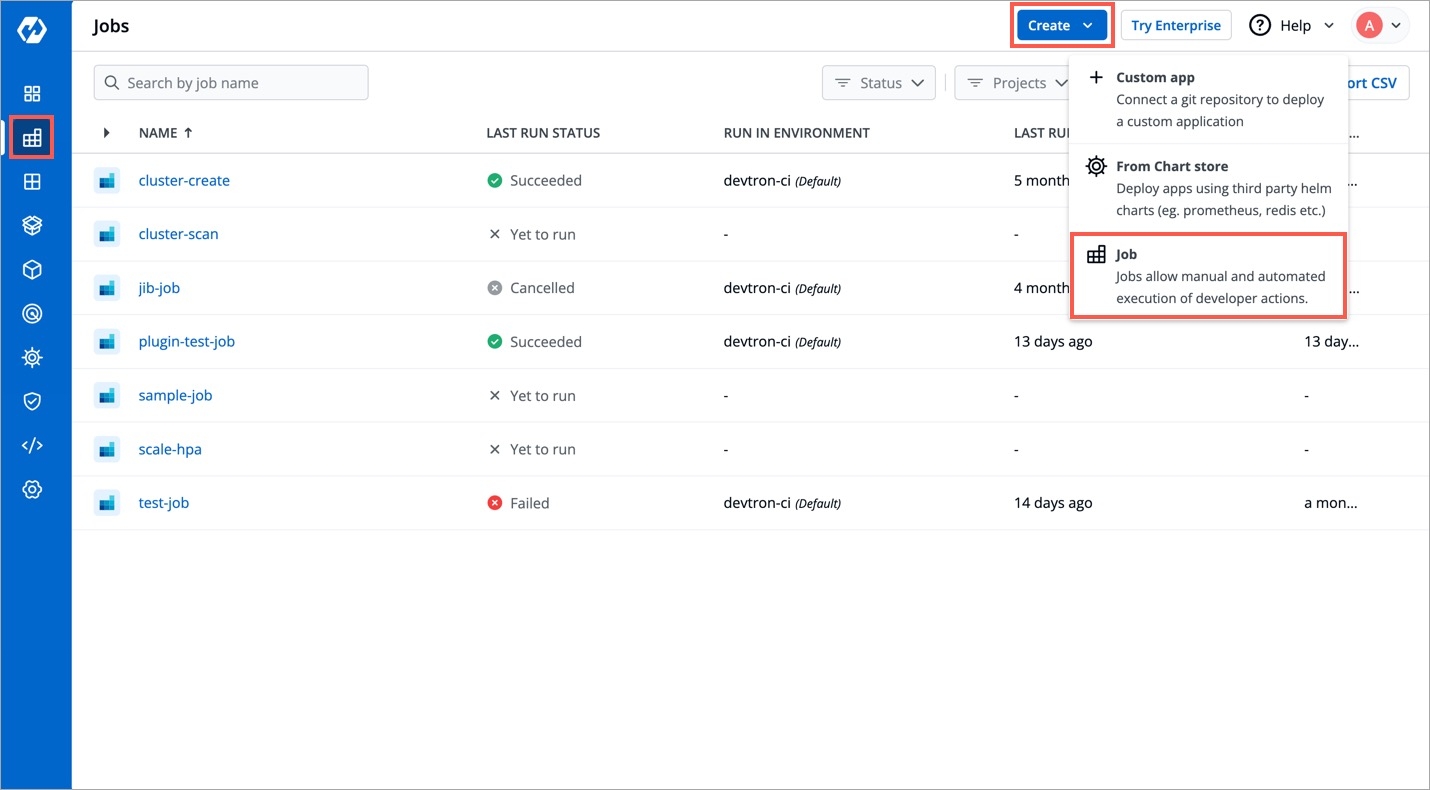
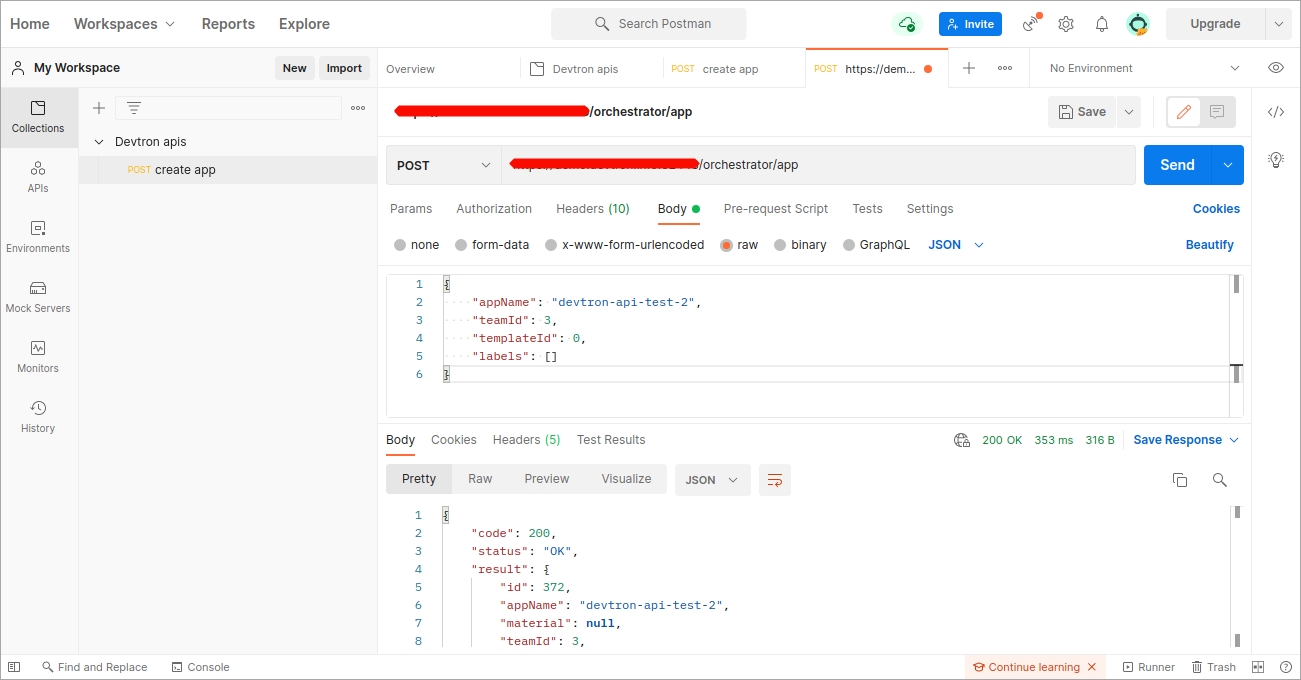
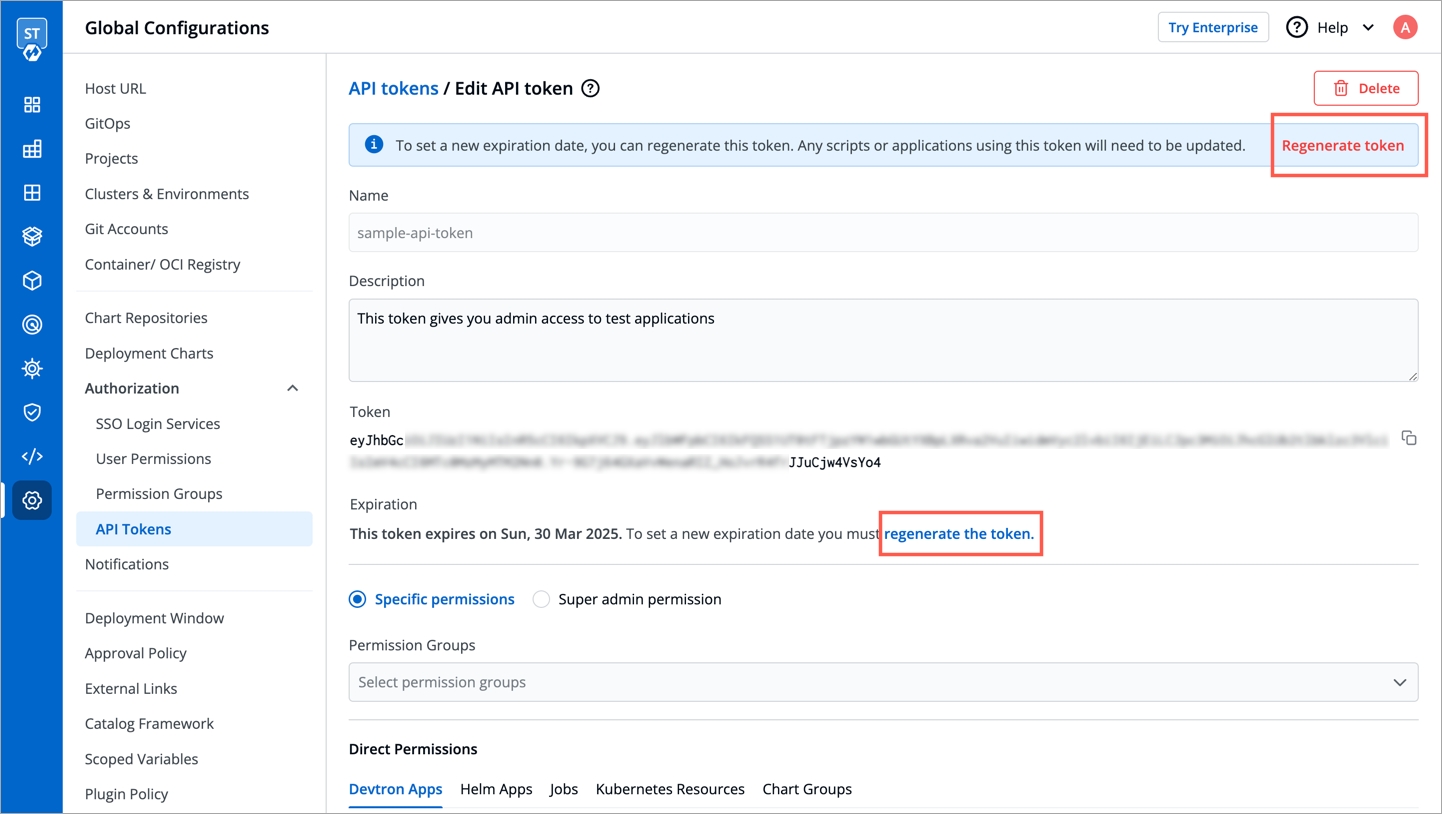
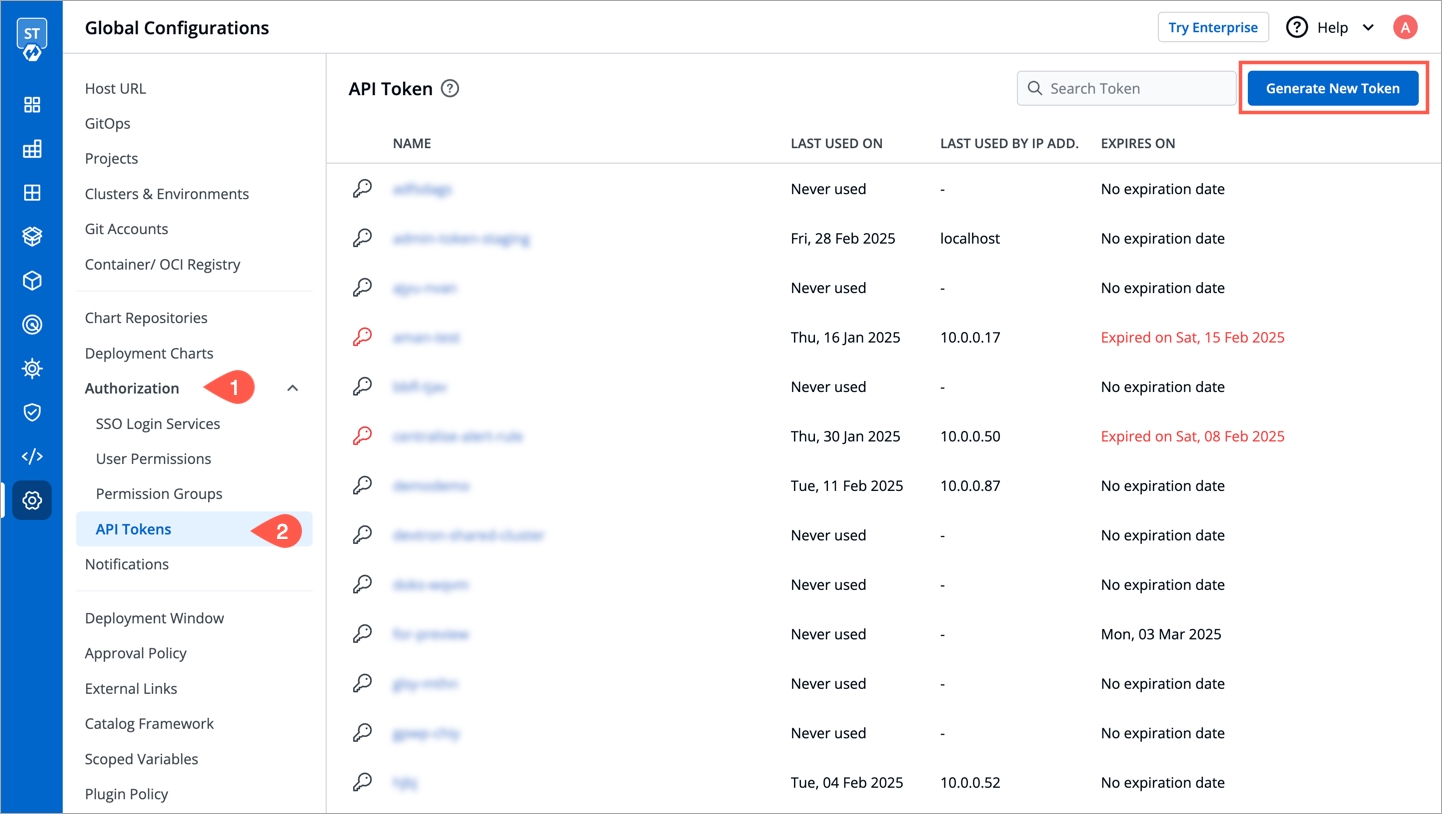
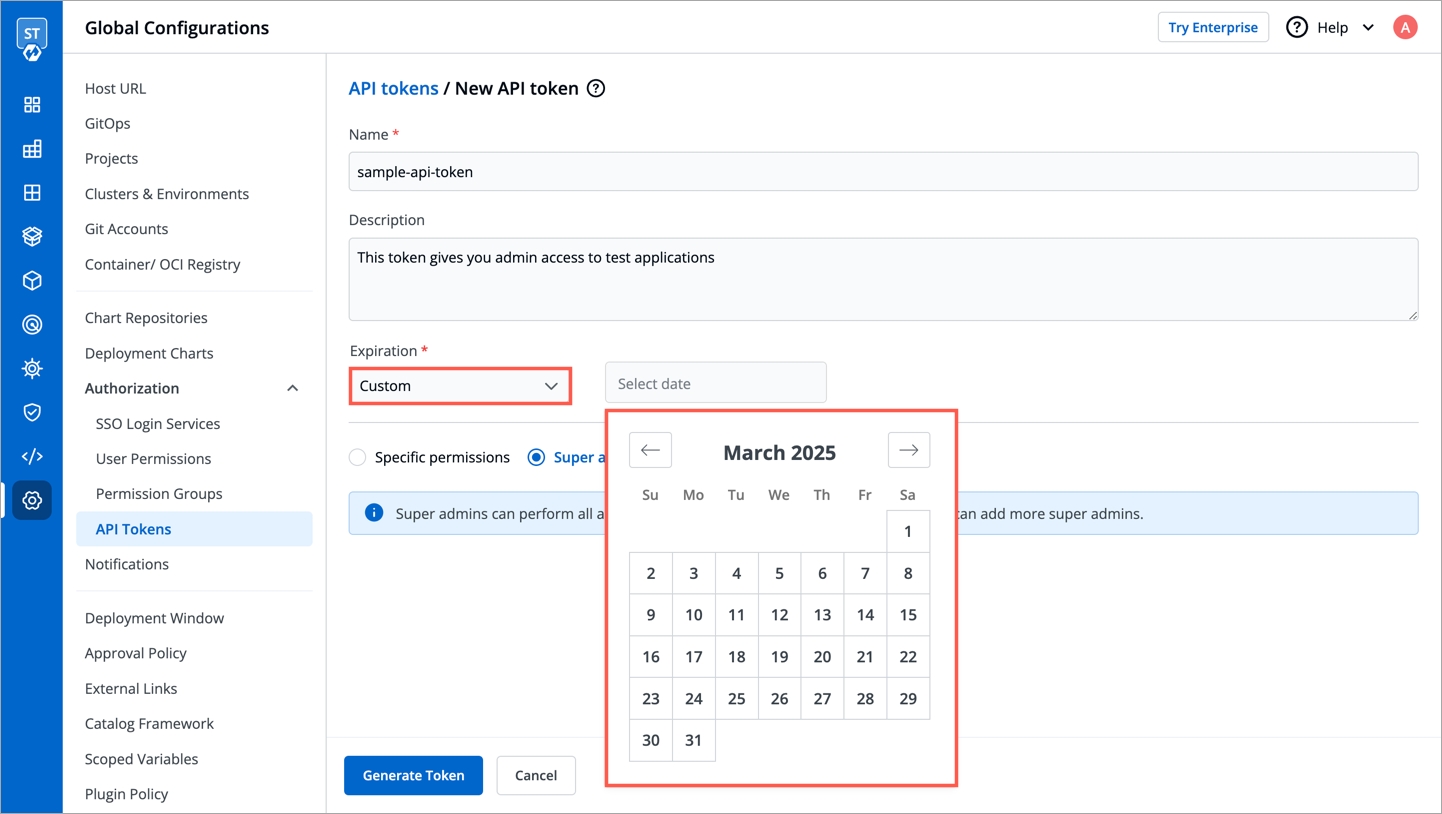
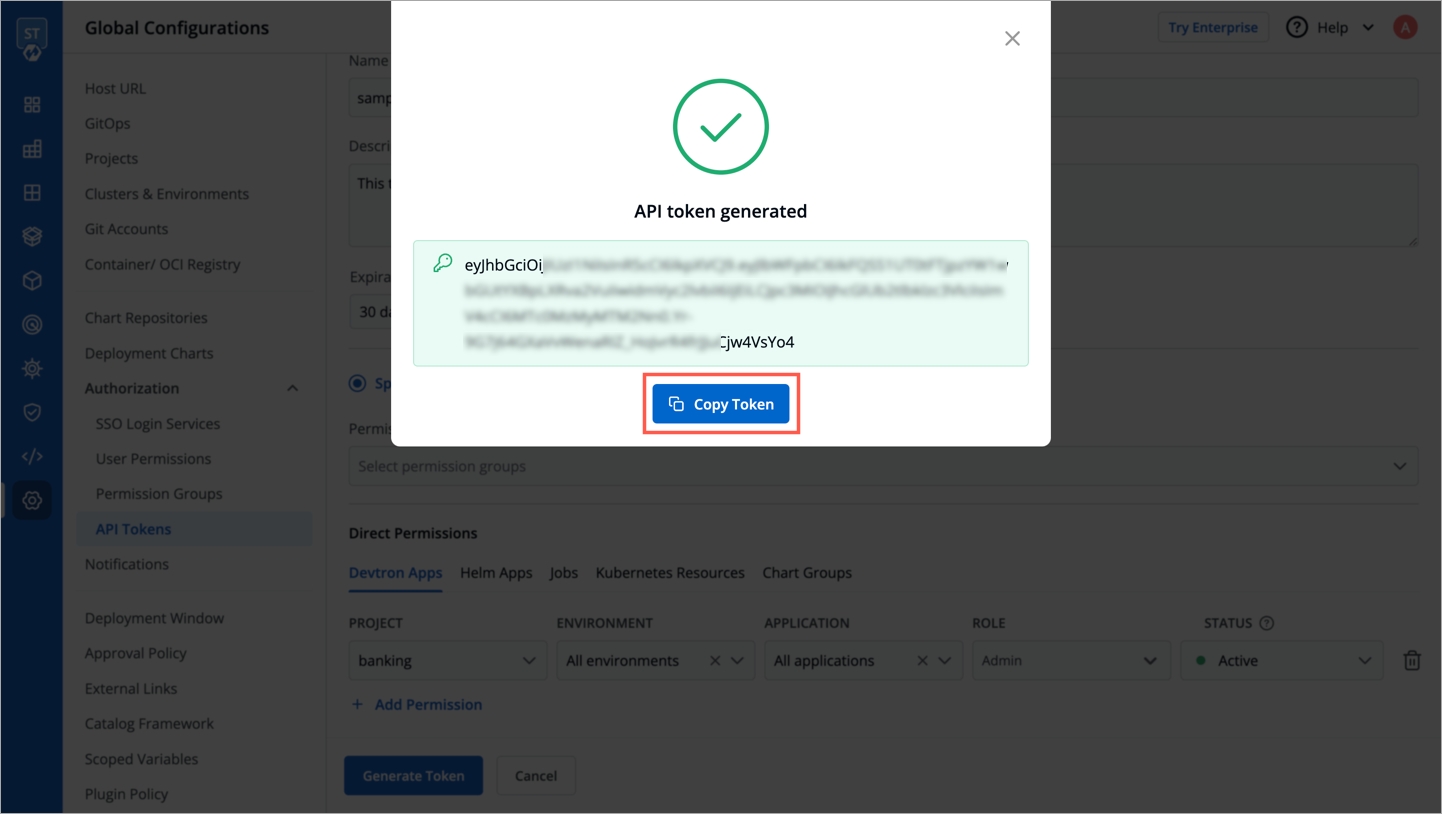
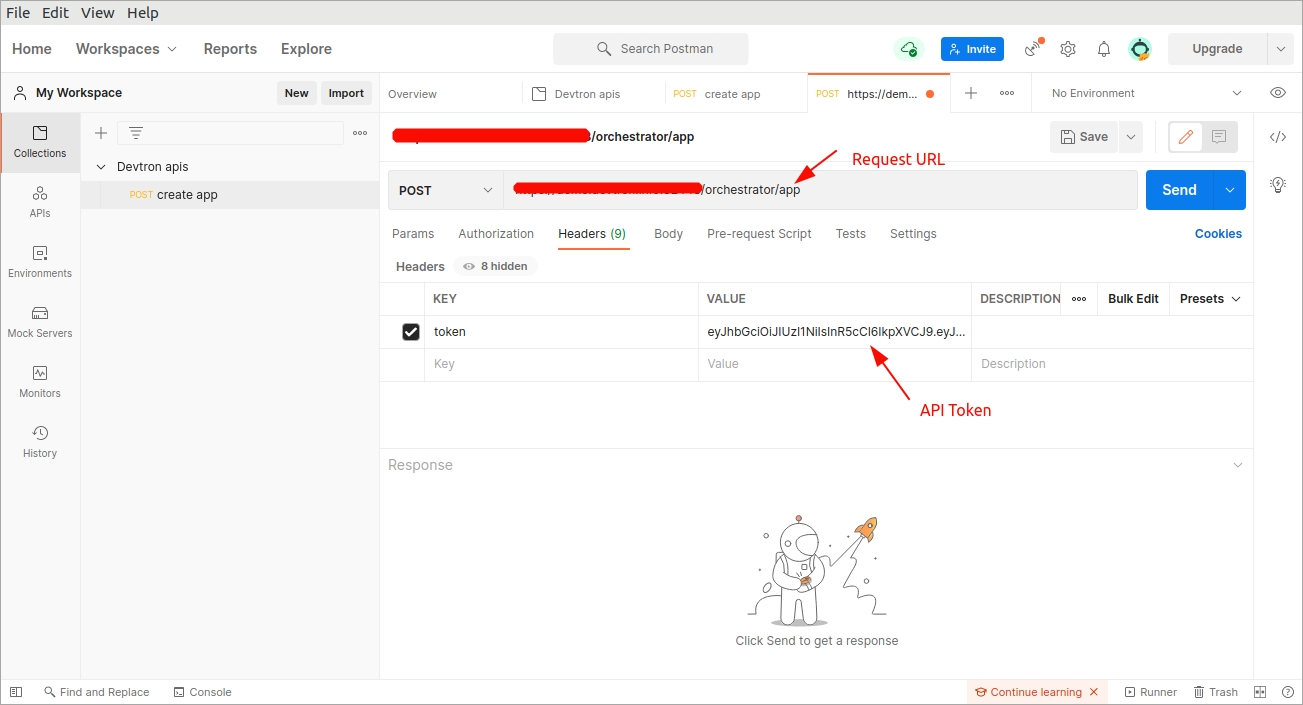
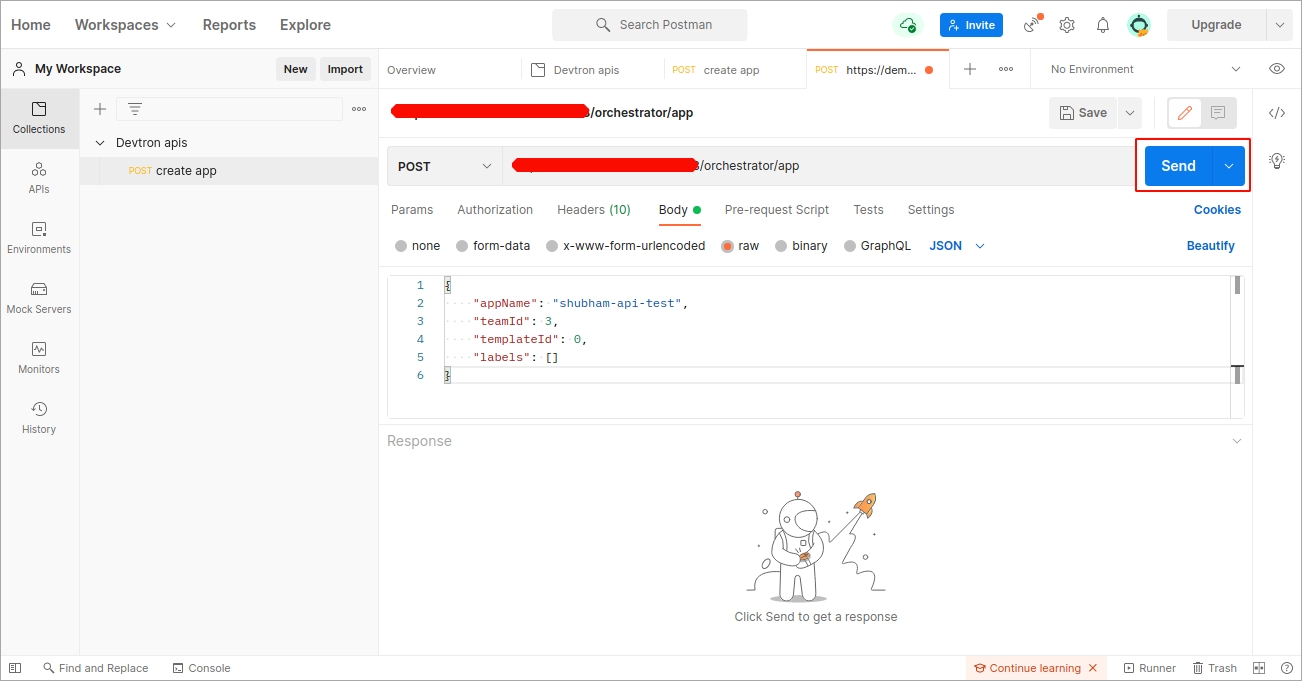
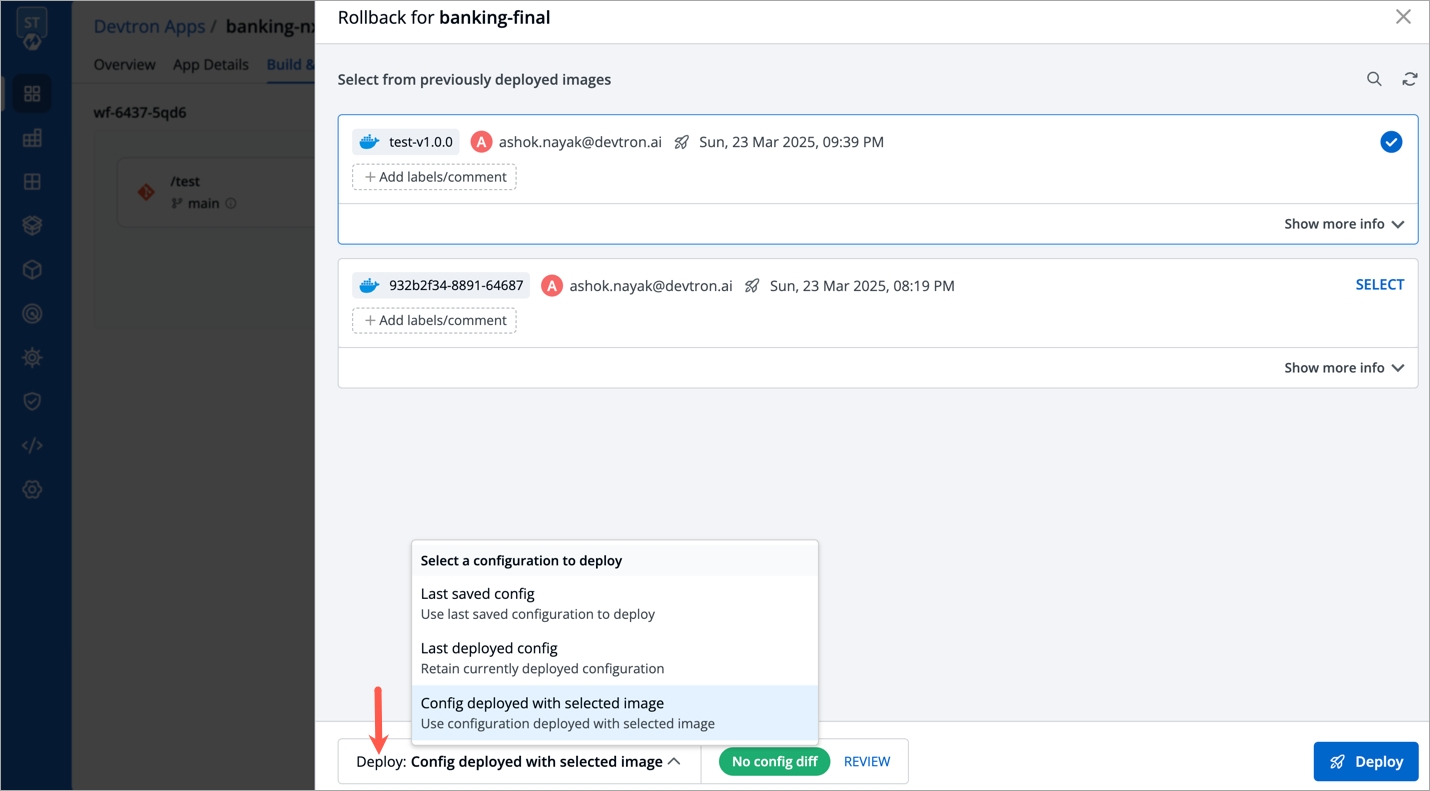
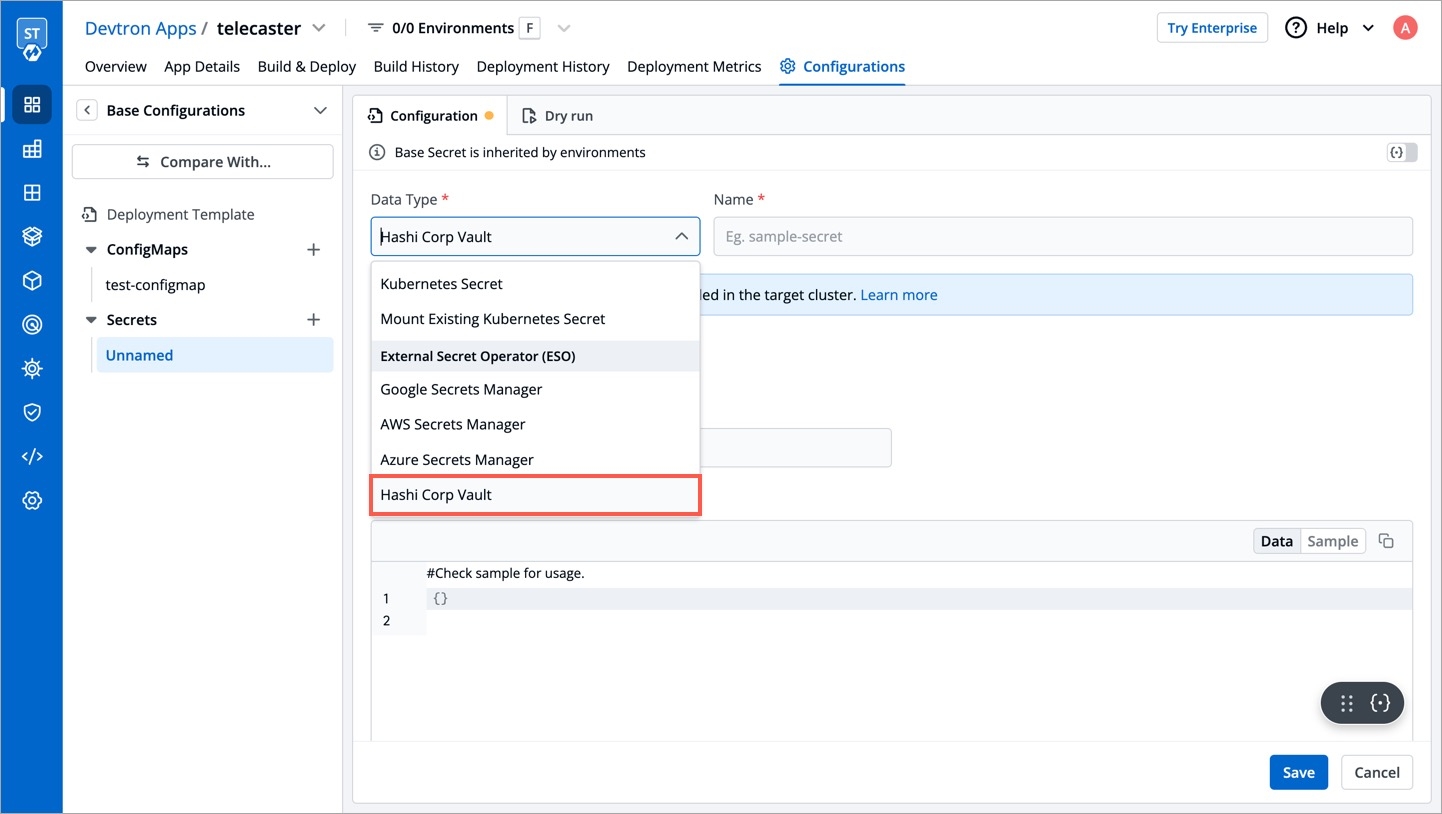
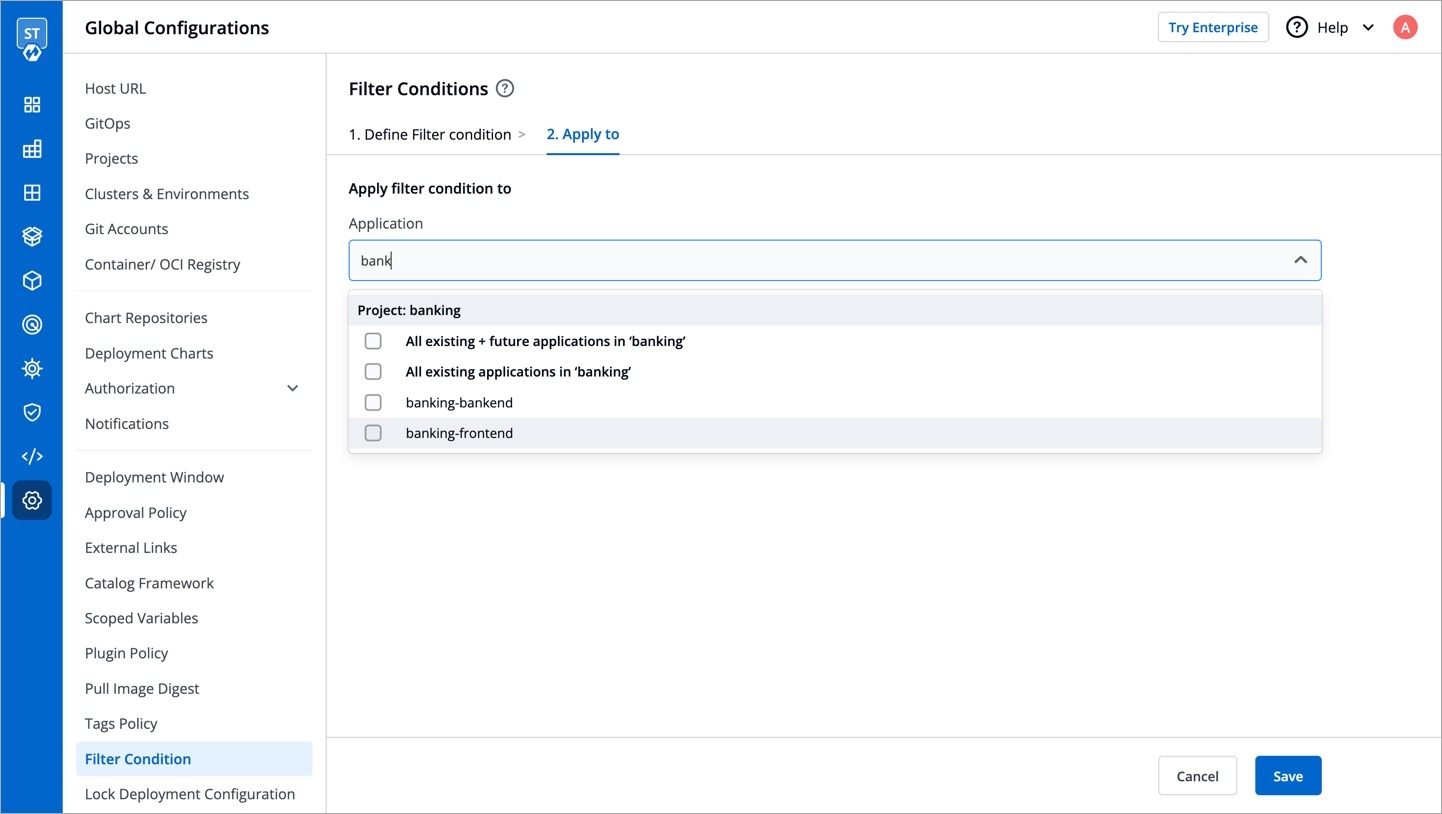
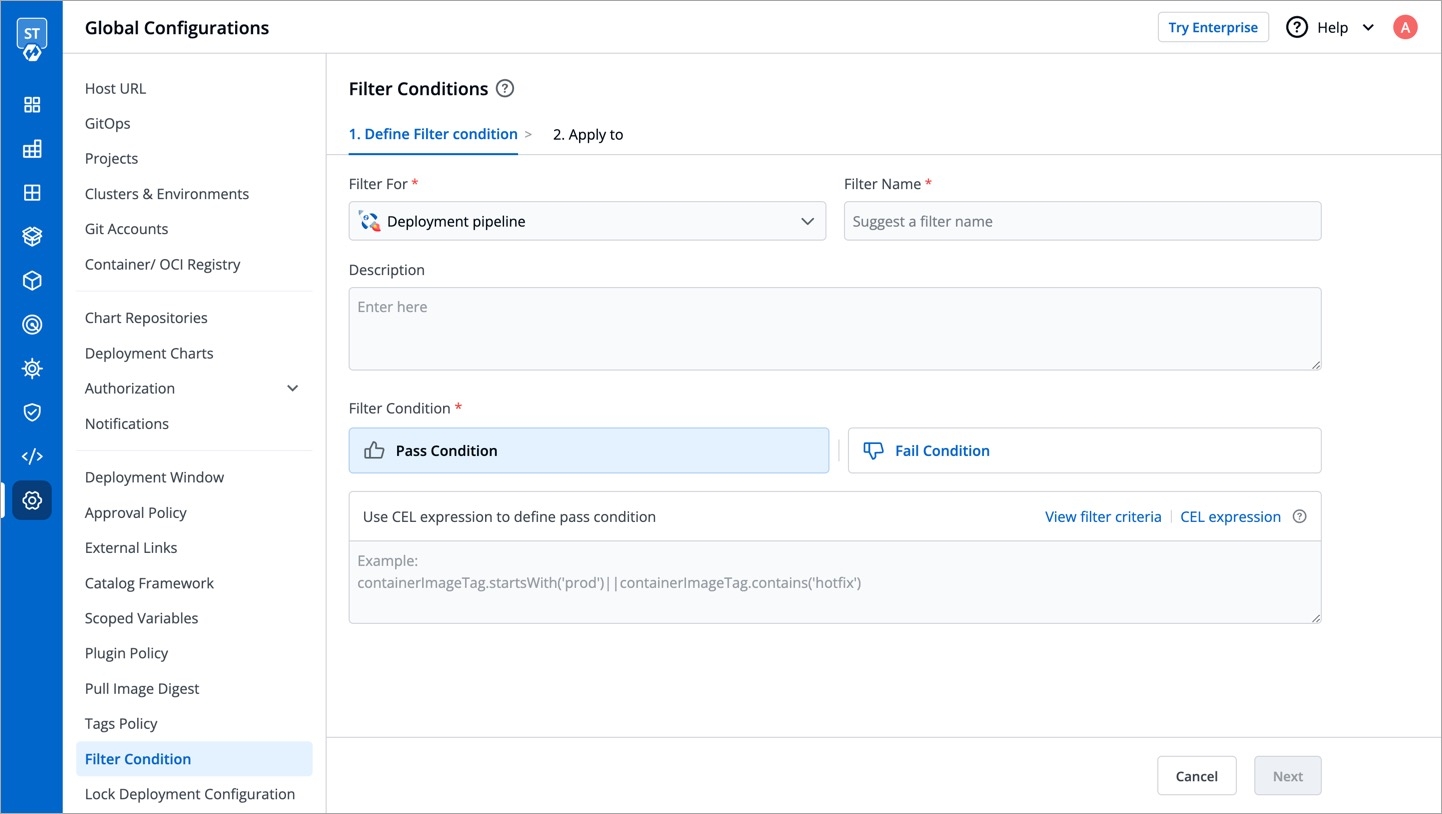
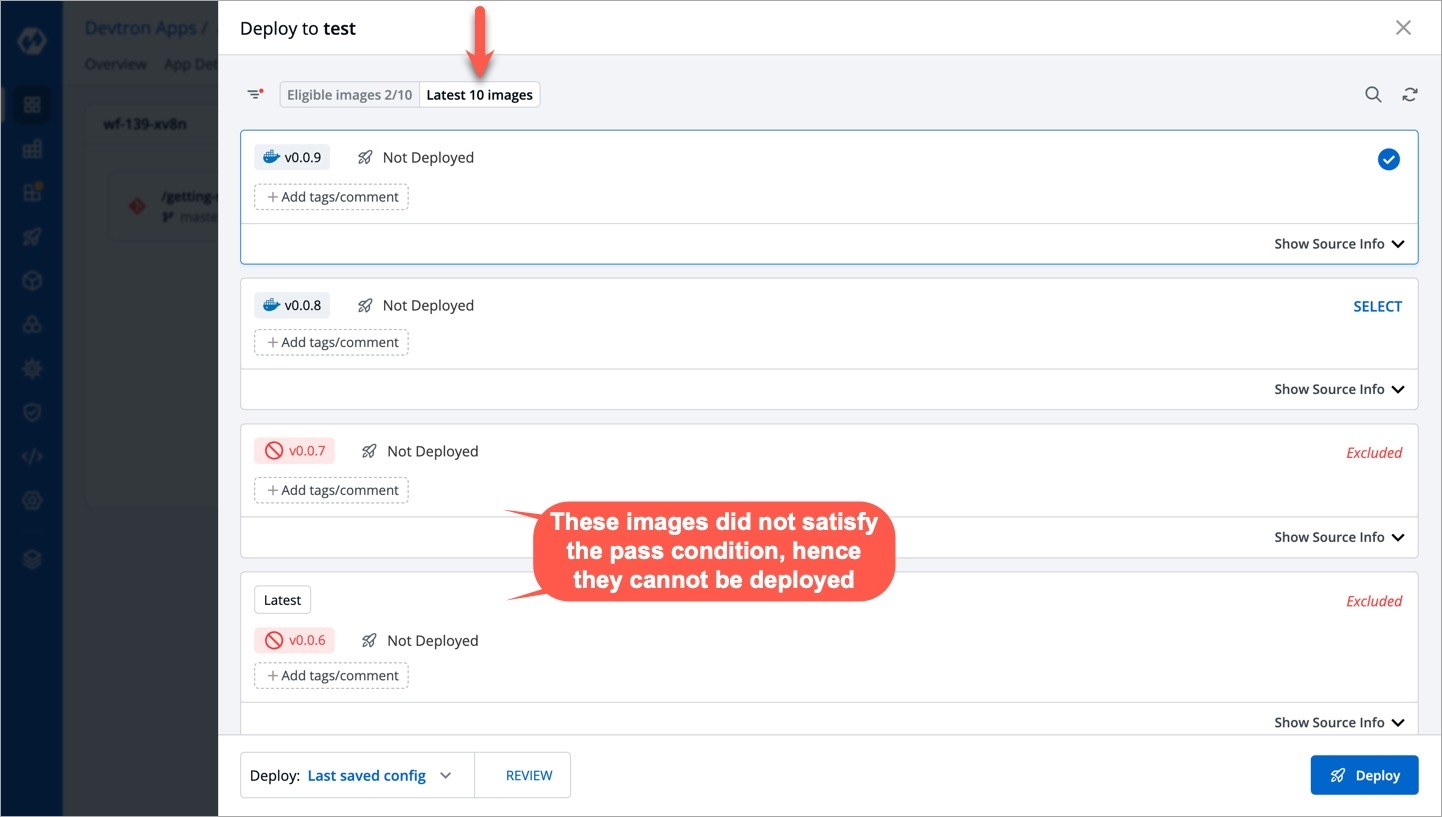
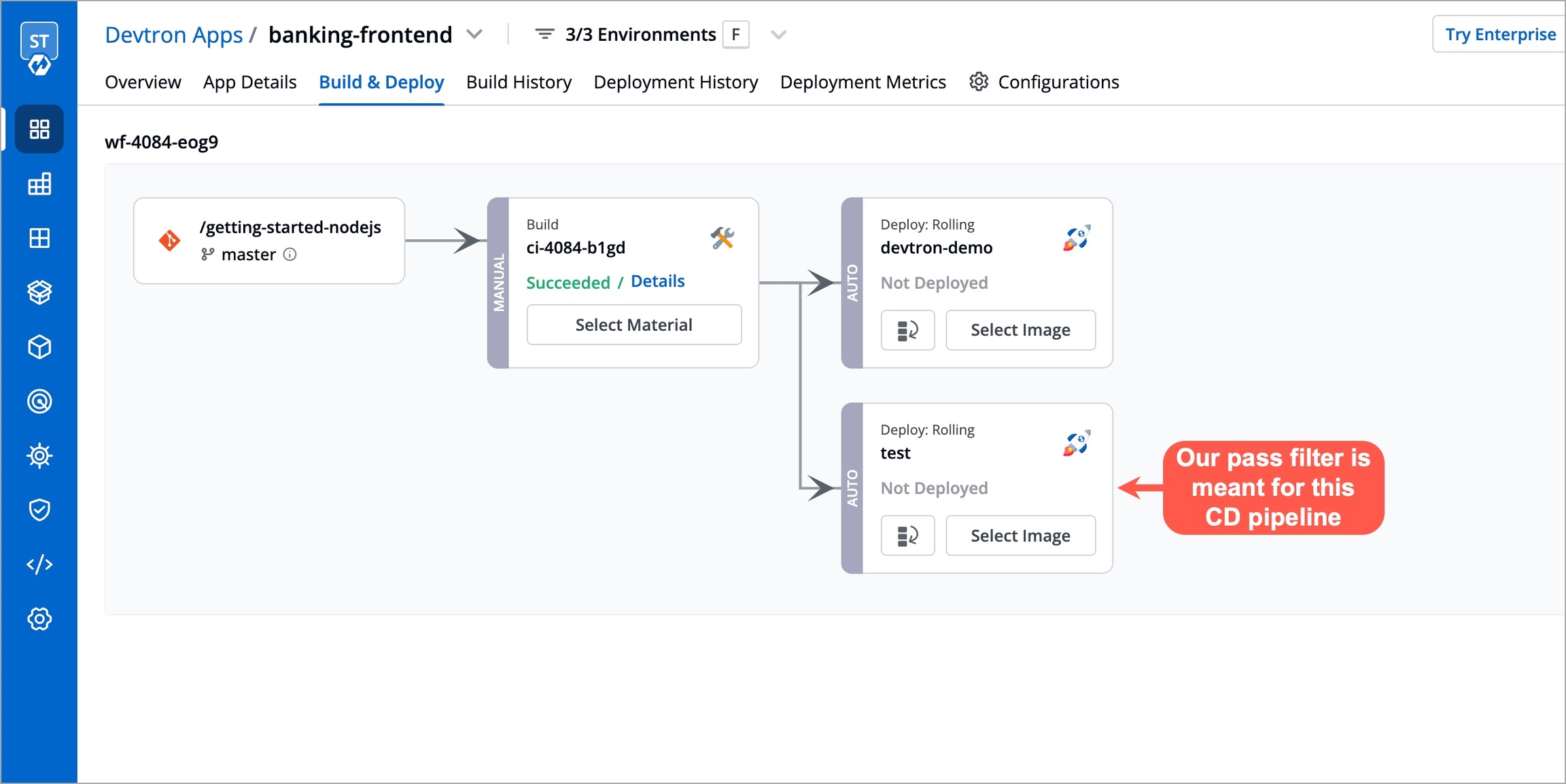
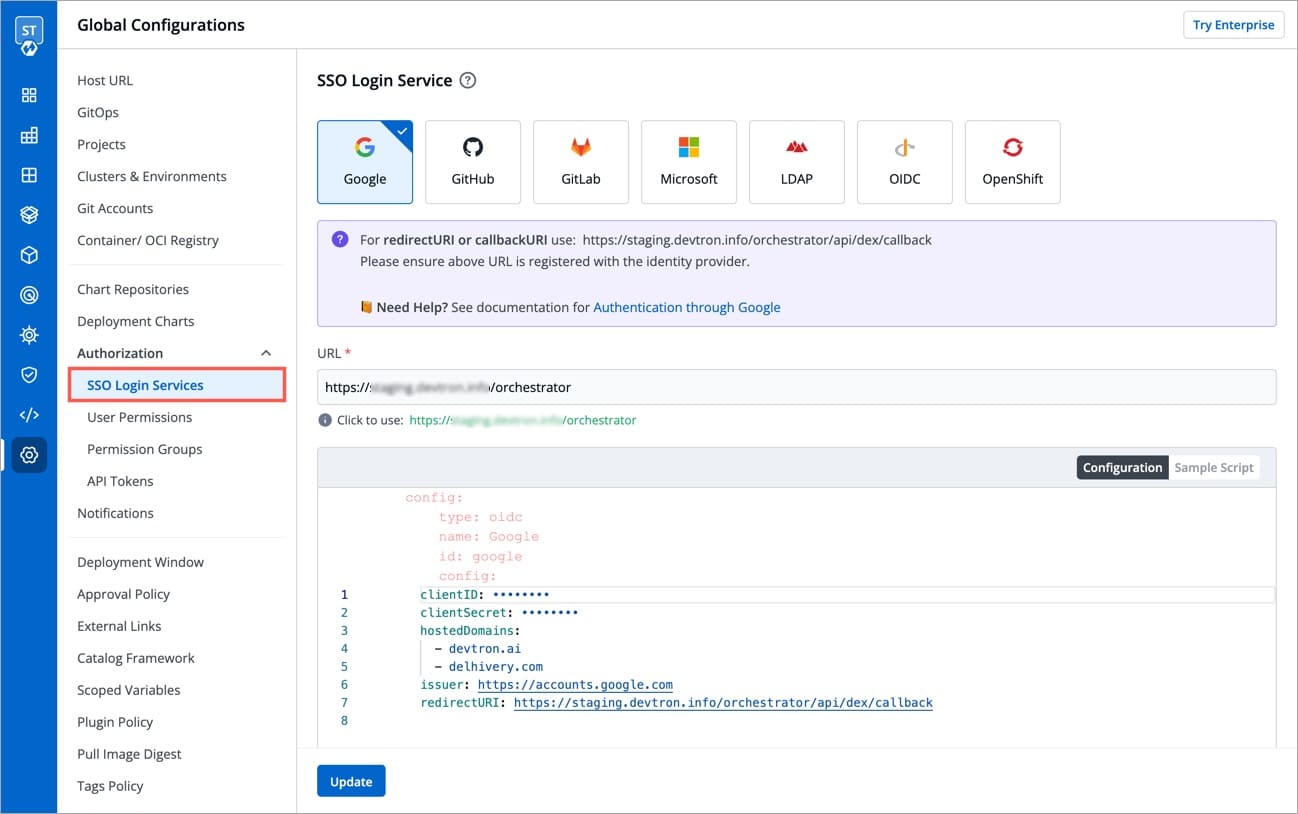
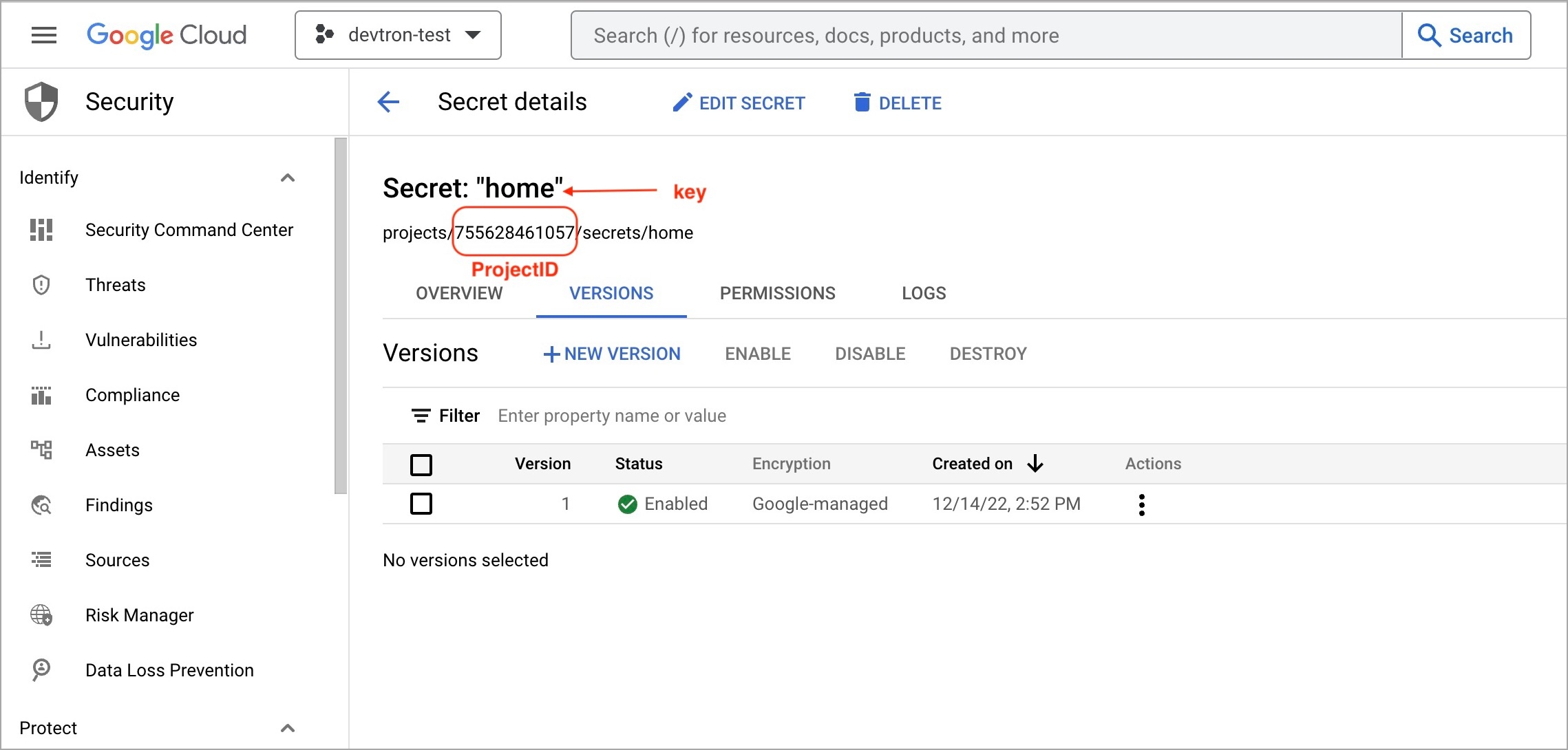
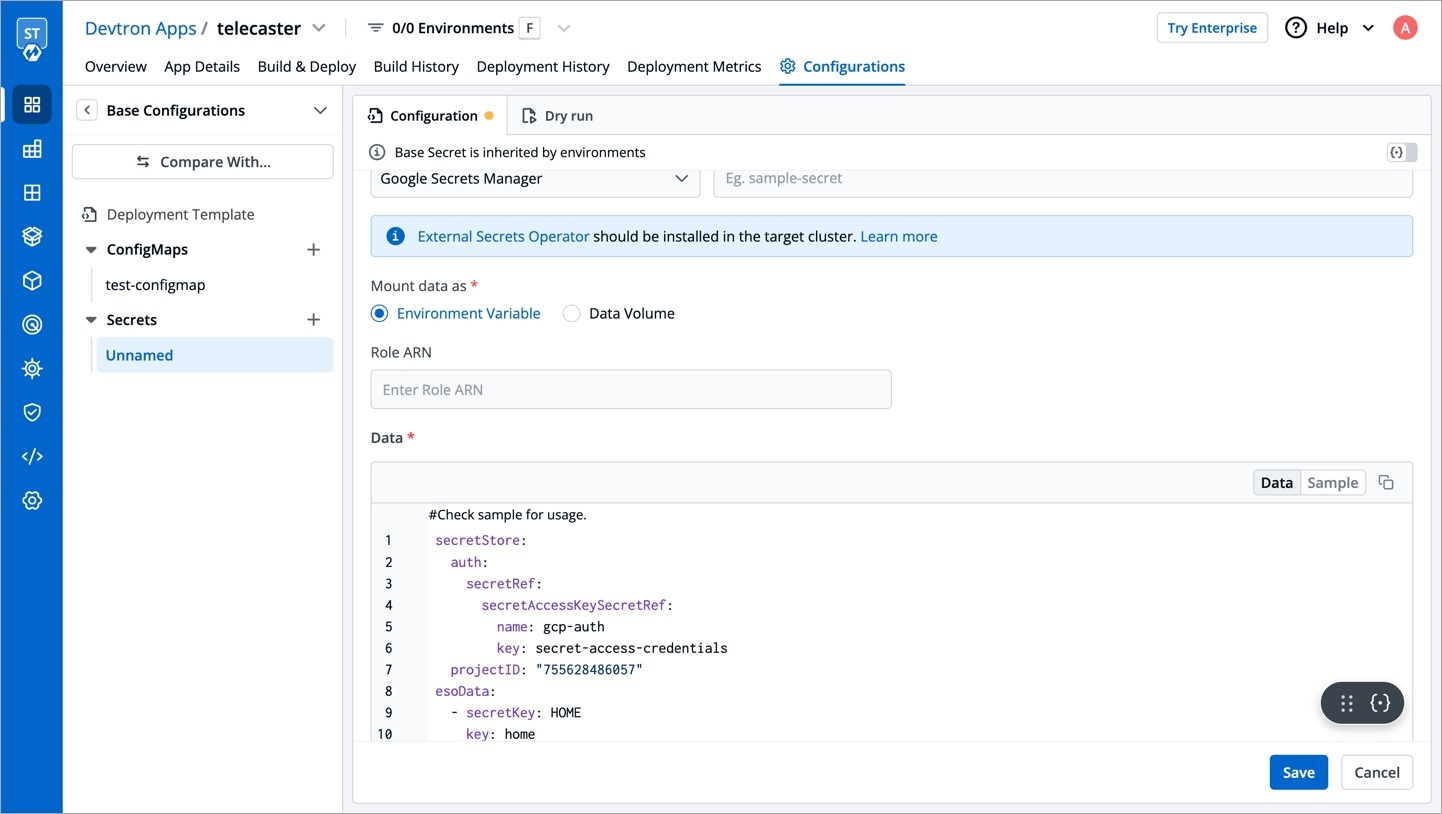
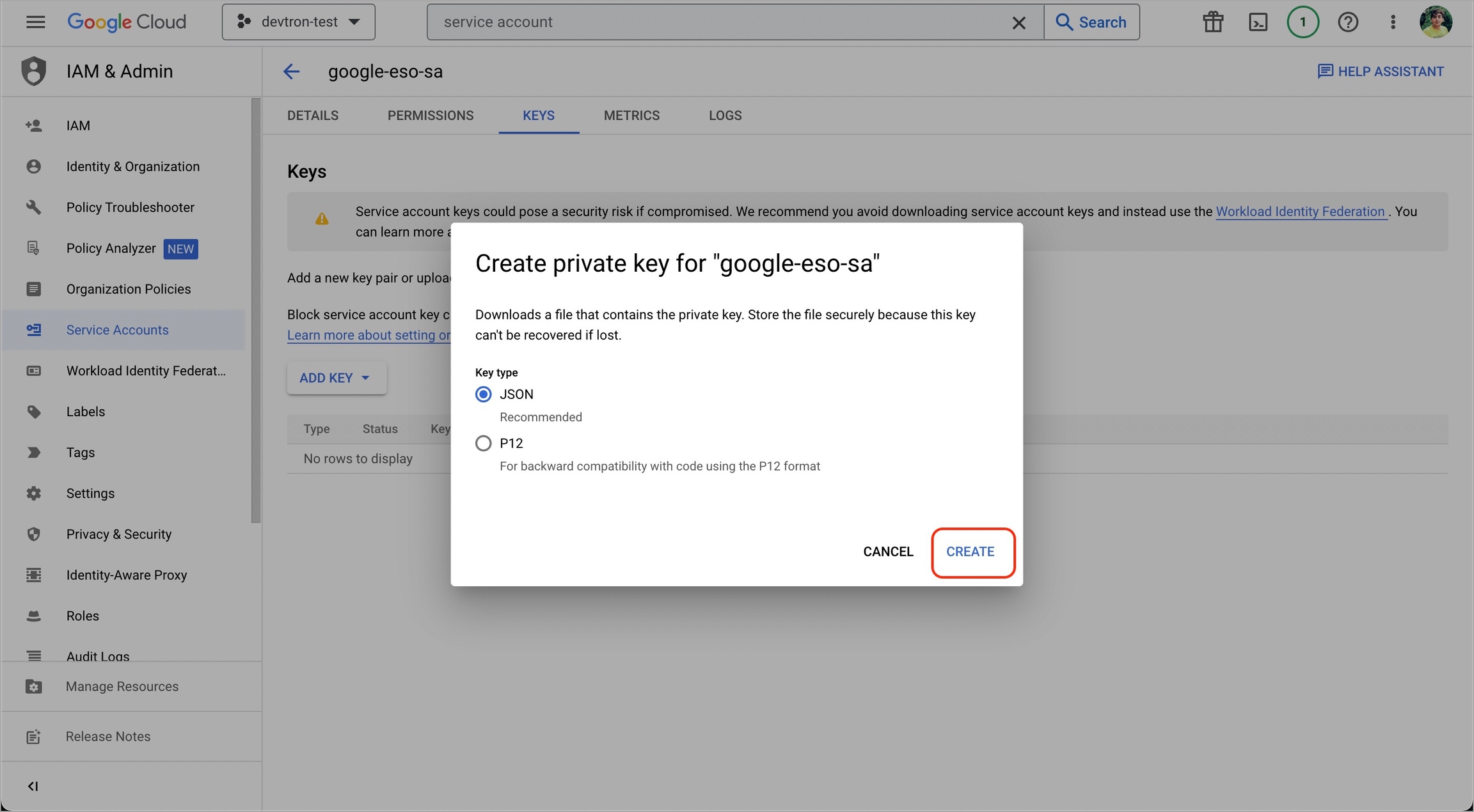
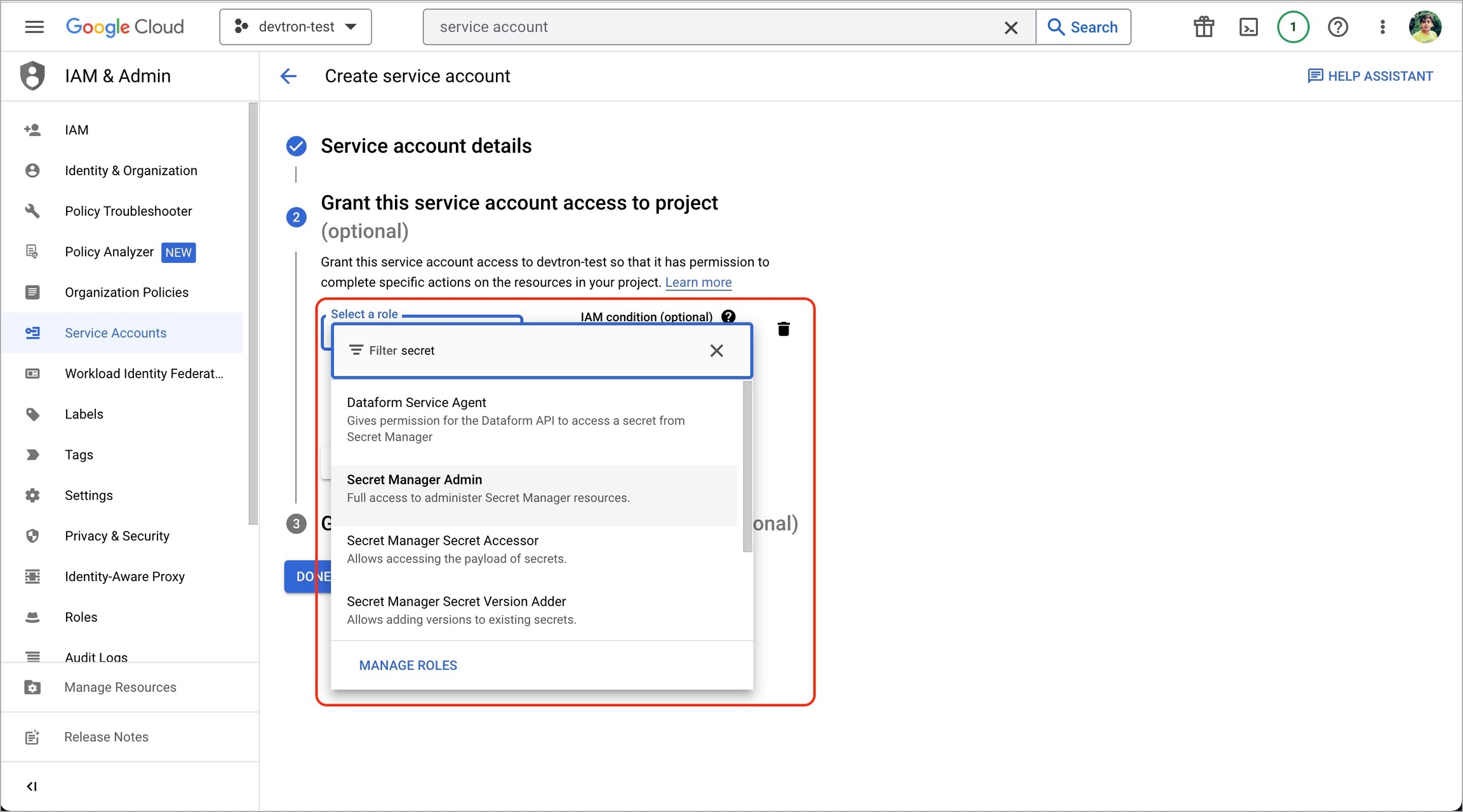
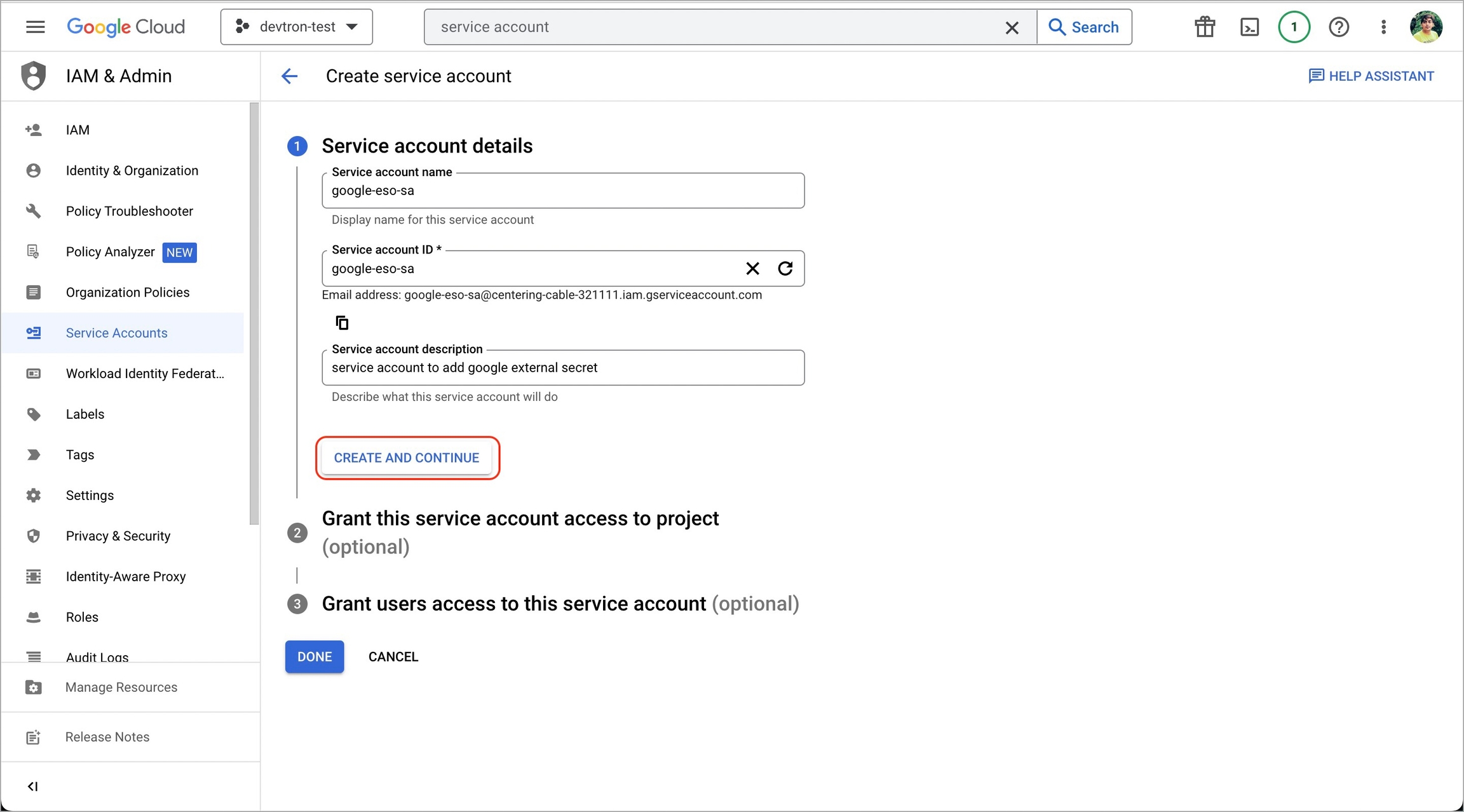
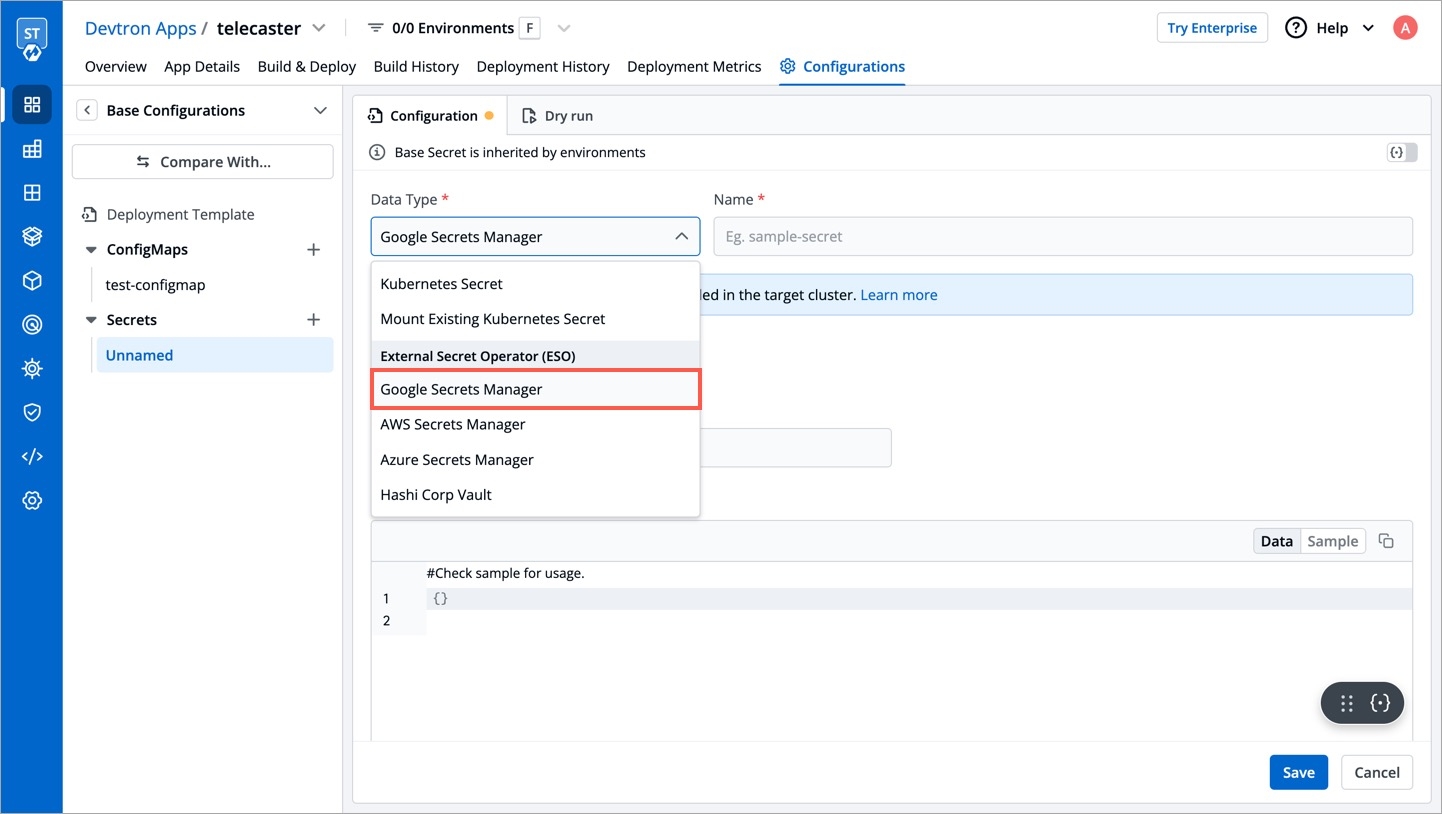
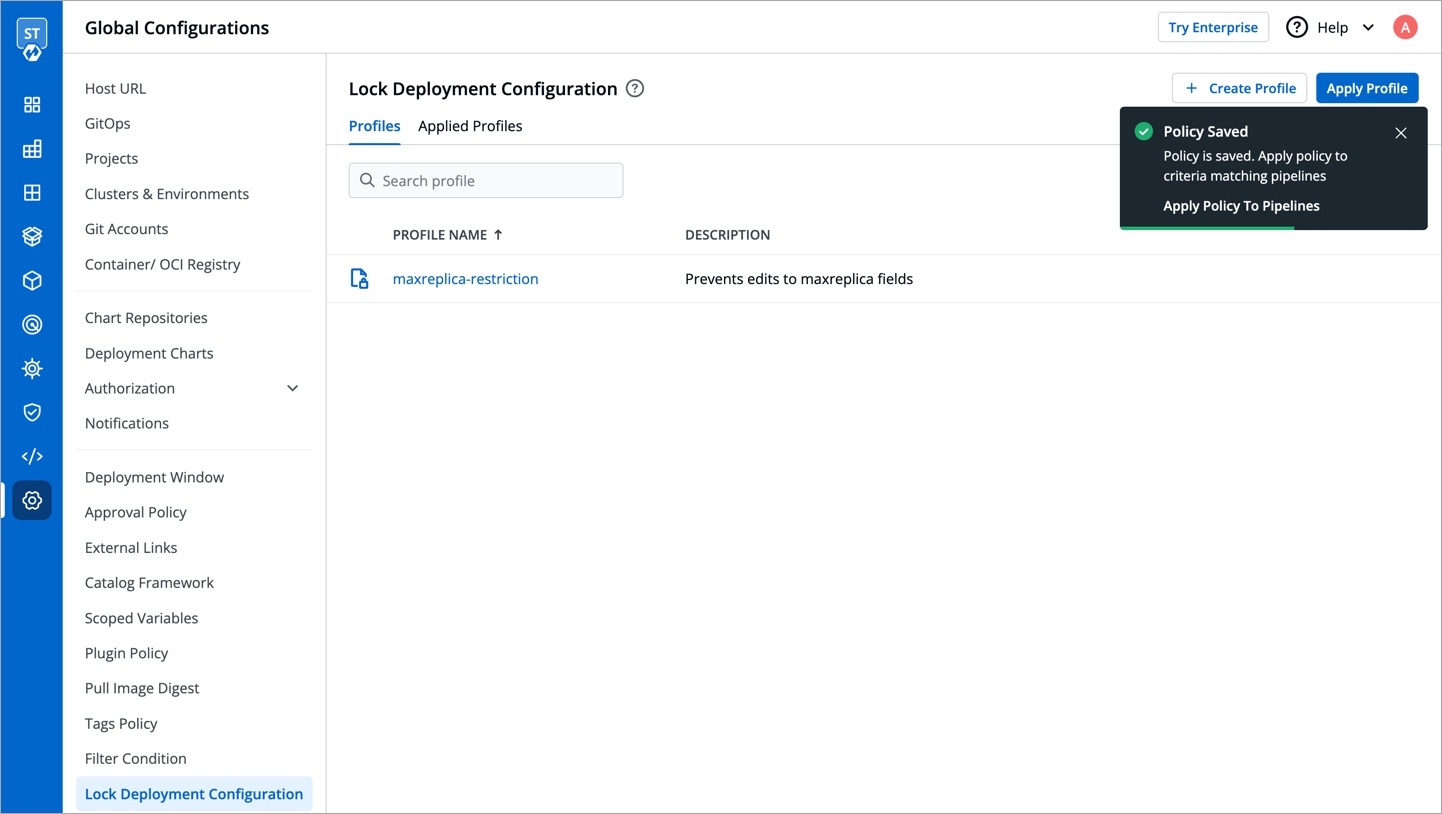
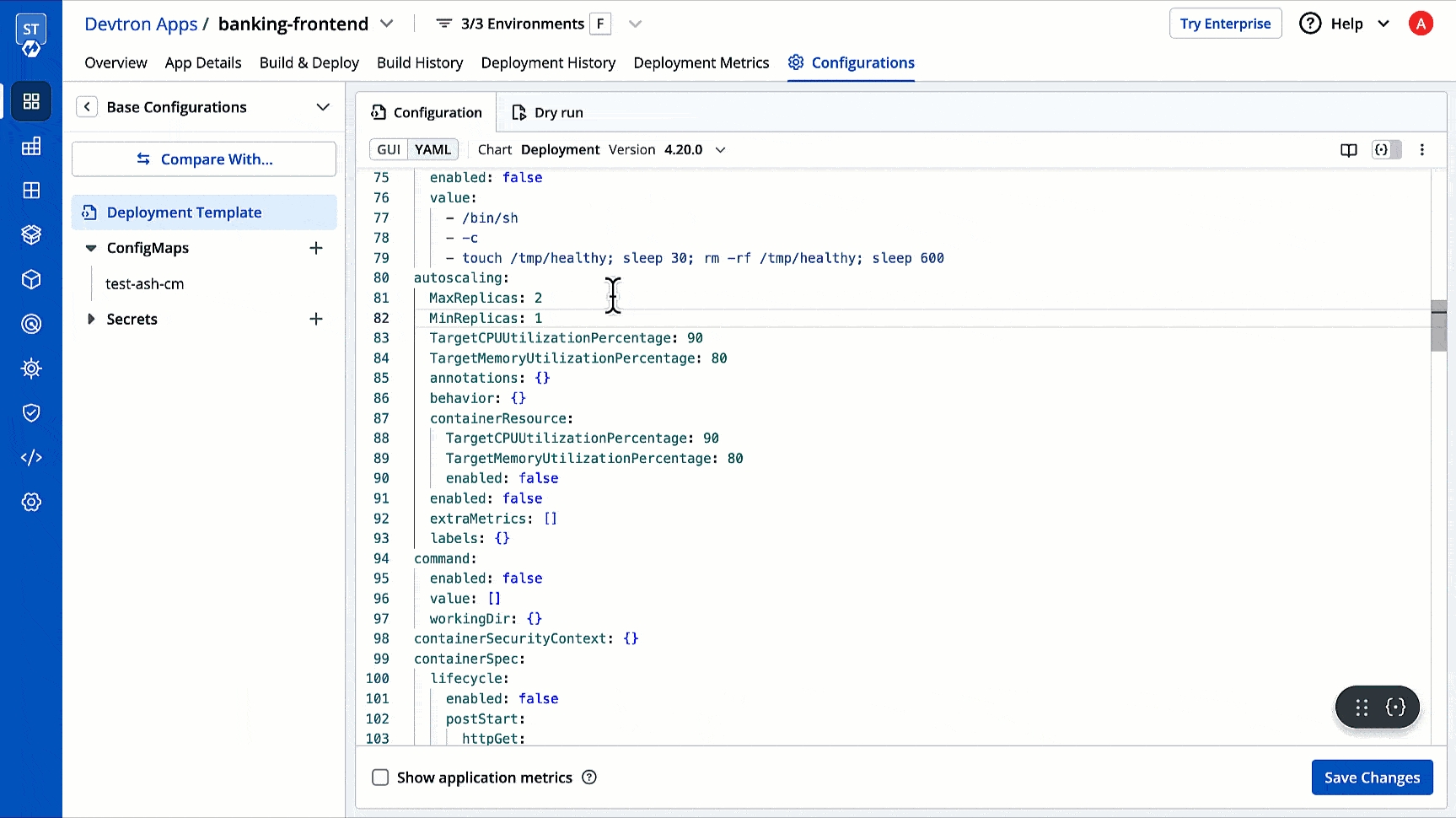
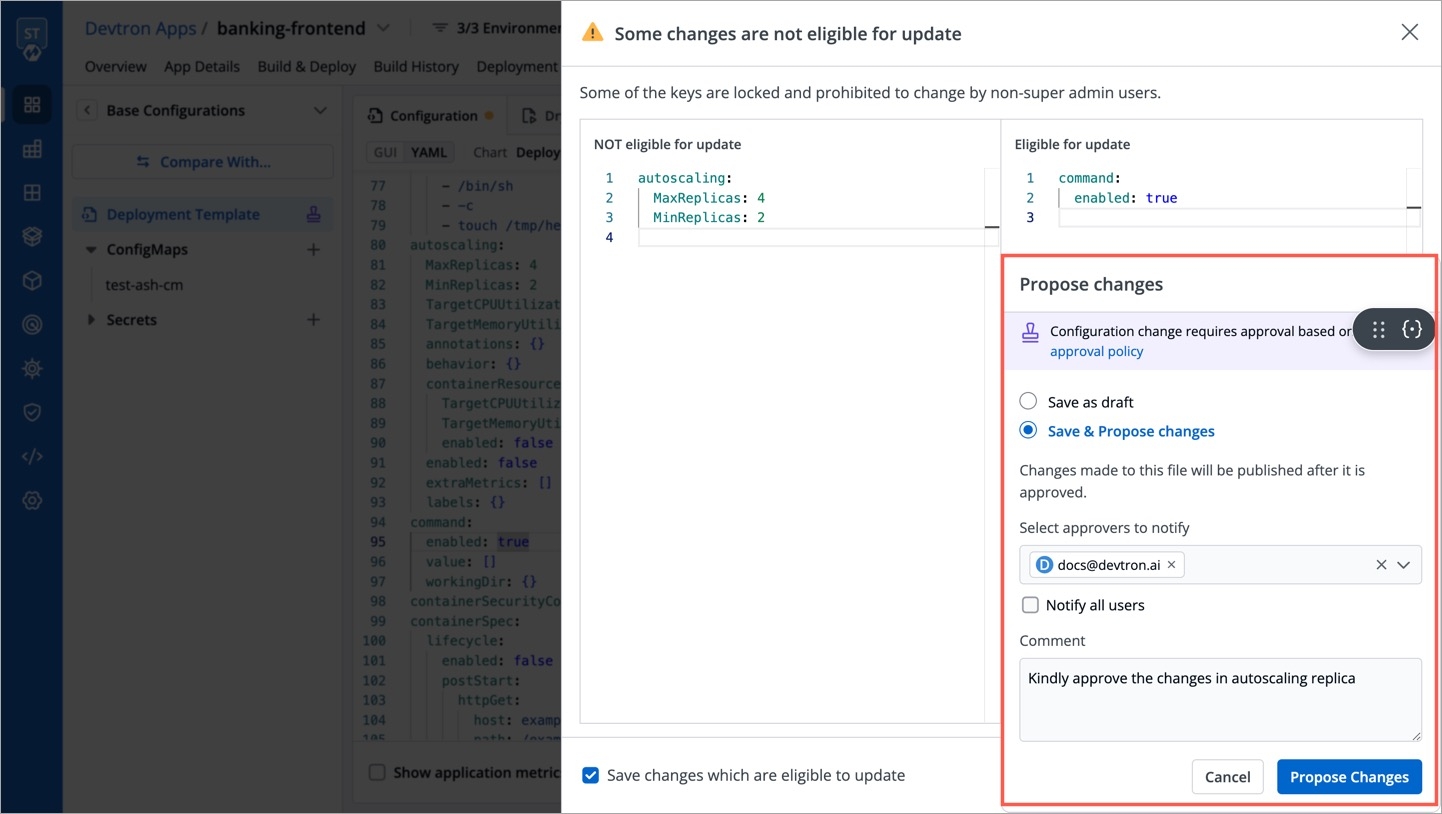
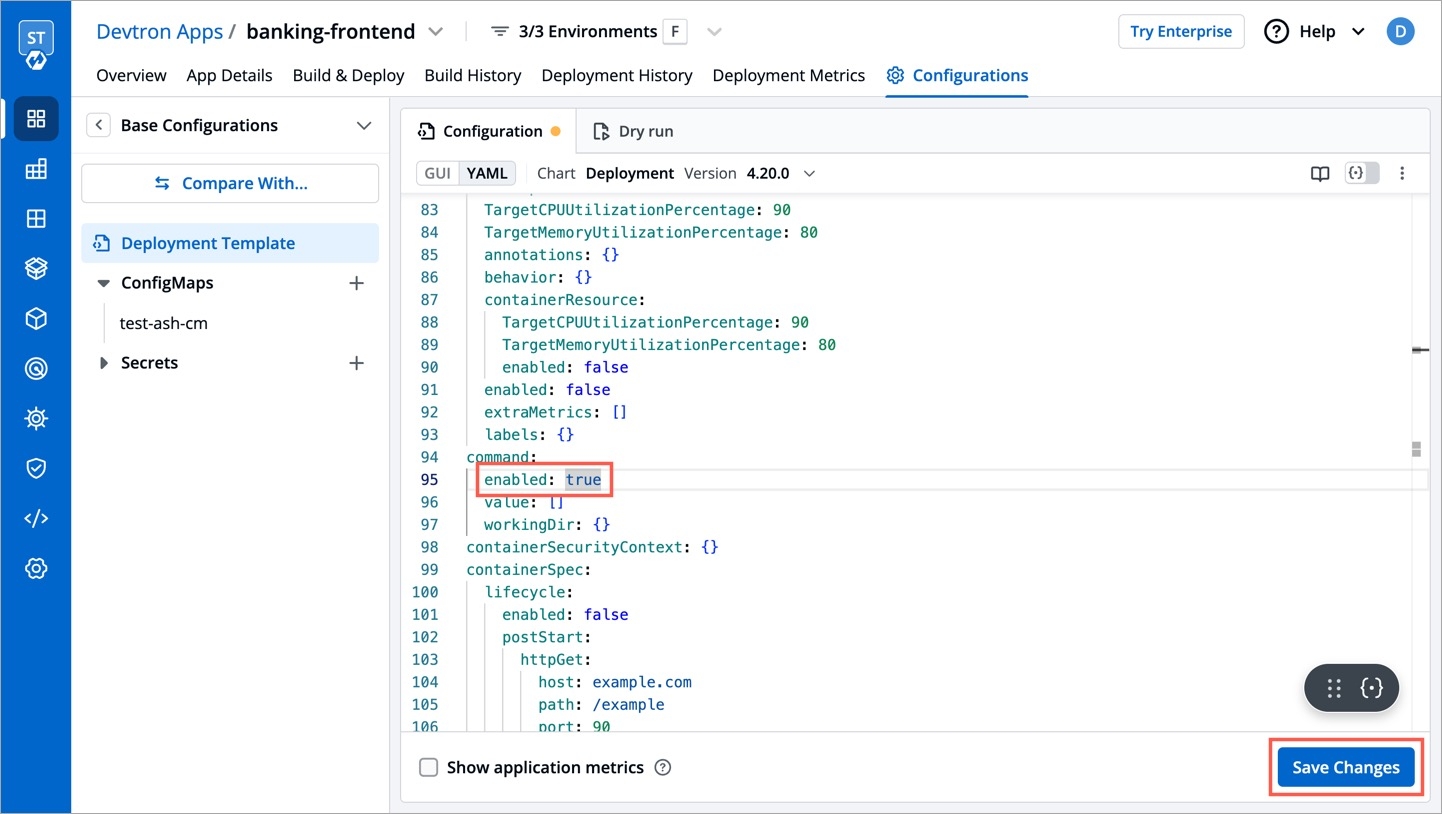
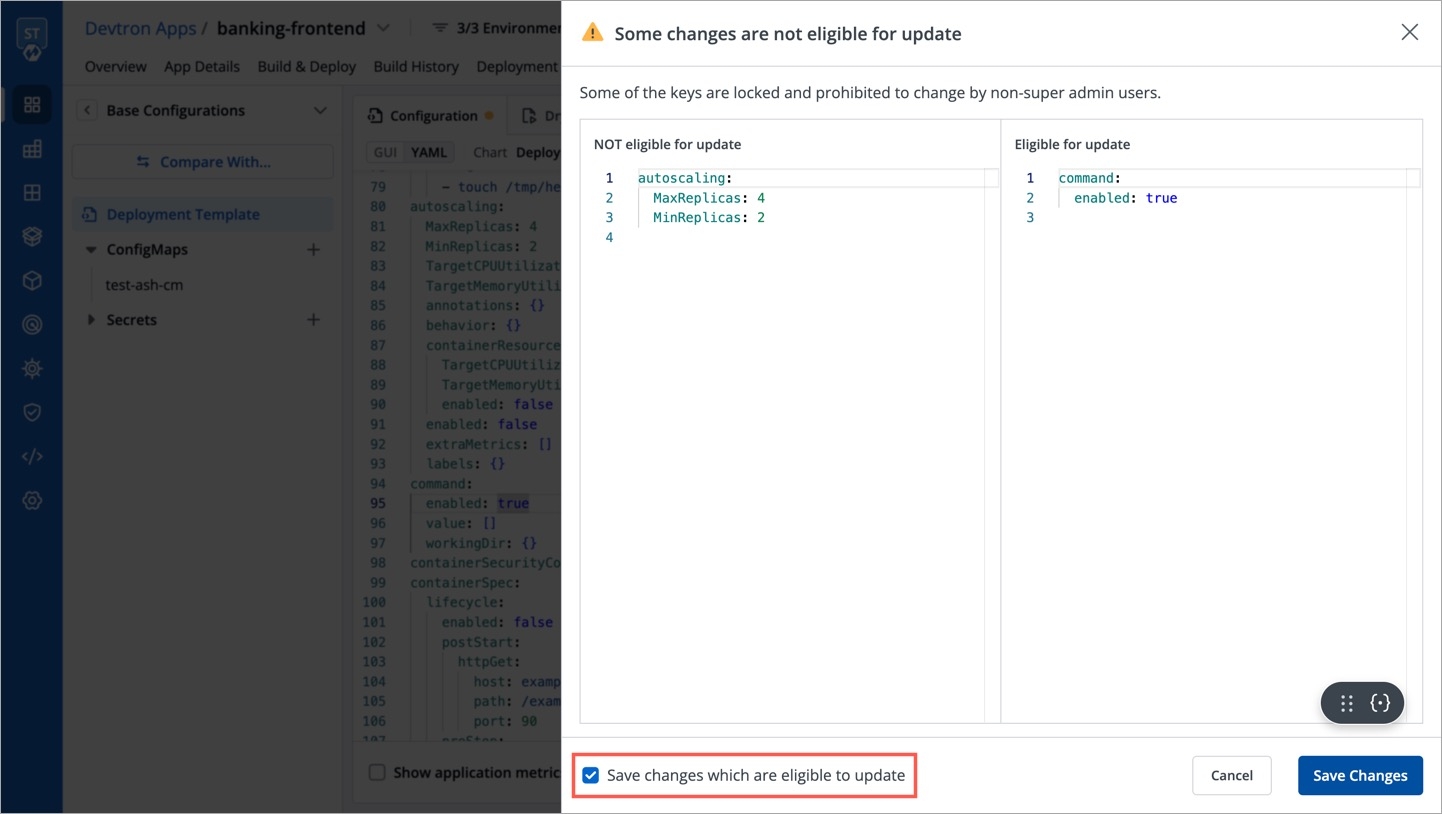
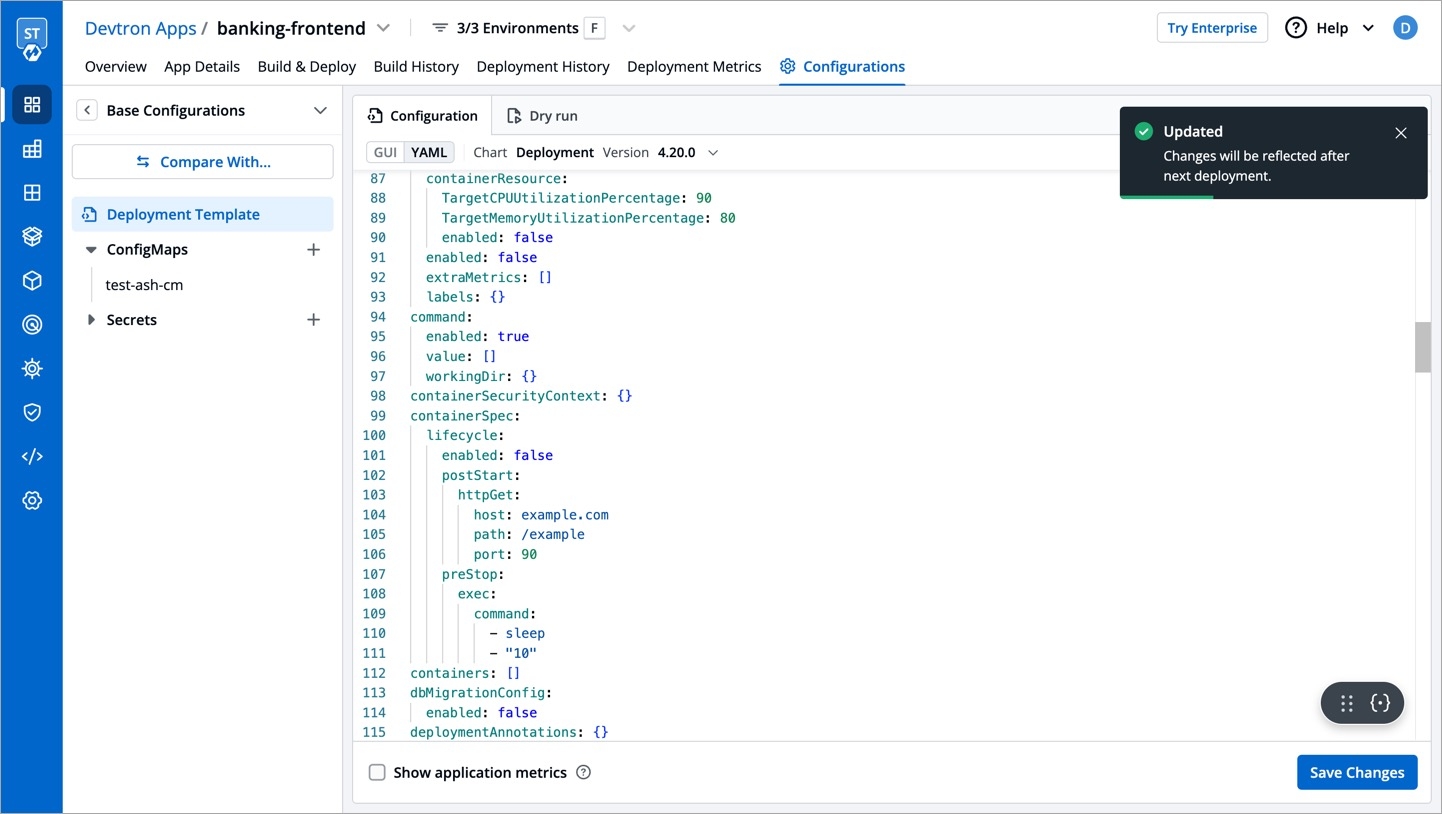
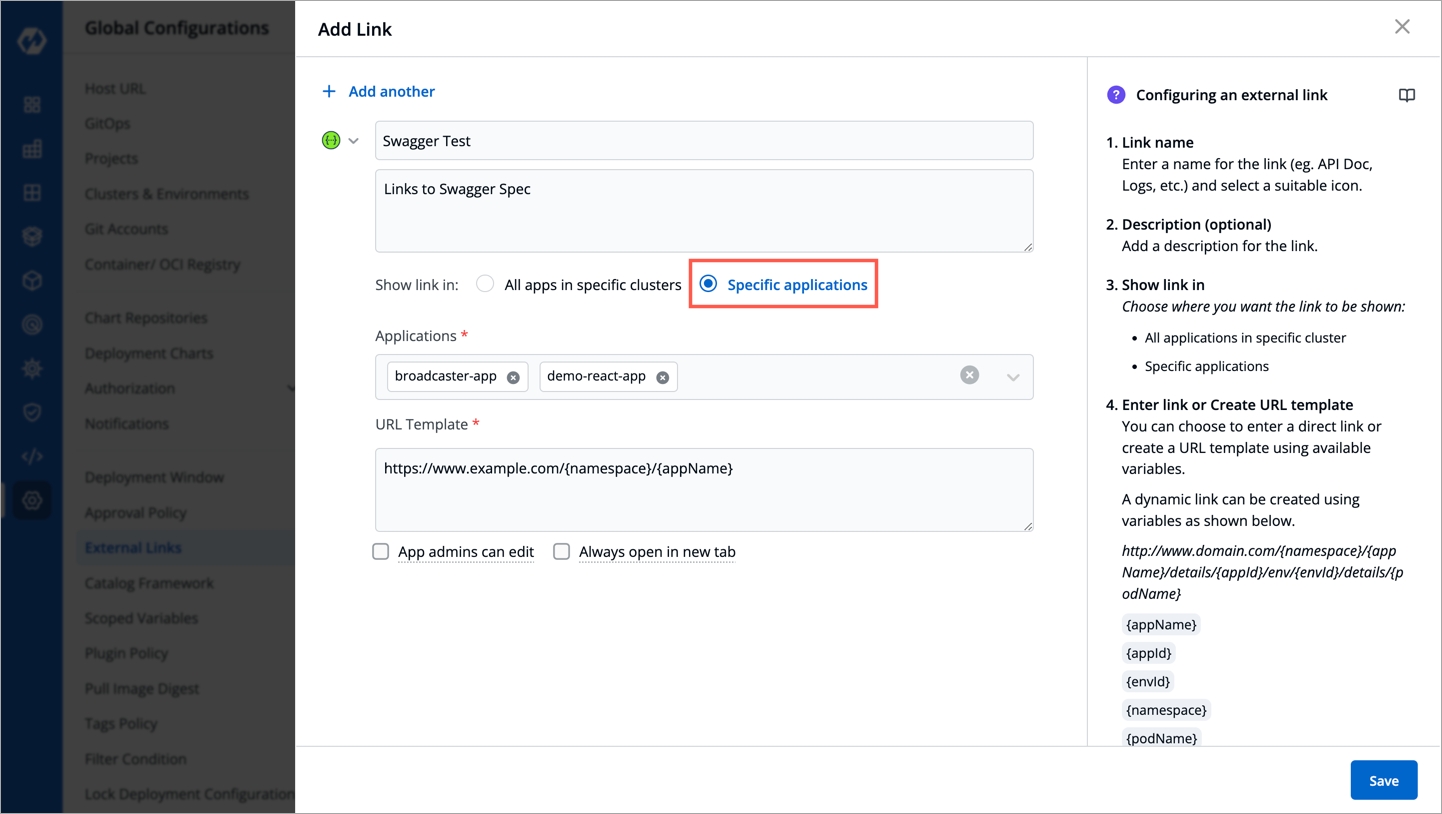
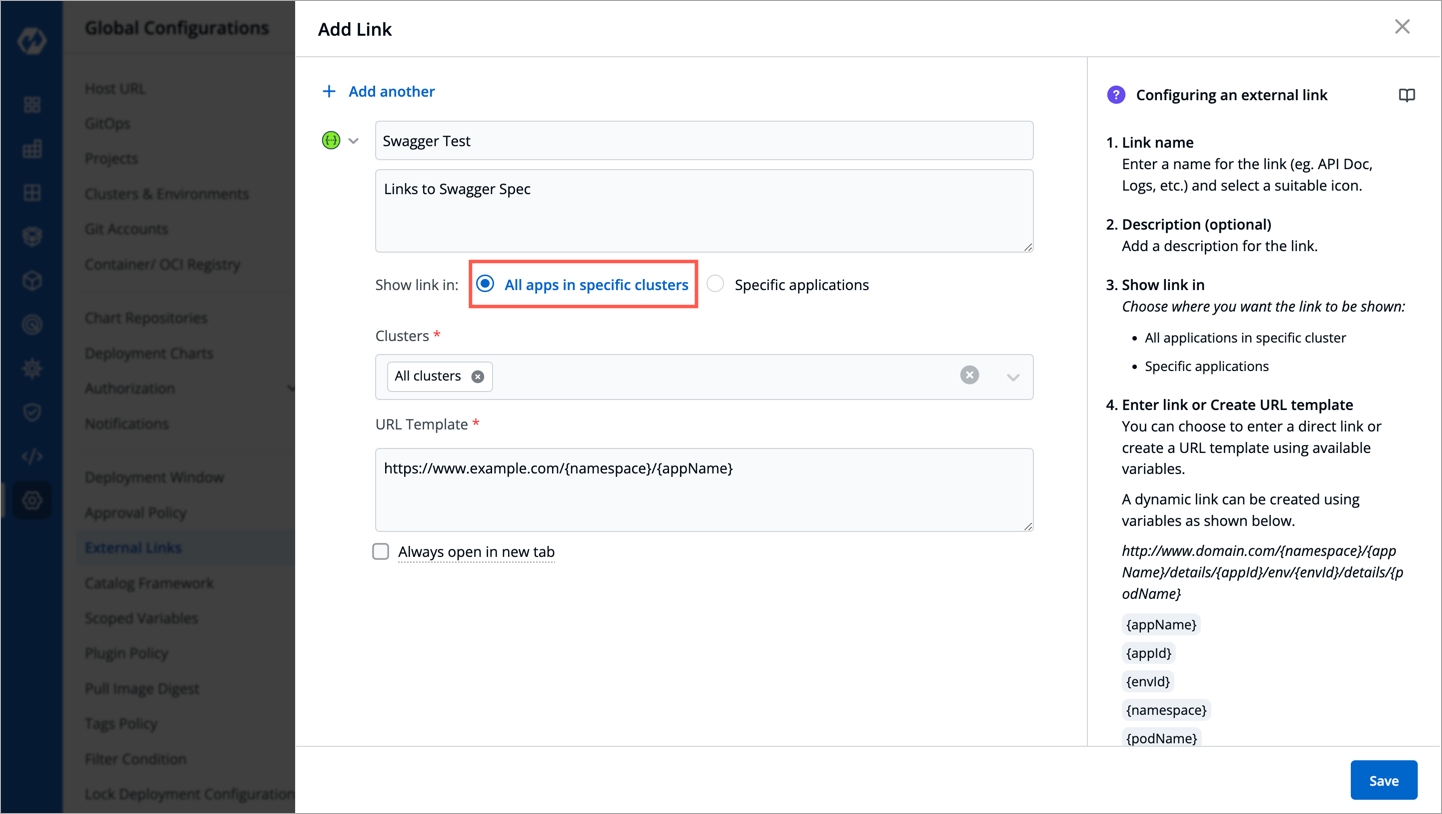
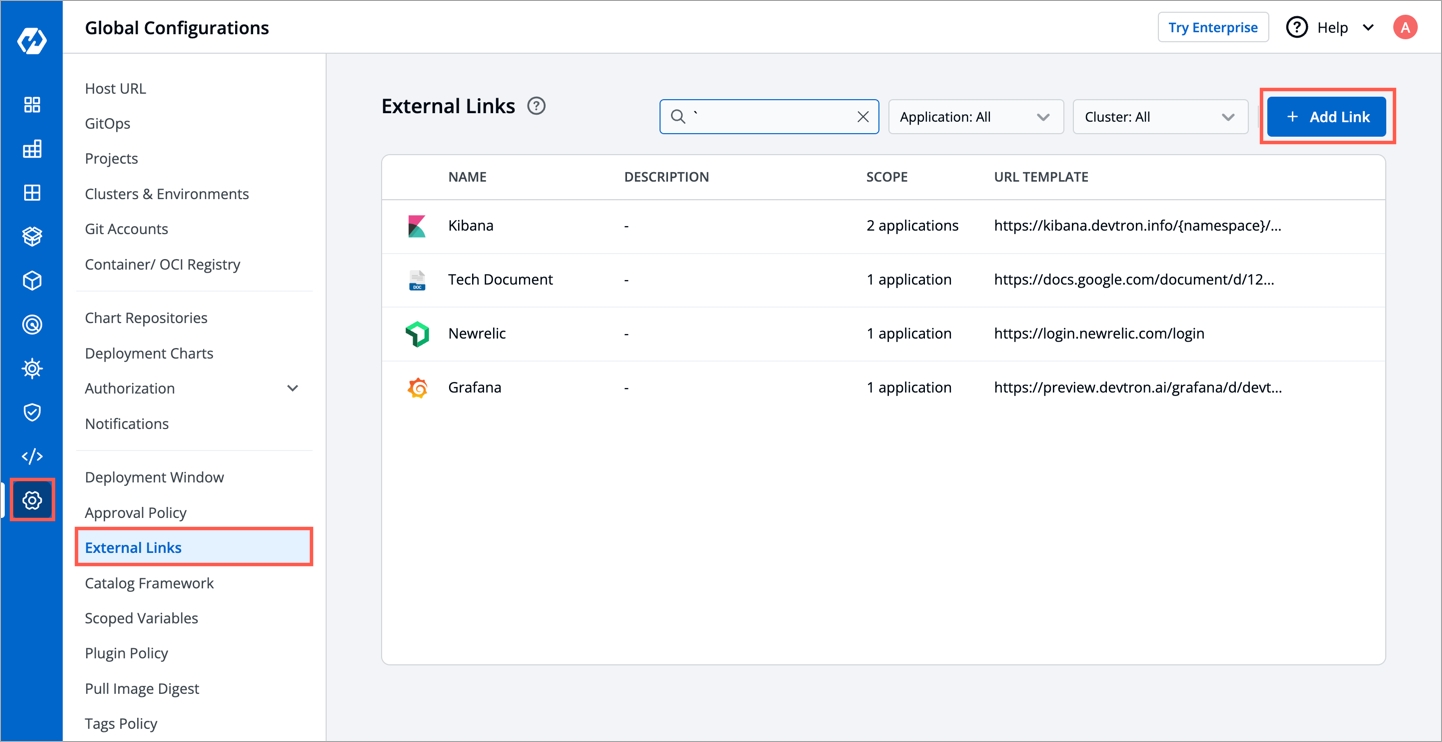
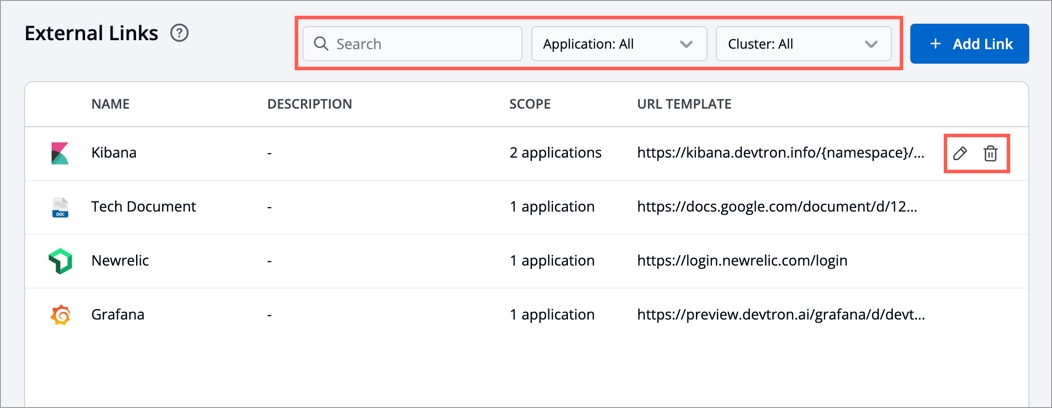
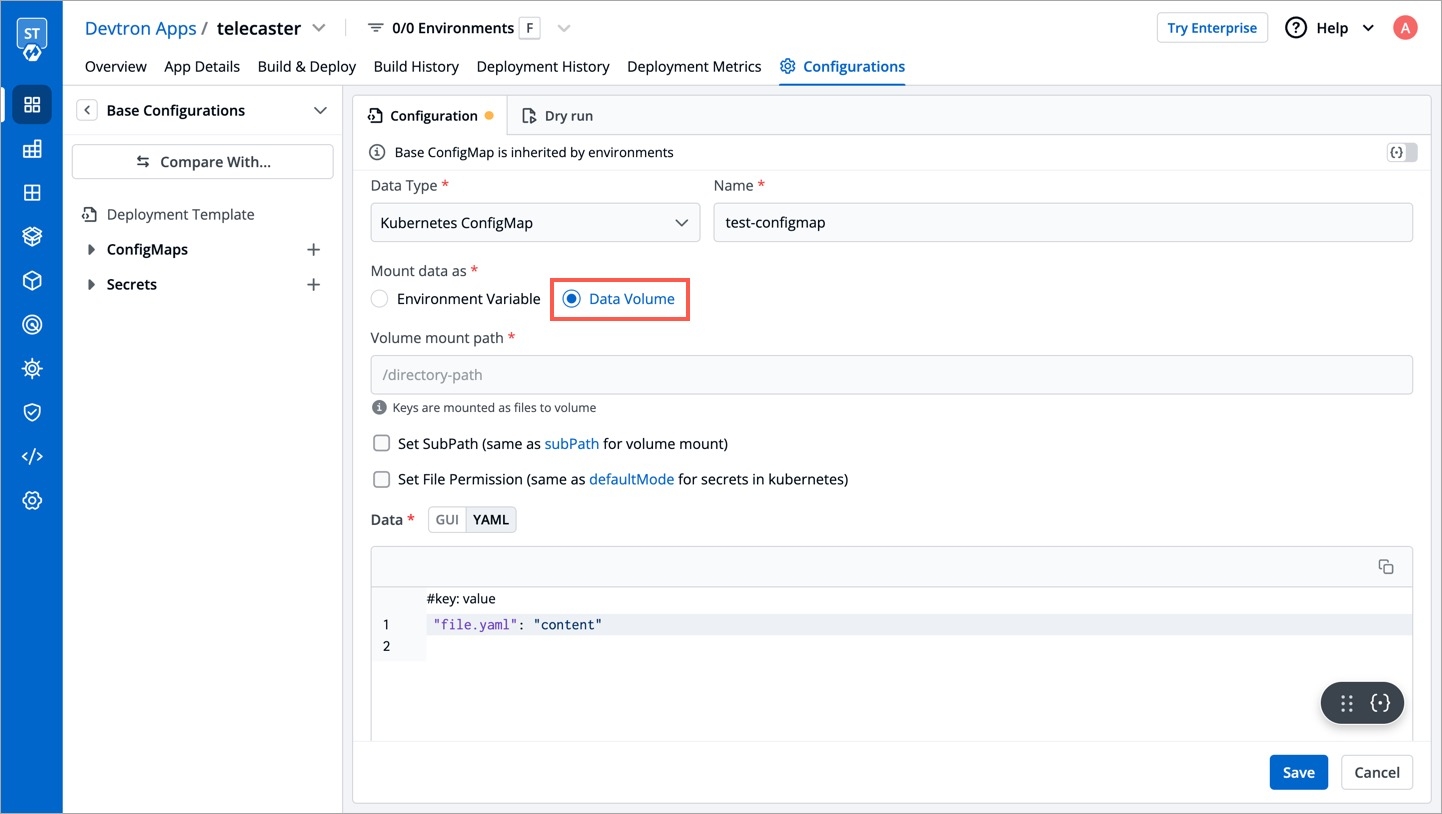
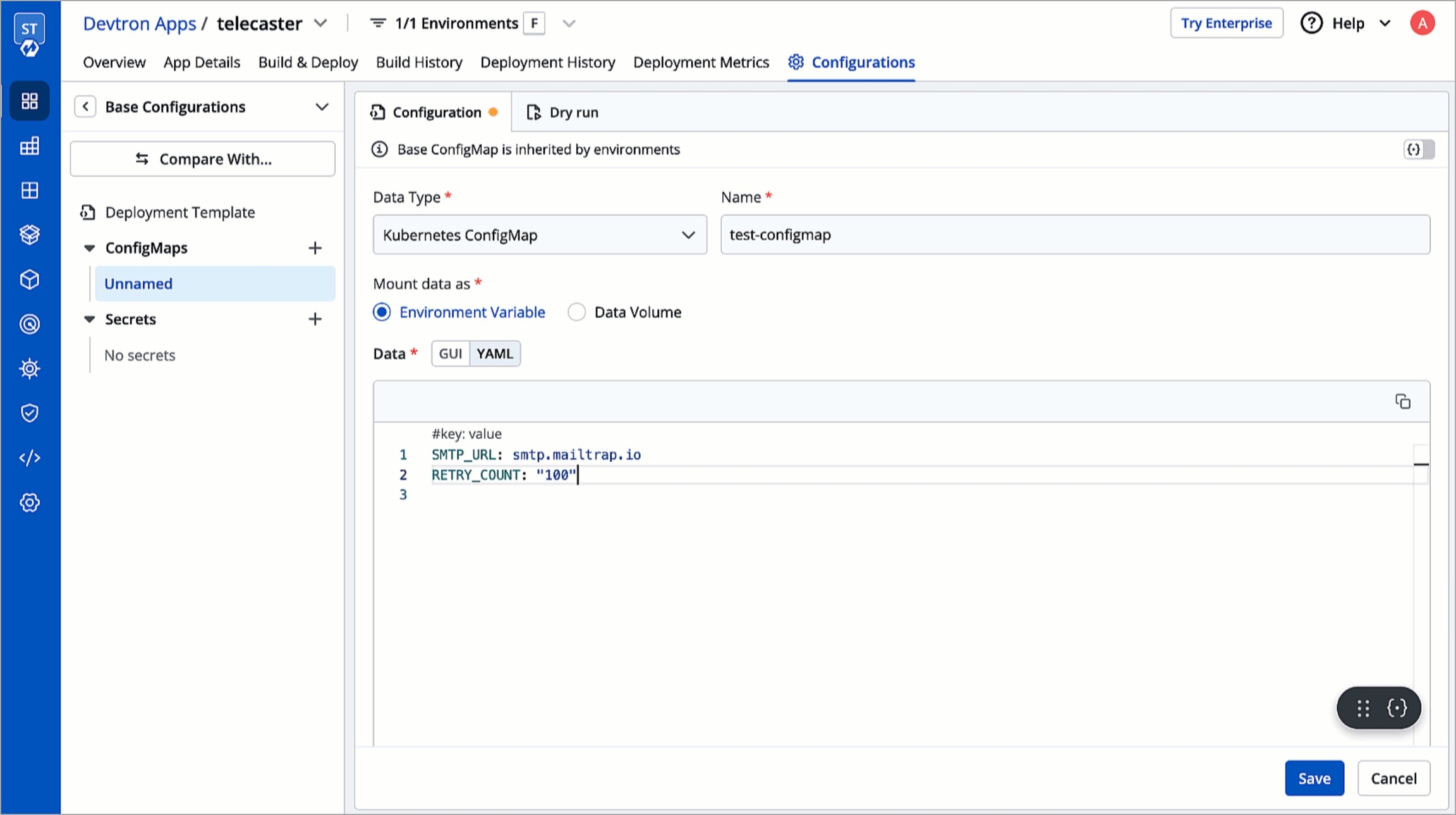
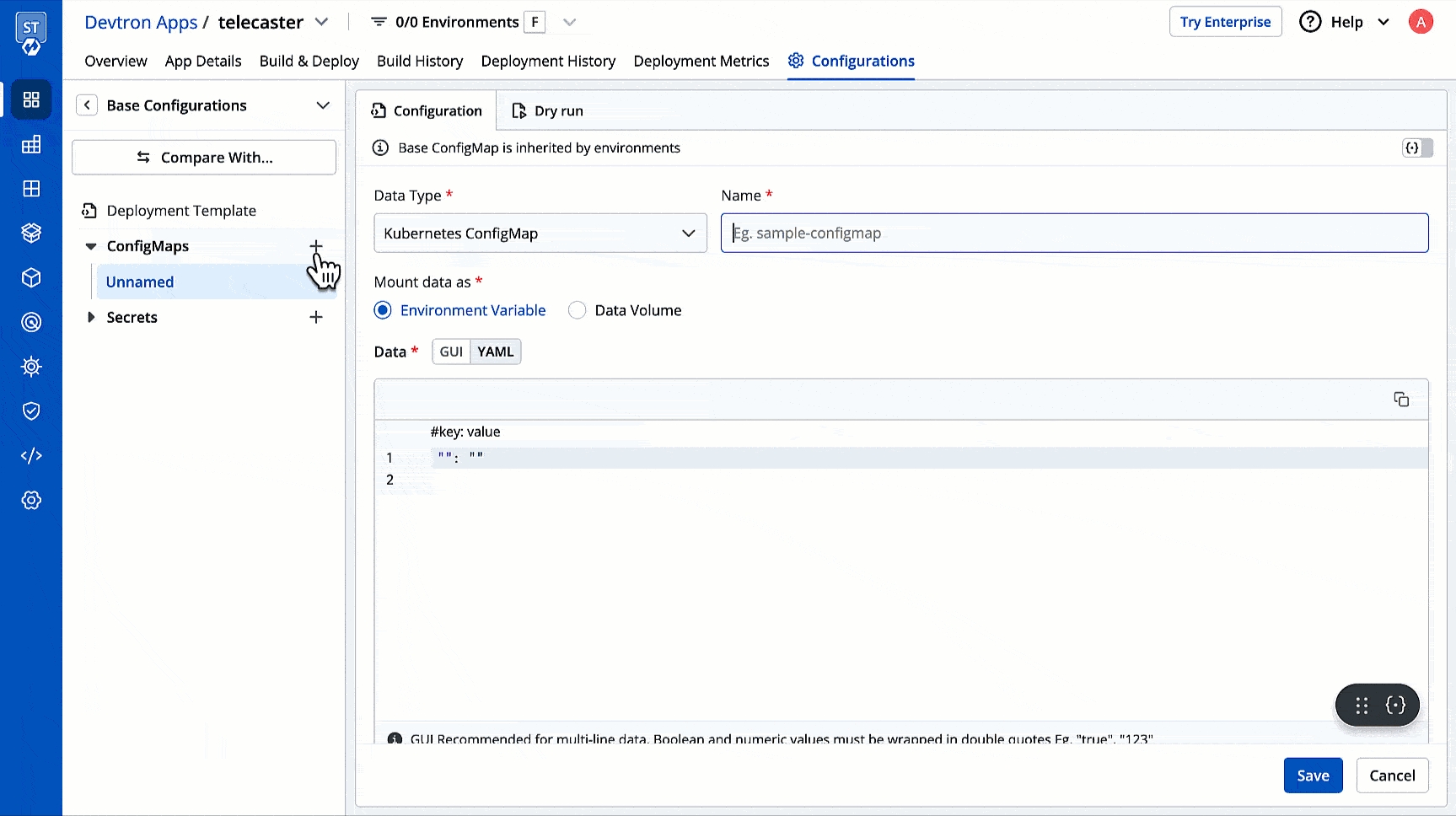
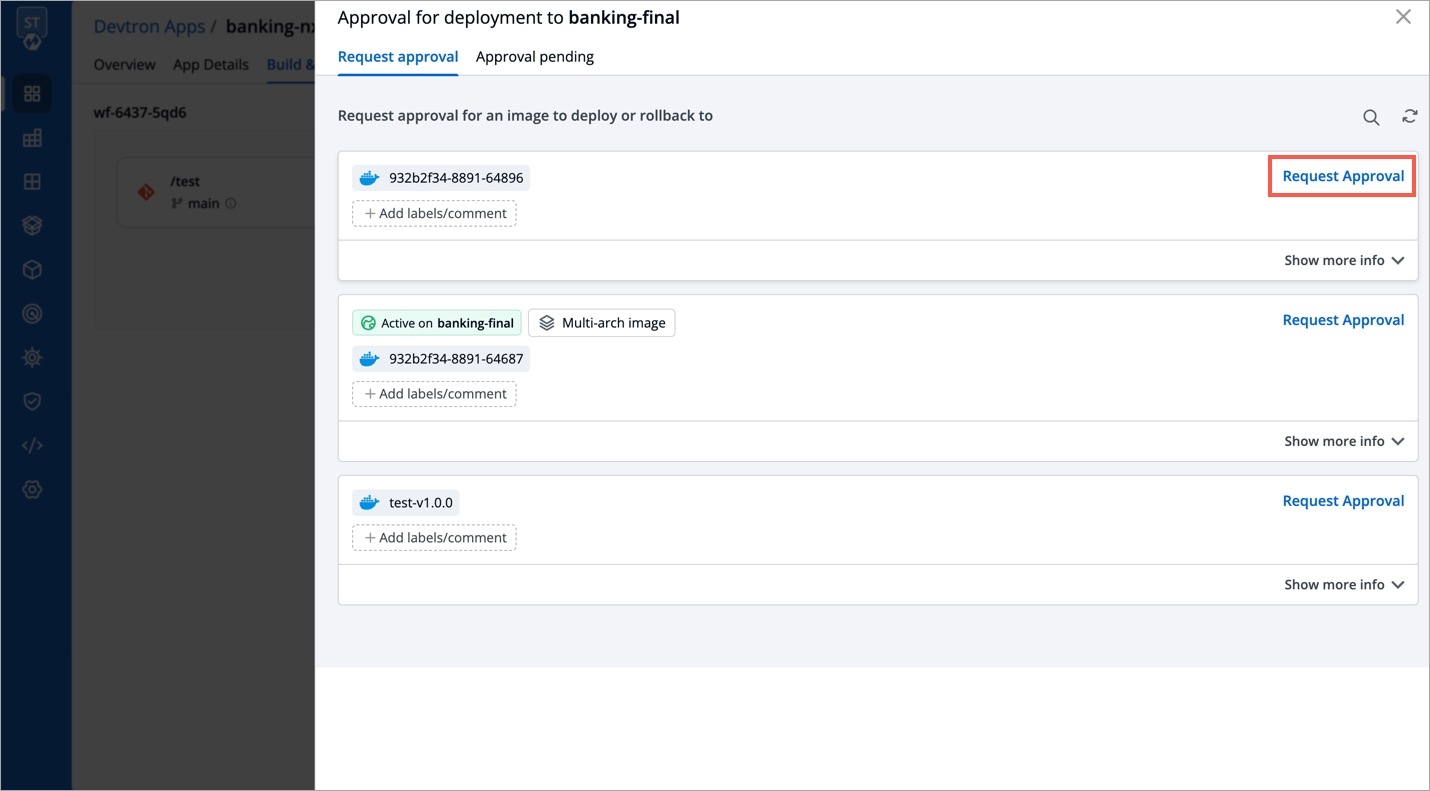
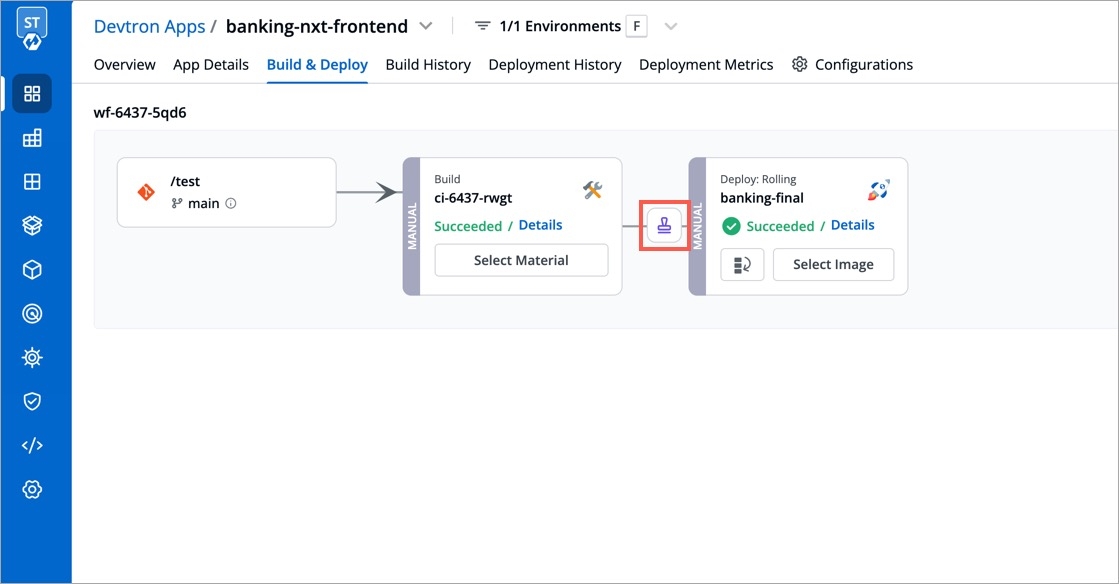
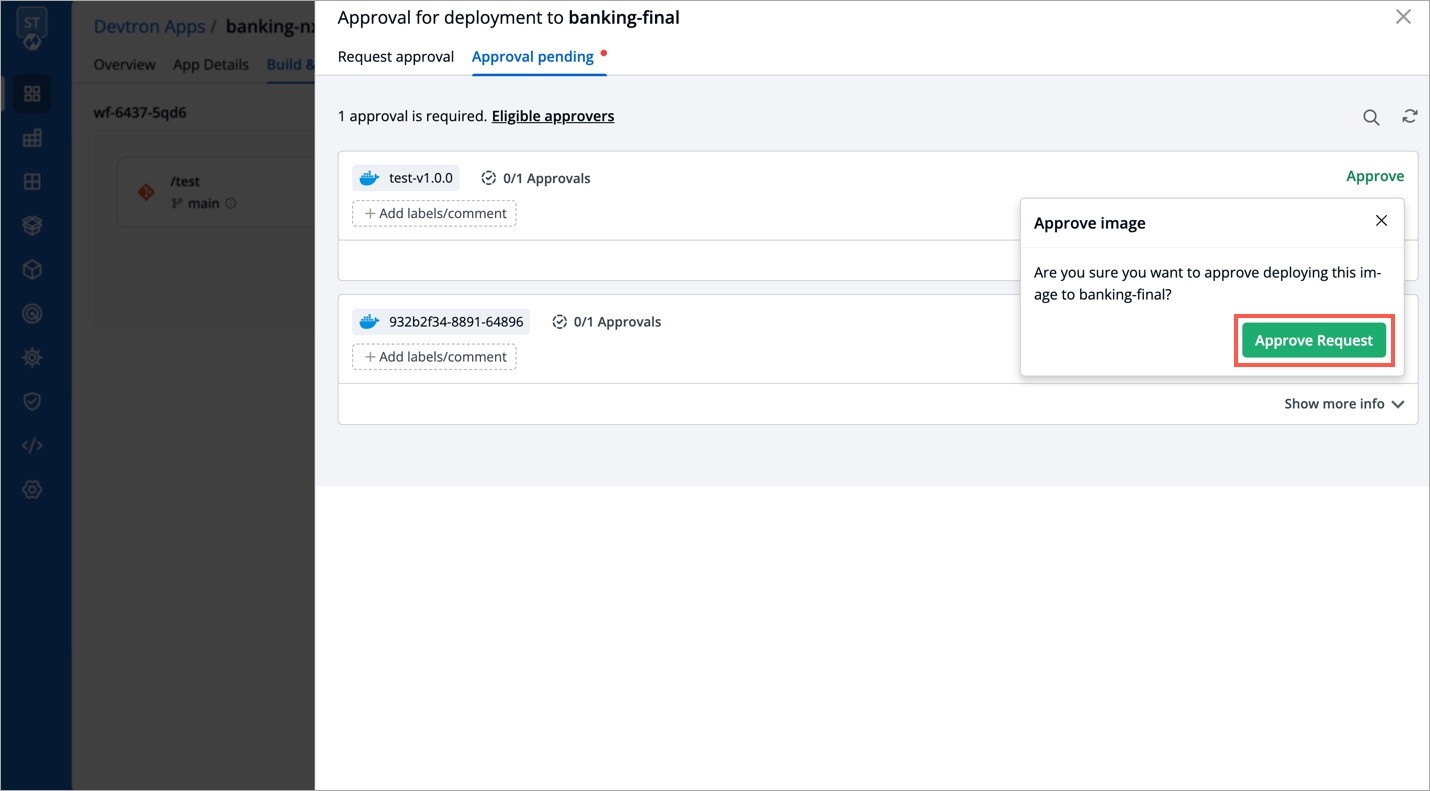
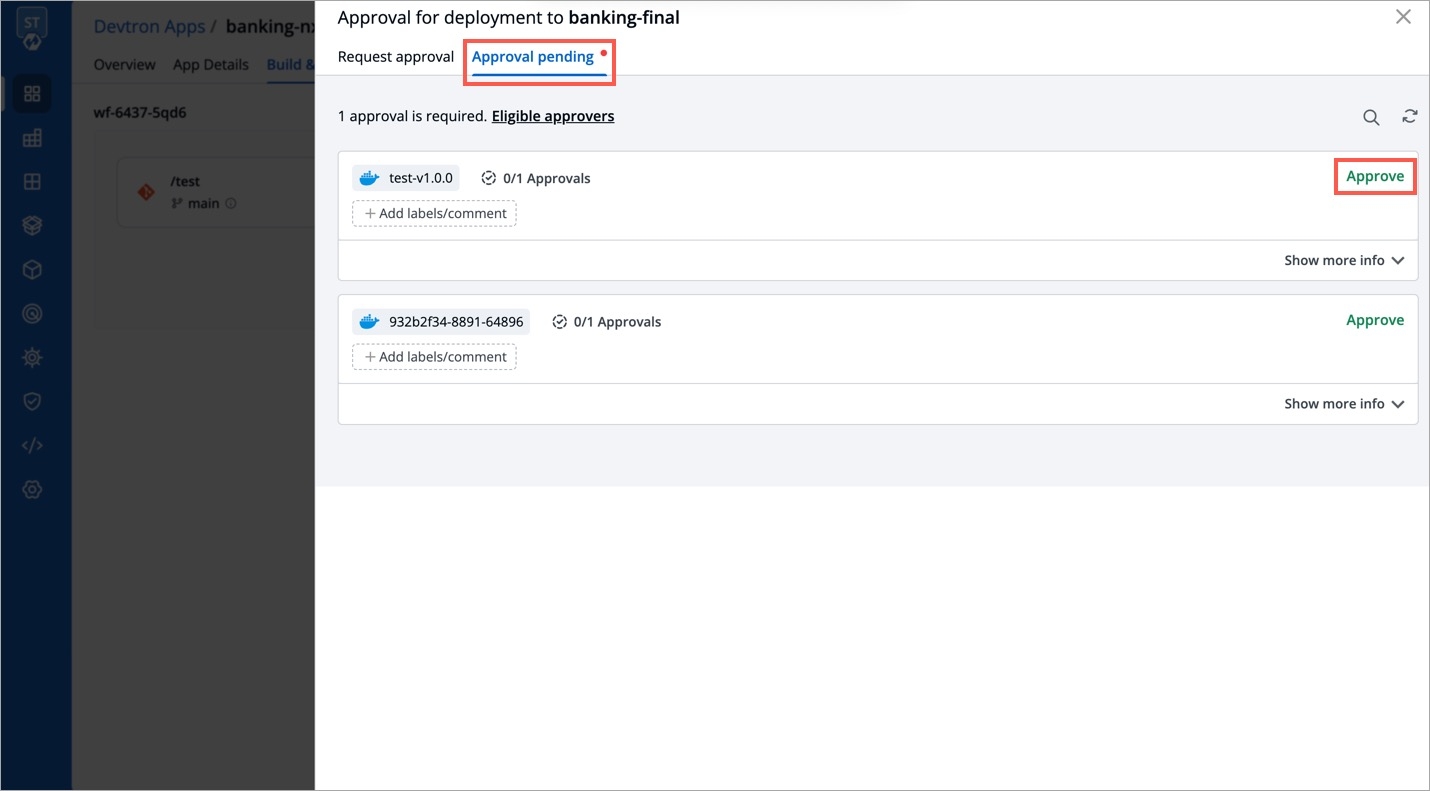
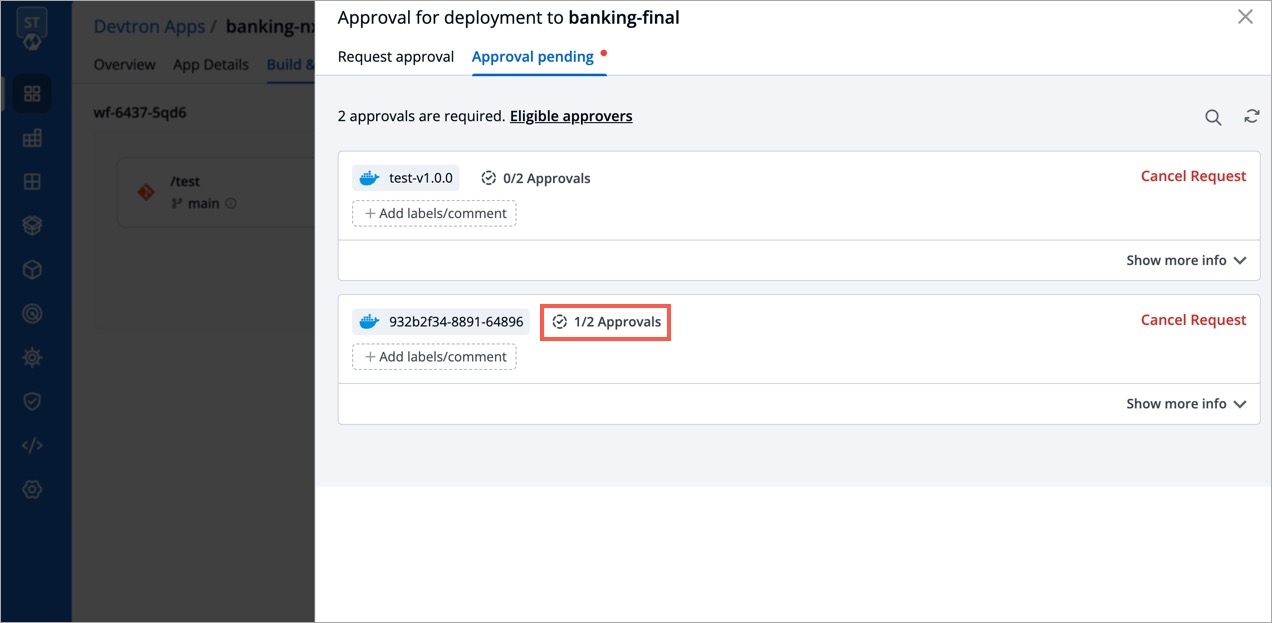
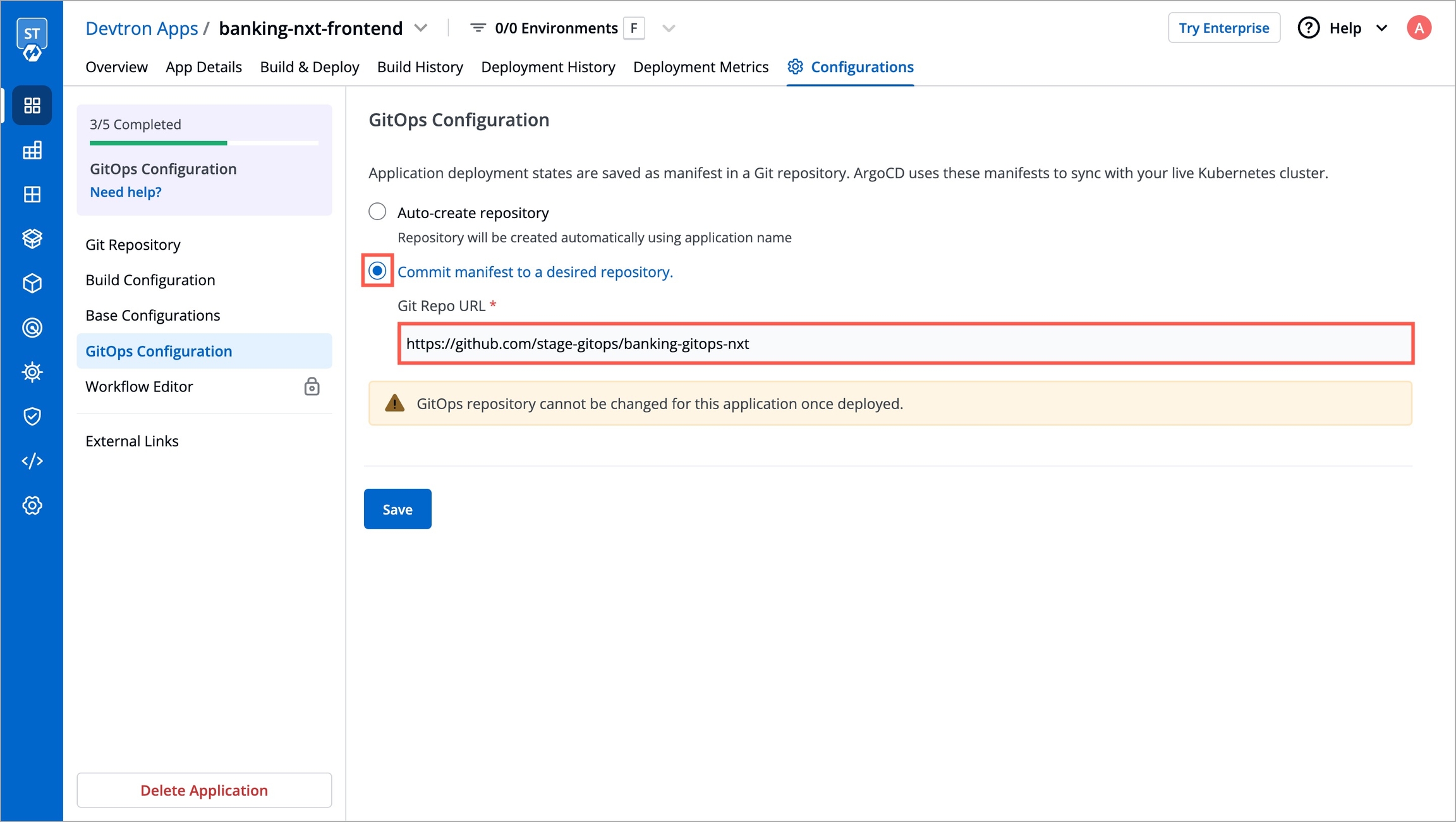
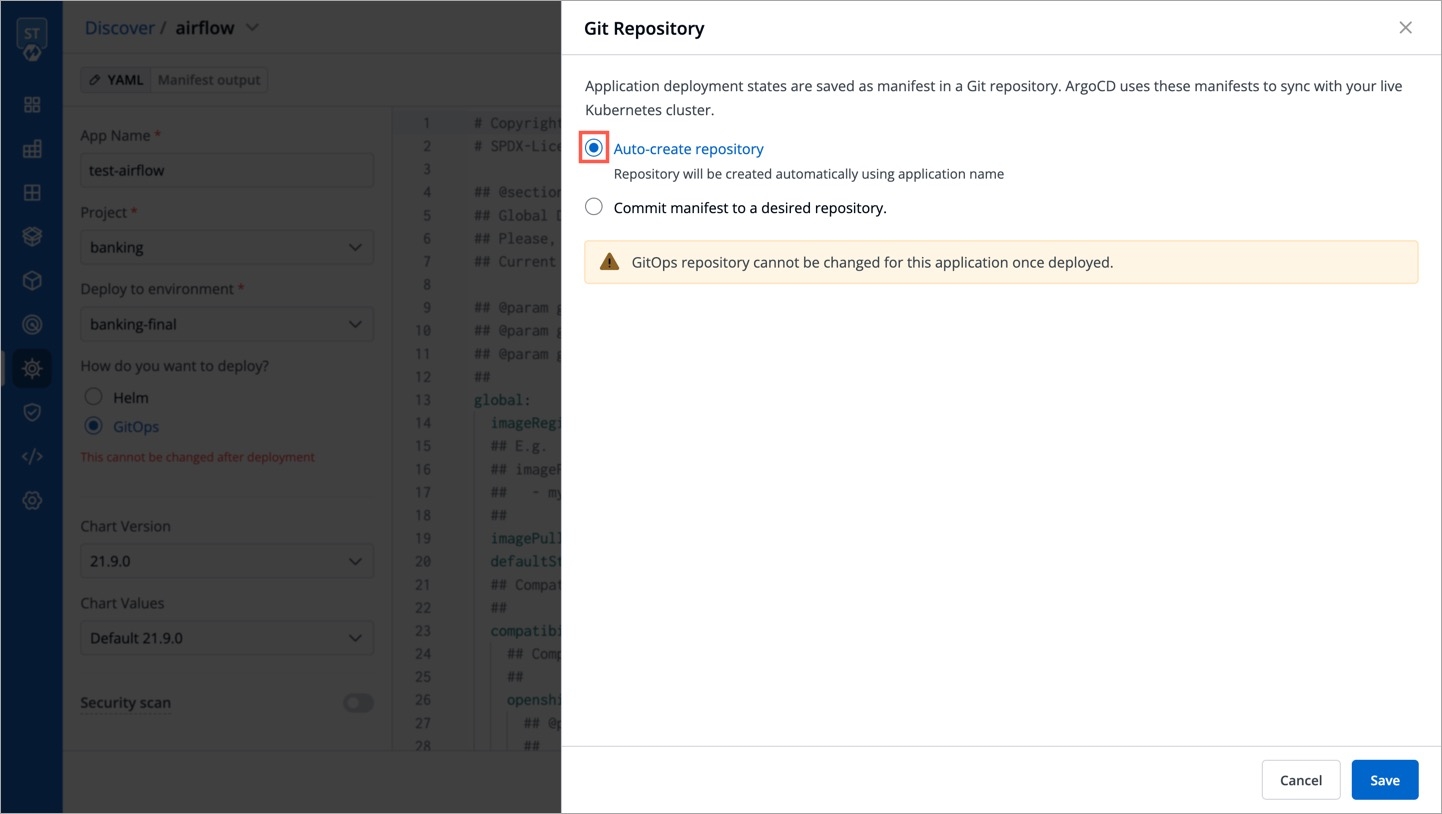
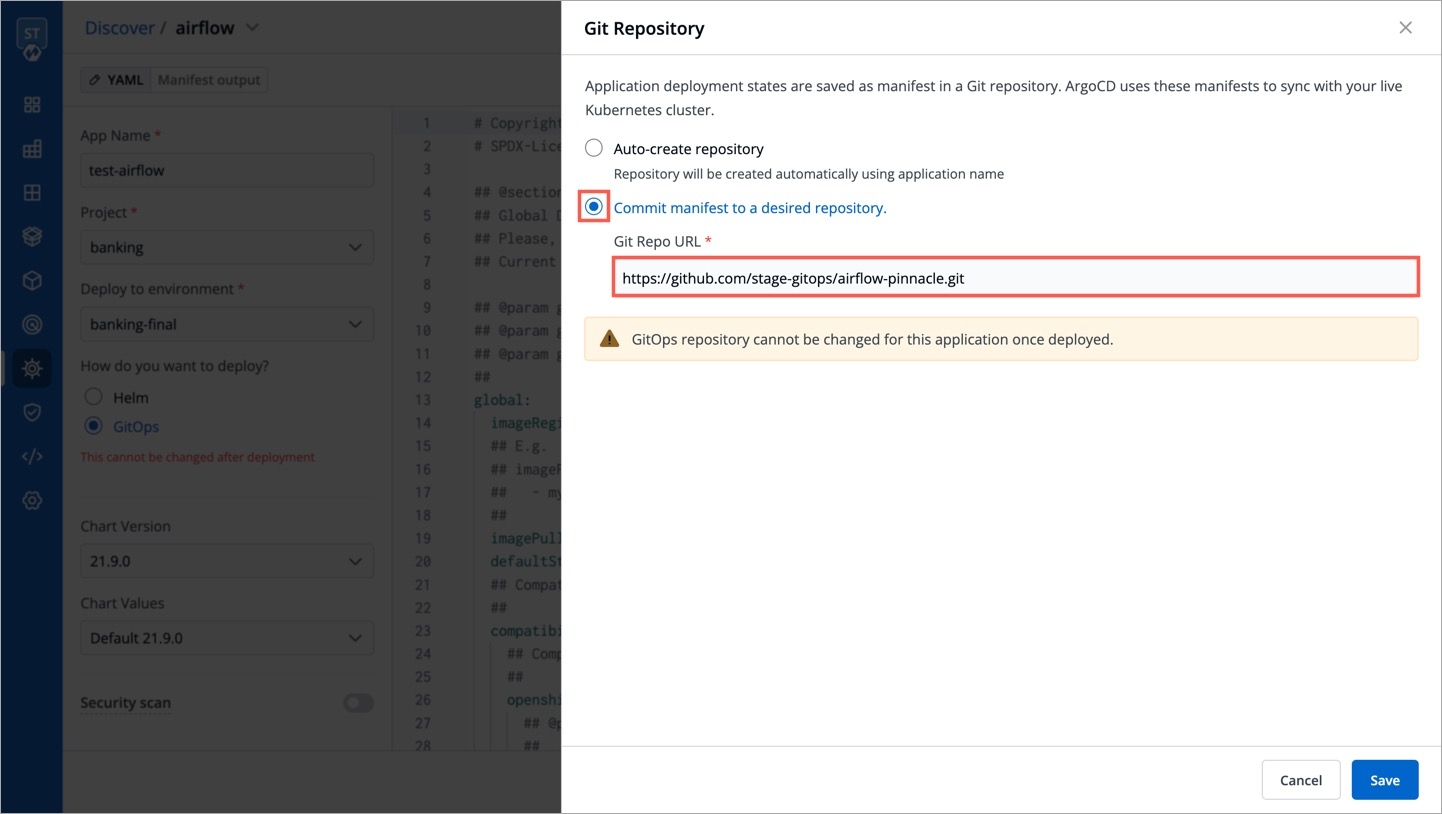
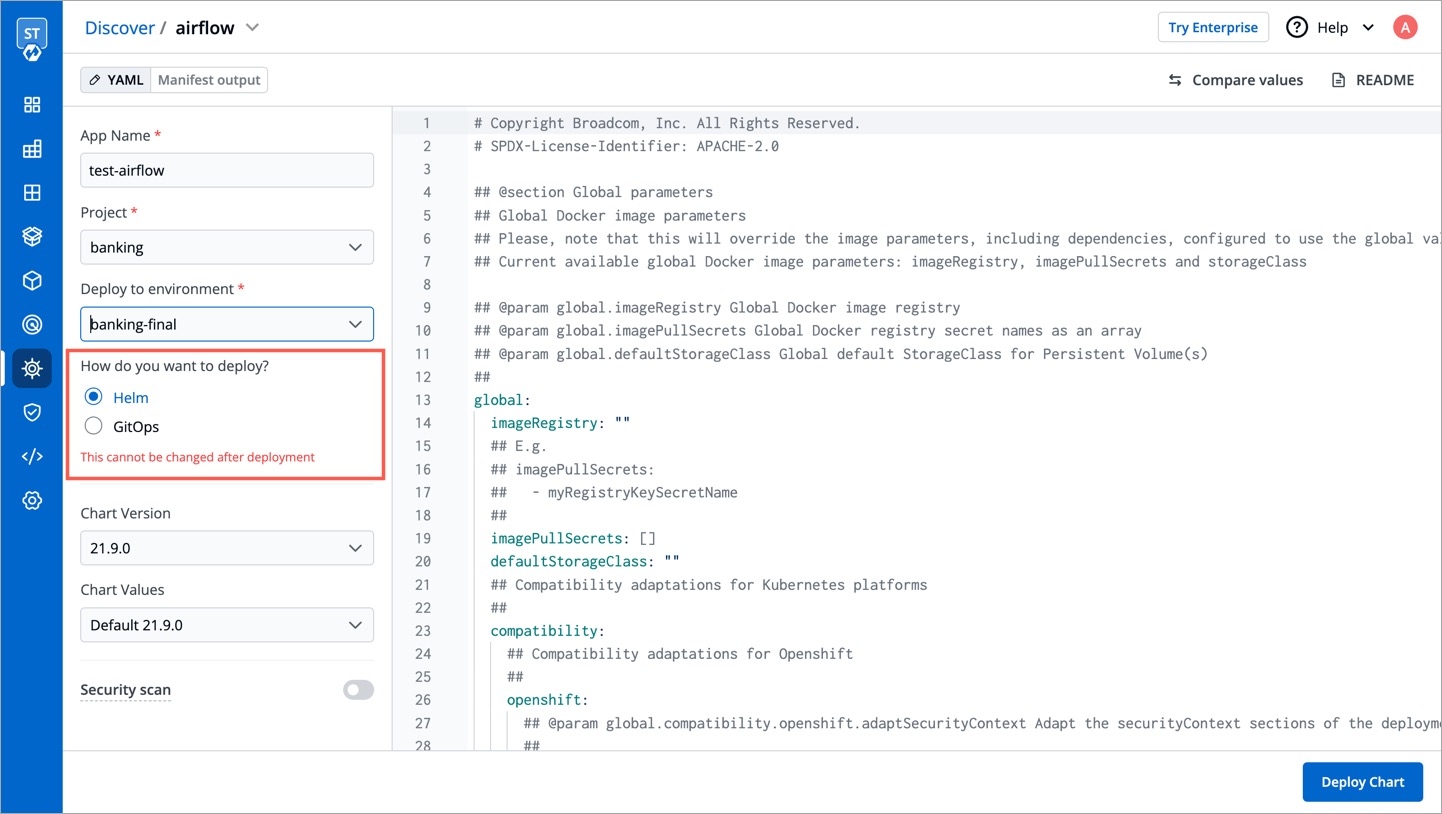
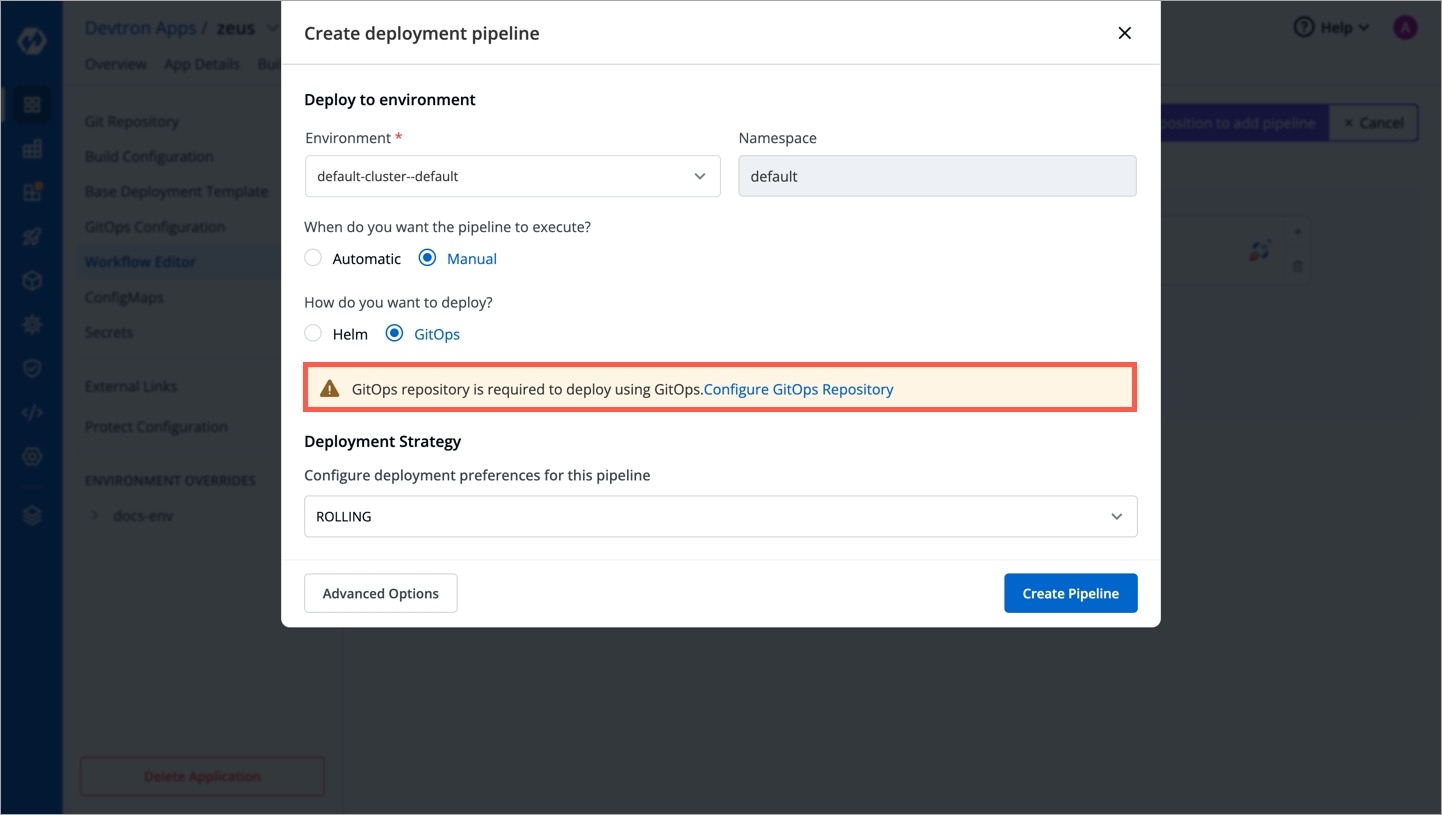
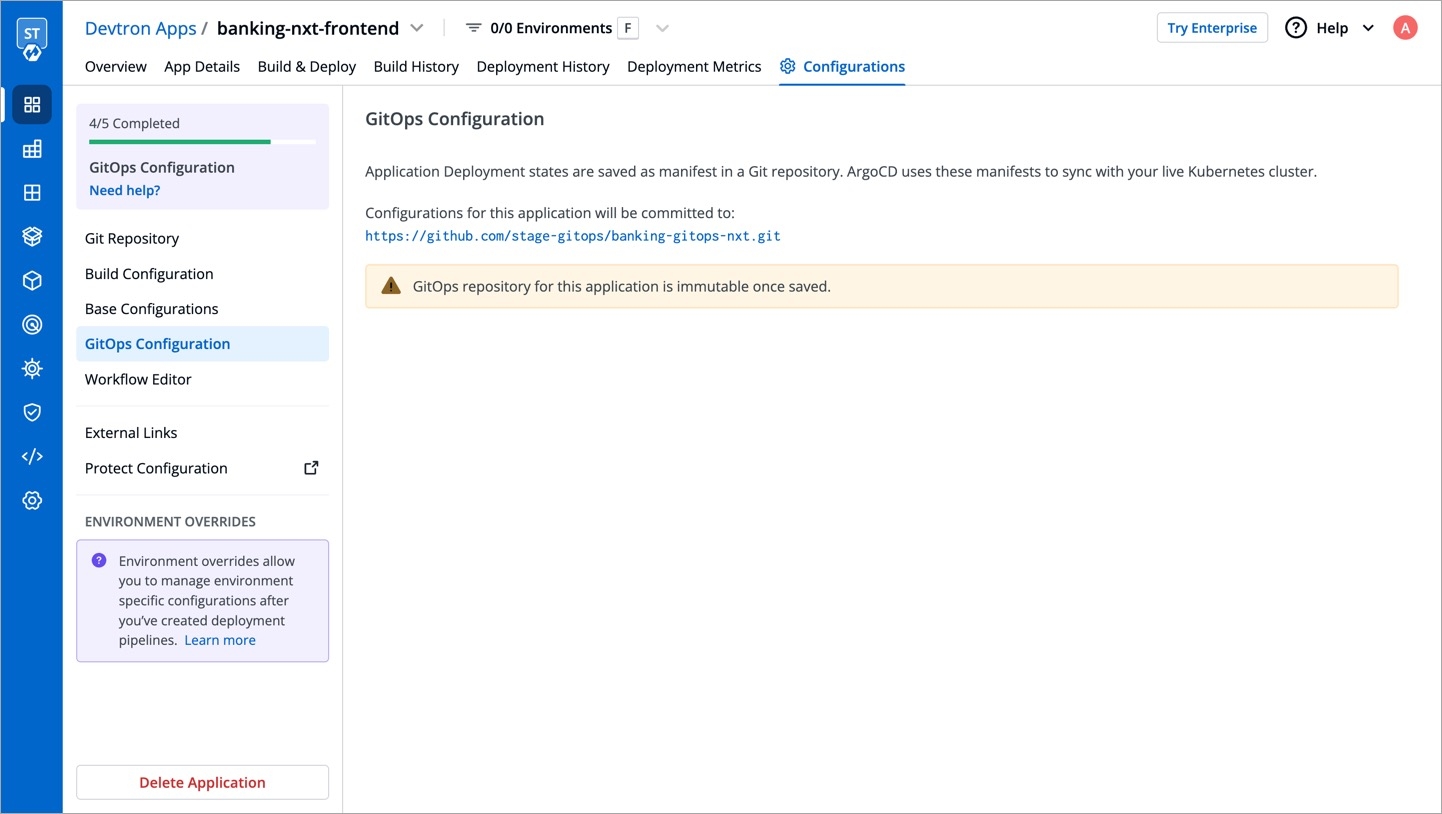
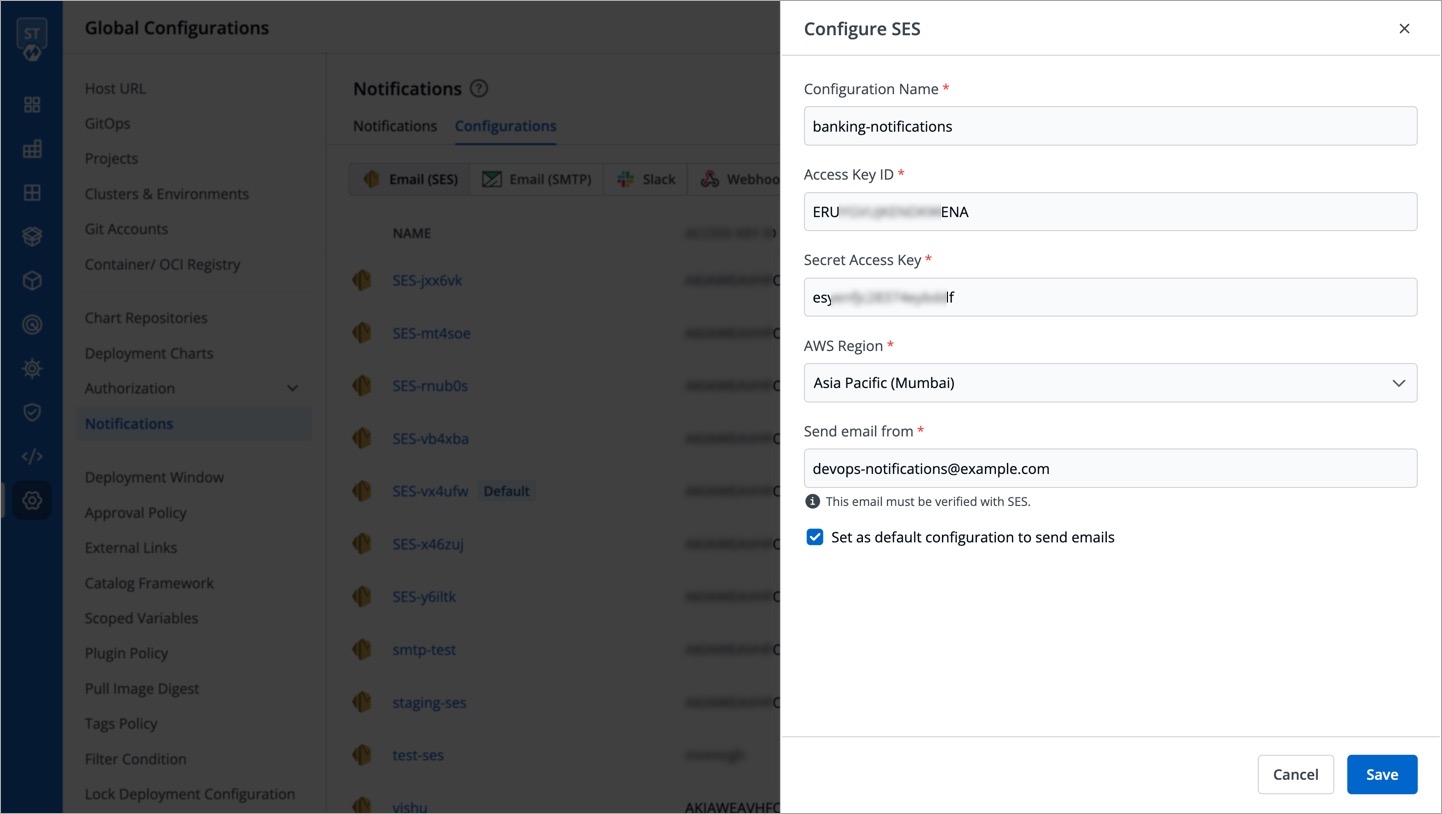
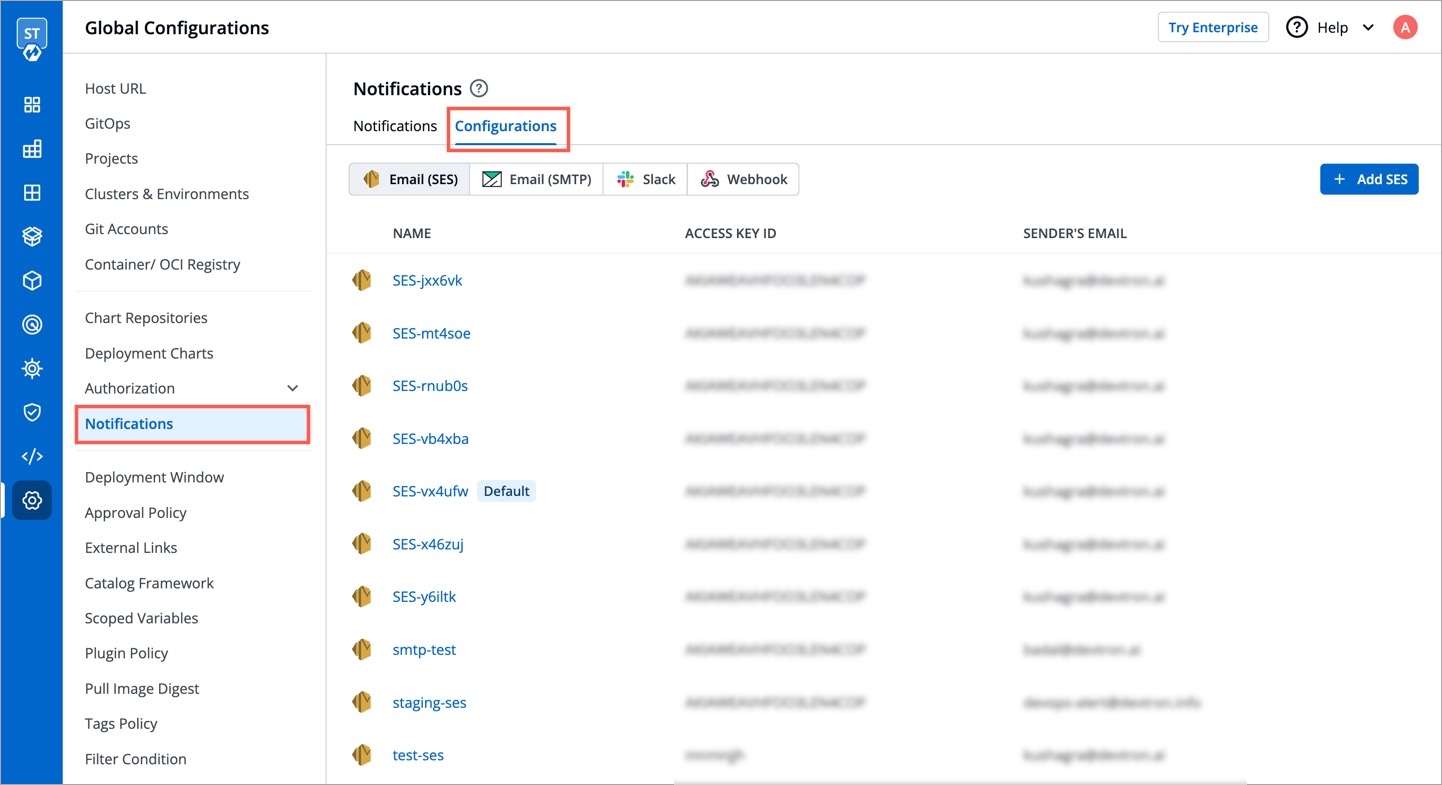
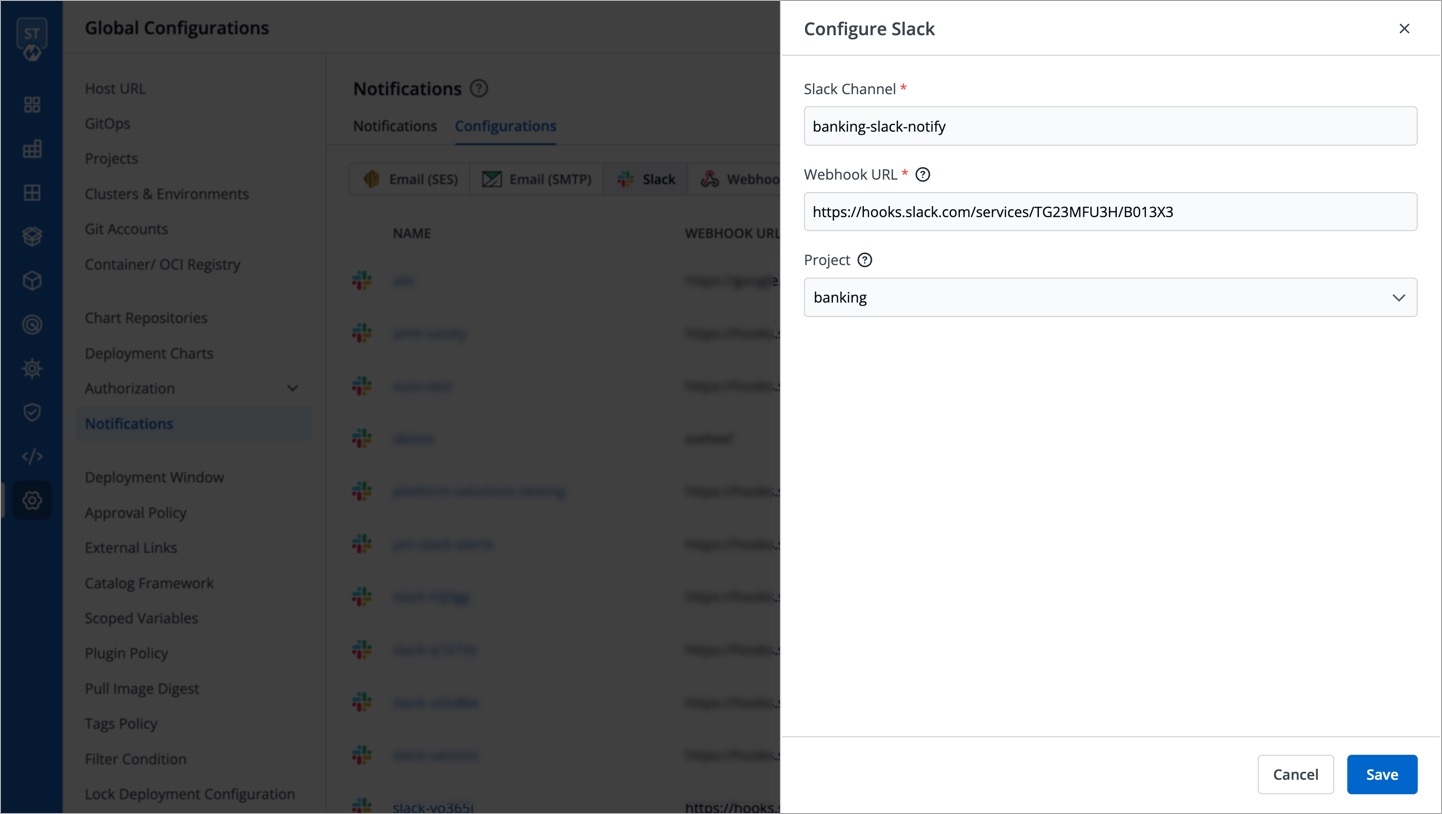
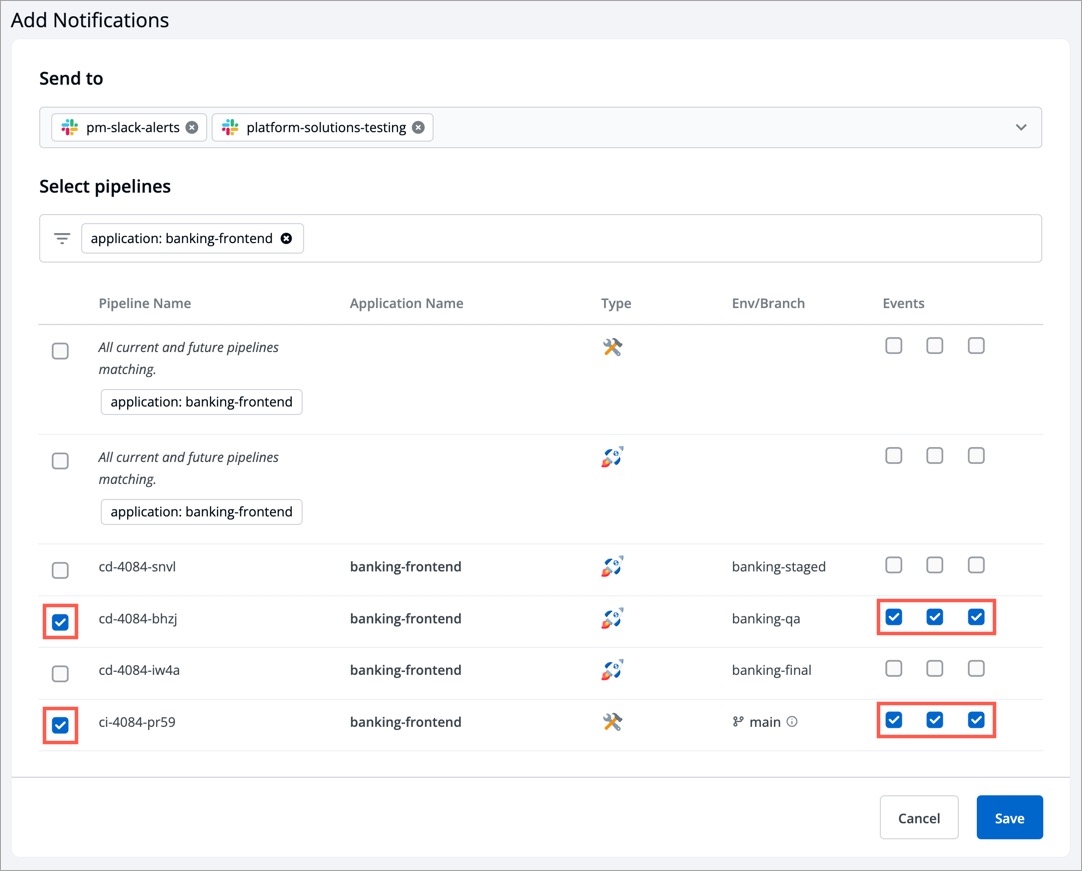
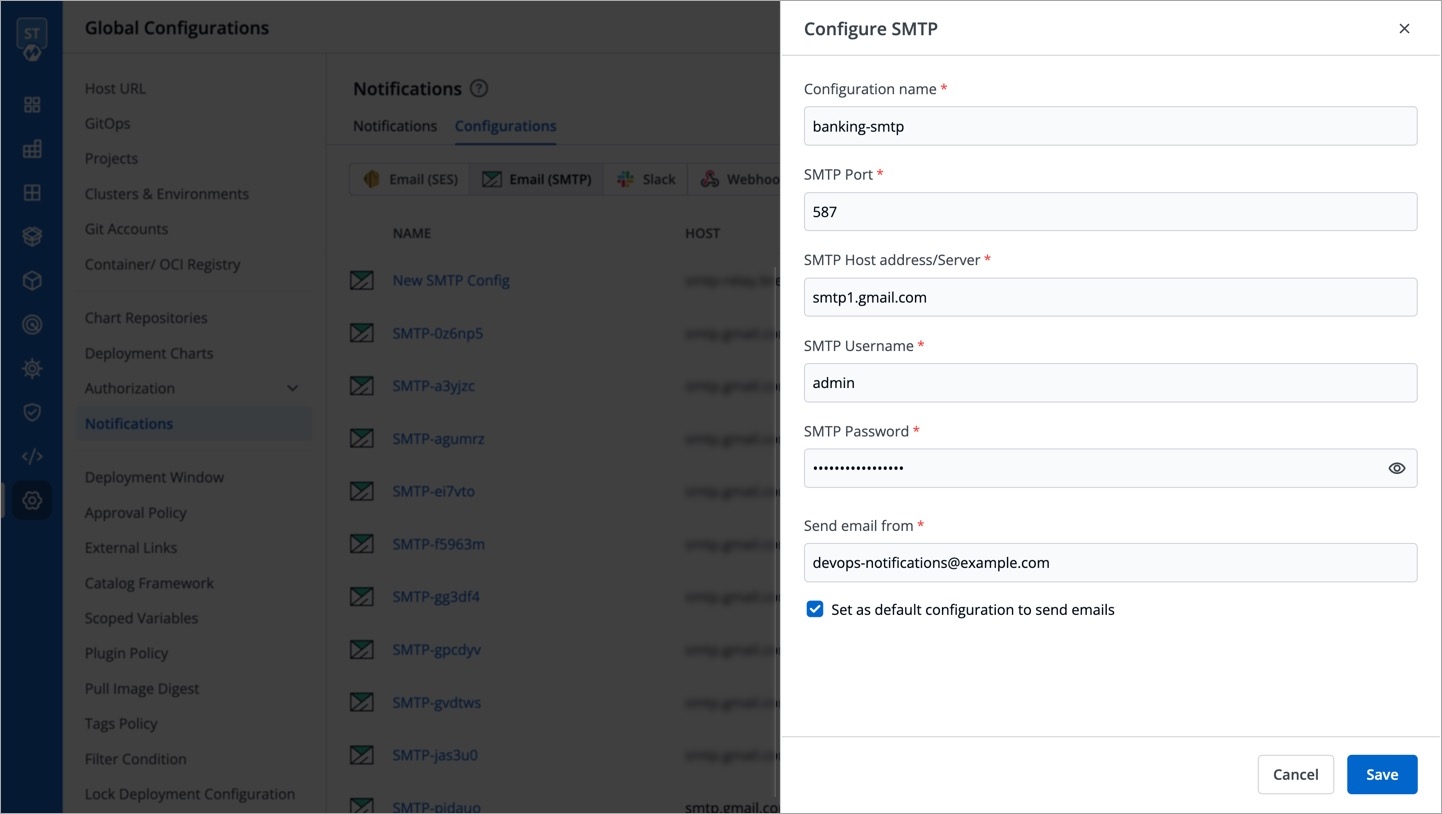
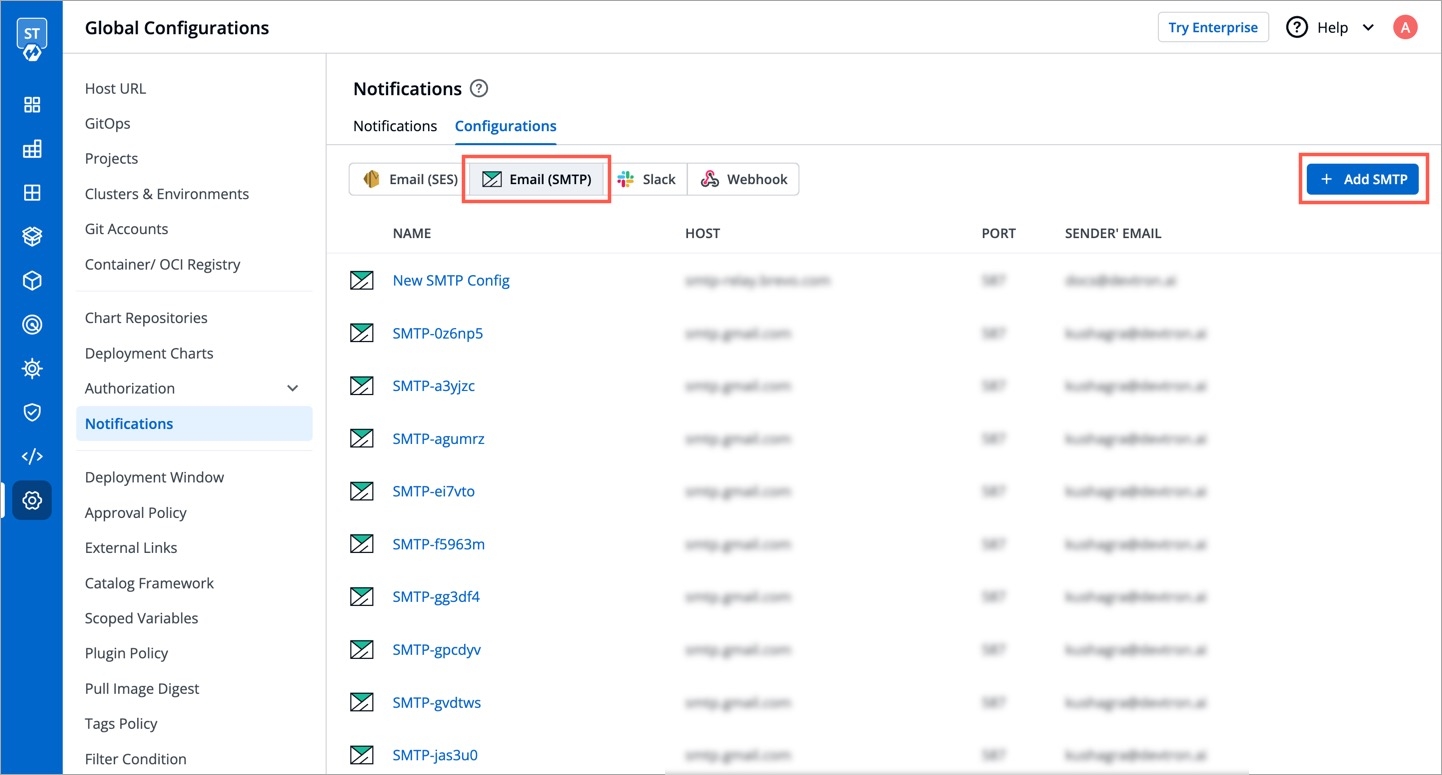
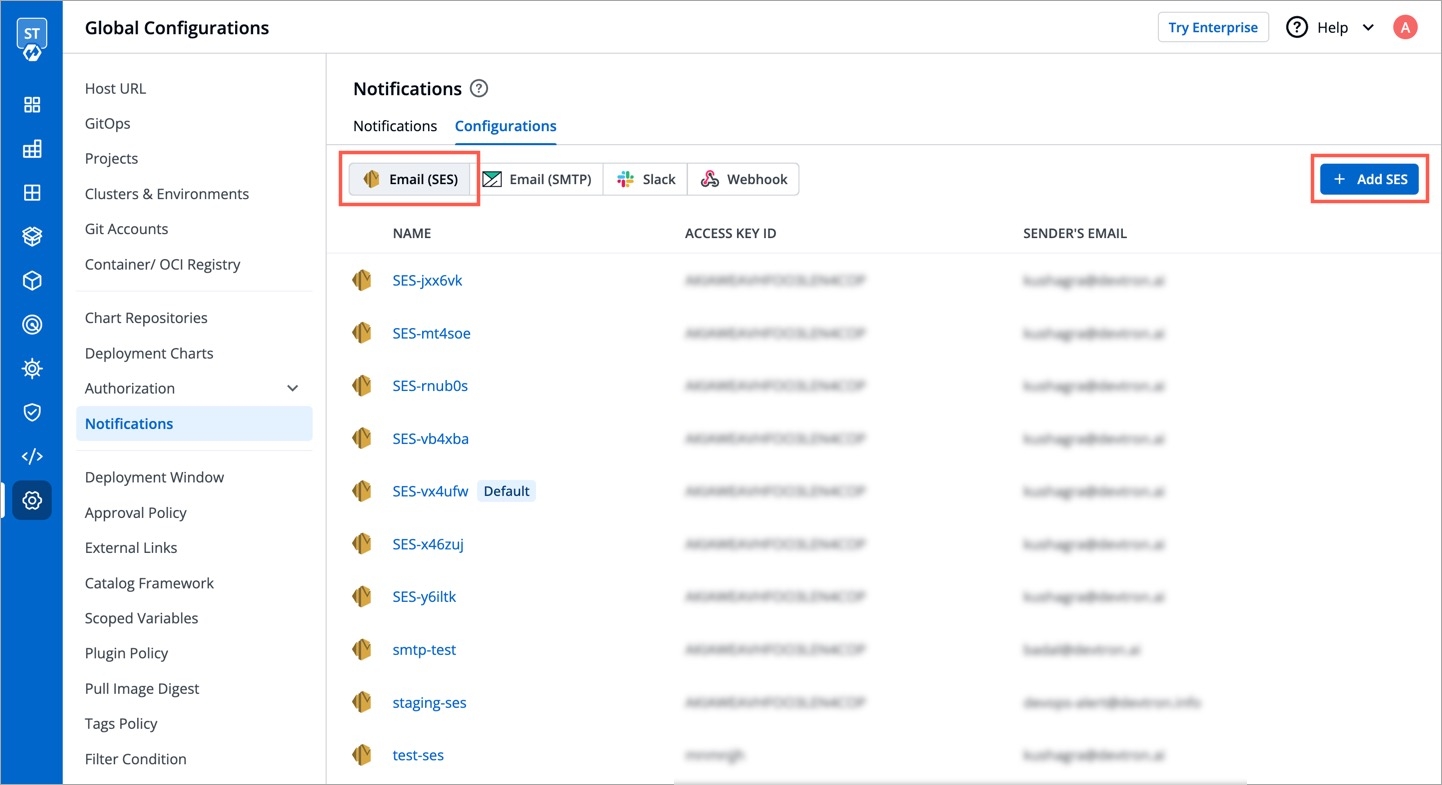
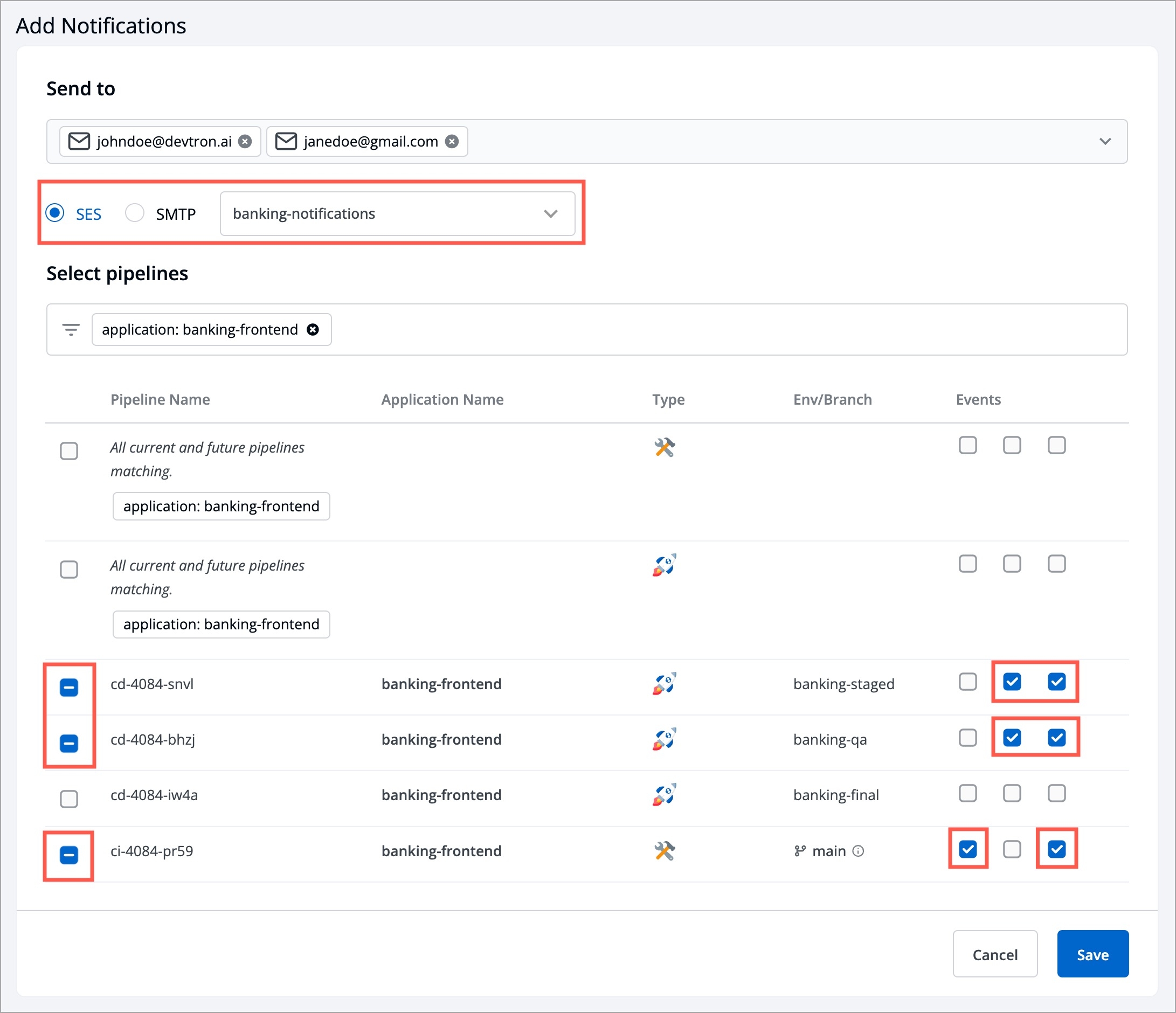
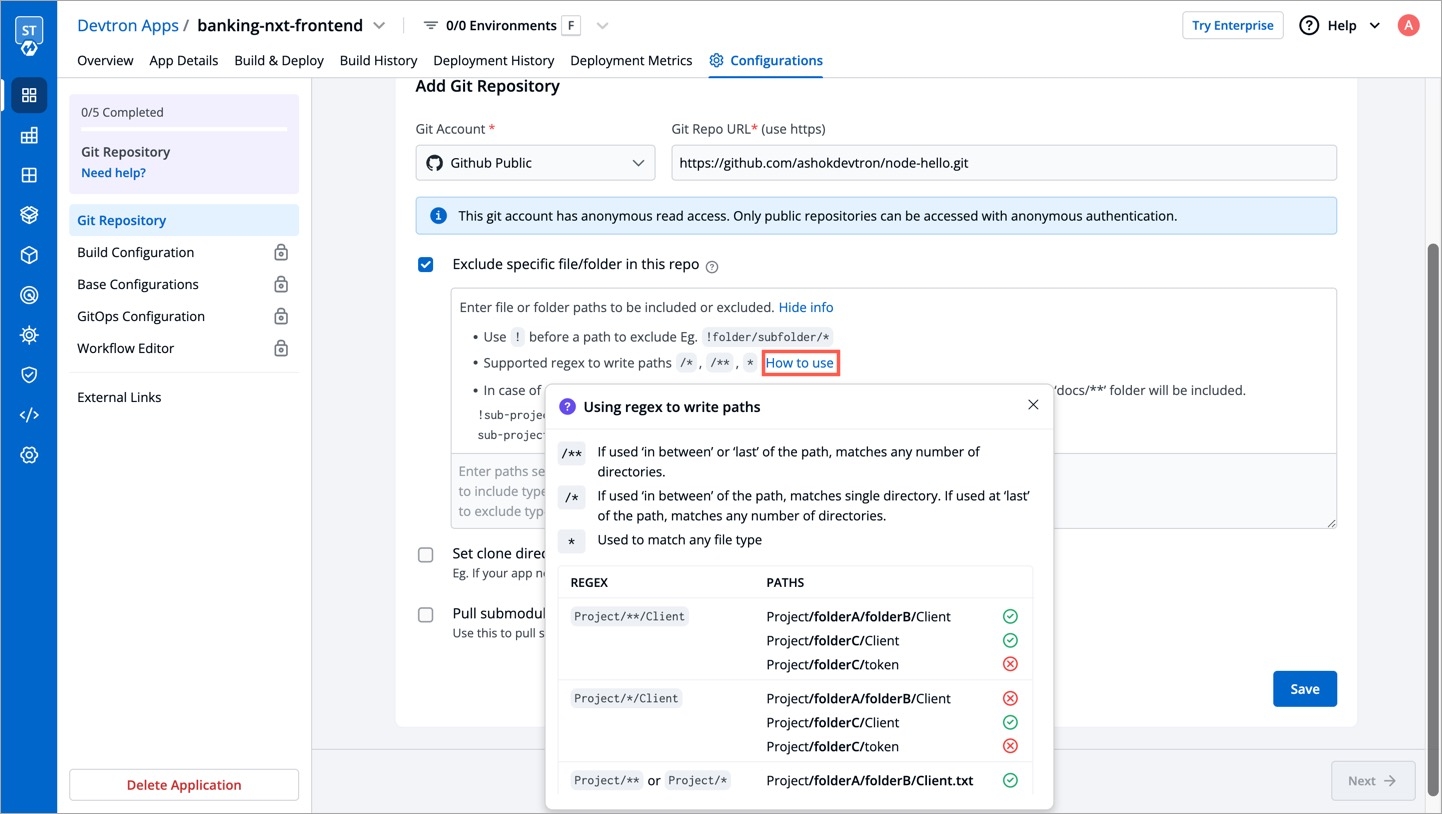
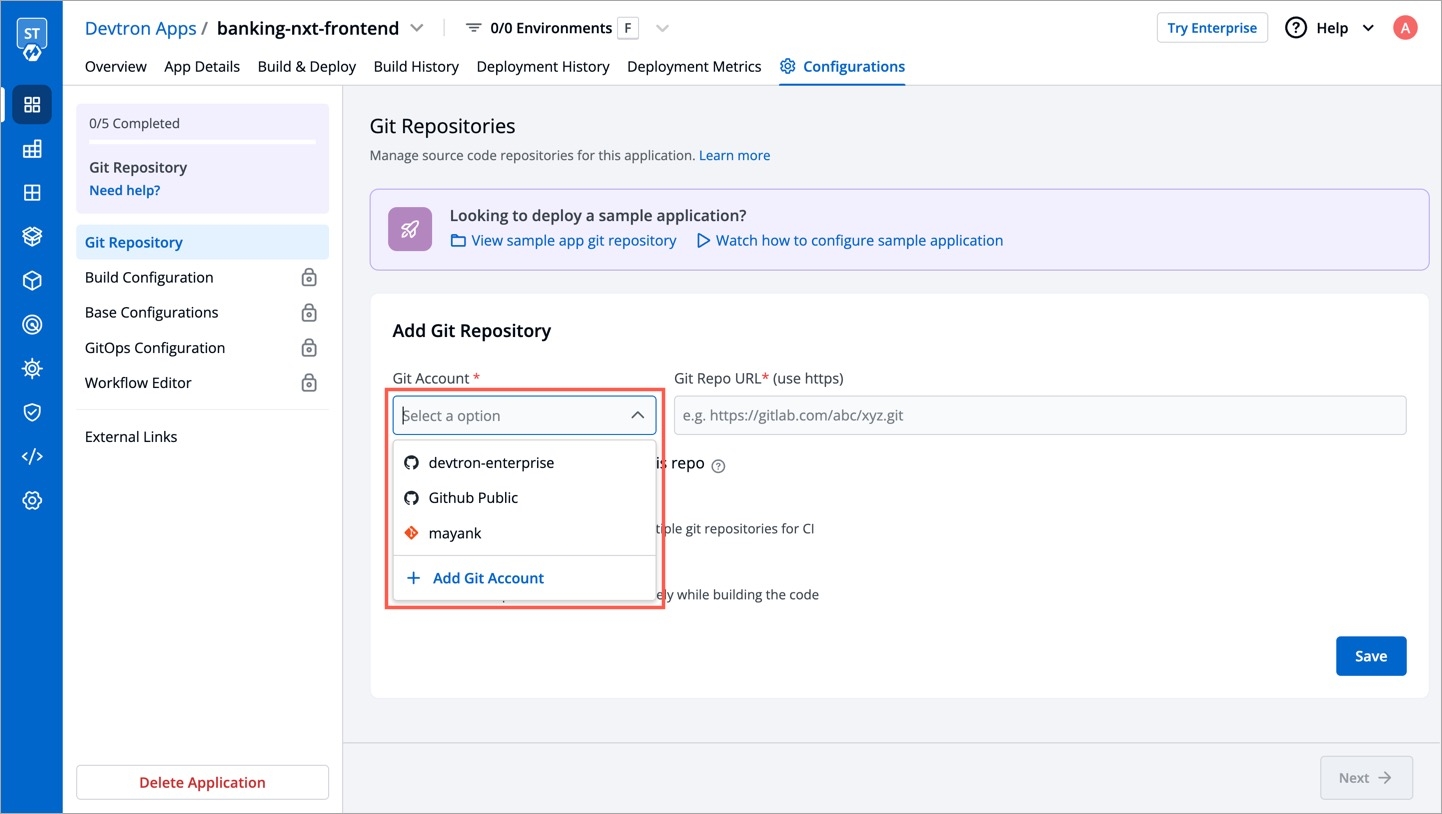
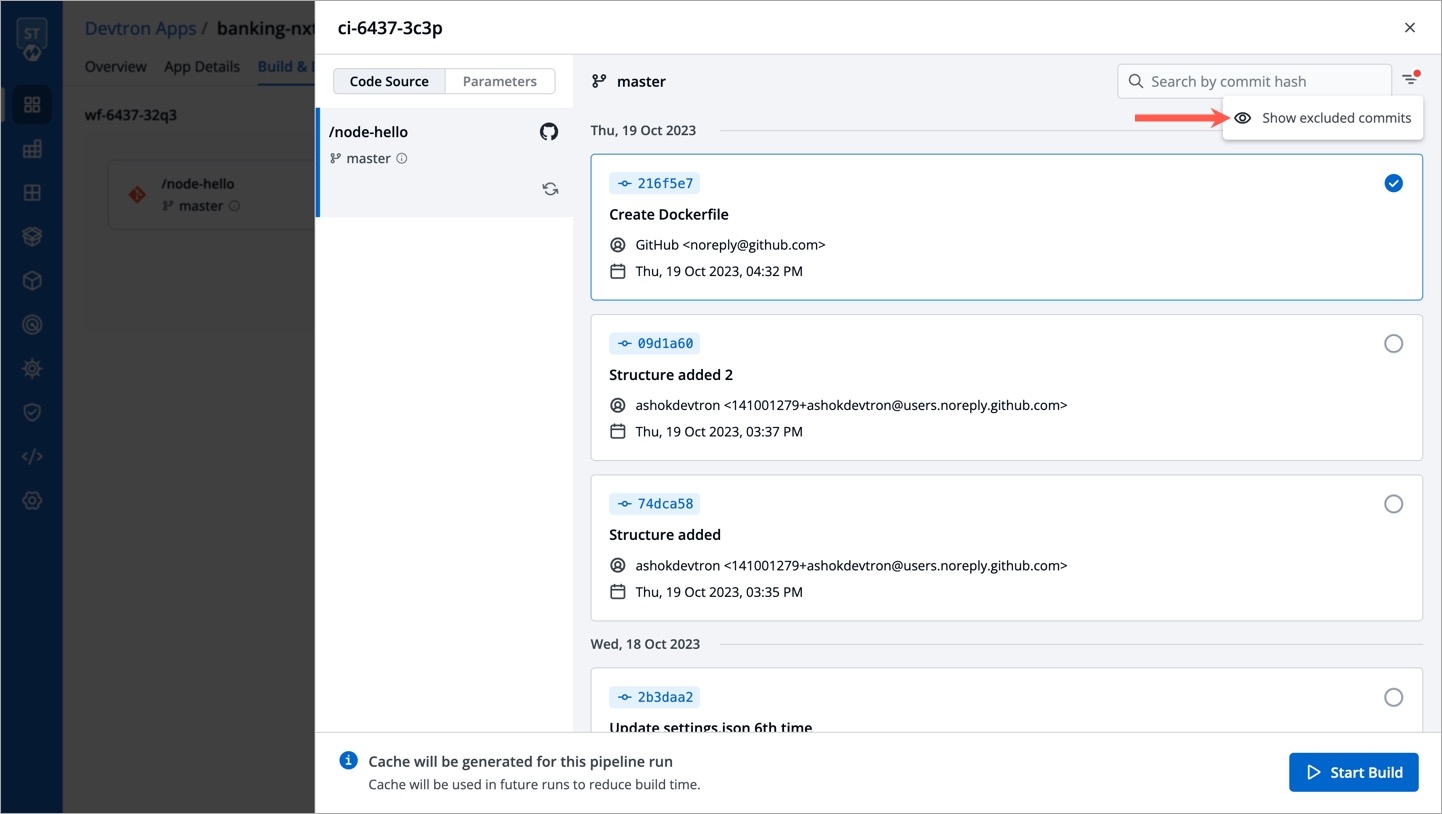
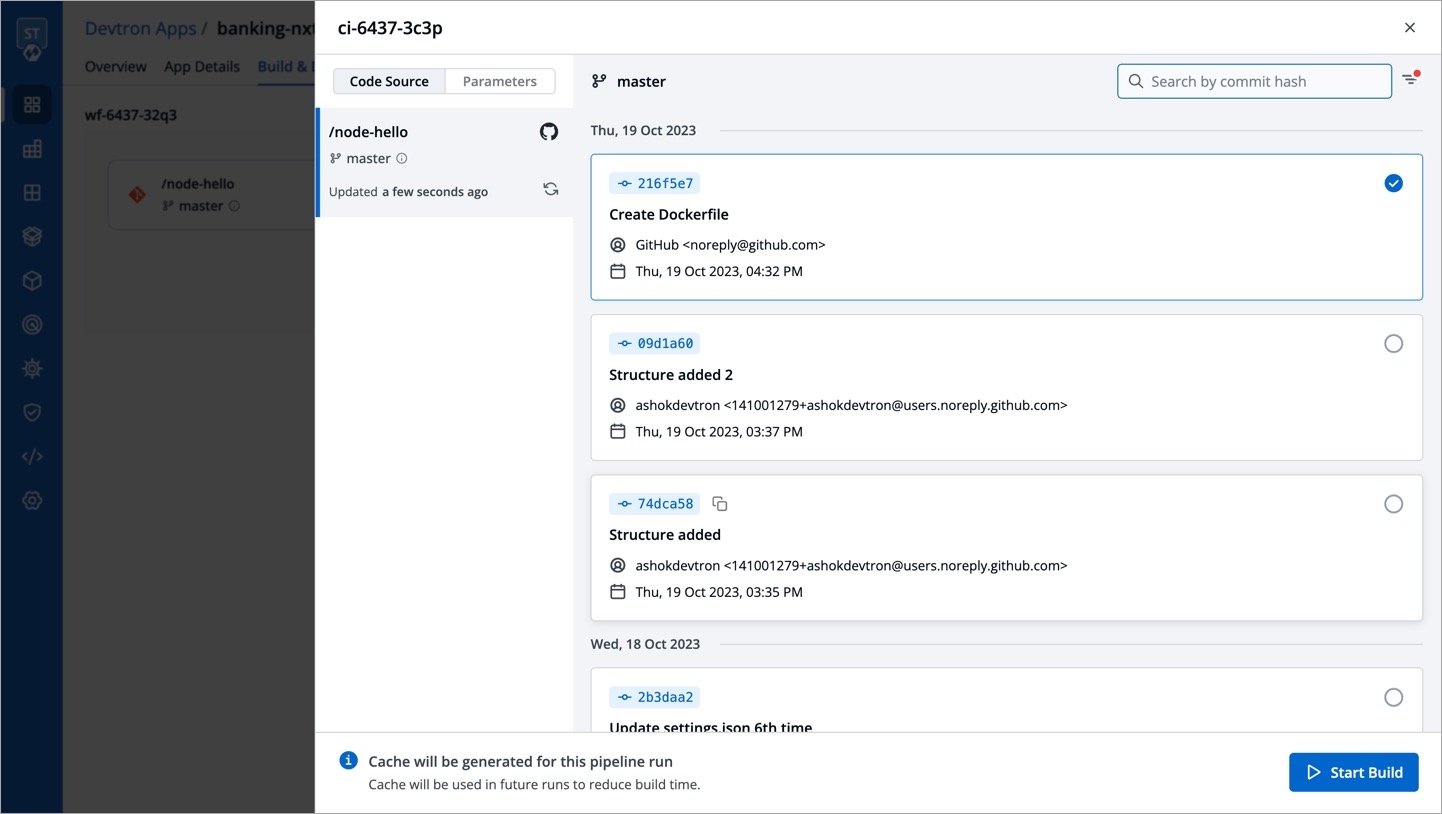
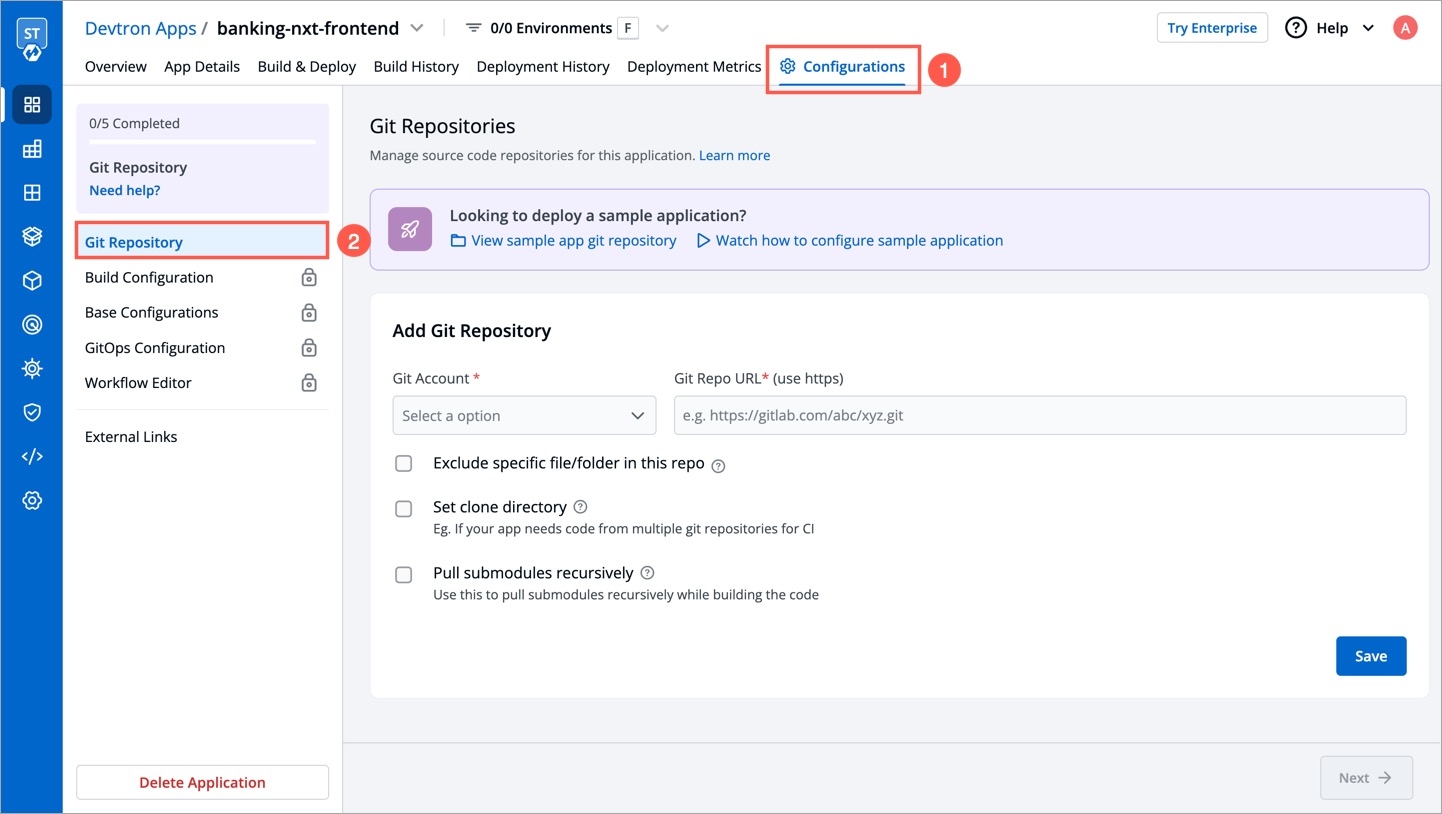
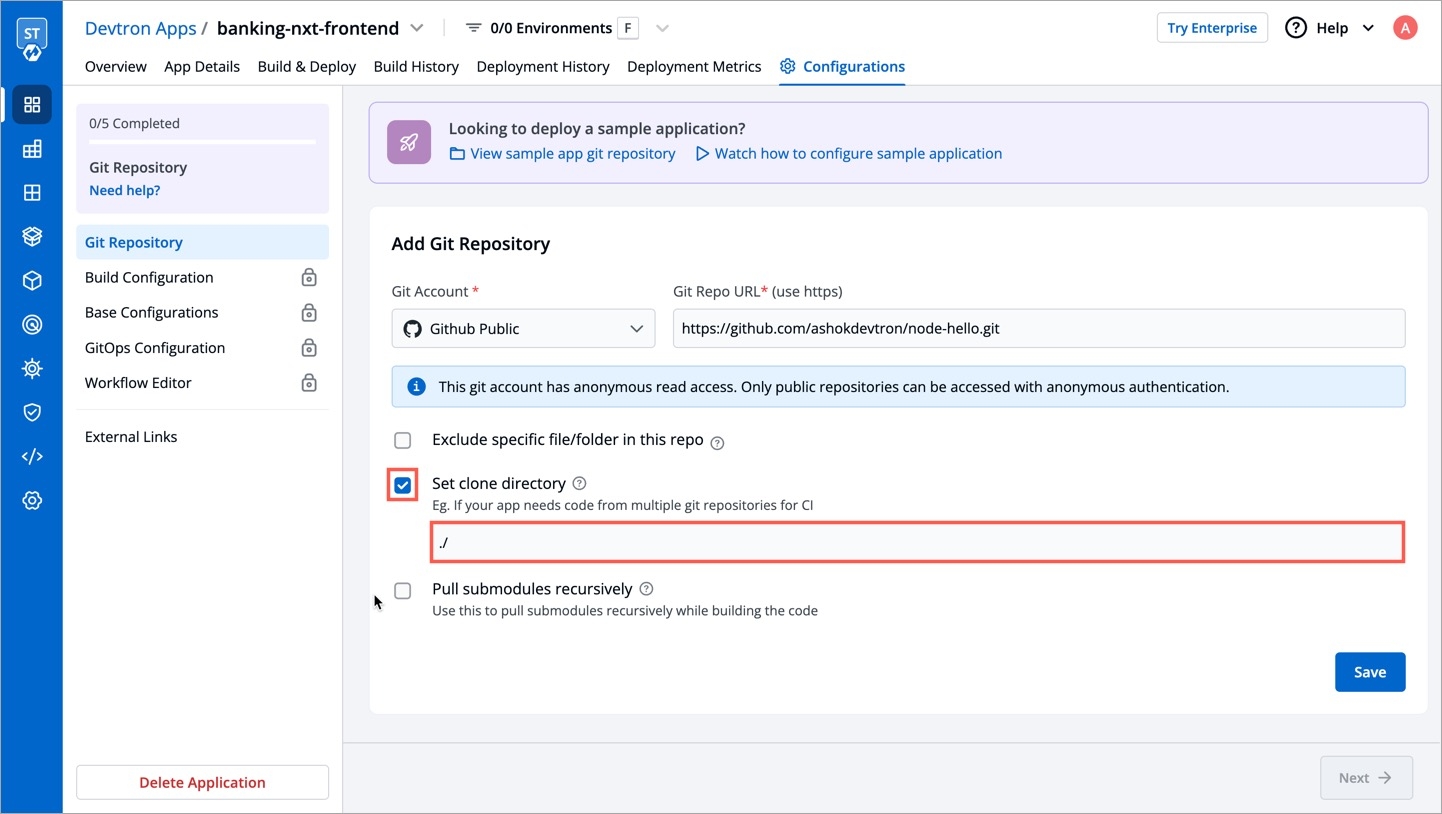
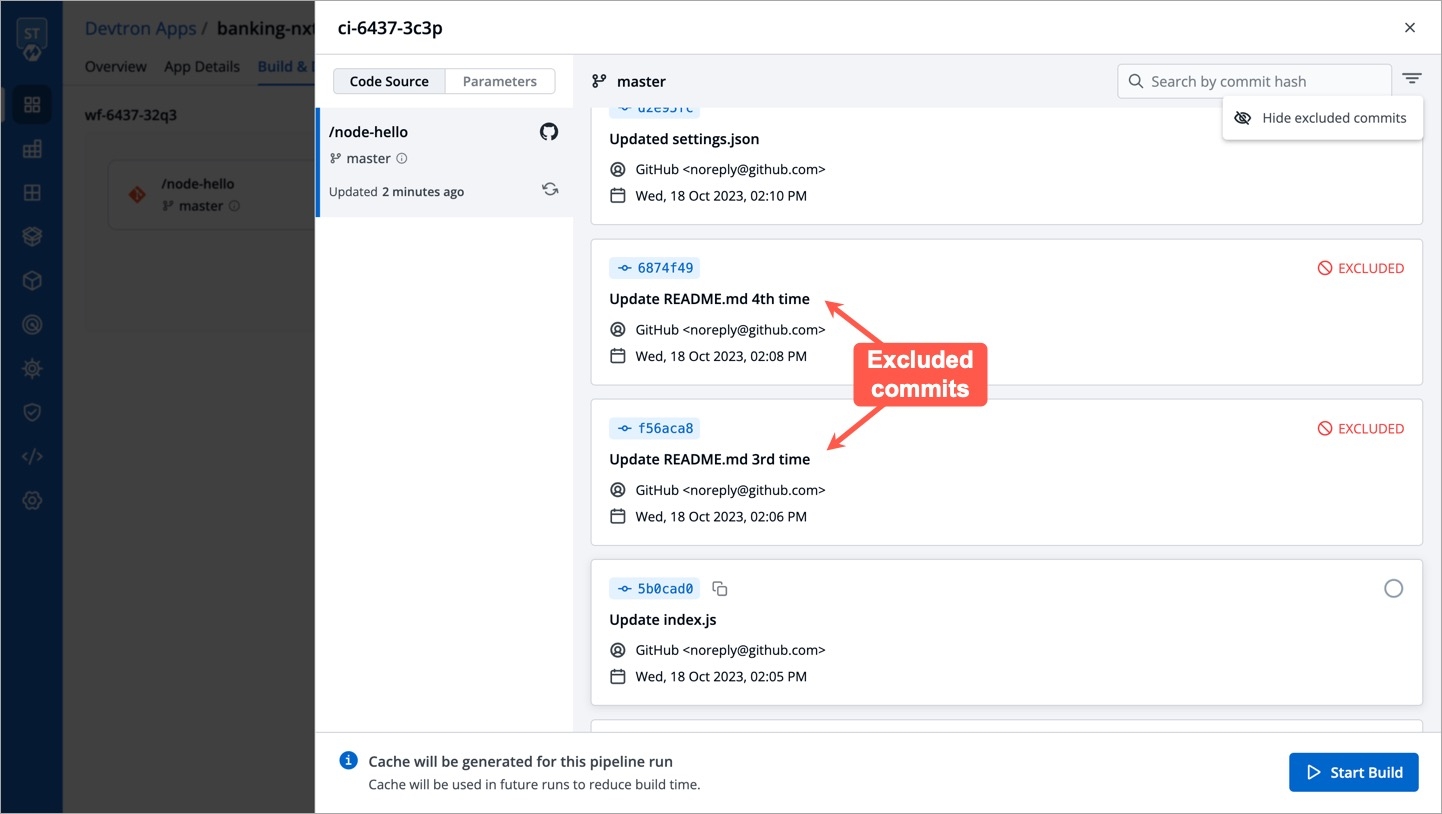
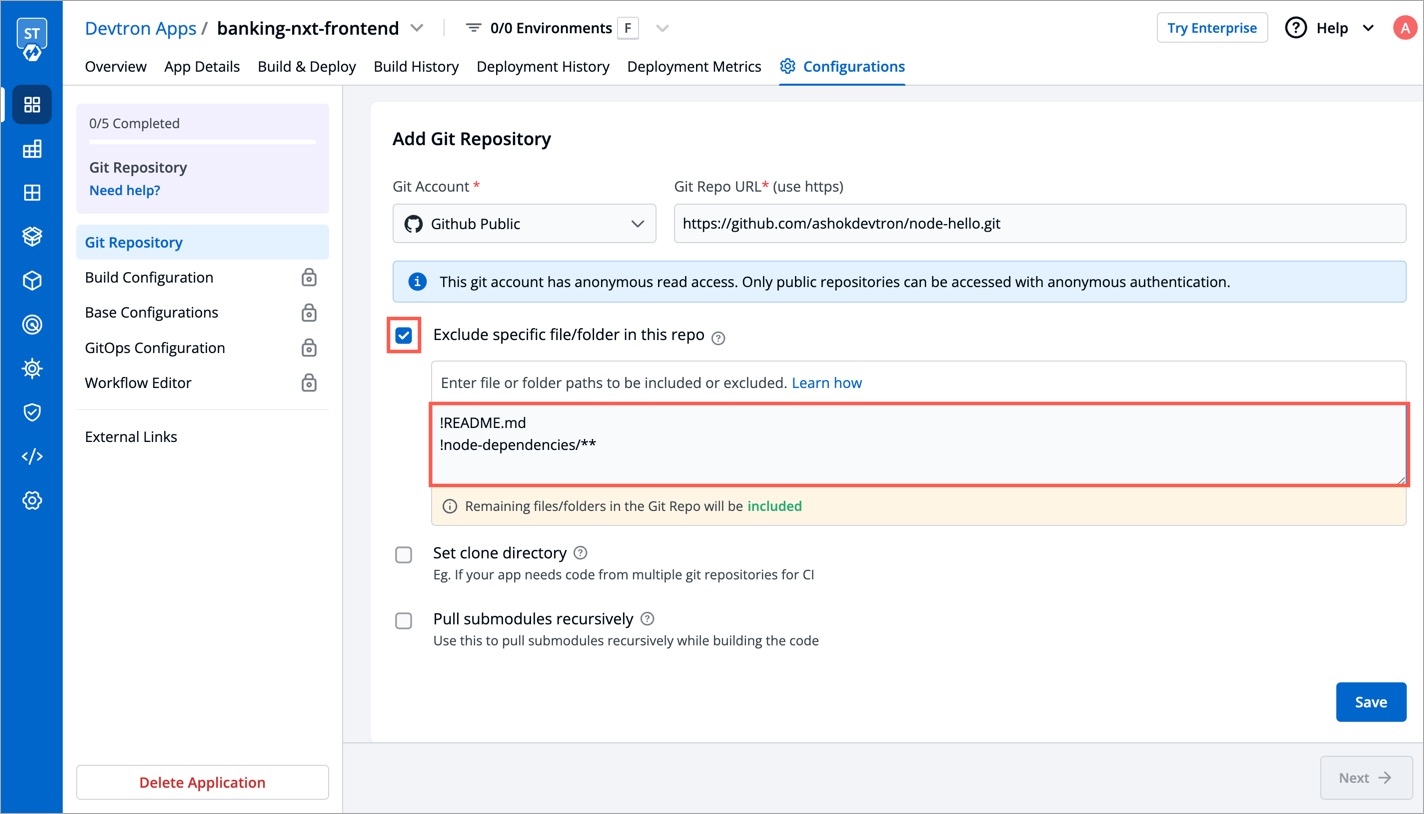
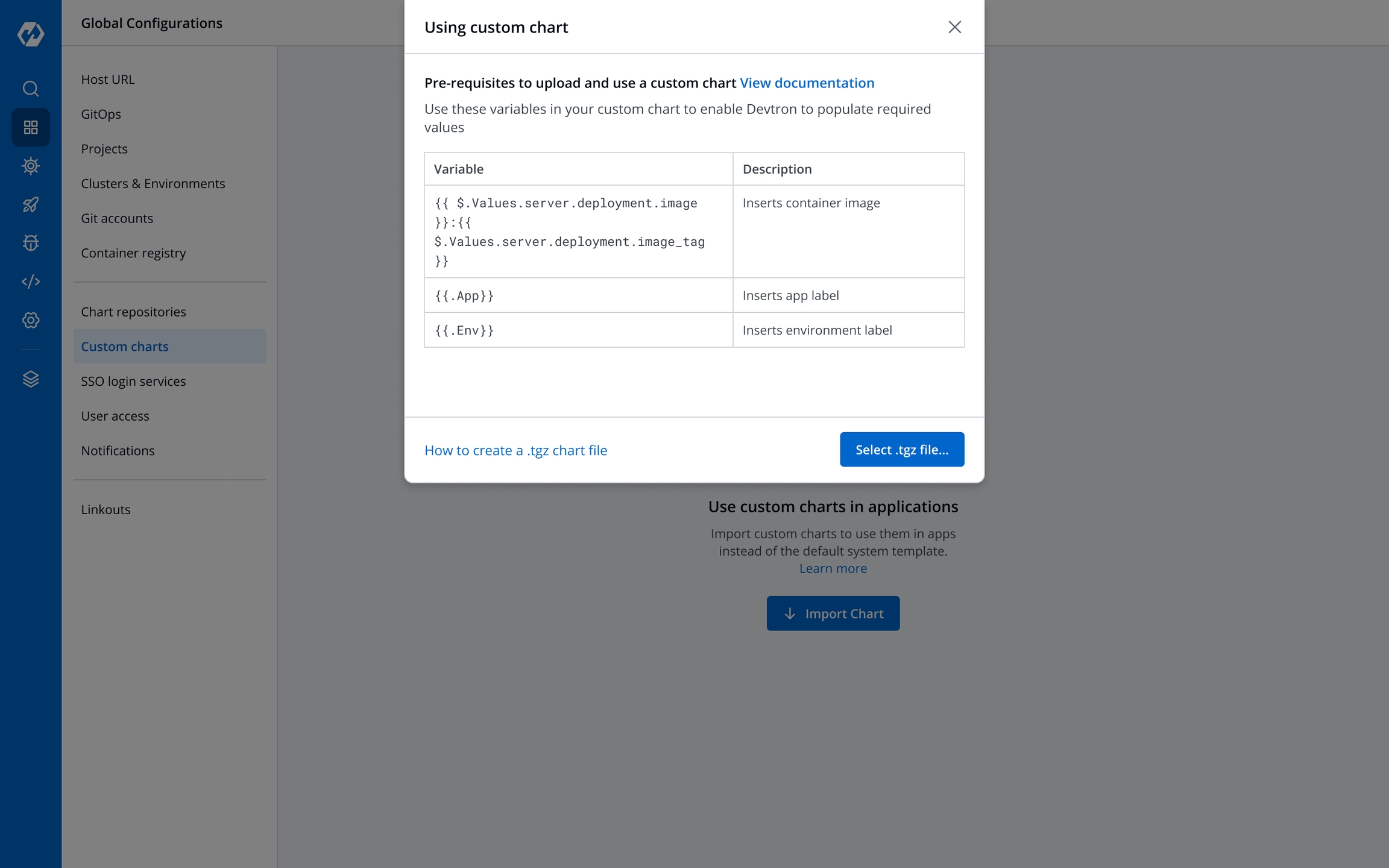
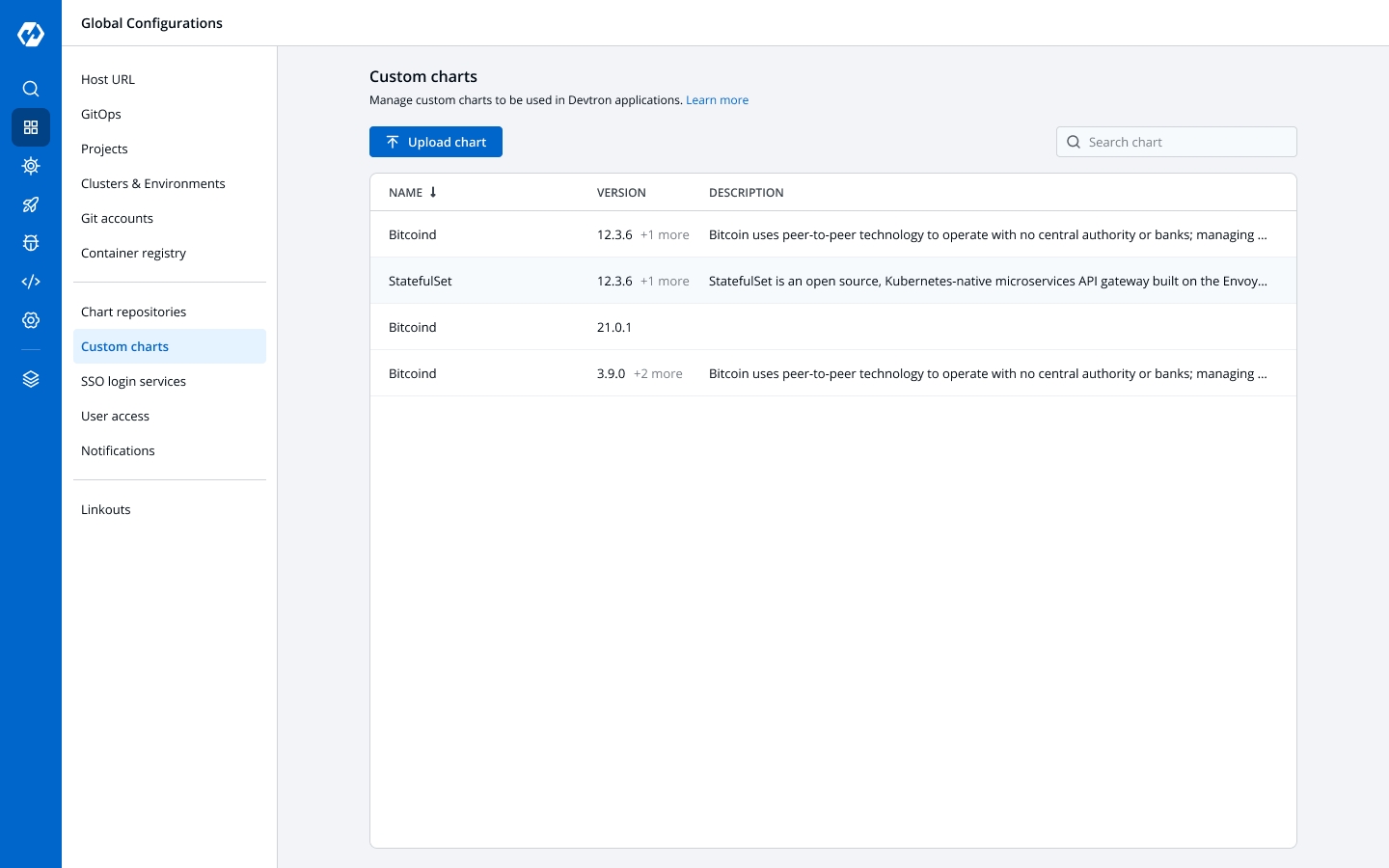

The CI pipeline includes Pre and Post-build steps to validate and introduce checkpoints in the build process. The pre/post plugins allow you to execute some standard tasks, such as Code analysis, Load testing, Security scanning etc. You can build custom pre-build/post-build tasks or select one of the standard preset plugins provided by Devtron.
Preset plugin is an API resource which you can add within the CI build environment. By integrating the preset plugin in your application, it helps your development cycle to keep track of finding bugs, code duplication, code complexity, load testing, security scanning etc. You can analyze your code easily.
Devtron CI pipeline includes the following build stages:
Pre-Build Stage: The tasks in this stage run before the image is built.
Build Stage: In this stage, the build is triggered from the source code (container image) that you provide.
Post-Build Stage: The tasks in this stage are triggered once the build is complete.
Make sure you have CI build pipeline before you start configuring Pre-Build or Post-Build tasks.
Each Pre/Post-build stage is executed as a series of events called tasks and includes custom scripts. You can create one or more tasks that are dependent on one another for execution. In other words, the output variable of one task can be used as an input for the next task to build a CI runner. The tasks will run following the execution order.
The tasks can be re-arranged by drag-and-drop; however, the order of passing the variables must be followed.
You can create a task either by selecting one of the available preset plugins or by creating a custom script.
Pre-Build/Post-Build
Create a task using one of the integrated in Devtron:
Create a task from which you can customize your script with:
Or,
Lets take Codacy as an example and configure it in the Pre-Build stage in the CI pipeline for finding bugs, detecting dependency vulnerabilities, and enforcing code standards.
Go to the Applications and select your application from the Devtron Apps tabs.
Go to the App Configuration tab, click Workflow Editor.
Select the build pipeline for configuring the pre/post-build tasks.
On the Edit build pipeline, in the Pre-Build Stage, click + Add task.
Select Codacy from PRESET PLUGINS.
Enter a relevant name or codacy in the Task name field. It is a mandatory field.
Enter a descriptive message for the task in the Description field. It is an optional field.
Note: The description is available by default.
In the Input Variables, provide the information in the following fields:
CodacyEndpoint
String
API endpoint for Codacy
GitProvider
String
Git provider for the scanning
CodacyApiToken
String
API token for Codacy. If it is provided, it will be used, otherwise it will be picked from Global secret (CODACY_API_TOKEN)
Organisation
String
Your Organization for Codacy
RepoName
String
Your Repository name
Branch
String
Your branch name
In Trigger/Skip Condition, set the trigger conditions to execute a task or Set skip conditions. As an example: CodacyEndpoint equal to https://app.codacy.com.
Note: You can set more than one condition.
In Pass/Failure Condition set the conditions to execute pass or fail of your build. As an example: Pass if number of issues equal to zero.
Note: You can set more than one condition.
Click Update Pipeline.
Go to the Build & Deploy, click the build pipeline and start your build.
Click Details on the build pipeline and you can view the details on the Logs.
On the Edit build pipeline screen, select the Pre-build stage.
Select + Add task.
Select Execute custom script.
The task type of the custom script may be a Shell or a Container image.
Select the Task type as Shell.
Consider an example that creates a Shell task to stop the build if the database name is not "mysql". The script takes 2 input variables, one is a global variable (DOCKER_IMAGE), and the other is a custom variable (DB_NAME) with a value "mysql". The task triggers only if the database name matches "mysql". If the trigger condition fails, this Pre-build task will be skipped and the build process will start. The variable DB_NAME is declared as an output variable that will be available as an input variable for the next task. The task fails if DB_NAME is not equal to "mysql".
Task name
Required
A relevant name for the task
Description
Optional
A descriptive message for the task
Task type
Optional
Shell: Custom shell script goes here
Input variables
Optional
Variable name: Alphanumeric chars and (_) only
Source or input value: The variable's value can be global, output from the previous task, or a custom value. Accepted data types include: STRING | BOOL | NUMBER | DATE
Description: Relevant message to describe the variable.
Trigger/Skip condition
Optional
A conditional statement to execute or skip the task
Script
Required
Custom script for the Pre/Post-build tasks
Output directory path
Optional
Output variables
Optional
Environment variables that are passed as input variables for the next task.
Pass/Failure Condition (Optional): Conditional statements to determine the success/failure of the task. A failed condition stops the execution of the next task and/or build process
Select Update Pipeline.
Here is a screenshot with the failure message from the task:
Select the Task type as Container image.
This example creates a Pre-build task from a container image. The output variable from the previous task is available as an input variable.
Task name
Required
A relevant name for the task
Description
Optional
A descriptive message for the task
Task type
Optional
Container image
Input variables
Optional
Variable name: Alphanumeric chars and (_) only
Source or input value: The variable's value can be global, output from the previous task, or a custom value Accepted data types include: STRING | BOOL | NUMBER | DATE
Description: Relevant message to describe the variable
Trigger/Skip condition
Optional
A conditional statement to execute or skip the task
Container image
Required
Select an image from the drop-down list or enter a custom value in the format <image>:<tag>
Mount custom code
Optional
Enable to mount the custom code in the container. Enter the script in the box below.
Mount above code at (required): Path where the code should be mounted
Command
Optional
The command to be executed inside the container
Args
Optional
The arguments to be passed to the command mentioned in the previous field
Port mapping
Optional
The port number on which the container listens. The port number exposes the container to outside services.
Mount code to container
Optional
Mounts the source code inside the container. Default is "No". If set to "Yes", enter the path.
Mount directory from host
Optional
Mount any directory from the host into the container. This can be used to mount code or even output directories.
Output directory path
Optional
Directory path for the script output files such as logs, errors, etc.
Select Update Pipeline.
Go to Preset Plugins section to know more about the available plugins
Trigger the CI pipeline
In any piece of software or code, variables are used for holding data such as numbers or strings. Variables are created by declaring them, which involves specifying the variable's name and type, followed by assigning it a value.
Devtron offers super-admins the capability to define scoped variables (key-value pairs). It means, while the key remains the same, its value may change depending on the following context:
Global: Variable value will be universally same throughout Devtron.
Advantages of using scoped variables
Reduces repeatability: Configuration management team can centrally maintain the static data.
Simplifies bulk edits: All the places that use a variable get updated when you change the value of the variable.
Keeps data secure: You can decide the exposure of a variable's value to prevent misuse or leakage of sensitive data.
On Devtron, a super-admin can download a YAML template. It will contain a schema for defining the variables.
From the left sidebar, go to Global Configurations → Scoped Variables
Click Download template.
Open the downloaded template using any code editor (say VS Code).
The YAML file contains key-value pairs that follow the below schema:
apiVersion
string
The API version of the resource (comes pre-filled)
kind
string
The kind of resource (i.e. Variable, comes pre-filled)
spec
object
The complete specification object containing all the variables
spec.name
string
Unique name of the variable, e.g. DB_URL
spec.shortDescription
string
A short description of the variable (up to 120 characters)
spec.notes
string
Additional details about the variable (will not be shown on UI)
spec.isSensitive
boolean
Whether the variable value is confidential (will not be shown on UI if true)
spec.values
array
The complete values object containing all the variable values as per context
The spec.values array further contains the following elements:
category
string
The context, e.g., Global, Cluster, Application, Env, ApplicationEnv
value
string
The value of the variable
selectors
object
A set of selectors that restrict the scope of the variable
selectors.attributeSelectors
object
A map of attribute selectors to values
selectors.attributeSelectors.<selector_key>
string
The key of the attribute selector, e.g., ApplicationName, EnvName, ClusterName
selectors.attributeSelectors.<selector_value>
string
The value of the attribute selector
Here's a truncated template containing the specification of two variables for your understanding:
apiVersion: devtron.ai/v1beta1
kind: Variable
spec:
# First example of a variable
- name: DB_URL
shortDescription: My application's customers are stored
notes: The DB is a MySQL DB running version 7.0. The DB contains confidential
information.
isSensitive: true
values:
- category: Global
value: mysql.example.com
# Second example of a variable
- name: DB_Name
shortDescription: My database name to recognize the DB
notes: NA
isSensitive: false
values:
- category: Global
value: Devtron
- category: ApplicationEnv
value: app1-p
selectors:
attributeSelectors:
ApplicationName: MyFirstApplication
EnvName: prodOnce you save the YAML file, go back to the screen where you downloaded the template.
Use the file uploader utility to upload your YAML file.
The content of the file will be uploaded for you to review and edit. Click Review Changes.
You may check the changes between the last saved file and the current one before clicking Save.
Click the Variable List tab to view the variables. Check the How to Use a Scoped Variable section to know more.
Only a super-admin can edit existing scoped variables.
Option 1: Directly edit using the UI
Option 2: Reupload the updated YAML file
Reuploading the YAML file will replace the previous file, so any variable that existed in the previous file but not in the latest one will be lost
Once a variable is defined, it can be used by your authorized users on Devtron. A scoped variable widget would appear only on the screens that support its usage.
Currently, the widget is shown only on the following screens in App Configuration:
Workflow Editor → Edit build pipeline → Pre-build stage (tab)
Workflow Editor → Edit build pipeline → Post-build stage (tab)
Workflow Editor → Edit deployment pipeline → Post-Deployment stage (tab)
Workflow Editor → Edit deployment pipeline → Post-Deployment stage (tab)
Deployment Template
ConfigMaps
Secrets
Upon clicking on the widget, a list of variables will be visible.
Use the copy button to copy a relevant variable of your choice.
It would appear in the following format upon pasting it within an input field: @{{variable-name}}
When multiple values are associated with a scoped variable, the precedence order is as follows, with the highest priority at the top:
Global
Environment + App: This is the most specific scope, and it will take precedence over all other scopes. For example, the value of DB name variable for the app1 application in the prod environment would be app1-p, even though there is a global DB name variable set to Devtron. If a variable value for this scope is not defined, the App scope will be checked.
App: This is the next most specific scope, and it will take precedence over the Environment, Cluster, and Global scopes. For example, the value of DB name variable for the app1 application would be project-tahiti, even though the value of DB name exists in lower scopes. If a variable value for this scope is not defined, the Environment scope will be checked.
Environment: This is the next most specific scope, and it will take precedence over the Cluster and Global scopes. For example, the value of DB name variable in the prod environment would be devtron-prod, even though the value of DB name exists in lower scopes. If a variable value for this scope is not defined, the Cluster scope will be checked.
Cluster: This is the next most specific scope, and it will take precedence over the Global scope. For example, the value of DB name variable in the gcp-gke cluster would be Devtron-gcp, even though there is a global DB name variable set to Devtron-gcp. If a variable value for this scope is not defined, the Global scope will be checked.
Global: This is the least specific scope, and it will only be used if no variable values are found in other higher scopes. The value of DB name variable would be Devtron.
There are some system variables that exist by default in Devtron that you can readily use if needed:
DEVTRON_NAMESPACE: Provides name of the namespace
DEVTRON_CLUSTER_NAME: Provides name of the cluster configured on Devtron
DEVTRON_ENV_NAME: Provides name of the environment
DEVTRON_IMAGE_TAG: Provides image tag associated with the container image
DEVTRON_IMAGE: Provides full image path of the container image, e.g., gcr.io/k8s-minikube/kicbase:v0.0.39
DEVTRON_APP_NAME: Provides name of the application on Devtron
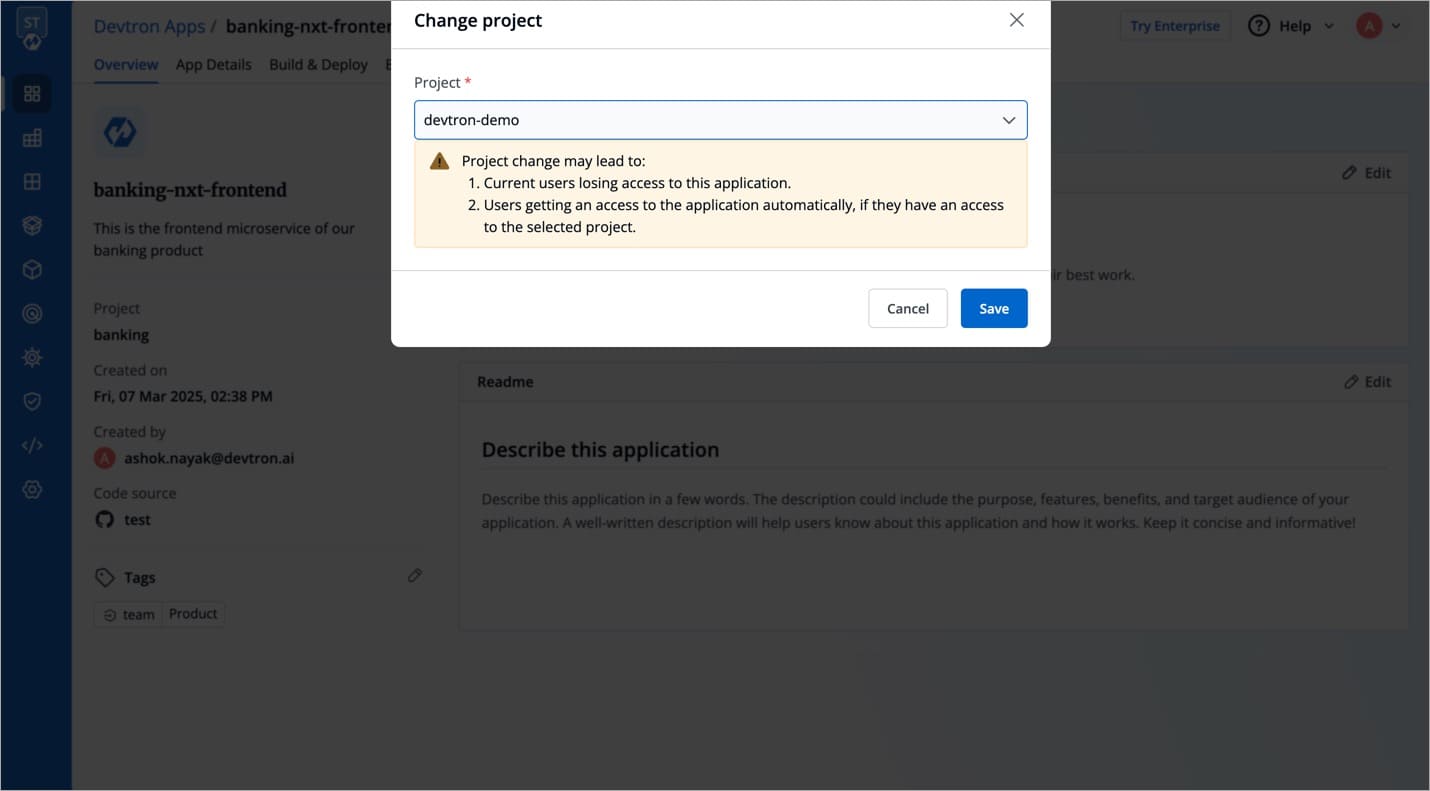
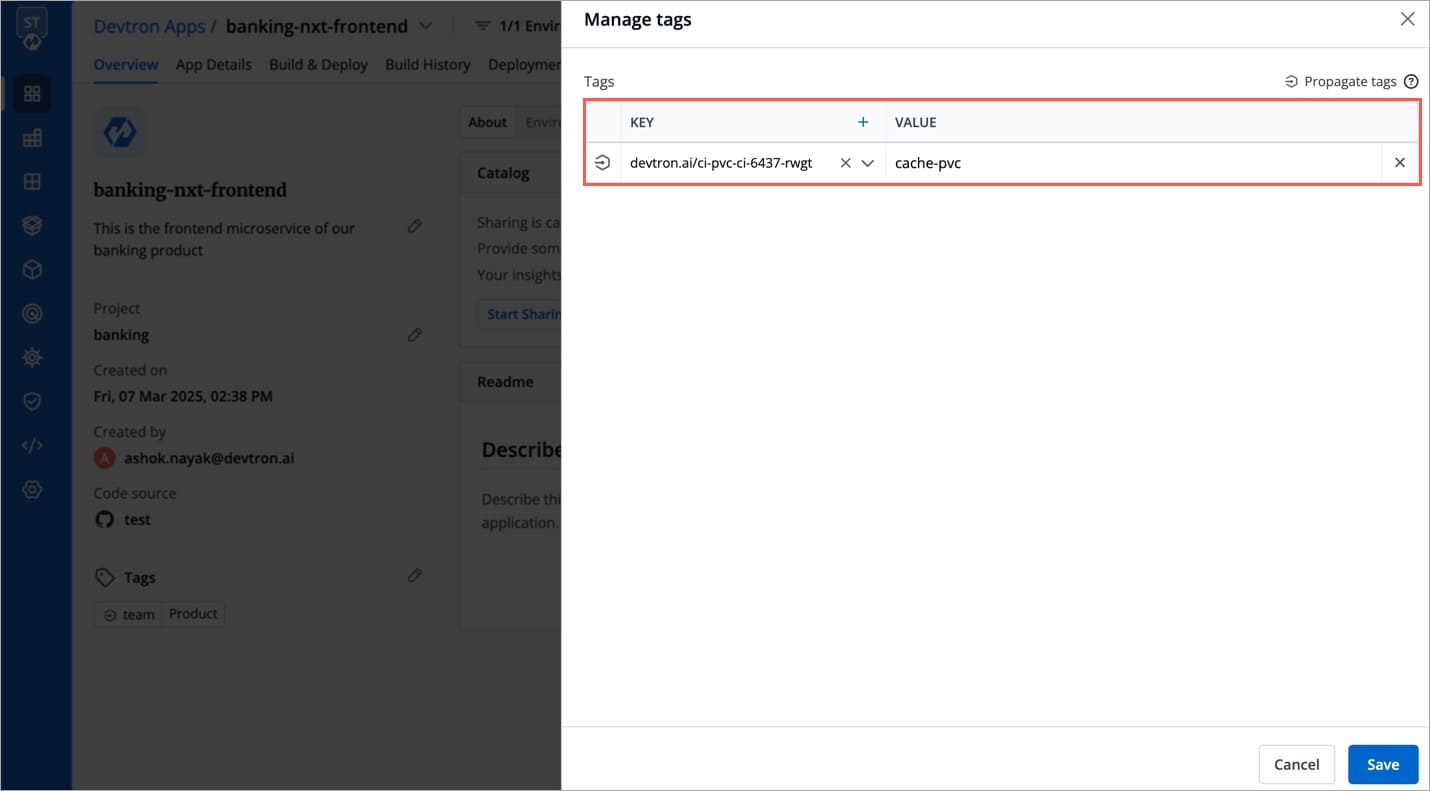
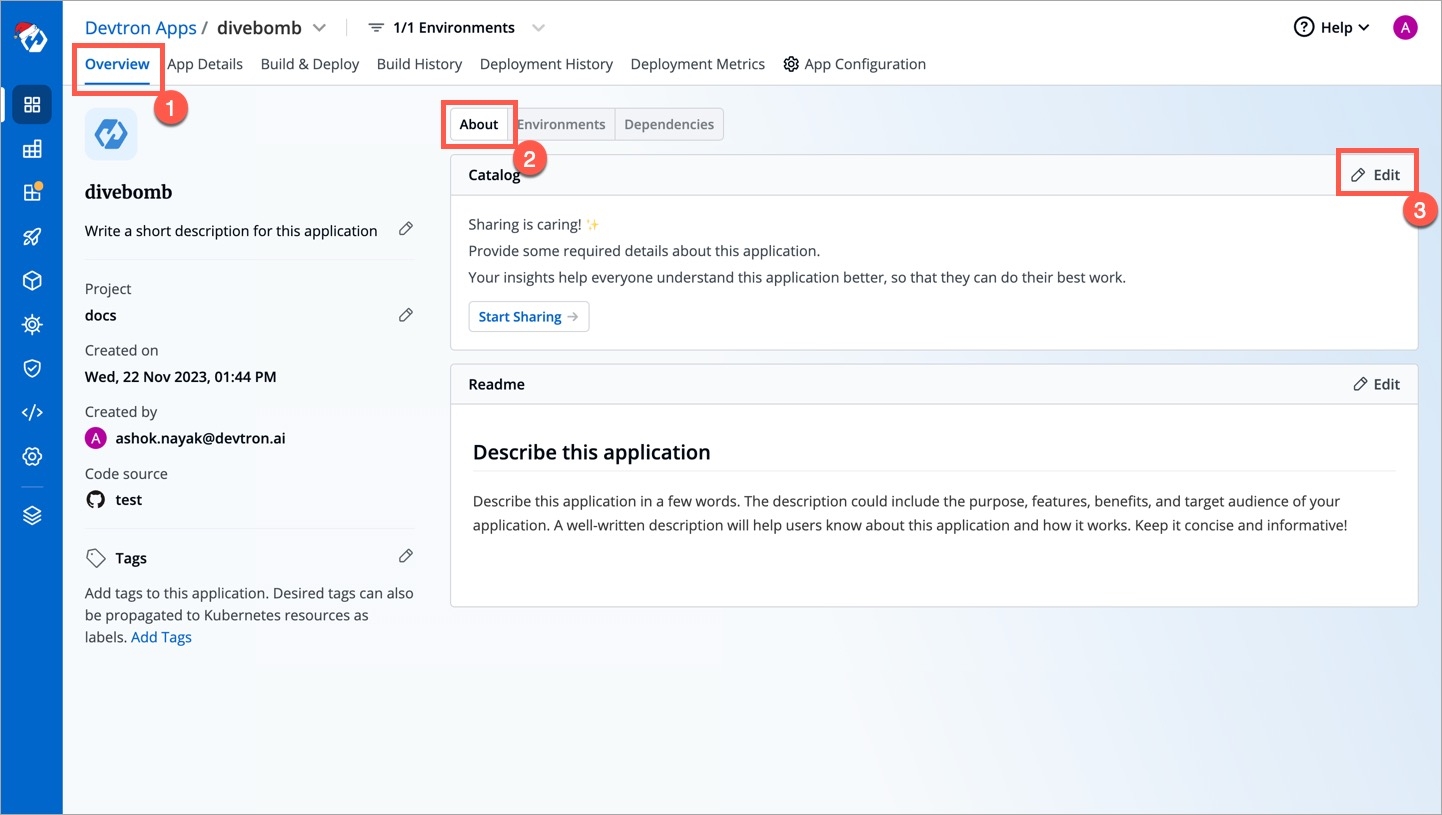
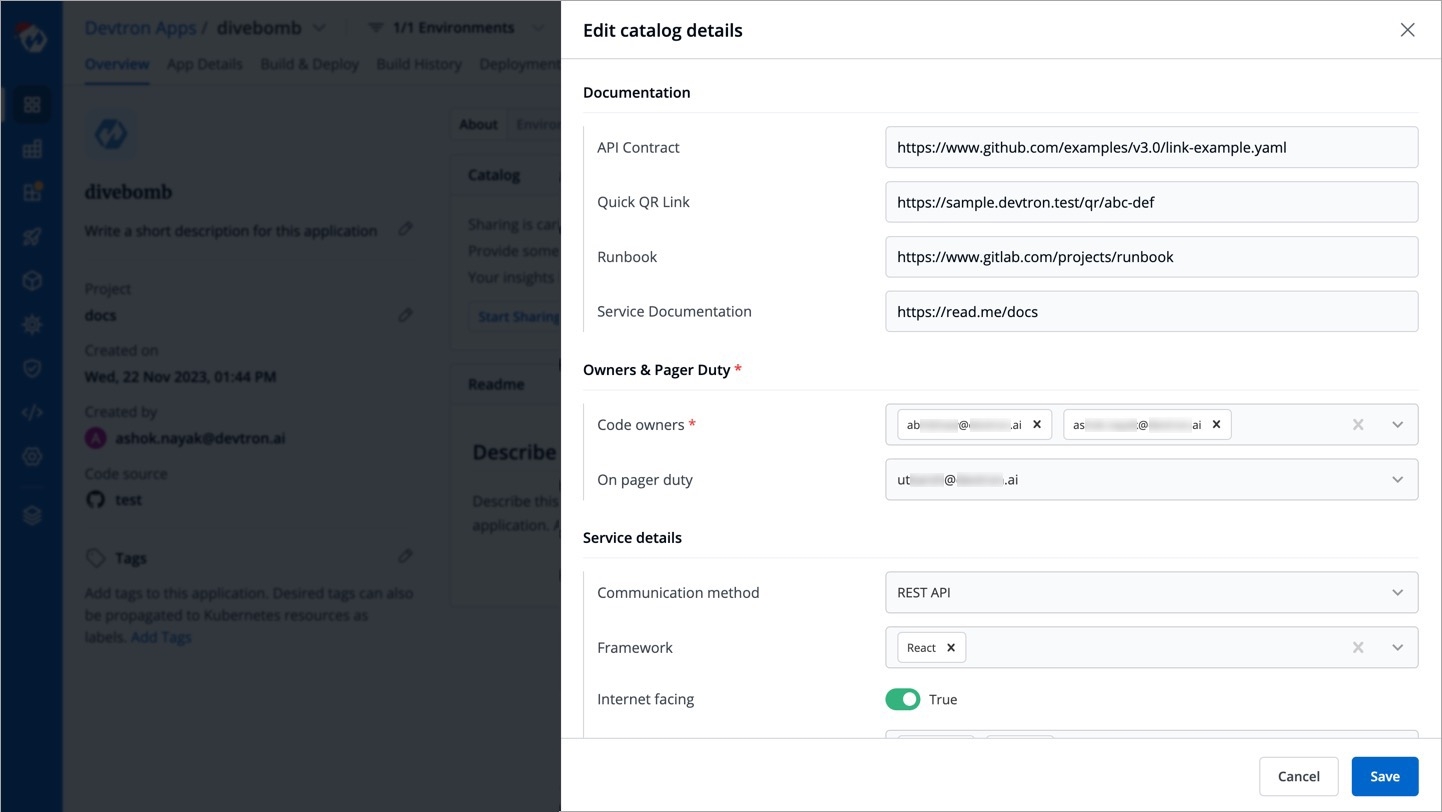
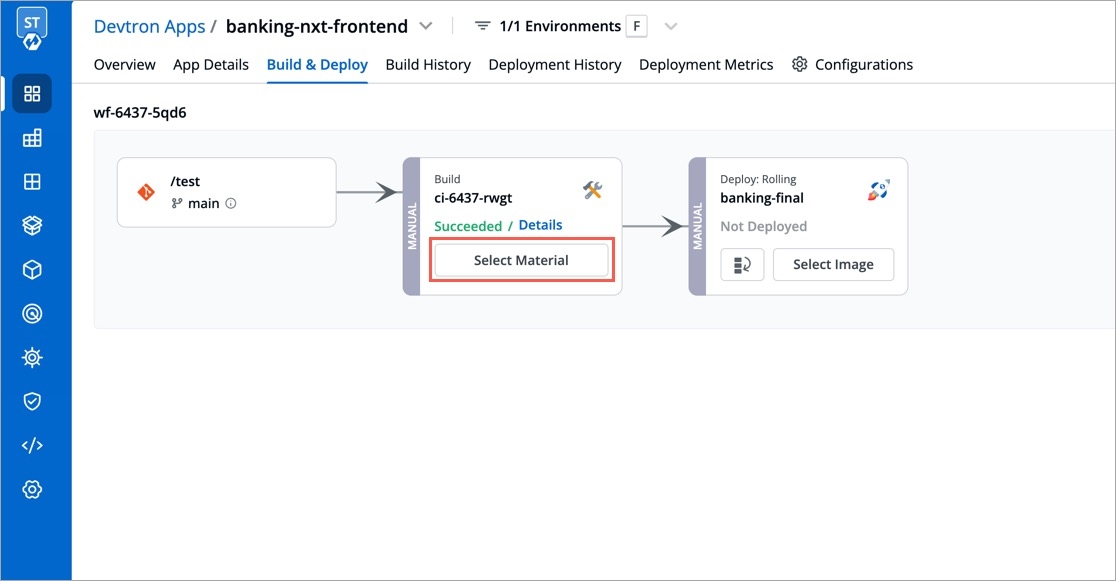
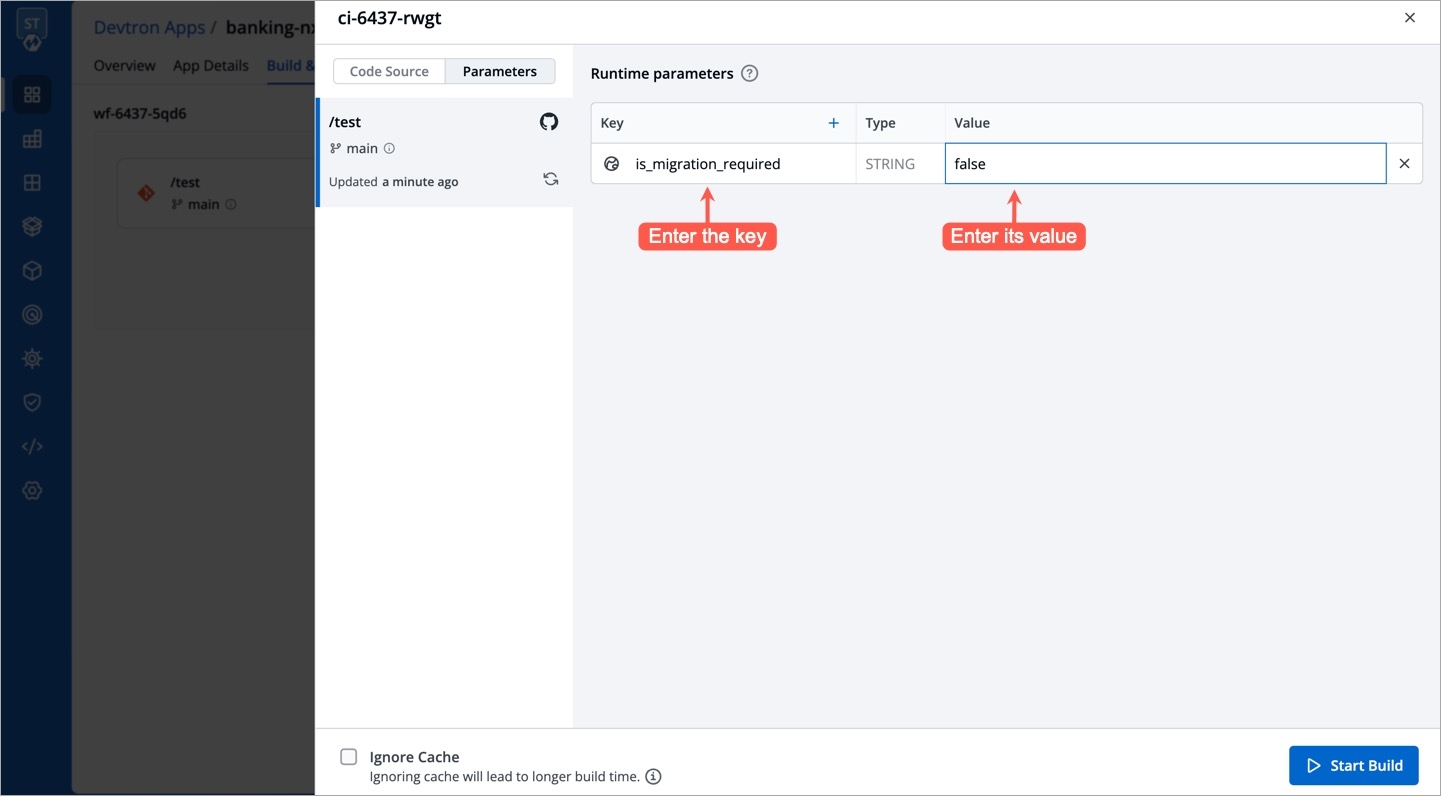
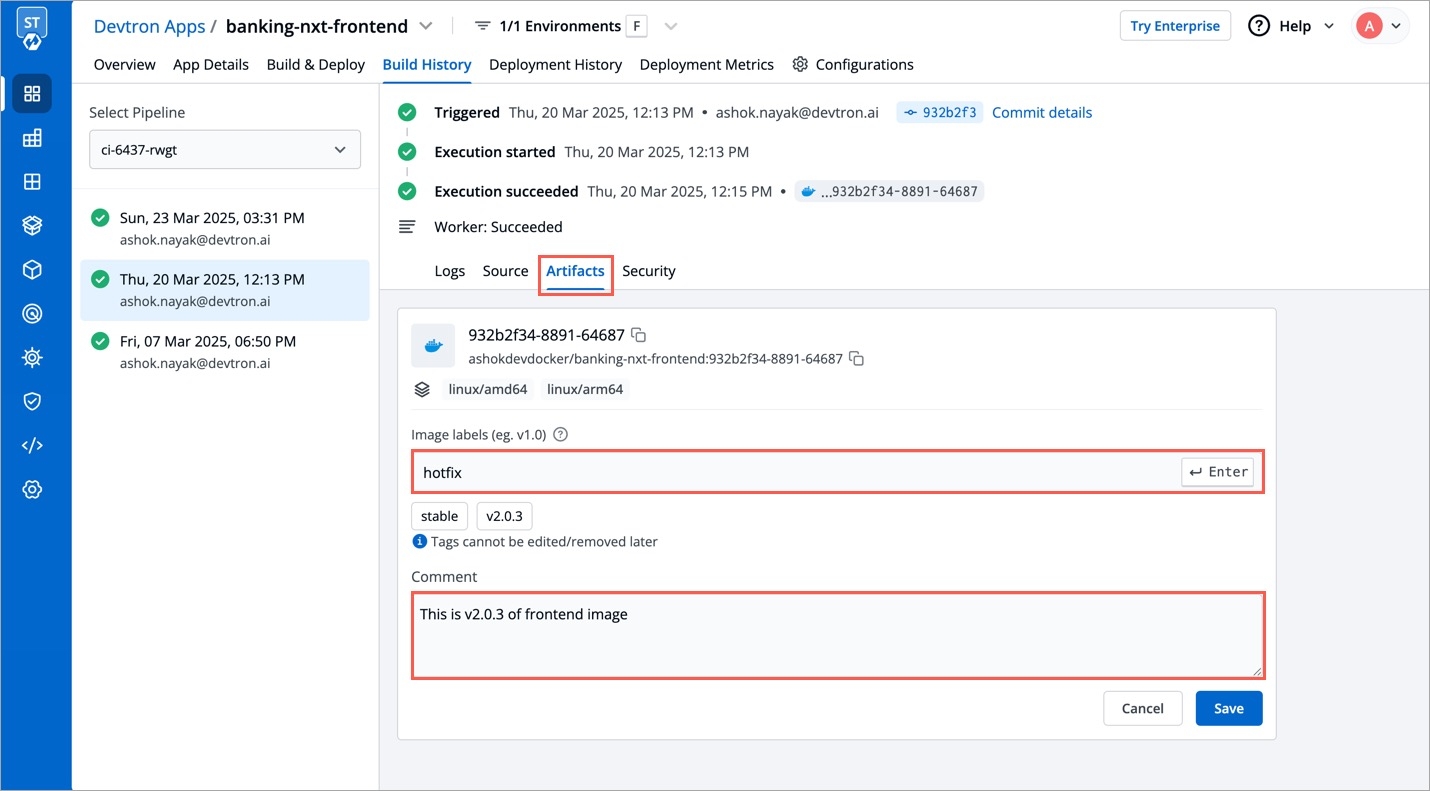
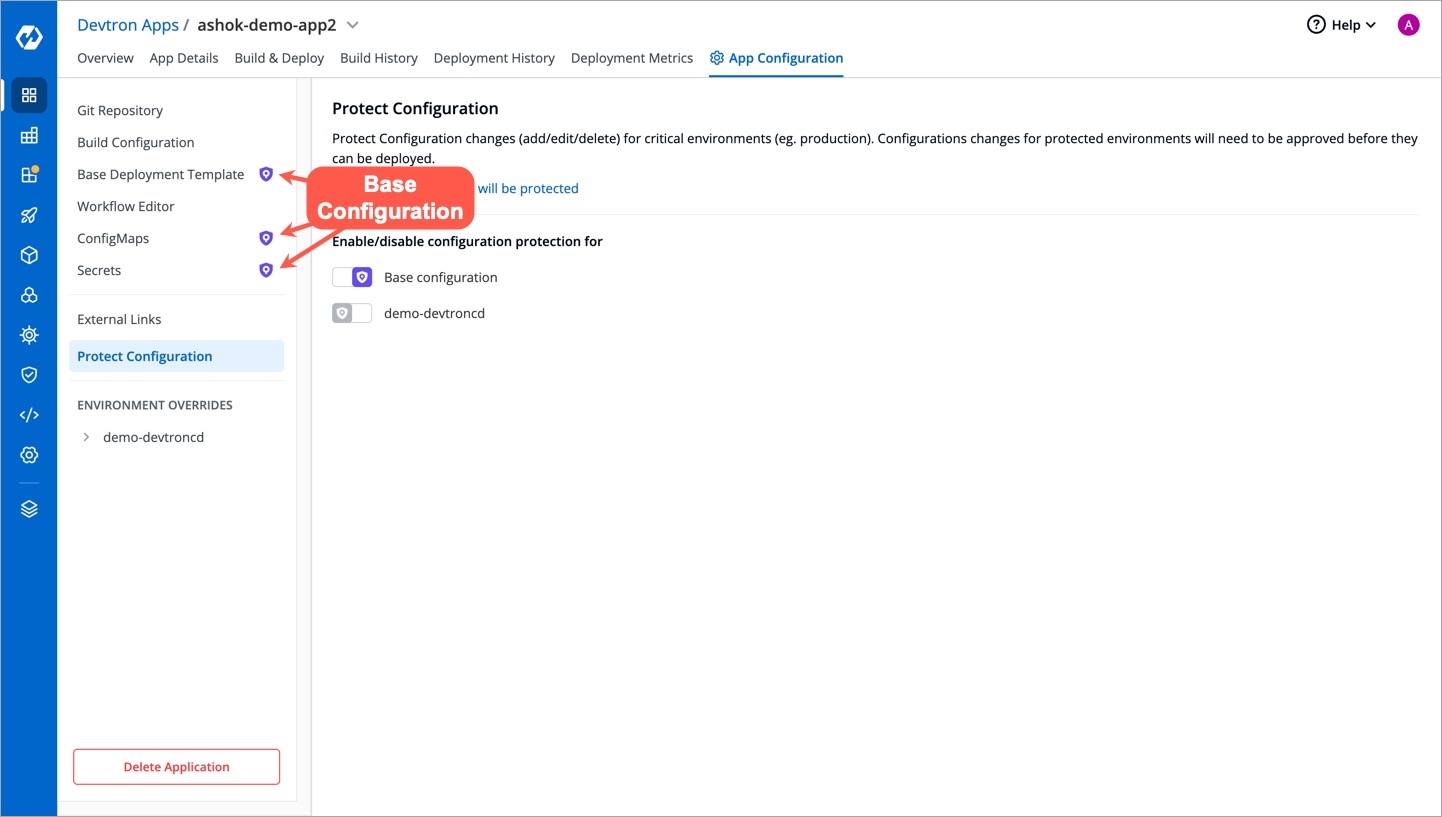
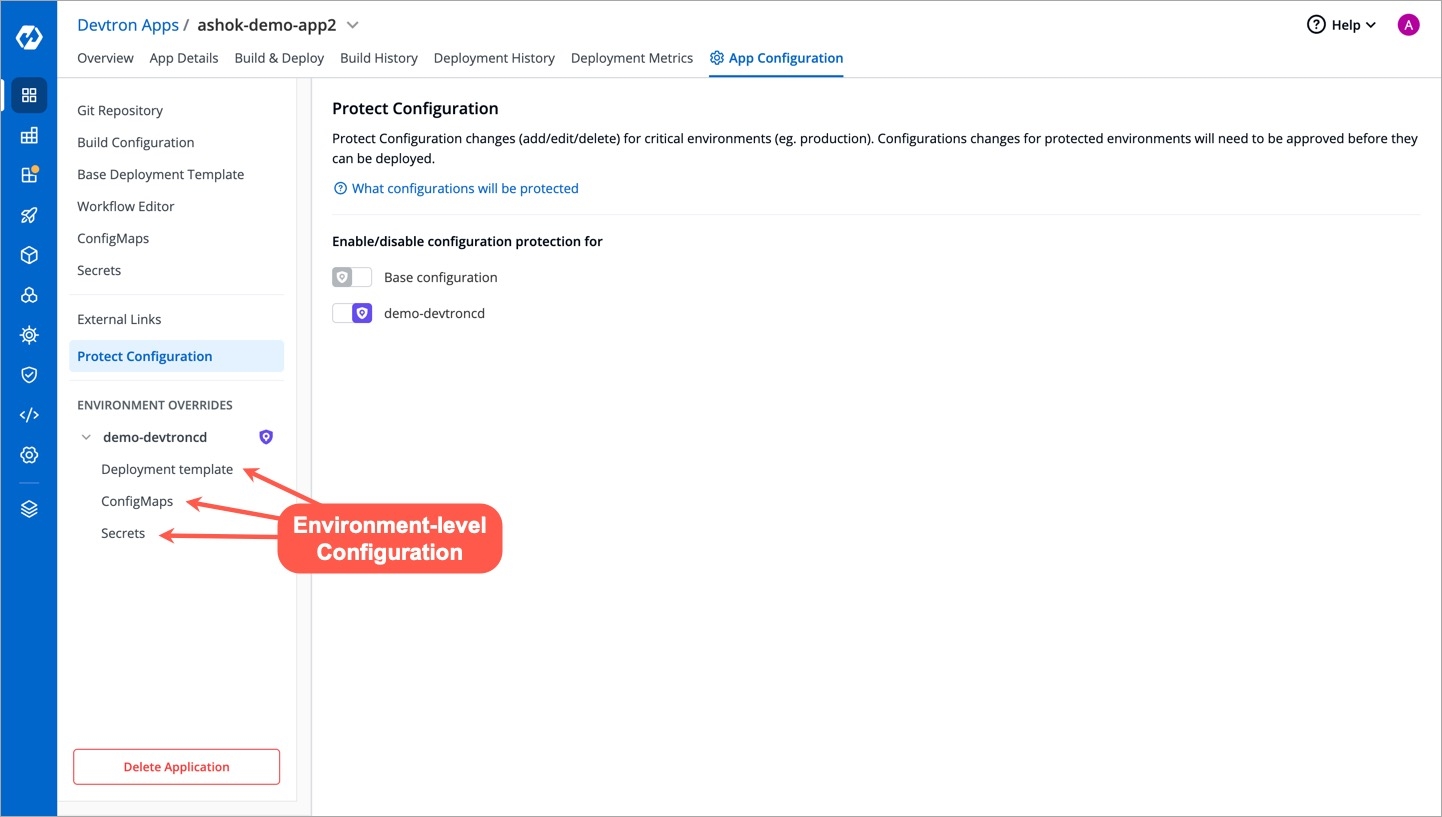
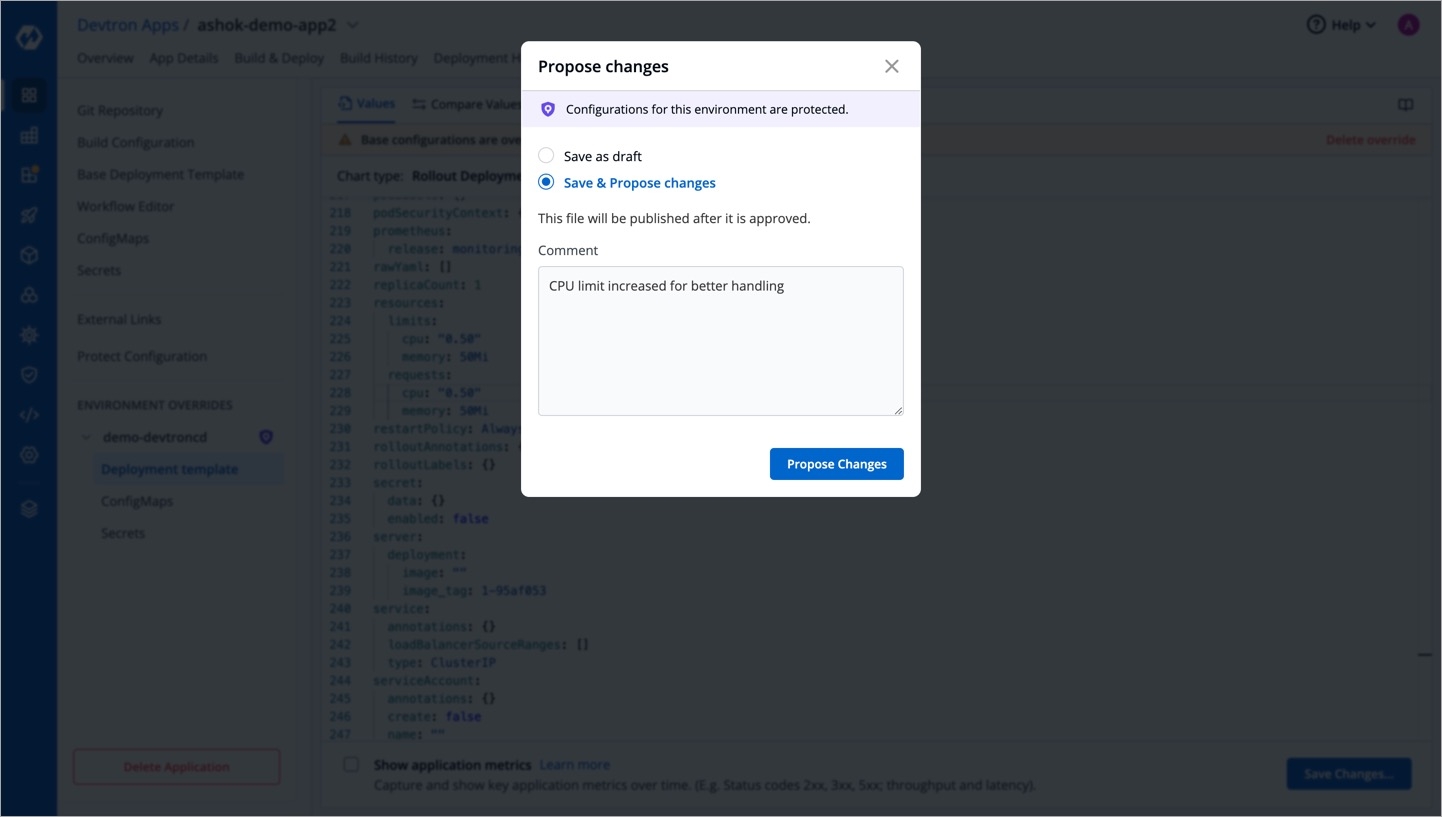
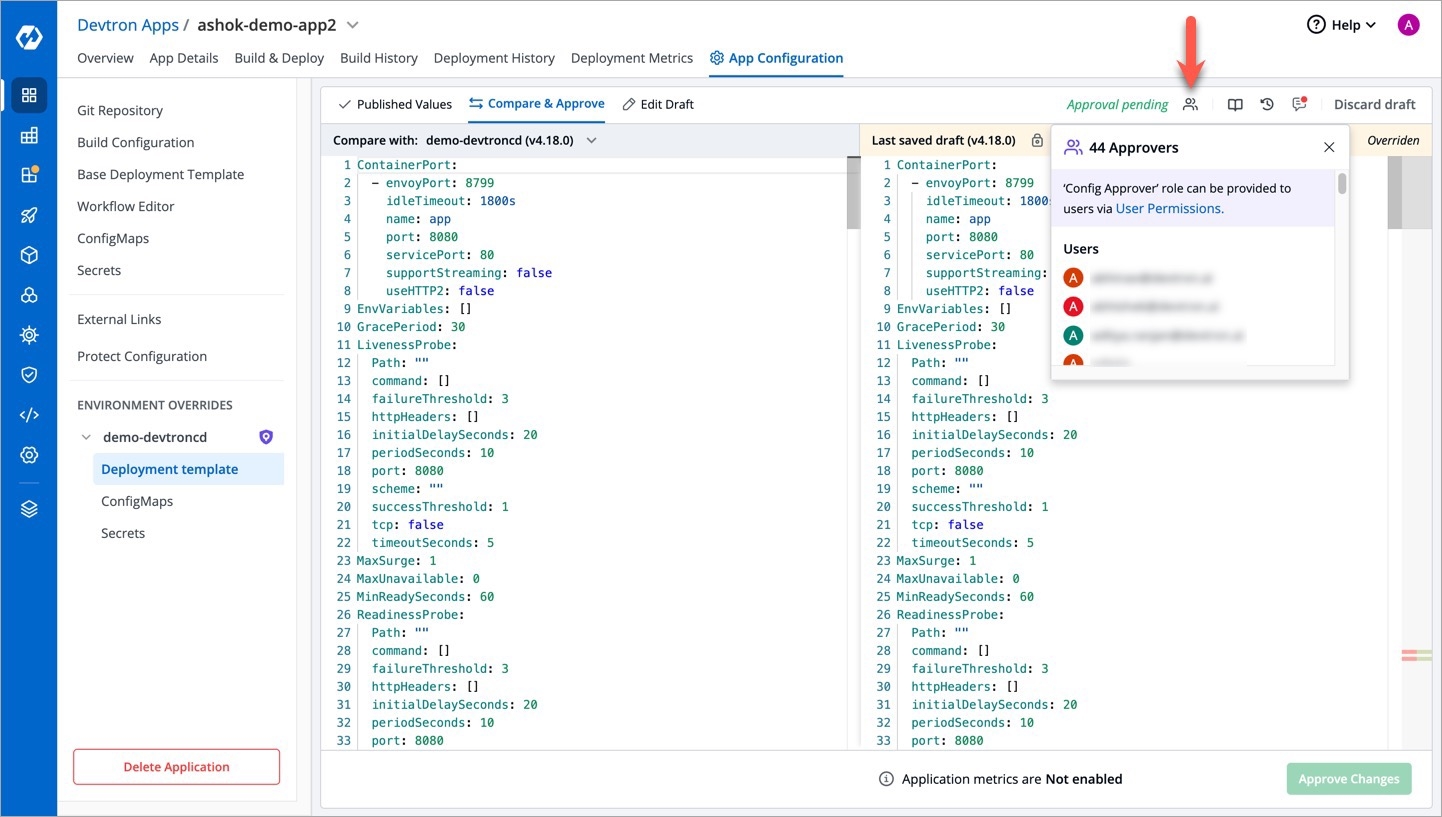
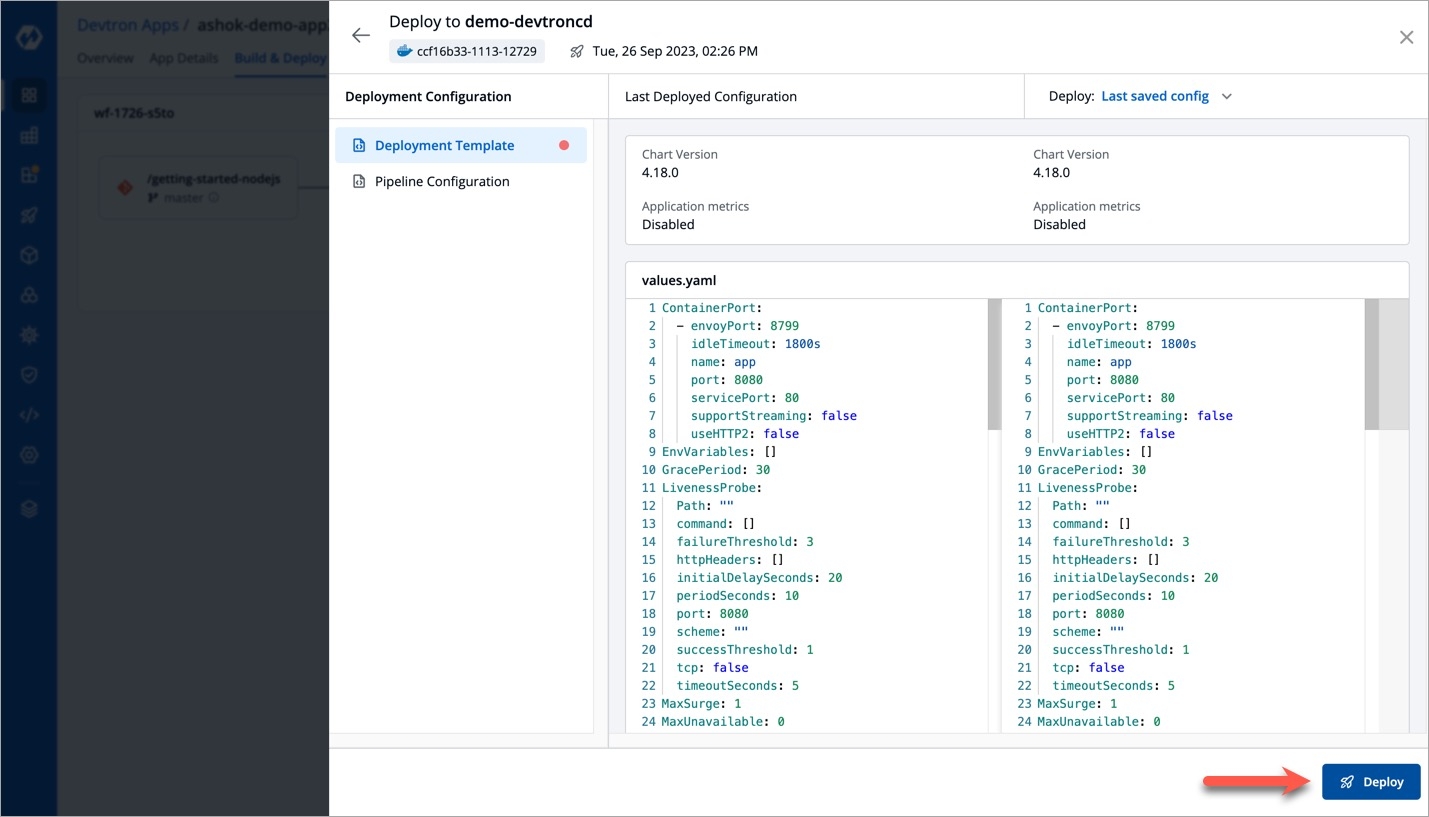
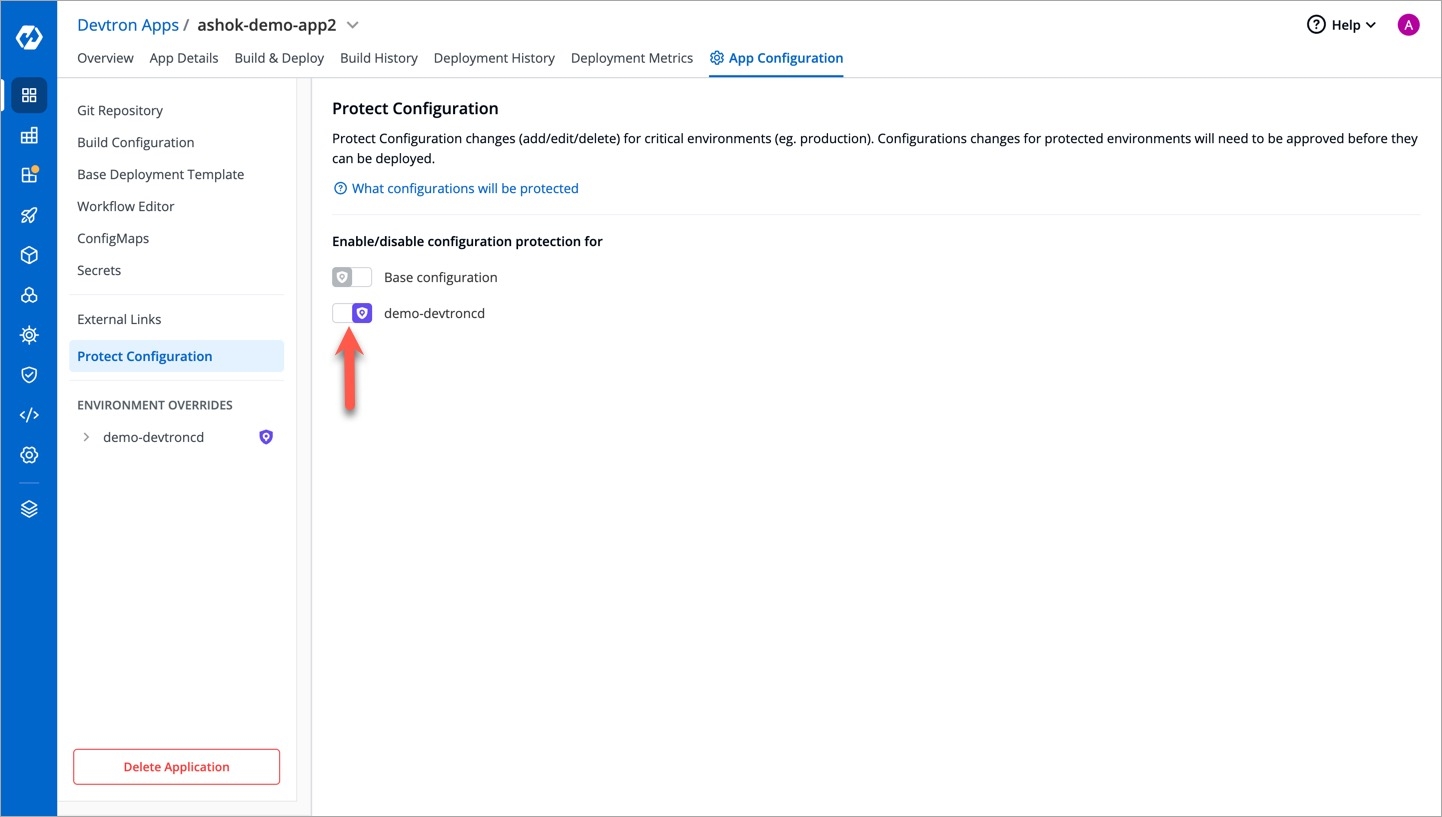
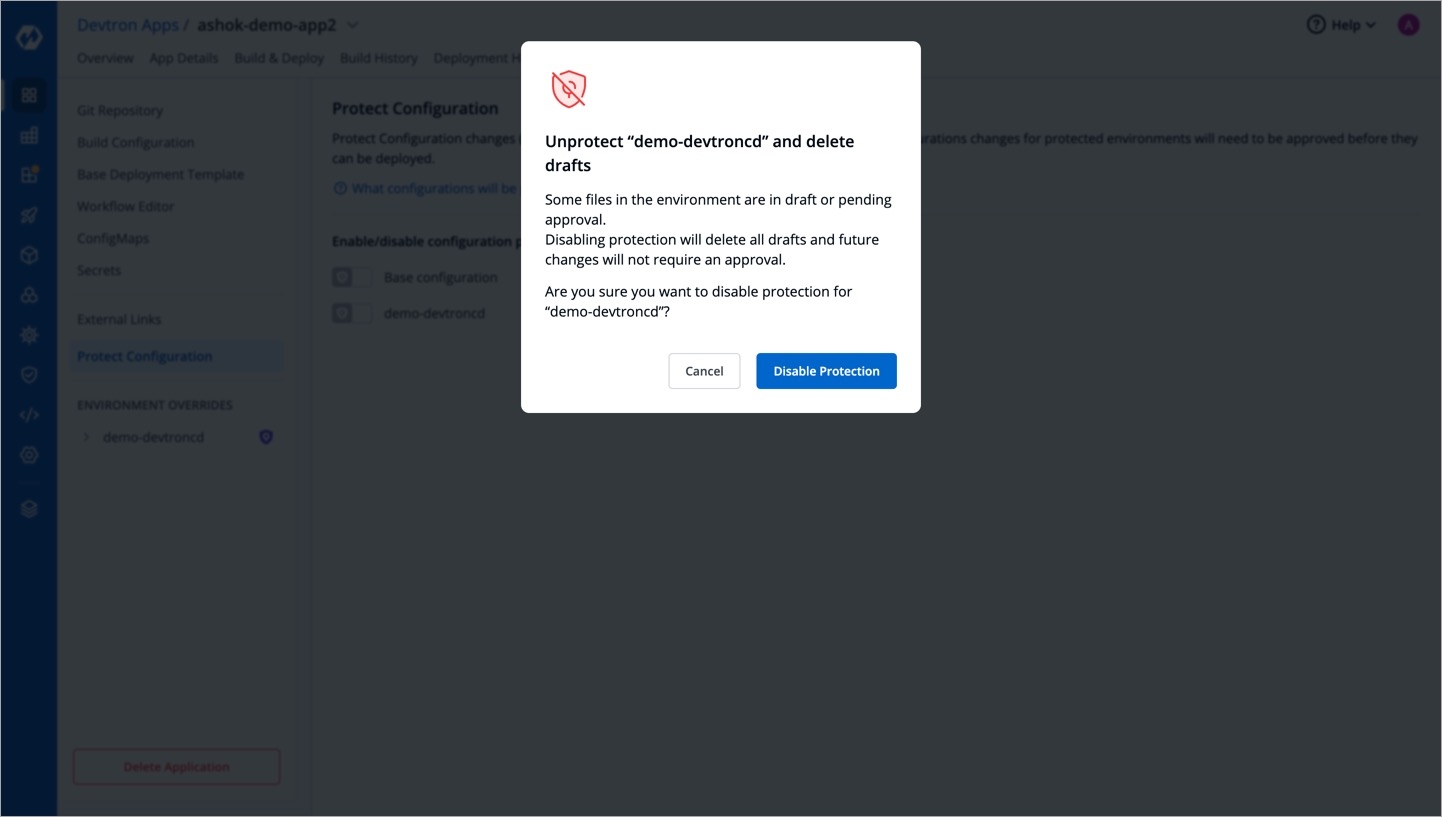
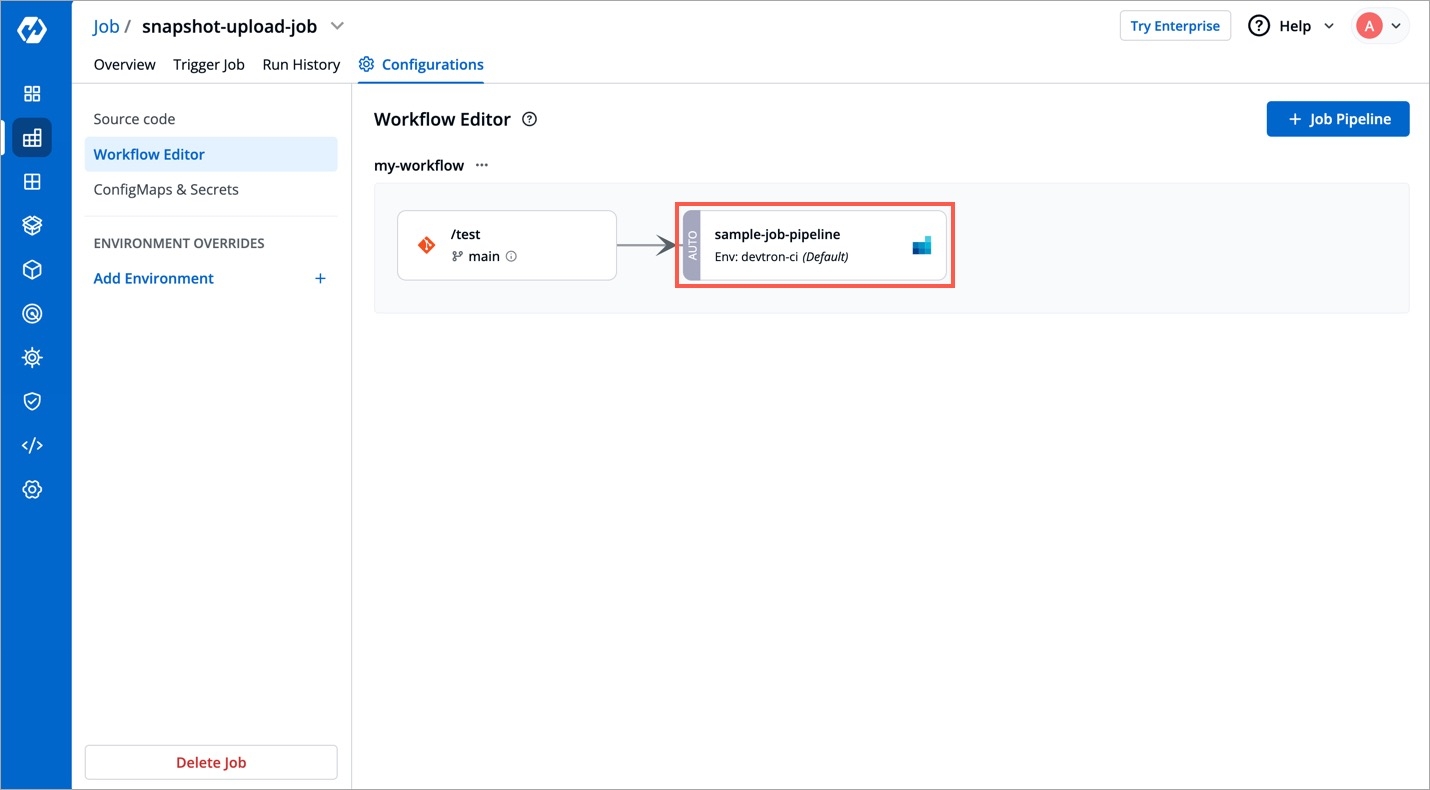
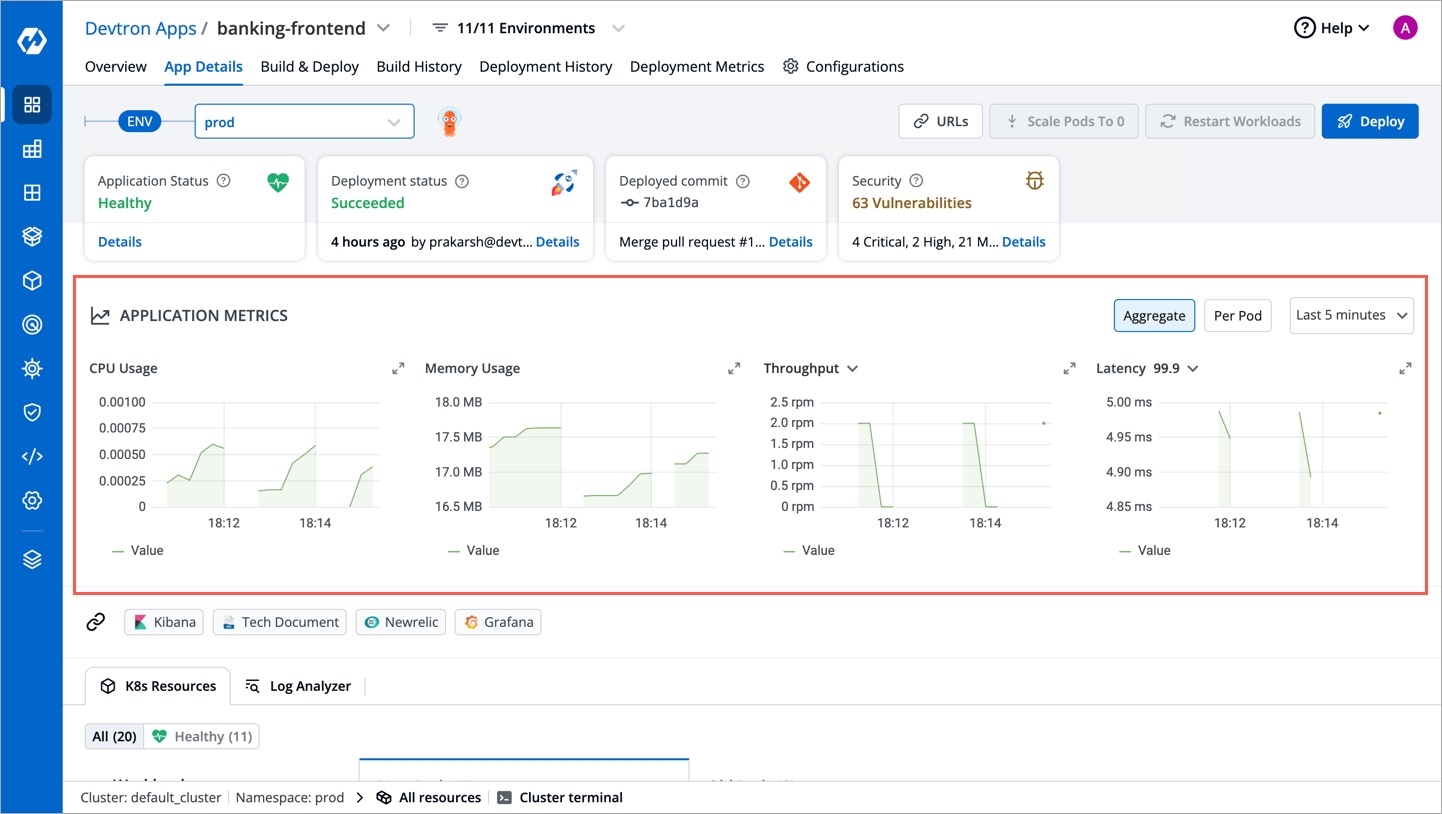
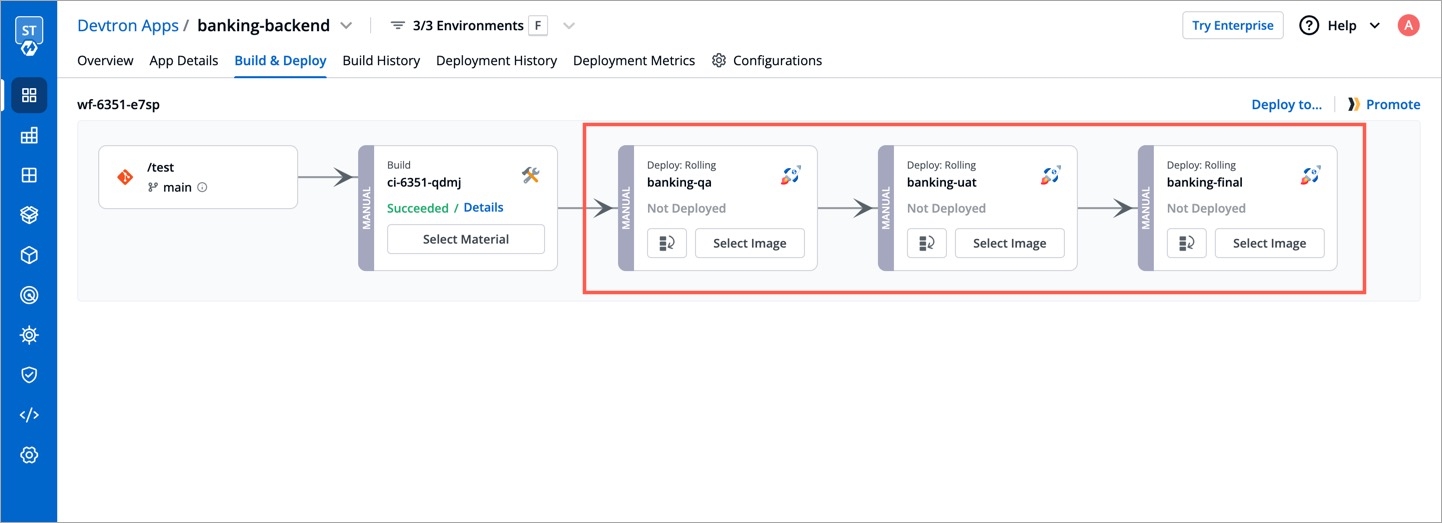
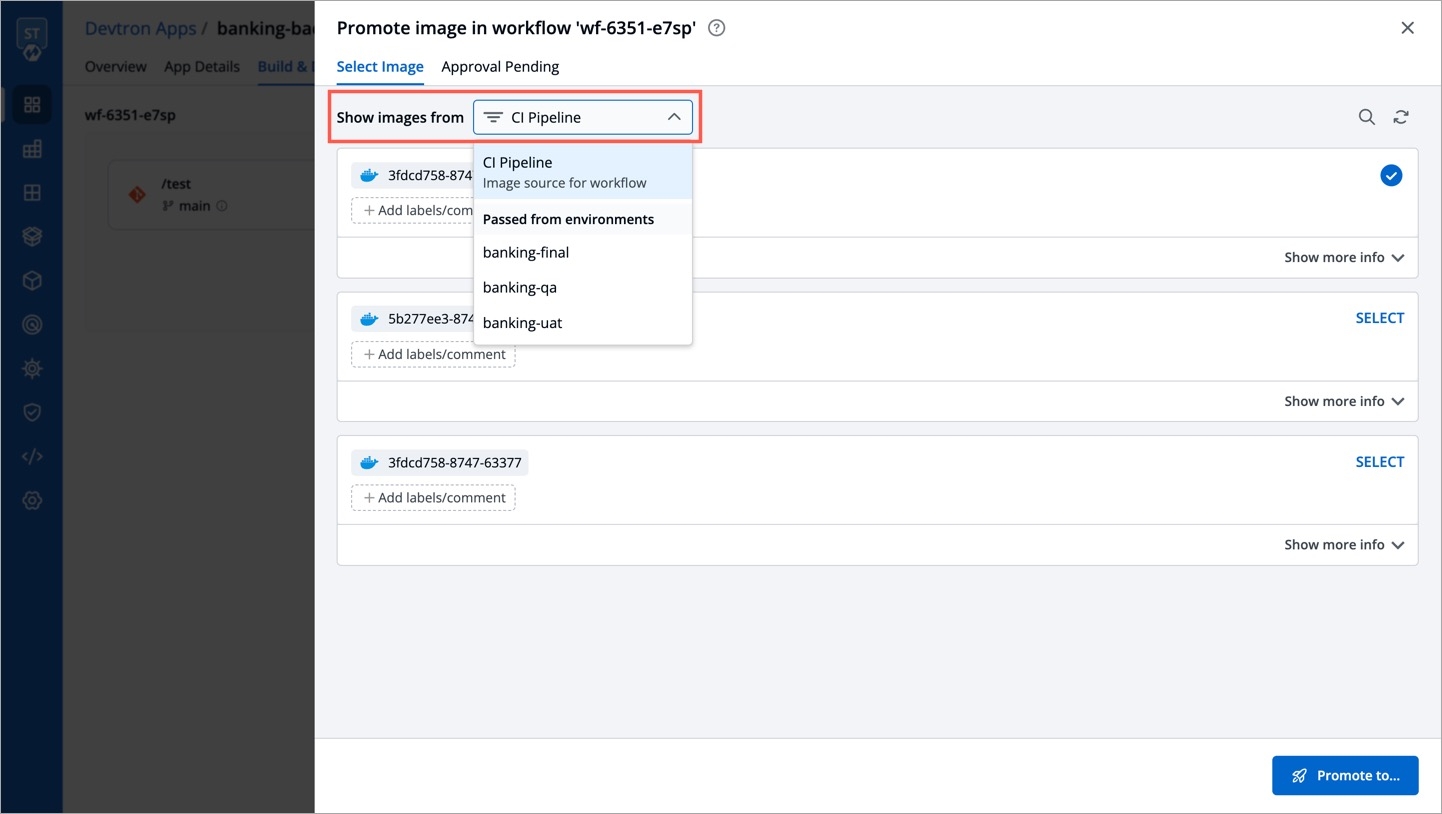
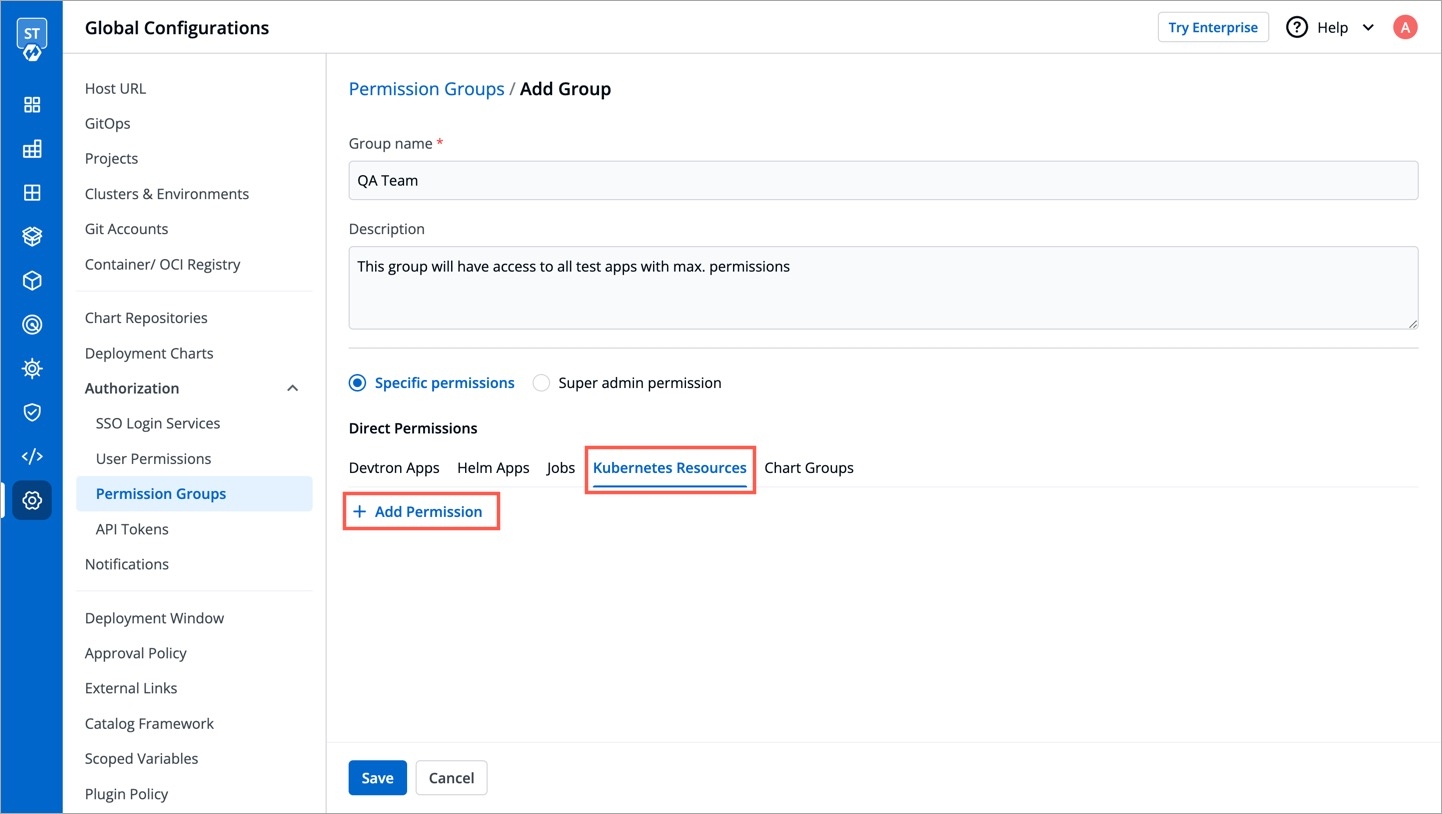
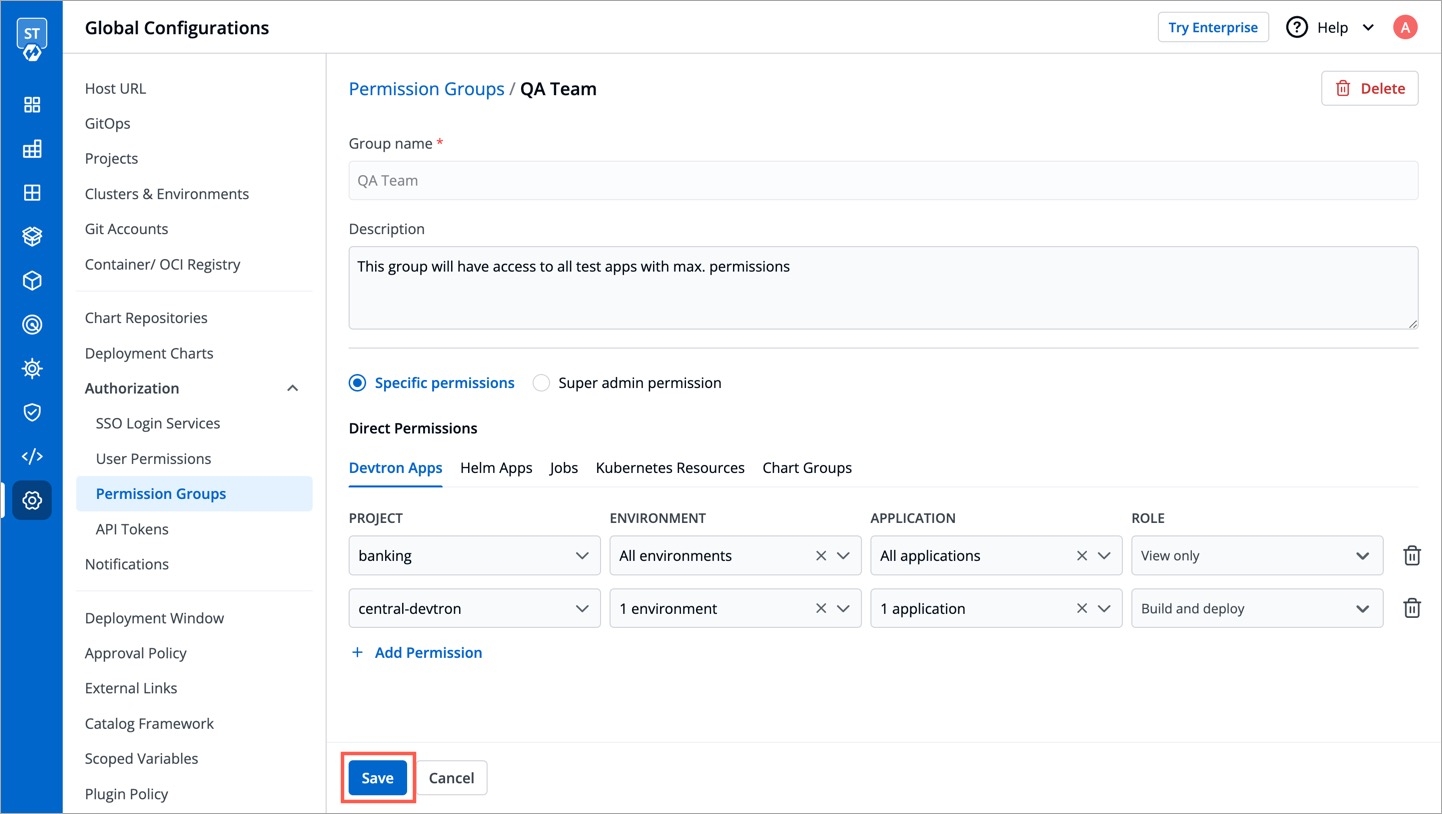
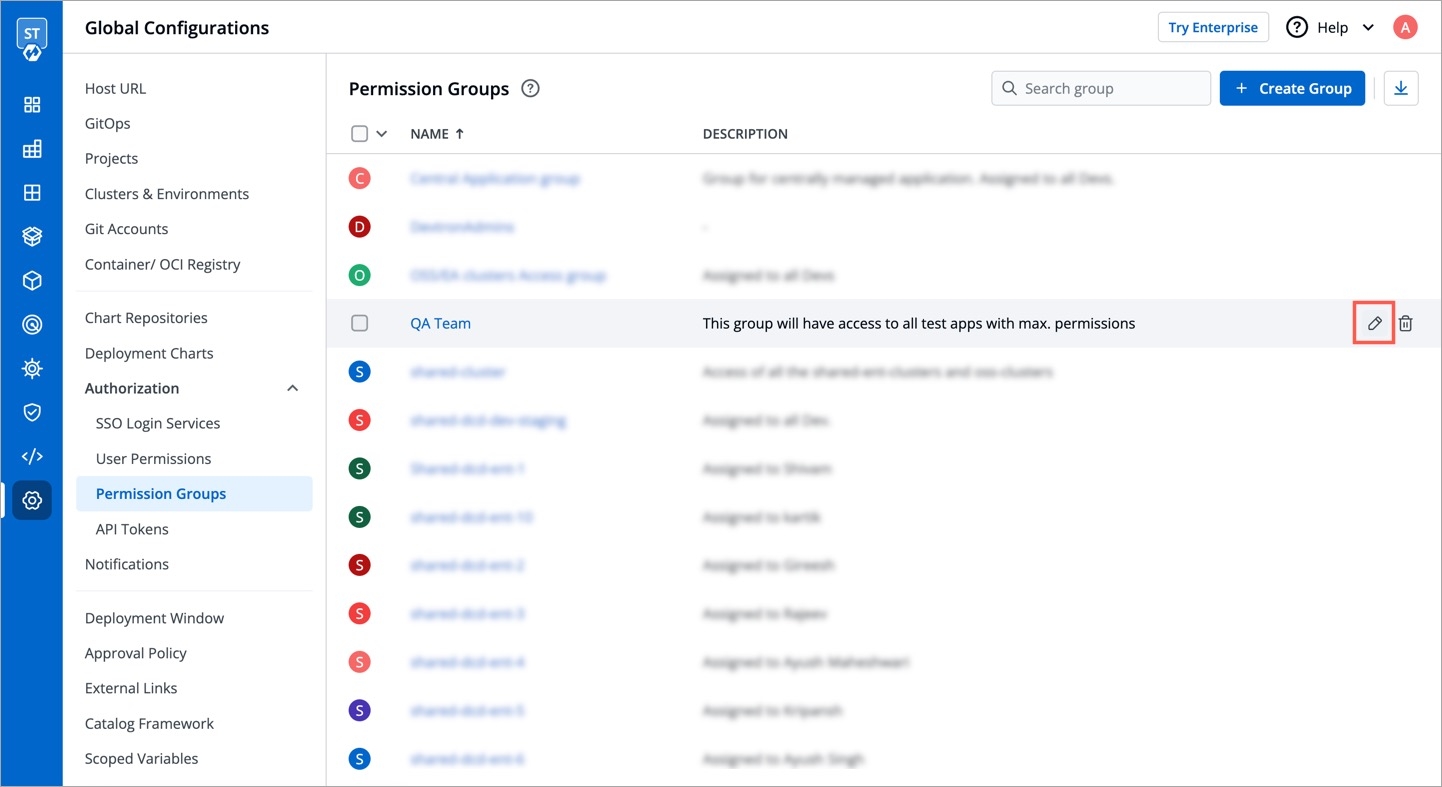
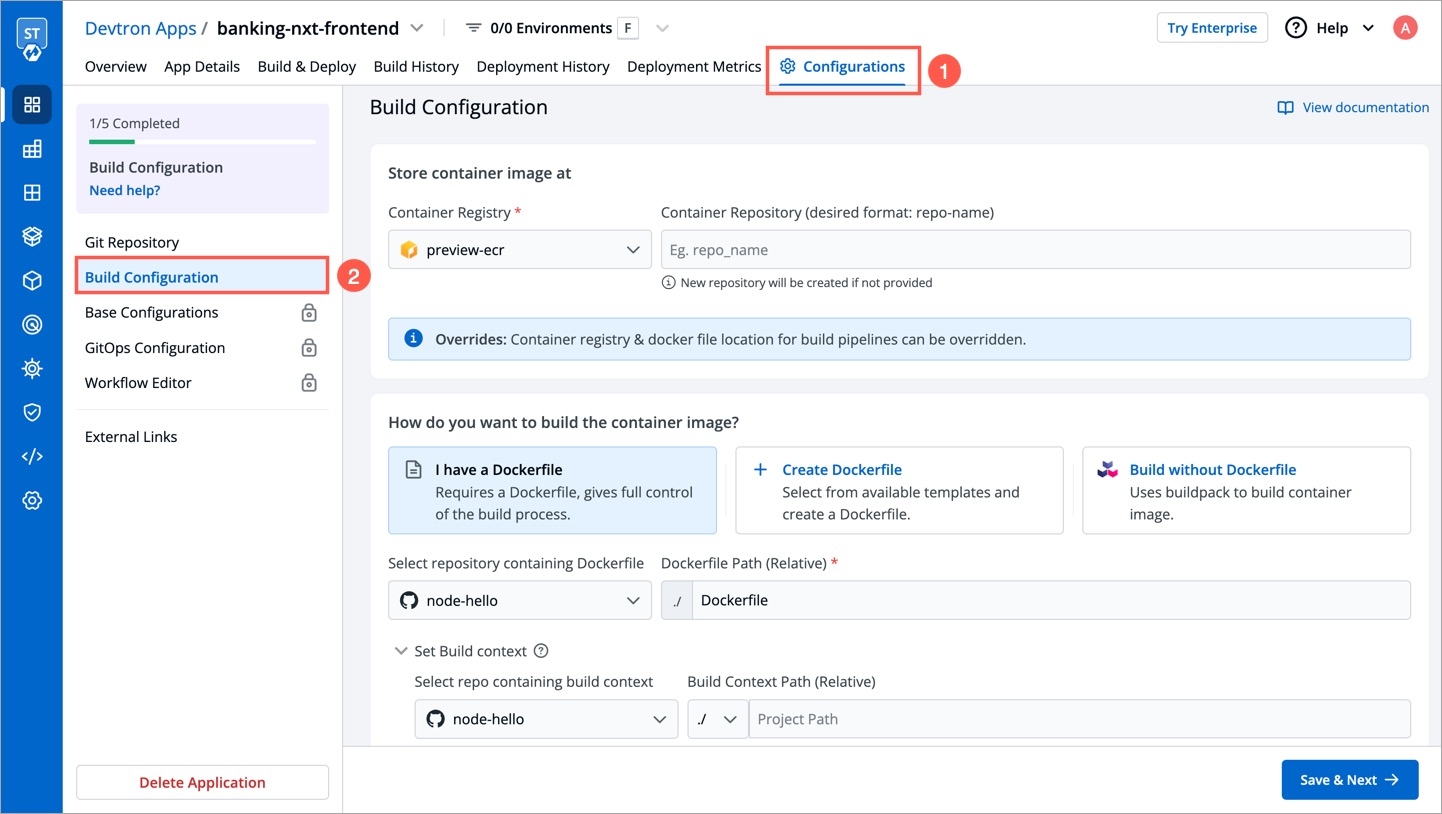
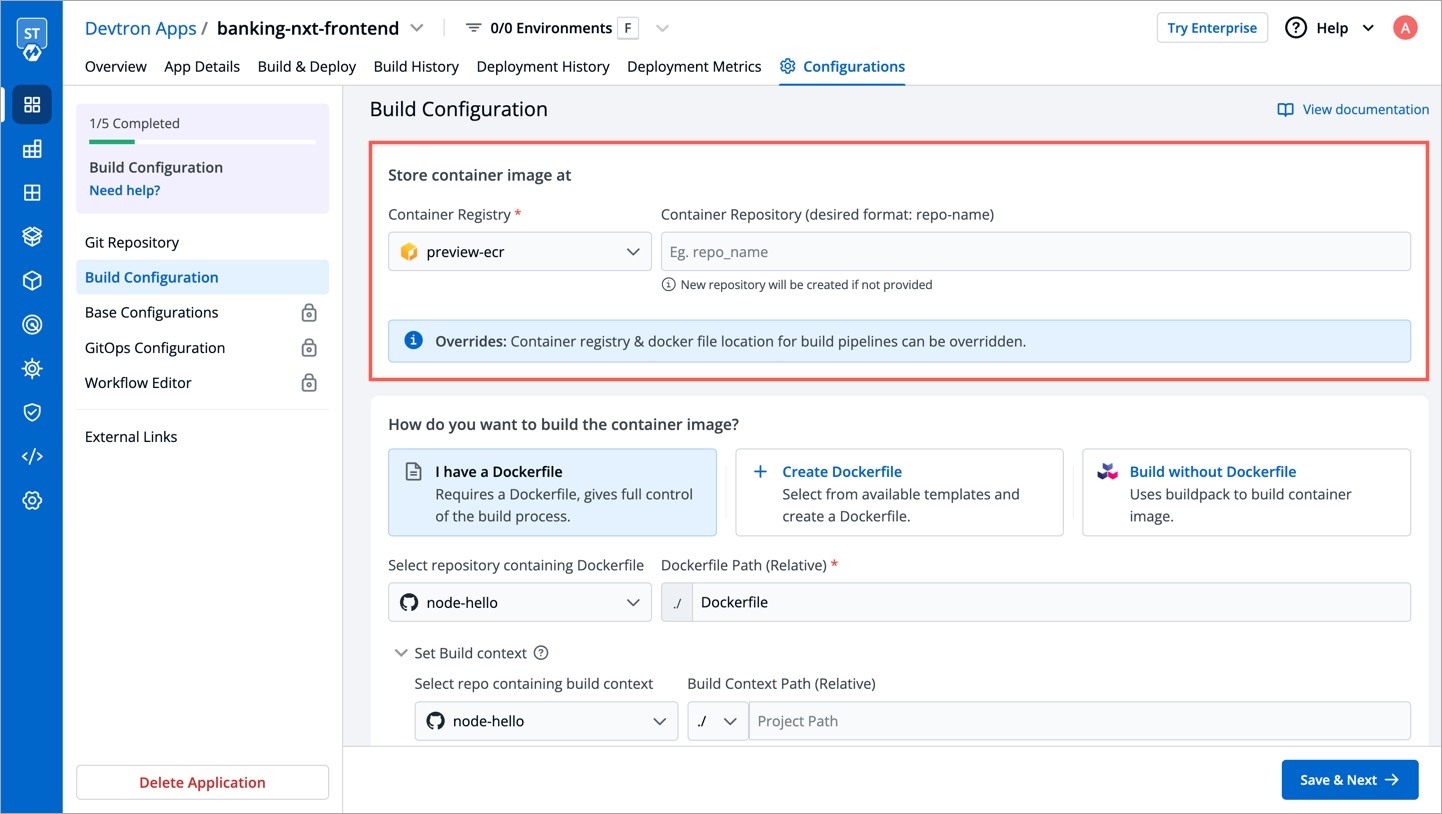
CI Pipeline can be created in three different ways, , and .
Each of these methods have different use-cases which can be used according to the needs of the organization. Let’s begin with Continuous Integration.
Click on Continuous Integration, a prompt comes up in which we need to provide our custom configurations. Below is the description of some configurations which are required.
[Note] Options such as pipeline execution, stages and scan for vulnerabilities, will be visible after clicking on advanced options present in the bottom left corner.
Pipeline name is an auto-generated name which can also be renamed by clicking on Advanced options.
You can select the method you want to execute the pipeline. By default the value is automatic. In this case it will get automatically triggered if any changes are made to the respective git repository. You can set it to manual if you want to trigger the pipeline manually.
In source type, we can observe that we have three types of mechanisms which can be used for building your CI Pipeline. In the drop-down you can observe we have Branch Fixed, Pull Request and Tag Creation.
If you select the Branch Fixed as your source type for building CI Pipeline, then you need to provide the corresponding Branch Name.
Branch Name is the name of the corresponding branch (eg. main or master, or any other branch)
[Note] It only works if Git Host is Github or Bitbucket Cloud as of now. In case you need support for any other Git Host, please create a .
If you select the Pull Request option, you can configure the CI Pipeline using the generated PR. For this mechanism you need to configure a webhook for the repository added in the Git Material.
Prerequisites for Pull Request
If using GitHub - To use this mechanism, as stated above you need to create a webhook for the corresponding repository of your Git Provider. In Github to create a webhook for the repository -
Go to settings of that particular repository
Click on webhook section under options tab
In the Payload URL section, please copy paste the Webhook URL which can be found at Devtron Dashboard when you select source type as Pull Request as seen in above image.
Change content type to - application/json
Copy paste the Secret as well from the Dashboard when you select the source type as Pull Request
Now, scroll down and select the custom events for which you want to trigger the webhook to build CI Pipeline -
Check the radio button for Let me select individual events
Then, check the Branch or Tag Creation and Pull Request radio buttons under the individual events as mentioned in image below.
[Note] If you select Branch or Tag Creation, it will work for the Tag Creation mechanism as well.
After selecting the respective options, click on the generate the webhook button to create a webhook for your respective repository.
If using Bitbucket Cloud - If you are using Bitbucket cloud as your git provider, you need to create a webhook for that as we created for Github in the above section. Follow the steps to create webhook -
Go to Repository Settings on left sidebar of repository window
Click on Webhooks and then click on Add webhook as shown in the image.
Give any appropriate title as per your choice and then copy-paste the url which you can get from Devtron Dashboard when you select Pull Request as source type in case of Bitbucket Cloud as Git Host.
Check the Pull Request events for which you want to trigger the webhook and then save the configurations.
Filters
Now, coming back to the Pull Request mechanism, you can observe we have the option to add filters. In a single repository we have multiple PRs generated, so to have the exact PR for which you want to build the CI Pipeline, we have this feature of filters.
You can add a few filters which can be seen in the dropdown to sort the exact PR which you want to use for building the pipeline.
Below are the details of different filters which you can use as per your requirement. Please select any of the filters and pass the value in regex format as one has already given for example and then click on Create Pipeline.
Devtron uses regexp library, view . You can test your custom regex from .
The third option i.e, Tag Creation. In this mechanism you need to provide the tag name or author to specify the exact tag for which you want to build the CI Pipeline. To work with this feature as well, you need to configure the webhook for either Github or Bitbucket as we did in the previous mechanism i.e, Pull Request.
In this process as well you can find the option to filter the specific tags with certain filter parameters. Select the appropriate filter as per your requirement and pass the value in form of regex, one of the examples is already given.
Select the appropriate filter and pass the value in the form of regex and then click on Create Pipeline.
When you click on the advanced options button which can be seen at the bottom-left of the screen, you can see some more configuration options which includes pipeline execution, stages and scan for vulnerabilities.
There are 3 dropdowns given below:
Pre-build
Docker build
Post-build
(a) Pre-build
This section is used for those steps which you want to execute before building the Docker image. To add a Pre-build stage, click on Add Stage and provide a name to your pre-stage and write your script as per your requirement. These stages will run in sequence before the docker image is built. Optionally, you can also provide the path of the directory where the output of the script will be stored locally.
You can add one or more than one stage in a CI Pipeline.
(b) Docker build
Though we have the option available in the Docker build configuration section to add arguments in key-value pairs for the docker build image. But one can also provide docker build arguments here as well. This is useful, in case you want to override them or want to add new arguments to build your docker image.
(c) Post-build
The post-build stage is similar to the pre-build stage. The difference between the post-build stage and the pre-build stage is that the post-build will run when your CI pipeline will be executed successfully.
Adding a post-build stage is similar to adding a pre-build stage. Click on Add Stage and provide a name to your post-stage. Here you can write your script as per your requirement, which will run in sequence after the docker image is built. You can also provide the path of the directory in which the output of the script will be stored in the Remote Directory column. And this is optional to fill because many times you run scripts that do not provide any output.
NOTE:
(a) You can provide pre-build and post-build stages via the Devtron tool’s console or can also provide these details by creating a file devtron-ci.yaml inside your repository. There is a pre-defined format to write this file. And we will run these stages using this YAML file. You can also provide some stages on the Devtron tool’s console and some stages in the devtron-ci.yaml file. But stages defined through the Devtron dashboard are first executed then the stages defined in the devtron-ci.yaml file.
(b) The total timeout for the execution of the CI pipeline is by default set as 3600 seconds. This default timeout is configurable according to the use-case. The timeout can be edited in the configmap of the orchestrator service in the env variable env:"DEFAULT_TIMEOUT" envDefault:"3600"
Scan for vulnerabilities adds a security feature to your application. If you enable this option, your code will be scanned for any vulnerabilities present in your code. And you will be informed about these vulnerabilities. For more details please check doc
You have provided all the details required to create a CI pipeline, now click on Create Pipeline.
You can also update any configuration of an already created CI Pipeline, except the pipeline name. The pipeline name can not be edited.
Click on your CI pipeline, to update your CI Pipeline. A window will be popped up with all the details of the current pipeline.
Make your changes and click on Update Pipeline at the bottom to update your Pipeline.
You can only delete CI pipeline if you have no CD pipeline created in your workflow.
To delete a CI pipeline, go to the App Configurations and then click on Workflow editor
Click on Delete Pipeline at the bottom to delete the CD pipeline
Users can run the test case using the Devtron dashboard or by including the test cases in the devtron.ci.yaml file in the source git repository. For reference, check:
The test cases given in the script will run before the test cases given in the devtron.ci.yaml
If one code is shared across multiple applications, Linked CI Pipeline can be used, and only one image will be built for multiple applications because if there is only one build, it is not advisable to create multiple CI Pipelines.
To create a Linked CI Pipeline, please follow the steps mentioned below :
Click on + New Build Pipeline button.
Select Linked CI Pipeline.
Select the application in which the source CI pipeline is present.
Select the source CI pipeline.
Provide a name for linked CI pipeline.
Click on Create Linked CI Pipeline button to create linked CI pipeline.
After creating a linked CI pipeline, you can create a CD pipeline. You cannot trigger build from linked CI pipeline, it can be triggered only from source CI pipeline. Initially you will not see any images to deploy in CD pipeline created from linked CI pipeline. Trigger build in source CI pipeline to see the images in CD pipeline of linked CI pipeline. After this, whenever you trigger build in source CI pipeline, the build images will be listed in CD pipeline of linked CI pipeline too.
You can use Devtron for deployments on Kubernetes while using your own CI tool such as Jenkins. External CI features can be used for cases where the CI tool is hosted outside the Devtron platform.
You can send the ‘Payload script’ to your CI tools such as Jenkins and Devtron will receive the build image every time the CI Service is triggered or you can use the Webhook URL which will build an image every time CI Service is triggered using Devtron Dashboard.
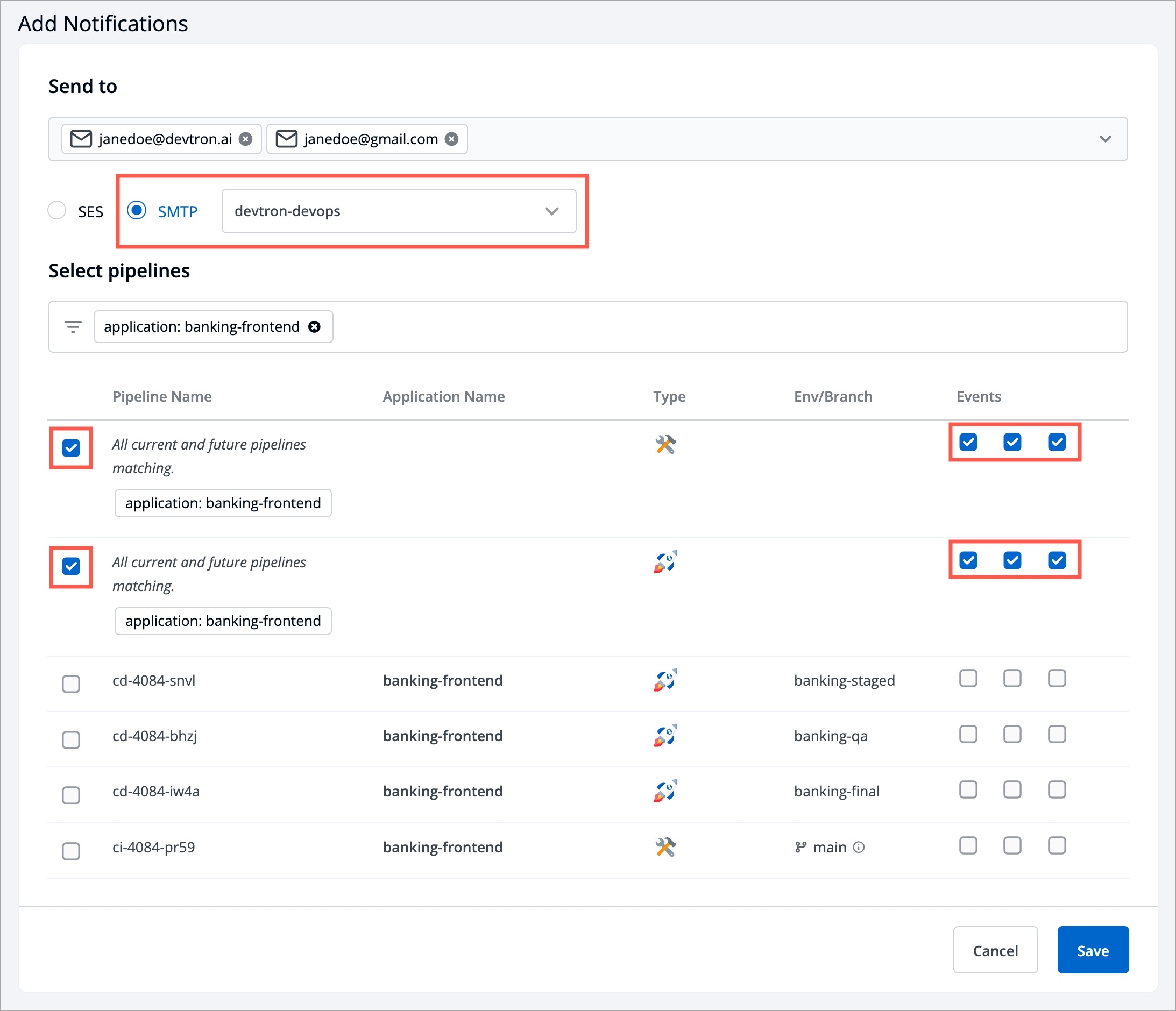
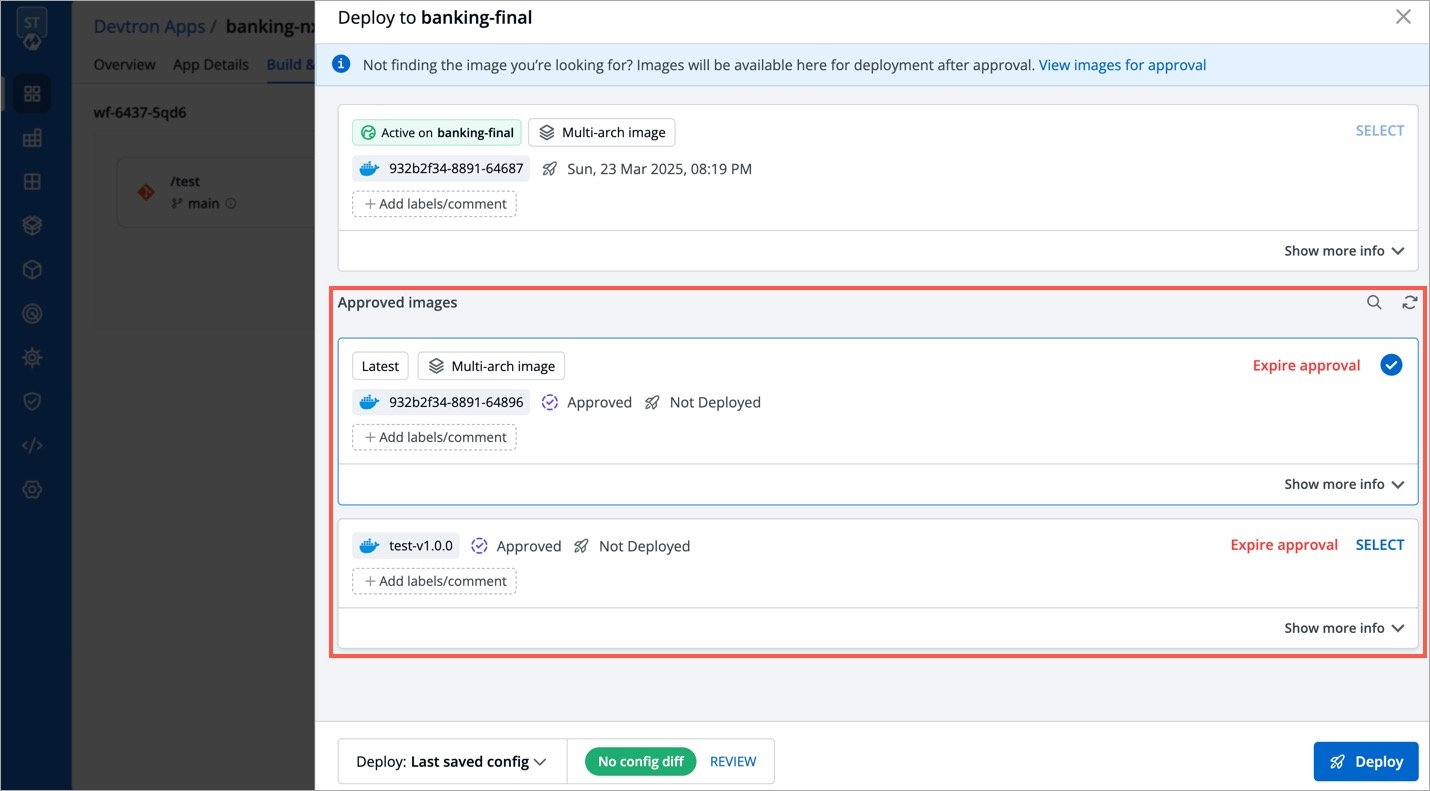
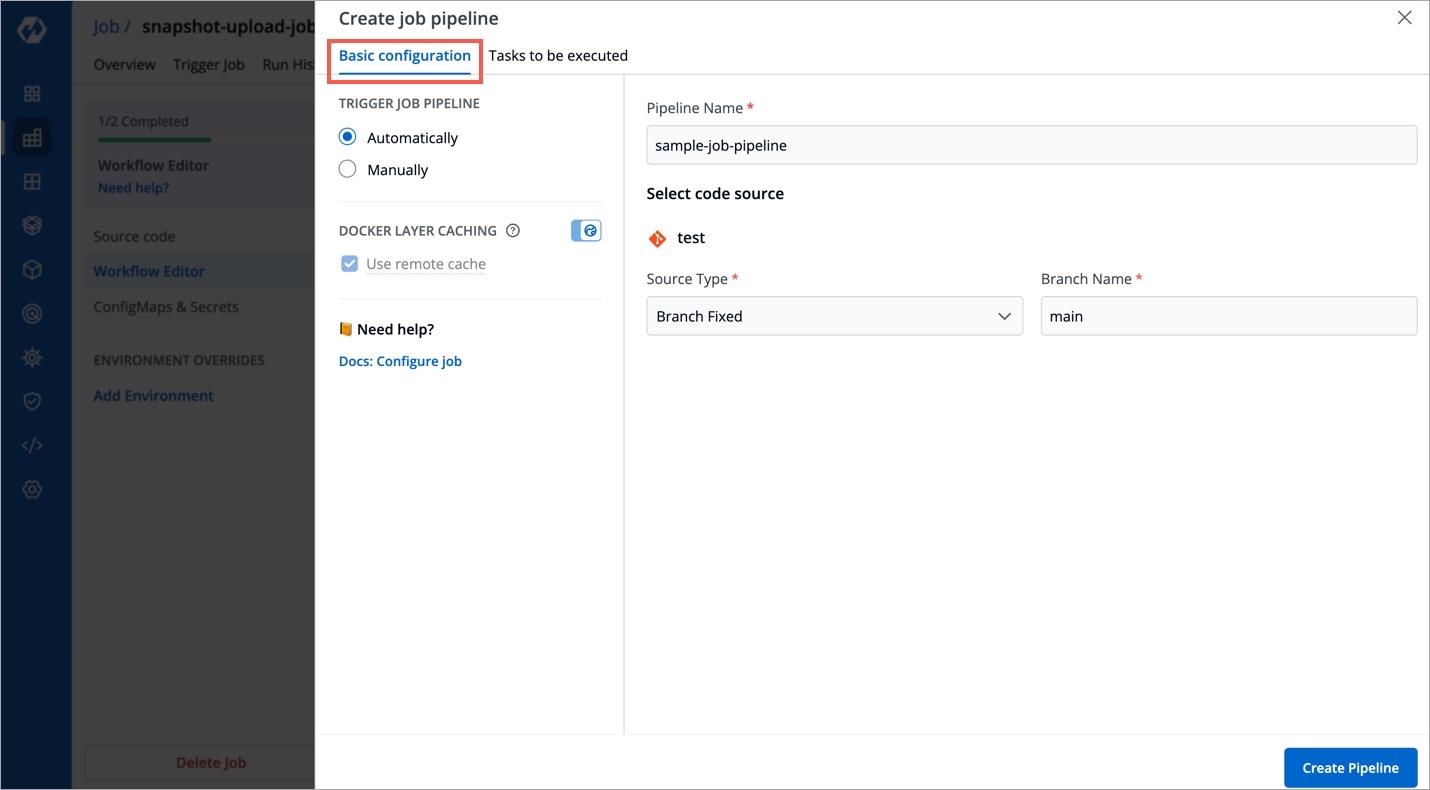
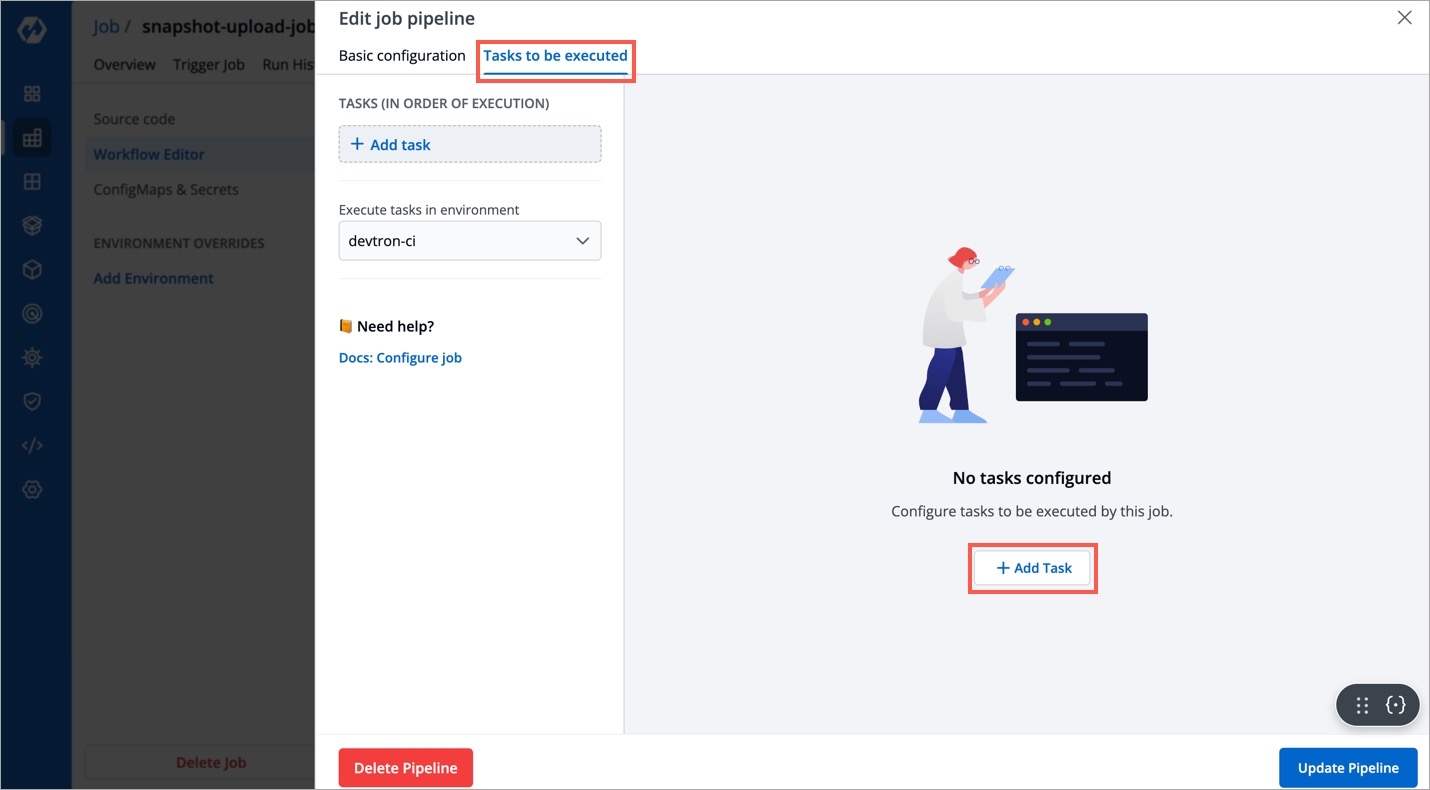
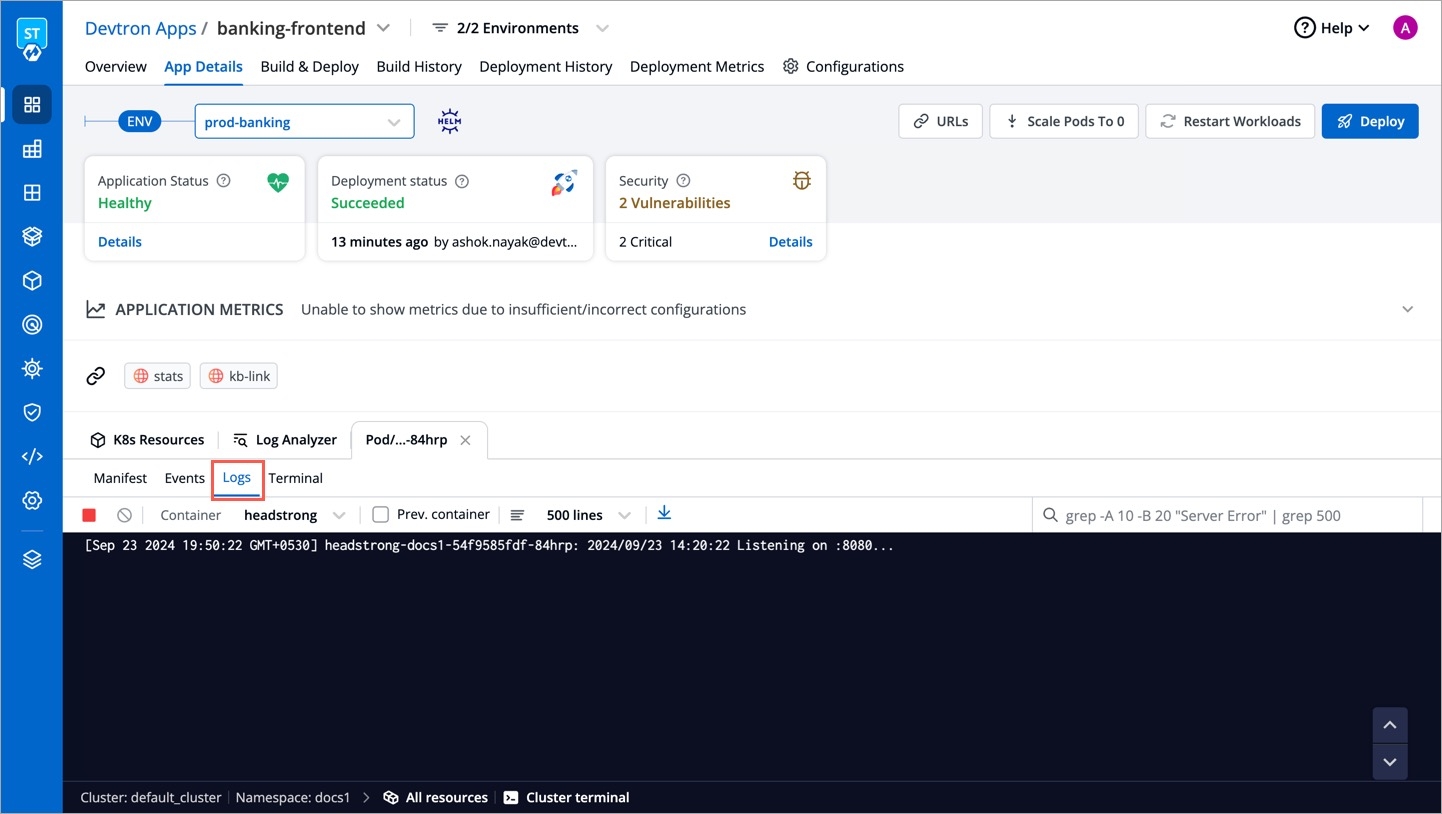
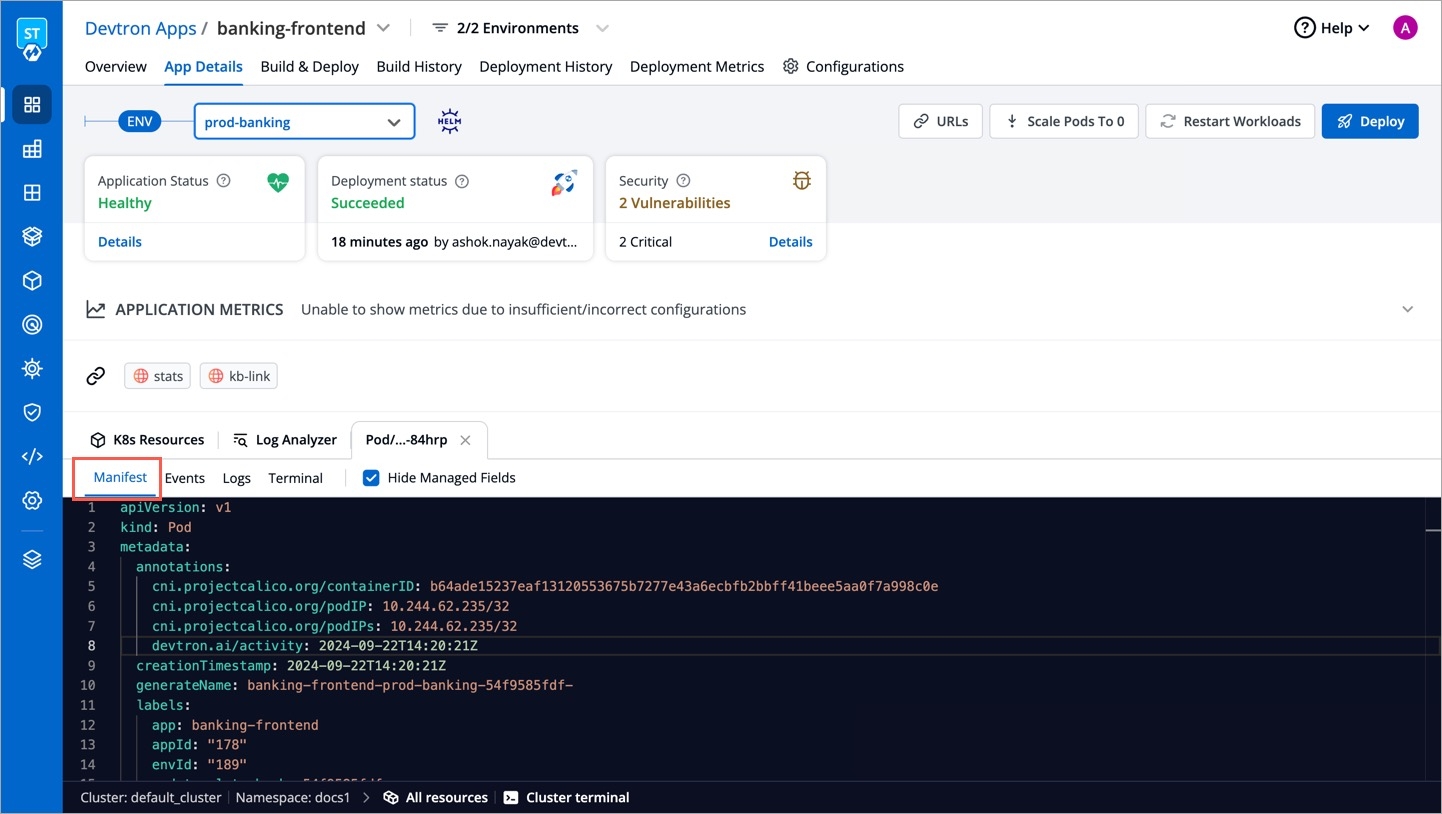
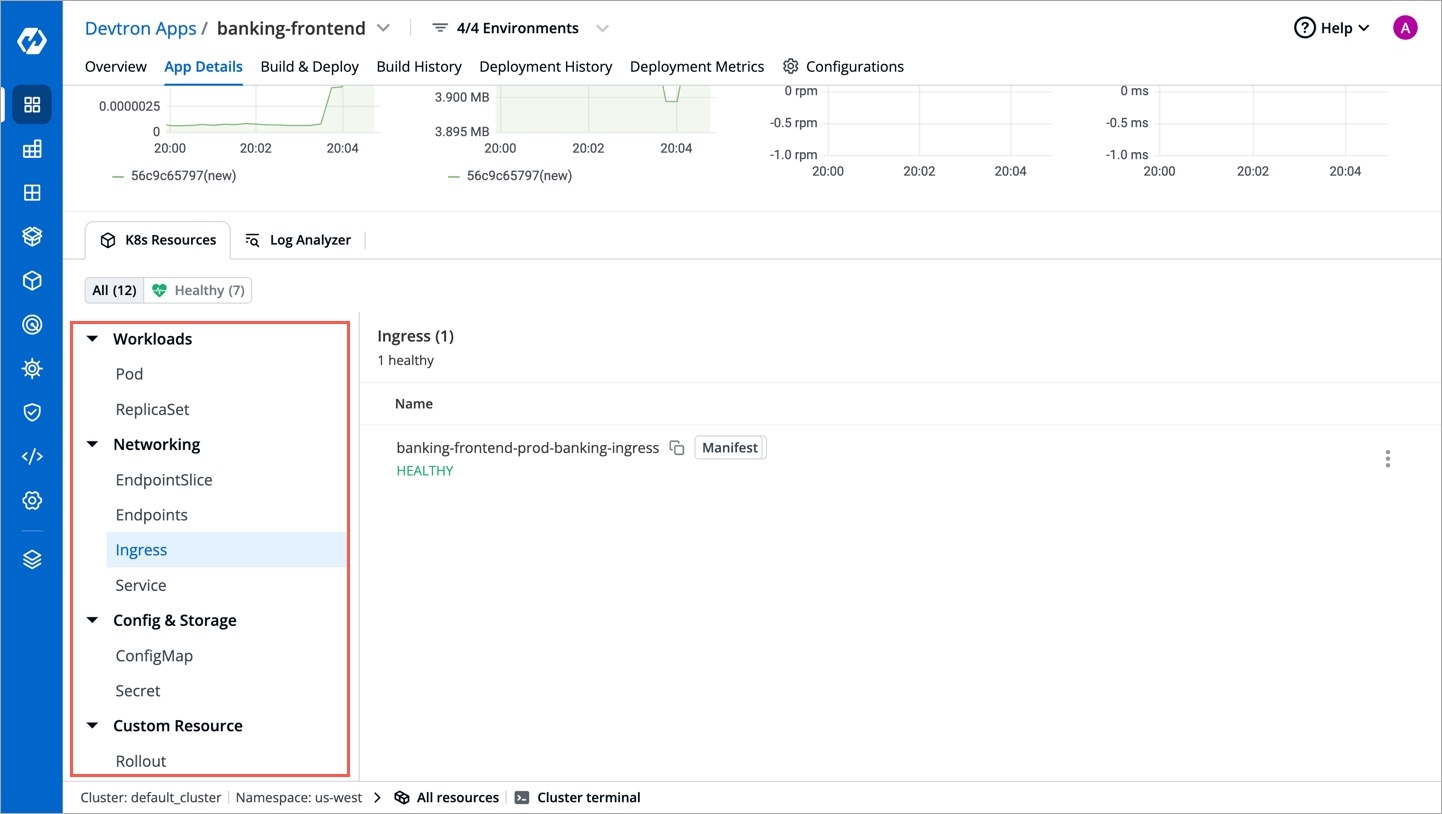
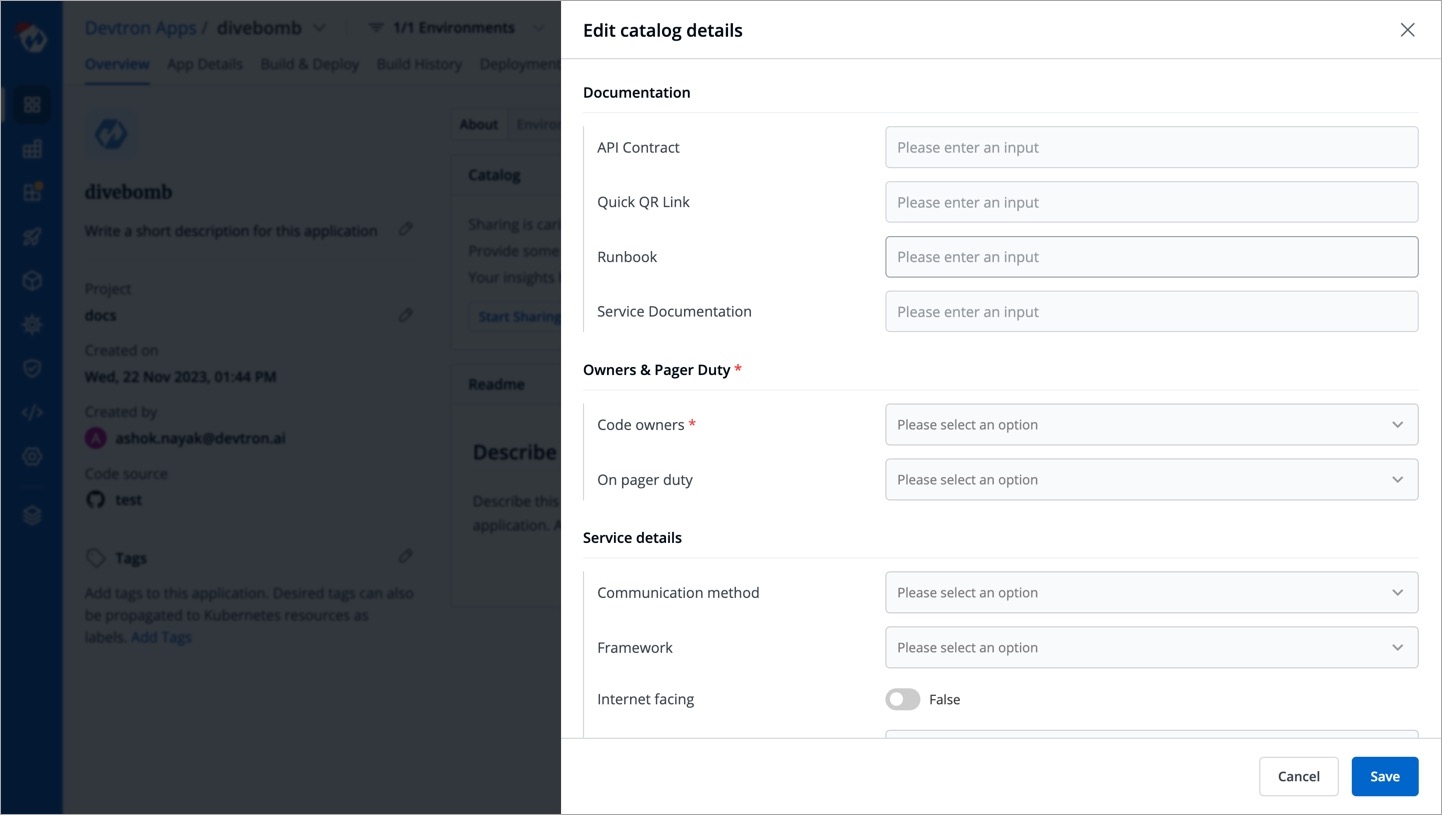
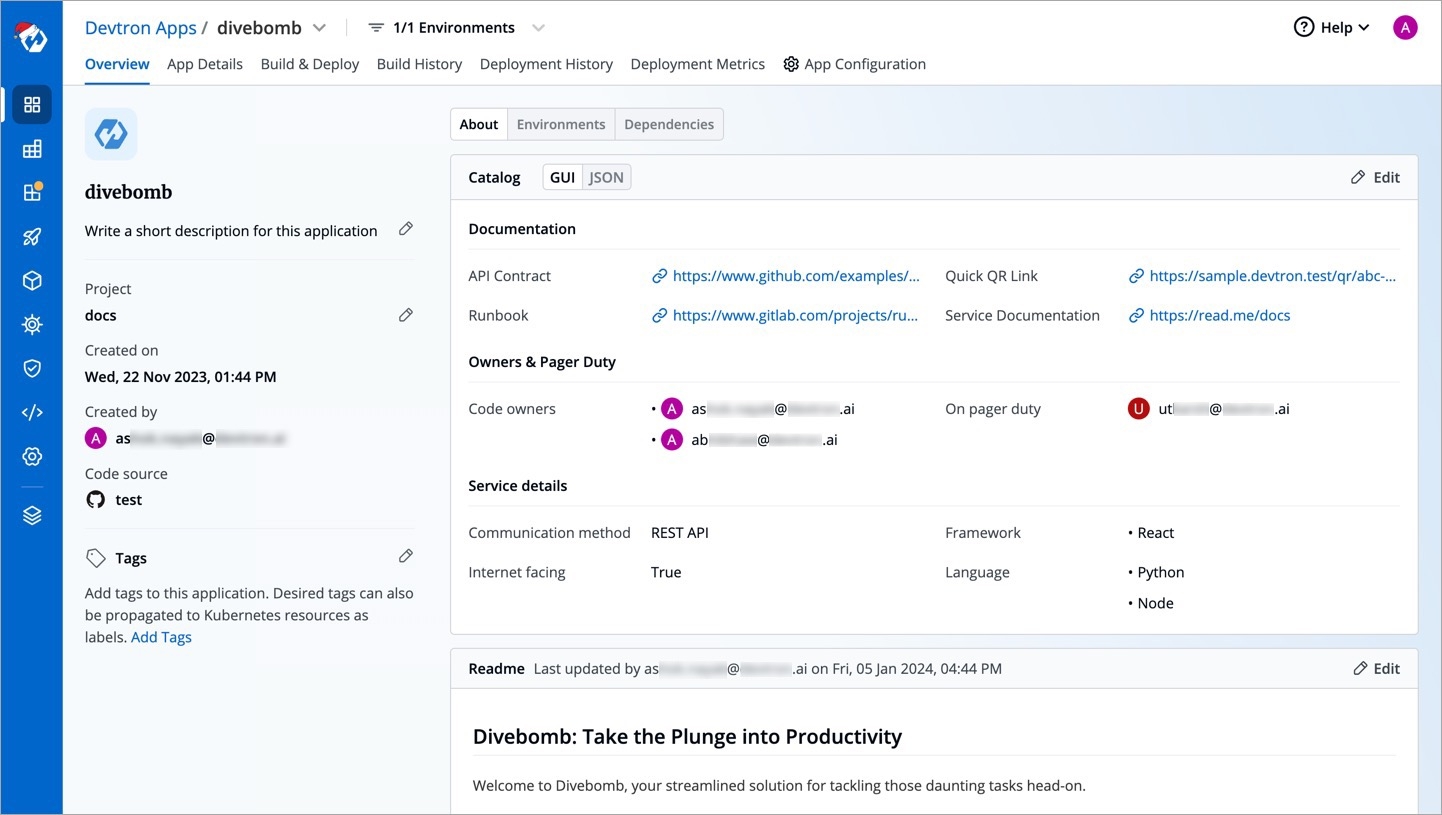
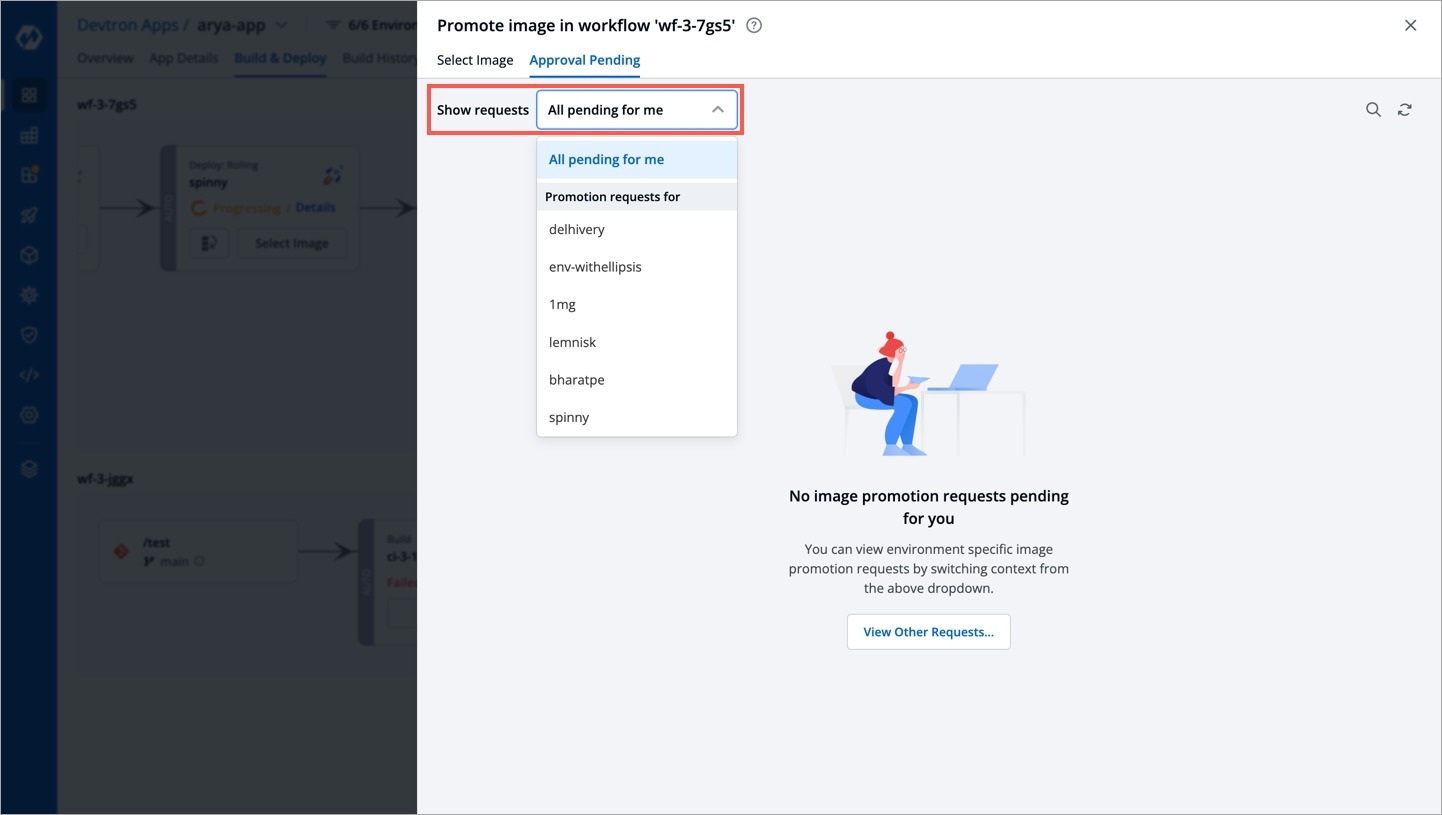
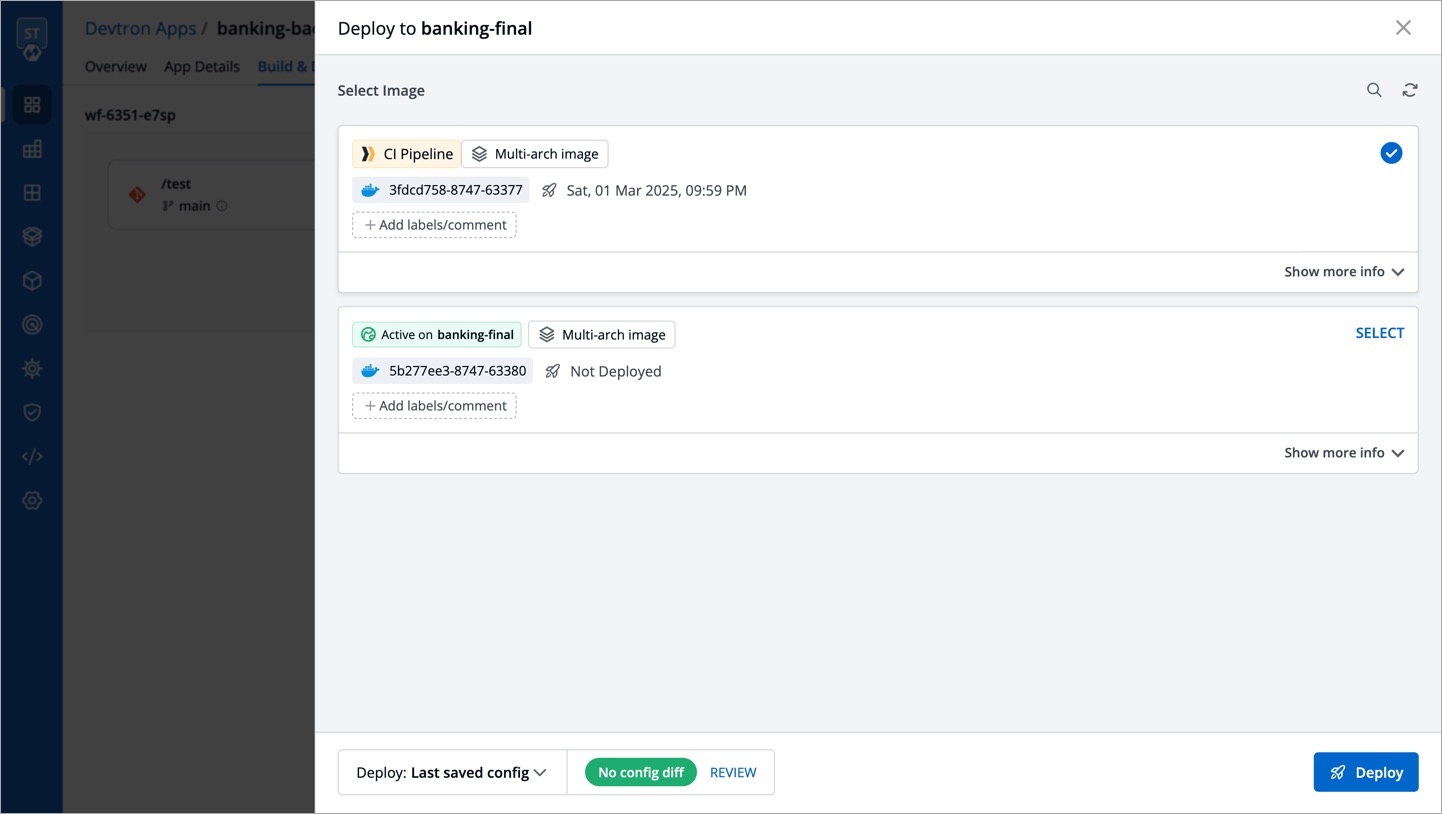
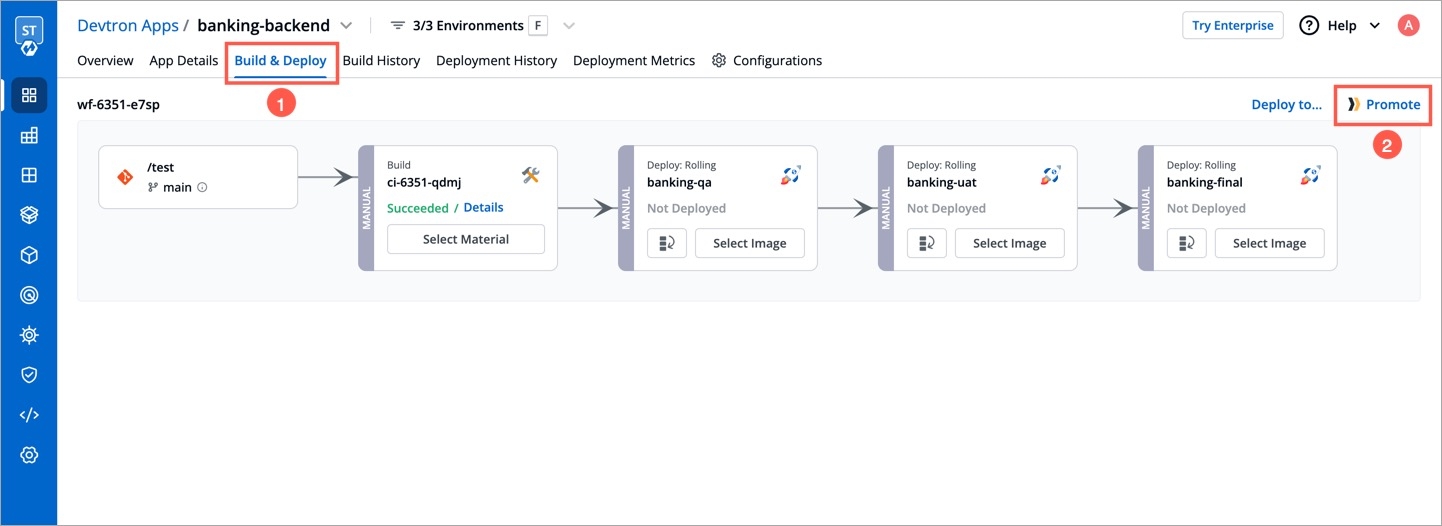
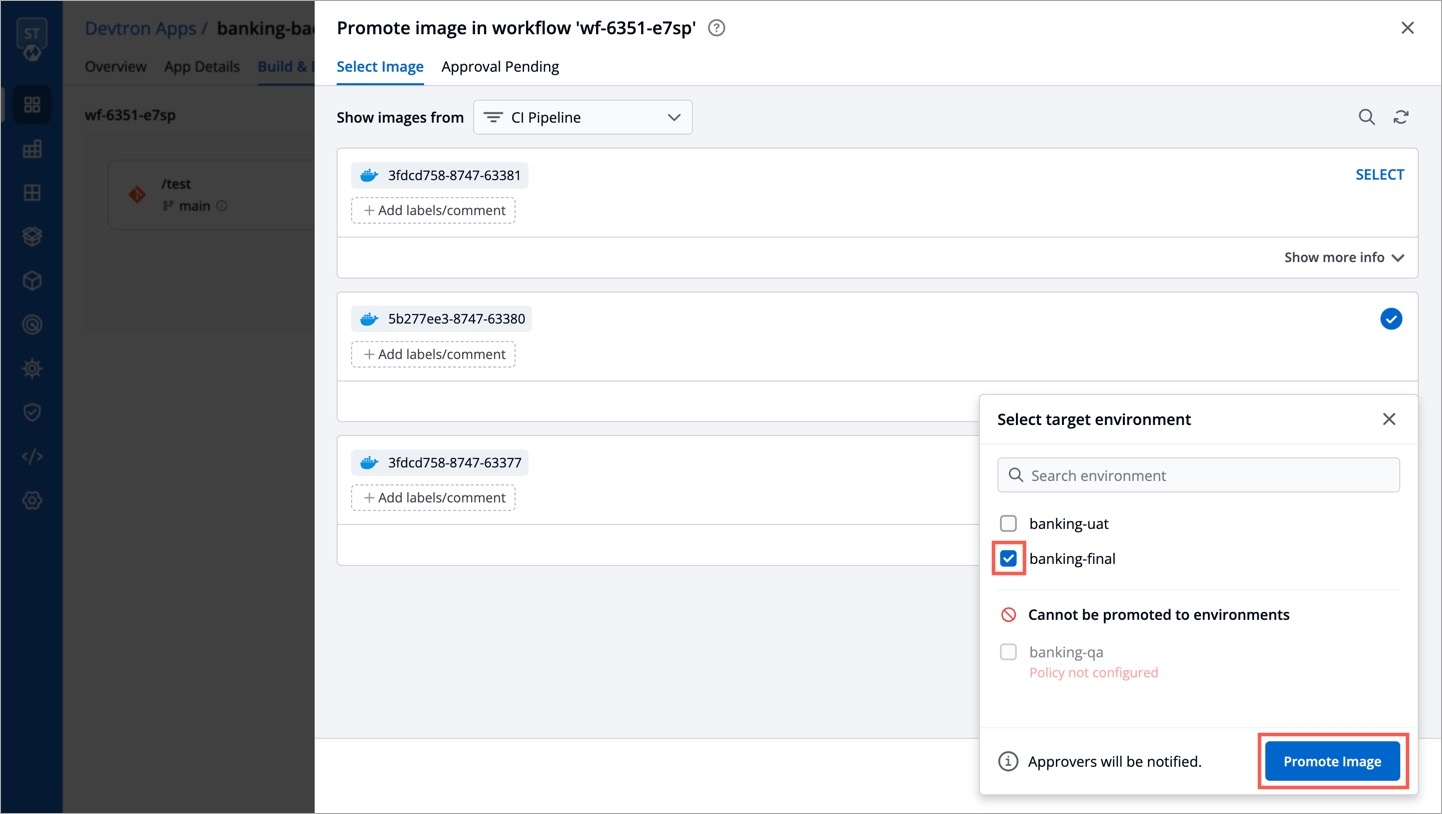
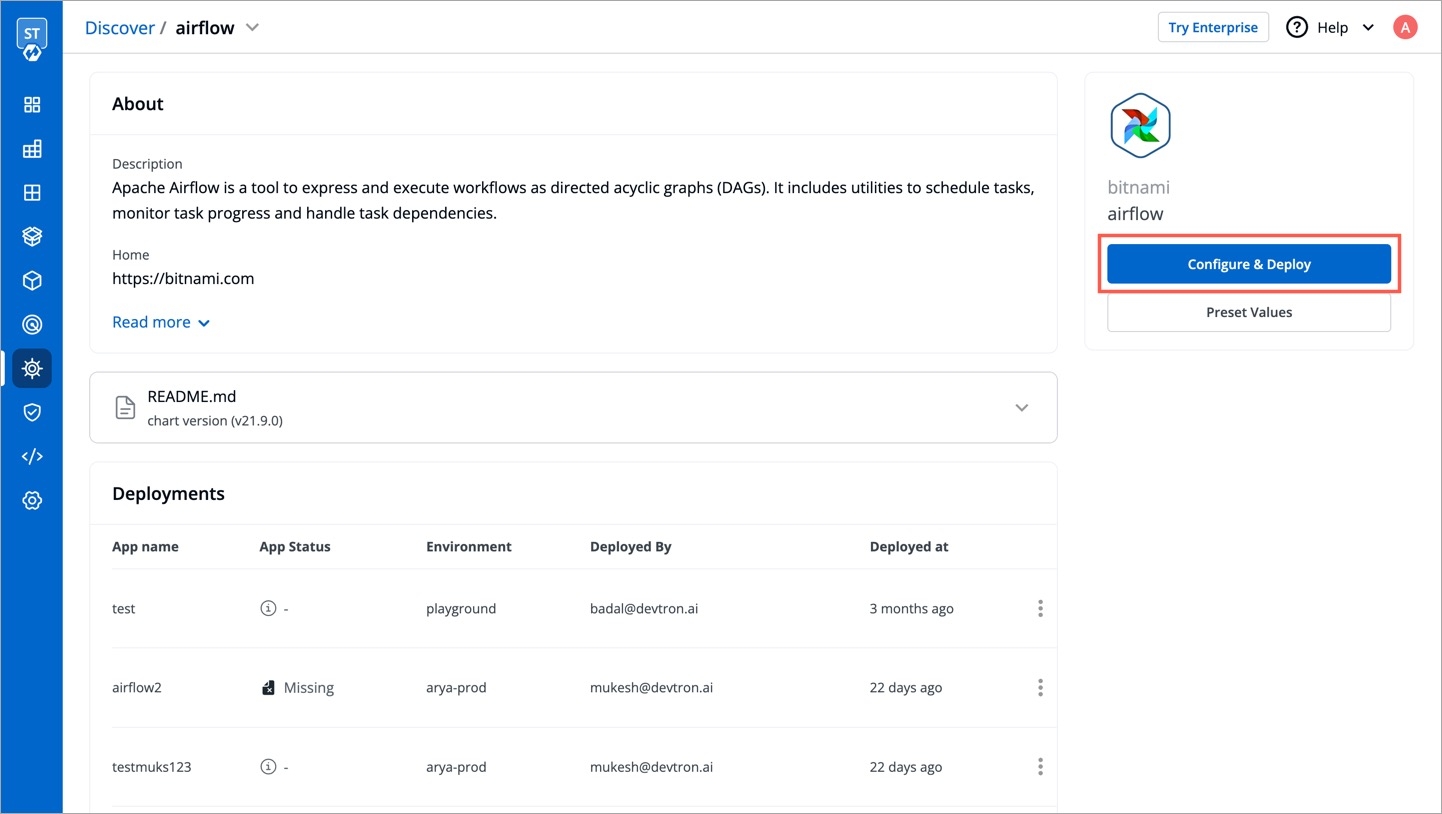
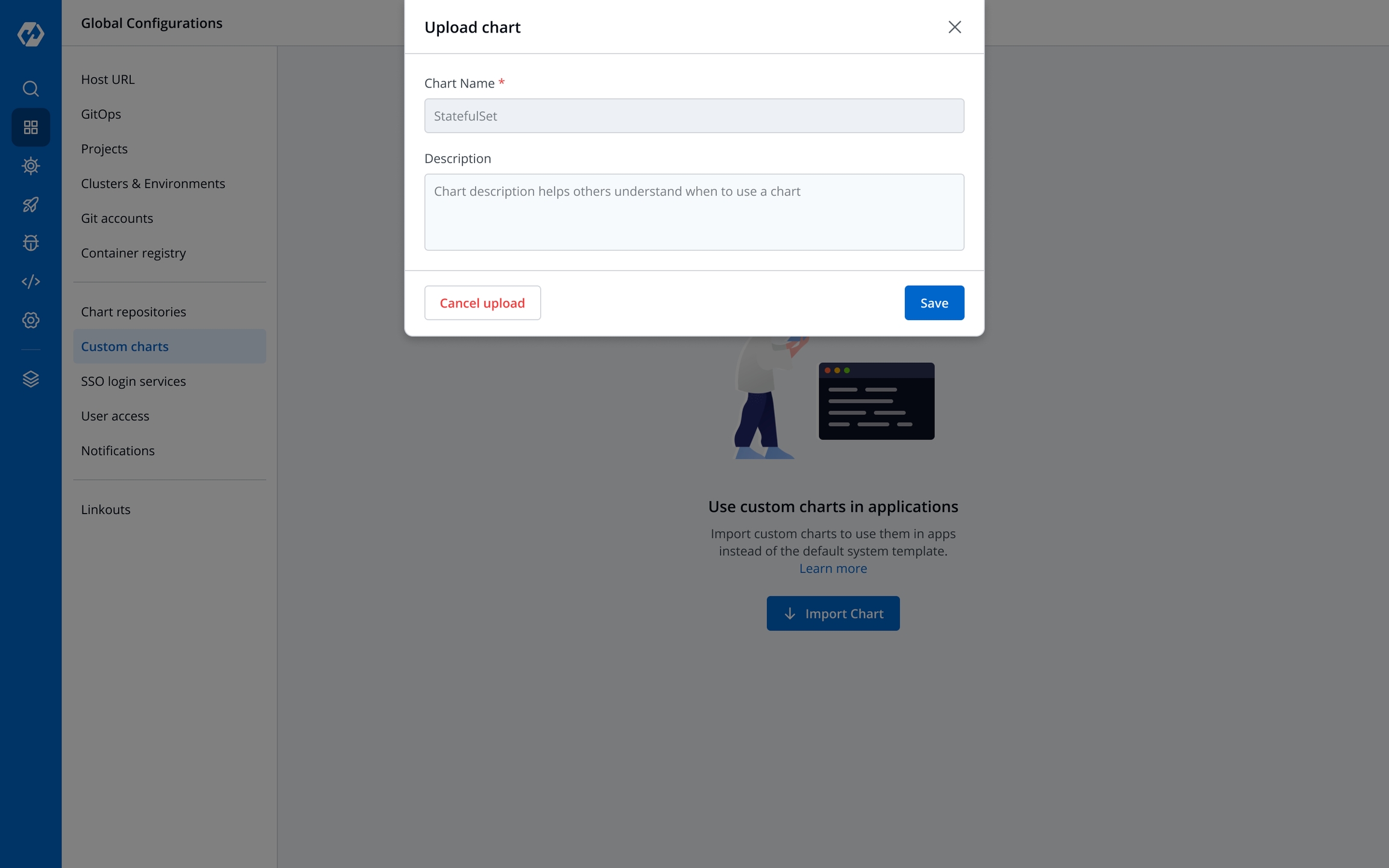
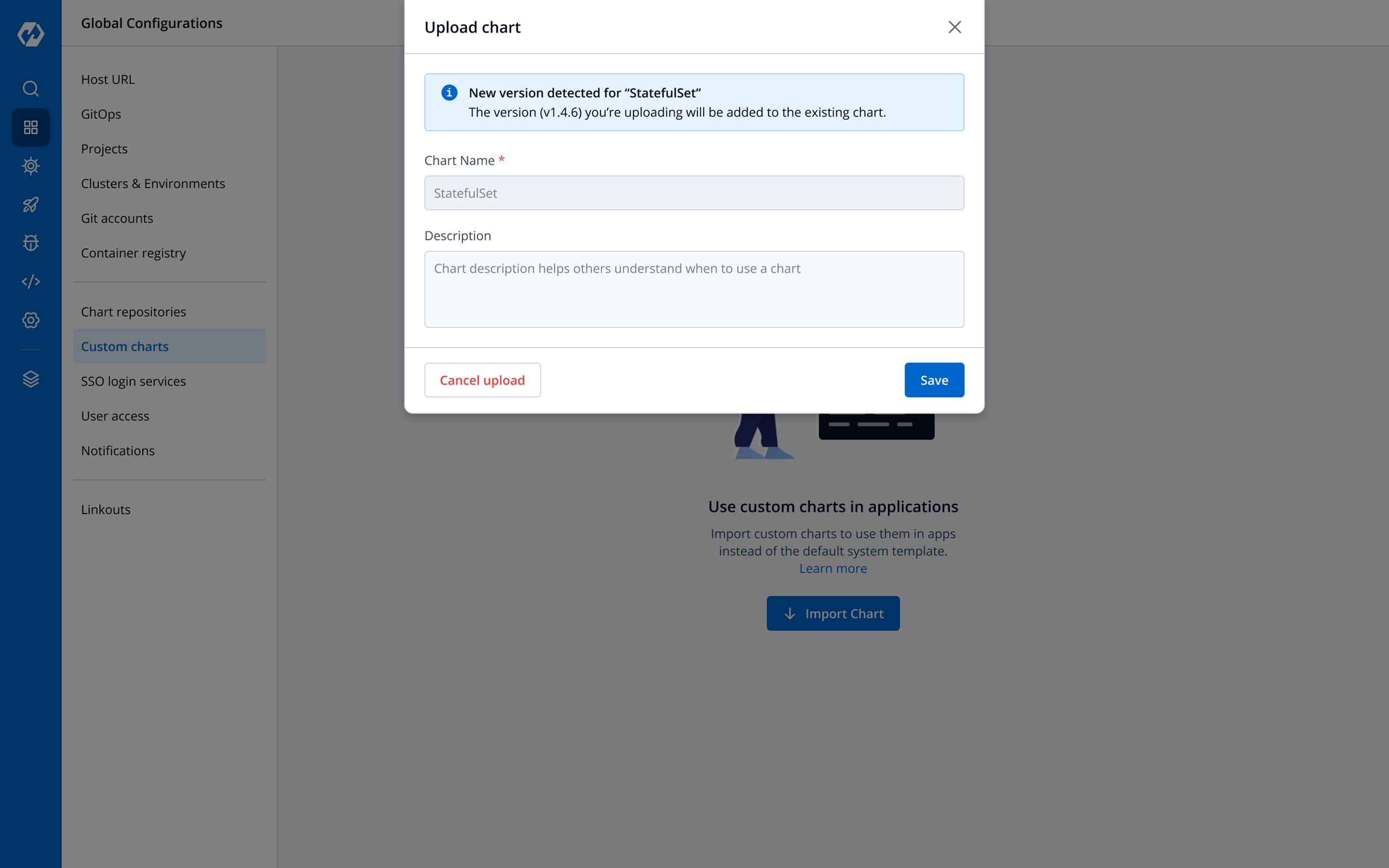
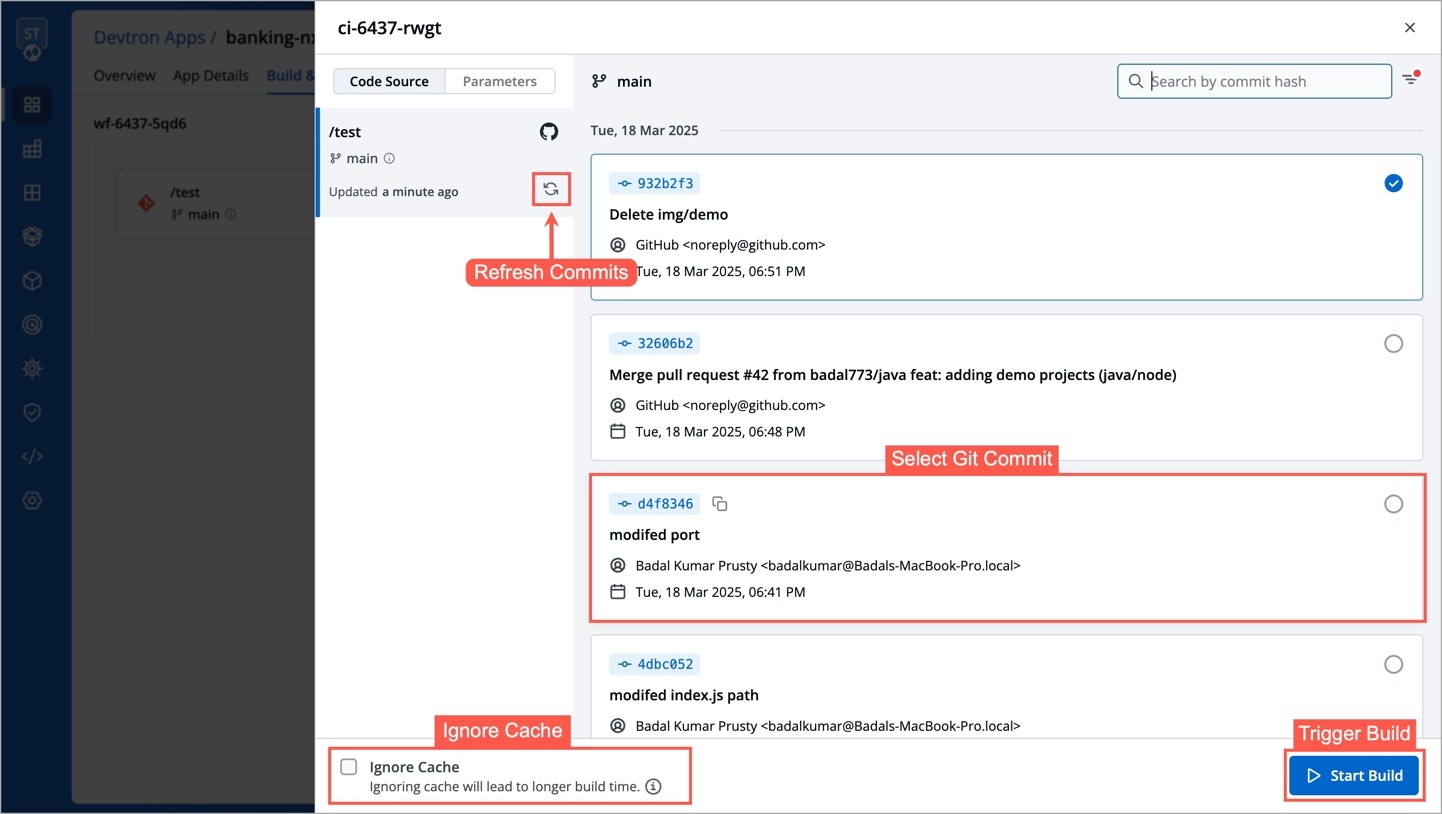
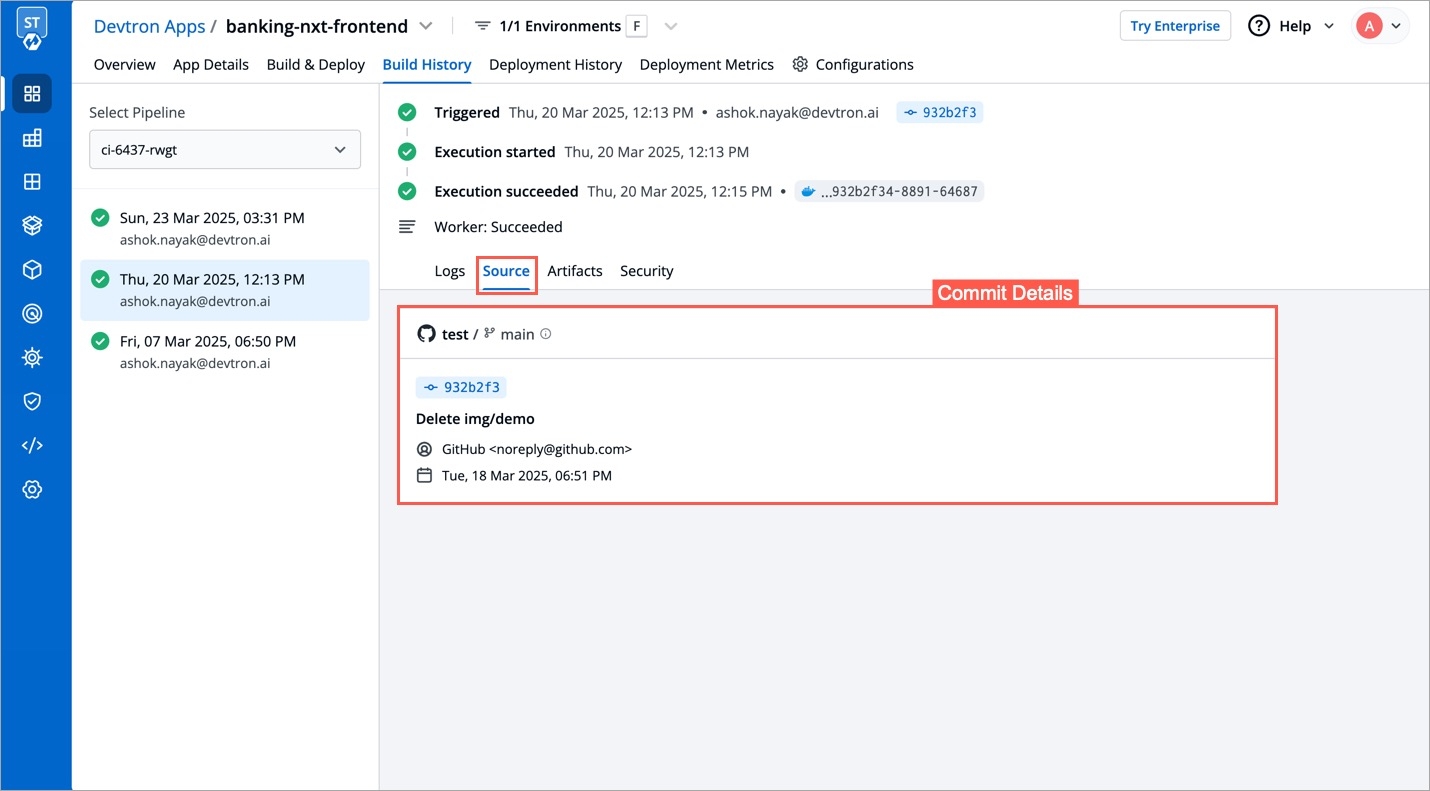
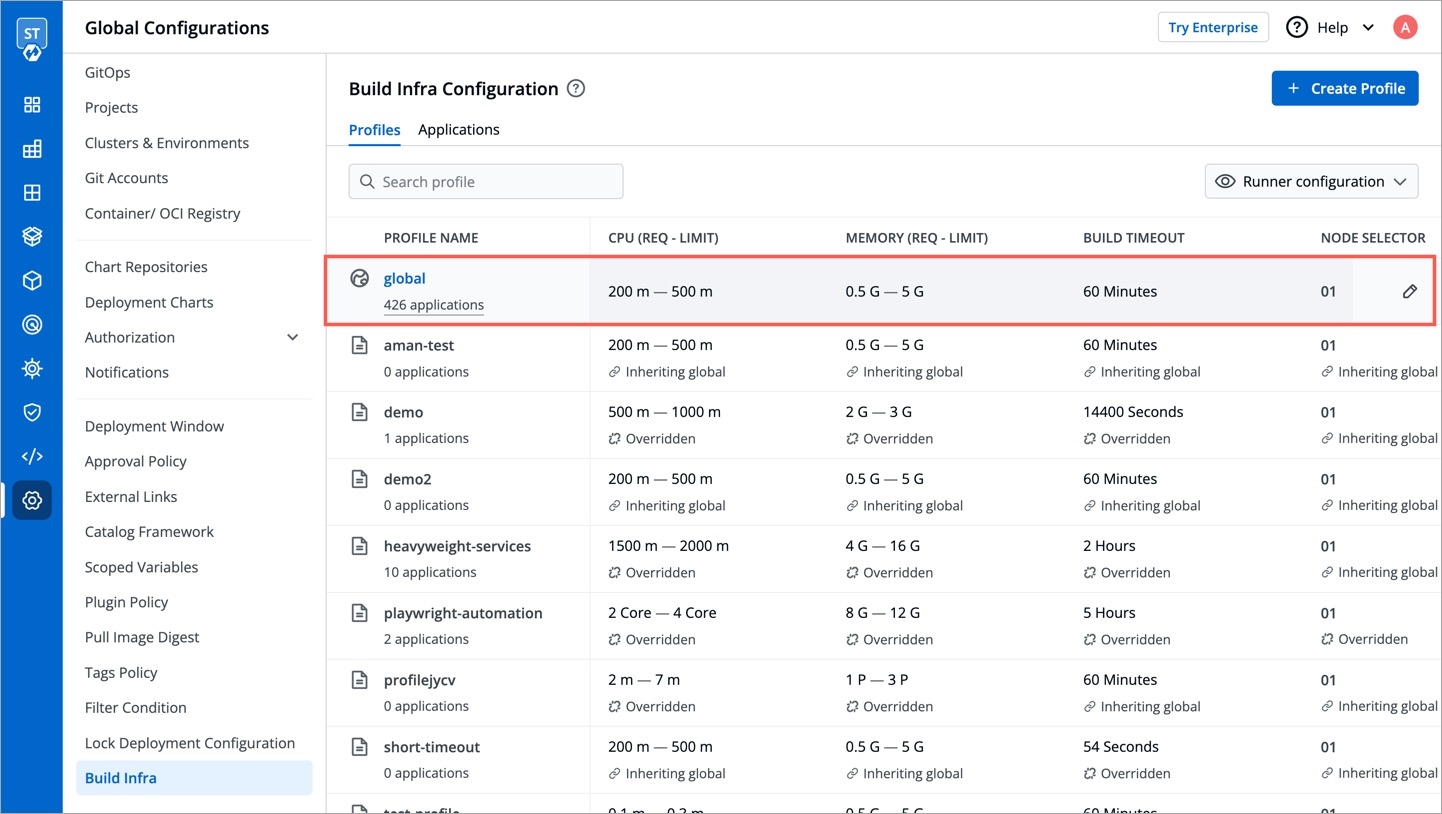
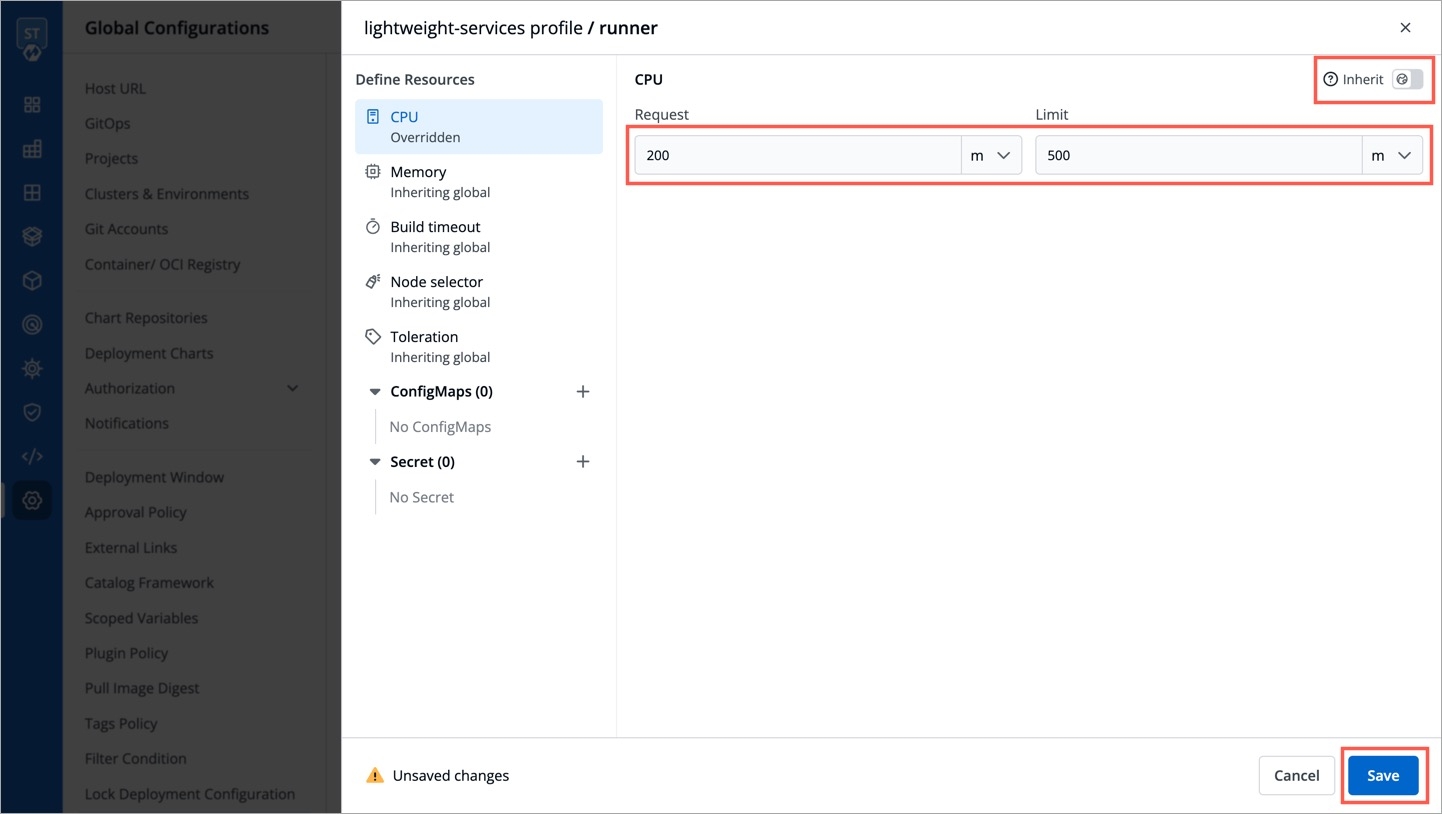
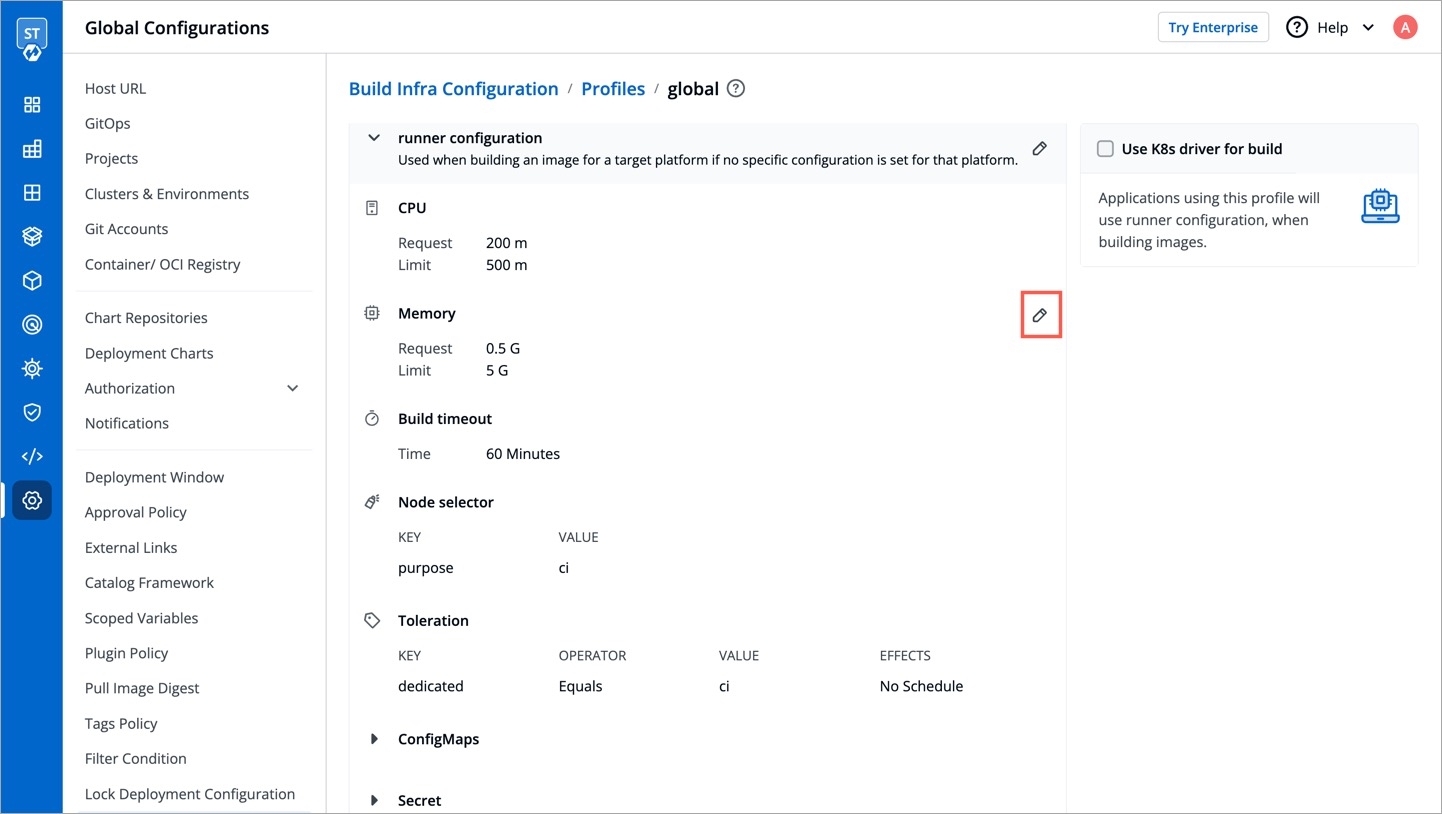
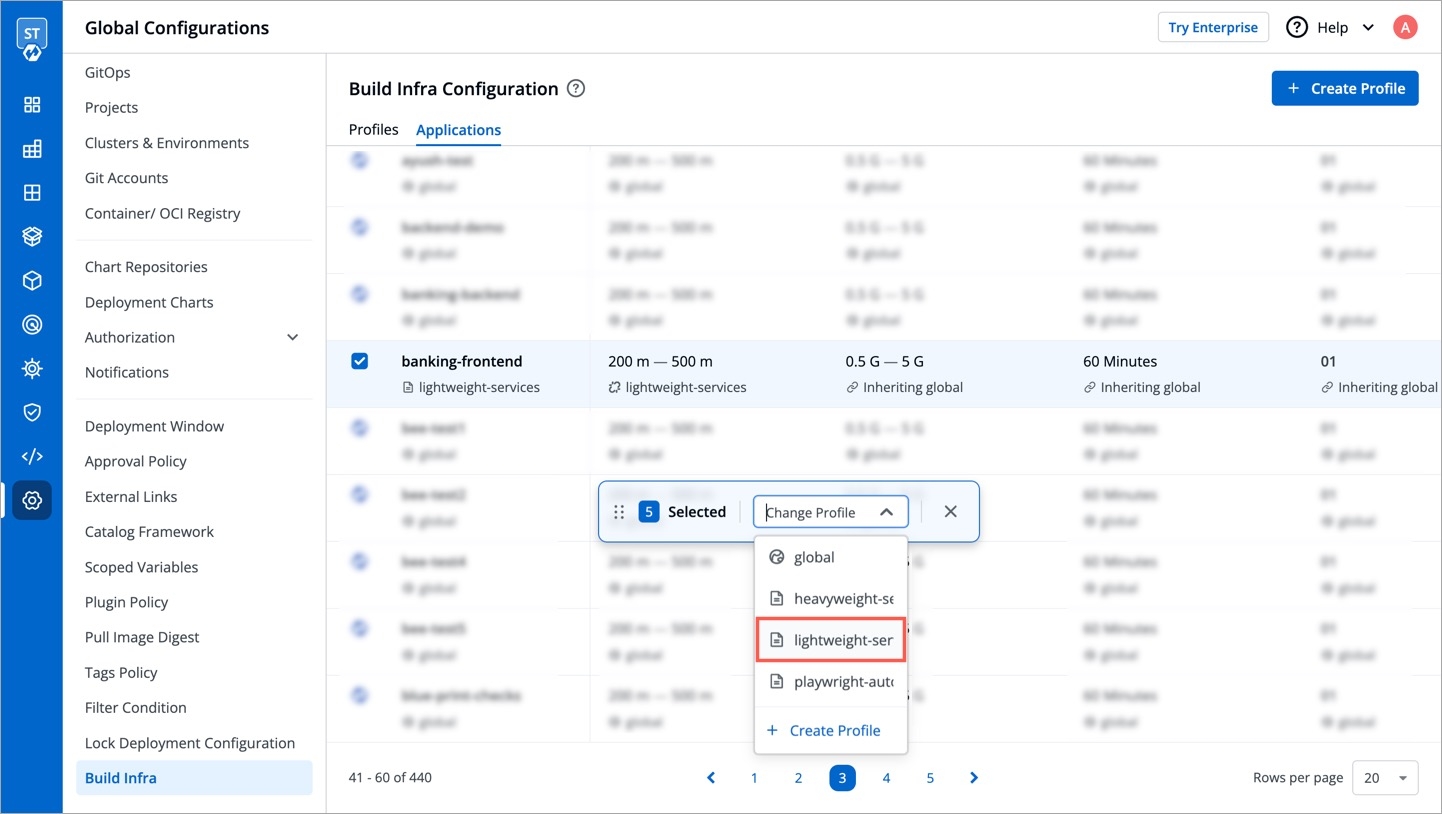
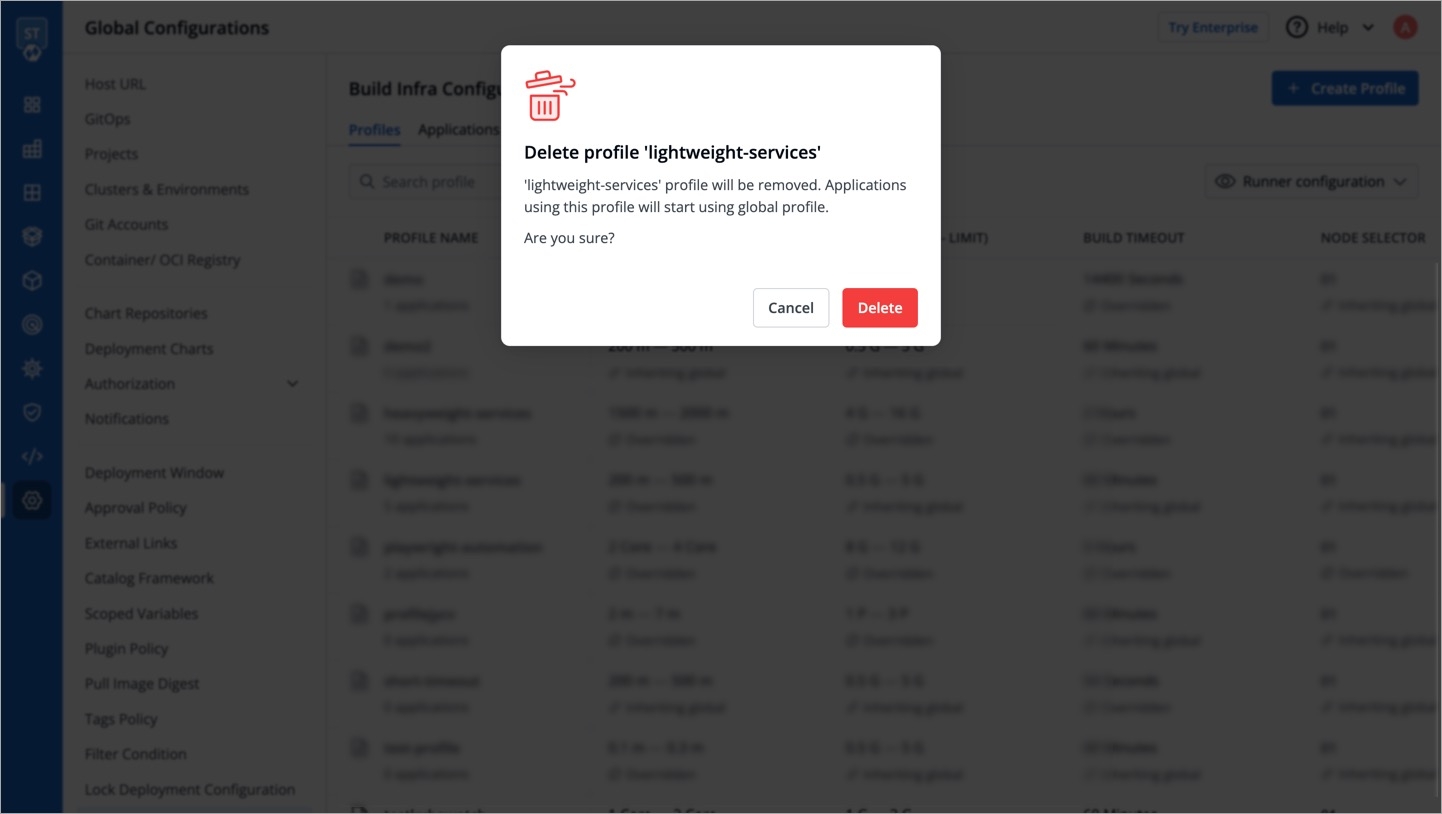
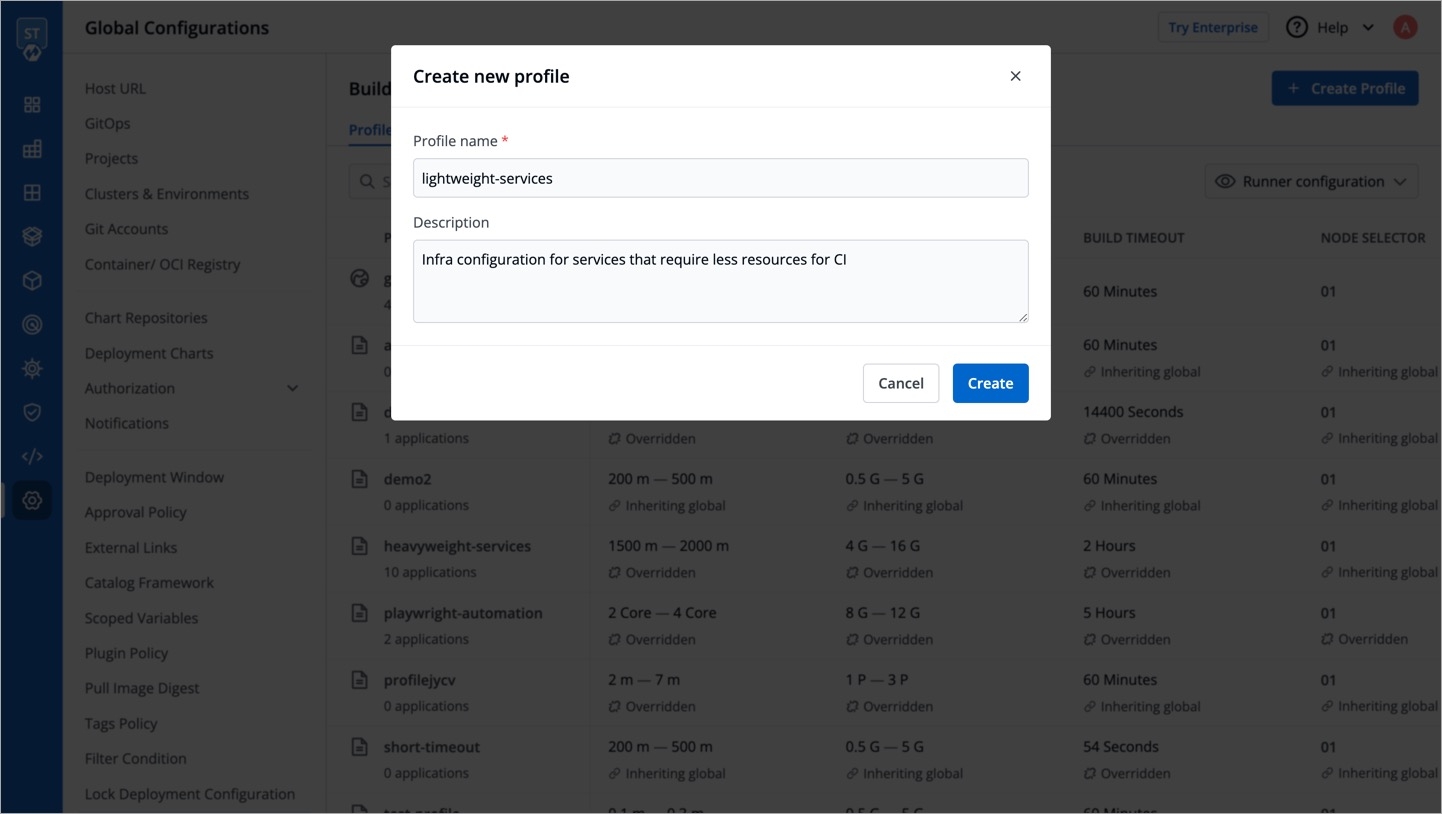
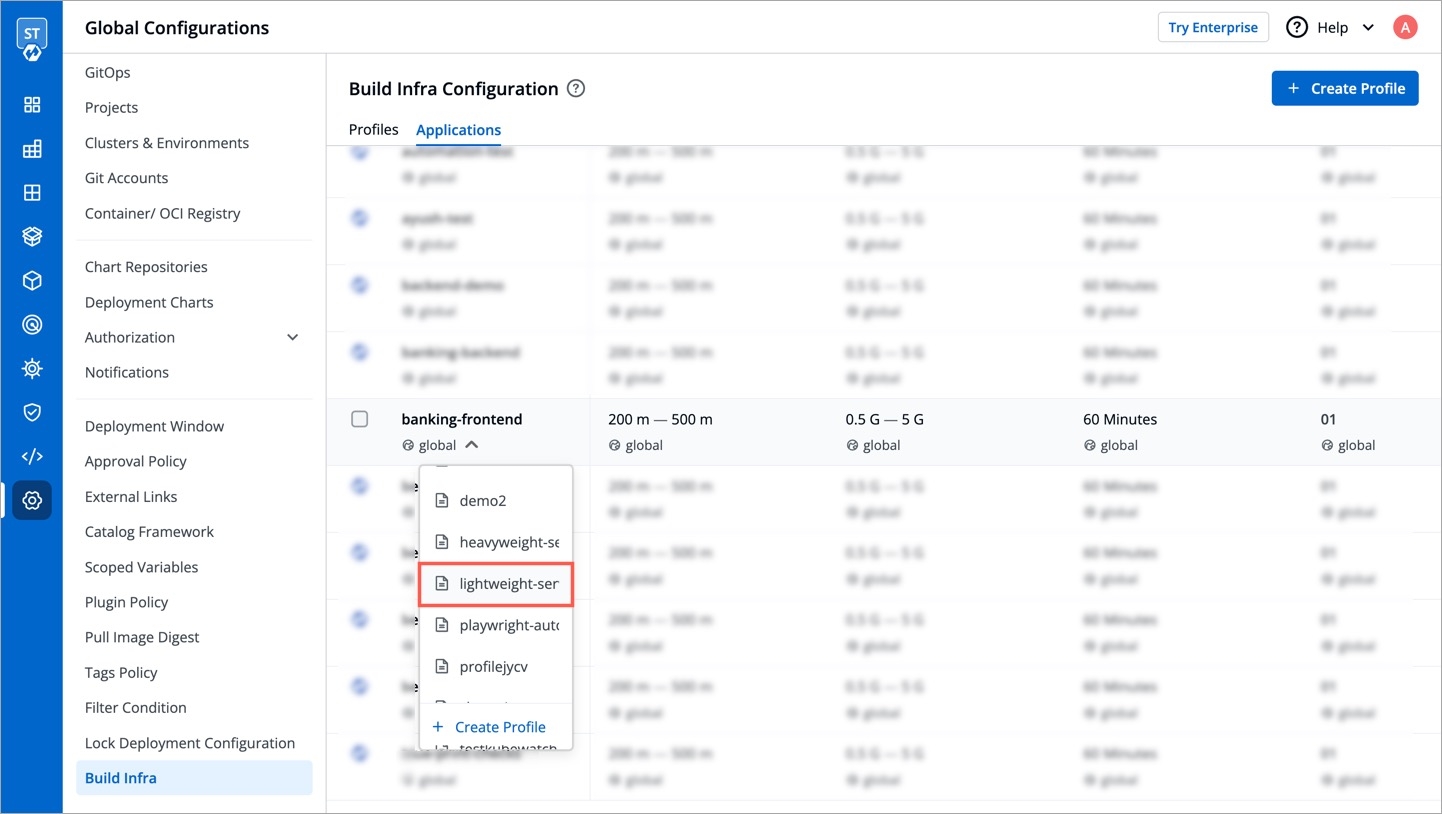
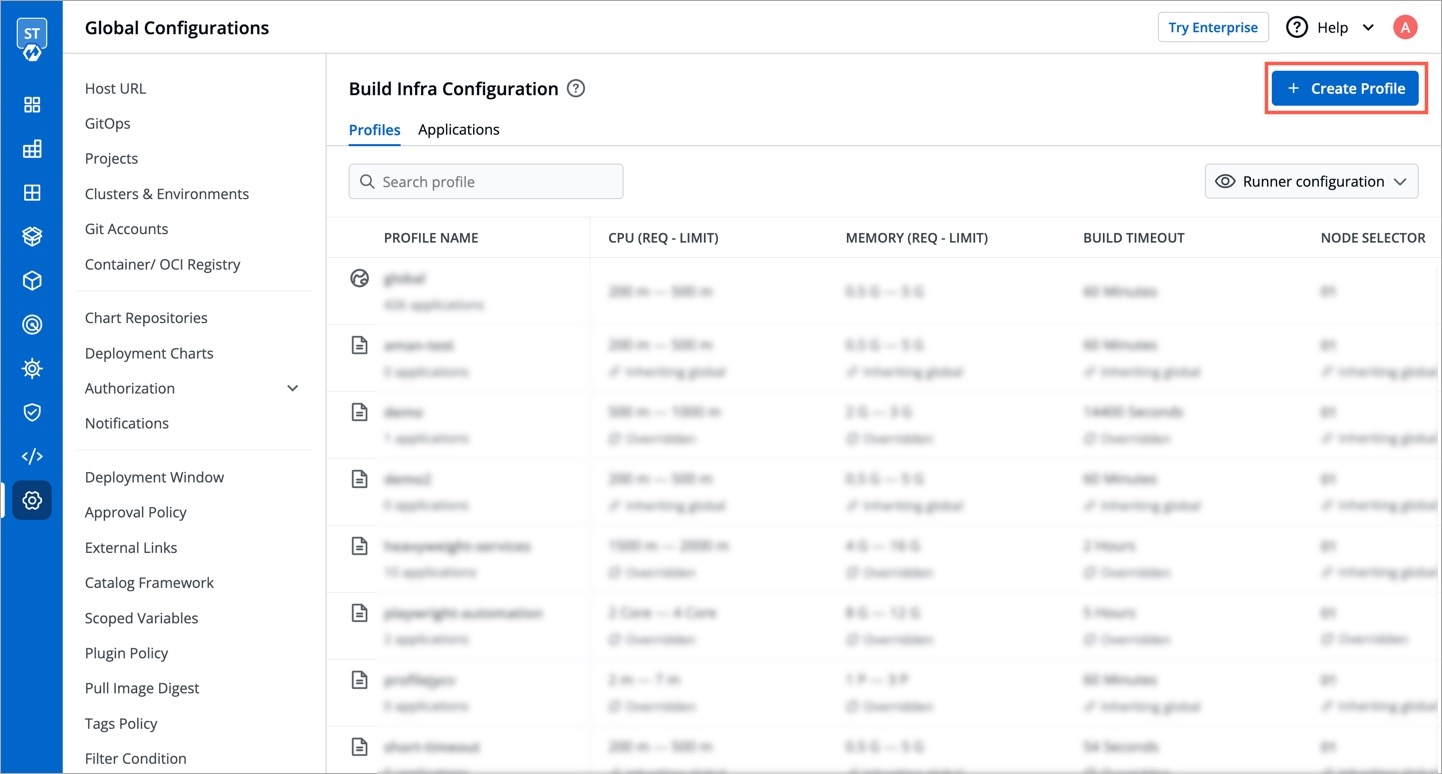
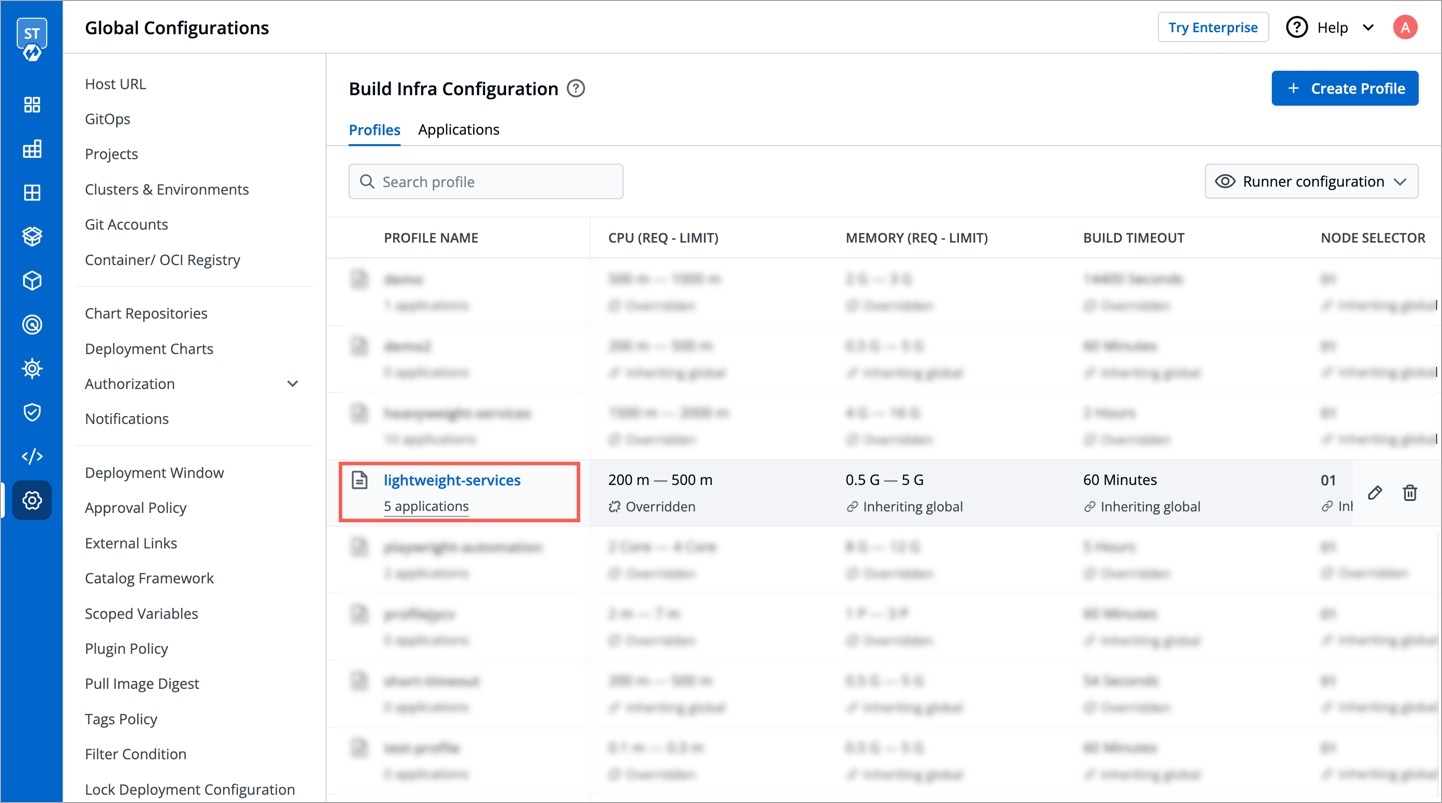
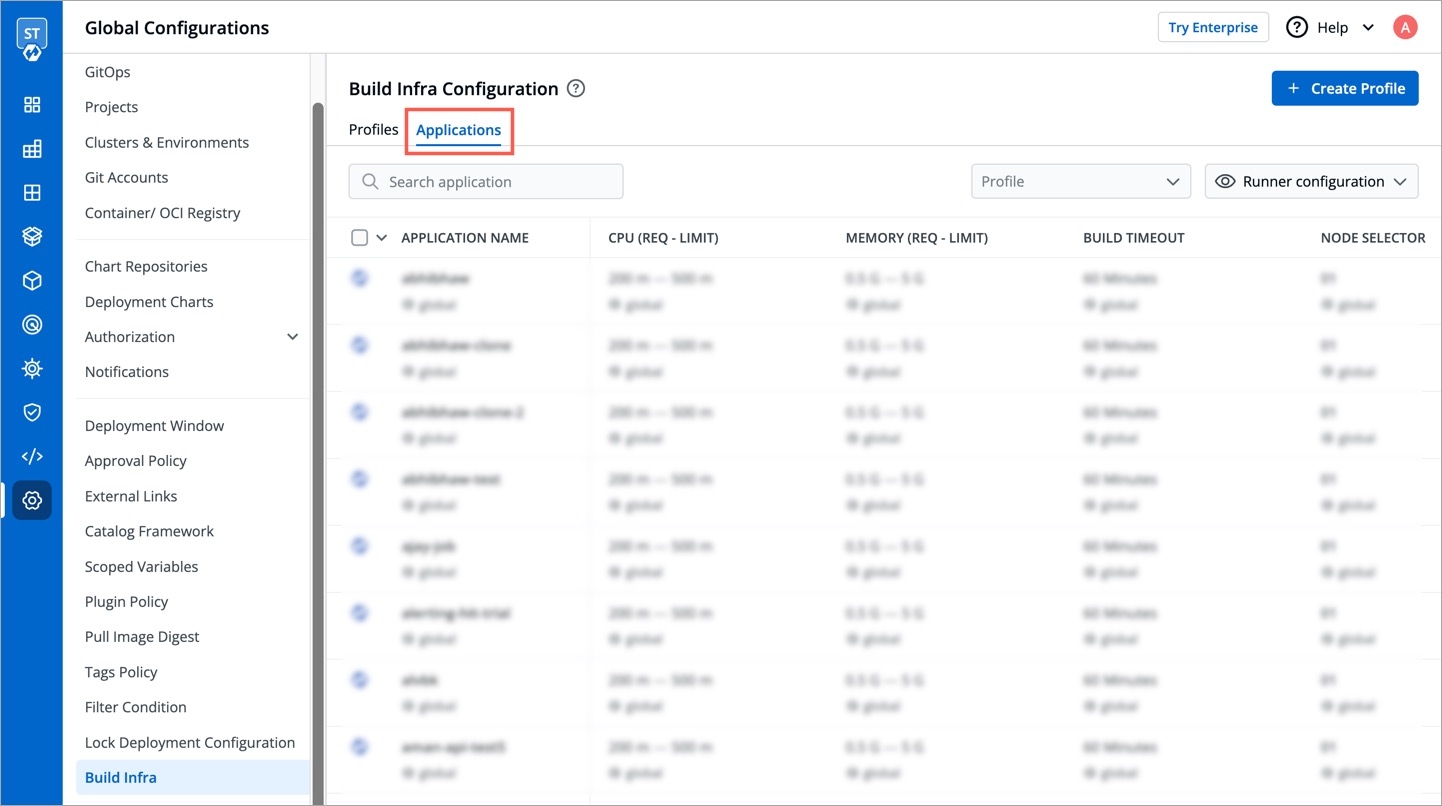
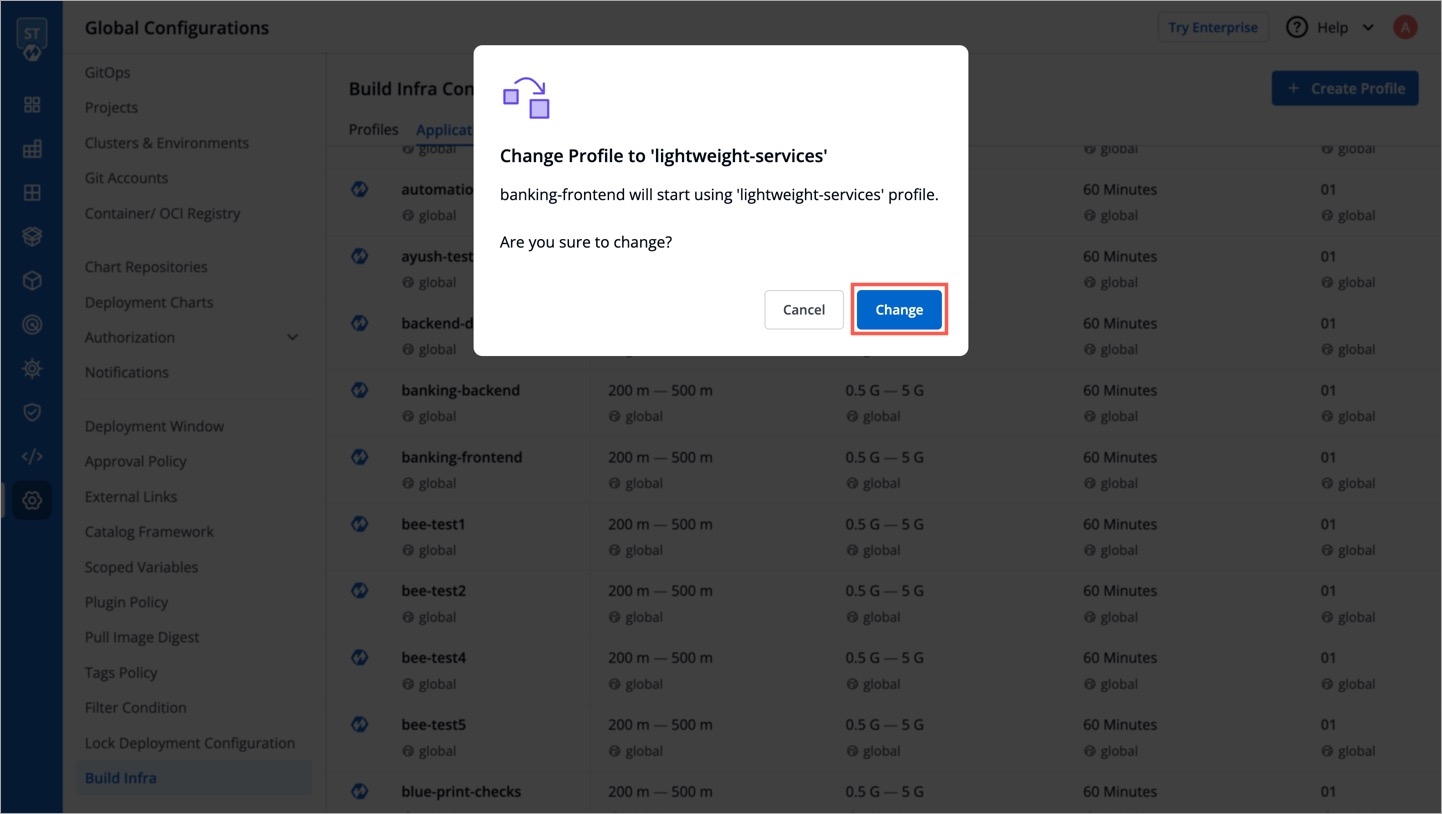
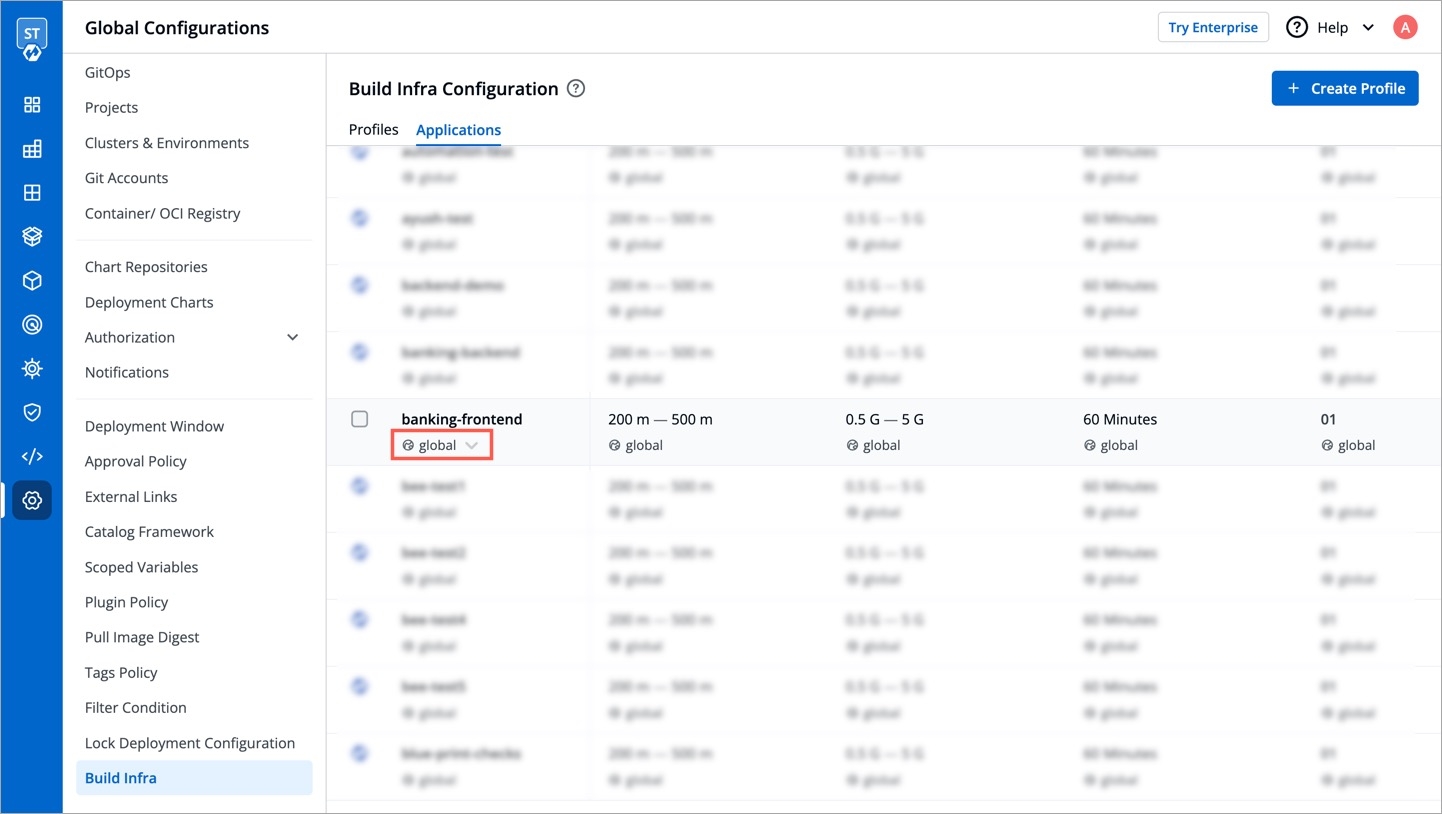
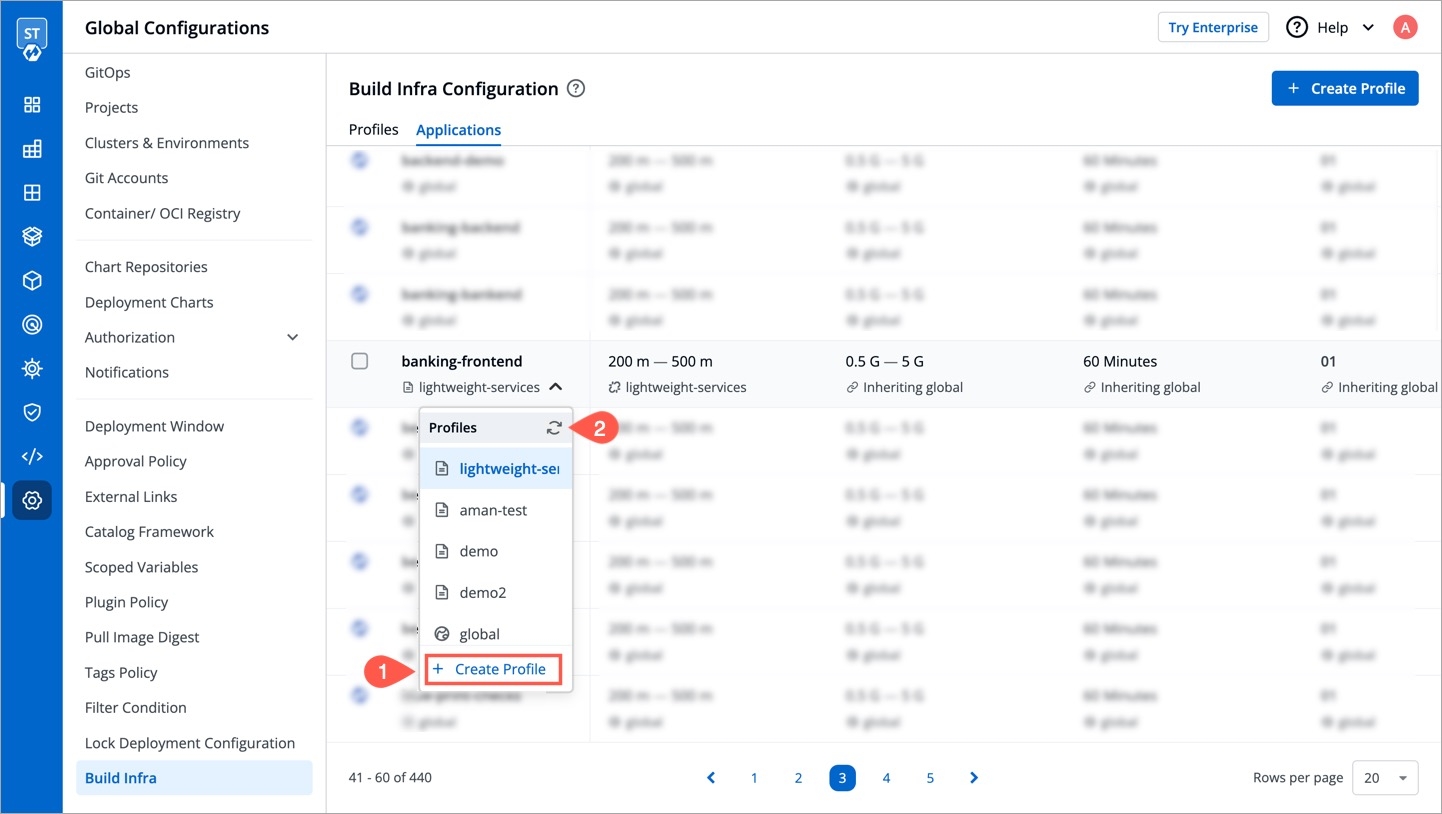
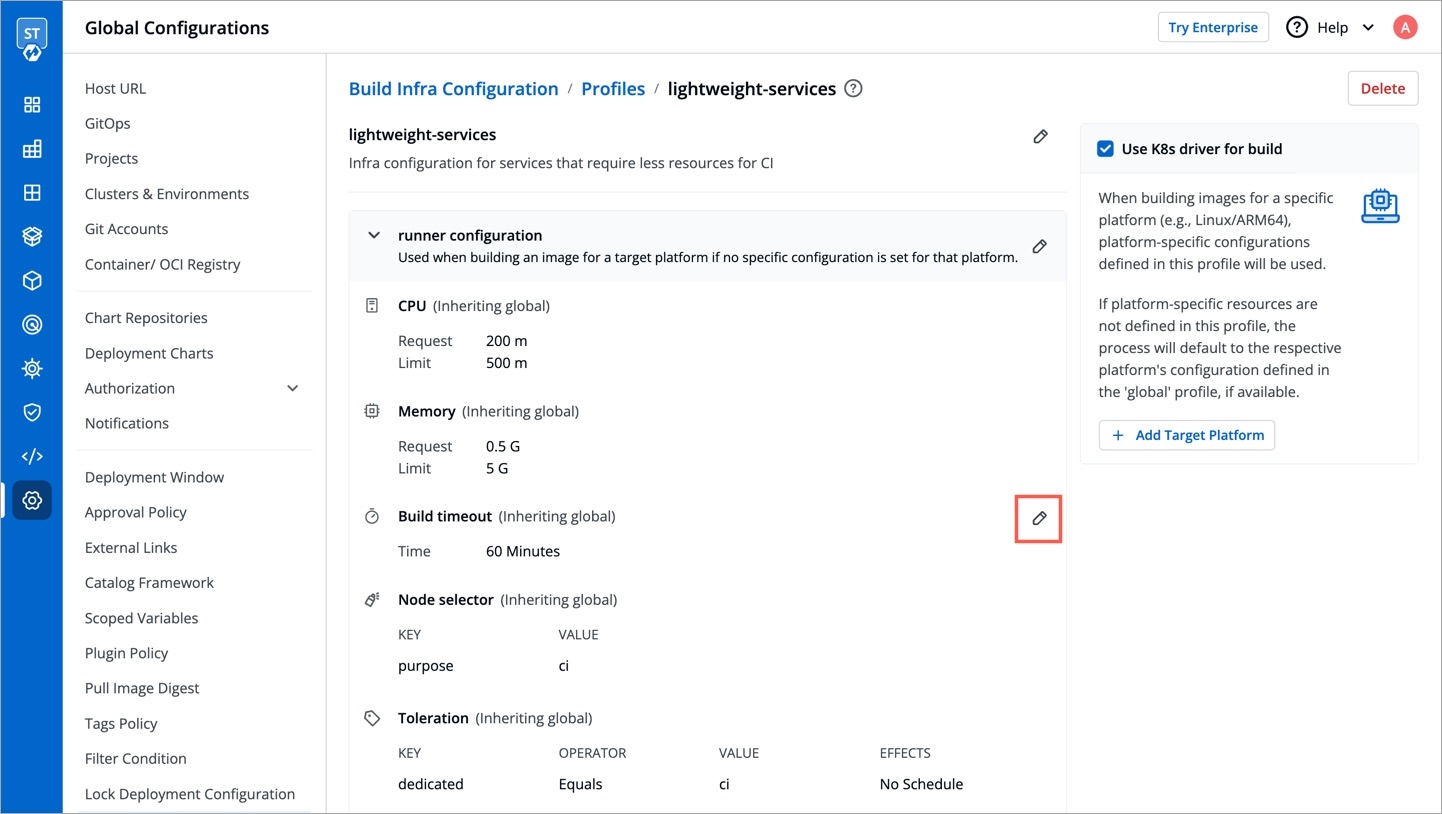
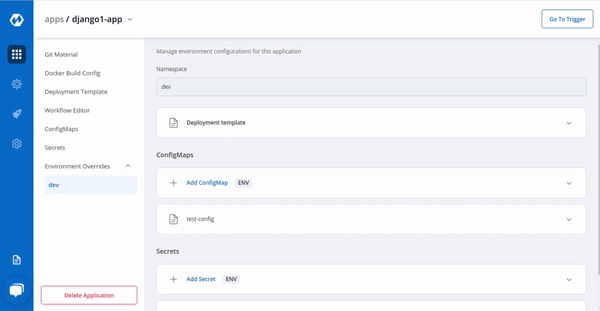
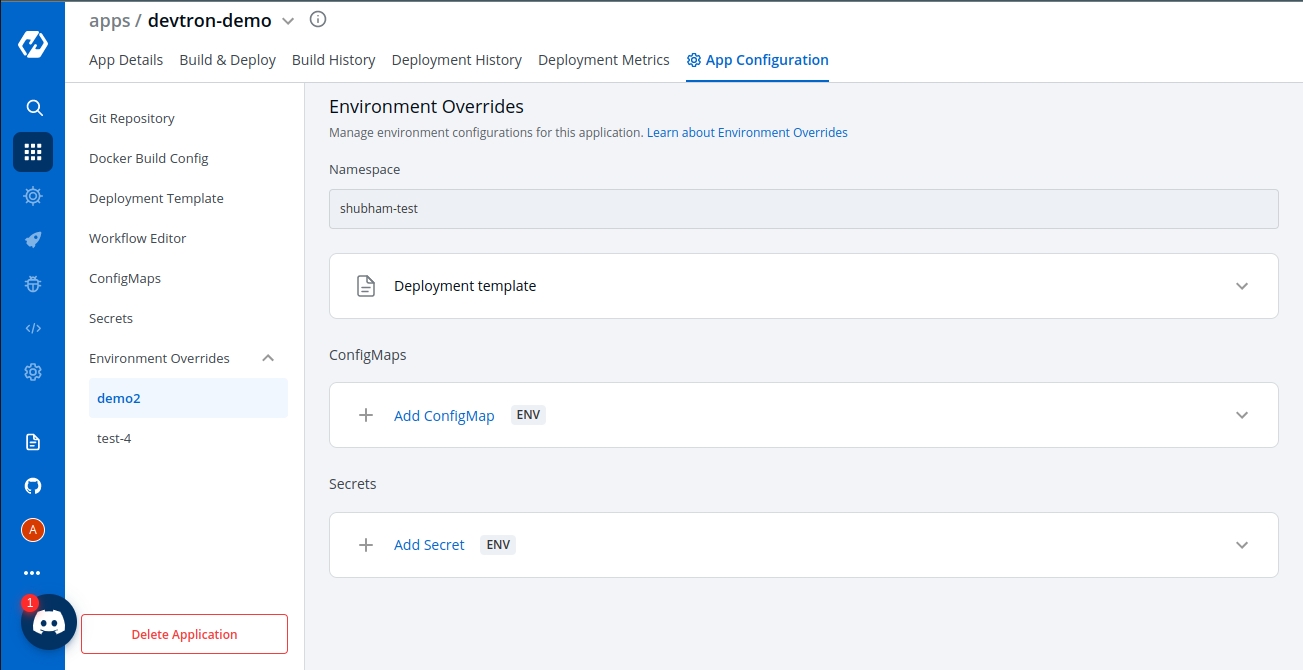
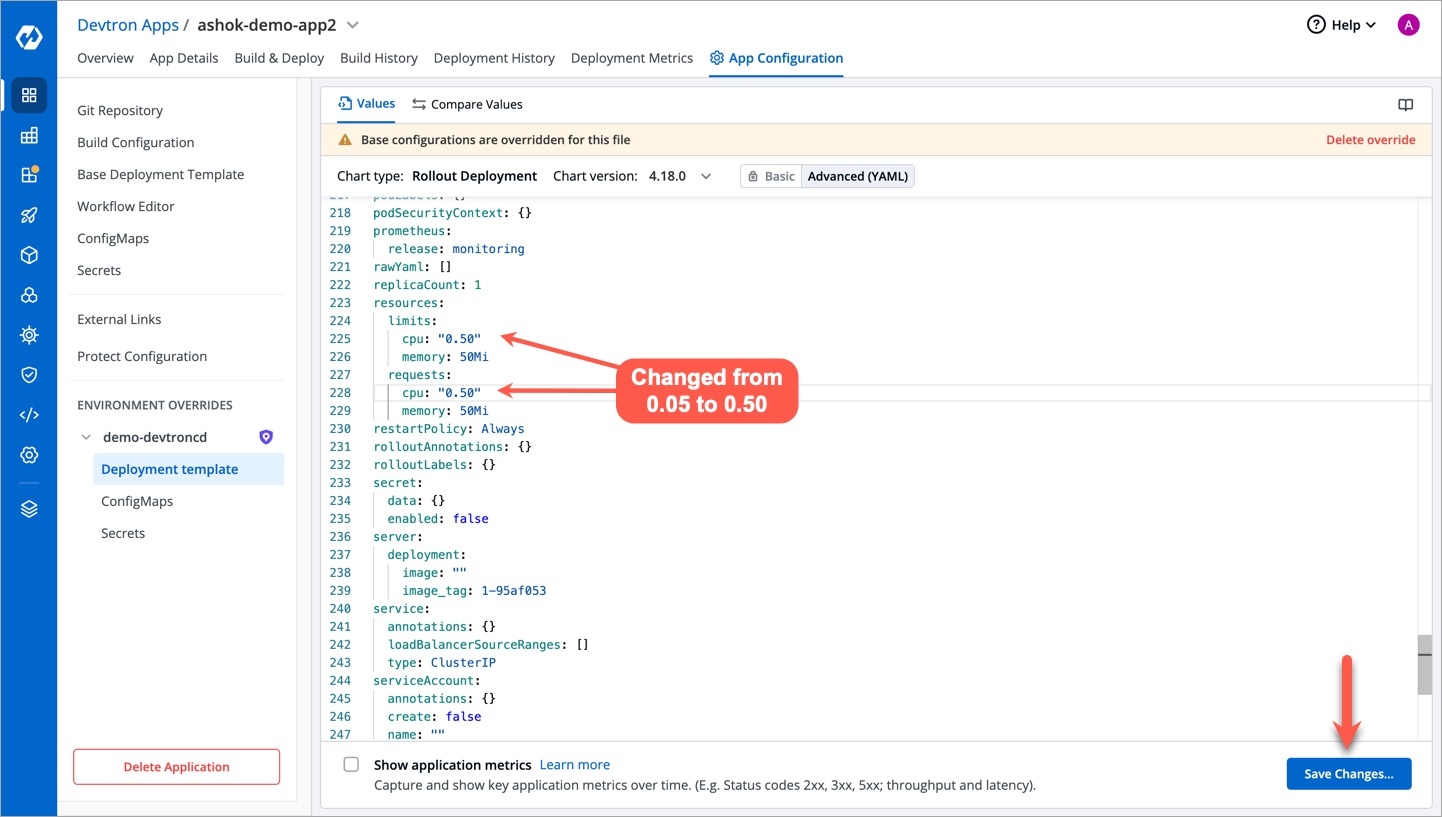
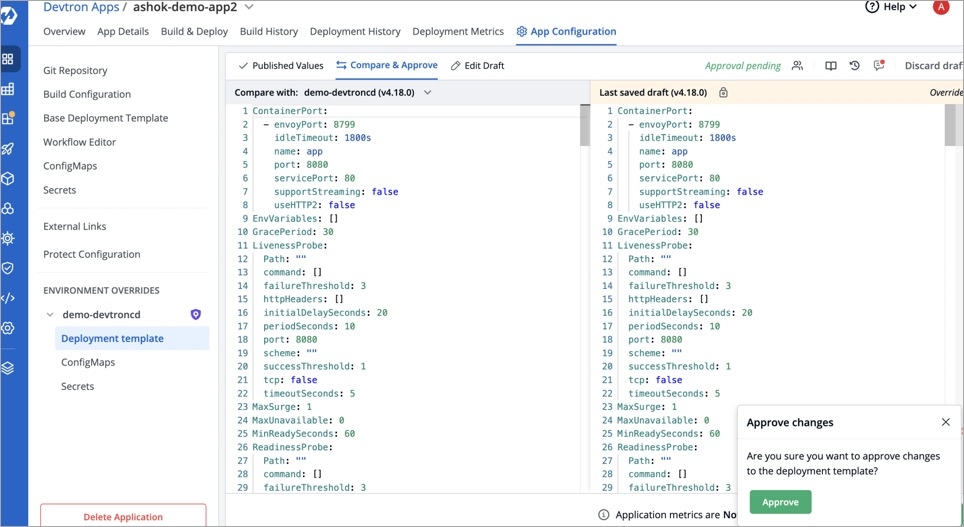
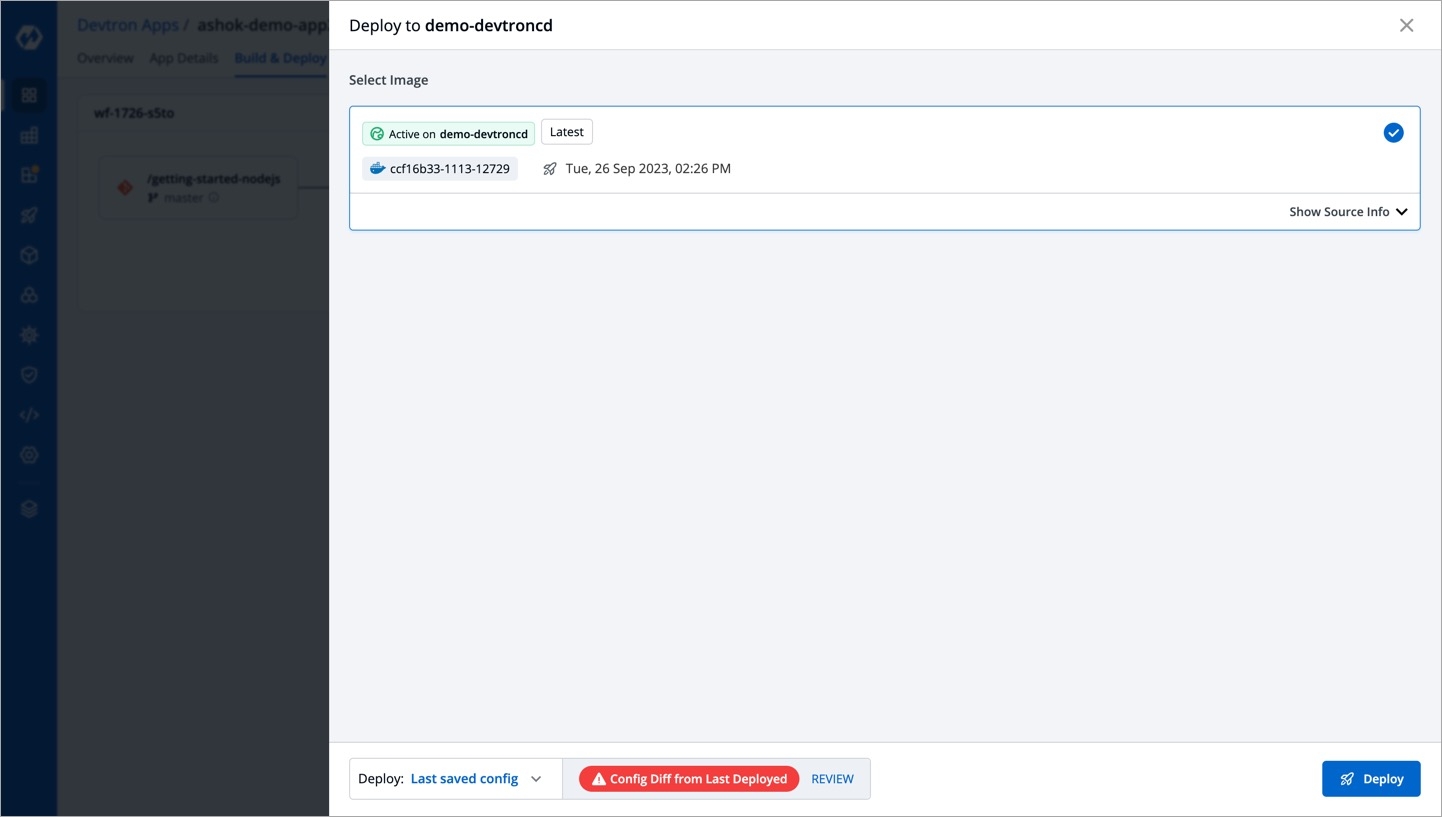
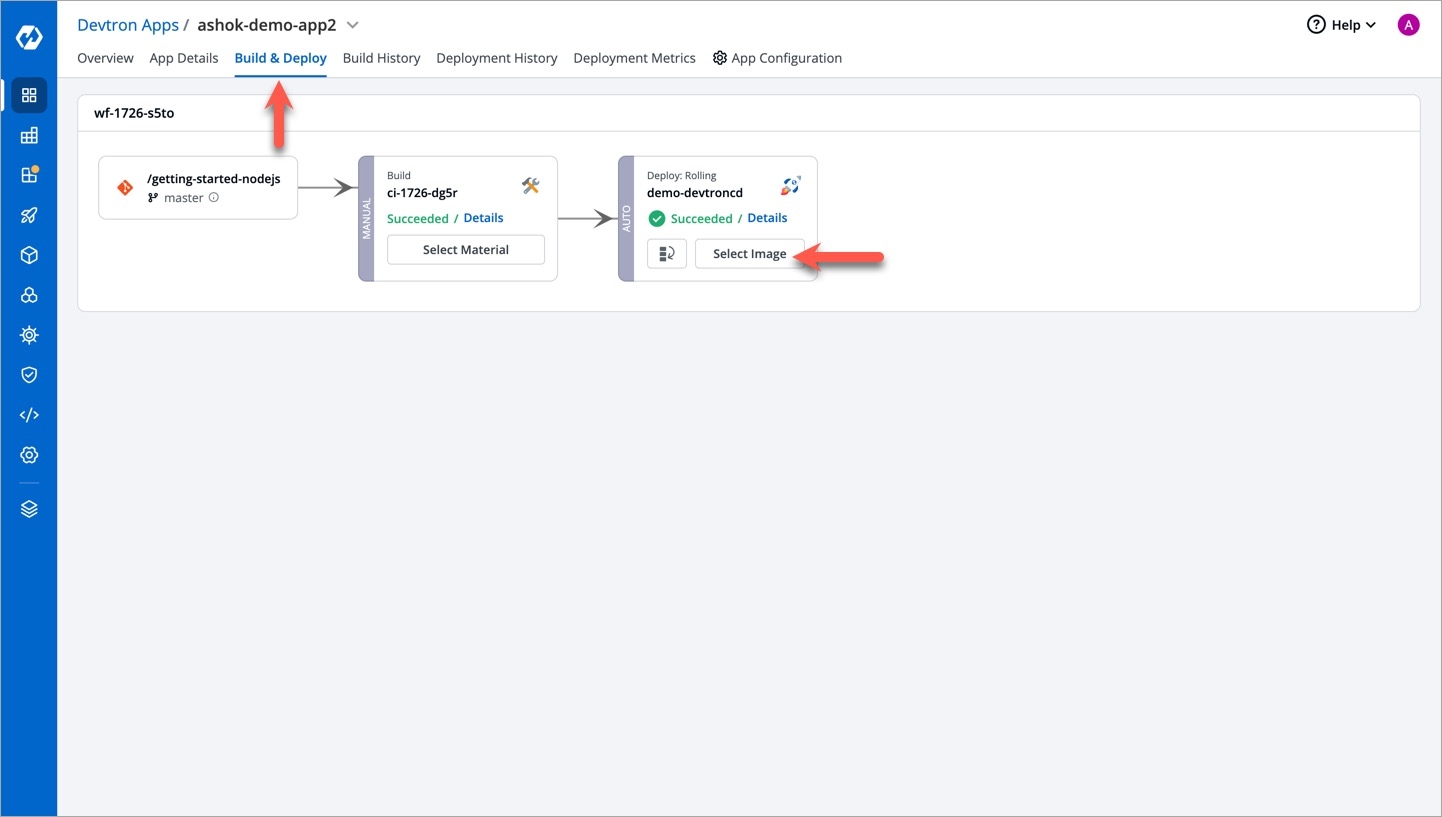
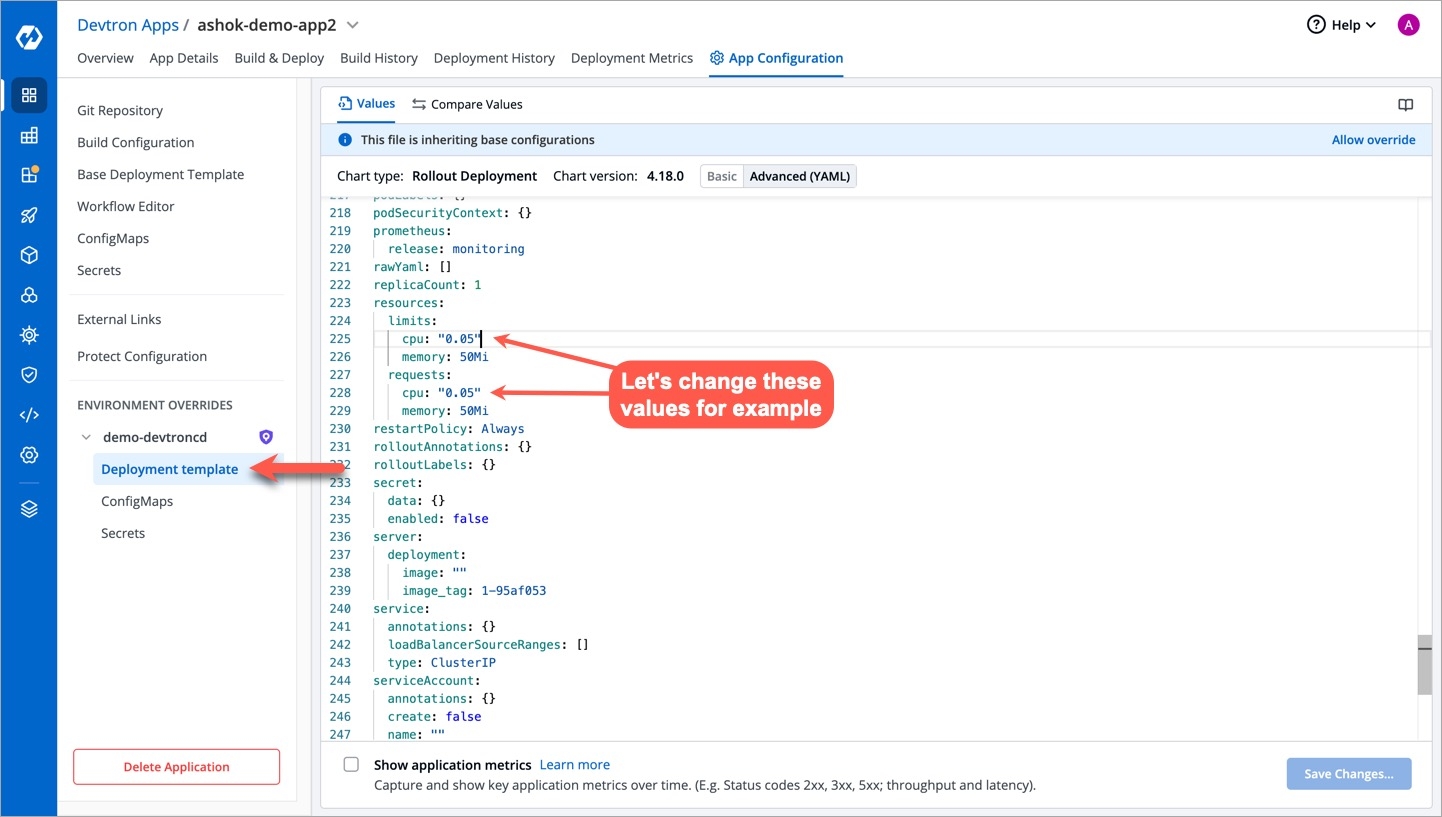
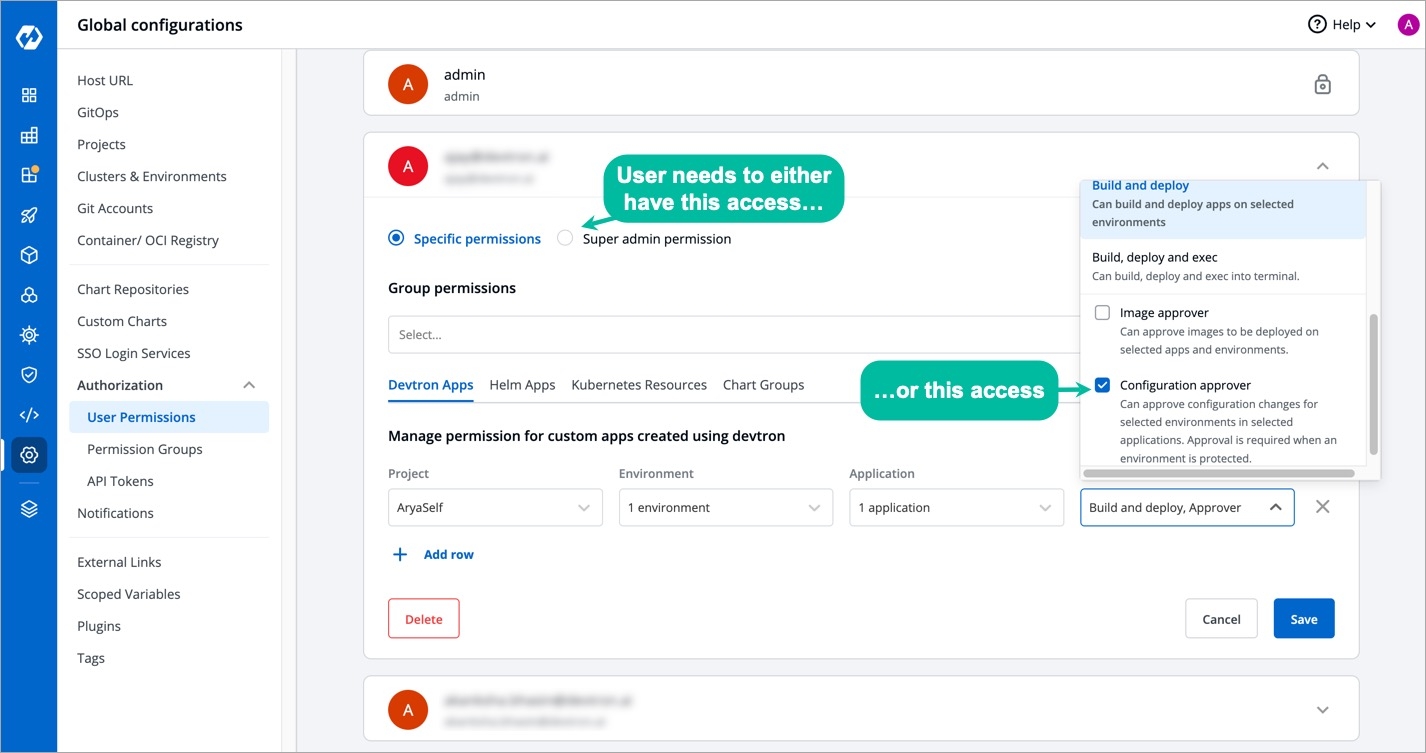
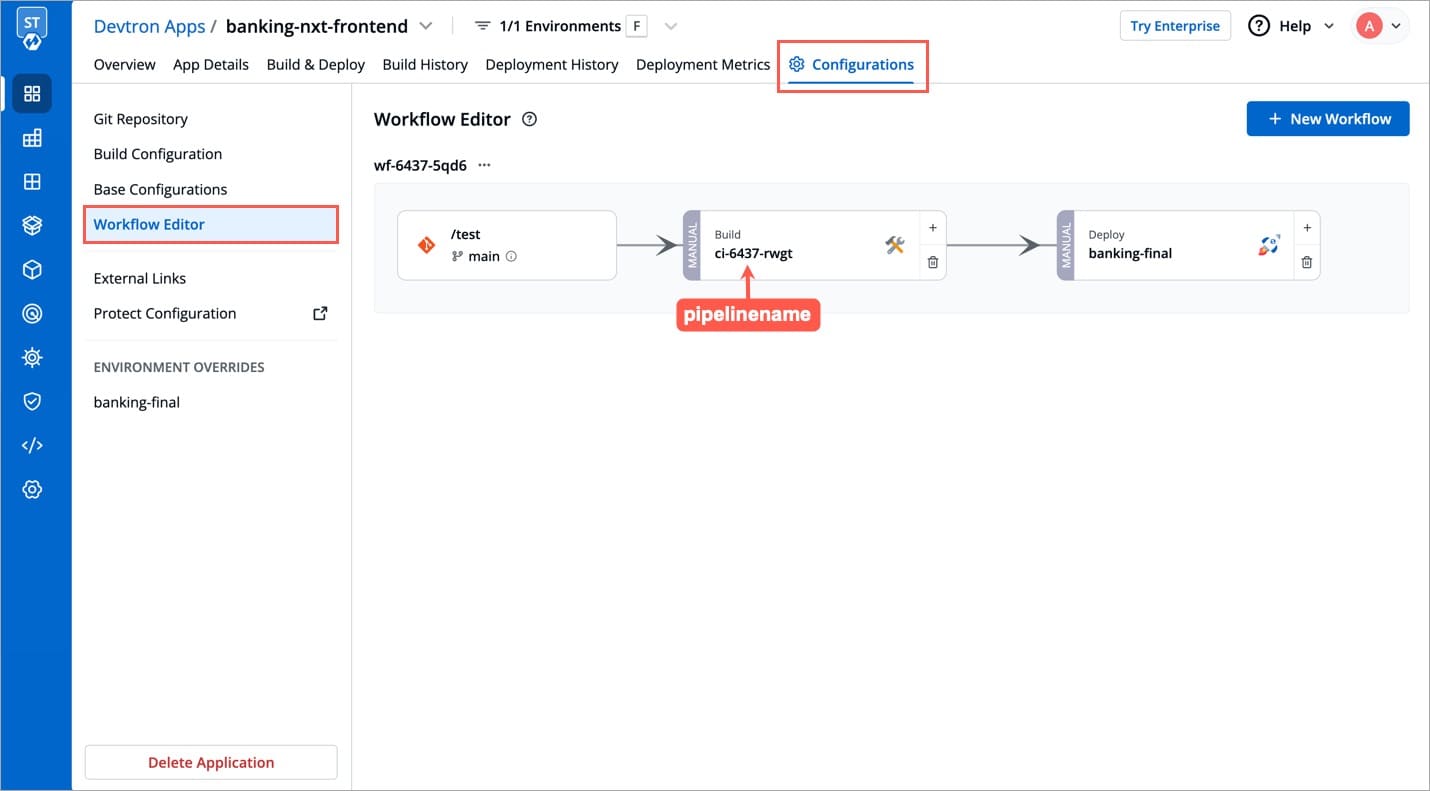
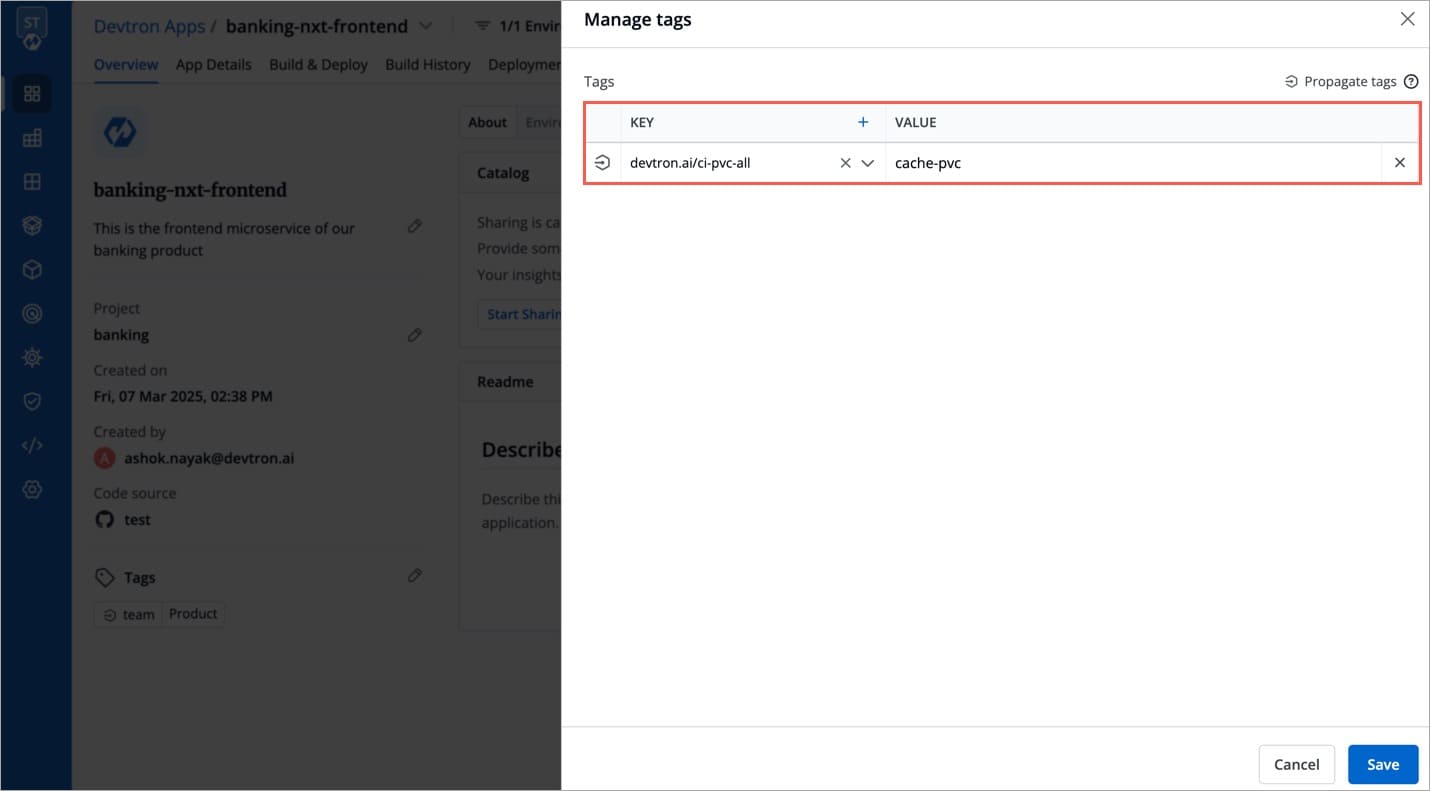
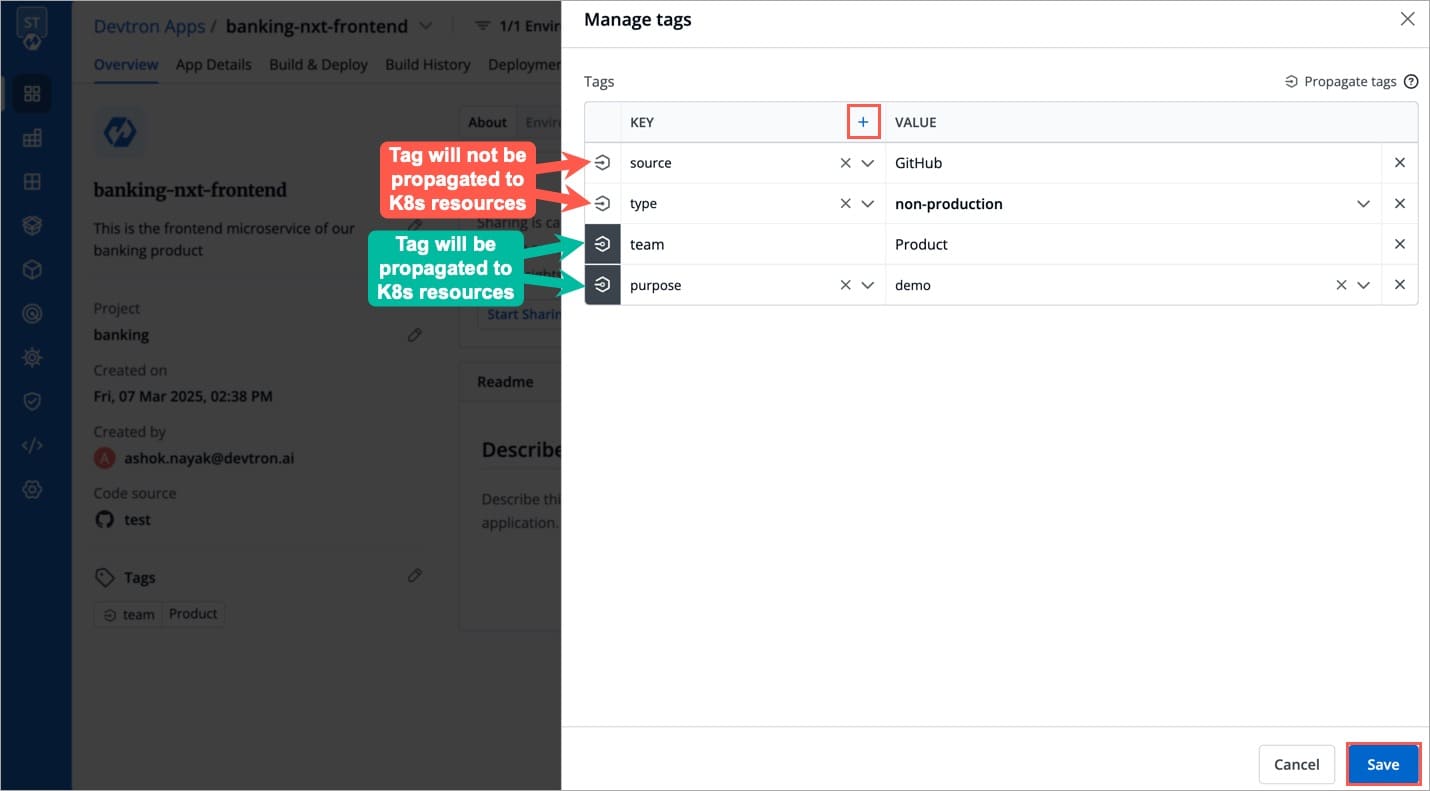
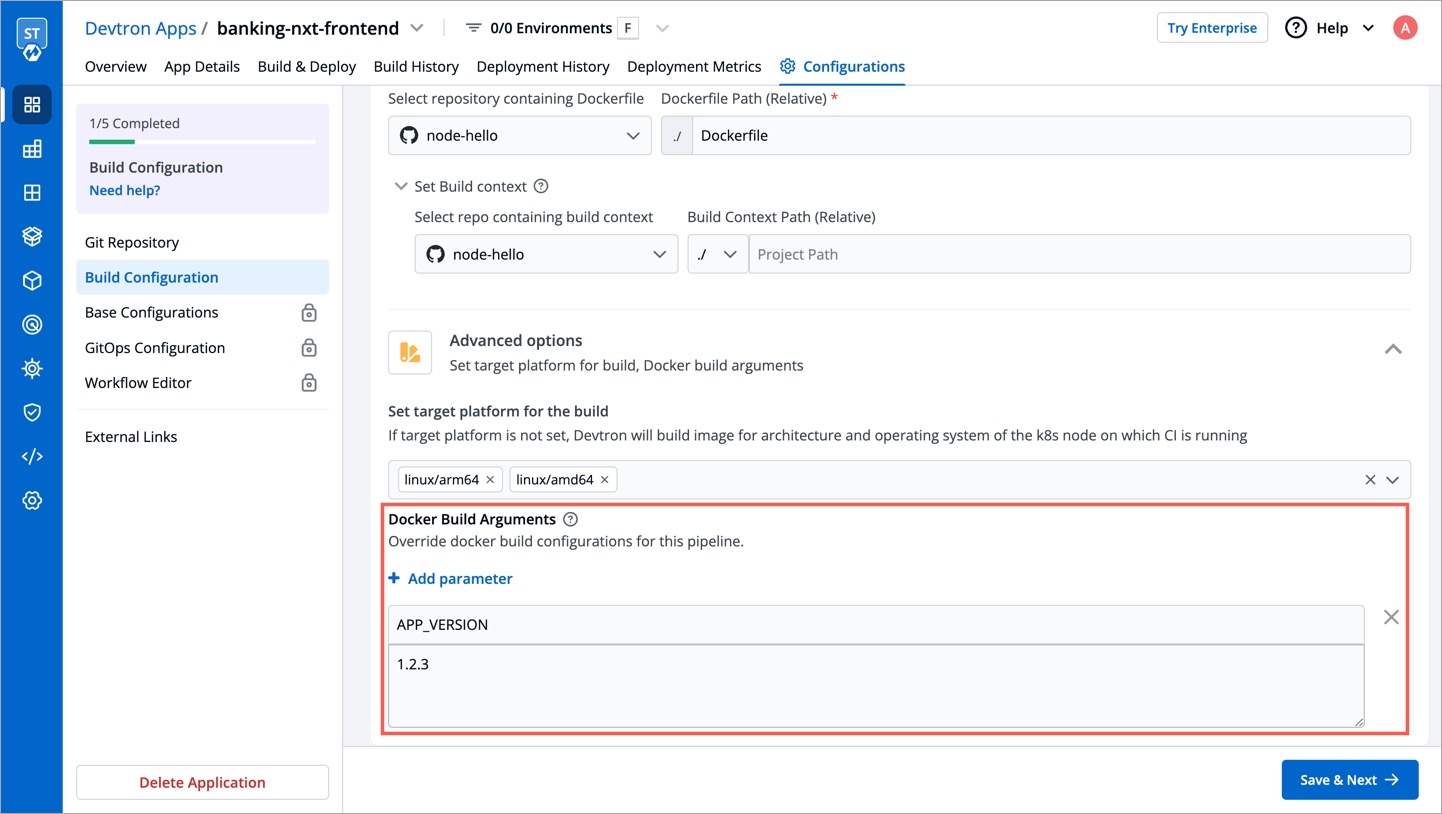
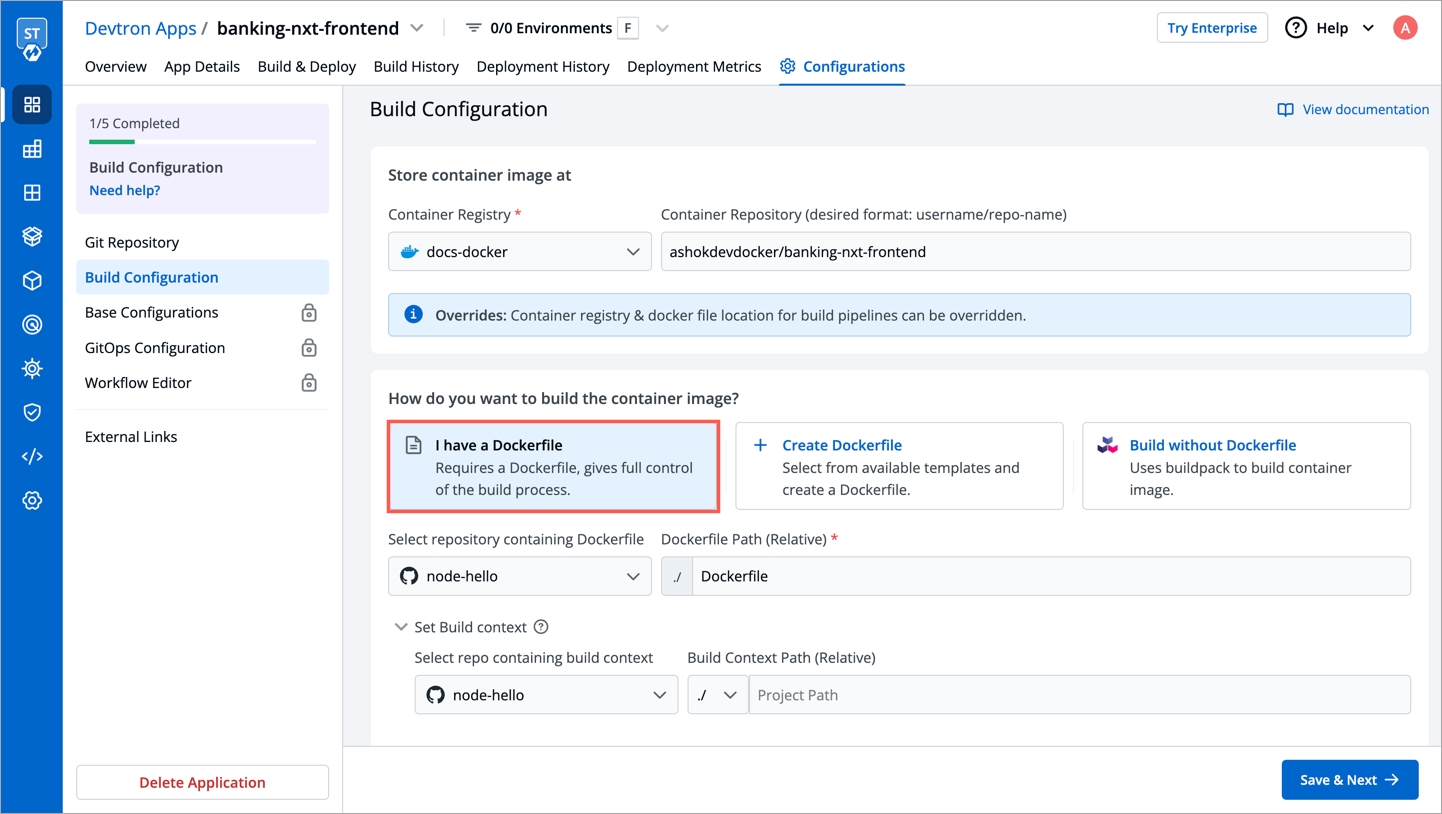
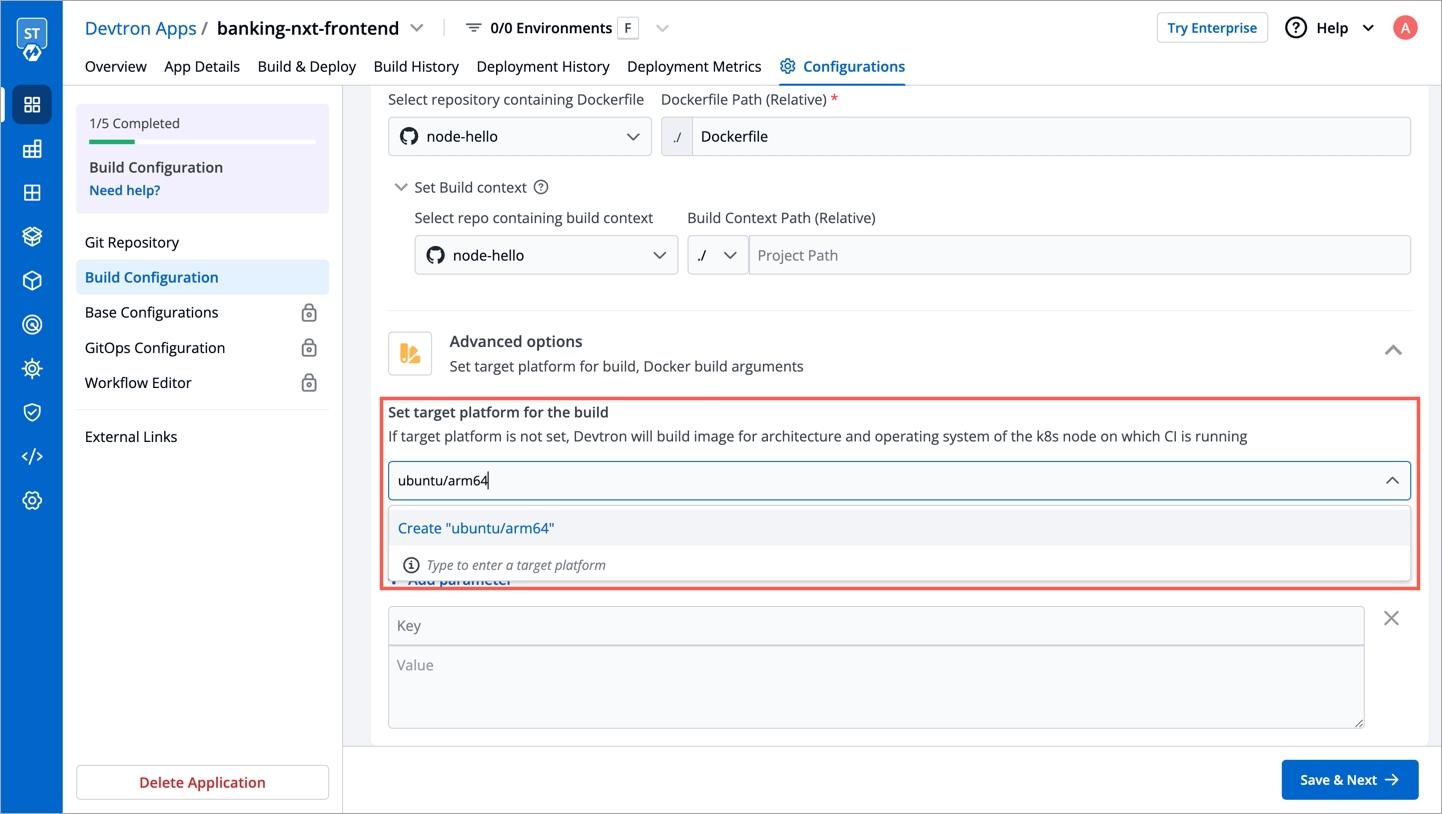
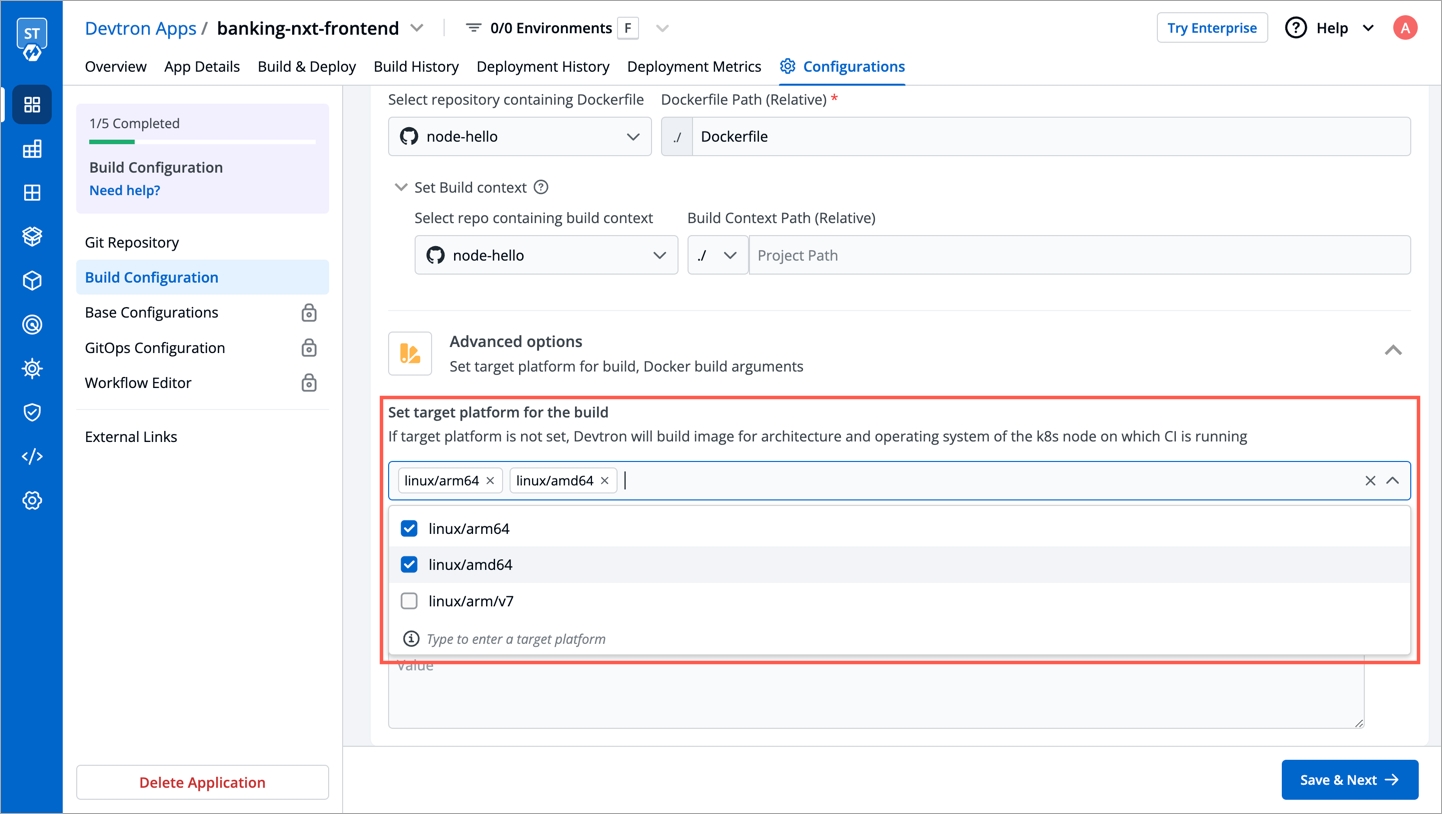
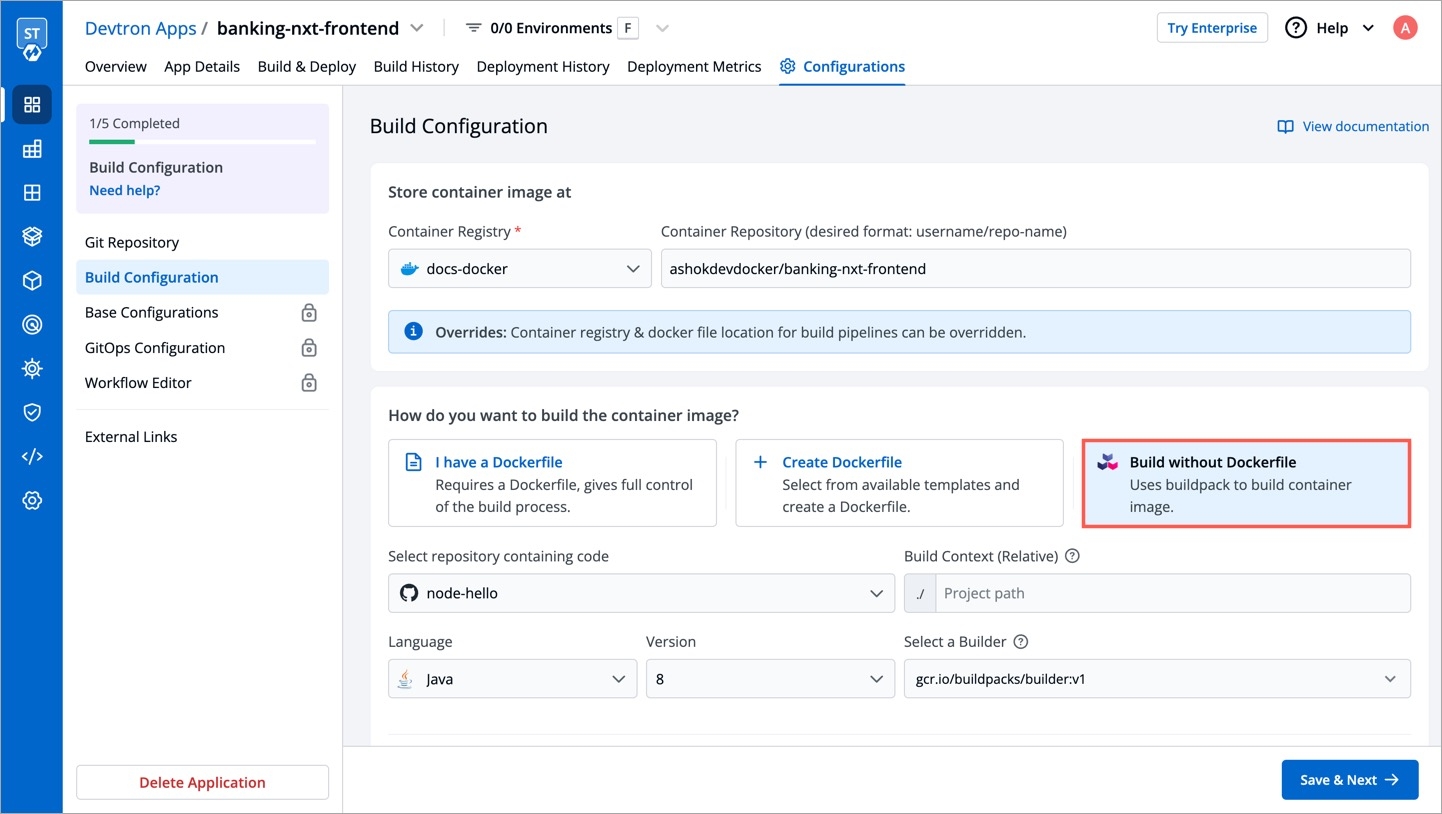
Pipeline Name
Name of the pipeline
Pipeline Execution (Advanced)
Select from automatic or manual execution depending upon your use-case
Source Type
Select the source through which the CI Pipeline will be triggered
Stages (Advanced)
1.Pre-build Stages- Scripts to be executed before building an image. 2.Docker build Stages- Provide a new argument and override an old argument in key-value pair. 3. Post-build Stages- Scripts to be executed after building image
Scan for vulnerabilities (Advanced)
It will scan your image and find if any vulnerabilities present
Source branch name
Branch from which the Pull Request is generated.
Target branch name
Branch to which the Pull request will be merged.
Author
The one who created the Pull Request.
Title
Title provided to the Pull Request.
State
It shows the state of PR and as of now it is fixed to Open which cannot be changed.
Author
The one who created the tag.
Tag name
Name of the tag for which the webhook will be triggered.
version
specify the version of yaml
appliesTo
applies the changes to a specified branch
type
branch type on which changes are to be applied, it can be BRANCH_FIXED or TAG_PATTERN
value
branch name on which changes are to be applied, it can take a value as the name of branch (“master”) or as a regular expression ("%d.%d.%d-rc")
script
A script which you want to execute, you can also execute the docker commands here
beforeDockerBuildStages
script to run before the docker build step
afterDockerBuildStages
script to run after the docker build step
outputLocation
The location where you want to see the output of the report of Test cases
Pipeline Name
Name of the pipeline
Source Type
‘Branch Fixed’ or ‘Tag Regex’
Branch Name
Name of the branch
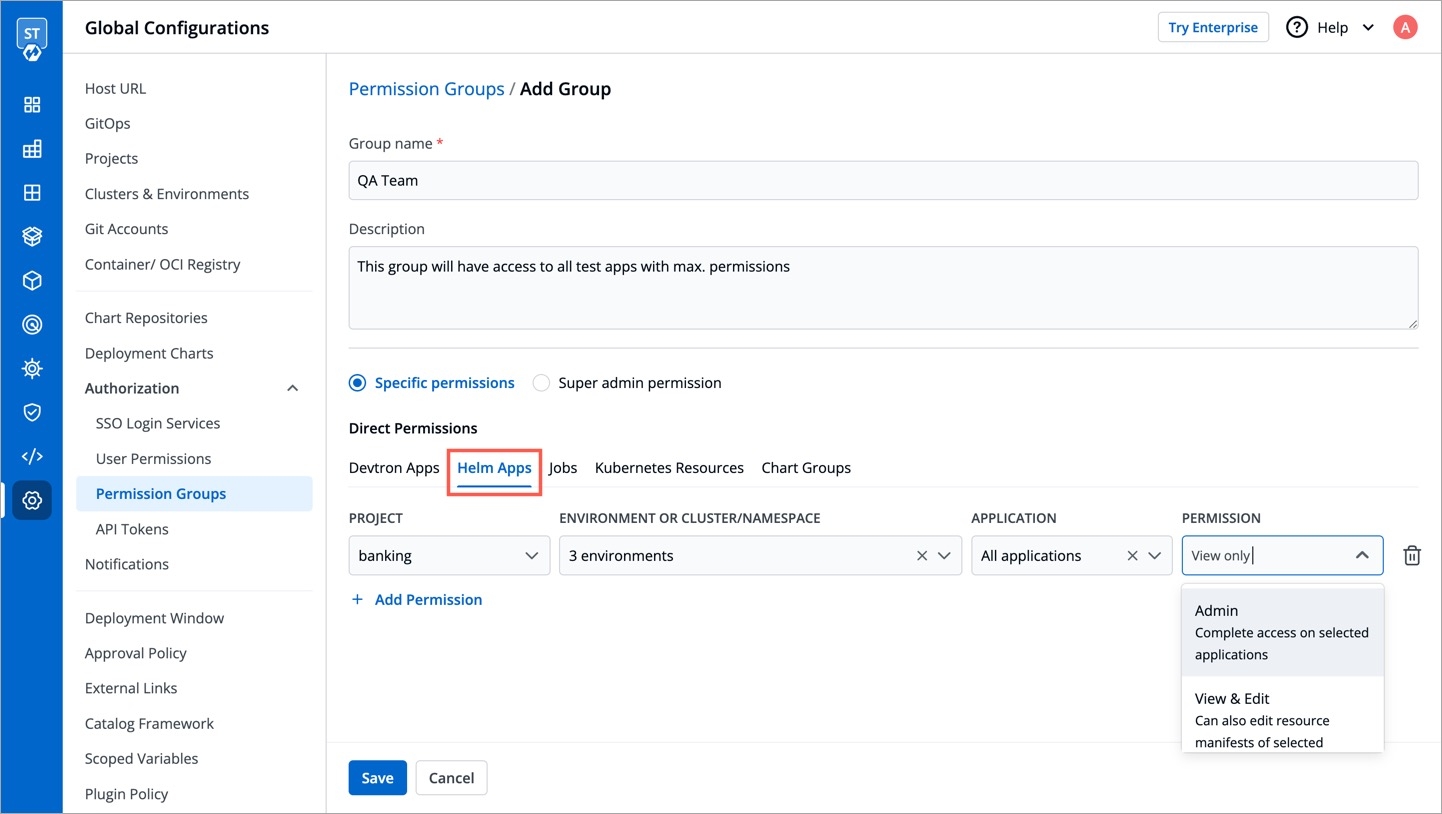
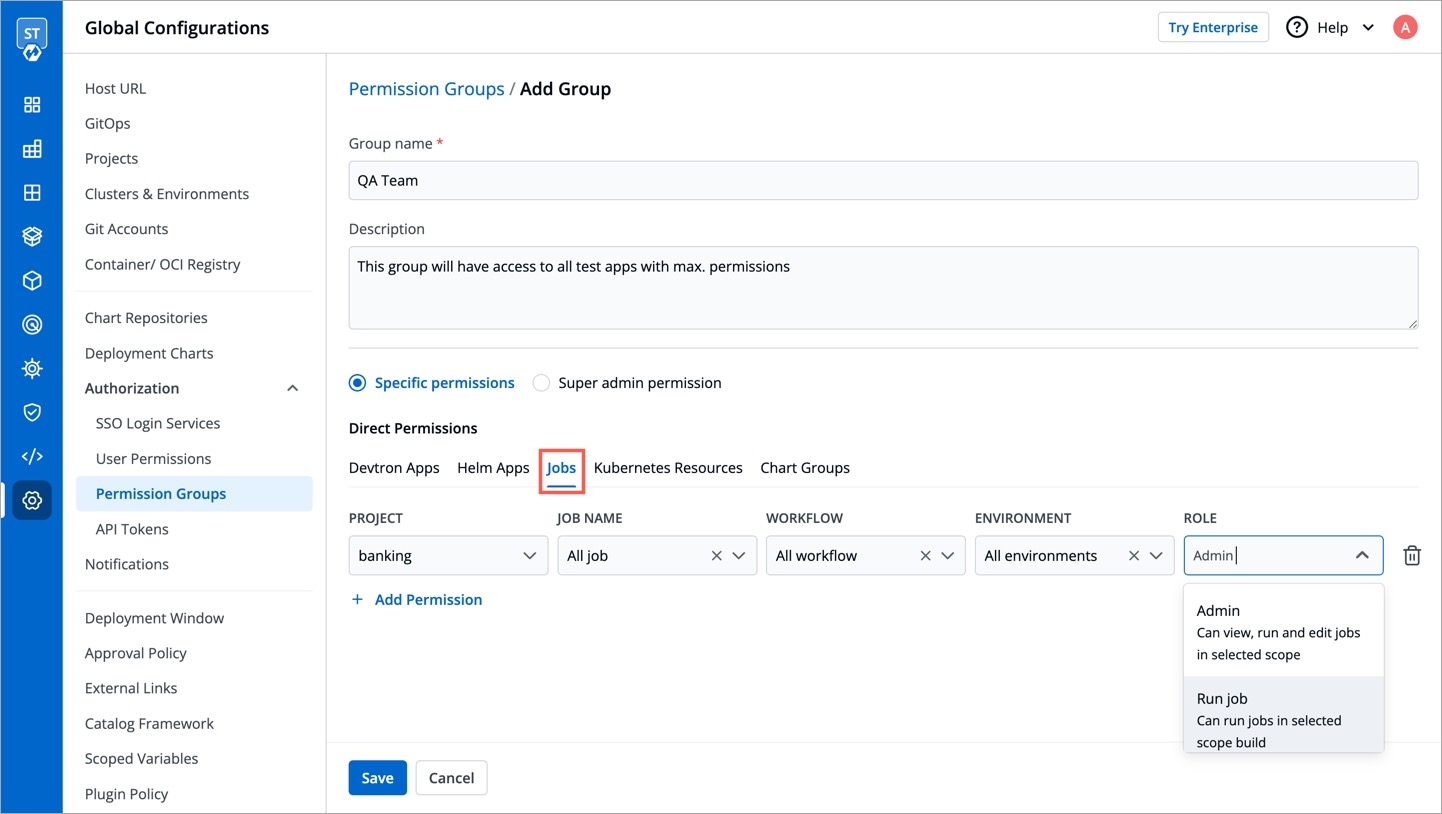
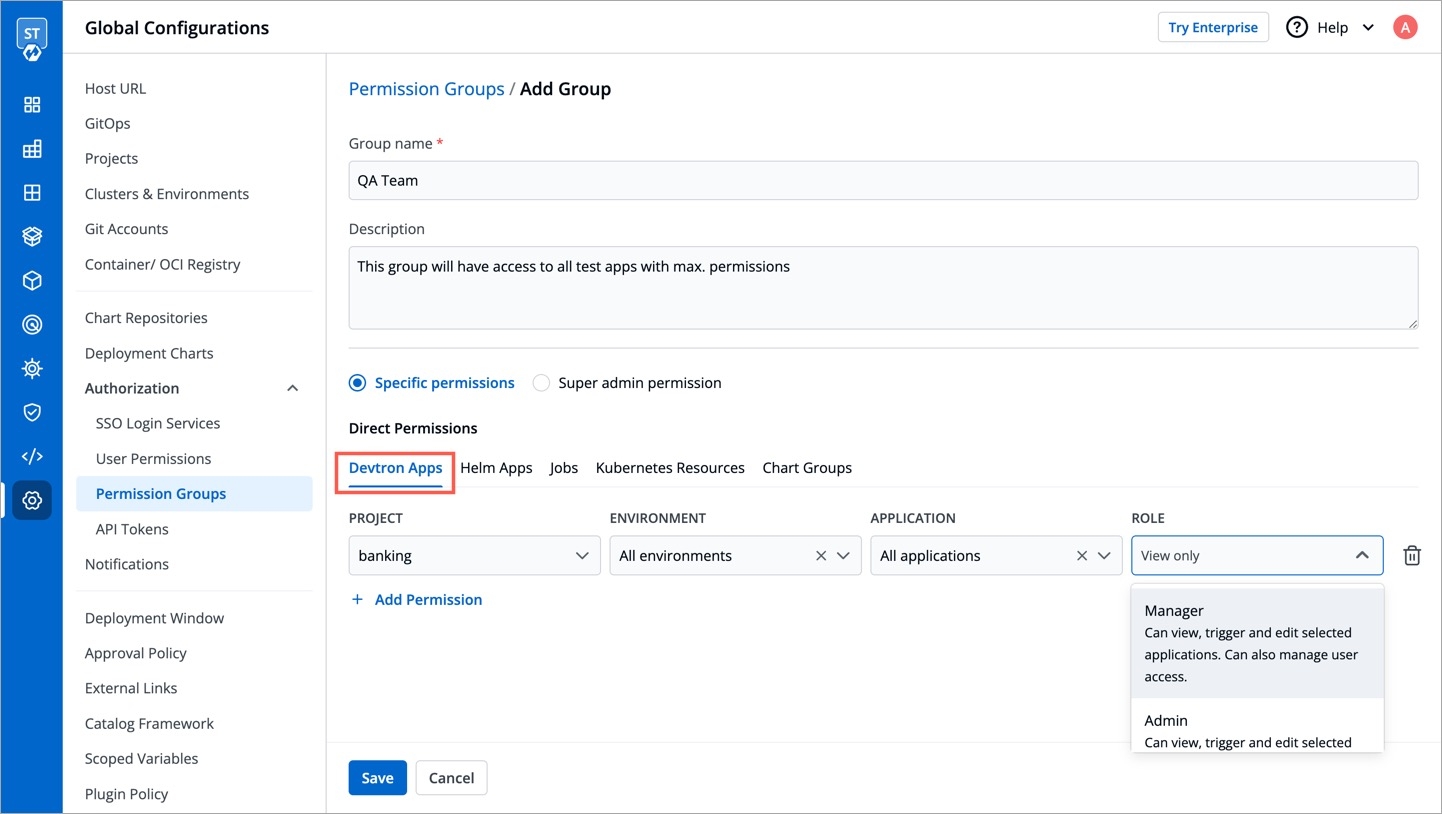
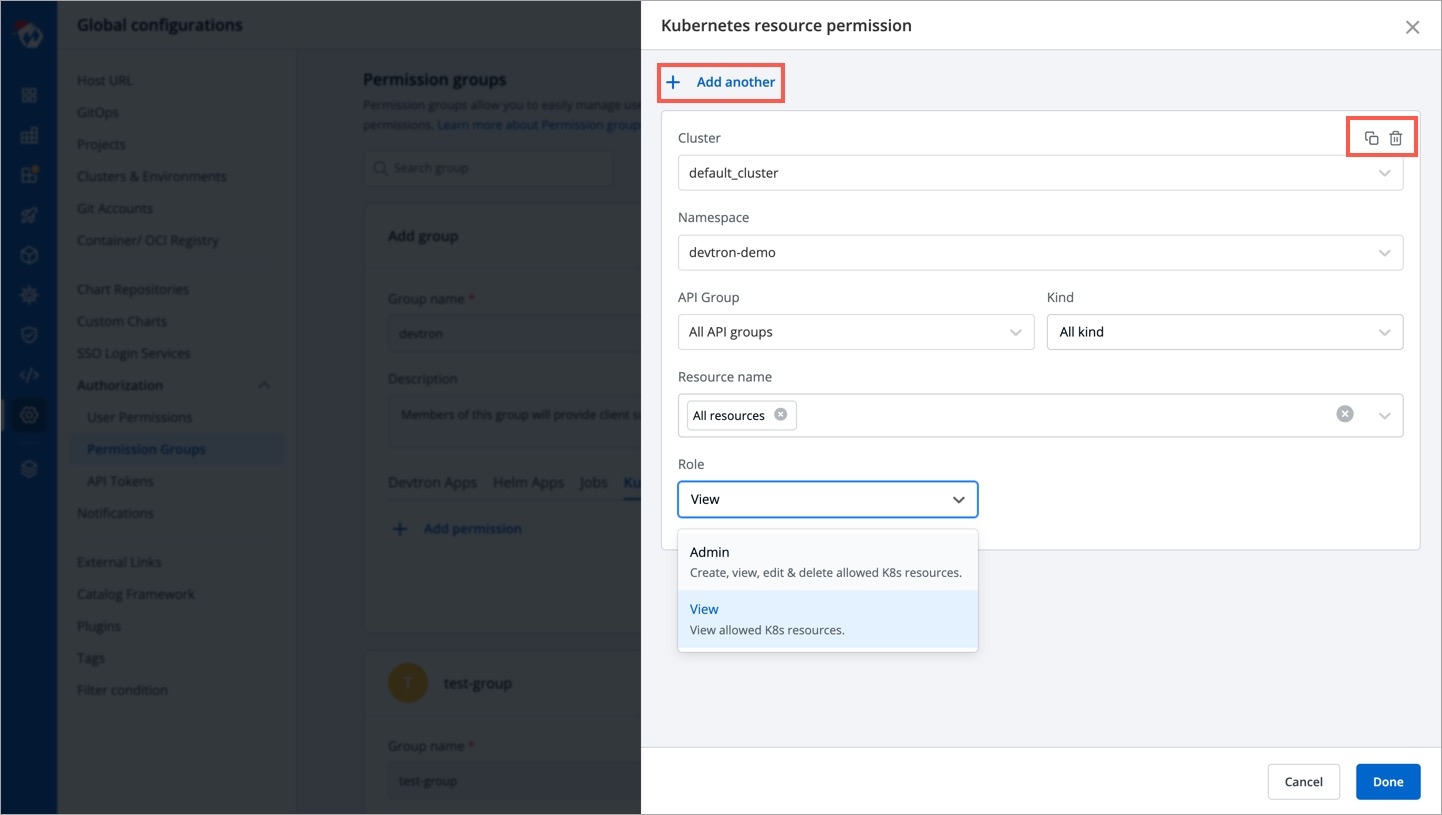
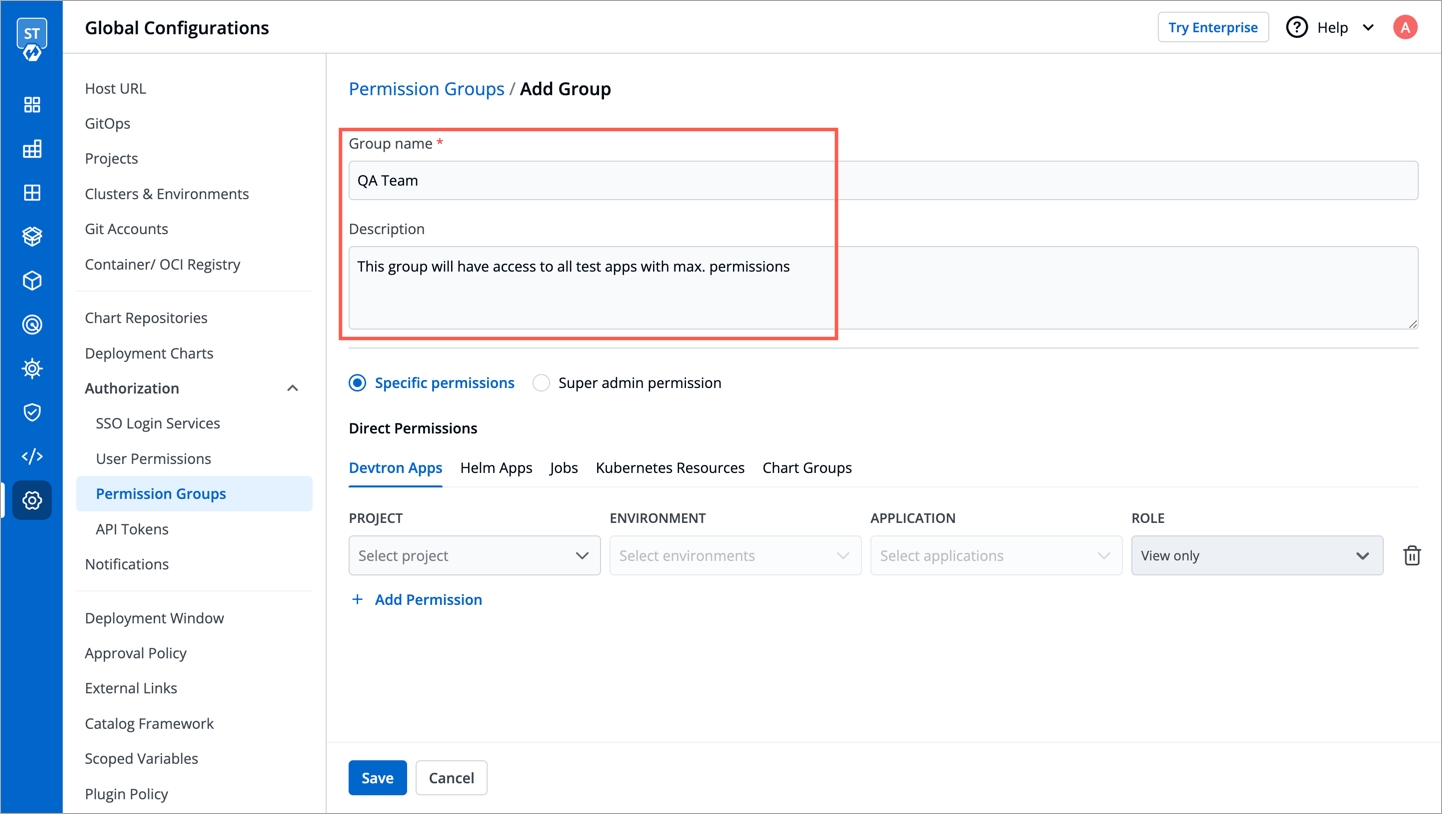
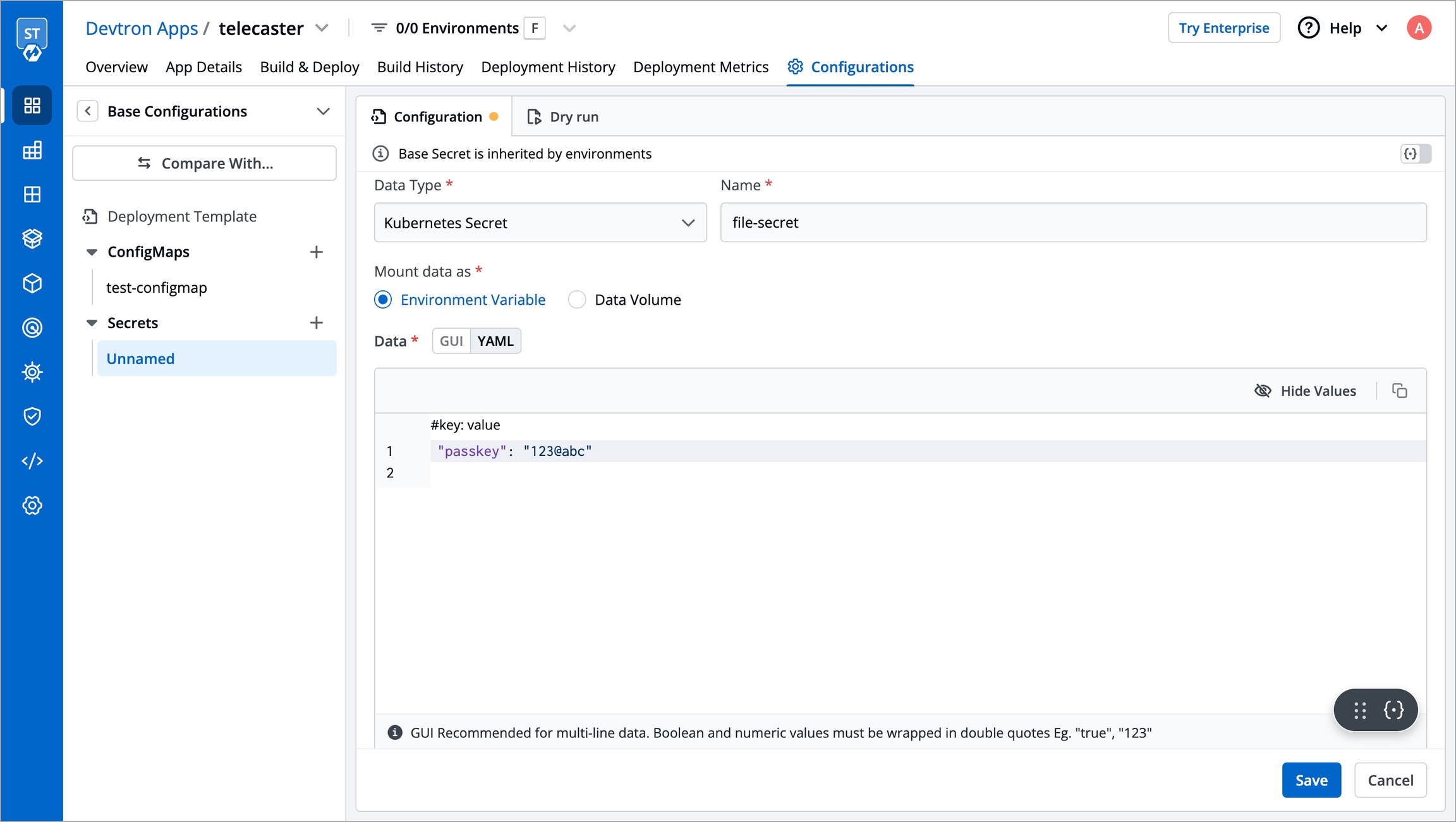
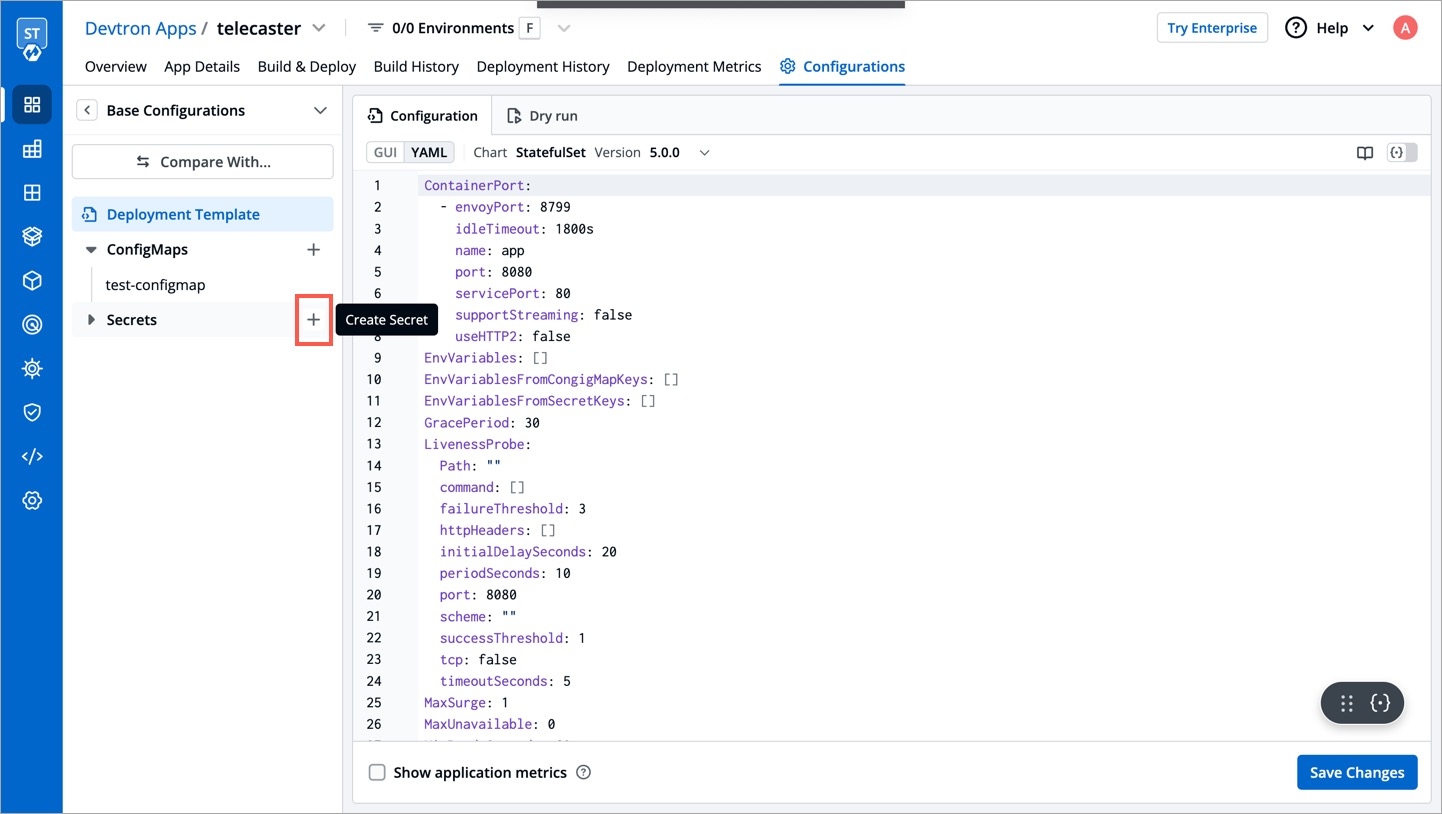
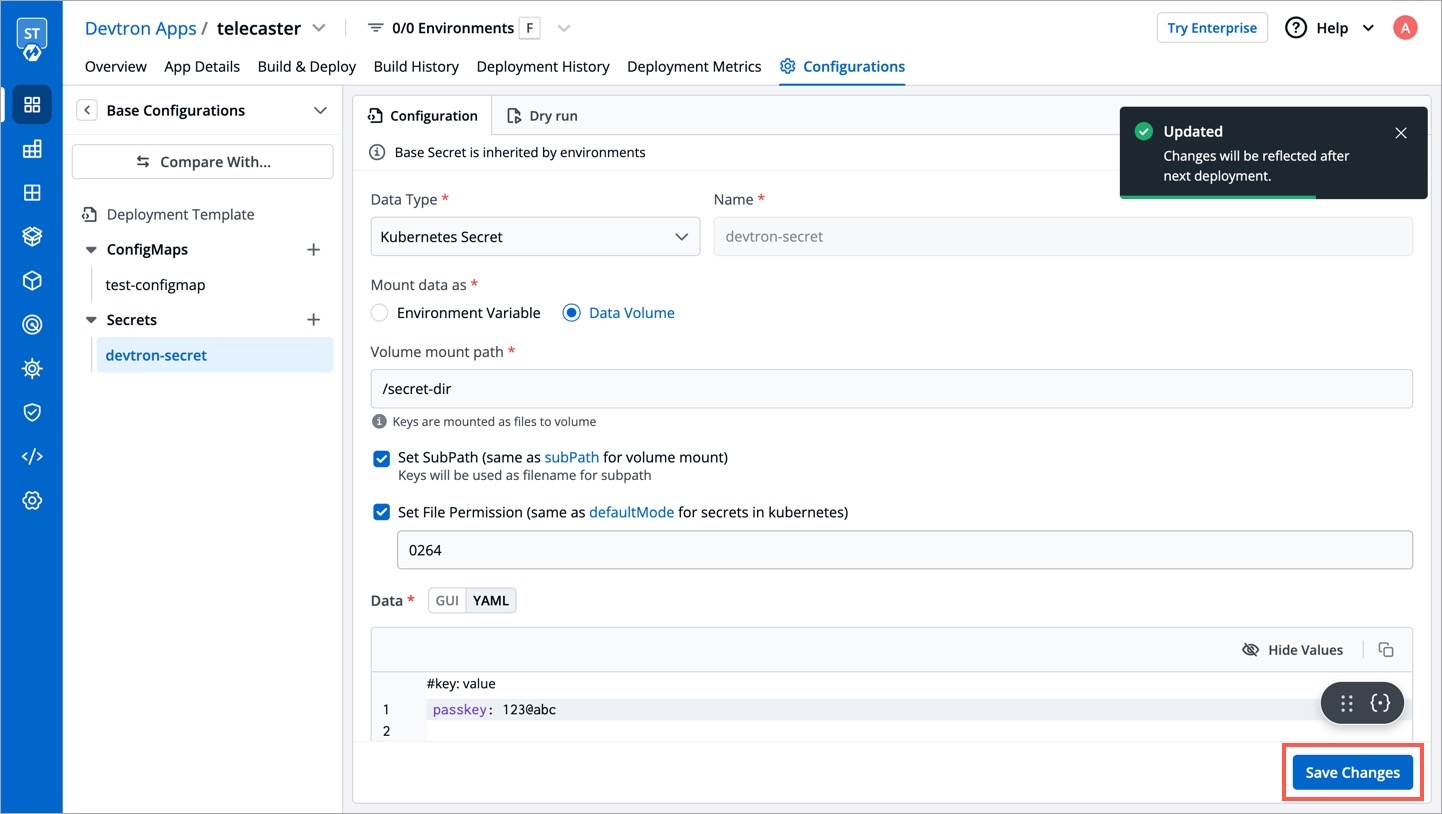
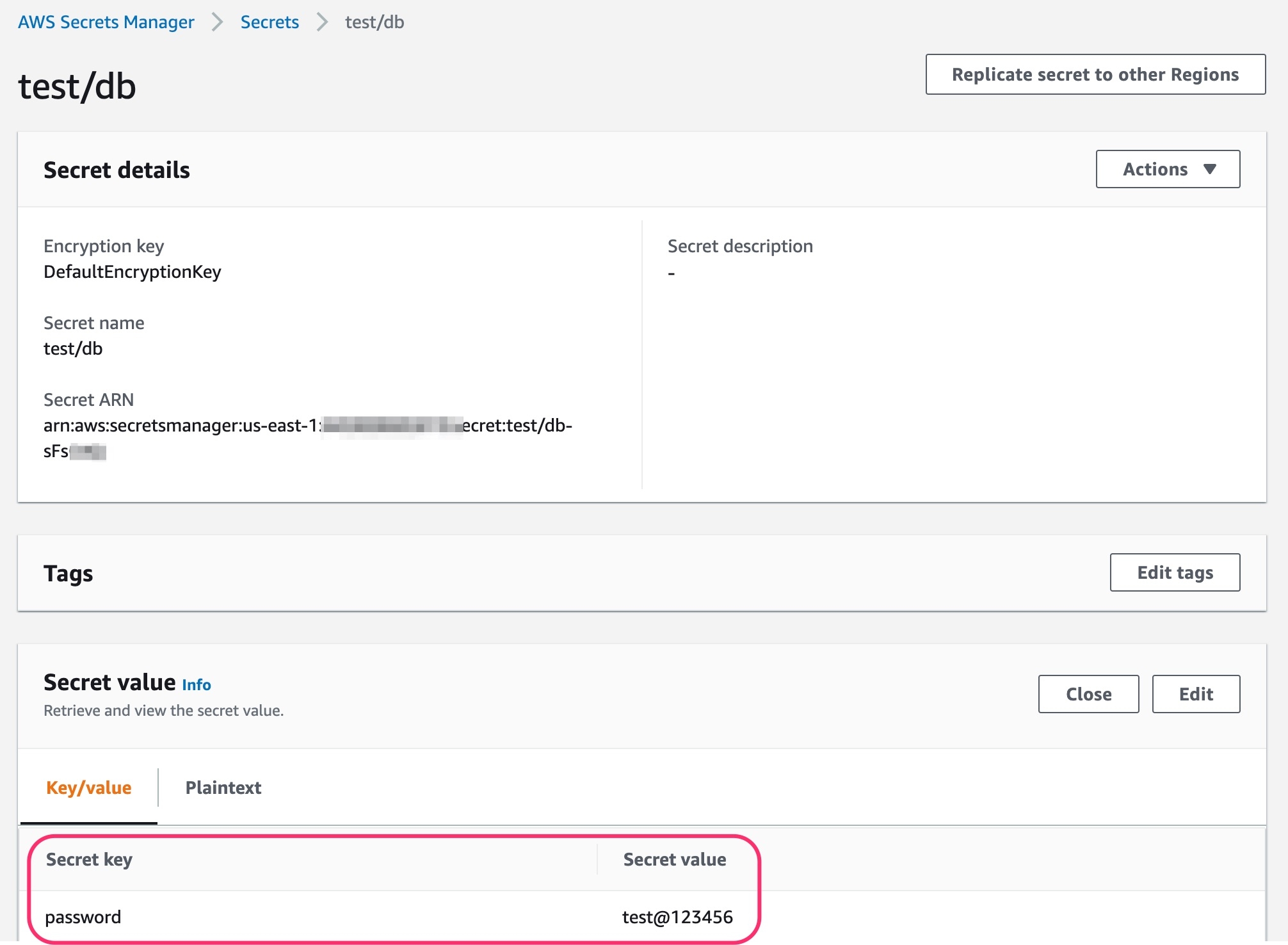
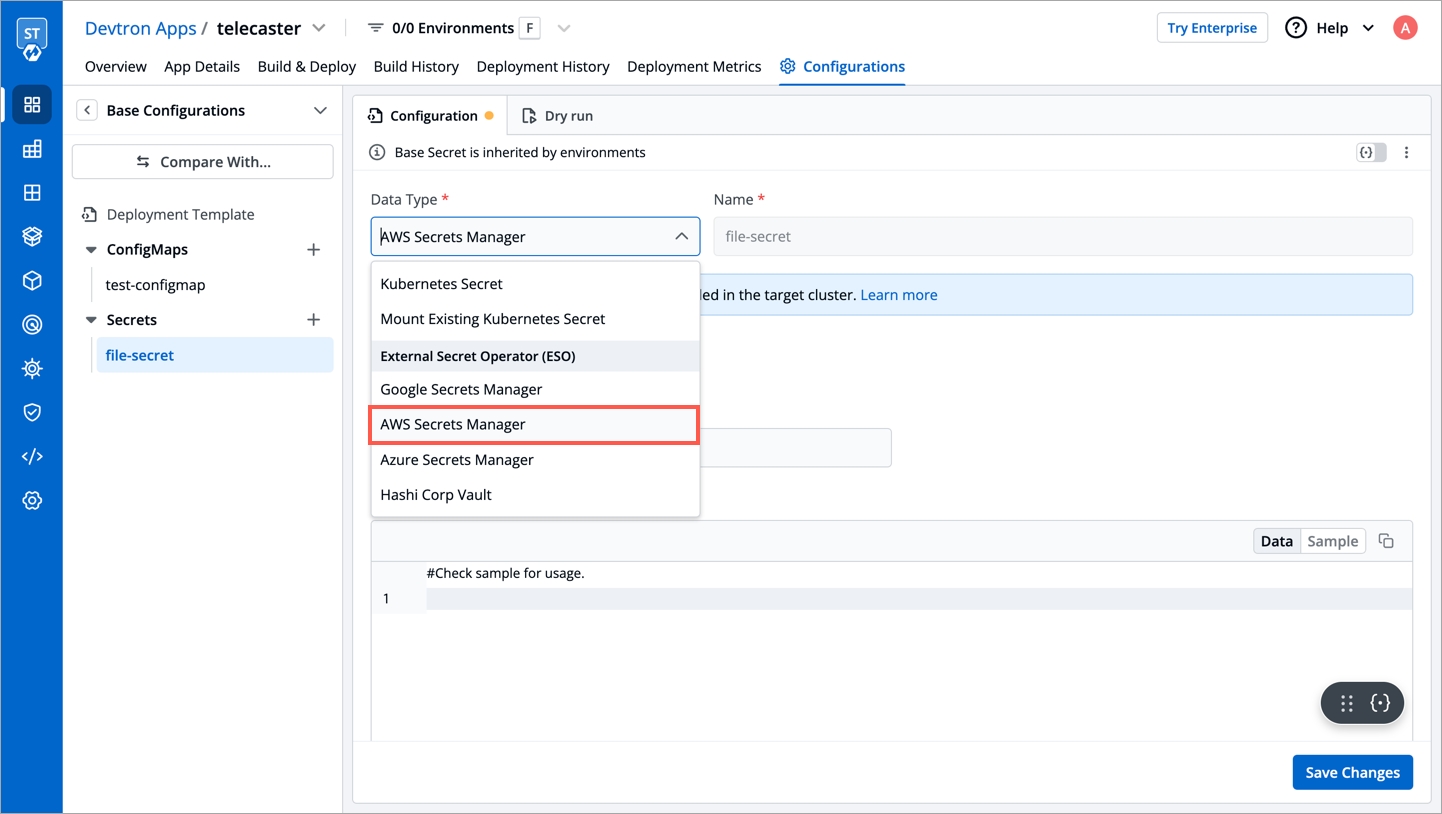
Like any enterprise product, Devtron supports fine grained access control to the resources based on:
Type of action allowed on Devtron resources (Create Vs View)
Sensitivity of the data (Editing image Vs Editing memory)
Access can be added to the User either directly or via Permission groups.
Devtron supports the following levels of access:
View only: User with View only access has the least privilege. This user can only view combination of environments, applications and helm charts on which access has been granted to the user. This user cannot view sensitive data like secrets used in applications or charts.
Build and Deploy: In addition to View only access, user with Build and deploy permission can build and deploy the image of the permitted applications and helm charts to the permitted environments.
Admin: User with Admin access can create, edit, delete and view permitted applications in the permitted projects.
Manager: User with Manager access can do everything that an Admin type user can do, in addition, they can also give and revoke access of users for the applications and environments of which they are Manager.
Super Admin: User with Super admin privilege has unrestricted access to all Devtron resources. Super admin can create, modify, delete and view any Devtron resource without any restriction; its like Superman without the weakness of Kryptonite. Super Admin can also add and delete user access across any Devtron resource, add delete git repository credentials, container registry credentials, cluster and environment.
View
Yes
No
No
No
No
Build and Deploy
Yes
No
No
No
Yes
Admin
Yes
Yes
Yes
Yes
Yes
Manager
Yes
Yes
Yes
Yes
Yes
Super Admin
Yes
Yes
Yes
Yes
Yes
View Only
Yes
No
No
No
View and Edit
Yes
Yes
Yes
No
Admin
Yes
Yes
Yes
Yes
Super Admin
Yes
Yes
Yes
Yes
Manager
Yes
Yes
Yes
Super Admin
Yes
Yes
Yes
Super Admin
Yes
Yes
Yes
To add a user, go to the Authorization > User Permissions section of Global Configurations. Click Add user.
There are two types of permissions in Devtron:
Specific permissions
Selecting option allows you to manage access and provide the accordingly for:
Devtron Apps
Helm Apps
Kubernetes Resources
Chart Groups
Super admin permission
Selecting option will get full access to Devtron resources and the rest of the options will not be available.
To assign a super admin access, go to the Authorization > User Permissions section of Global Configurations.
Click Add user.
Provide the email address of a user. You can add more than one email address. Please note that email address must be same as that in the email field in the JWT token returned by OIDC provider.
Select Super admin permission and click Save.
A user now will have a Super admin access.
Note:
Only users with Super admin permission can assign super admin permissions to a user.
We suggest that super admin access must be given to the selected users only.
To assign a specific permission, go to the Authorization > User Permissions section of Global Configurations.
Click Add user.
Provide the email address of a user. You can add more than one email address. Please note that email address must be same as that in the email field in the JWT token returned by OIDC provider.
Select Specific permissions.
Select the group permission from the drop-down list, if required.
Selecting Specific permission option allows you to manage access and provide the role-based access accordingly for
In Devtron Apps option, you can provide access to a user to manage permission for custom apps created using Devtron.
Note: The Devtron Apps option will be available only if you install CI/CD integration.
Provide the information in the following fields:
Project
Select a project from the drop-down list to which you want to give permission to the user. You can select only one project at a time.
Note: If you want to select more than one project, then click Add row.
Environment
Select the specific environment or all environments from the drop-down list.
Note: If you select All environments option, then a user gets access to all the current environments including any new environment which gets associated with the application later.
Application
Select the specific applications or all applications from the drop-down list corresponding to your selected Environments.
Note: If you select All applications option, then a user gets access to all the current applications including any new application which gets associated with the project later
.
Role
Select one of the to which you want to give permission to the user:
View only
Build and Deploy
Admin
Manager
You can add multiple rows for Devtron app permission.
Once you have finished assigning the appropriate permissions for the users, Click Save.
In Helm Apps option, you can provide access to a user to manage permission for Helm apps deployed from Devtron or outside Devtron.
Provide the information in the following fields:
Project
Select a project from the drop-down list to which you want to give permission to the user. You can select only one project at a time.
Note: If you want to select more than one project, then click Add row.
Environment or cluster/namespace
Select the specific environment or all existing environments in default cluster from the drop-down list.
Note: If you select all existing + future environments in default cluster option, then a user gets access to all the current environments including any new environment which gets associated with the application later.
Application
Select the specific application or all applications from the drop-down list corresponding to your selected Environments.
Note: If All applications option is selected, then a user gets access to all the current applications including any new application which gets associated with the project later
.
Role
Select one of the to which you want to give permission to the user:
View only
View & Edit
Admin
You can add multiple rows for Devtron app permission.
Once you have finished assigning the appropriate permissions for the users, Click Save.
In Kubernetes Resources option, you can provide permission to view, inspect, manage, and delete resources in your clusters from Kubernetes Resource Browser page in Devtron. You can also create resources from the Kubernetes Resource Browser page.
Note: Only super admin users will be able to see Kubernetes Resources tab and provide permission to other users to access Resource Browser.
To provide Kubernetes resource permission, click Add permission.
On the Kubernetes resource permission, provide the information in the following fields:
Cluster
Select a cluster from the drop-down list to which you want to give permission to the user. You can select only one cluster at a time.
Note: To add another cluster, then click Add another.
Namespace
Select the namespace from the drop-down list.
API Group
Select the specific API group or All API groups from the drop-down list corresponding to the K8s resource.
Kind
Select the kind or All kind from the drop-down list corresponding to the K8s resource.
Resource name
Select the resource name or All resources from the drop-down list to which you want to give permission to the user.
Role
Select one of the to which you want to give permission to the user and click Done:
View
Admin
You can add multiple rows for Kubernetes resource permission.
Once you have finished assigning the appropriate permissions for the users, Click Save.
In Chart group permission option, you can manage the access of users for Chart Groups in your project.
Note: The Chart group permission option will be available only if you install CI/CD integration.
NOTE: You can only give users the ability to create or edit, not both.
View
Enable View to view chart groups only.
Create
Enable Create if you want the users to create, view, edit or delete the chart groups.
Edit
Deny: Select Deny option from the drop-down list to restrict the users to edit the chart groups.
Specific chart groups: Select the Specific Charts Groups option from the drop-down list and then select the chart group for which you want to allow users to edit.
Click Saveonce you have configured all the required permissions for the users.
Direct user permissions cannot be edited if you're using LDAP/Microsoft for SSO and 'auto-assign permission' is enabled. Permissions can only be managed via permission groups in such a scenario.
You can edit the user permissions by clicking on the downward arrow.
Edit the user permissions.
After you have done editing the user permissions, click Save.
If you want to delete the user/users with particular permissions, click Delete.
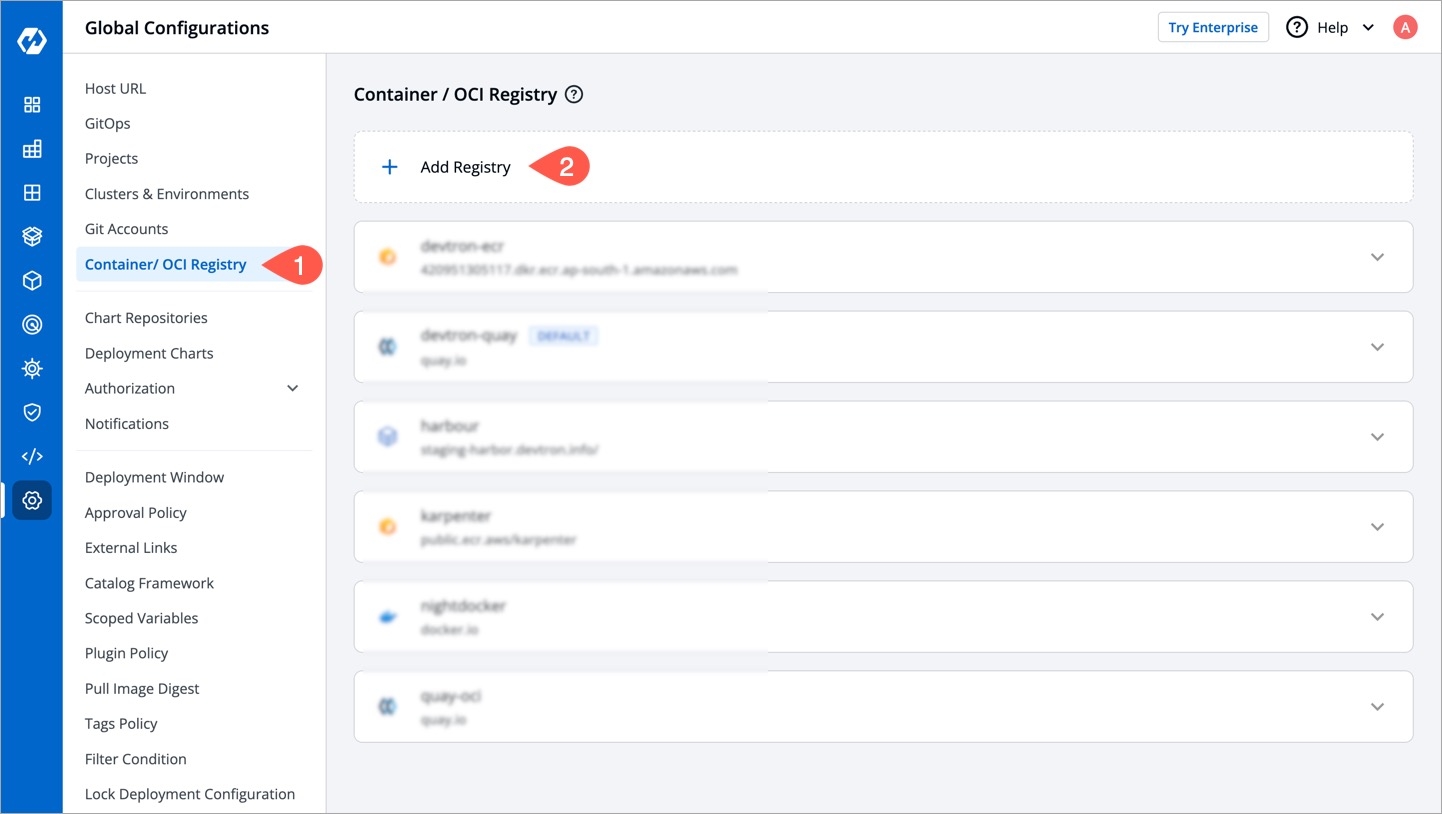
In Devtron, you can either use Helm or GitOps (Argo CD) to deploy your applications and charts. GitOps is a branch of DevOps that focuses on using Git repositories to manage infrastructure and application code deployments.
If you use the GitOps approach, Devtron will store Kubernetes configuration files and the desired state of your applications in Git repositories.
Go to Global Configurations → GitOps
Select any one of the to configure GitOps.
The Git provider you select for configuring GitOps might impact the following sections:
Fill all the mandatory fields. Refer to know more about the respective fields.
In the Directory Management in Git section, you get the following options:
Use default git repository structure:
This option lets Devtron automatically create a GitOps repository within your organization. The repository name will match your application name, and it cannot be changed. Since Devtron needs admin access to create the repository, ensure the Git credentials you provided in Step 3 have administrator rights.
Allow changing git repository for application:
Select this option if you wish to use your own GitOps repo. This is ideal if there are any confidentiality/security concerns that prevent you from giving us admin access. Therefore, the onus is on you to create a GitOps repo with your Git provider, and then on Devtron. Make sure the Git credentials you provided in Step 3 have at least read/write access. Choosing this option will unlock a page under the tab.
Click Save/Update. A green tick will appear on the active Git provider.
Alternatively, you may use the feature flag FEATURE_USER_DEFINED_GITOPS_REPO_ENABLE to enable or disable custom GitOps repo.
Go to .
Select the cluster where Devtron is running, i.e., default_cluster.
Go to the Config & Storage dropdown on the left.
Click ConfigMap.
Use the namespace filter (located on the right-hand side) to select devtroncd namespace. Therefore, it will show only the ConfigMaps related to Devtron, and filter out the rest.
Find the ConfigMap meant for the dashboard of your Devtron instance, i.e., dashboard-cm (with an optional suffix).
Click Edit Live Manifest.
Add the feature flag (with the intended boolean value) within the data dictionary
Click Apply Changes.
Below are the Git providers supported in Devtron for storing configuration files.
Fill the following mandatory fields:
Fill the following mandatory fields:
An organization on Azure DevOps. If you don't have one, refer .
A project in your Azure DevOps organization. Refer .
Fill the following mandatory fields:
Here, you get 2 options:
- Select this if you wish to store GitOps configuration in a web-based Git repository hosting service offered by Bitbucket.
- Select this if you wish to store GitOps configuration in a git repository hosted on a self-managed Bitbucket Data Center (on-prem).
Fill the following mandatory fields:
Fill the following mandatory fields:
We do NOT recommend using GitHub organization that contains your source code.
Create a new account on GitHub (if you do not have one).
On the upper-right corner of your GitHub page, click your profile photo, then click Settings.
On the Access section, click Organizations.
On the Organizations section, click New organization.
Pick a for your organization. You have the option to select create free organization also.
On the Set up your organization page,
Enter the organization account name, contact email.
Select the option your organization belongs to.
Verify your account and click Next.
Your GitHub organization name will be created.
Go to your profile and click Your organizations to view all the organizations you created.
For more information about the plans available for your team, see . You can also refer official doc page for more detail.
Note:
repo - Full control of private repositories (able to access commit status, deployment status, and public repositories).
admin:org - Full control of organizations and teams (Read and write access).
delete_repo - Grants delete repo access on private repositories.
Create a new account on GitLab (if you do not have one).
You can create a group by going to the 'Groups' tab on the GitLab dashboard and click New group.
Select Create group.
Enter the group name (required) and select the optional descriptions if required, and click Create group.
Your group will be created and your group name will be assigned with a new Group ID (e.g. 61512475).
Note:
api - Grants complete read/write access to the scoped project API.
write_repository - Allows read/write access (pull, push) to the repository.
Go to Azure DevOps and navigate to Projects.
Select your organization and click New project.
On the Create new project page,
Enter the project name and description of the project.
Select the visibility option (private or public), initial source control type, and work item process.
Click Create.
Azure DevOps displays the project welcome page with the project name.
You can also refer official page for more details.
Note:
code - Grants the ability to read source code and metadata about commits, change sets, branches, and other version control artifacts. .
Create a new individual account on Bitbucket (if you do not have one).
Select your profile and settings avatar on the upper-right corner of the top navigation bar.
Select All workspaces from the dropdown menu.
Select the Create workspace on the upper-right corner of the Workspaces page.
On the Create a Workspace page:
Enter a Workspace name.
Enter a Workspace ID. Your ID cannot have any spaces or special characters, but numbers and capital letters are fine. This ID becomes part of the URL for the workspace and anywhere else where there is a label that identifies the team (APIs, permission groups, OAuth, etc.).
Click Create.
Your Workspace name and Workspace ID will be created.
You can also refer for more details.
Note:
repo - Full control of repositories (Read, Write, Admin, Delete) access.
After your CI pipeline is ready, you can start building your CD pipeline. Devtron enables you to design your CD pipeline in a way that fully automates your deployments. Images from CI stage can be deployed to one or more environments through dedicated CD pipelines.
Click the '+' sign on CI Pipeline to attach a CD Pipeline to it.
A basic Create deployment pipeline window will pop up.
Here, you get three sections:
This section expects four inputs from you:
Devtron supports multiple deployment strategies depending on the .
Refer to know more about each strategy in depth.
This option is available at the bottom of the Create deployment pipeline window.
Now, the window will have 3 distinct tabs, and you will see the following additions:
If your deployment requires prior actions like DB migration, code quality check (QC), etc., you can use the Pre-deployment stage to configure such tasks.
Tasks
Here you can add one or more tasks. The tasks can be re-arranged using drag-and-drop and they will be executed sequentially.
Trigger Pre-Deployment Stage
Refer the trigger types from .
ConfigMaps & Secrets
If you want to use some configuration files and secrets in pre-deployment stages or post-deployment stages, then you can use the ConfigMaps & Secrets options. You will get them as a drop-down in the pre-deployment stage.
Execute tasks in application environment
These Pre-deployment CD / Post-deployment CD pods can be created in your deployment cluster or the devtron build cluster. If your scripts/tasks has some dependency on the deployment environment, you may run these pods in the deployment cluster. Thus, your scripts (if any) can interact with the cluster services that may not be publicly exposed.
Some tasks require extra permissions for the node where Devtron is installed. However, if the node already has the necessary permissions for deploying applications, there is no need to assign them again. Instead, you can enable the Execute tasks in application environment option for the pre-CD or post-CD steps. By default, this option is disabled.
To enable the Execute tasks in application environment option, follow these steps:
Go to the chart store and search for the devtron-in-clustercd chart.
Configure the chart according to your requirements and deploy it in the target cluster.
After the deployment, edit the devtron-cm configmap and add the following key-value pair:
ORCH_HOST value should be same as of CD_EXTERNAL_LISTENER_URL value which is passed in values.yaml.
Delete the Devtron pod using the following command:
Again navigate to the chart store and search for the "migration-incluster-cd" chart.
Edit the cluster-name and secret name values within the chart. The cluster name refers to the name used when adding the cluster in the global configuration and for which you are going to enable Execute tasks in application environment option.
Deploy the chart in any environment within the Devtron cluster. Now you should be able to enable Execute tasks in application environment option for an environment of target cluster.
Pipeline name will be auto-generated; however, you are free to modify the name as per your requirement.
If you want only approved images to be eligible for deployment, enable the Manual approval for deployment option in the respective deployment pipeline. By doing so, unapproved images would be prevented from being deployed for that deployment pipeline.
Users can also specify the number of approvals required for each deployment, where the permissible limit ranges from one approval (minimum) to six approvals (maximum). In other words, if the image doesn't get the specified number of approvals, it will not be eligible for deployment
To enable manual approval for deployment, follow these steps:
Click the deployment pipeline for which you want to enable manual approval.
Turn on the ‘Manual approval for deployment’ toggle button.
Select the number of approvals required for each deployment.
To know more about the approval process, refer .
This will be utilized only when an existing container image is copied to another repository using the . The image will be copied with the tag generated by the Image Tag Pattern you defined.
Enable the toggle button as shown below.
Click the edit icon.
You can write an alphanumeric pattern for your image tag, e.g., prod-v1.0.{x}. Here, 'x' is a mandatory variable whose value will incrementally increase with every pre or post deployment trigger (that option is also available to you). You can also define the value of 'x' for the next trigger in case you want to change it.
Click Update Pipeline.
To know how and where this image tag would appear, refer
Although Devtron ensures that remain unique, the same cannot be said if images are pushed with the same tag to the same container registry from outside Devtron.
Therefore, to eliminate the possibility of pulling an unintended image, Devtron offers the option to pull container images using digest and image tag.
An image digest is a unique and immutable SHA-256 string returned by the container registry when you push an image. So the image referenced by the digest will never change.
Users need to have Admin permission or above (along with access to the environment and application) to enable this option. However, this option will be non-editable in case the super-admin has enabled .
If you need to run any actions for e.g., closure of Jira ticket, load testing or performance testing, you can configure such actions in the post-deployment stages.
Post-deployment stages are similar to pre-deployment stages. The difference is, pre-deployment executes before the deployment, while post-deployment occurs after.
You can use in post deployments as well. The option to execute tasks in application environment is available too.
You can update the deployment stages and the deployment strategy of the CD Pipeline whenever you require it. However, you cannot change the name of a CD Pipeline or its Deployment Environment. If you want a new CD pipeline for the same environment, first delete the previous CD pipeline.
To update a CD Pipeline, go to the App Configurations section, Click on Workflow editor and then click on the CD Pipeline you want to Update.
Make changes as needed and click on Update Pipeline to update this CD Pipeline.
If you no longer require the CD Pipeline, you can also delete the Pipeline.
To delete a CD Pipeline, go to the App Configurations and then click on the Workflow editor. Now click on the pipeline you wish to delete. A pop-up having the CD details will appear. Verify the name and the details to ensure that you are not accidentally deleting the wrong CD pipeline and then click Delete Pipeline to delete it.
Deleting a CD pipeline also deletes all the K8s resources associated with it and will bring a disruption in the deployed micro-service. Before deleting a CD pipeline, please ensure that the associated resources are not being used in any production workload.
A deployment strategy is a method of updating, downgrading, or creating new versions of an application. The options you see under deployment strategy depend on the selected chart type (see fig 2). Below are some deployment configuration-based strategies.
Blue-green deployments involve running two versions of an application at the same time and moving traffic from the in-production version (the green version) to the newer version (the blue version).
A rolling deployment slowly replaces instances of the previous version of an application with instances of the new version of the application. Rolling deployment typically waits for new pods to become ready via a readiness check before scaling down the old components. If a significant issue occurs, the rolling deployment can be aborted.
Canary deployments are a pattern for rolling out releases to a subset of users or servers. The idea is to first deploy the change to a small subset of servers, test it, and then roll the change out to the rest of the servers. The canary deployment serves as an early warning indicator with less impact on downtime: if the canary deployment fails, the rest of the servers aren't impacted.
The recreate strategy is a dummy deployment that consists of shutting down version 'A' and then deploying version 'B' after version 'A' is turned off.
A recreate deployment incurs downtime because, for a brief period, no instances of your application are running. However, your old code and new code do not run at the same time. It terminates the old version and releases the new one.
Unlike other strategies mentioned above, 'Recreate' strategy doesn't contain keys for you to configure.
Devtron supports attaching multiple deployment pipelines to a single build pipeline, in its workflow editor. This feature lets you deploy an image first to stage, run tests and then deploy the same image to production.
Please follow the steps mentioned below to create sequential pipelines:
After creating CI/build pipeline, create a CD pipeline by clicking on the + sign on CI pipeline and configure the CD pipeline as per your requirements.
To add another CD Pipeline sequentially after previous one, again click on + sign on the last CD pipeline.
Similarly, you can add multiple CD pipelines by clicking + sign of the last CD pipeline, each deploying in different environments.
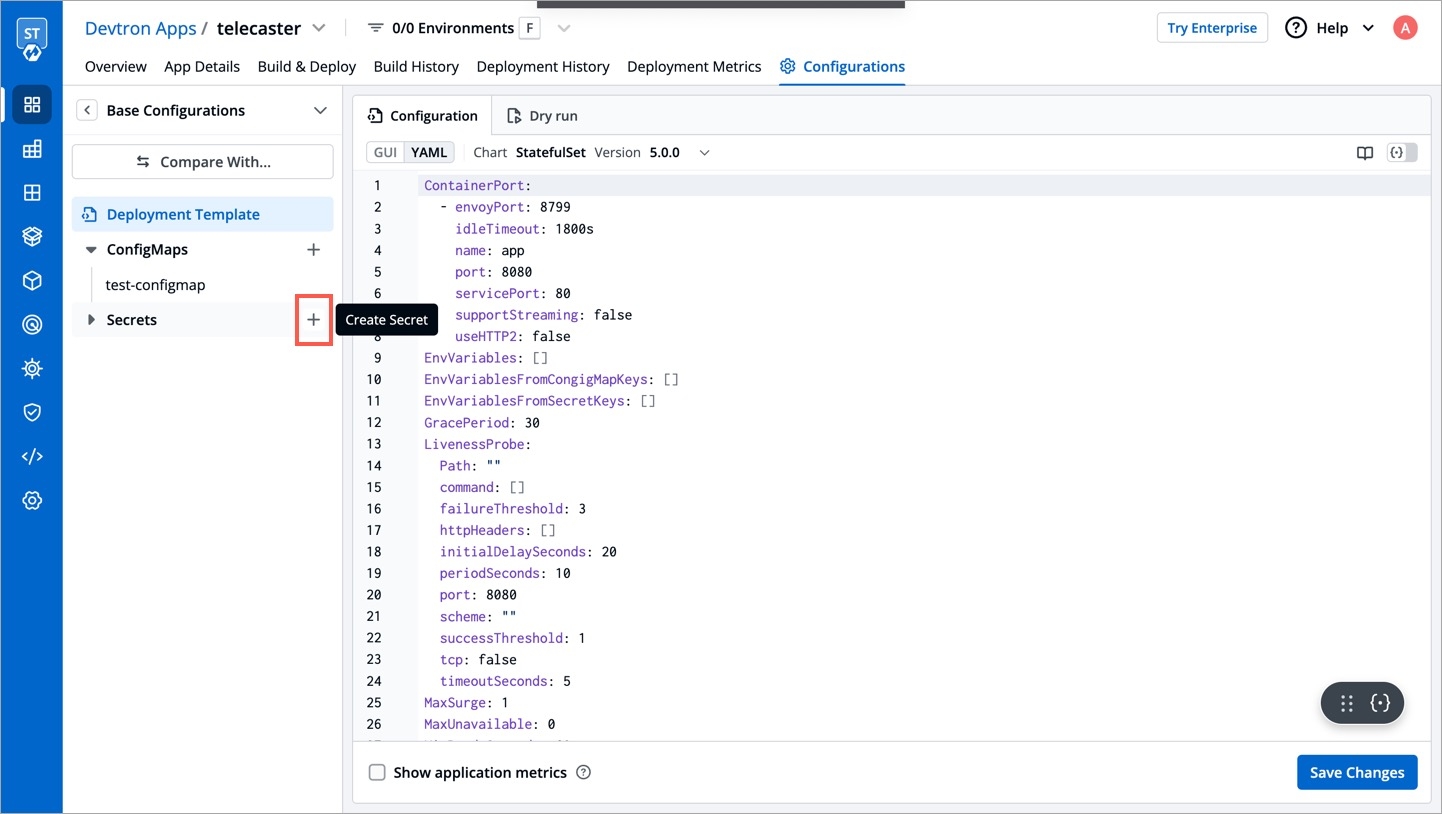
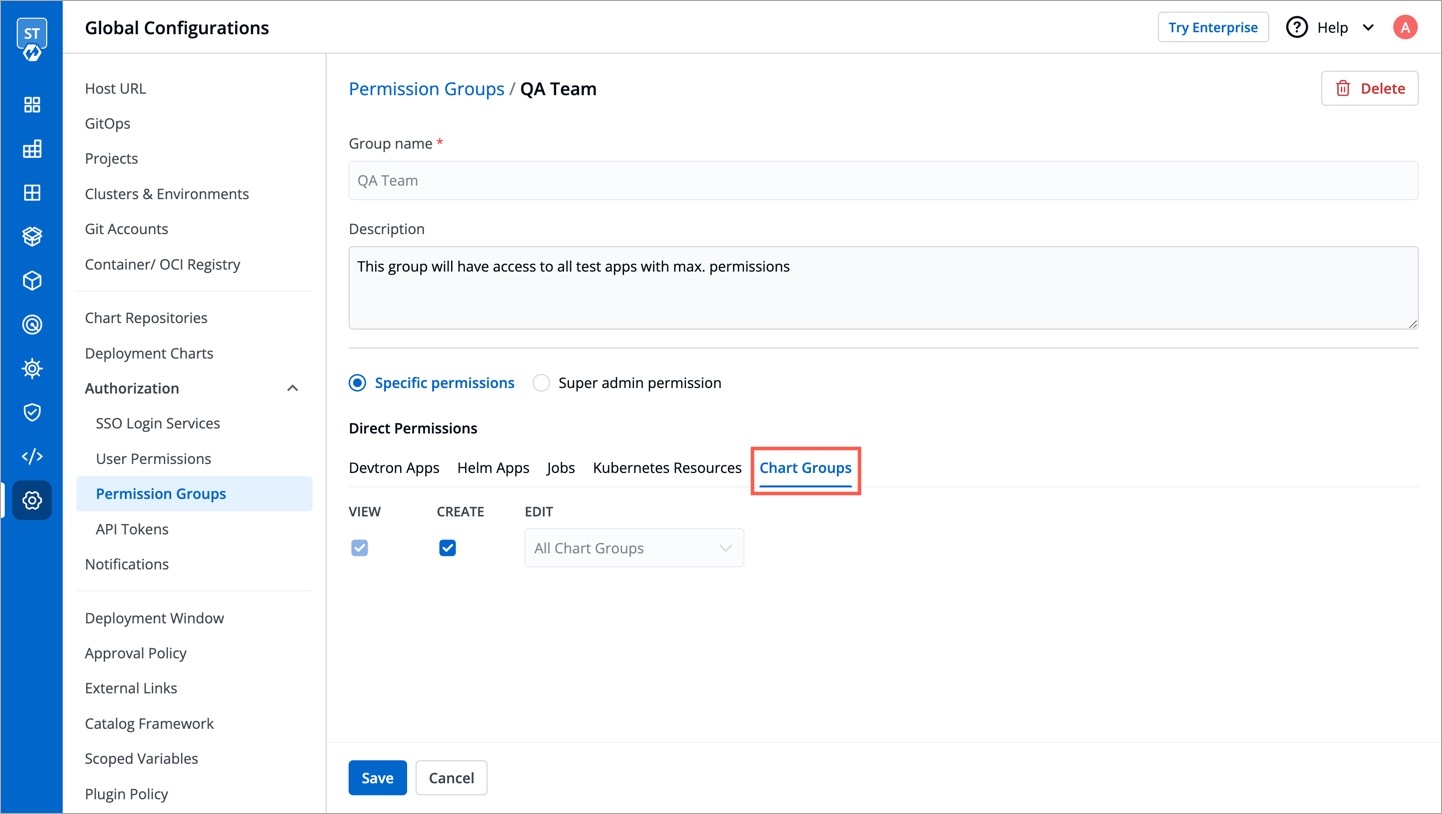
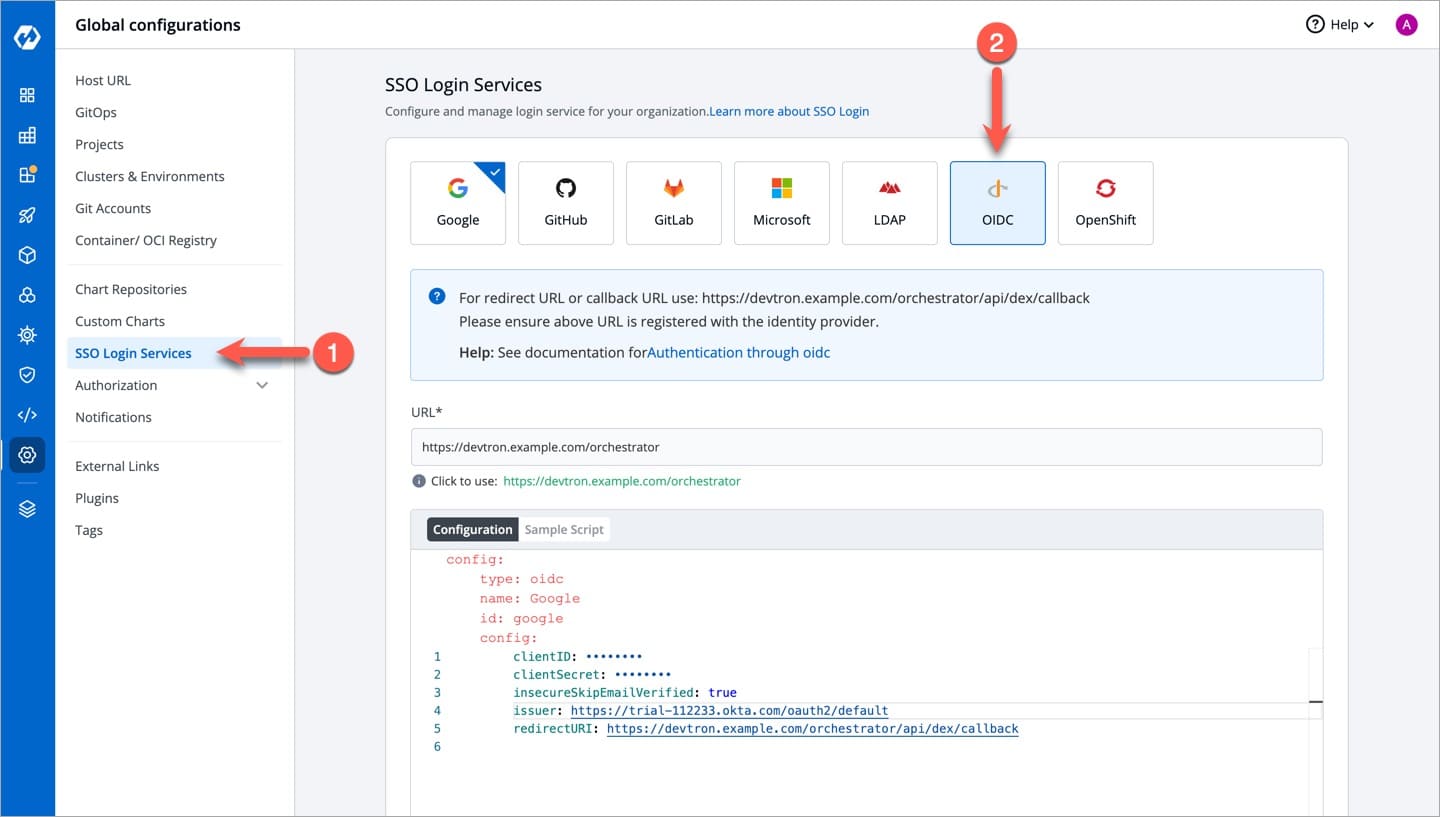
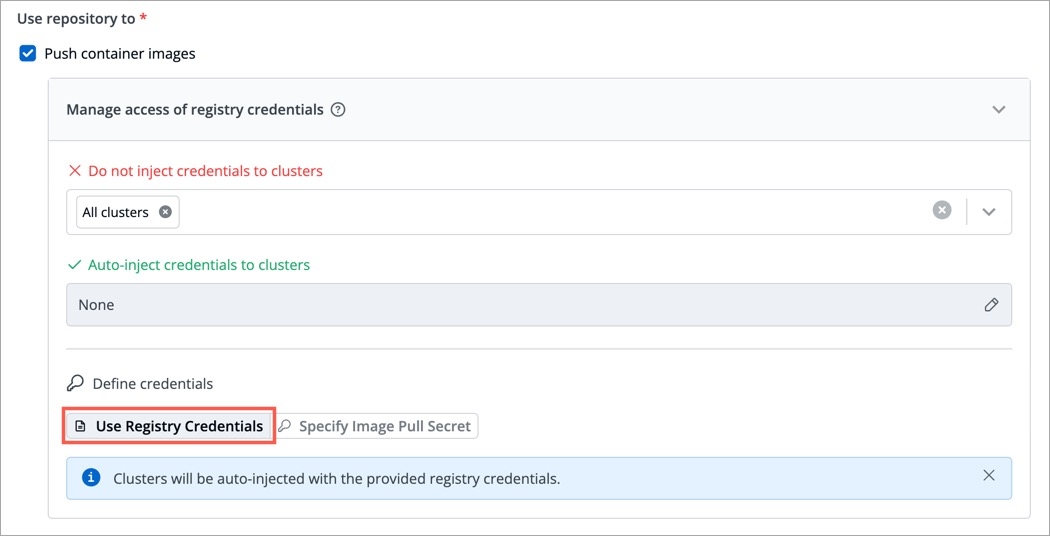
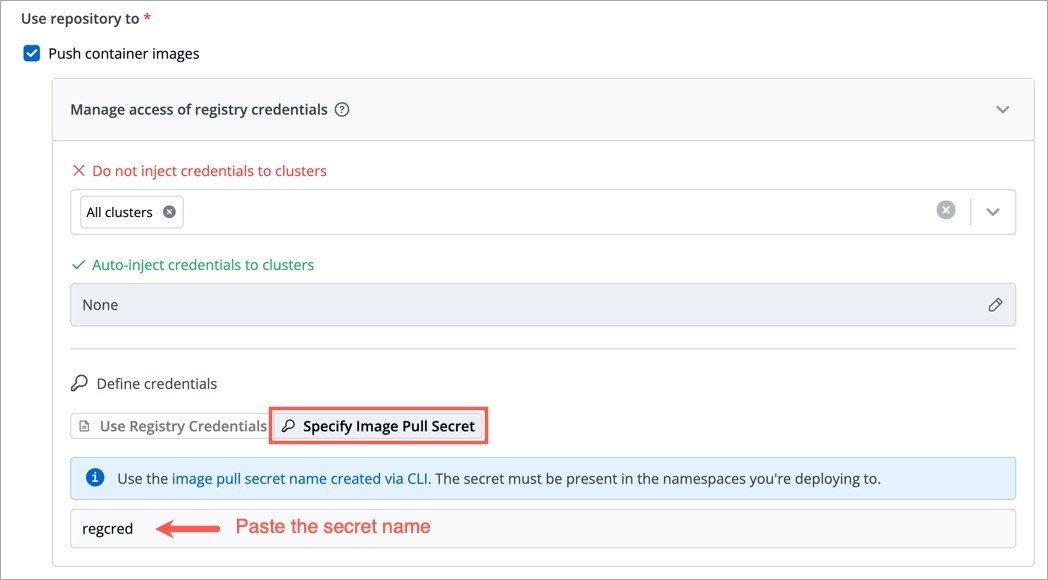
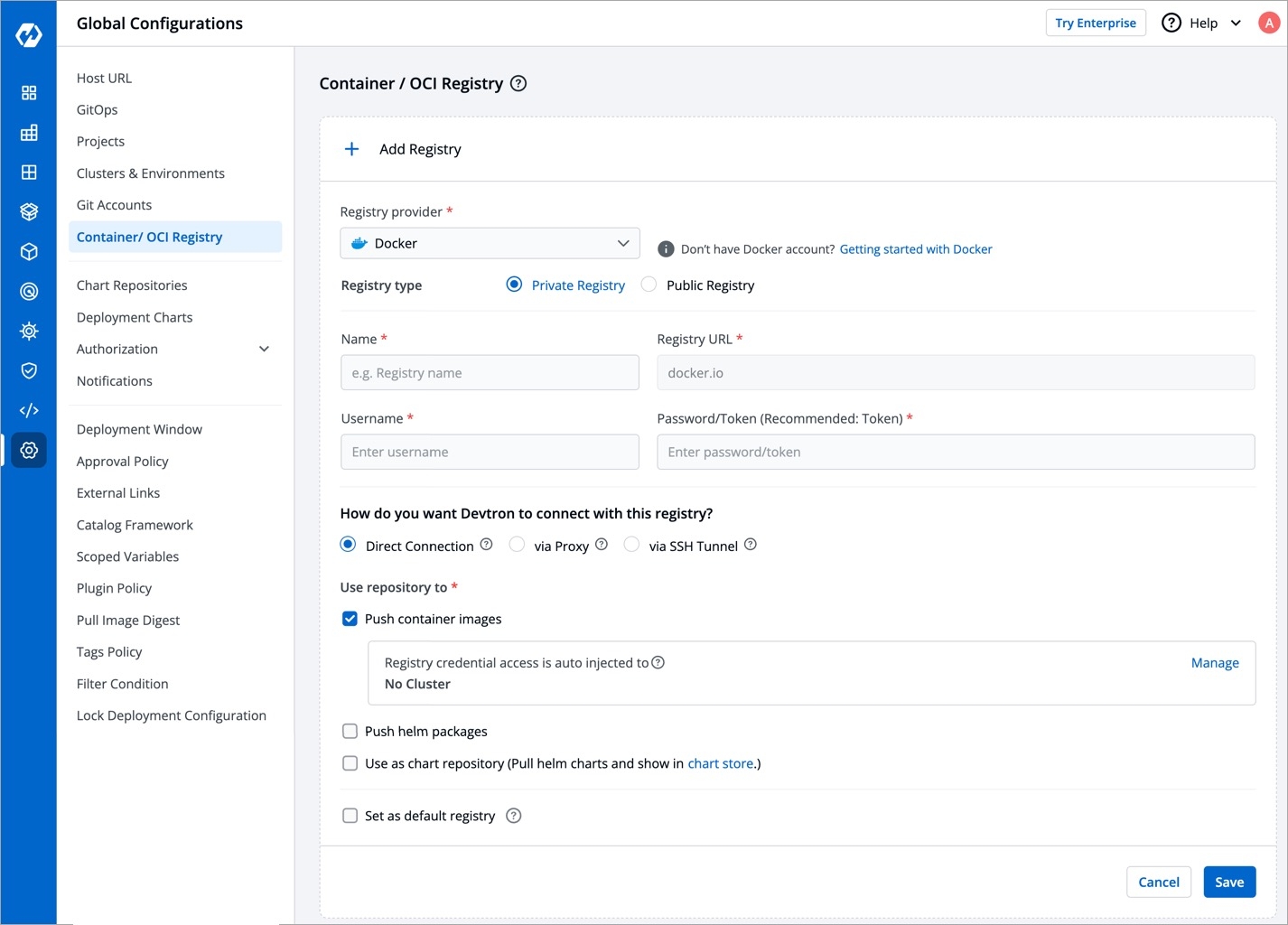
Git Host
Shows the URL of GitHub, e.g., https://github.com/
GitHub Organisation Name
Enter the GitHub organization name. If you do not have one, refer how to create organization in Github.
GitHub Username
Provide the username of your GitHub account
Personal Access Token
Provide your personal access token (PAT). It is used as an alternate password to authenticate your GitHub account. If you do not have one, create a GitHub PAT here.
Git Host
Shows the URL of GitLab, e.g., https://gitlab.com/
GitLab Group ID
Enter the GitLab group ID. If you do not have one, refer GitLab Group ID.
GitLab Username
Provide the username of your GitLab account
Personal Access Token
Provide your personal access token (PAT). It is used as an alternate password to authenticate your GitLab account. If you do not have one, create a GitLab PAT here.
Azure DevOps Organisation Url*
Enter the Org URL of Azure DevOps. Format should be https://dev.azure.com/<org-name>, where <org-name> represents the organization name, e.g., https://dev.azure.com/devtron-test
Azure DevOps Project Name
Enter the Azure DevOps project name. If you do not have one, refer Azure DevOps Project Name.
Azure DevOps Username*
Provide the username of your Azure DevOps account
Azure DevOps Access Token*
Provide your Azure DevOps access token. It is used as an alternate password to authenticate your Azure DevOps account. If you do not have one, create a Azure DevOps access token here.
Bitbucket Host
Shows the URL of Bitbucket Cloud, e.g., https://bitbucket.org/
Bitbucket Workspace ID
Enter the Bitbucket workspace ID. If you do not have one, refer Bitbucket Workspace Id
Bitbucket Project Key
Enter the Bitbucket project key. If you do not have one, refer Bitbucket Project Key. Note: If the project is not provided, the repository is automatically assigned to the oldest project in the workspace.
Bitbucket Username*
Provide the username of your Bitbucket account
Personal Access Token
Provide your personal access token (PAT). It is used as an alternate password to authenticate your Bitbucket Cloud account. If you do not have one, create a Bitbucket Cloud PAT here.
Bitbucket Host
Enter the URL address of your Bitbucket Data Center, e.g., https://bitbucket.mycompany.com
Bitbucket Project Key
Enter the Bitbucket project key. Refer Bitbucket Project Key.
Bitbucket Username*
Provide the username of your Bitbucket Data Center account
Password
Provide the password to authenticate your Bitbucket Data Center account
Environment
Select the environment where you want to deploy your application
(List of available environments)
Namespace
Automatically populated based on the selected environment
Not Applicable
Trigger
When to execute the deployment pipeline
Automatic: Deployment triggers automatically when a new image completes the previous stage (build pipeline or another deployment pipeline) Manual: Deployment is not initiated automatically. You can trigger deployment with a desired image.
Deployment Approach
How to deploy the application
Helm or GitOps Refer GitOps
ORCH_HOST: <host_url>/orchestrator/webhook/msg/nats
Example:
ORCH_HOST: http://xyz.devtron.com/orchestrator/webhook/msg/nats
kubectl delete pod -l app=devtron -n devtroncdEnsure your custom tag do not start or end with a period (.) or comma (,)blueGreen:
autoPromotionSeconds: 30
scaleDownDelaySeconds: 30
previewReplicaCount: 1
autoPromotionEnabled: falseautoPromotionSeconds
It will make the rollout automatically promote the new ReplicaSet to active Service after this time has passed
scaleDownDelaySeconds
It is used to delay scaling down the old ReplicaSet after the active Service is switched to the new ReplicaSet
previewReplicaCount
It will indicate the number of replicas that the new version of an application should run
autoPromotionEnabled
It will make the rollout automatically promote the new ReplicaSet to the active service
rolling:
maxSurge: "25%"
maxUnavailable: 1maxSurge
No. of replicas allowed above the scheduled quantity
maxUnavailable
Maximum number of pods allowed to be unavailable
canary:
maxSurge: "25%"
maxUnavailable: 1
steps:
- setWeight: 25
- pause:
duration: 15 # 1 min
- setWeight: 50
- pause:
duration: 15 # 1 min
- setWeight: 75
- pause:
duration: 15 # 1 minmaxSurge
It defines the maximum number of replicas the rollout can create to move to the correct ratio set by the last setWeight
maxUnavailable
The maximum number of pods that can be unavailable during the update
setWeight
It is the required percent of pods to move to the next step
duration
It is used to set the duration to wait to move to the next step
recreate:
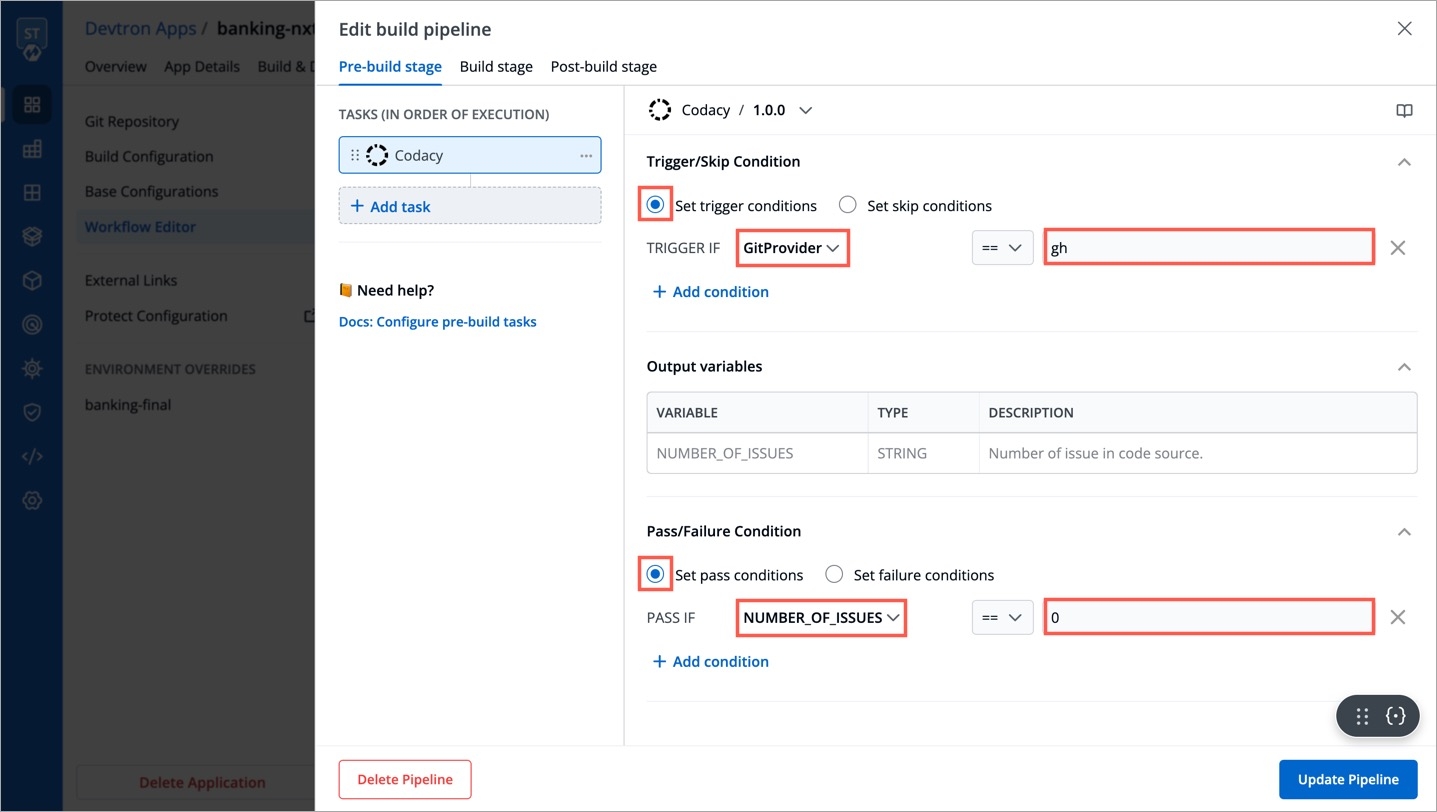
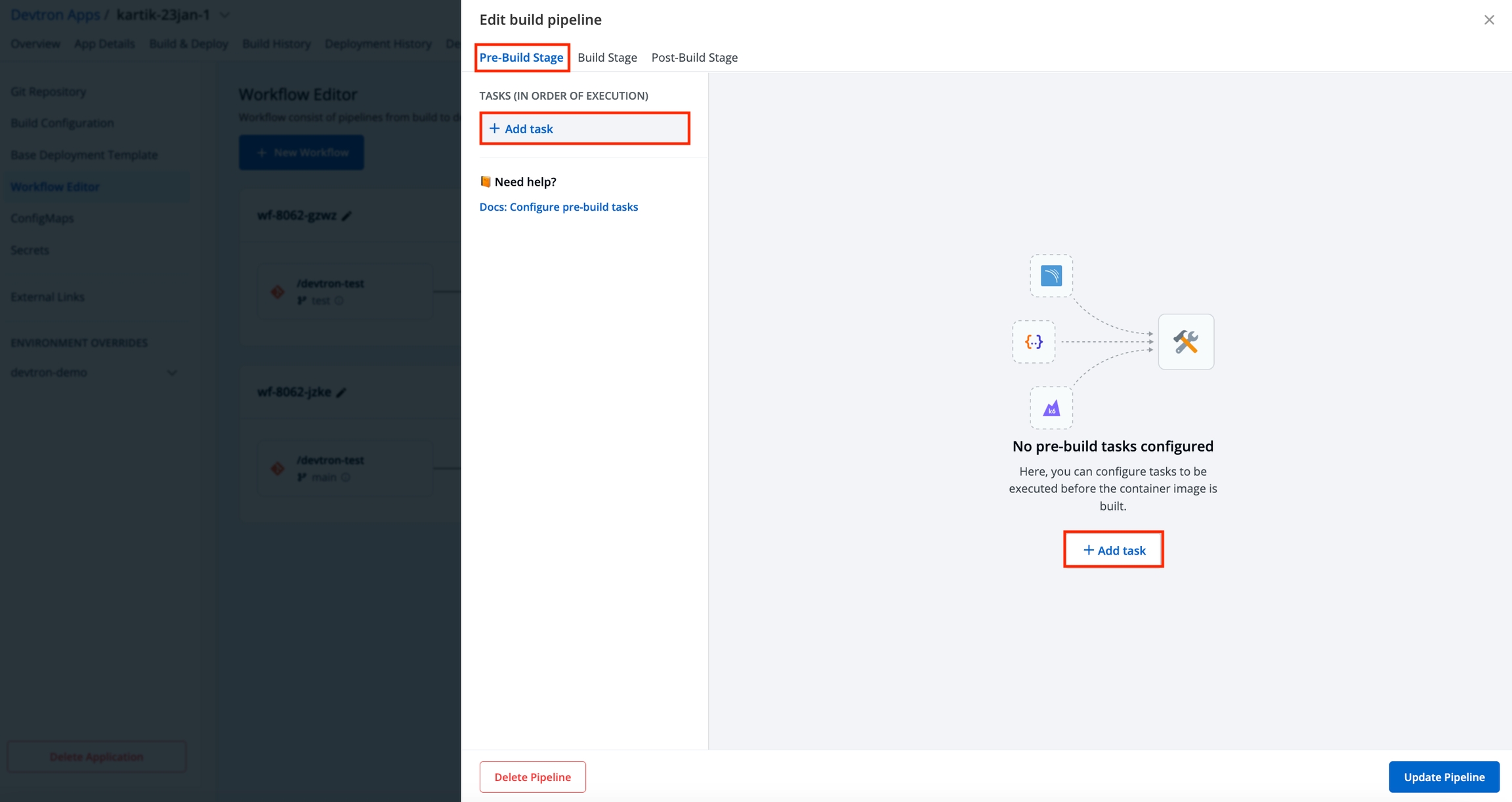
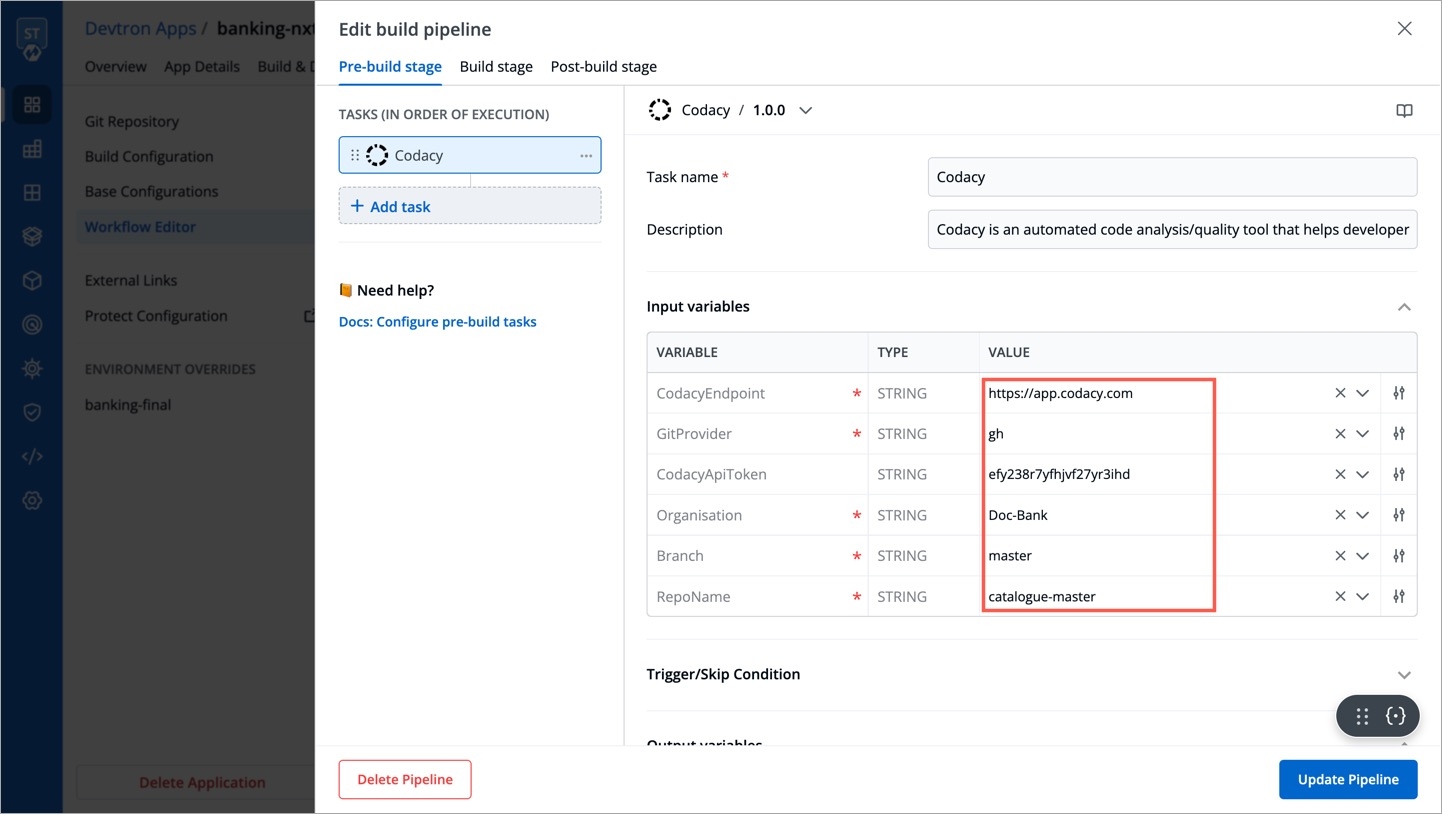
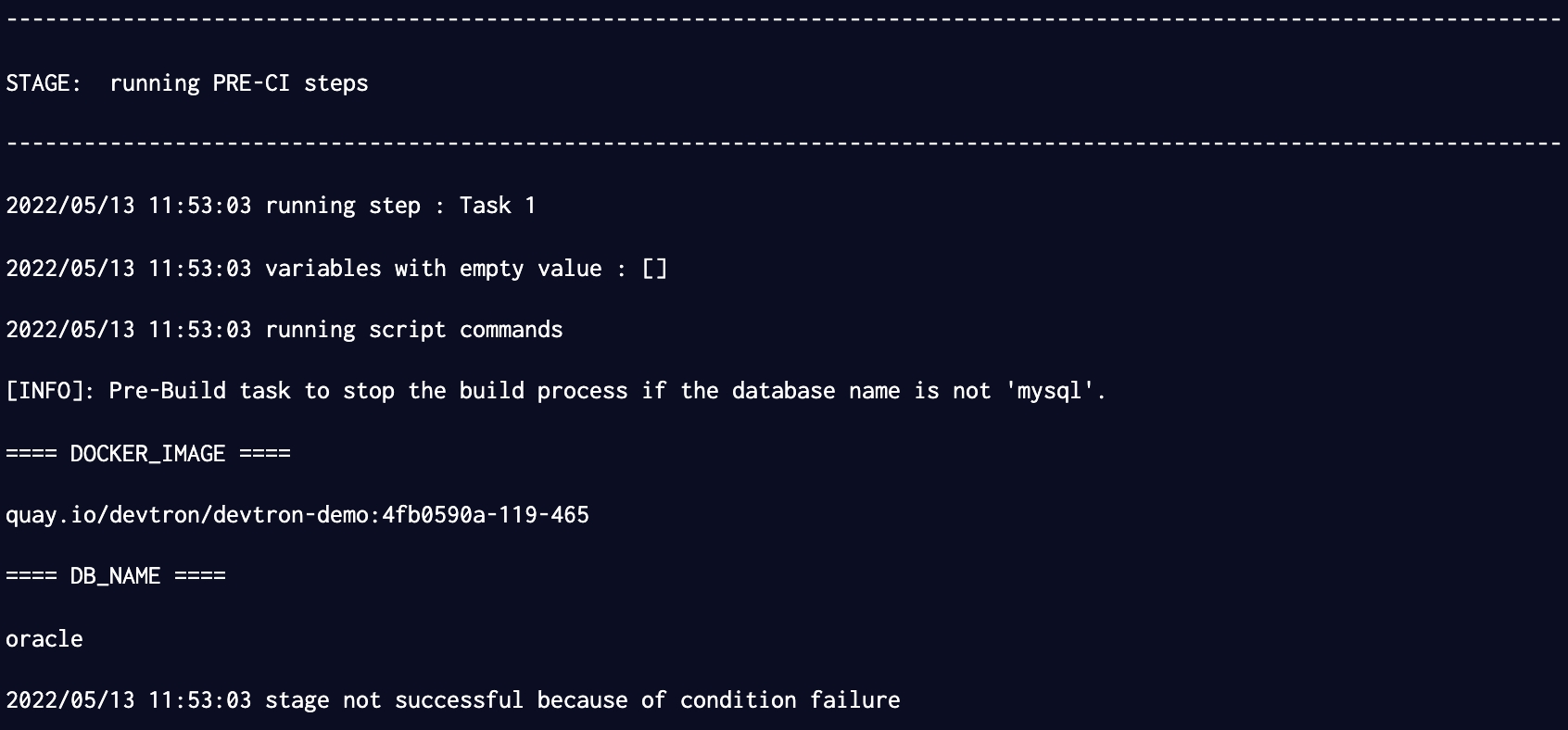
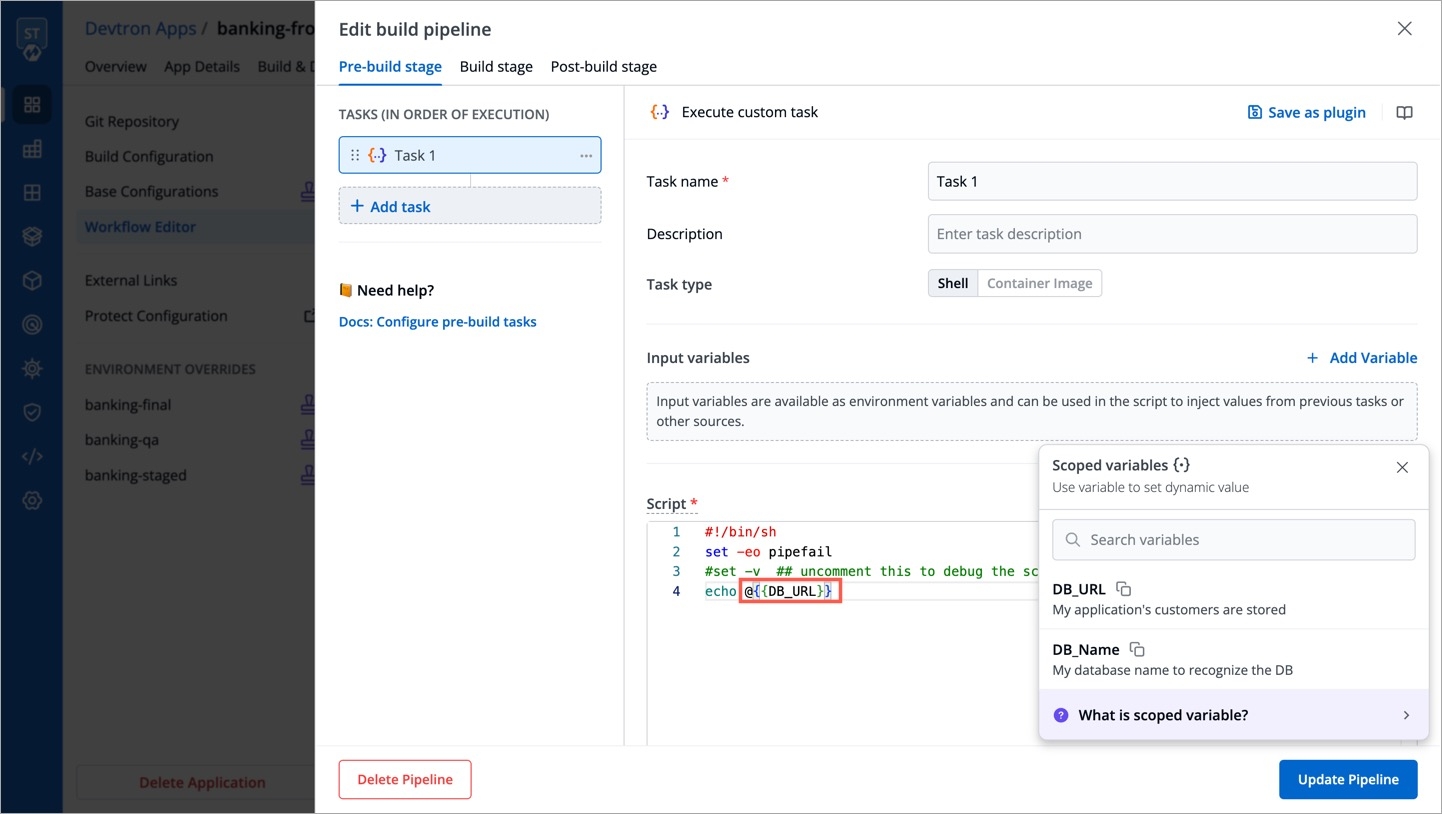
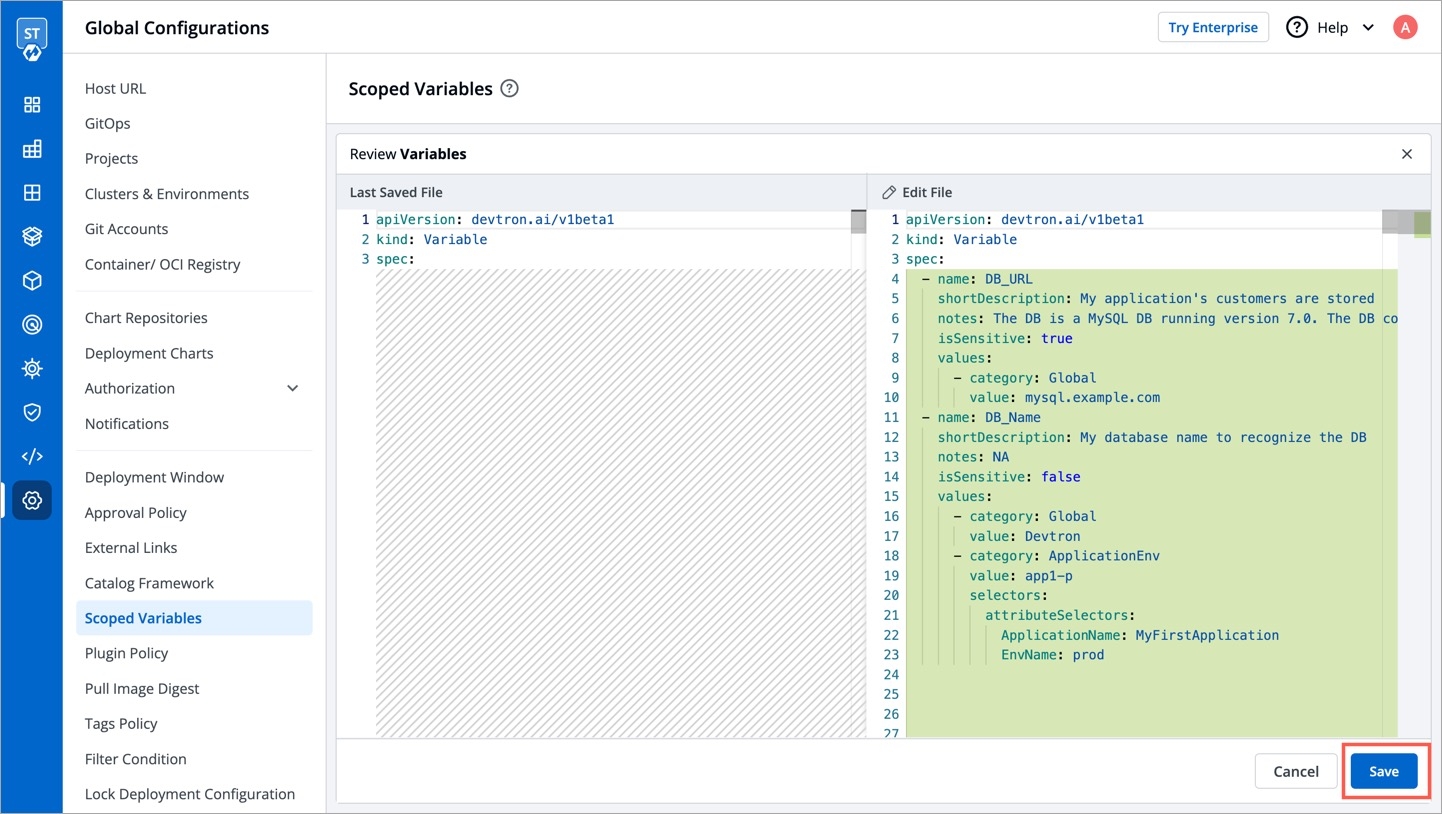
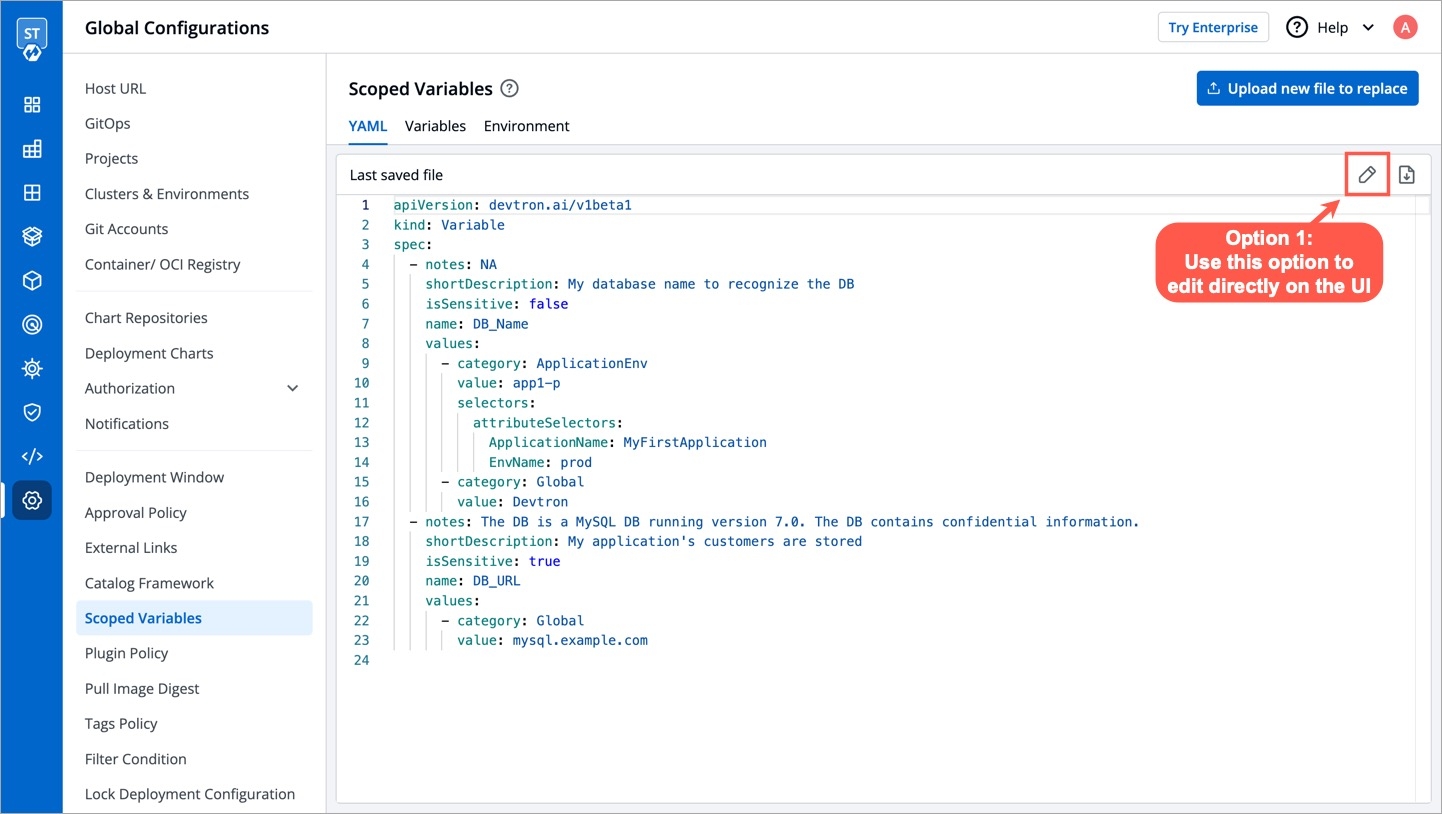
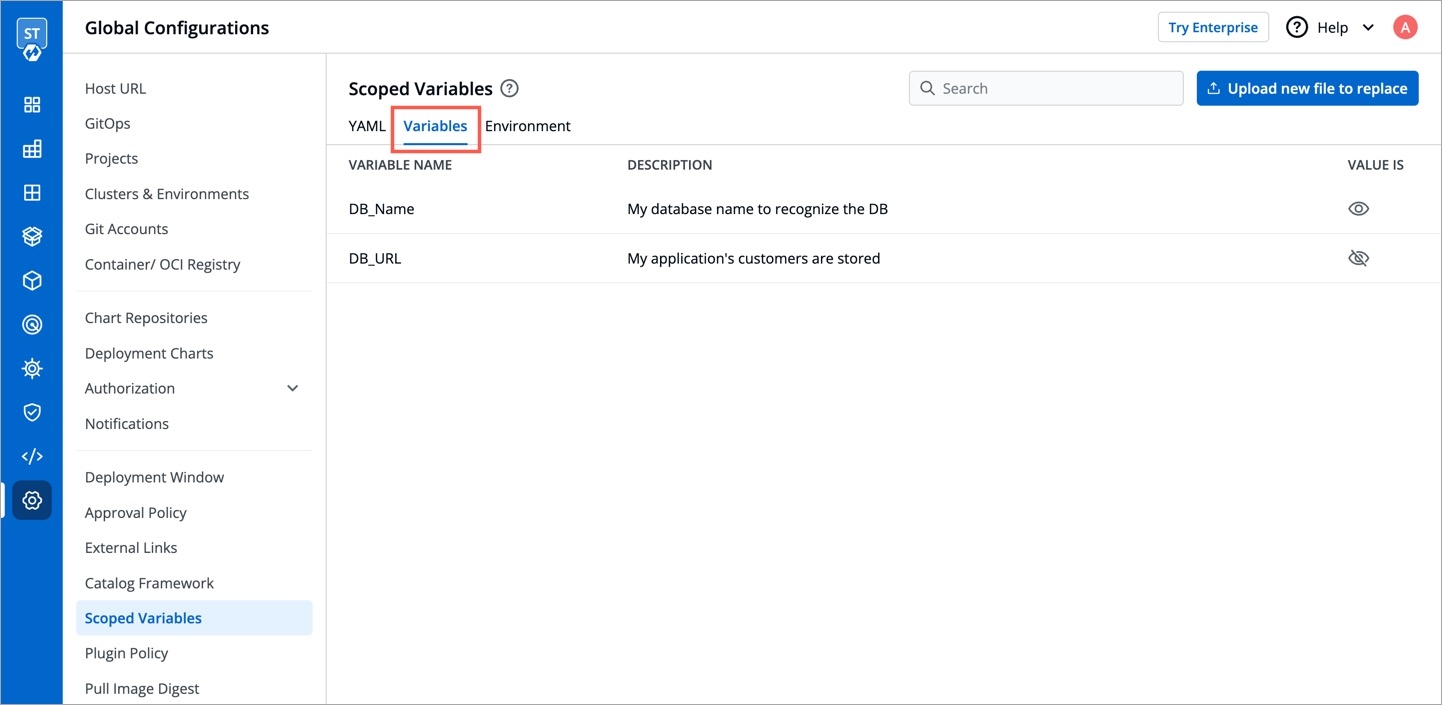
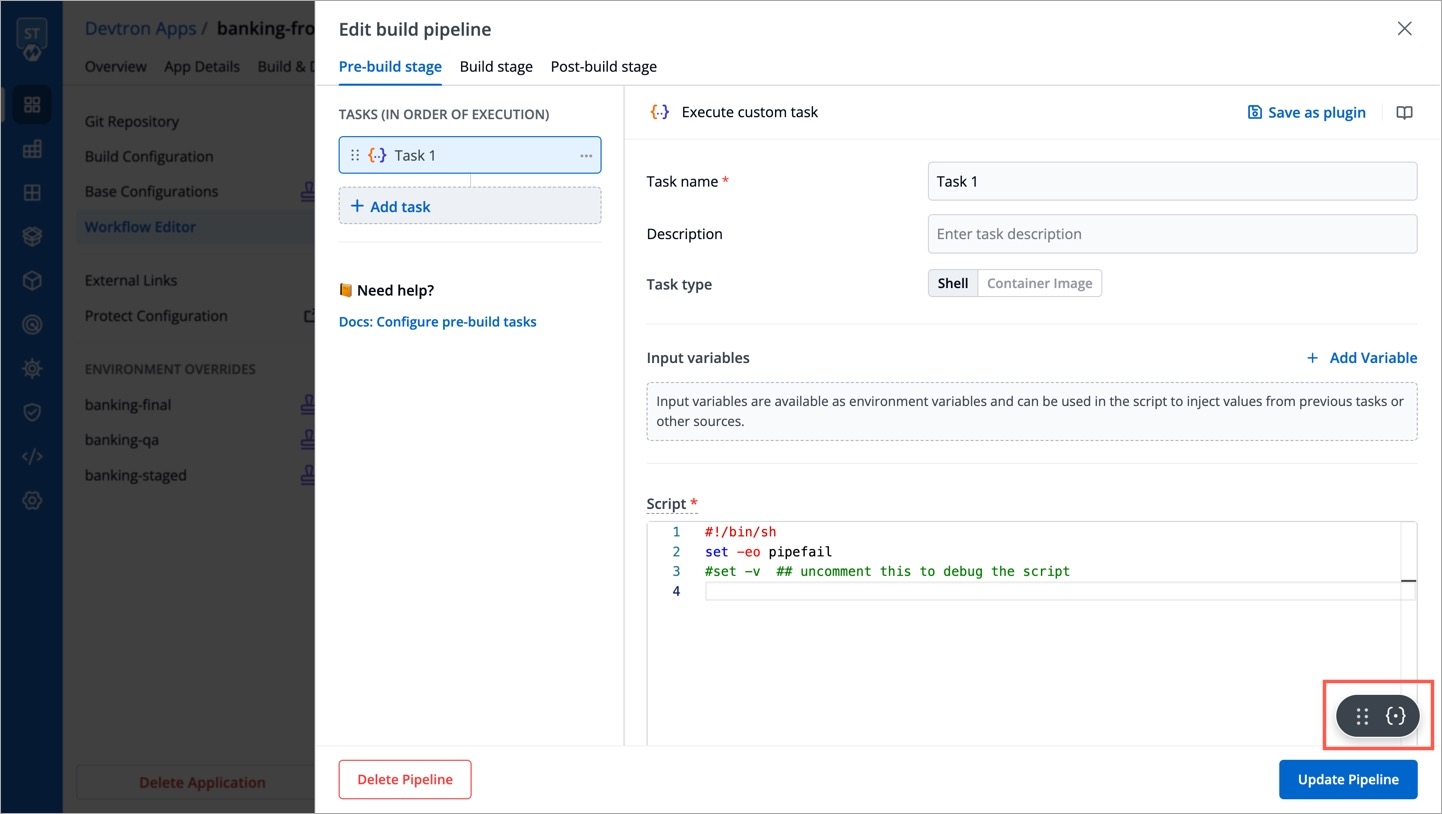
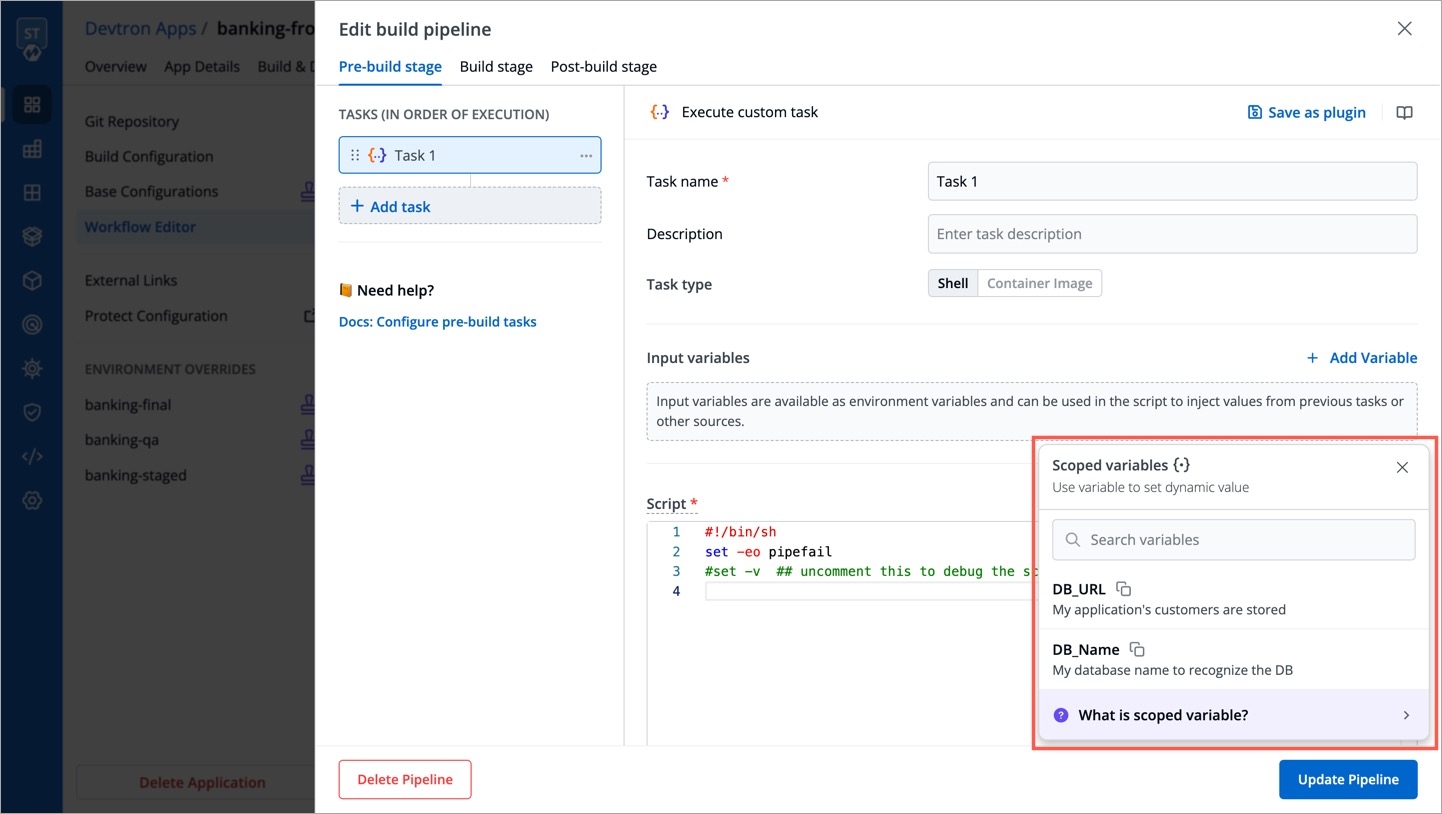
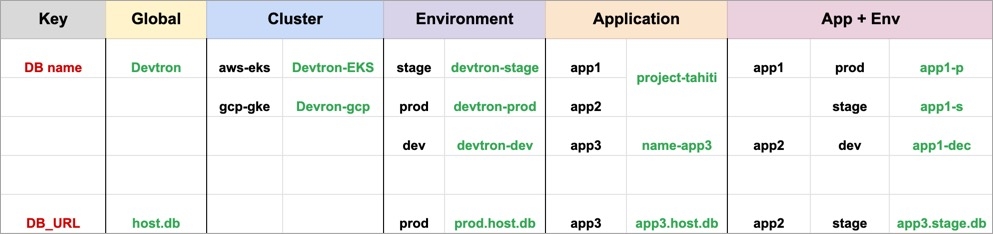
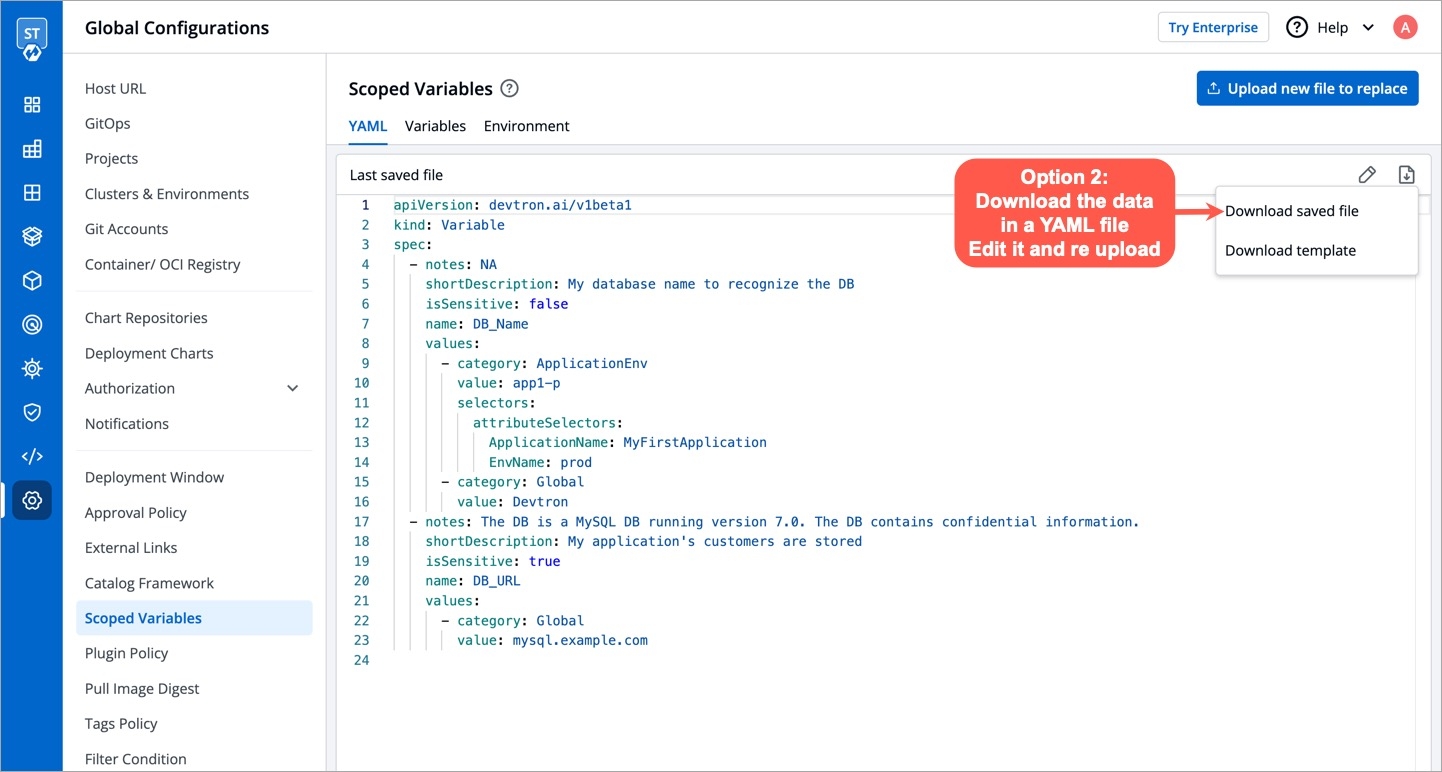
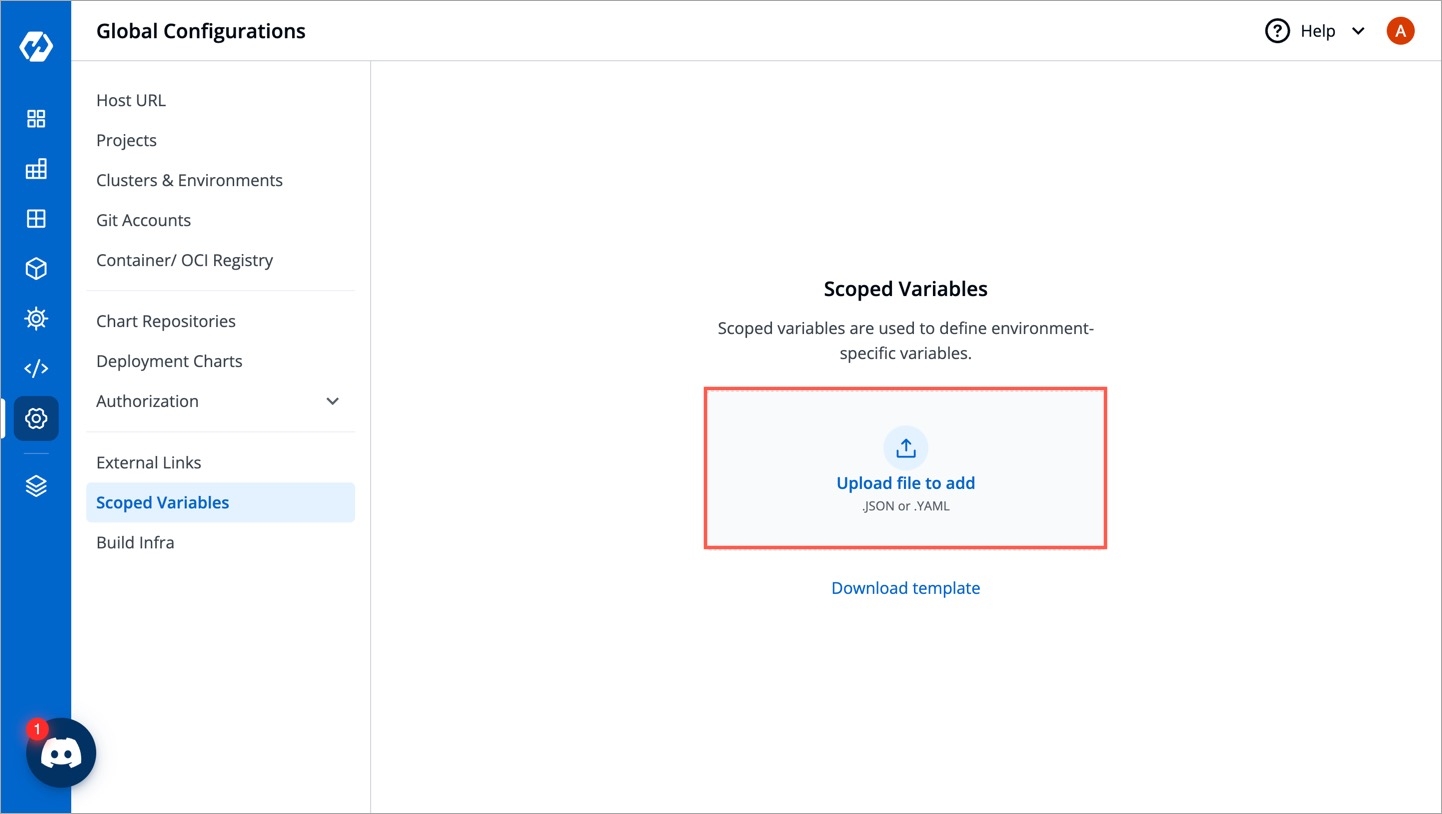
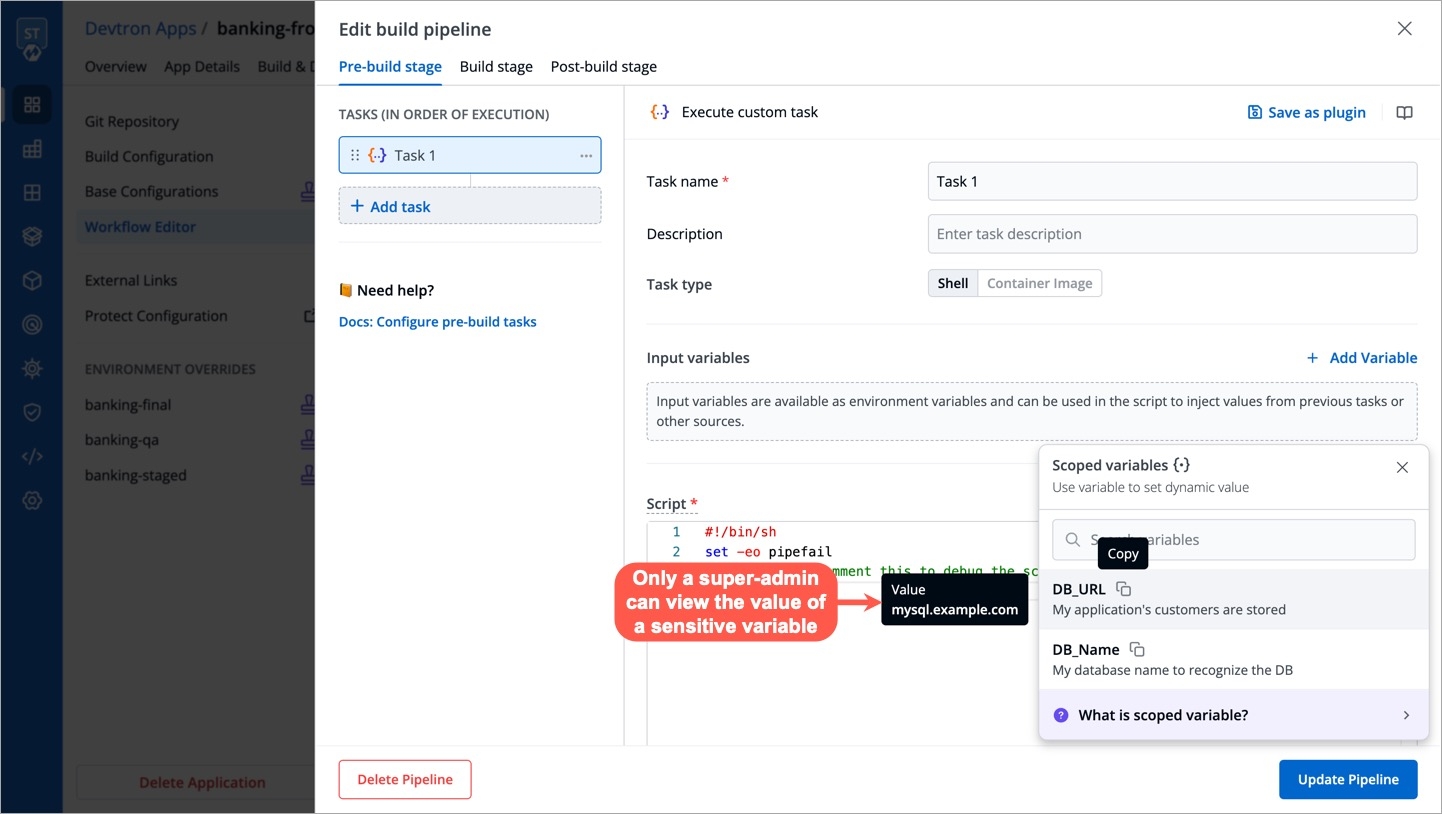
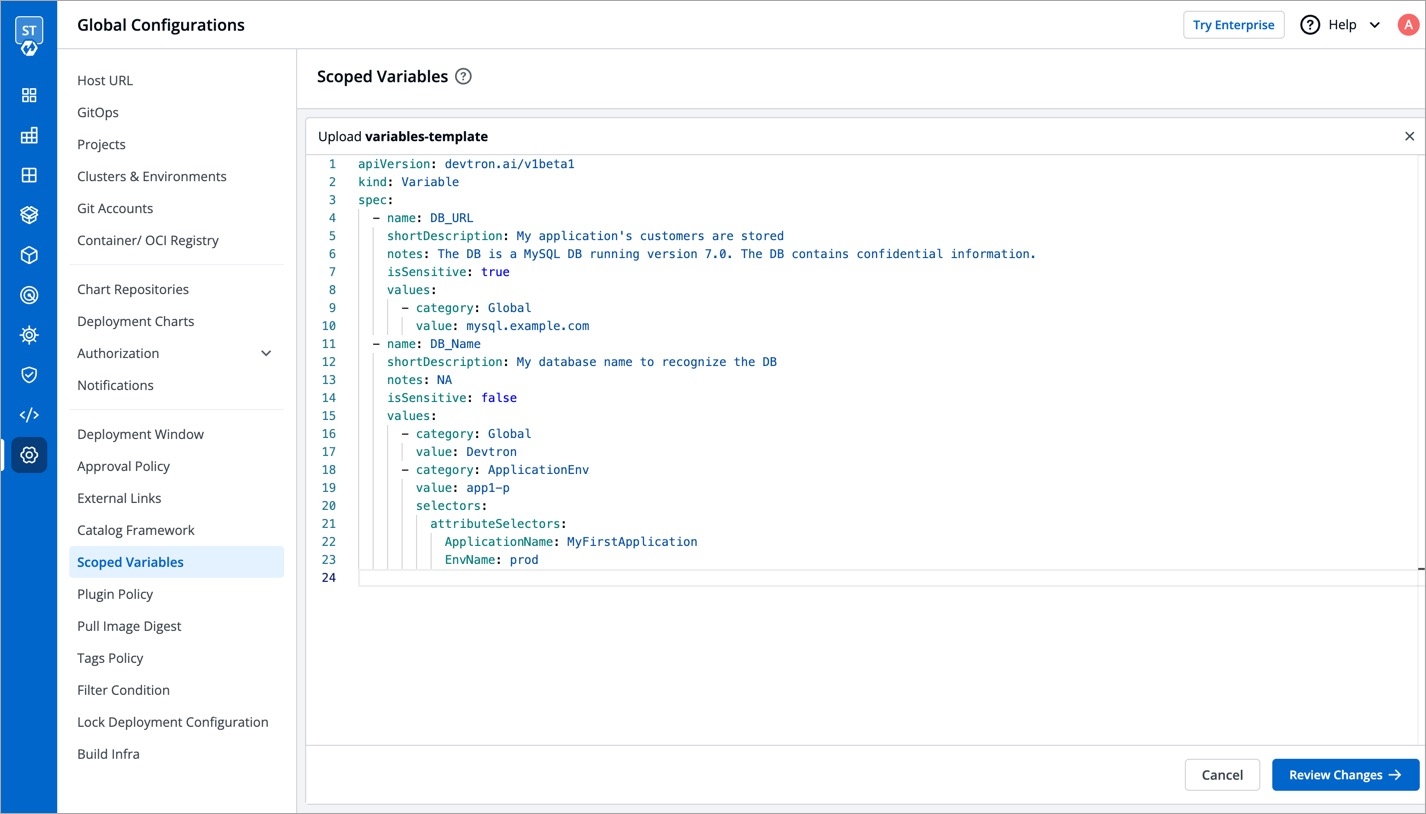
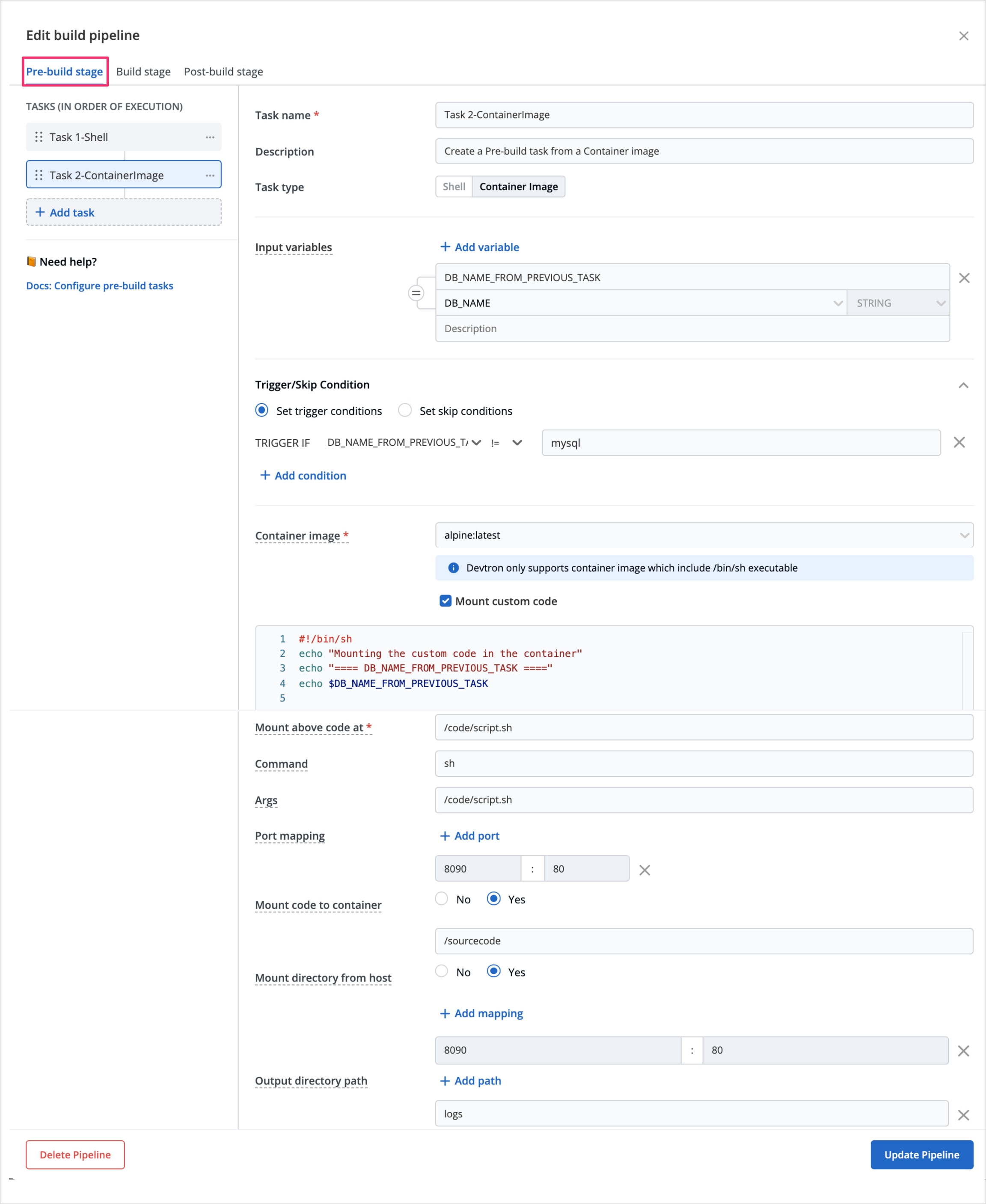
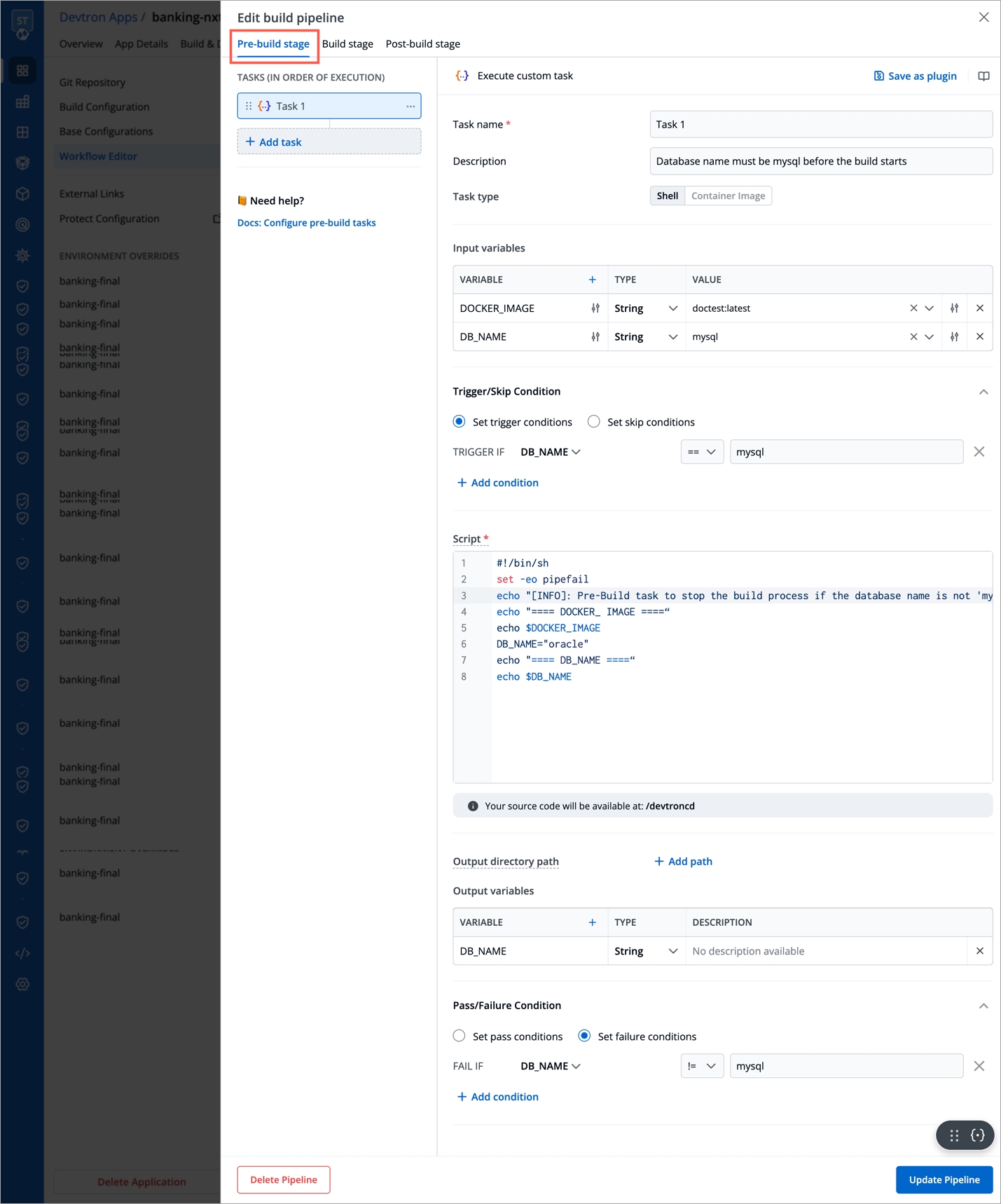
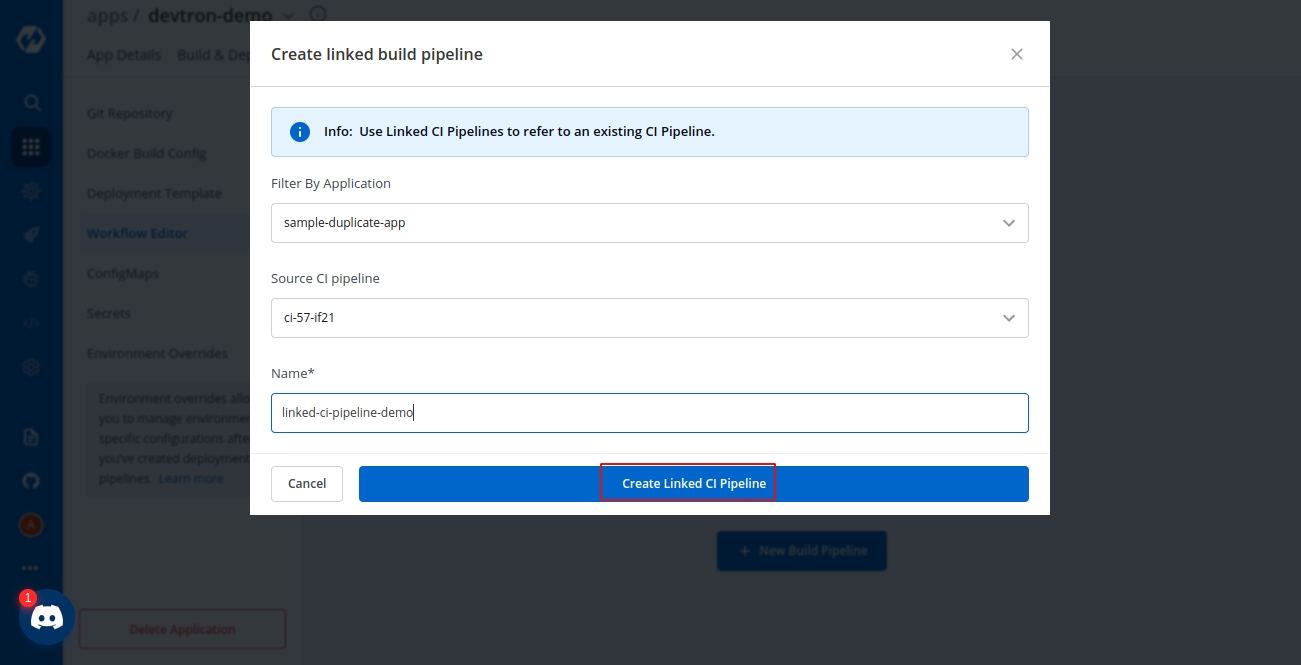
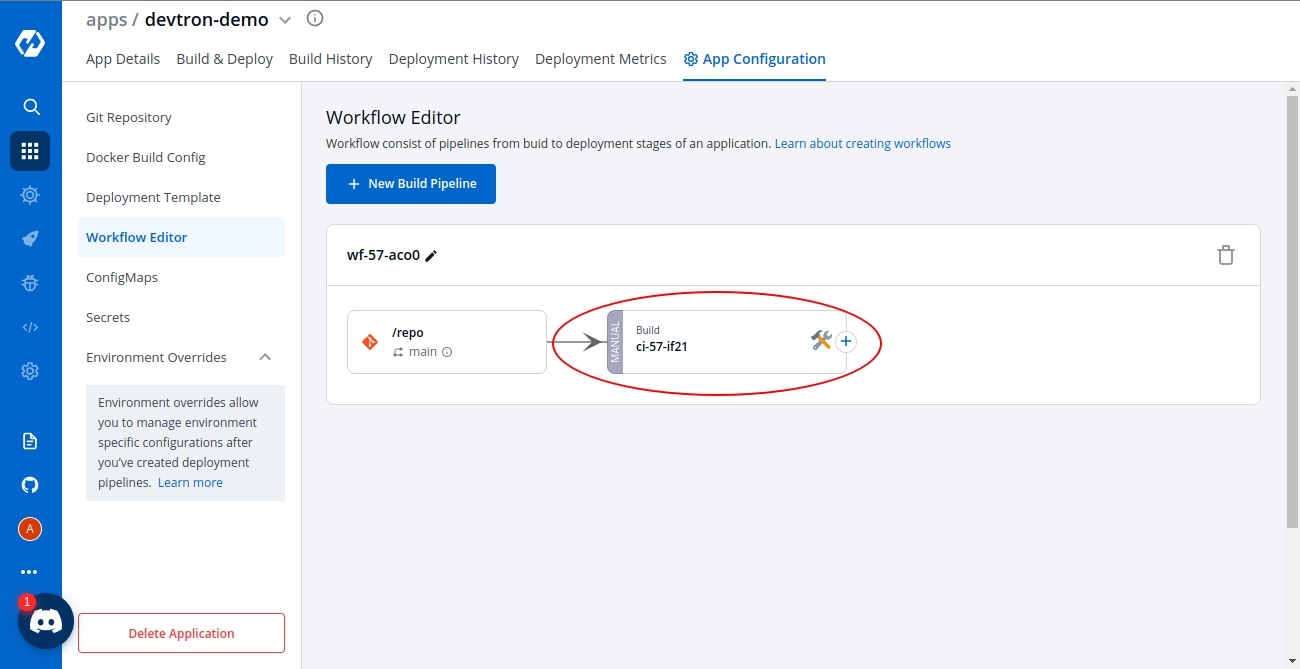
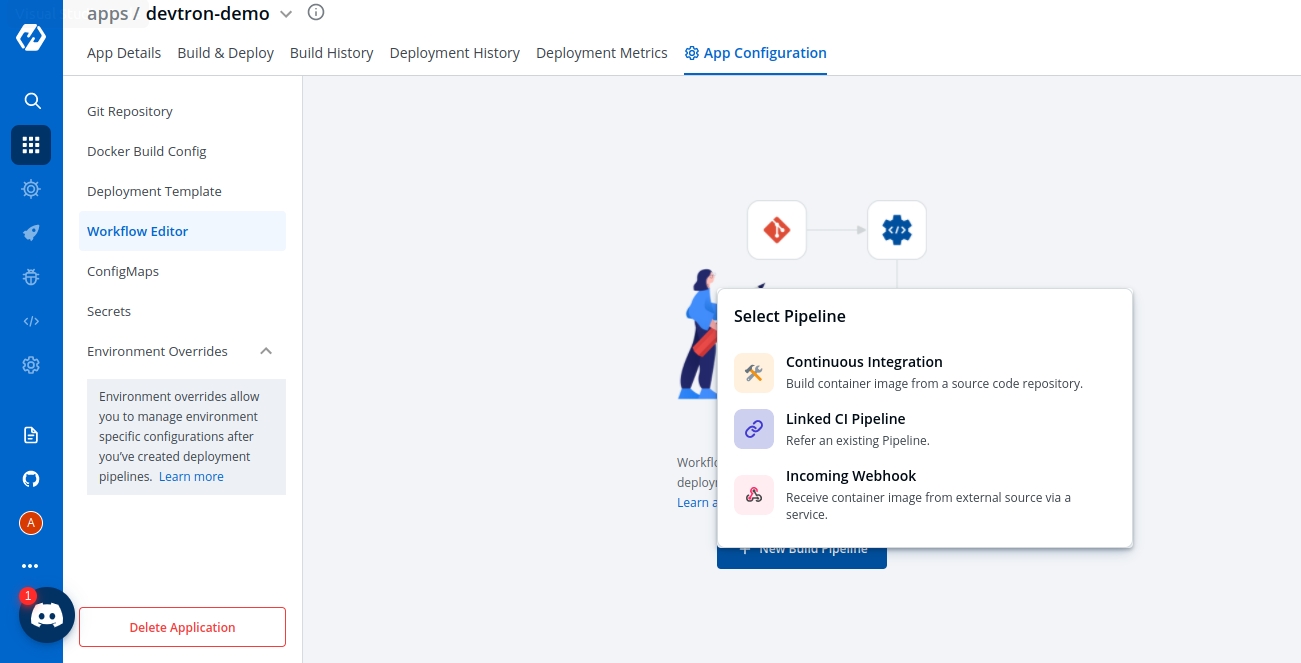
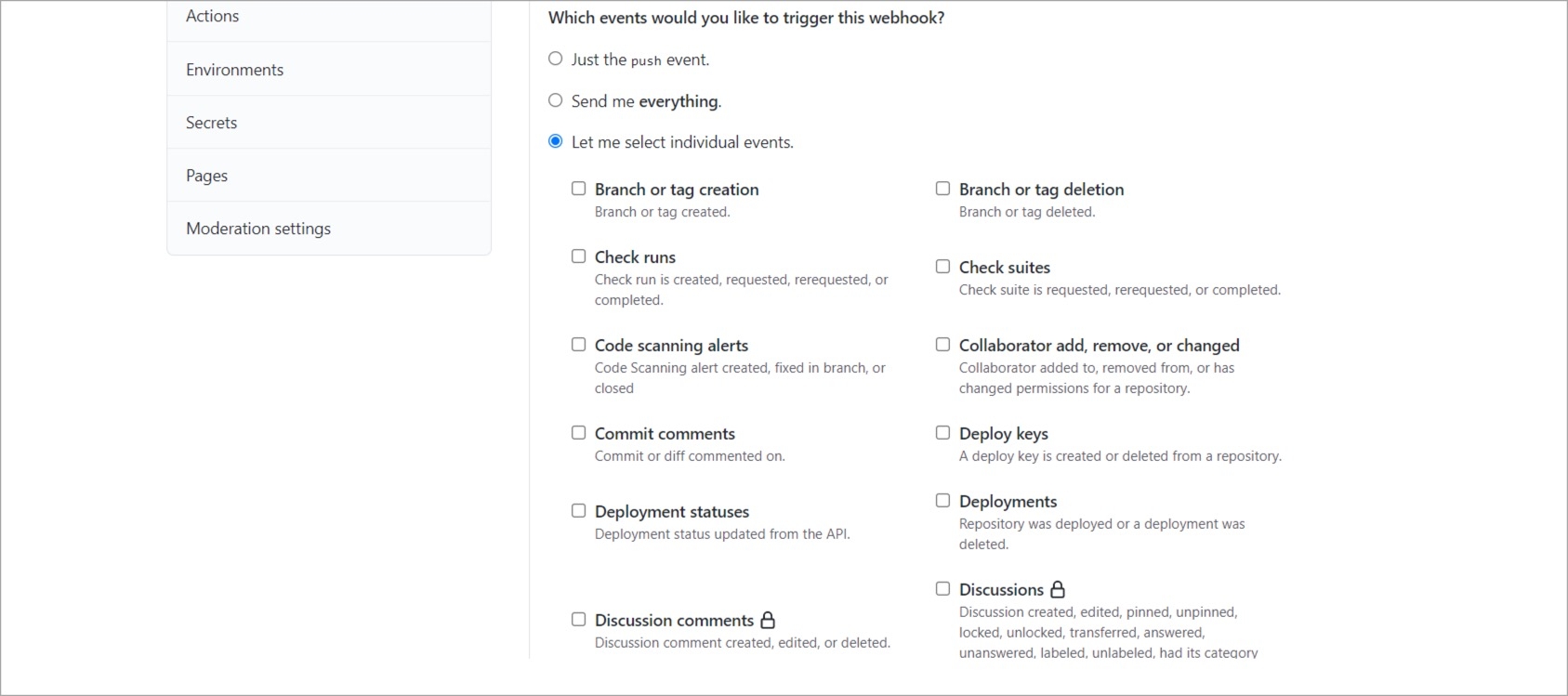
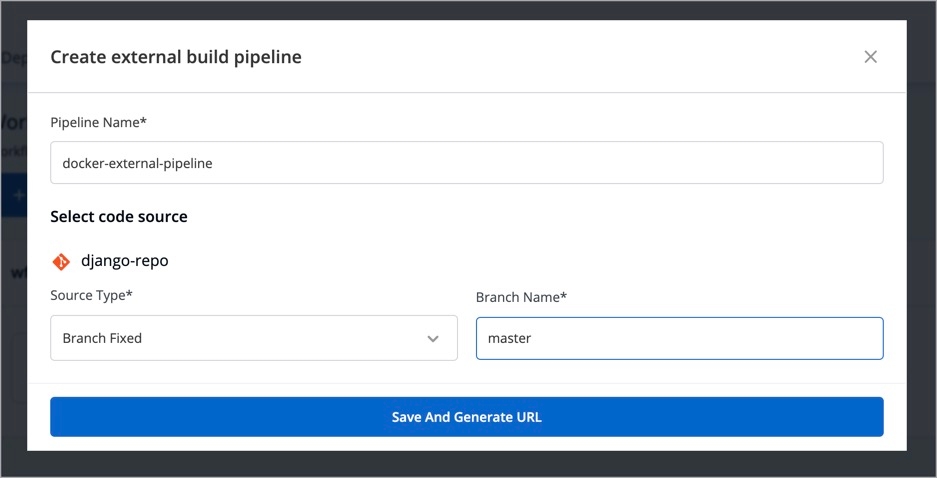
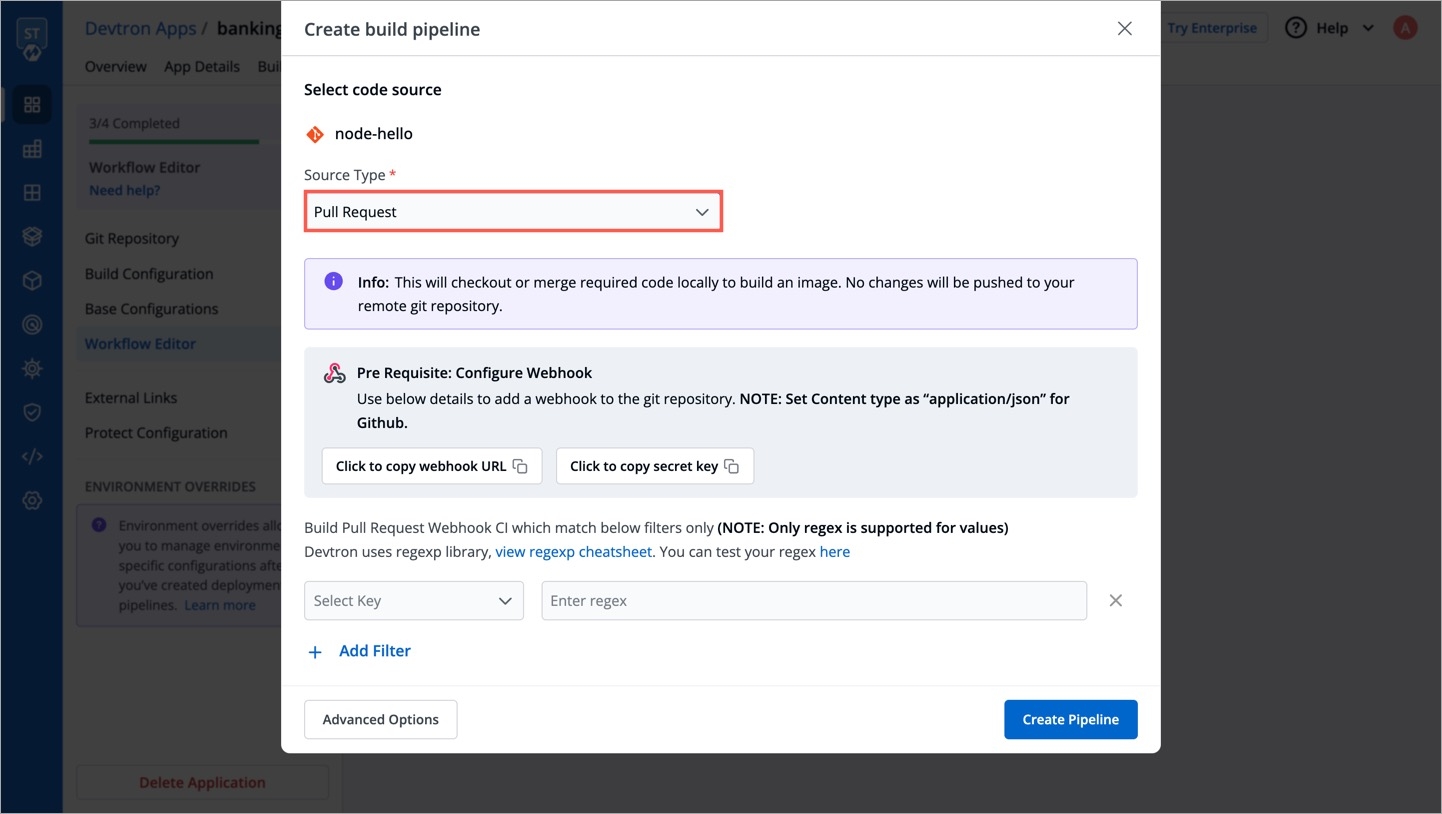
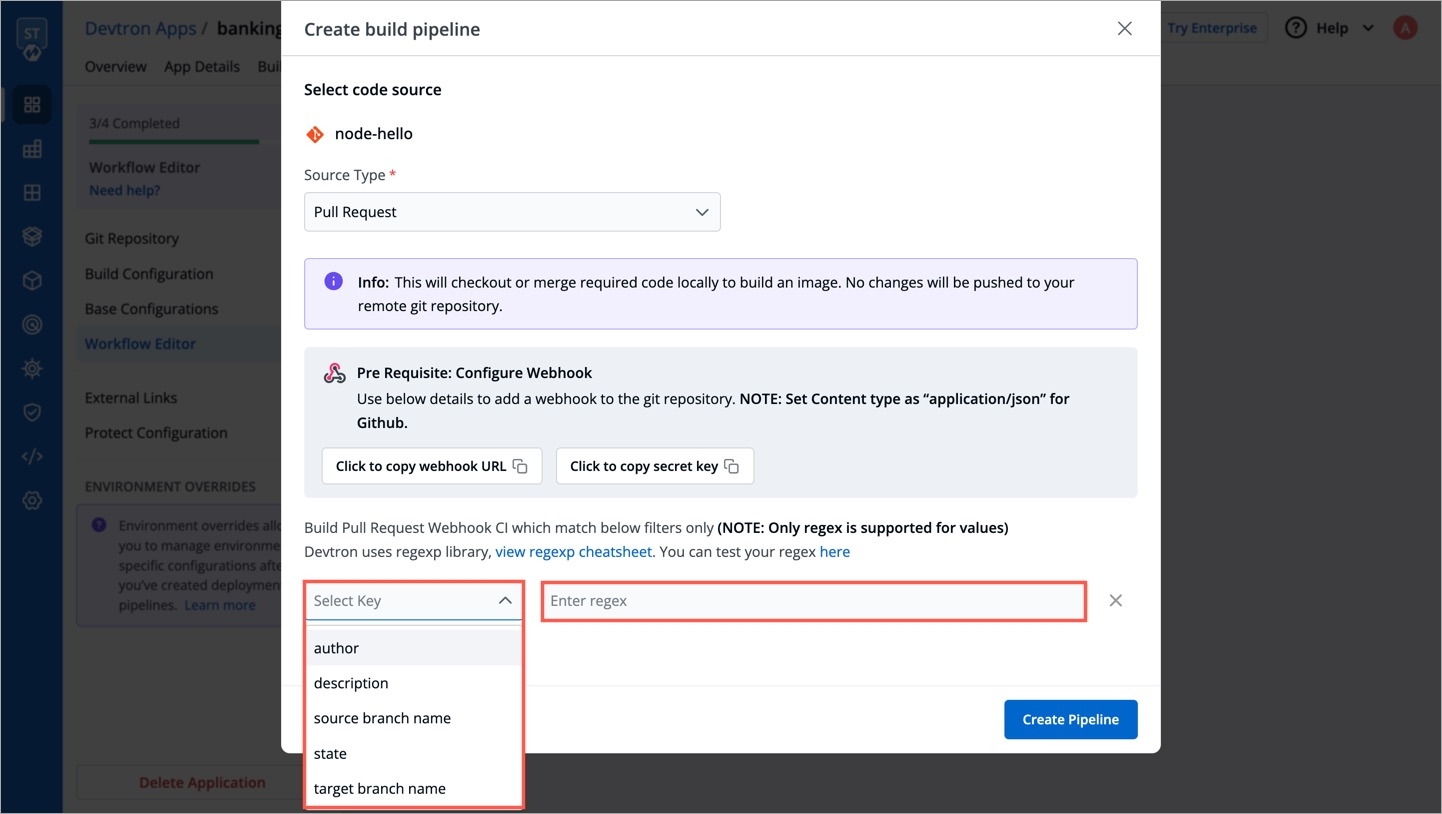
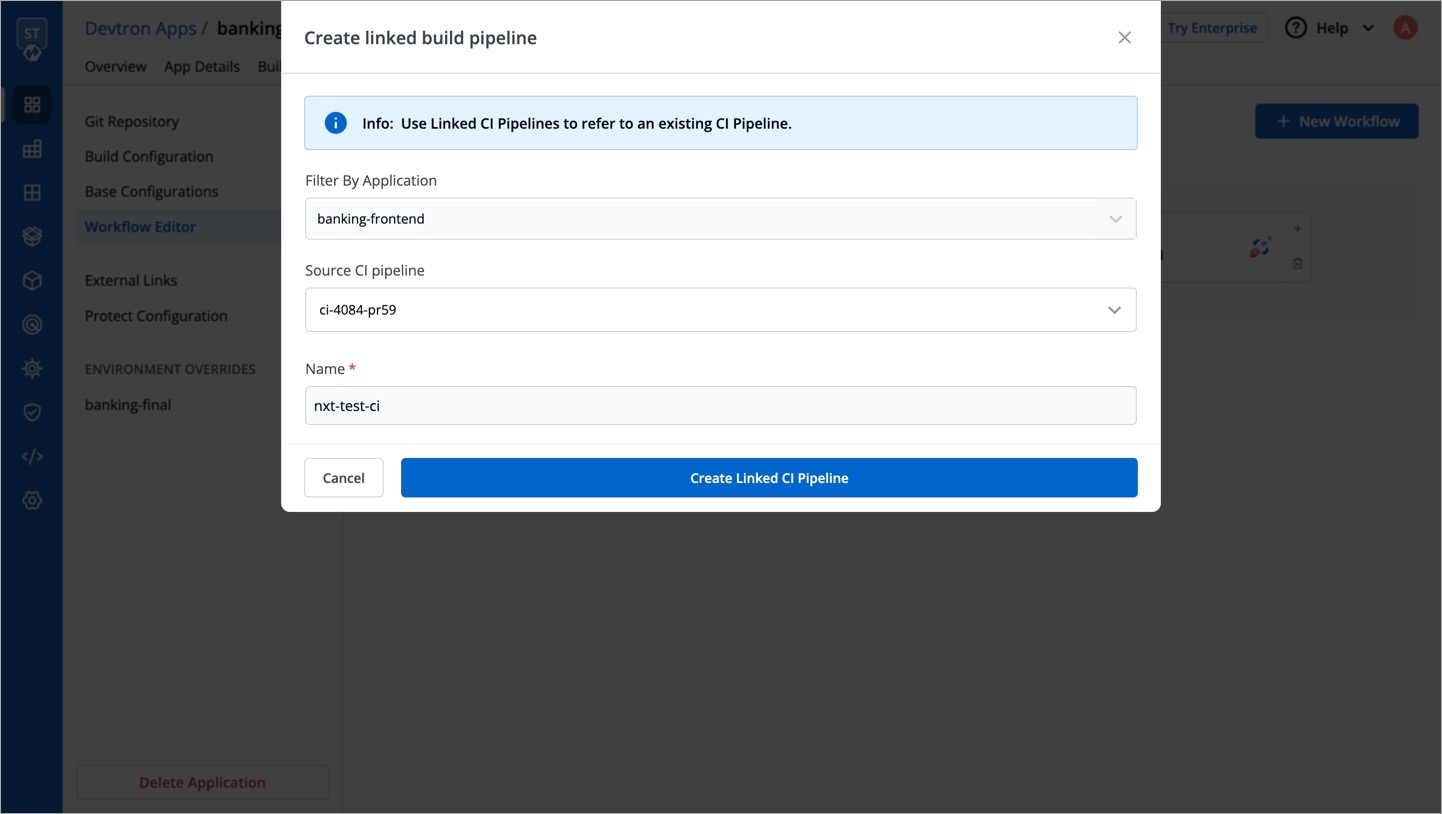
For Helm installation this section refers to secrets section of values.yaml.
Configure the following properties:
POSTGRESQL_PASSWORD
Using this parameter the auto-generated password for Postgres can be edited as per requirement(Used by Devtron to store the app information)
NA
WEBHOOK_TOKEN
If you want to continue using Jenkins for CI then provide this for authentication of requests should be base64 encoded
NA
For Helm installation this section refers to configs section of values.yaml.
Configure the following properties:
BASE_URL_SCHEME
Either of HTTP or HTTPS (required)
HTTP
BASE_URL
URL without scheme and trailing slash, this is the domain pointing to the cluster on which the Devtron platform is being installed. For example, if you have directed domain devtron.example.com to the cluster and the ingress controller is listening on port 32080 then URL will be devtron.example.com:32080 (required)
change-me
DEX_CONFIG
dex config if you want to integrate login with SSO (optional) for more information check
NA
EXTERNAL_SECRET_AMAZON_REGION
AWS region for the secret manager to pick (required)
NA
PROMETHEUS_URL
URL of Prometheus where all cluster data is stored; if this is wrong, you will not be able to see application metrics like CPU, RAM, HTTP status code, latency, and throughput (required)
NA
Devtron provides ways to control how much memory or CPU can be allocated to each Devtron microservice. You can adjust the resources that are allocated to these microservices based on your requirements. The resource configurations are available in following sizes:
Small: To configure the small resources (e.g. to manage less than 10 apps on Devtron ) based on the requirements, append the Devtron installation command with -f https://raw.githubusercontent.com/devtron-labs/devtron/main/charts/devtron/resources-small.yaml.
For Helm installation this section refers to customOverrides section of values.yaml. In this section you can override values of devtron-cm which you want to keep persistent. For example:
You can configure the following properties:
CI_NODE_LABEL_SELECTOR
Labels for a particular nodegroup which you want to use for running CIs
NA
CI_NODE_TAINTS_KEY
Key for toleration if nodegroup chosen for CIs have some taints
NA
CI_NODE_TAINTS_VALUE
Value for toleration if nodegroup chosen for CIs have some taints
NA
AWS SPECIFICWhile installing Devtron and using the AWS-S3 bucket for storing the logs and caches, the below parameters are to be used in the ConfigMap.
NOTE: For using the S3 bucket it is important to add the S3 permission policy to the IAM role attached to the nodes of the cluster.
DEFAULT_CACHE_BUCKET
AWS bucket to store docker cache, it should be created beforehand (required)
DEFAULT_BUILD_LOGS_BUCKET
AWS bucket to store build logs, it should be created beforehand (required)
DEFAULT_CACHE_BUCKET_REGION
AWS region of S3 bucket to store cache (required)
DEFAULT_CD_LOGS_BUCKET_REGION
AWS region of S3 bucket to store CD logs (required)
BLOB_STORAGE_S3_ENDPOINT
S3 compatible bucket endpoint.
The below parameters are to be used in the Secrets :
BLOB_STORAGE_S3_ACCESS_KEY
AWS access key to access S3 bucket. Required if installing using AWS credentials.
BLOB_STORAGE_S3_SECRET_KEY
AWS secret key to access S3 bucket. Required if installing using AWS credentials.
AZURE SPECIFICWhile installing Devtron using Azure Blob Storage for storing logs and caches, the below parameters will be used in the ConfigMap.
AZURE_ACCOUNT_NAME
Account name for AZURE Blob Storage
AZURE_BLOB_CONTAINER_CI_LOG
AZURE Blob storage container for storing ci-logs after running the CI pipeline
AZURE_BLOB_CONTAINER_CI_CACHE
AZURE Blob storage container for storing ci-cache after running the CI pipeline
GOOGLE CLOUD STORAGE SPECIFICWhile installing Devtron using Google Cloud Storage for storing logs and caches, the below parameters will be used in the ConfigMap.
BLOB_STORAGE_GCP_CREDENTIALS_JSON
Base-64 encoded GCP credentials json for accessing Google Cloud Storage
DEFAULT_CACHE_BUCKET
Google Cloud Storage bucket for storing ci-logs after running the CI pipeline
DEFAULT_LOGS_BUCKET
Google Cloud Storage bucket for storing ci-cache after running the CI pipeline
To convert string to base64 use the following command:
echo -n "string" | base64Note:
Ensure that the cluster has read and write access to the S3 buckets/Azure Blob storage container mentioned in DEFAULT_CACHE_BUCKET, DEFAULT_BUILD_LOGS_BUCKET or AZURE_BLOB_CONTAINER_CI_LOG, or AZURE_BLOB_CONTAINER_CI_CACHE.
Ensure that the cluster has read access to AWS secrets backends (SSM & secrets manager).
The following tables contain parameters and their details for Secrets and ConfigMaps that are configured during the installation of Devtron. If the installation is done using Helm, the values can be tweaked in values.yaml file.
We can use the --set flag to override the default values when installing with Helm. For example, to update POSTGRESQL_PASSWORD and BLOB_STORAGE_PROVIDER, use the install command as:
helm install devtron devtron/devtron-operator --create-namespace --namespace devtroncd \
--set secrets.POSTGRESQL_PASSWORD=change-me \
--set configs.BLOB_STORAGE_PROVIDER=S3Blob Storage allows users to store large amounts of unstructured data. Unstructured data is a data that does not adhere to a particular data model or definition, such as text or binary data. Configuring blob storage in your Devtron environment allows you to store build logs and cache.
In case, if you do not configure the Blob Storage, then:
You will not be able to access the build and deployment logs after an hour.
Build time for commit hash takes longer as cache is not available.
Artifact reports cannot be generated in pre/post build and deployment stages.
You can configure Blob Storage with one of the following Blob Storage providers given below:
Note: You can also use the respective following command to switch to another Blob Storage provider. As an example, If you are using MinIO Storage and want to switch to Azure Blob Storage, use the command provided on the Azure Blob Storage tab to switch.
Use the following command to configure MinIO for storing logs and cache.
Note: Unlike global cloud providers such as AWS S3 Bucket, Azure Blob Storage and Google Cloud Storage, MinIO can be hosted locally also.
helm repo update
helm upgrade devtron devtron/devtron-operator --namespace devtroncd \
--reuse-values \
--set installer.modules={cicd} \
--set minio.enabled=trueUse the following command to configure AWS S3 bucket for storing build logs and cache. Refer to the AWS specific parameters on the Storage for Logs and Cache page.
Configure using S3 IAM policy:
NOTE: Pleasee ensure that S3 permission policy to the IAM role attached to the nodes of the cluster if you are using the below command.
helm repo update
helm upgrade devtron devtron/devtron-operator --namespace devtroncd \
--reuse-values \
--set installer.modules={cicd} \
--set configs.BLOB_STORAGE_PROVIDER=S3 \
--set configs.DEFAULT_CACHE_BUCKET=demo-s3-bucket \
--set configs.DEFAULT_CACHE_BUCKET_REGION=us-east-1 \
--set configs.DEFAULT_BUILD_LOGS_BUCKET=demo-s3-bucket \
--set configs.DEFAULT_CD_LOGS_BUCKET_REGION=us-east-1Configure using access-key and secret-key for aws S3 authentication:
helm repo update
helm upgrade devtron devtron/devtron-operator --namespace devtroncd \
--reuse-values \
--set installer.modules={cicd} \
--set configs.BLOB_STORAGE_PROVIDER=S3 \
--set configs.DEFAULT_CACHE_BUCKET=demo-s3-bucket \
--set configs.DEFAULT_CACHE_BUCKET_REGION=us-east-1 \
--set configs.DEFAULT_BUILD_LOGS_BUCKET=demo-s3-bucket \
--set configs.DEFAULT_CD_LOGS_BUCKET_REGION=us-east-1 \
--set secrets.BLOB_STORAGE_S3_ACCESS_KEY=<access-key> \
--set secrets.BLOB_STORAGE_S3_SECRET_KEY=<secret-key>Configure using S3 compatible storages:
helm repo update
helm upgrade devtron devtron/devtron-operator --namespace devtroncd \
--reuse-values \
--set installer.modules={cicd} \
--set configs.BLOB_STORAGE_PROVIDER=S3 \
--set configs.DEFAULT_CACHE_BUCKET=demo-s3-bucket \
--set configs.DEFAULT_CACHE_BUCKET_REGION=us-east-1 \
--set configs.DEFAULT_BUILD_LOGS_BUCKET=demo-s3-bucket \
--set configs.DEFAULT_CD_LOGS_BUCKET_REGION=us-east-1 \
--set secrets.BLOB_STORAGE_S3_ACCESS_KEY=<access-key> \
--set secrets.BLOB_STORAGE_S3_SECRET_KEY=<secret-key> \
--set configs.BLOB_STORAGE_S3_ENDPOINT=<endpoint>Use the following command to configure Azure Blob Storage for storing build logs and cache. Refer to the Azure specific parameters on the Storage for Logs and Cache page.
helm repo update
helm upgrade devtron devtron/devtron-operator --namespace devtroncd \
--reuse-values \
--set installer.modules={cicd} \
--set secrets.AZURE_ACCOUNT_KEY=xxxxxxxxxx \
--set configs.BLOB_STORAGE_PROVIDER=AZURE \
--set configs.AZURE_ACCOUNT_NAME=test-account \
--set configs.AZURE_BLOB_CONTAINER_CI_LOG=ci-log-container \
--set configs.AZURE_BLOB_CONTAINER_CI_CACHE=ci-cache-containerUse the following command to configure Google Cloud Storage for storing build logs and cache. Refer to the Google Cloud specific parameters on the Storage for Logs and Cache page.
helm repo update
helm upgrade devtron devtron/devtron-operator --namespace devtroncd \
--reuse-values \
--set installer.modules={cicd} \
--set configs.BLOB_STORAGE_PROVIDER=GCP \
--set secrets.BLOB_STORAGE_GCP_CREDENTIALS_JSON=eyJ0eXBlIjogInNlcnZpY2VfYWNjb3VudCIsInByb2plY3RfaWQiOiAiPHlvdXItcHJvamVjdC1pZD4iLCJwcml2YXRlX2tleV9pZCI6ICI8eW91ci1wcml2YXRlLWtleS1pZD4iLCJwcml2YXRlX2tleSI6ICI8eW91ci1wcml2YXRlLWtleT4iLCJjbGllbnRfZW1haWwiOiAiPHlvdXItY2xpZW50LWVtYWlsPiIsImNsaWVudF9pZCI6ICI8eW91ci1jbGllbnQtaWQ+IiwiYXV0aF91cmkiOiAiaHR0cHM6Ly9hY2NvdW50cy5nb29nbGUuY29tL28vb2F1dGgyL2F1dGgiLCJ0b2tlbl91cmkiOiAiaHR0cHM6Ly9vYXV0aDIuZ29vZ2xlYXBpcy5jb20vdG9rZW4iLCJhdXRoX3Byb3ZpZGVyX3g1MDlfY2VydF91cmwiOiAiaHR0cHM6Ly93d3cuZ29vZ2xlYXBpcy5jb20vb2F1dGgyL3YxL2NlcnRzIiwiY2xpZW50X3g1MDlfY2VydF91cmwiOiAiPHlvdXItY2xpZW50LWNlcnQtdXJsPiJ9Cg== \
--set configs.DEFAULT_CACHE_BUCKET=cache-bucket \
--set configs.DEFAULT_BUILD_LOGS_BUCKET=log-bucketACD_PASSWORD
ArgoCD Password for CD Workflow
Auto-Generated
Optional
AZURE_ACCOUNT_KEY
Account key to access Azure objects such as BLOB_CONTAINER_CI_LOG or CI_CACHE
""
Mandatory (If using Azure)
GRAFANA_PASSWORD
Password for Grafana to display graphs
Auto-Generated
Optional
POSTGRESQL_PASSWORD
Password for your Postgresql database that will be used to access the database
Auto-Generated
Optional
AZURE_ACCOUNT_NAME
Azure account name which you will use
""
Mandatory (If using Azure)
AZURE_BLOB_CONTAINER_CI_LOG
Name of container created for storing CI_LOG
ci-log-container
Optional
AZURE_BLOB_CONTAINER_CI_CACHE
Name of container created for storing CI_CACHE
ci-cache-container
Optional
BLOB_STORAGE_PROVIDER
Cloud provider name which you will use
MINIO
Mandatory (If using any cloud other than MINIO), MINIO/AZURE/S3
DEFAULT_BUILD_LOGS_BUCKET
S3 Bucket name used for storing Build Logs
devtron-ci-log
Mandatory (If using AWS)
DEFAULT_CD_LOGS_BUCKET_REGION
Region of S3 Bucket where CD Logs are being stored
us-east-1
Mandatory (If using AWS)
DEFAULT_CACHE_BUCKET
S3 Bucket name used for storing CACHE (Do not include s3://)
devtron-ci-cache
Mandatory (If using AWS)
DEFAULT_CACHE_BUCKET_REGION
S3 Bucket region where Cache is being stored
us-east-1
Mandatory (If using AWS)
EXTERNAL_SECRET_AMAZON_REGION
Region where the cluster is setup for Devtron installation
""
Mandatory (If using AWS)
ENABLE_INGRESS
To enable Ingress (True/False)
False
Optional
INGRESS_ANNOTATIONS
Annotations for ingress
""
Optional
PROMETHEUS_URL
Existing Prometheus URL if it is installed
""
Optional
CI_NODE_LABEL_SELECTOR
Label of CI worker node
""
Optional
CI_NODE_TAINTS_KEY
Taint key name of CI worker node
""
Optional
CI_NODE_TAINTS_VALUE
Value of taint key of CI node
""
Optional
CI_DEFAULT_ADDRESS_POOL_BASE_CIDR
CIDR ranges used to allocate subnets in each IP address pool for CI
""
Optional
CI_DEFAULT_ADDRESS_POOL_SIZE
The subnet size to allocate from the base pool for CI
""
Optional
CD_NODE_LABEL_SELECTOR
Label of CD node
kubernetes.io/os=linux
Optional
CD_NODE_TAINTS_KEY
Taint key name of CD node
dedicated
Optional
CD_NODE_TAINTS_VALUE
Value of taint key of CD node
ci
Optional
CD_LIMIT_CI_CPU
CPU limit for pre and post CD Pod
0.5
Optional
CD_LIMIT_CI_MEM
Memory limit for pre and post CD Pod
3G
Optional
CD_REQ_CI_CPU
CPU request for CI Pod
0.5
Optional
CD_REQ_CI_MEM
Memory request for CI Pod
1G
Optional
CD_DEFAULT_ADDRESS_POOL_BASE_CIDR
CIDR ranges used to allocate subnets in each IP address pool for CD
""
Optional
CD_DEFAULT_ADDRESS_POOL_SIZE
The subnet size to allocate from the base pool for CD
""
Optional
GITOPS_REPO_PREFIX
Prefix for Gitops repository
devtron
Optional
RECOMMEND_SECURITY_SCANNING=false
FORCE_SECURITY_SCANNING=false
HIDE_DISCORD=falseRECOMMEND_SECURITY_SCANNING
If True, security scanning is enabled by default for a new build pipeline. Users can however turn it off in the new or existing pipelines.
FORCE_SECURITY_SCANNING
If set to True, security scanning is forcefully enabled by default for a new build pipeline. Users can not turn it off for new as well as for existing build pipelines. Old pipelines that have security scanning disabled will remain unchanged and image scanning should be enabled manually for them.
HIDE_DISCORD
Hides discord chatbot from the dashboard.
A CI Workflow can be created in one of the following ways:
Sync with Environment
Create a Job
Each method has different use-cases that can be tailored according the needs of the organization.
Build and Deploy from Source Code workflow allows you to build the container image from a source code repository.
From the Applications menu, select your application.
On the App Configuration page, select Workflow Editor.
Select + New Workflow.
Select Build and Deploy from Source Code.
Enter the following fields on the Create build pipeline window:
The Advanced CI Pipeline includes the following stages:
Pre-build stage: The tasks in this stage are executed before the image is built.
Build stage: In this stage, the build is triggered from the source code that you provide.
Post-build stage: The tasks in this stage will be triggered once the build is complete.
The Pre-build and Post-build stages allow you to create Pre/Post-Build CI tasks as explained .
Go to the Build stage tab.
Source type
Branch Fixed
This allows you to trigger a CI build whenever there is a code change on the specified branch.
Enter the Branch Name of your code repository.
Branch Regex
Branch Regex allows users to easily switch between branches matching the configured Regex before triggering the build pipeline. In case of Branch Fixed, users cannot change the branch name in ci-pipeline unless they have admin access for the app. So, if users with Build and Deploy access should be allowed to switch branch name before triggering ci-pipeline, Branch Regex should be selected as source type by a user with Admin access.
For example if the user sets the Branch Regex as feature-*, then users can trigger from branches such as feature-1450, feature-hot-fix etc.
Pull Request
This allows you to trigger the CI build when a pull request is created in your repository.
The Pull Request source type feature only works for the host GitHub or Bitbucket Cloud for now. To request support for a different Git host, please create a GitHub issue .
To trigger the build from specific PRs, you can filter the PRs based on the following keys:
Select the appropriate filter and pass the matching condition as a regular expression (regex).
Devtron uses regexp library, view . You can test your custom regex from .
Select Create Pipeline.
Tag Creation
This allows you to trigger the CI build whenever a new tag is created.
To trigger the build from specific tags, you can filter the tags based on the author and/or the tag name.
Select the appropriate filter and pass the matching condition as a regular expression (regex).
Select Create Pipeline.
Scan for Vulnerabilities
To perform the security scan after the container image is built, enable the Scan for vulnerabilities toggle in the build stage. Refer to know more.
Custom Image Tag Pattern
This feature helps you apply custom tags (e.g., v1.0.0) to readily distinguish container images within your repository.
Enable the toggle button as shown below.
You can write an alphanumeric pattern for your image tag, e.g., test-v1.0.{x}. Here, 'x' is a mandatory variable whose value will incrementally increase with every build. You can also define the value of 'x' for the next build trigger in case you want to change it.
Click Update Pipeline.
Now, go to Build & Deploy tab of your application, and click Select Material in the CI pipeline.
Choose the git commit you wish to use for building the container image. Click Start Build.
The build will initiate and once it is successful the image tag would reflect at all relevant screens:
Build History
Docker Registry
CD Pipeline (Image Selection)
If one code is shared across multiple applications, Linked Build Pipeline can be used, and only one image will be built for multiple applications because if there is only one build, it is not advisable to create multiple CI Pipelines.
From the Applications menu, select your application.
On the App Configuration page, select Workflow Editor.
Select + New Workflow.
Select Linked Build Pipeline.
On the Create linked build pipeline screen:
Search for the application in which the source CI pipeline is present.
Select the source CI pipeline from the application that you selected above.
Enter a new name for the linked CI pipeline.
Click Create Linked CI Pipeline.
Thereafter, the source CI pipeline will indicate the number of Linked CI pipelines. Upon clicking it, it will display the child information as shown below. It reveals the applications and environments where Linked CI is used for deployment.
After creating a linked CI pipeline, you can create a CD pipeline.
Linked CI pipelines can't trigger builds. They rely on the source CI pipeline to build images. Trigger a build in the source CI pipeline to see the images available for deployment in the linked CI pipeline's CD stage.
For CI pipeline, you can receive container images from an external services via webhook API.
You can use Devtron for deployments on Kubernetes while using an external CI tool such as Jenkins or CircleCI. External CI feature can be used when the CI tool is hosted outside the Devtron platform. However, by using an external CI, you will not be able to use some of the Devtron features such as Image scanning and security policies, configuring pre-post CI stages etc.
Create a or an application.
To configure Git Repository, you can add any Git repository account (e.g., dummy account) and click Next.
To configure the Container Registry and Container Repository, you can leave the fields blank or simply add any test repository and click Save & Next.
On the Base Deployment Template page, select the Chart type from the drop-down list and configure as per your and click Save & Next.
On the Workflow Editor page, click New Workflow and select Deploy image from external service.
On the Deploy image from external source page, provide the information in the following fields:
Click Create Pipeline. A new CI pipeline will be created for the external source. To get the webhook URL and JSON sample payload to be used in external CI pipeline, click Show webhook details.
On the Webhook Details page, you have to authenticate via API token to allow requests from an external service (e.g. Jenkins or CircleCI).
For authentication, only users with super-admin permissions can select or generate an API token:
You can either use Select API Token if you have generated an under Global Configurations.
Or use Auto-generate token to generate the API token with the required permissions. Make sure to enter the token name in the Token name field.
To allow requests from the external source, you can request the API by using:
Webhook URL
cURL Request
HTTP Method: POST
API Endpoint: https://{domain-name}/orchestrator/webhook/ext-ci/{pipeline-id}
JSON Payload:
You can also select metadata to send to Devtron. Sample JSON will be generated accordingly. You can send the Payload script to your CI tools such as Jenkins and Devtron will receive the build image every time the CI pipeline is triggered or you can use the Webhook URL, which will build an image every time CI pipeline is triggered using Devtron Dashboard.
On the Jenkins dashboard, select the Jenkins job which you want to integrate with the Devtron dashboard.
Go to the Configuration > Build Steps, click Add build step, and then click Execute Shell.
Enter the cURL request command.
Make sure to enter the API token and dockerImage in your cURL command and click Save.
Now, you can access the images on the Devtron dashboard and deploy manually. In case, if you select Automatic deployment option, then your application will be deployed automatically everytime a new image is received.
Similarly, you can also integrate with external source such as CircleCI by:
Select the job on the CircleCI dashboard and click Configuration File.
On the respective job, enter the cURL command and update the API token and dockerImage in your cURL command.
You can update the configurations of an existing CI Pipeline except for the pipeline's name. To update a pipeline, select your CI pipeline. In the Edit build pipeline window, edit the required stages and select Update Pipeline.
You can only delete a CI pipeline if there is no CD pipeline created in your workflow.
To delete a CI pipeline, go to App Configurations > Workflow Editor and select Delete Pipeline.
Go to the Settings page of your repository and select Webhooks.
Select Add webhook.
In the Payload URL field, enter the Webhook URL that you get on selecting the source type as "Pull Request" or "Tag Creation" in Devtron the dashboard.
Change the Content-type to application/json.
In the Secret field, enter the secret from Devtron the dashboard when you select the source type as "Pull Request" or "Tag Creation".
Under Which events would you like to trigger this webhook?, select Let me select individual events. to trigger the webhook to build CI Pipeline.
Select Branch or tag creation and Pull Requests.
Select Add webhook.
Go to the Repository settings page of your Bitbucket repository.
Select Webhooks and then select Add webhook.
Enter a Title for the webhook.
In the URL field, enter the Webhook URL that you get on selecting the source type as "Pull Request" or "Tag Creation" in the Devtron dashboard.
Select the event triggers for which you want to trigger the webhook.
Select Save to save your configurations.
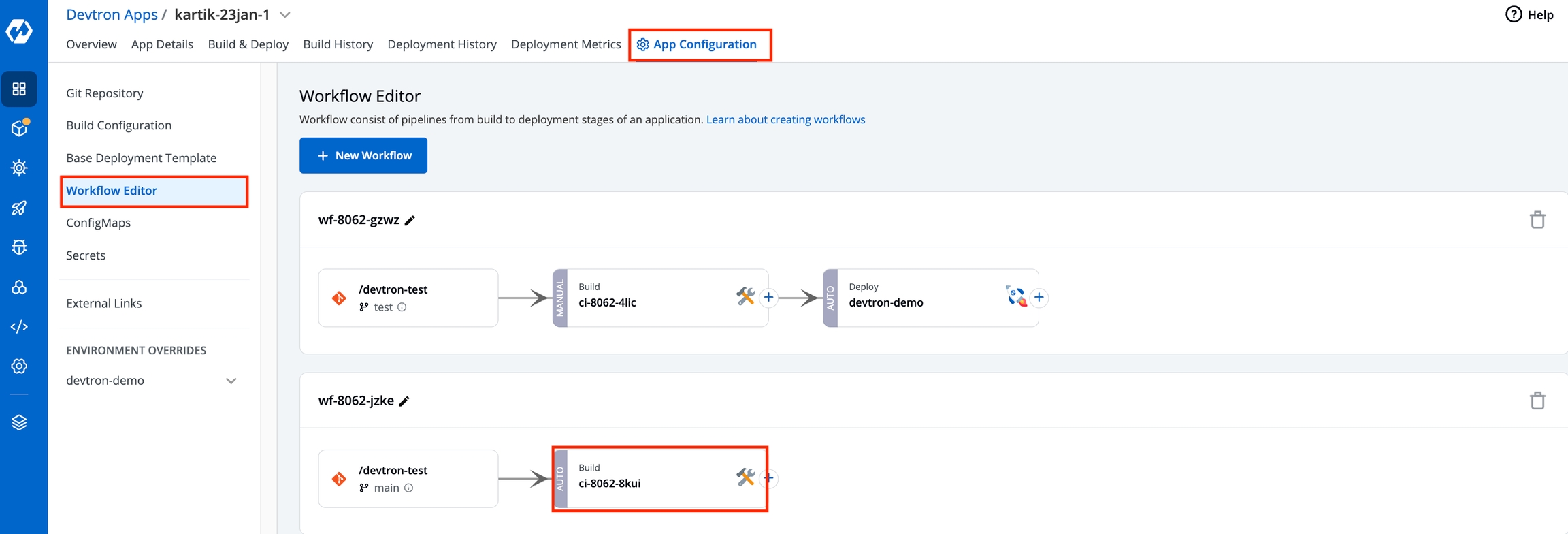

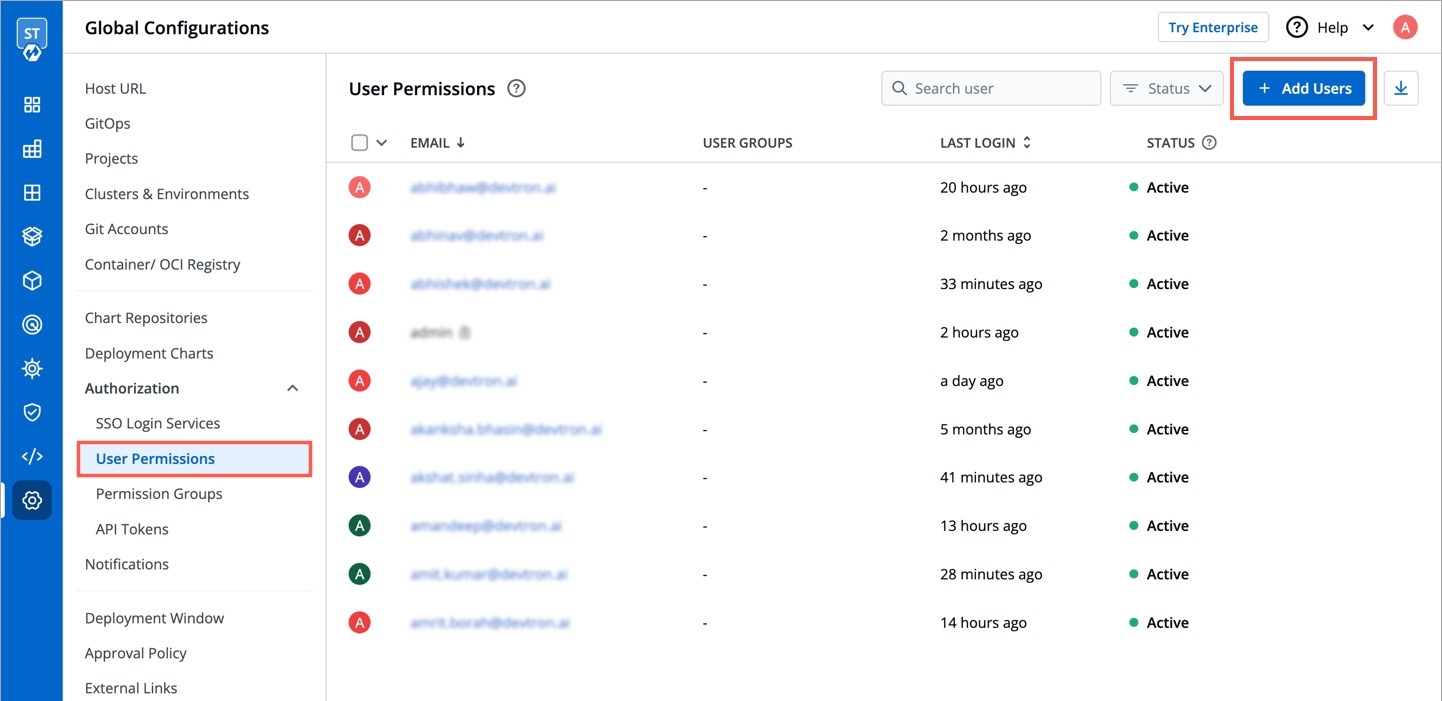
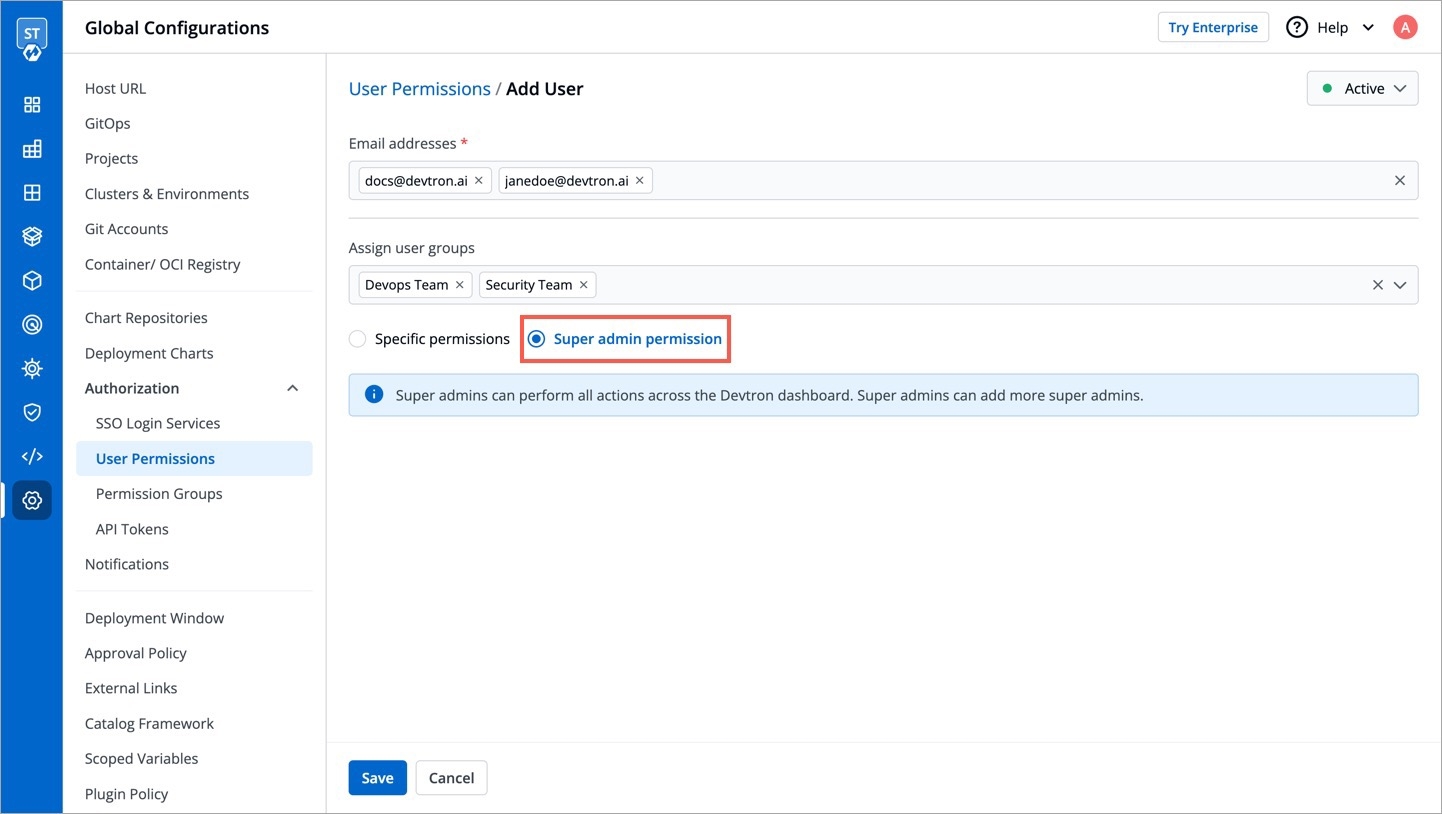
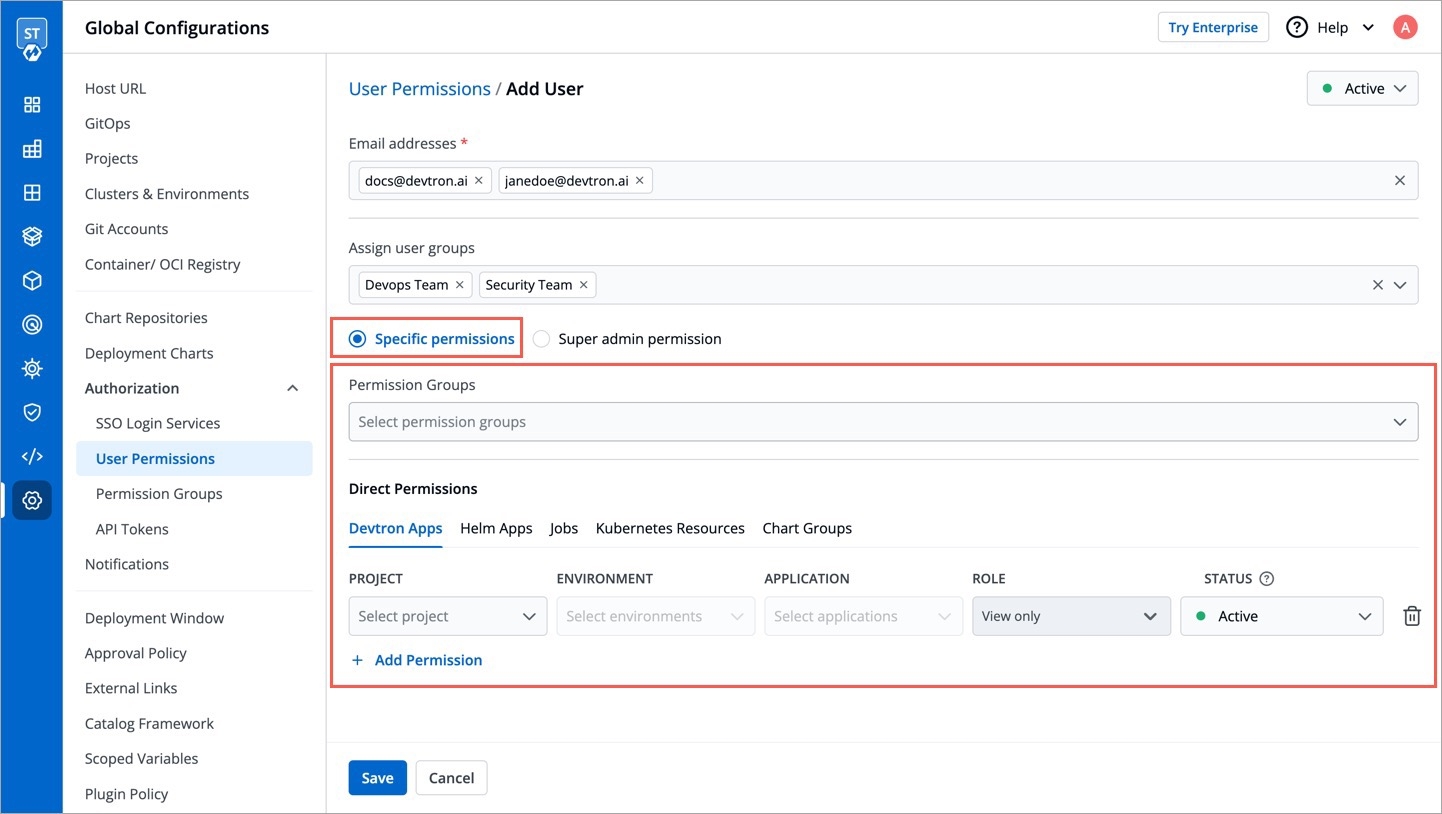
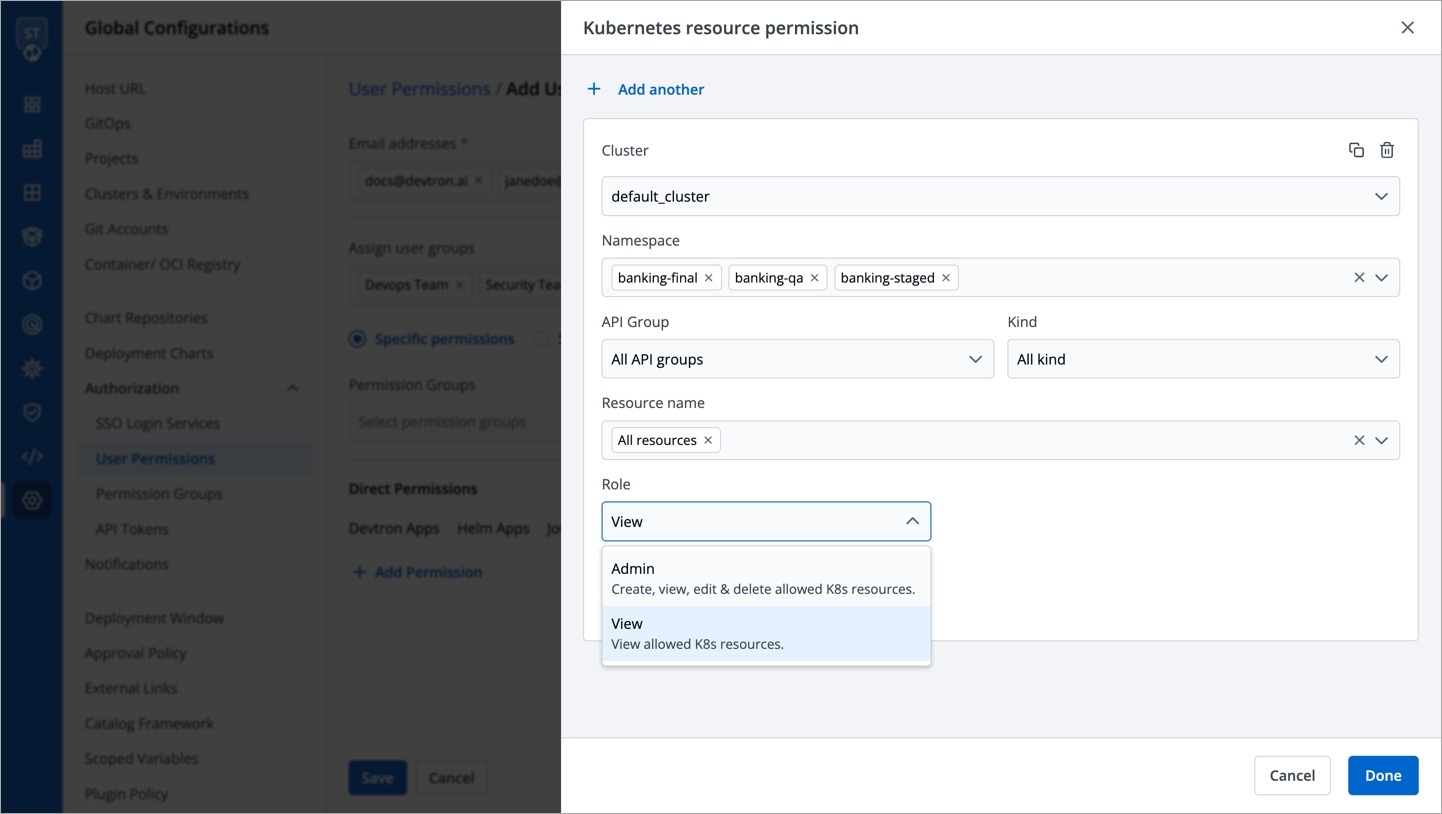
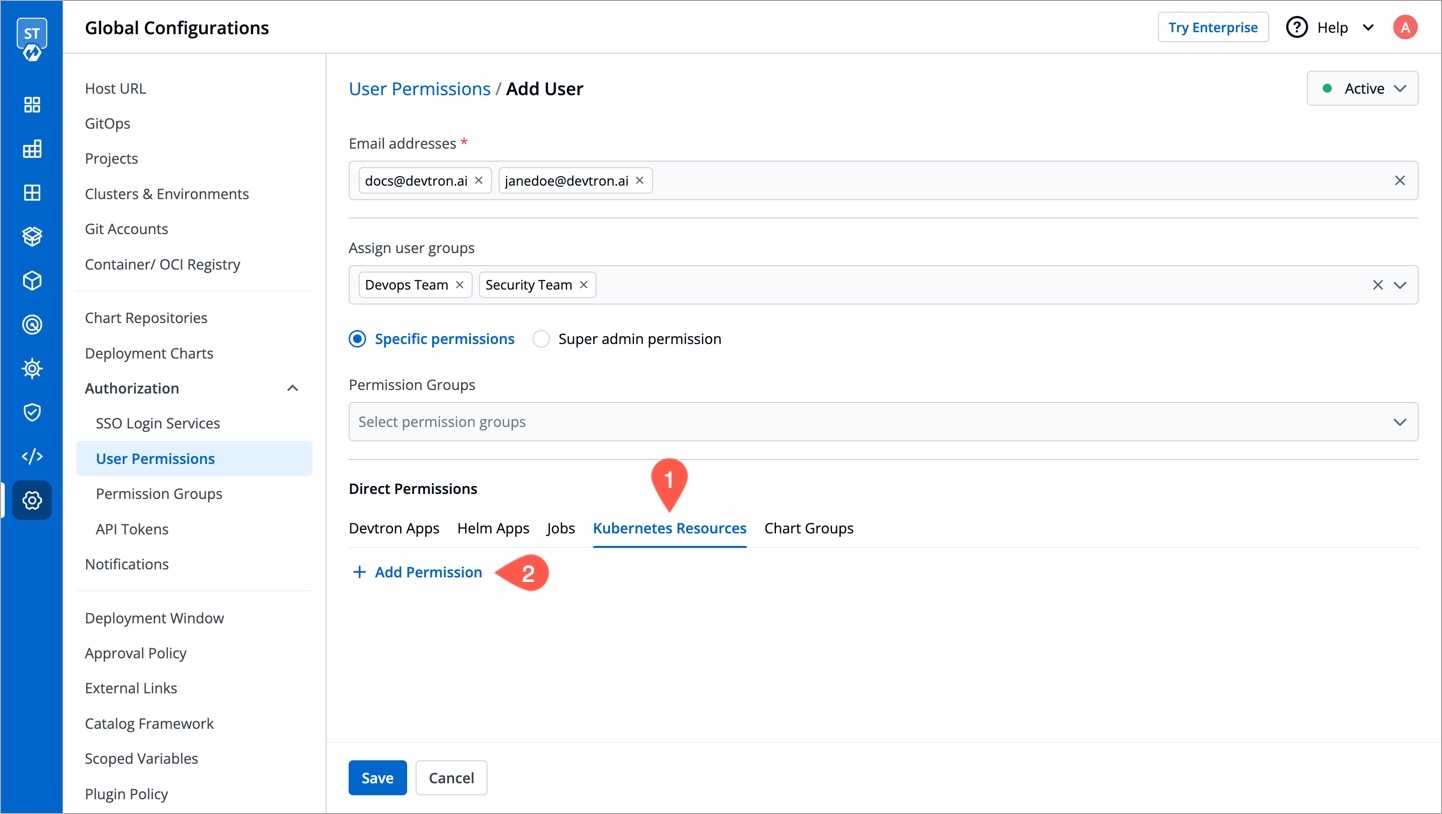
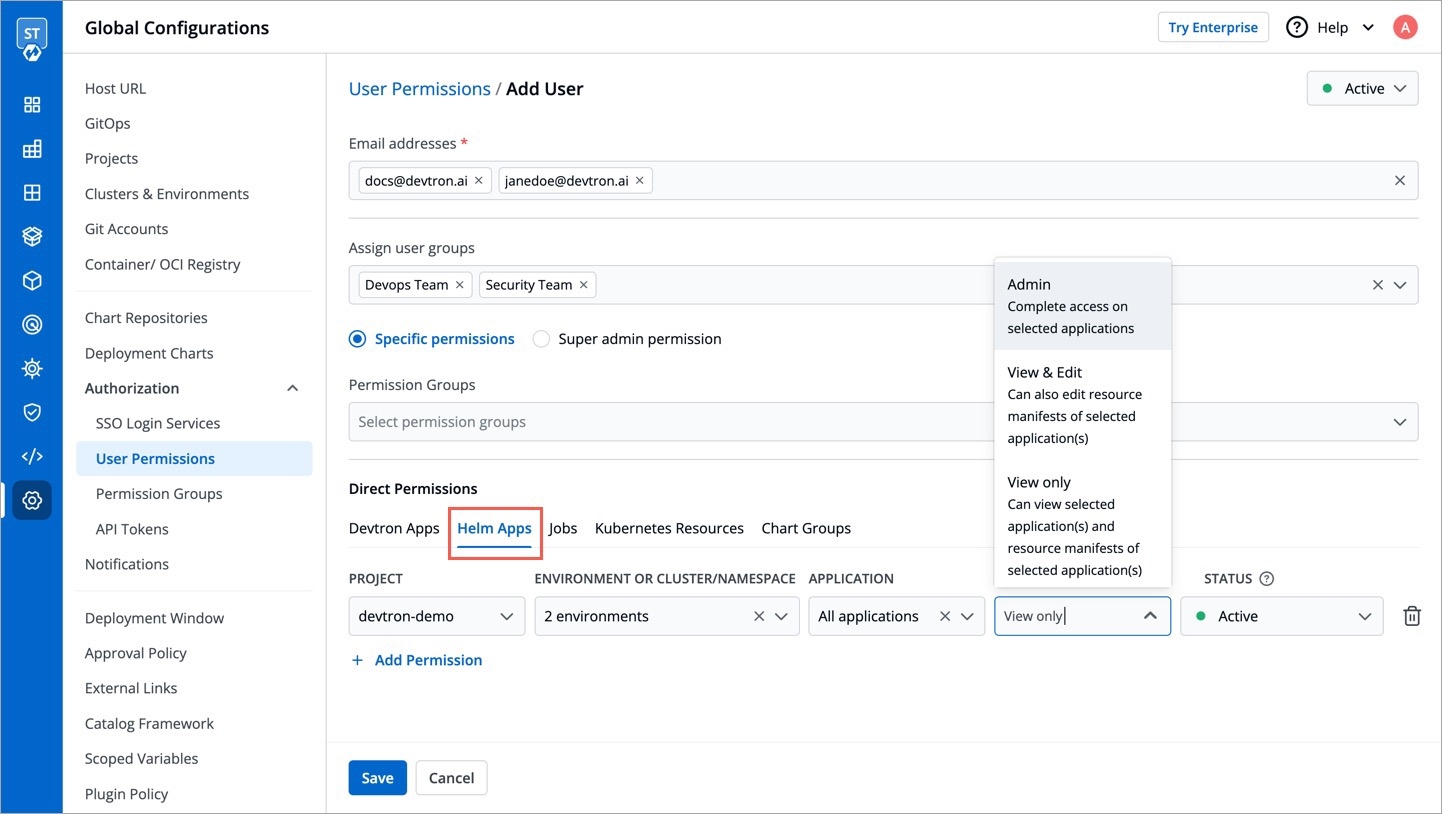
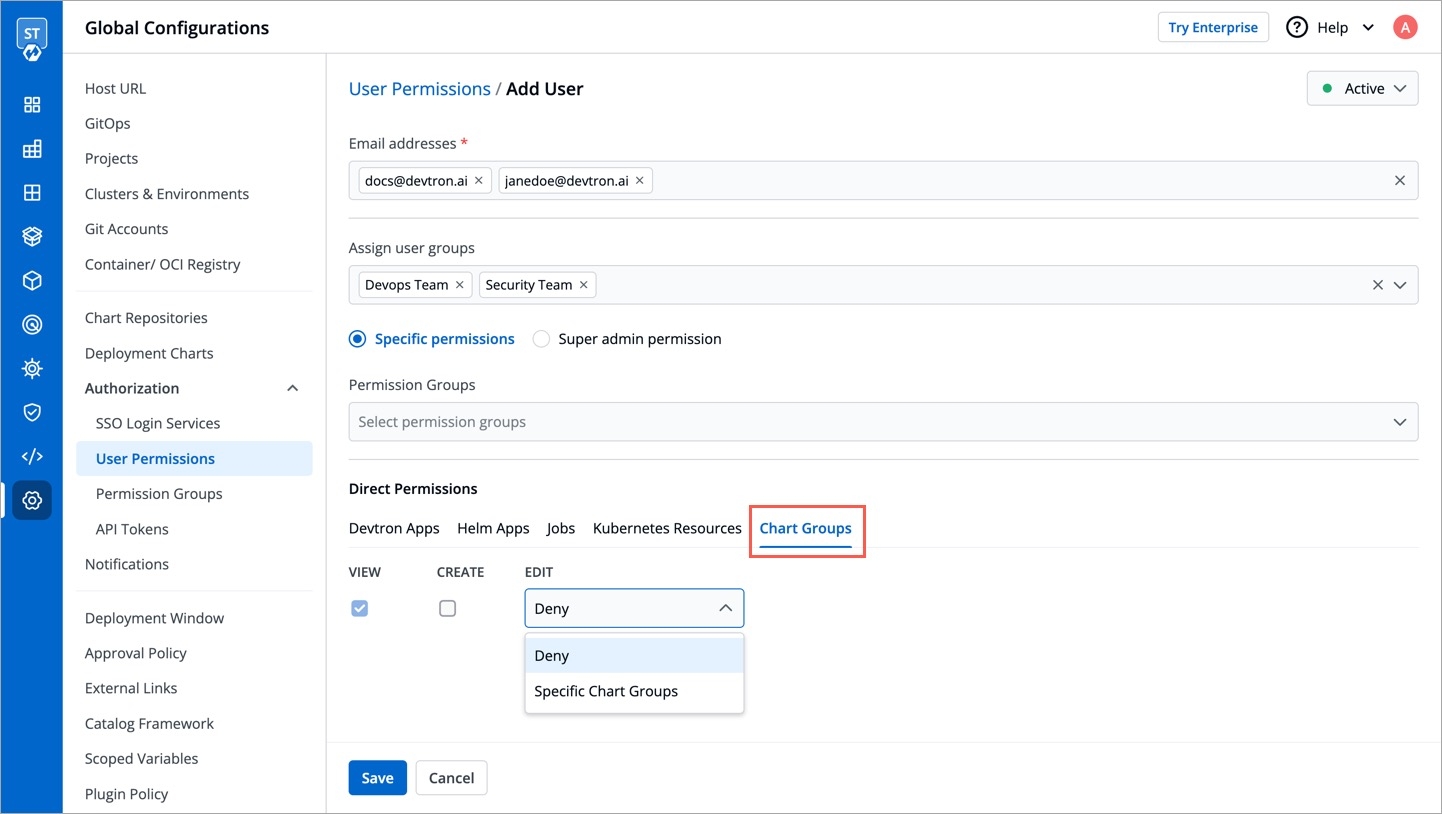
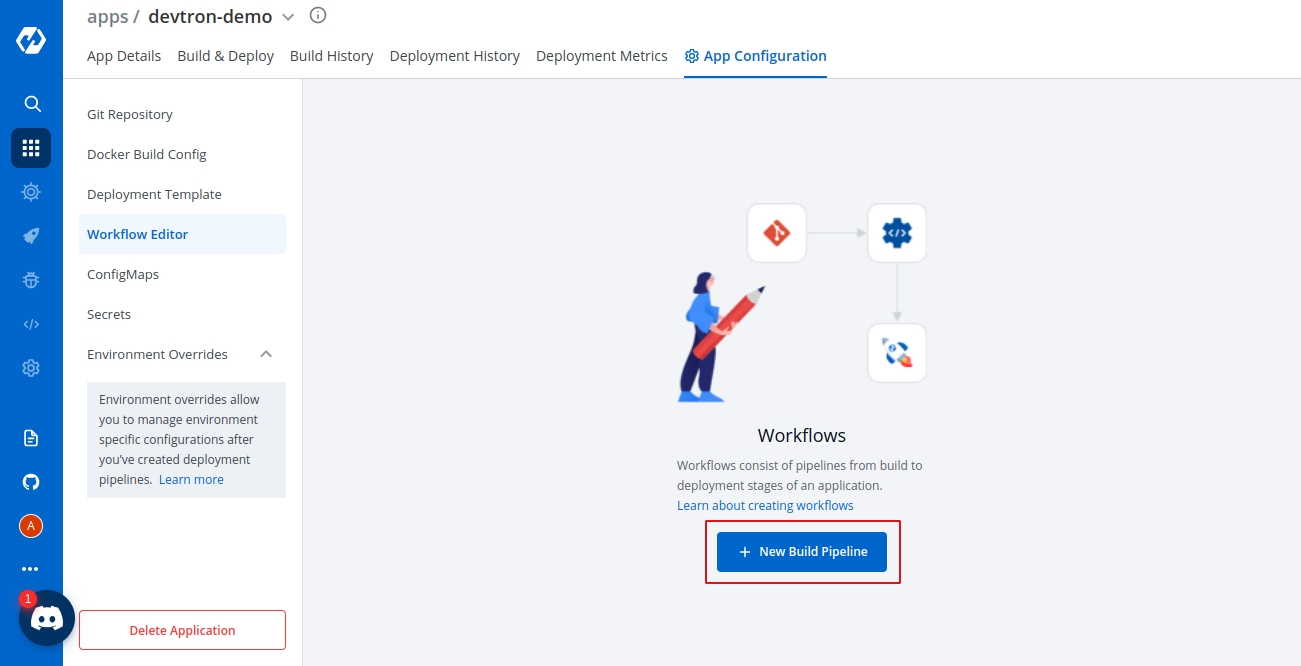
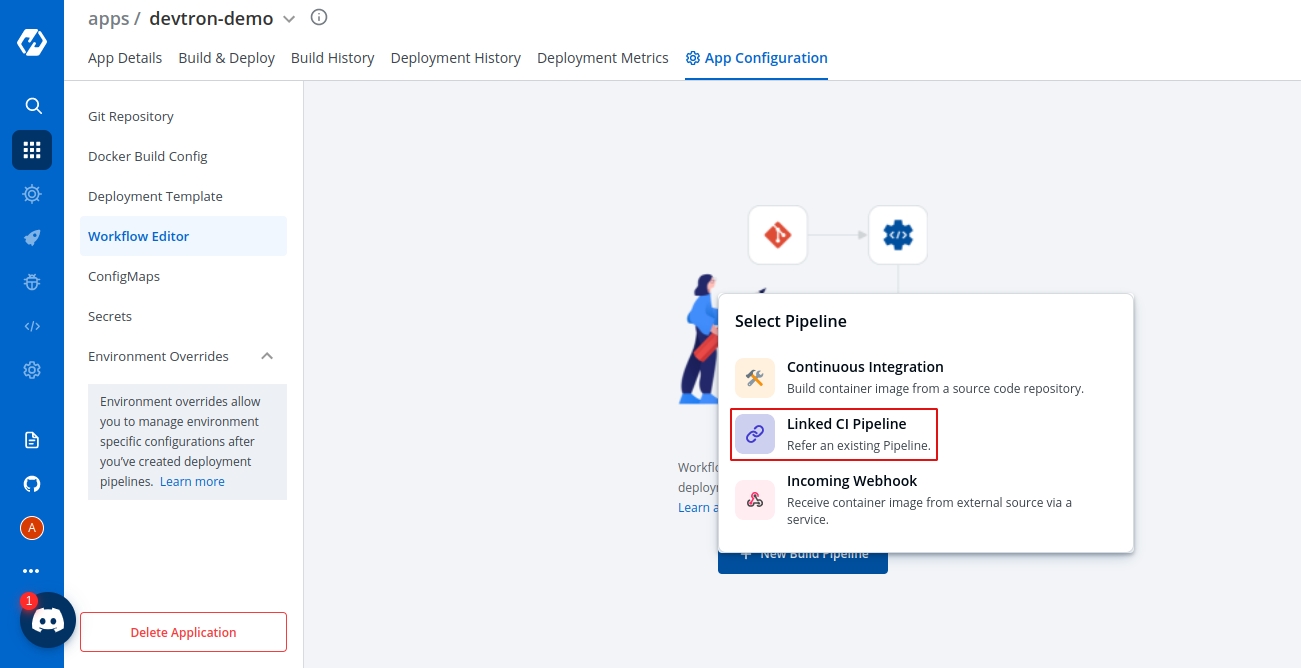
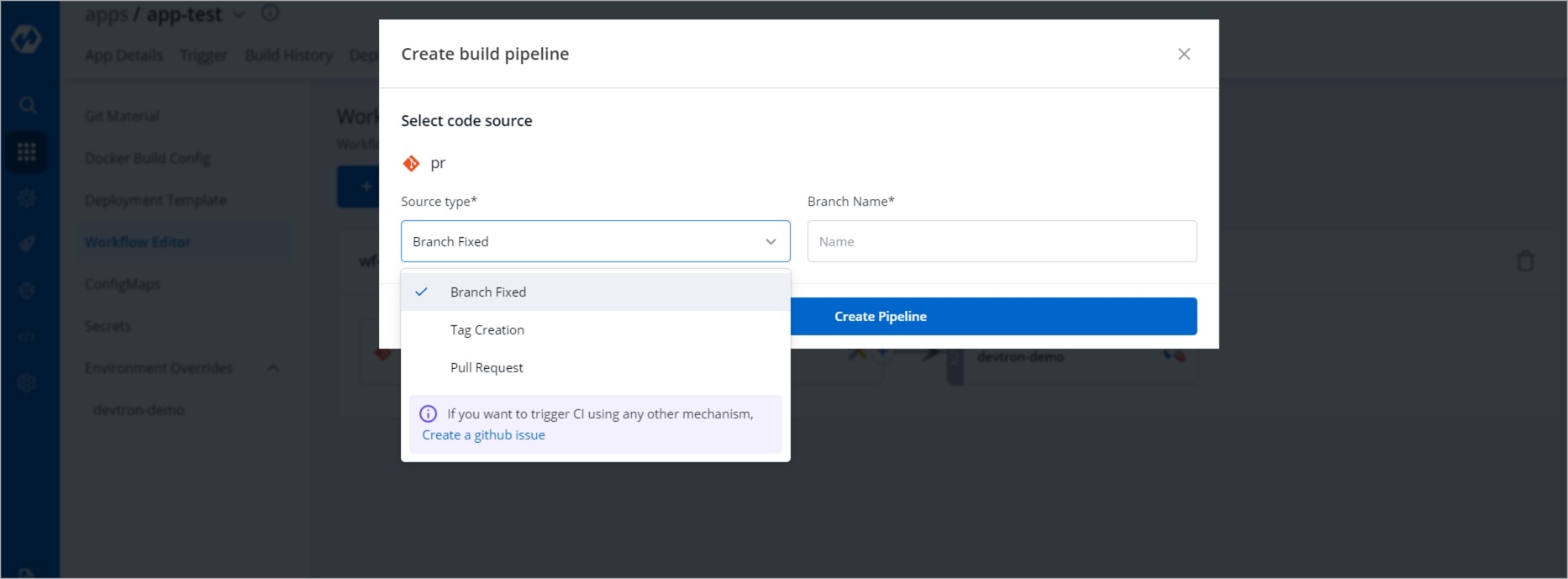
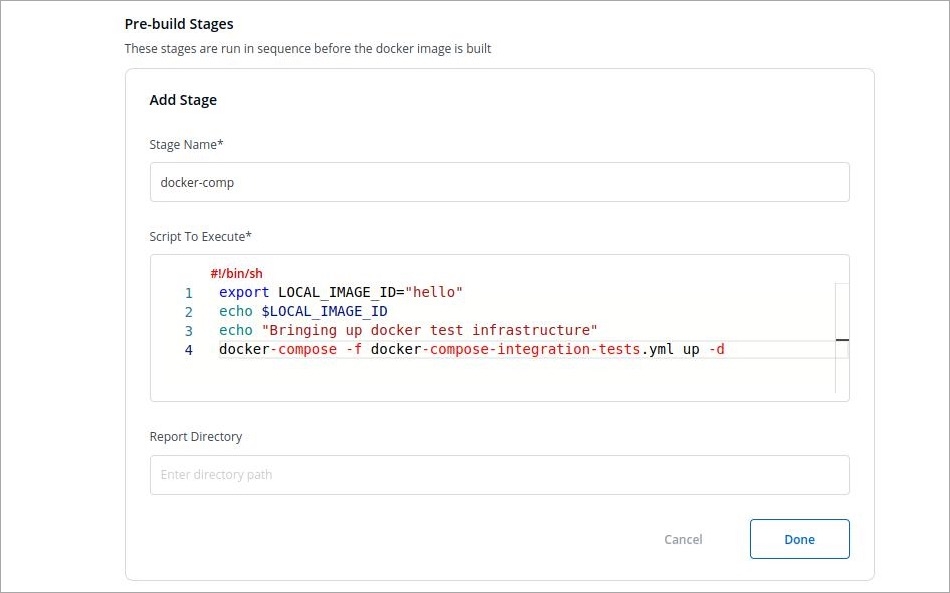
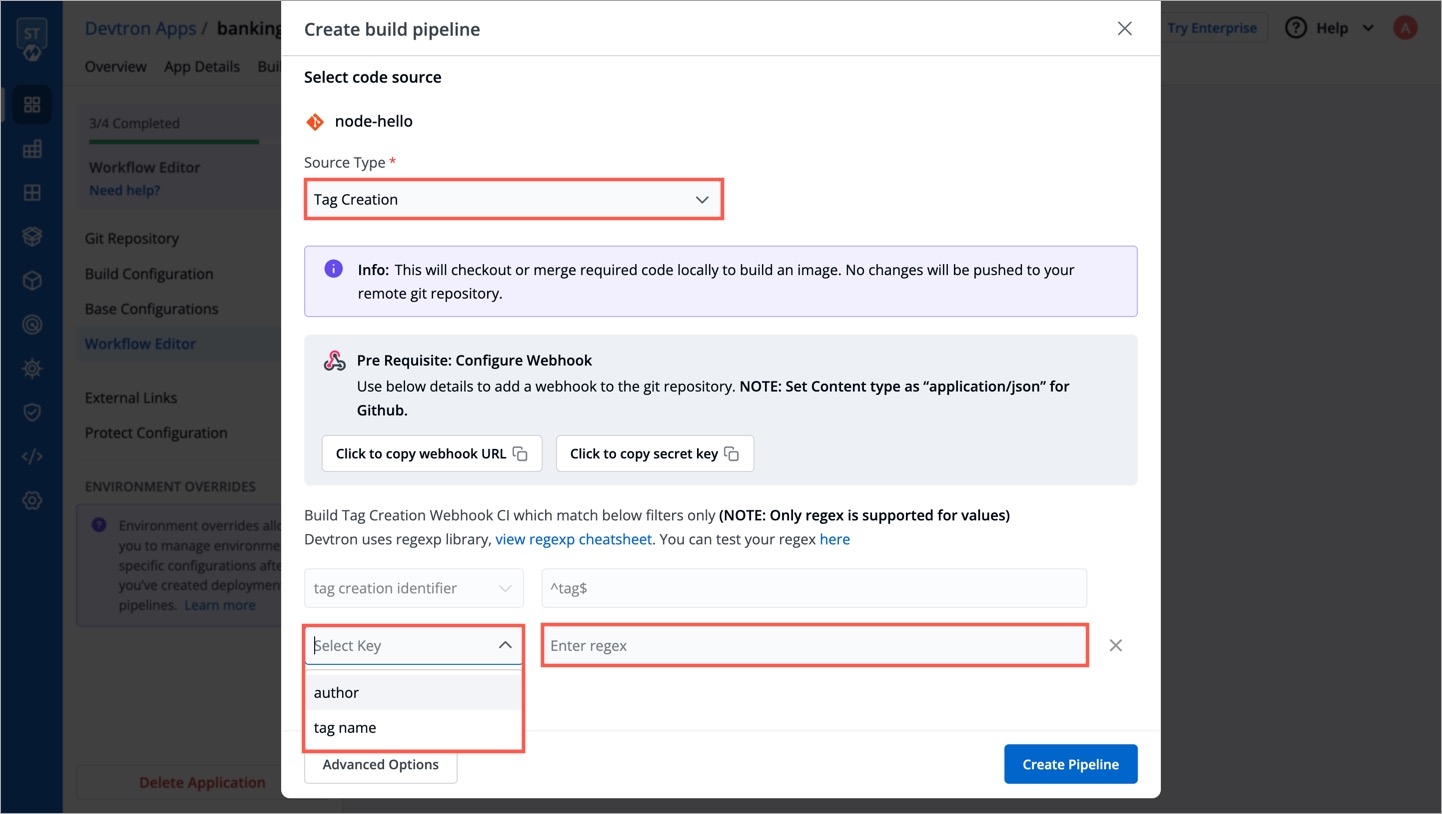
Source type
Required
Source type to trigger the CI. Available options: Branch Fixed | Branch Regex |Pull Request | Tag Creation
Branch Name
Required
Branch that triggers the CI build
Advanced Options
Optional
Create Pre-Build, Build, and Post-Build tasks
TRIGGER BUILD PIPELINE
Required
The build execution may be set to:
Automatically (default): Build is triggered automatically as the Git source code changes.
Manually: Build is triggered manually.
Pipeline Name
Required
A name for the pipeline
Source type
Required
Select the source type to build the CI pipeline: Branch Fixed | Branch Regex | Pull Request | Tag Creation
Branch Name
Required
Branch that triggers the CI build
Docker build arguments
Optional
Override docker build configurations for this pipeline.
Key: Field name
Value: Field value
Author
Author of the PR
Source branch name
Branch from which the Pull Request is generated
Target branch name
Branch to which the Pull request will be merged
Title
Title of the Pull Request
State
State of the PR. Default is "open" and cannot be changed
Author
The one who created the tag
Tag name
Name of the tag for which the webhook will be triggered
Ensure your custom tag do not start or end with a period (.) or comma (,)Deploy to environment
Environment: Provide the name of the environment.
Namespace: Provide the namespace.
When do you want to deploy
You can deploy either in one of the following ways:
Automatic: If you select automatic, your application will be deployed automatically everytime a new image is received.
Manual: In case of manual, you have to select the image and deploy manually.
Deployment Strategy
Configure the deployment preferences for this pipeline.
{
"dockerImage": "445808685819.dkr.ecr.us-east-2.amazonaws.com/orch:23907713-2"
}curl --location --request POST \
'https://{domain-name}/orchestrator/webhook/ext-ci/{pipeline-id}' \
--header 'Content-Type: application/json' \
--header 'token: {token}' \
--data-raw '{
"dockerImage": "445808685819.dkr.ecr.us-east-2.amazonaws.com/orch:23907713-2"
}'200
app detail page url
400
Bad request
401
Unauthorized
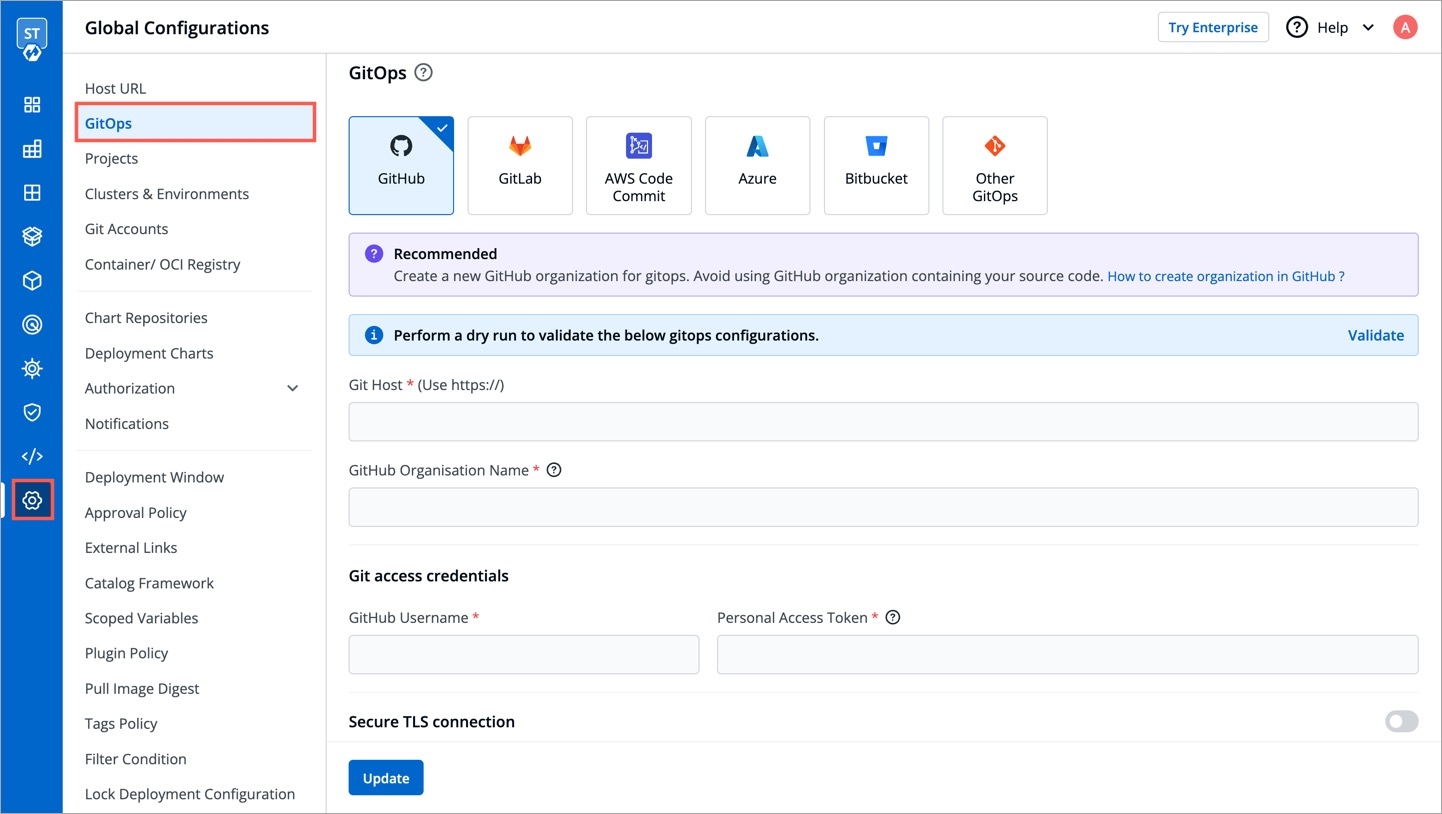

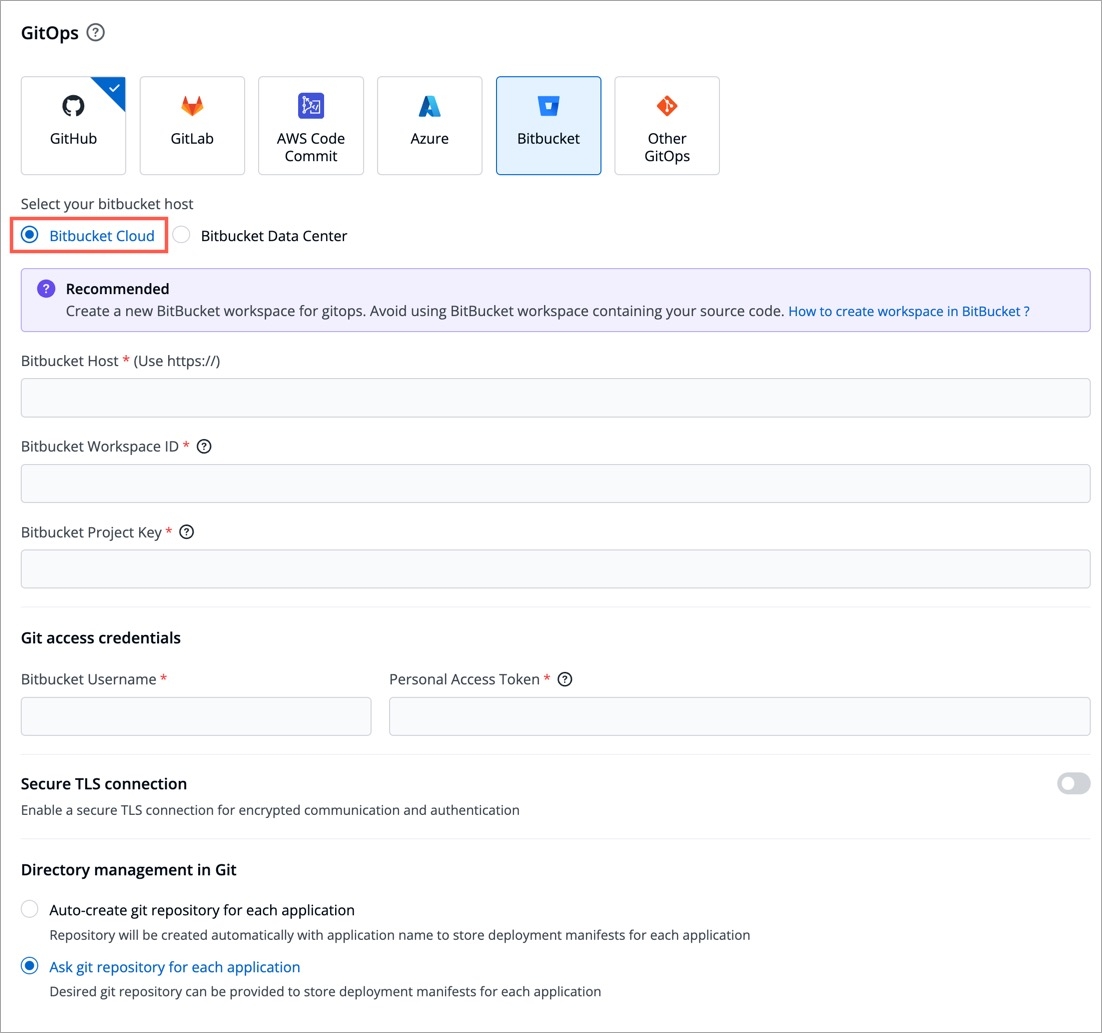
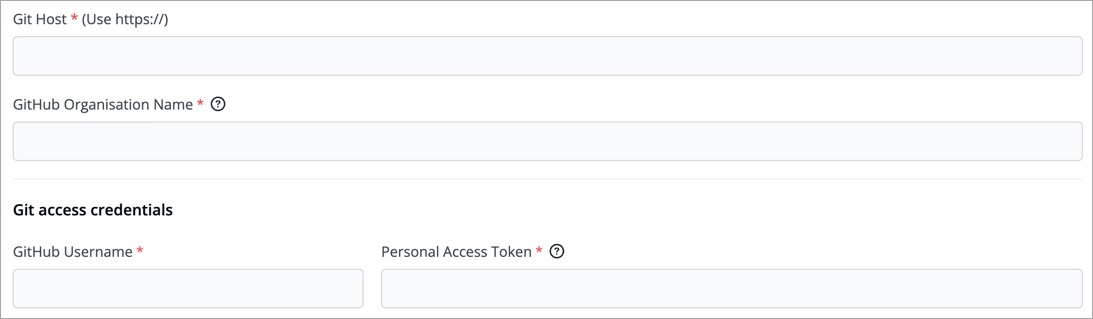
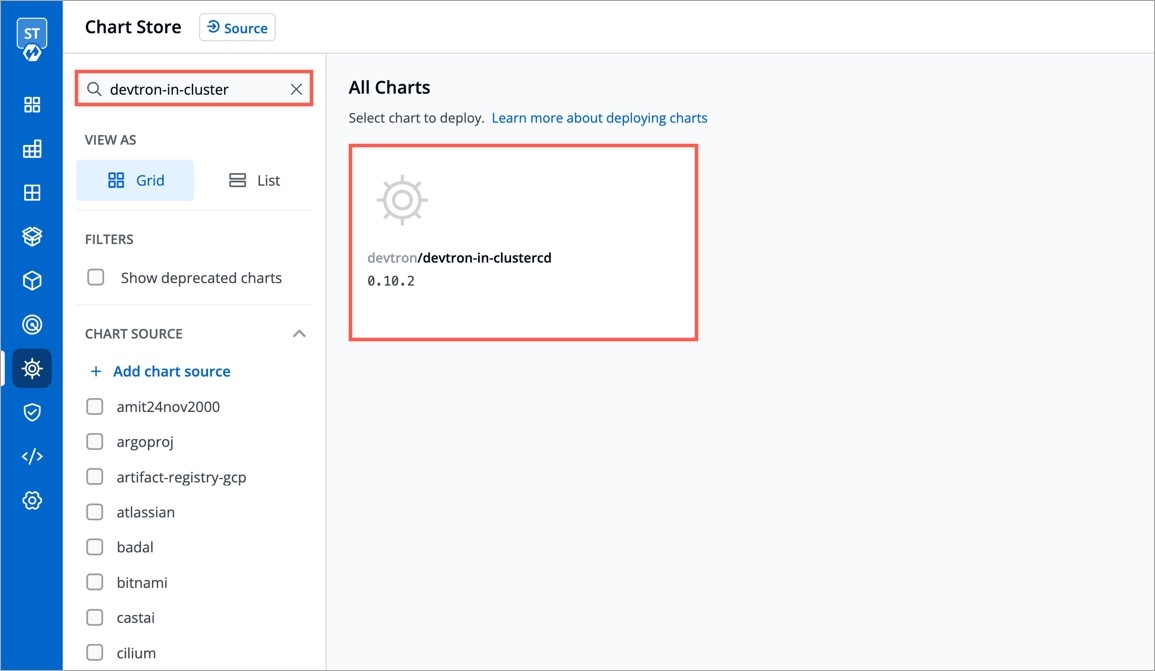
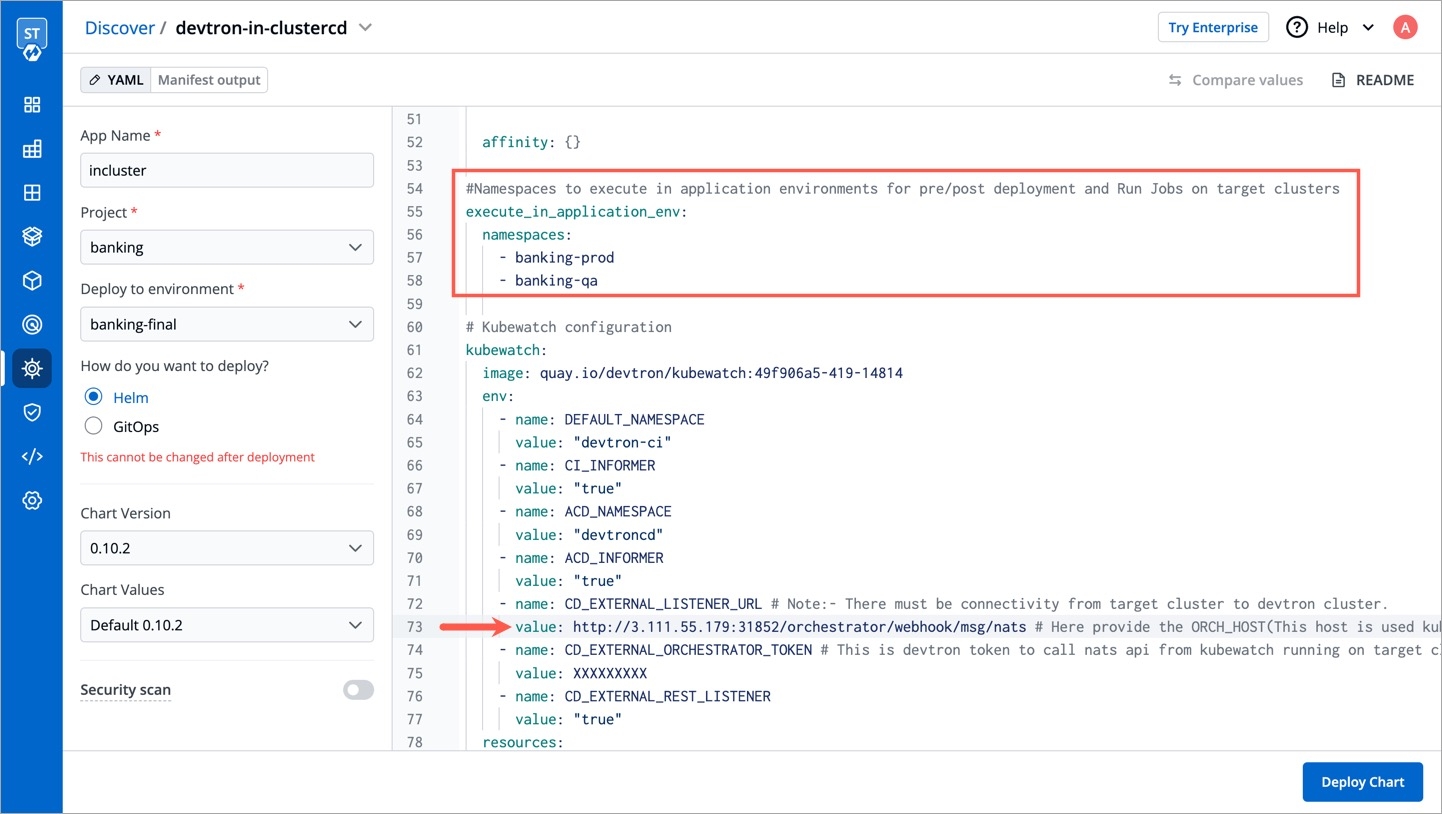

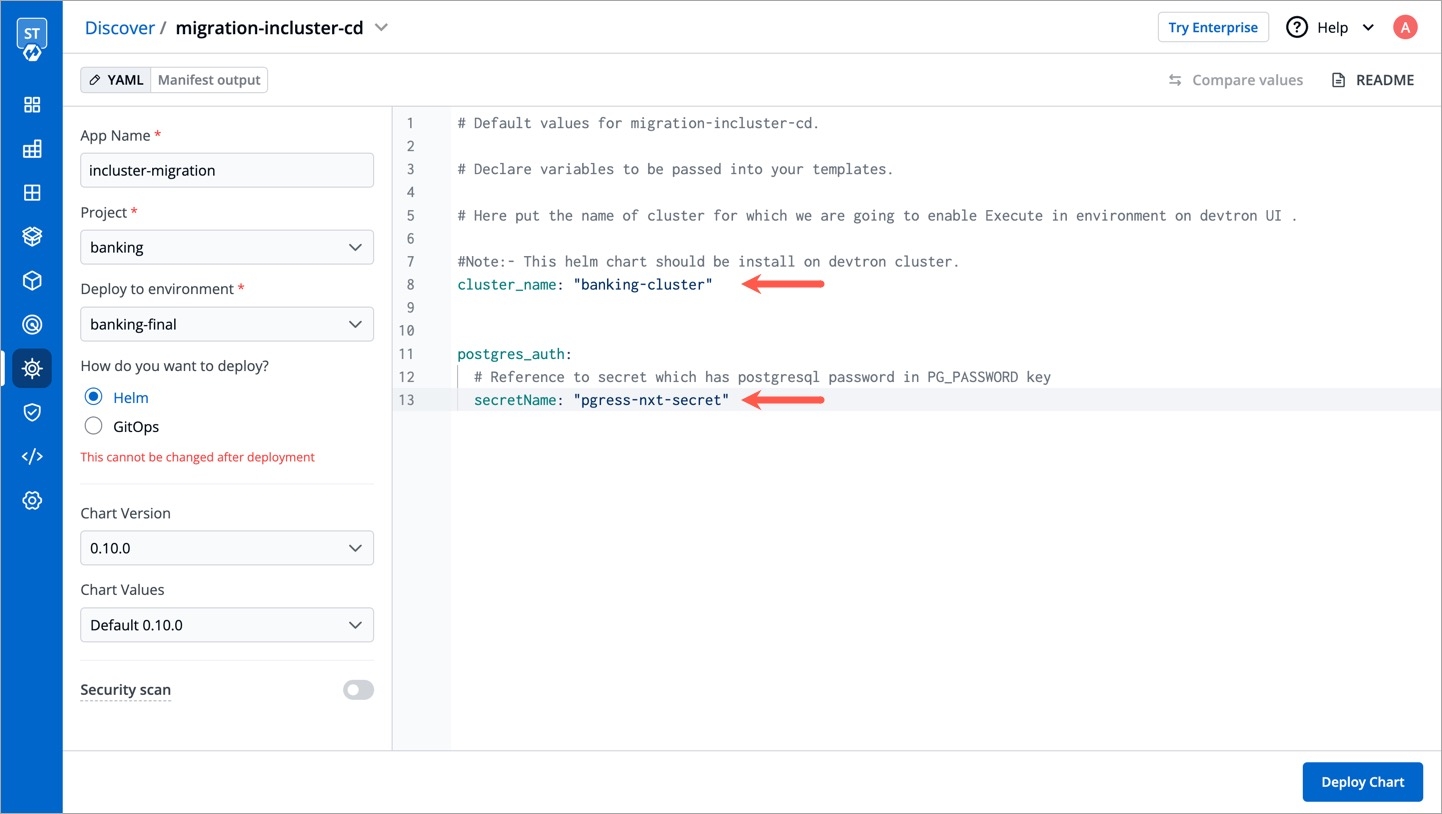
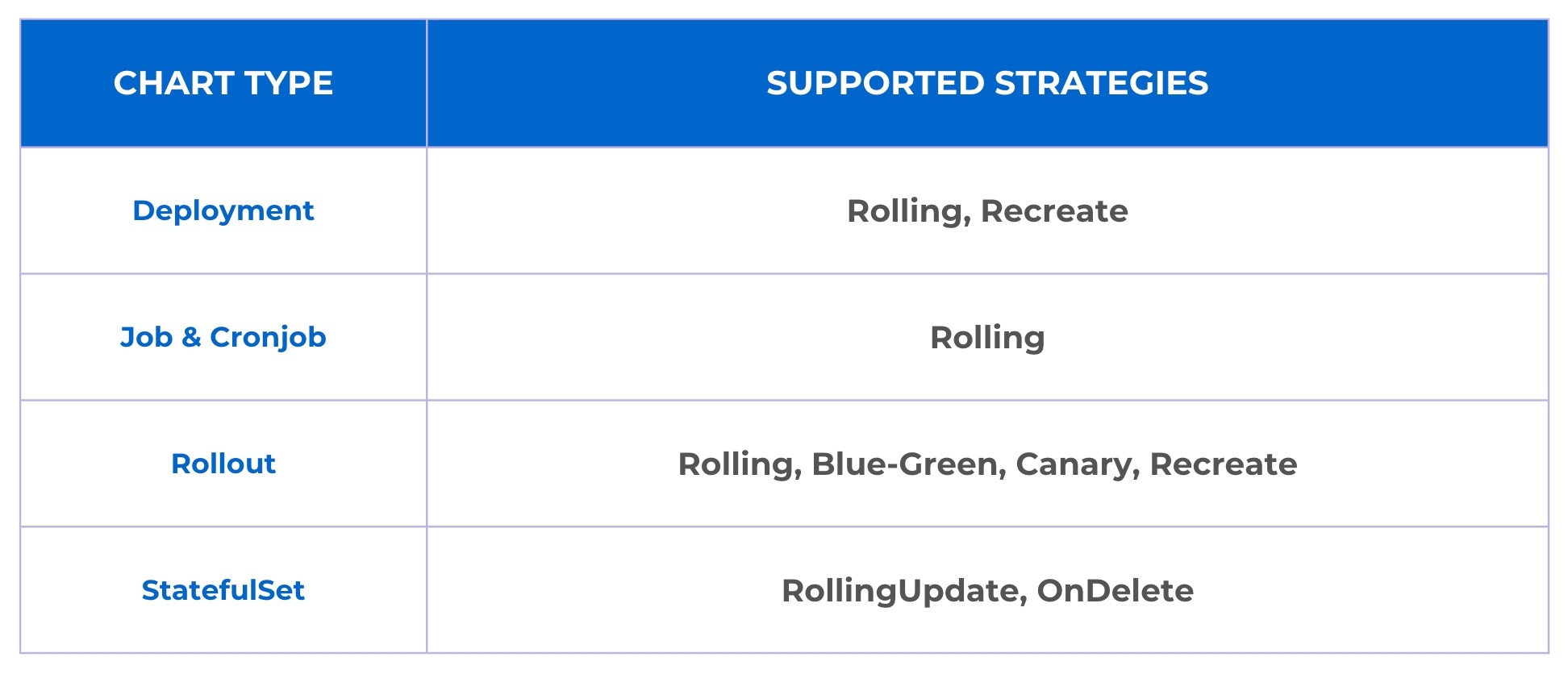
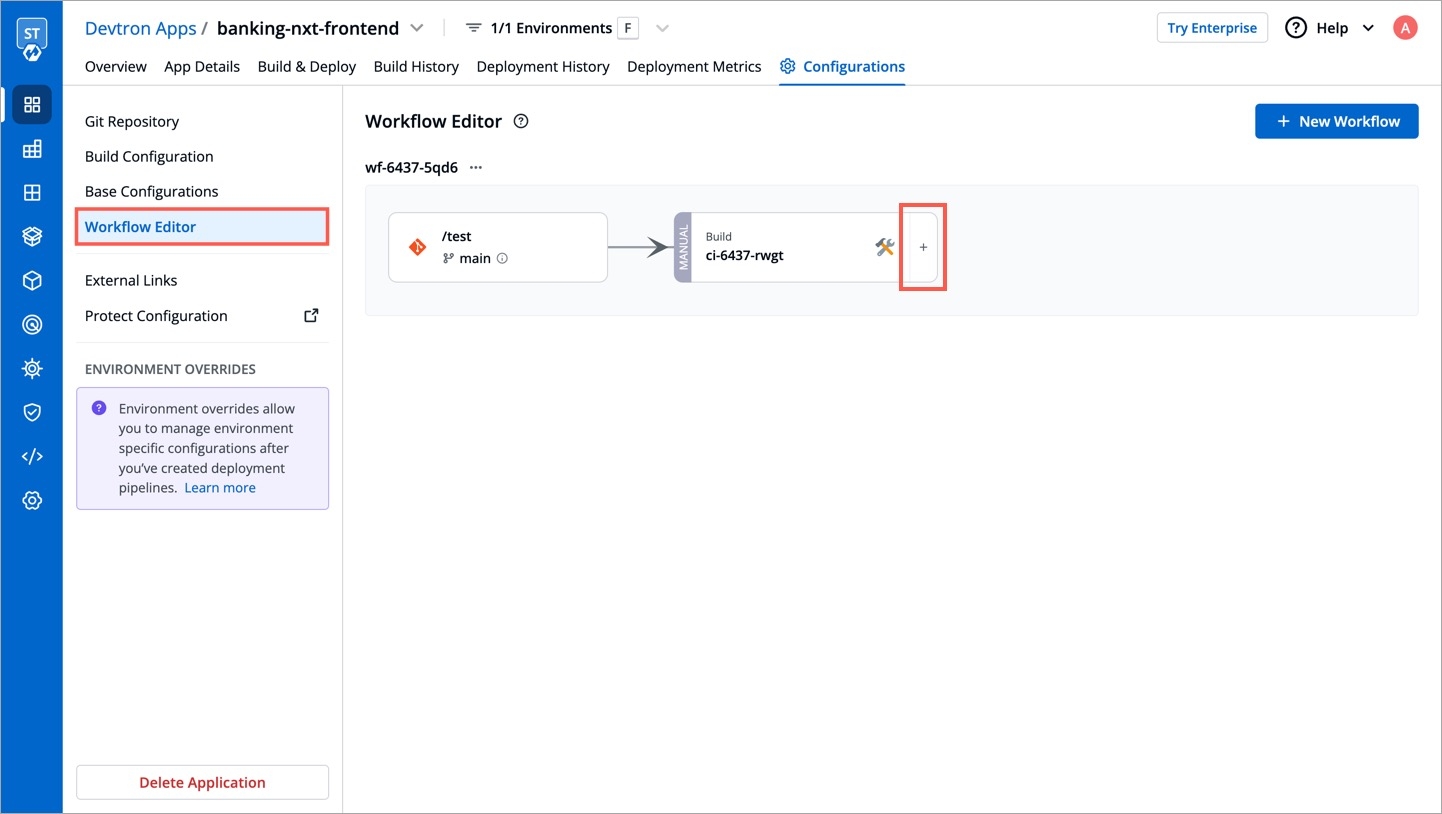
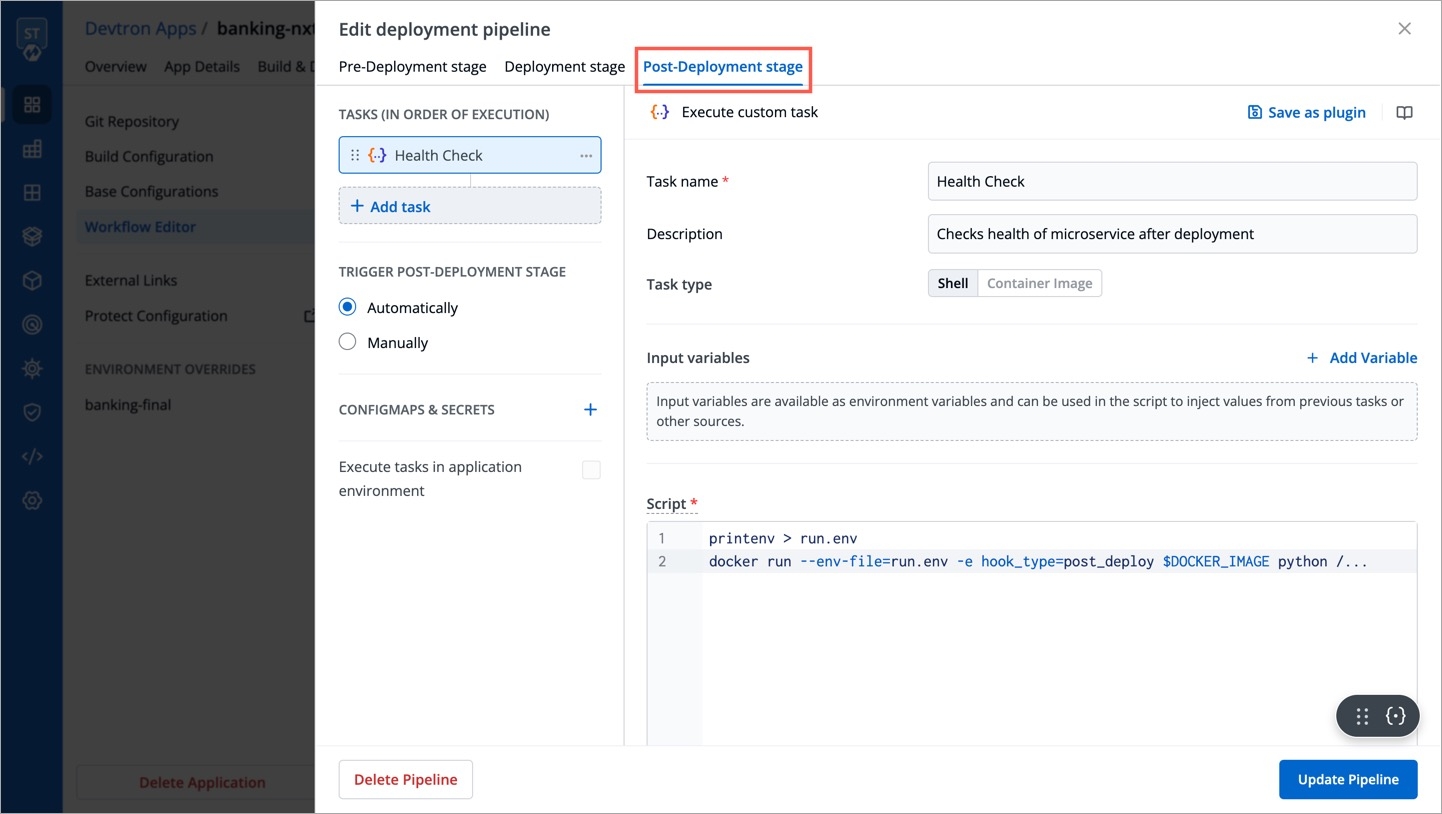
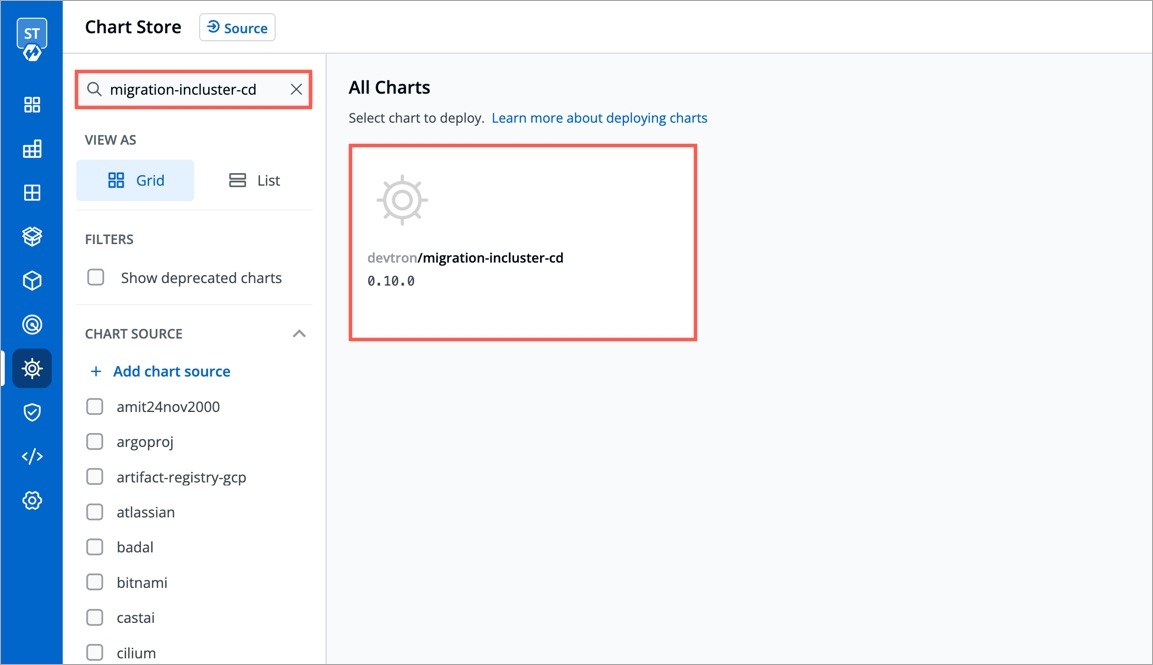
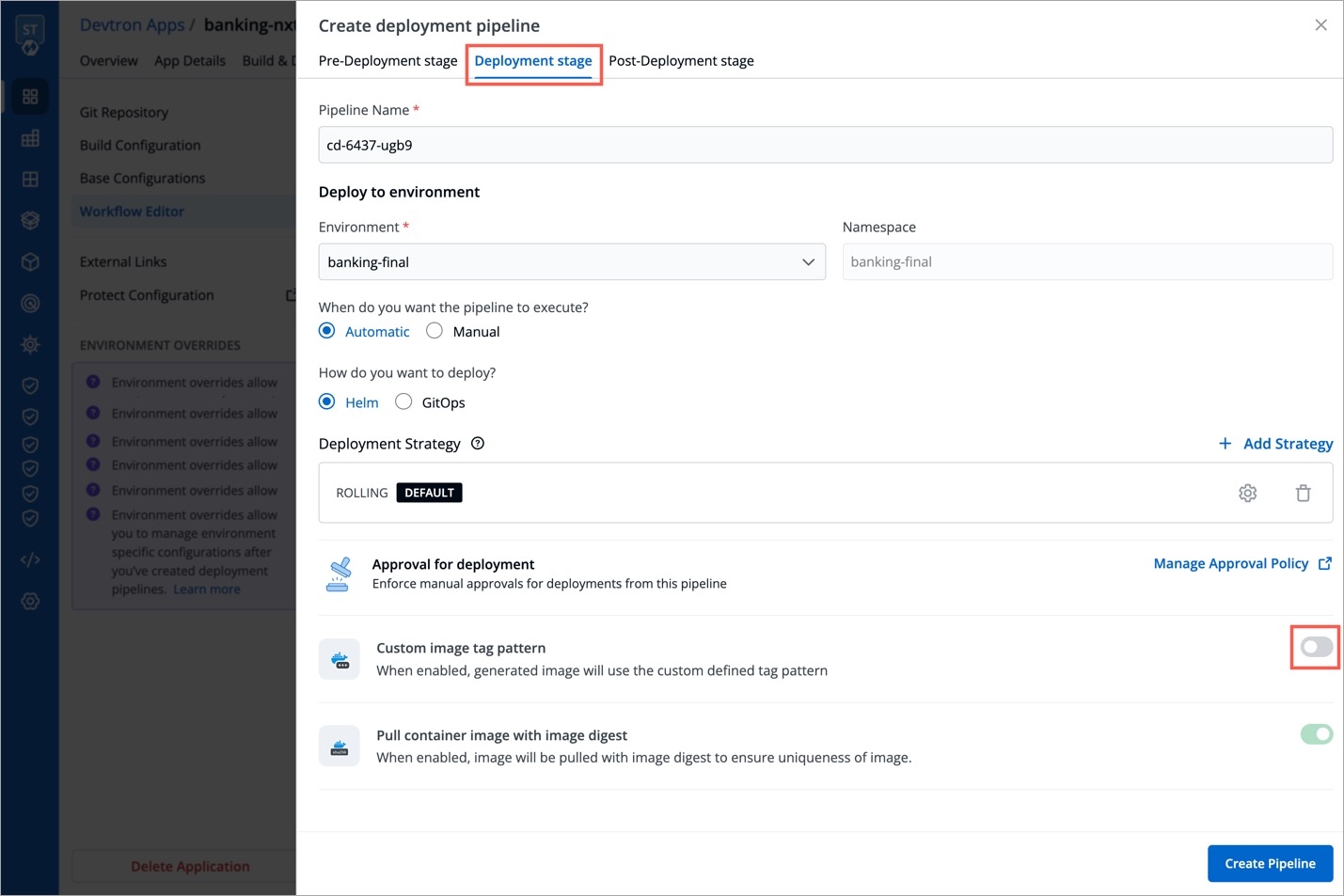
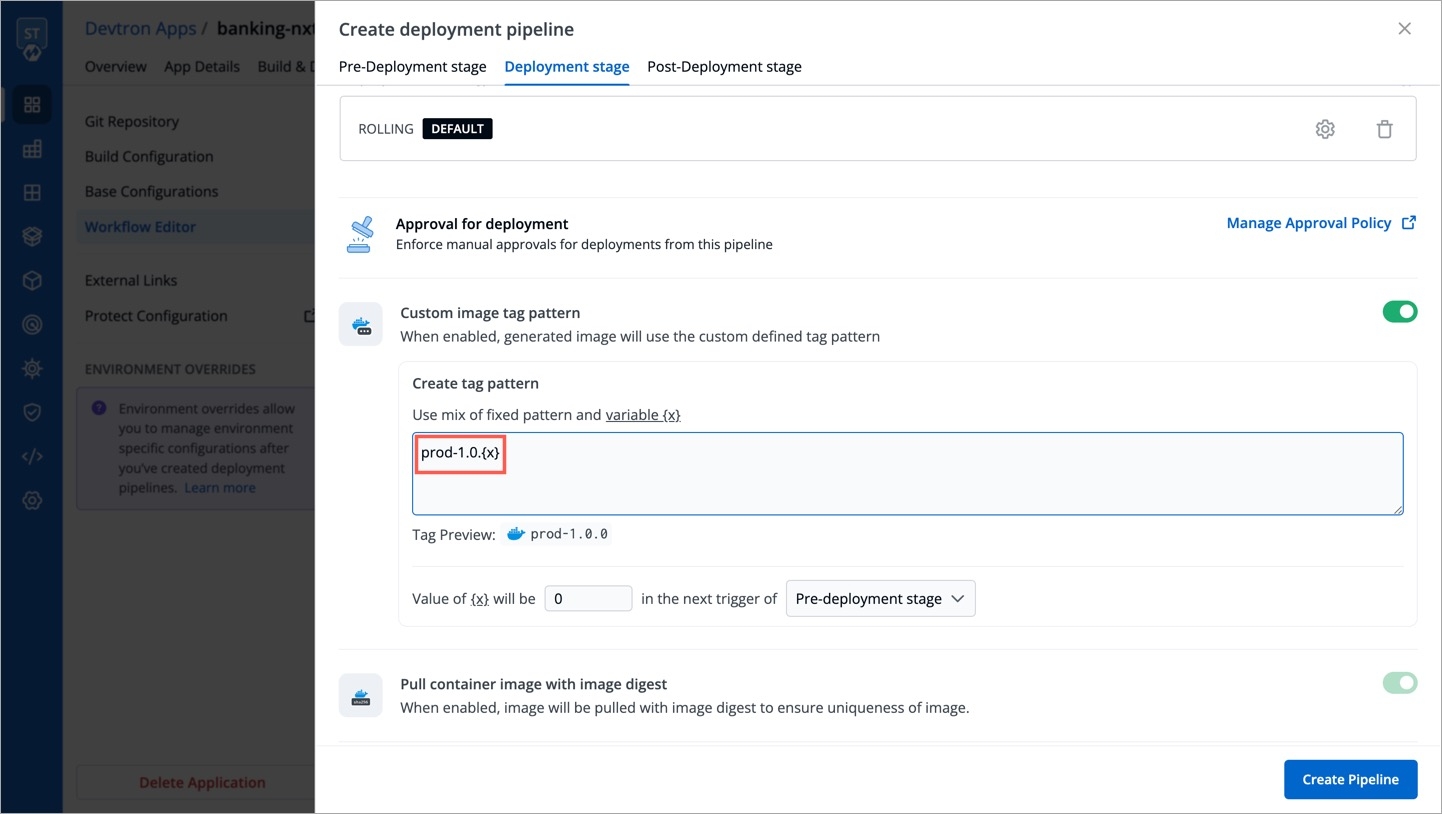
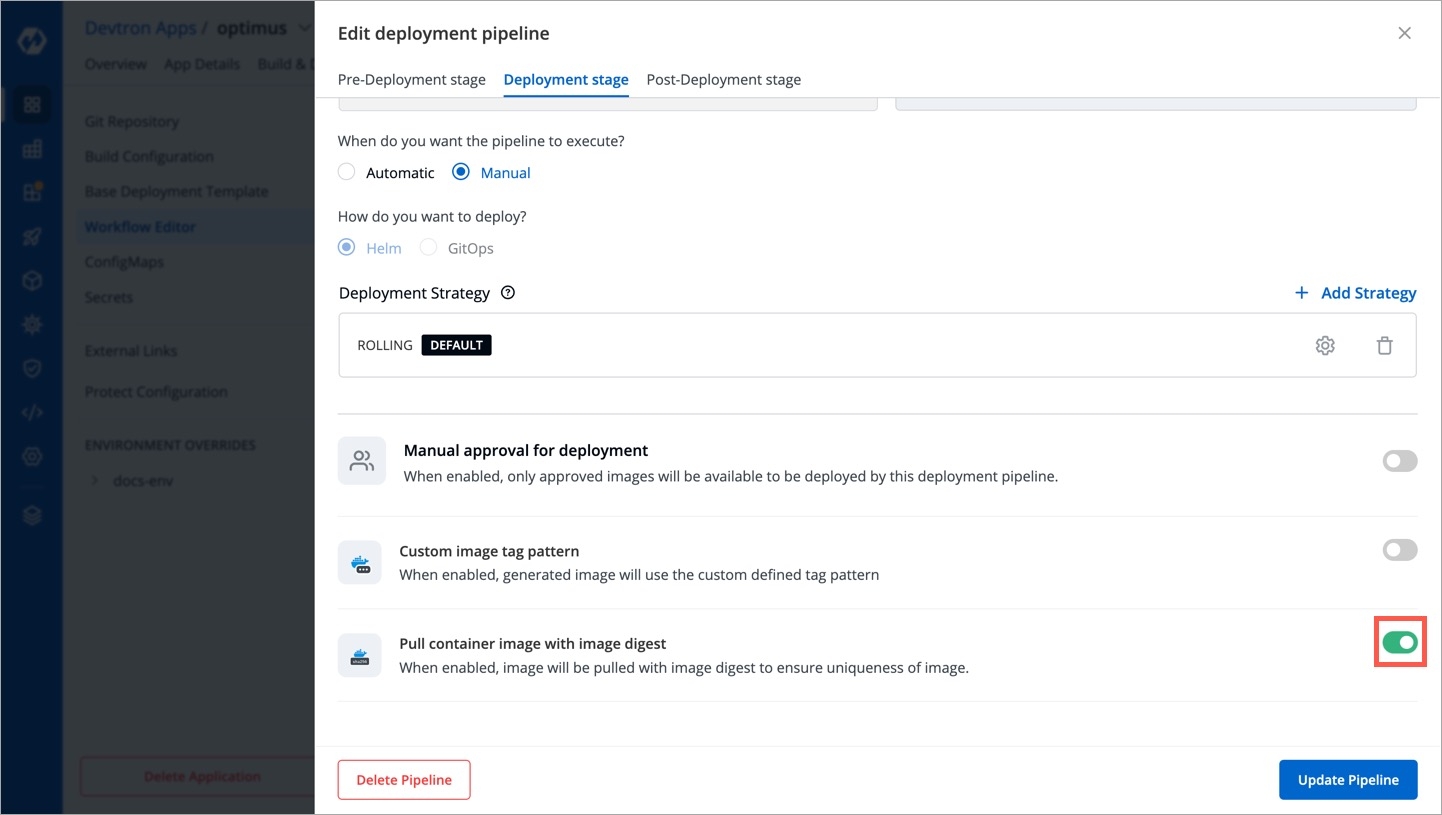
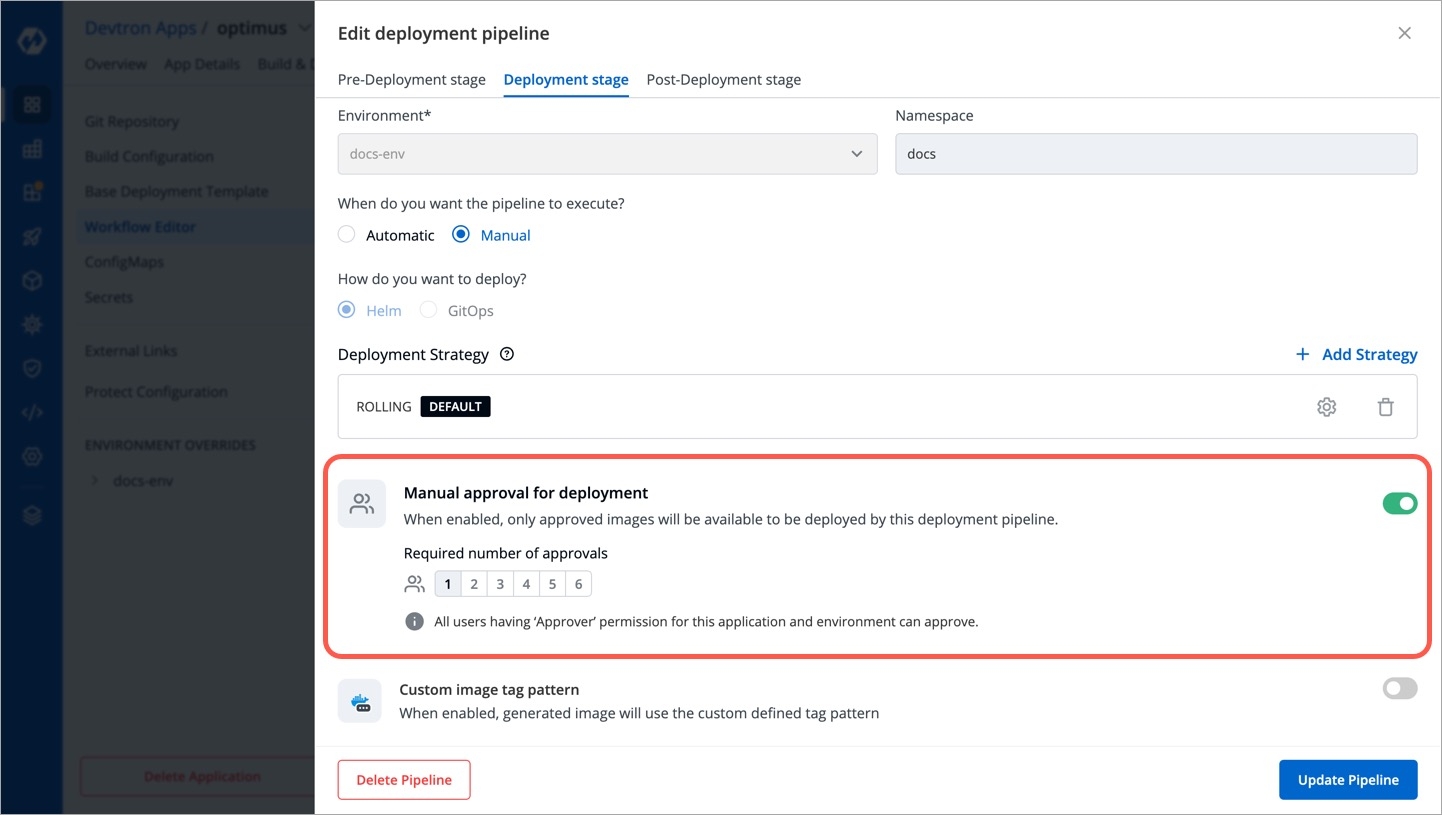
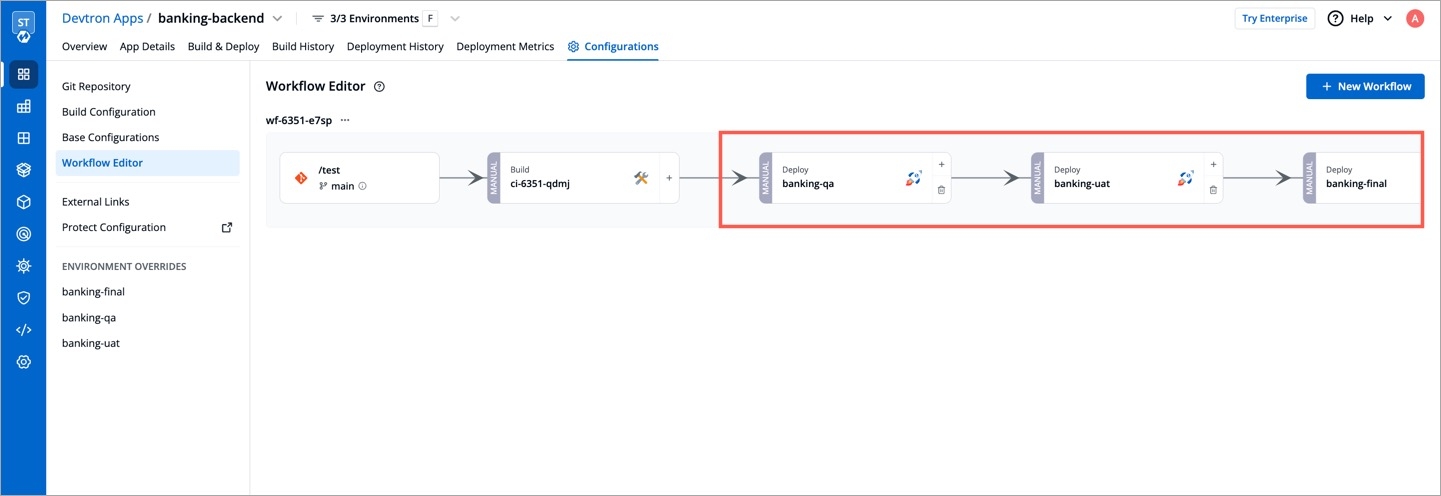
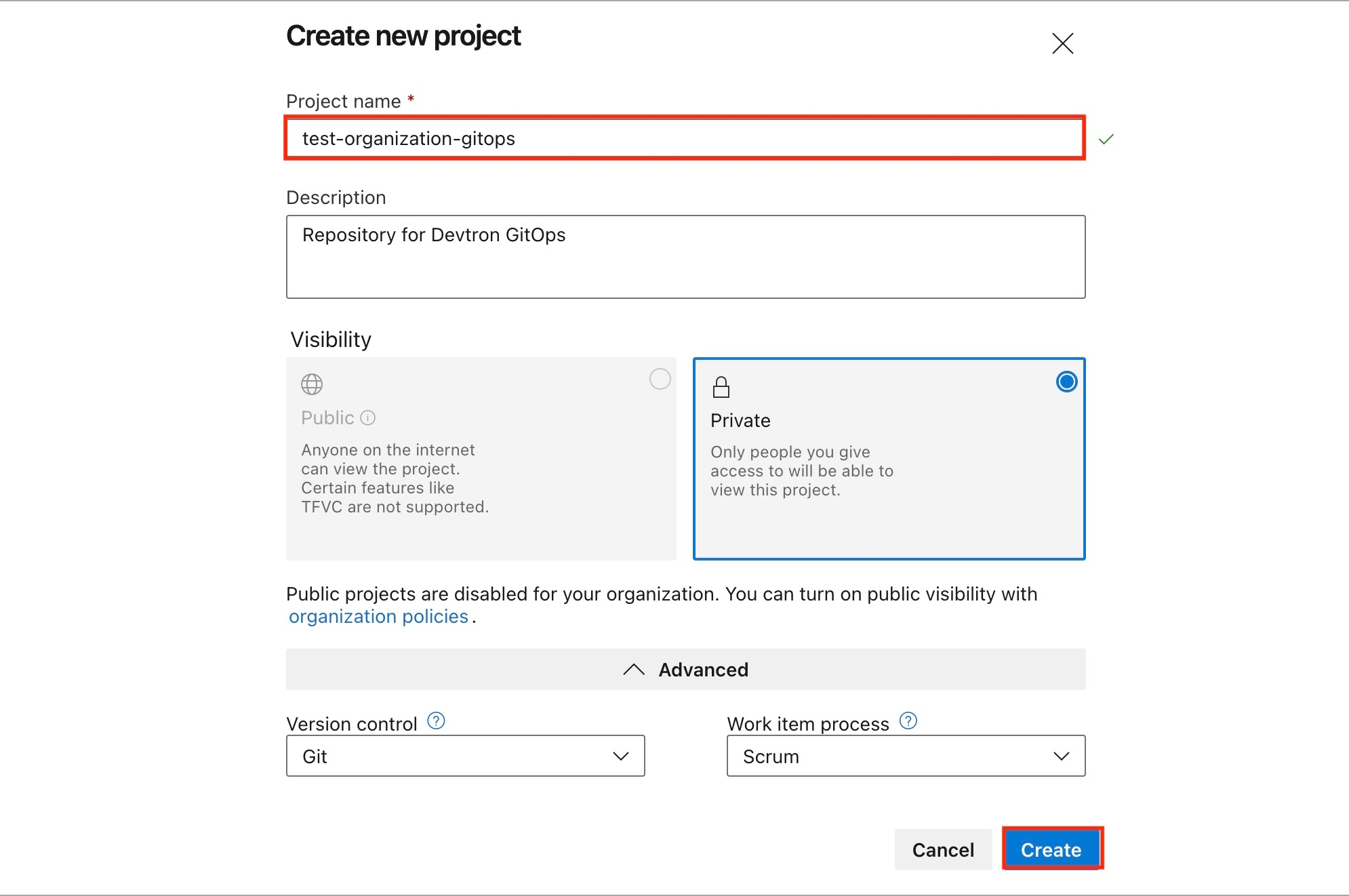
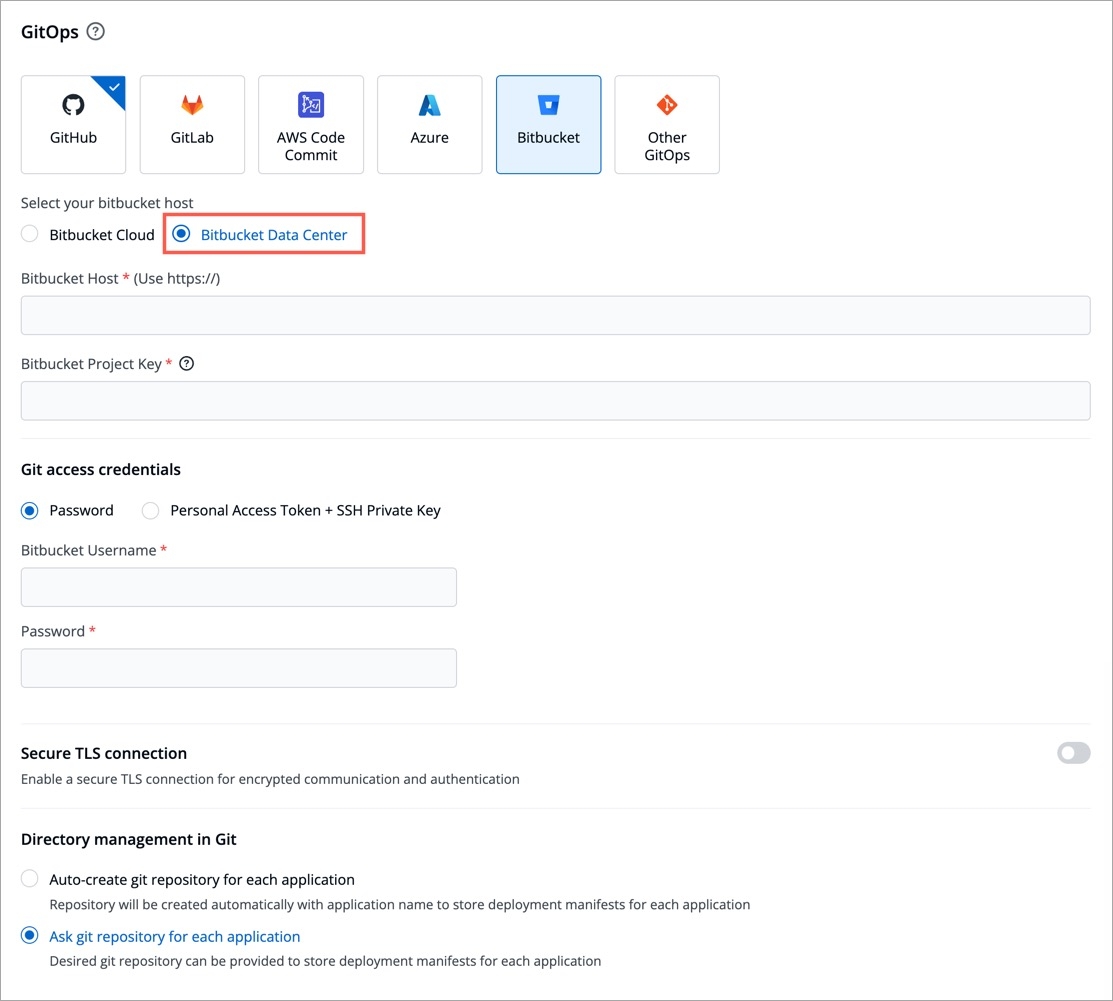

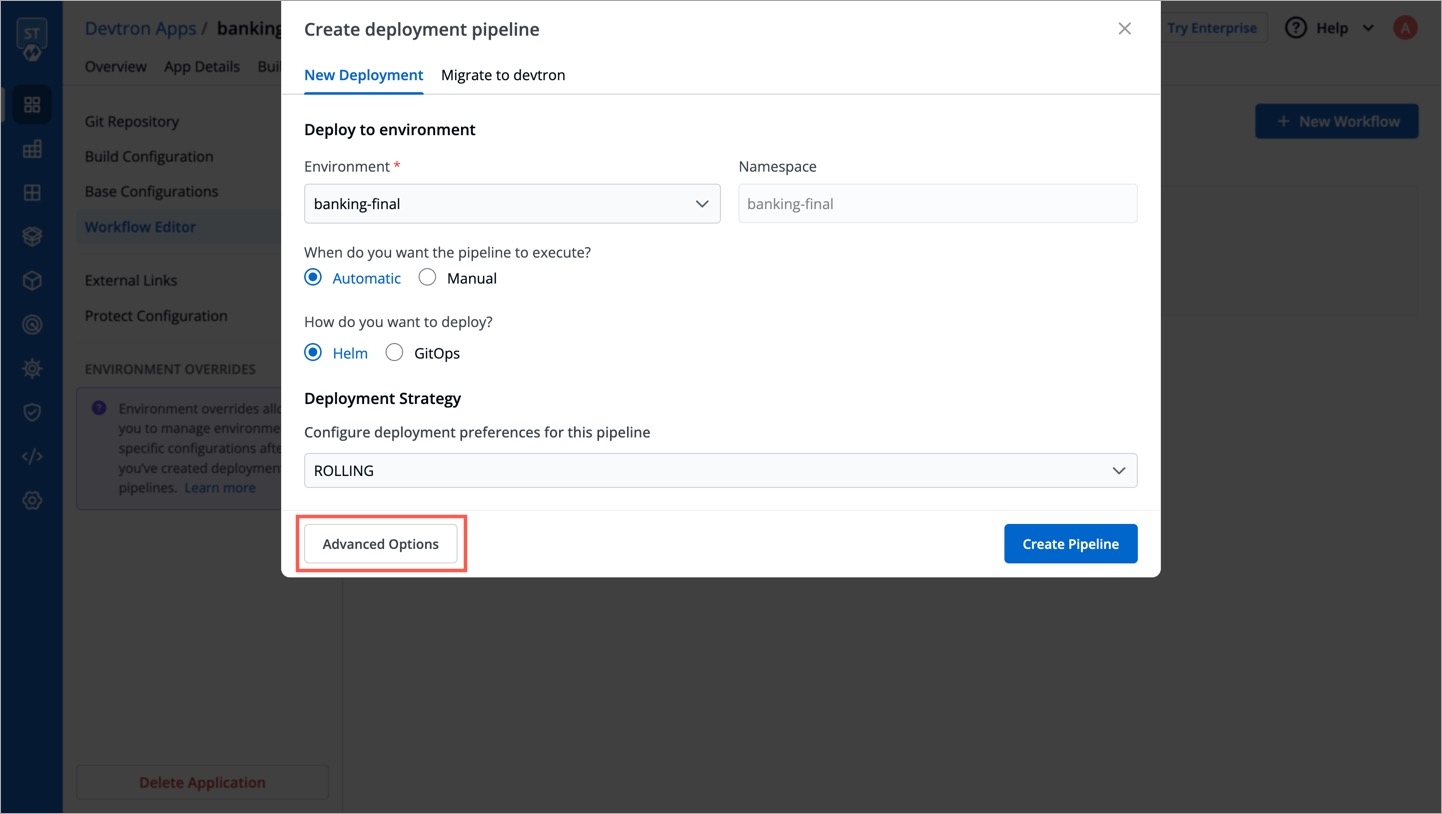
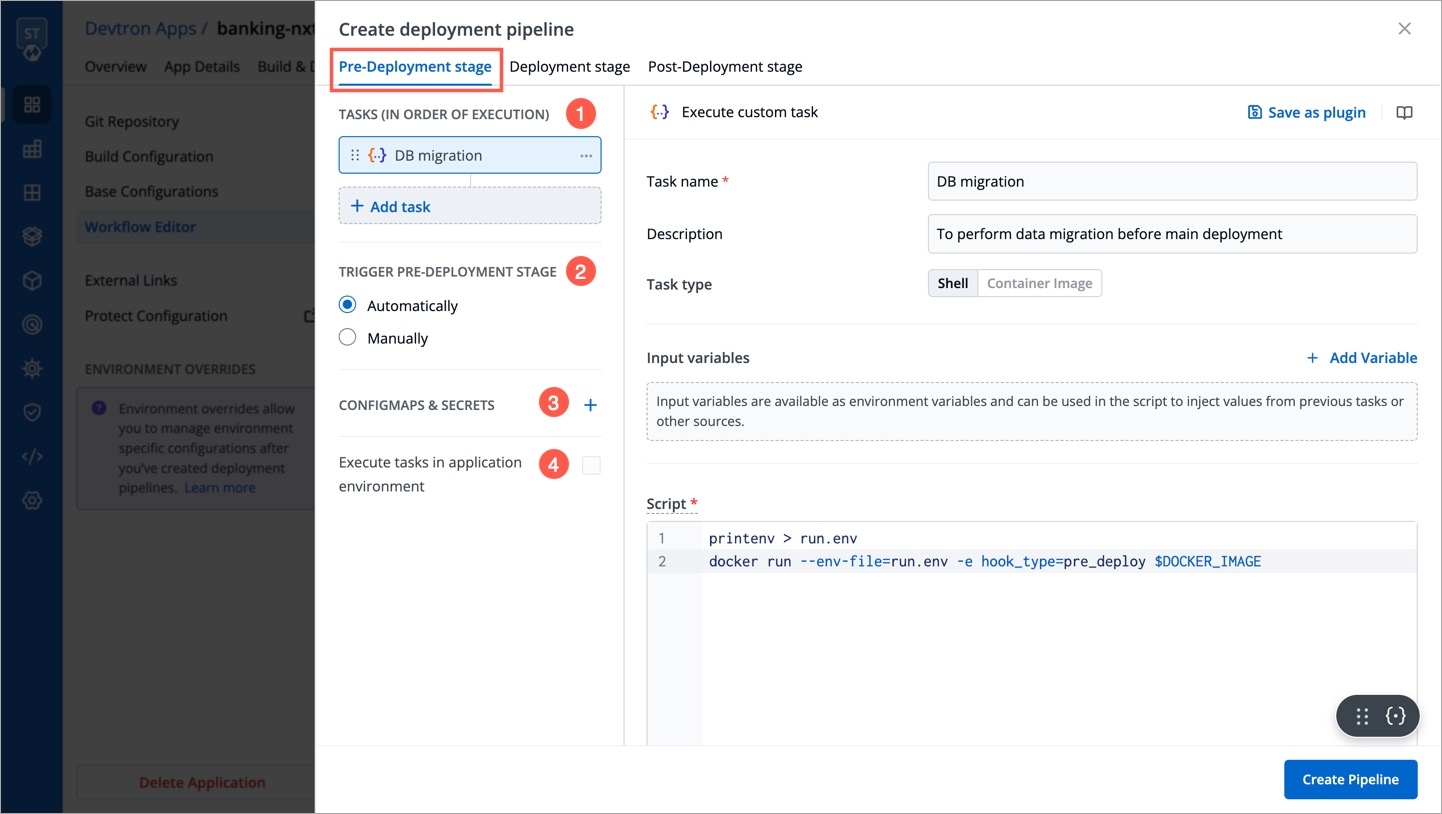
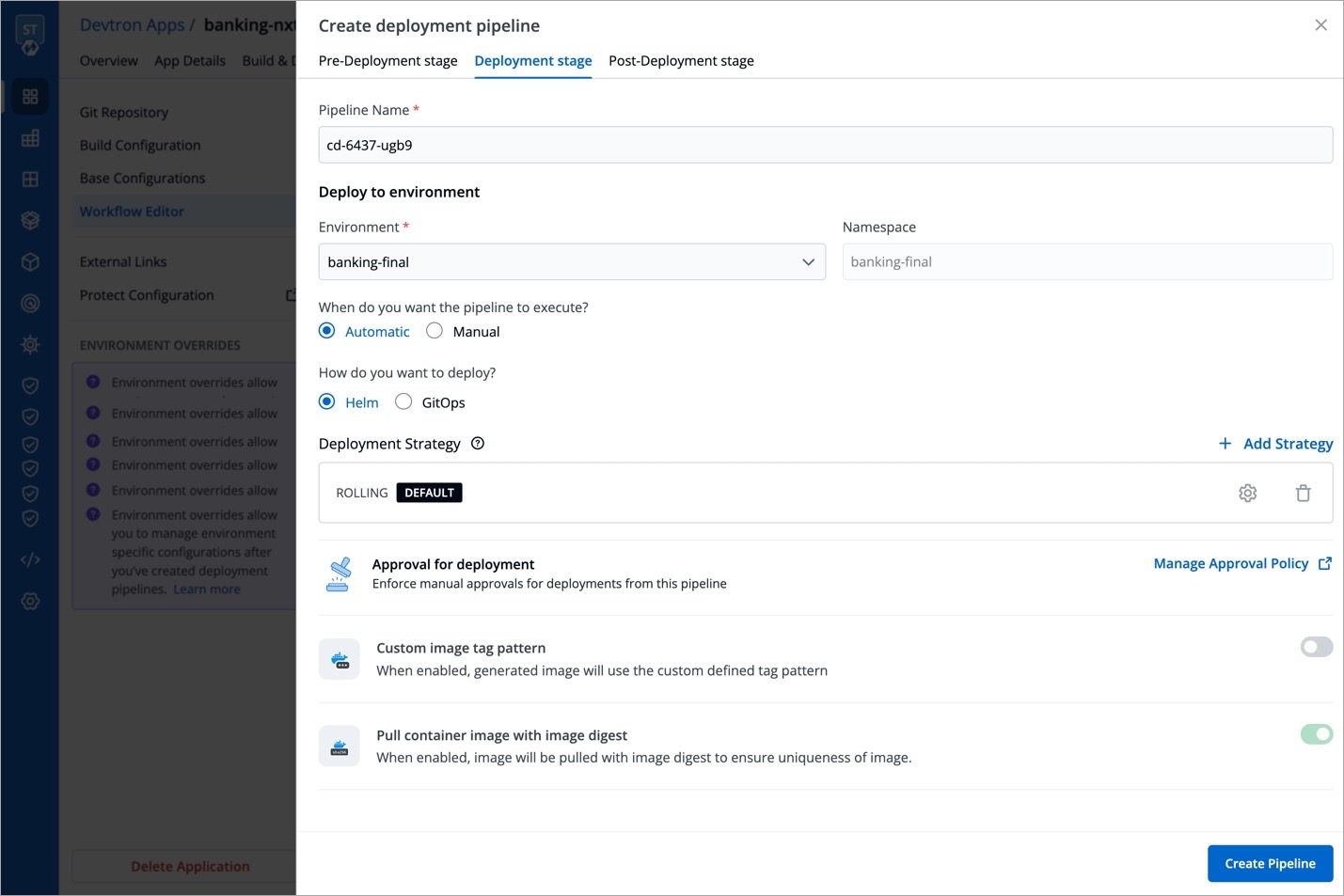
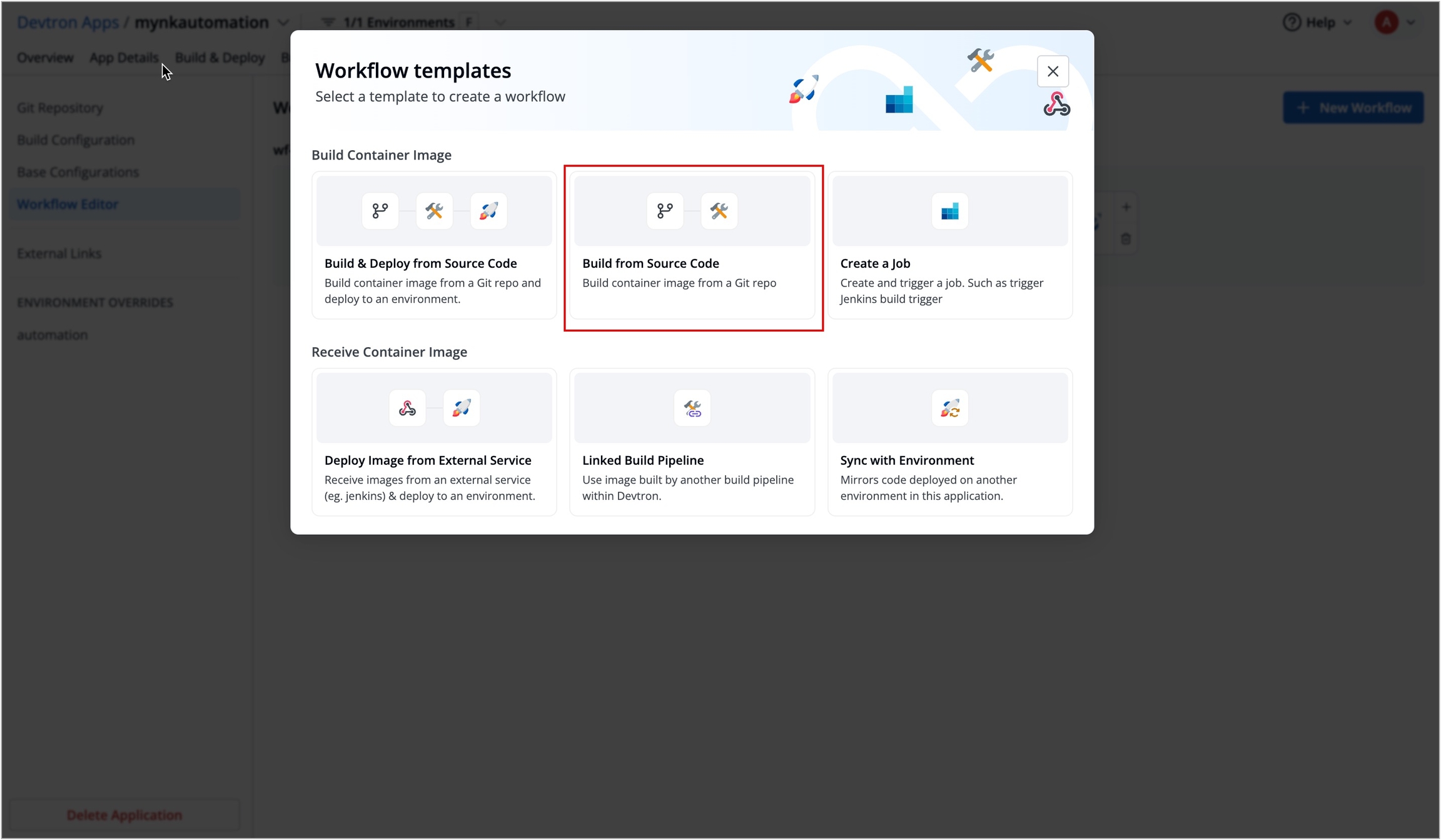
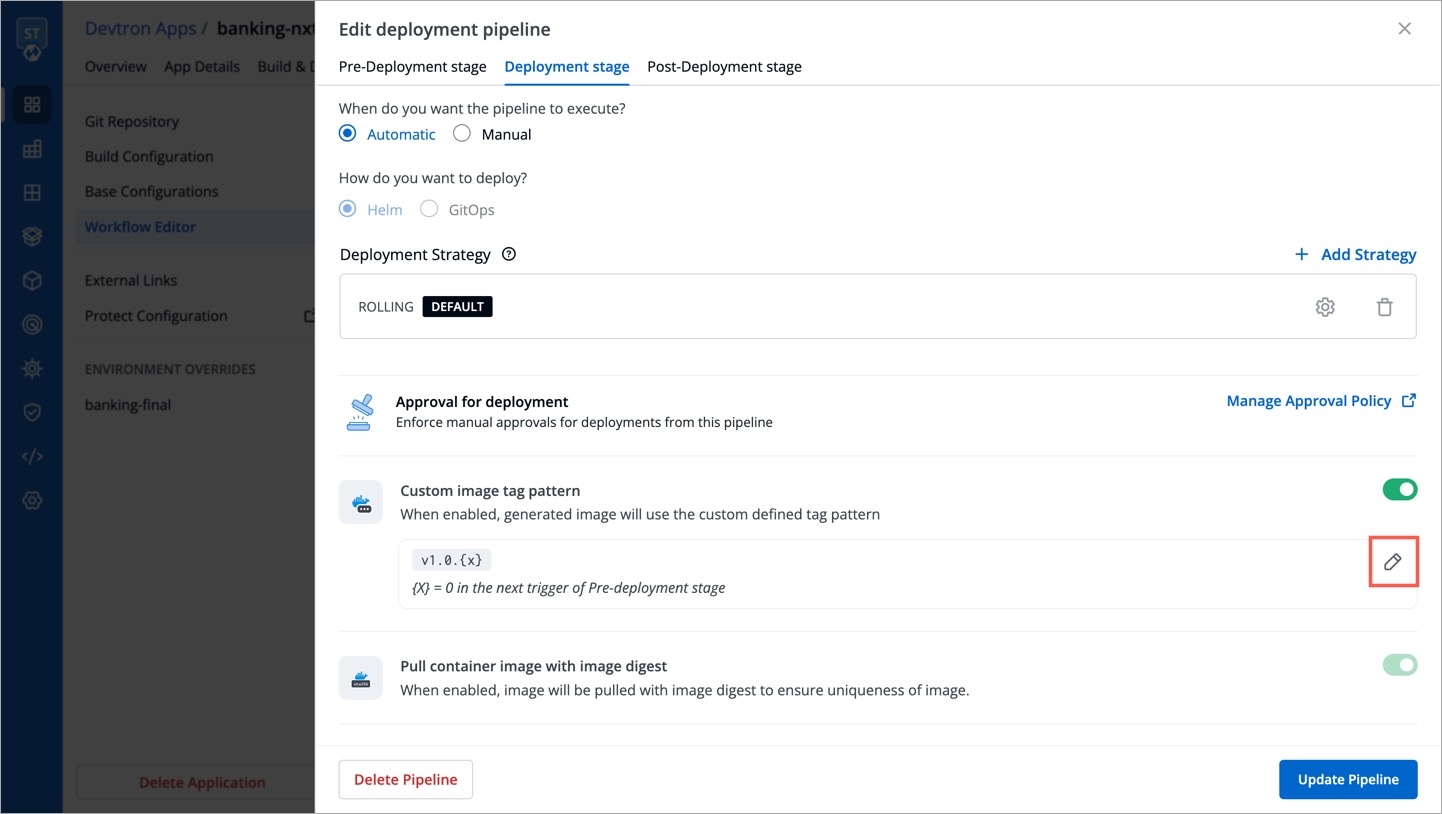
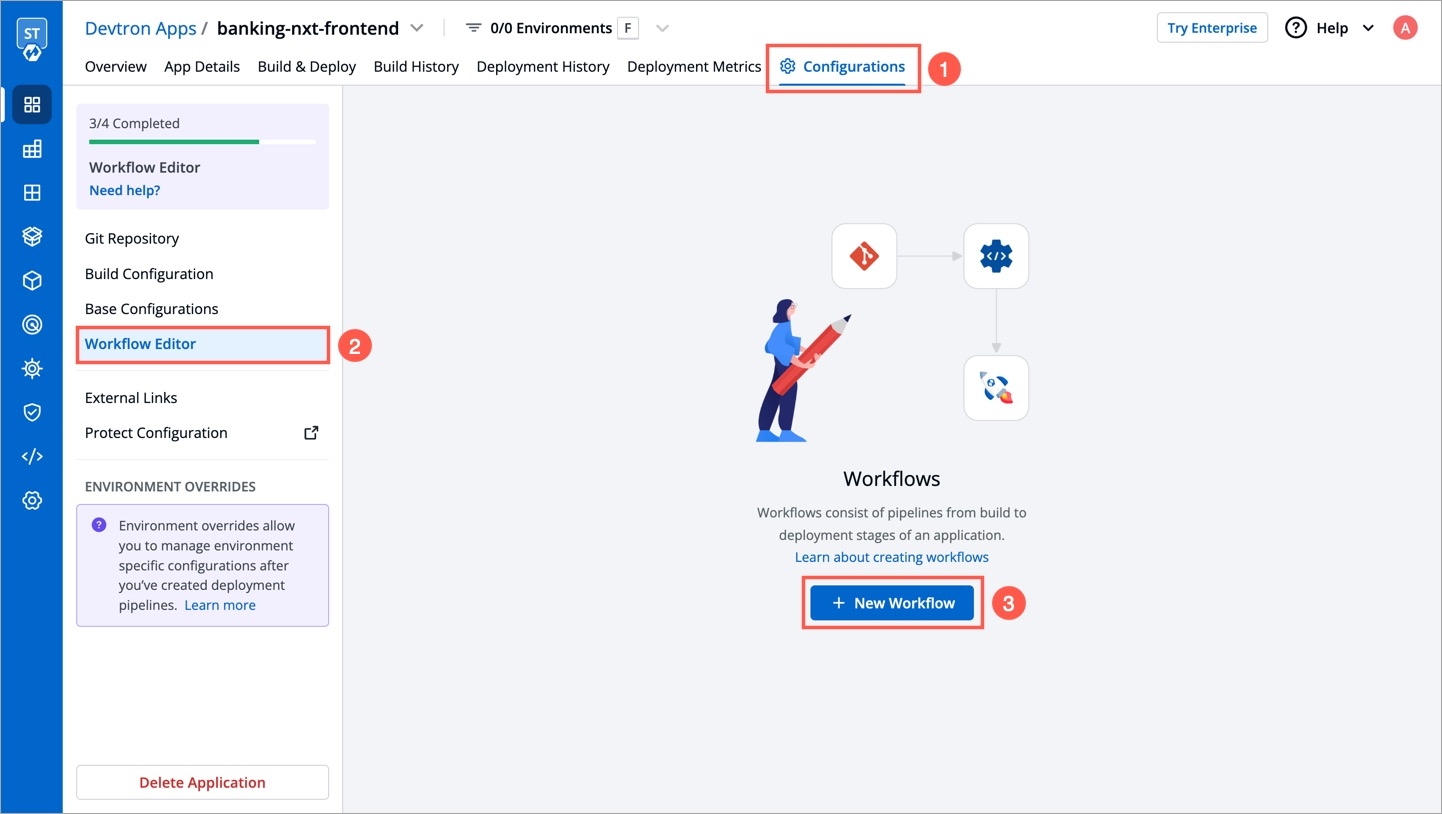
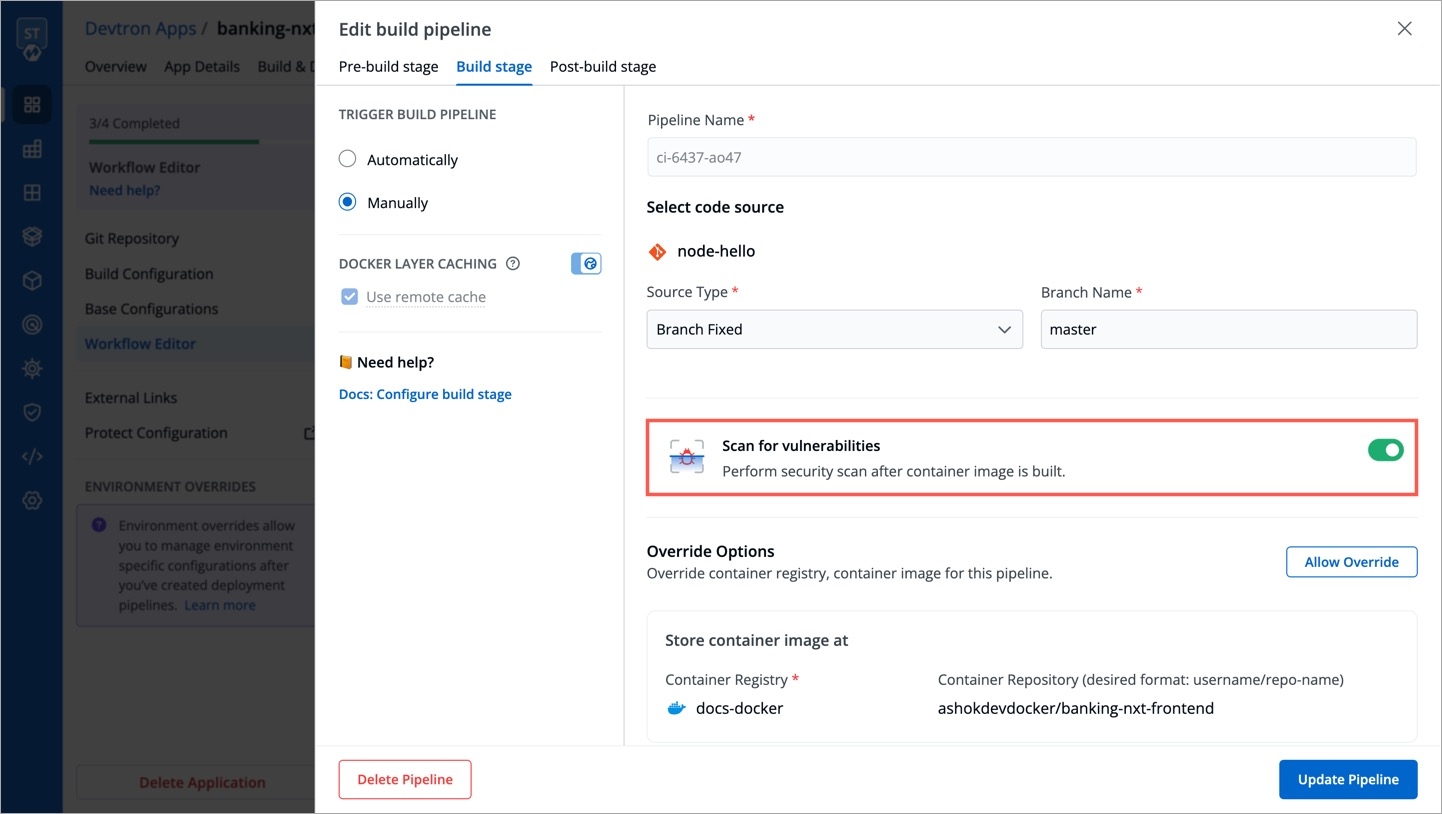
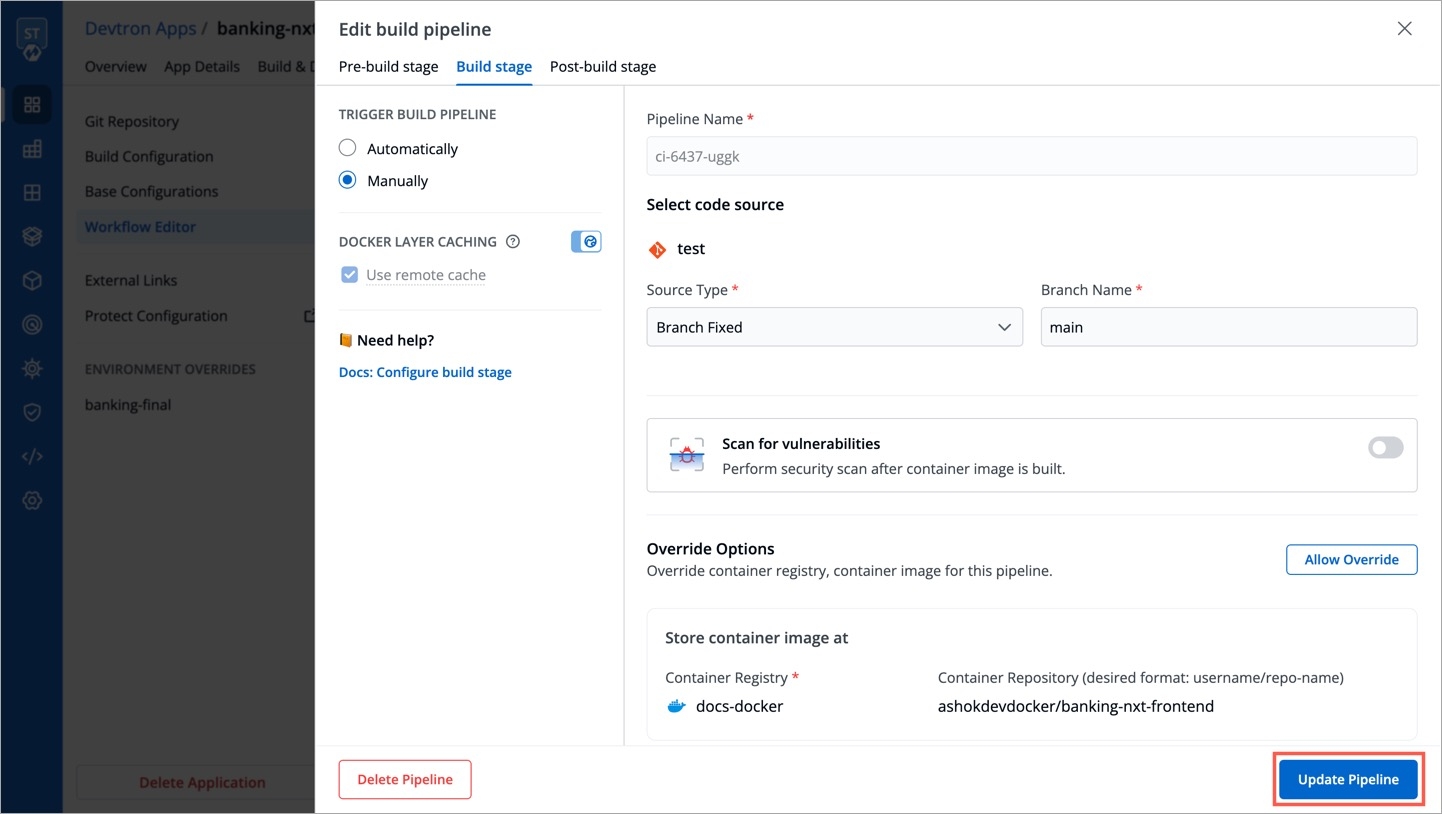
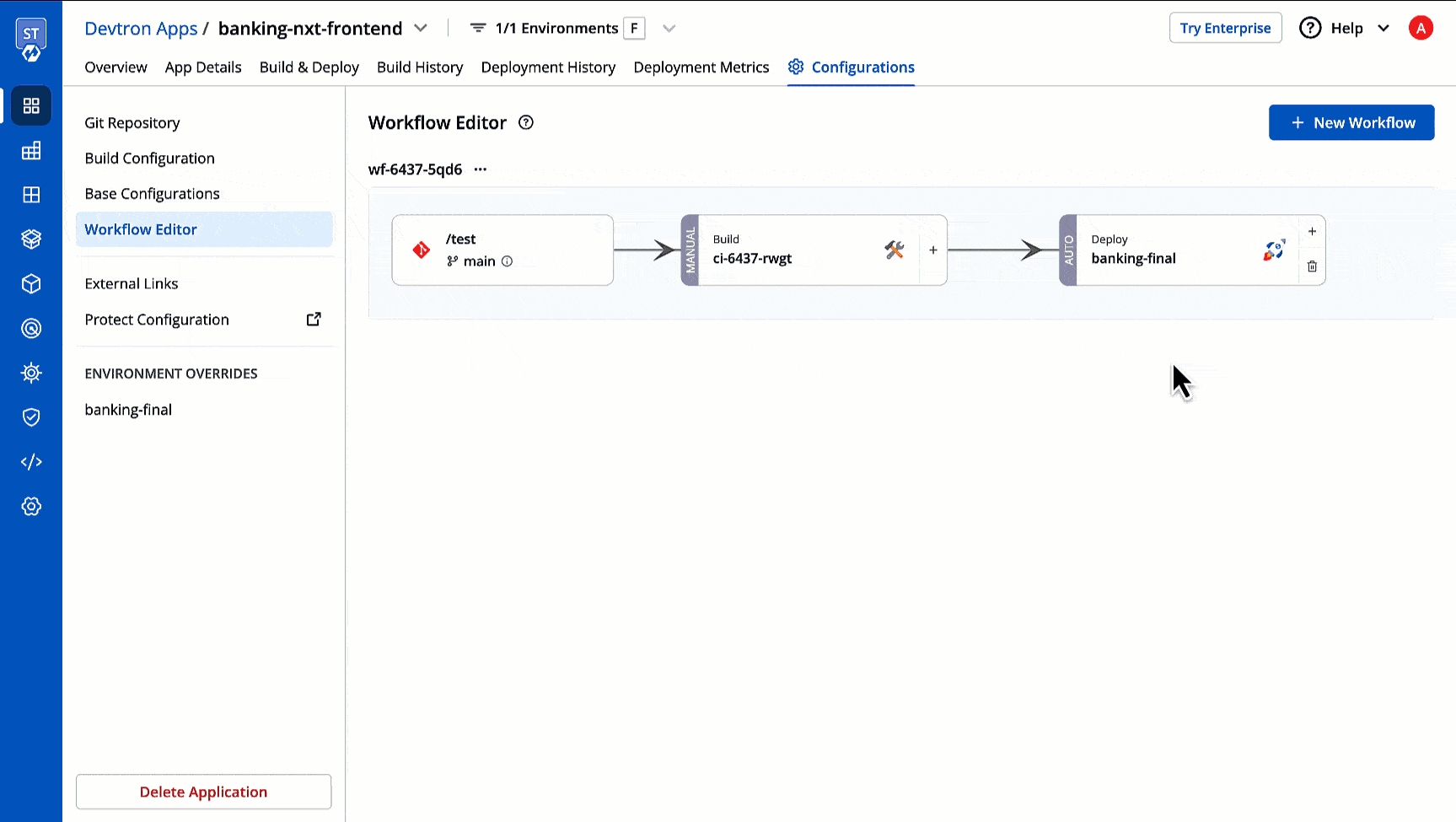
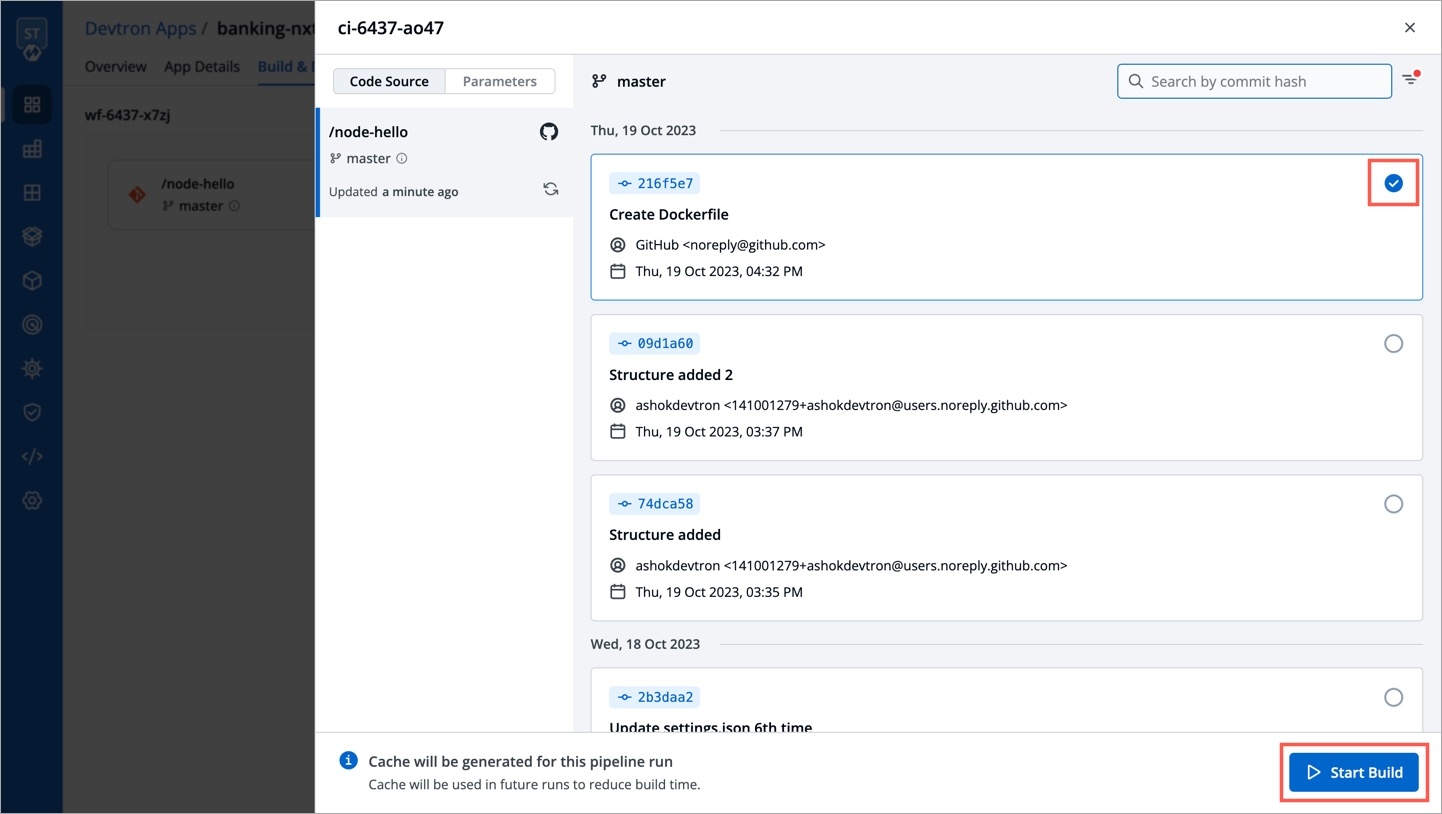
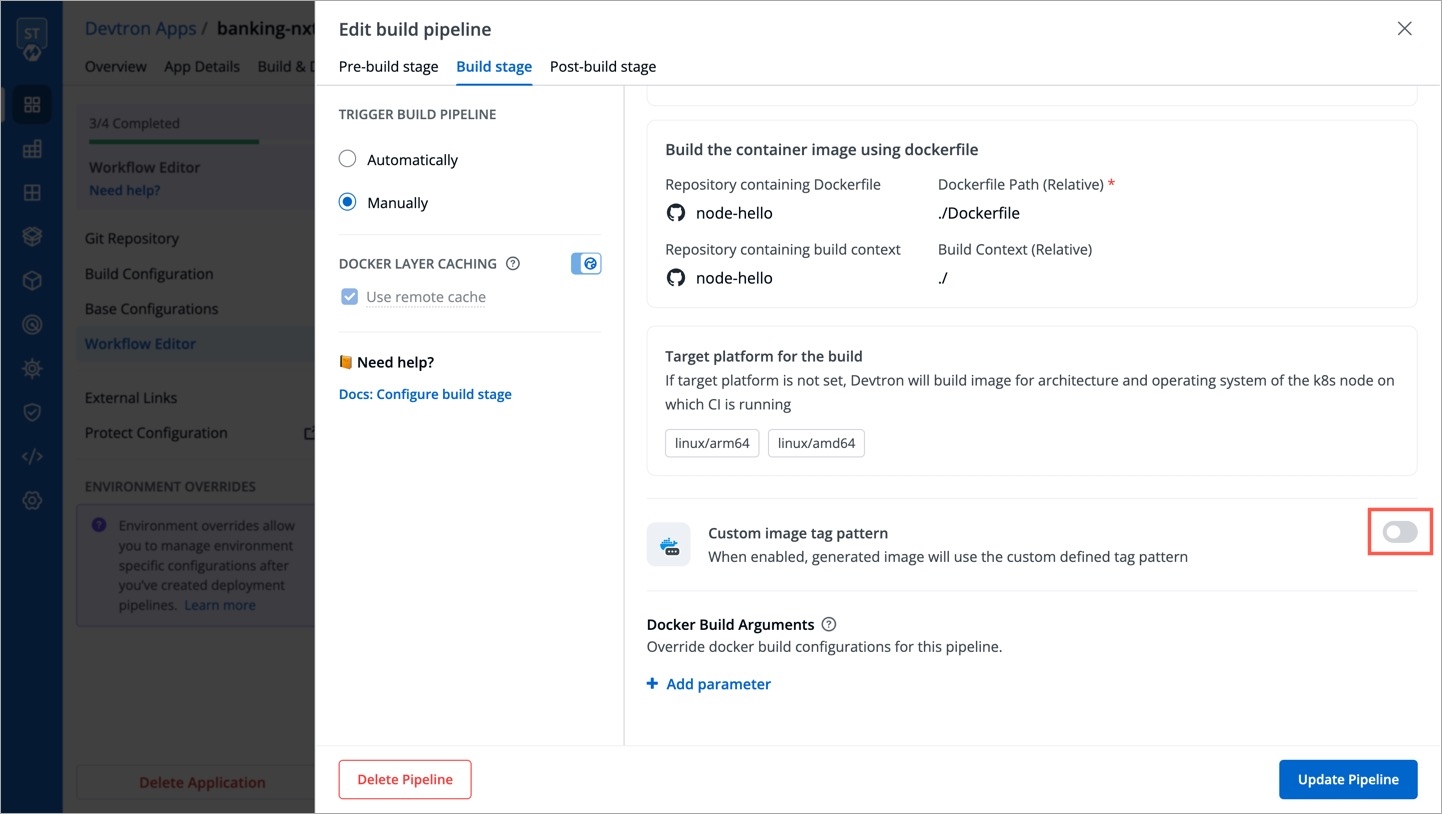
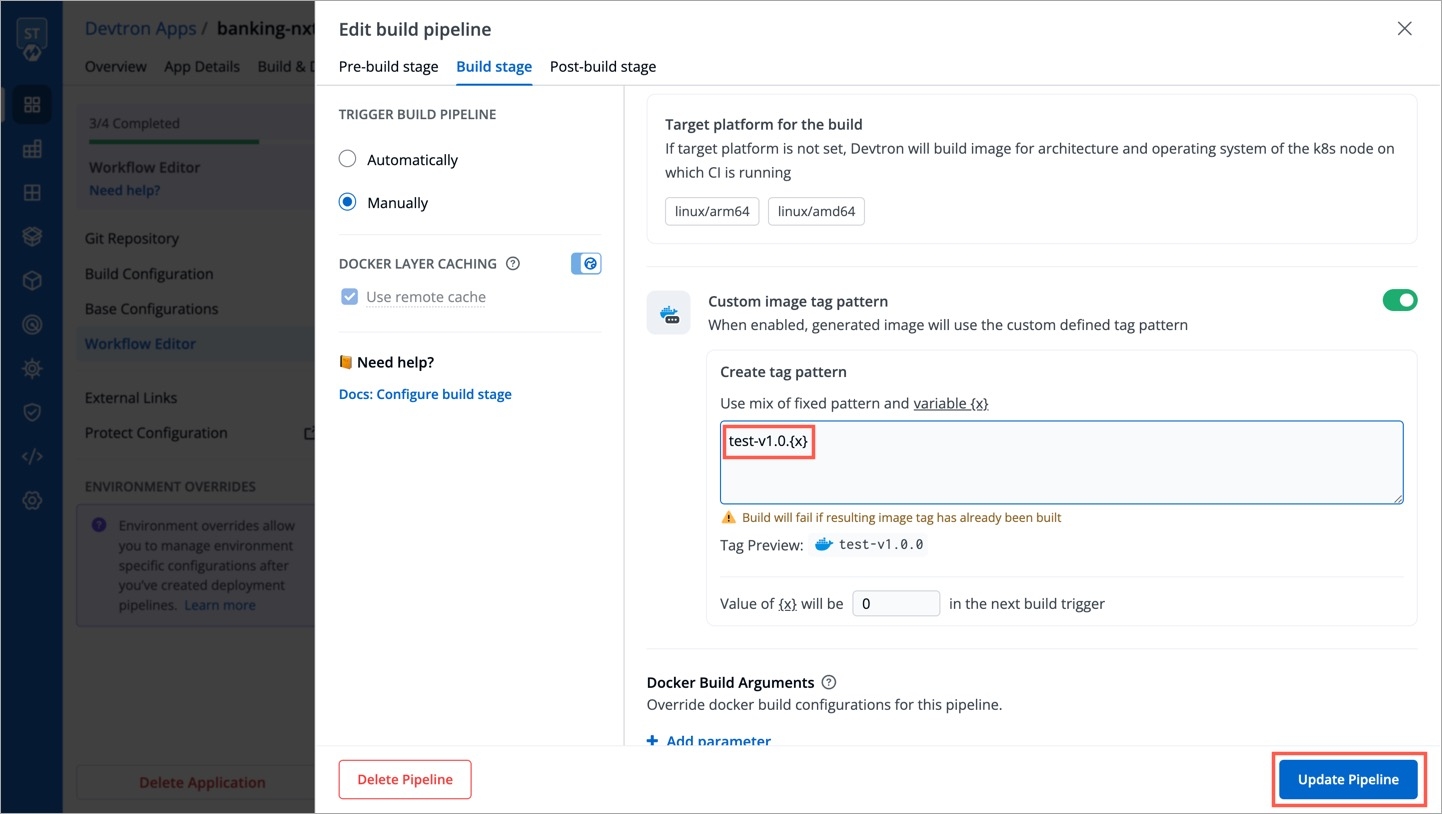
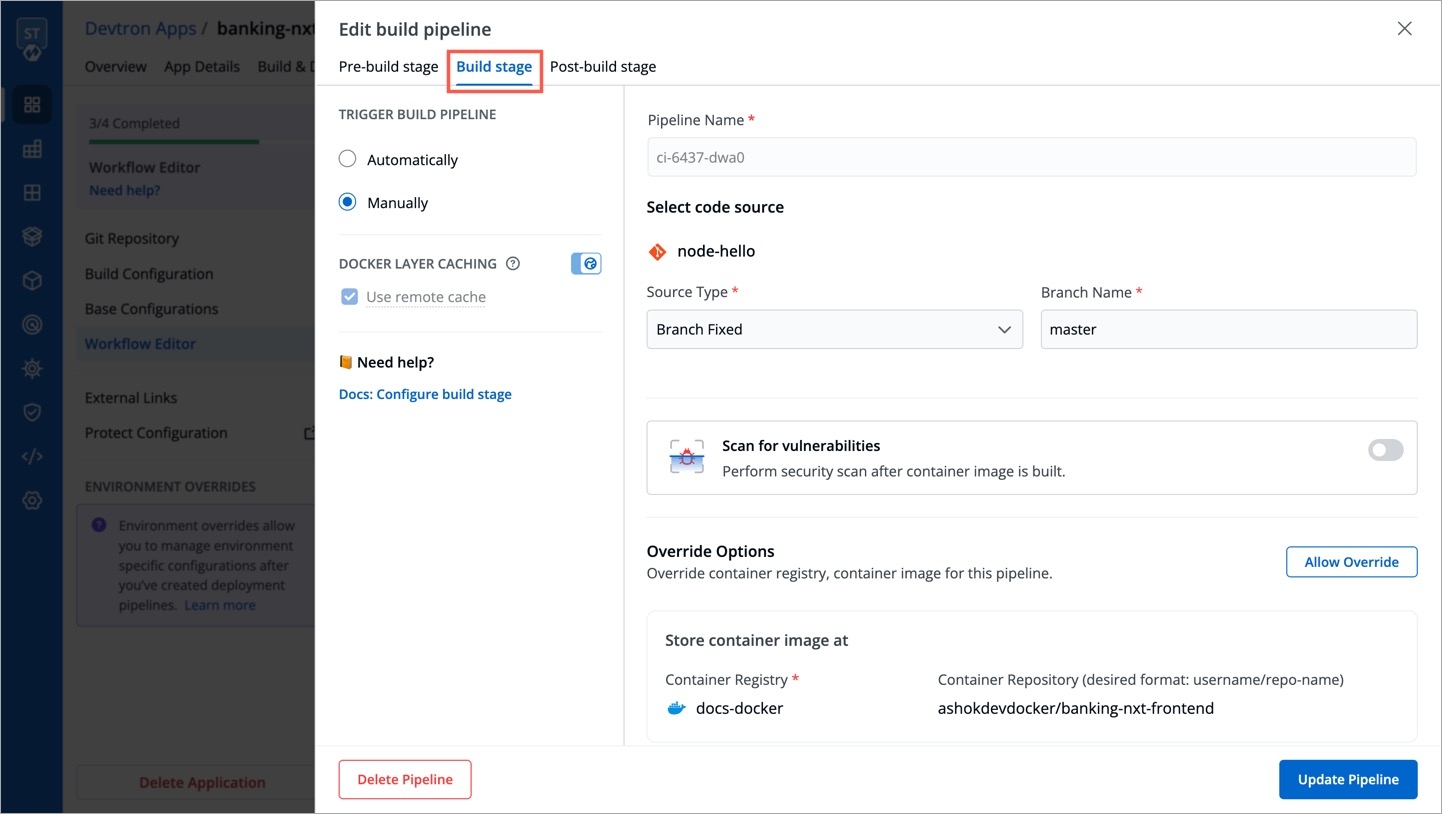
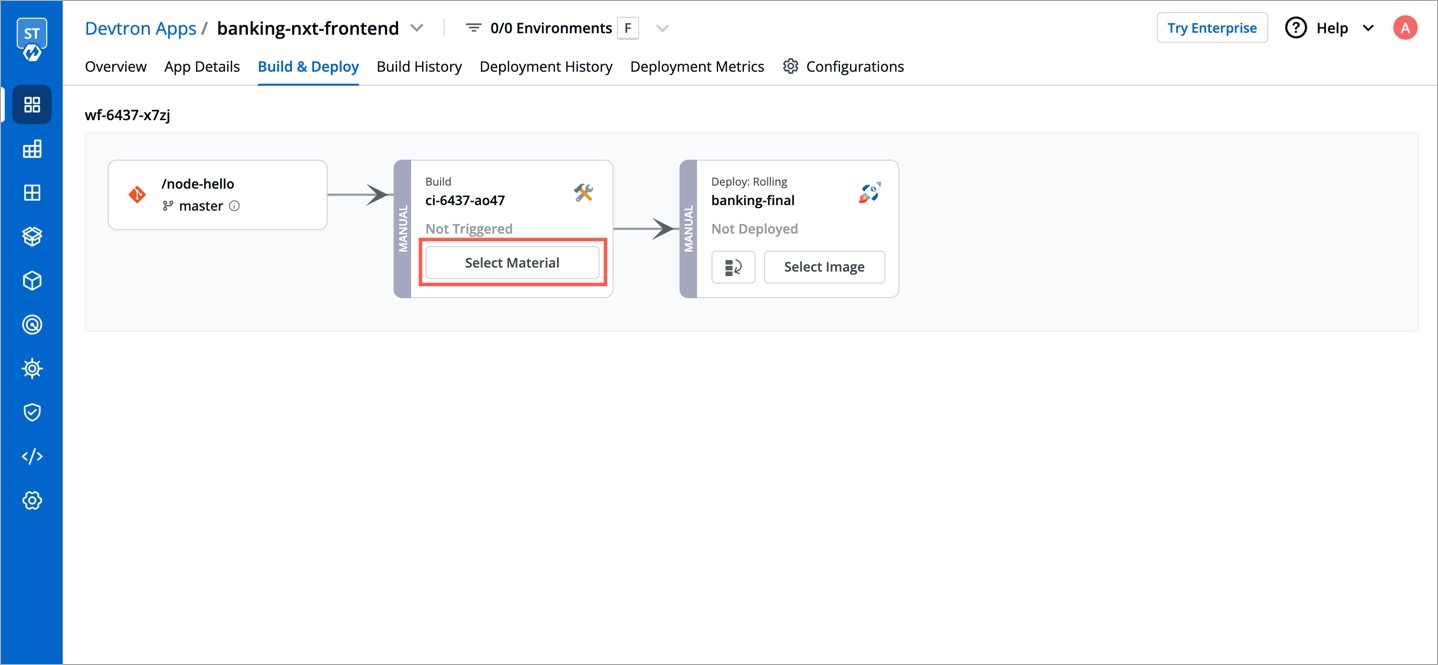
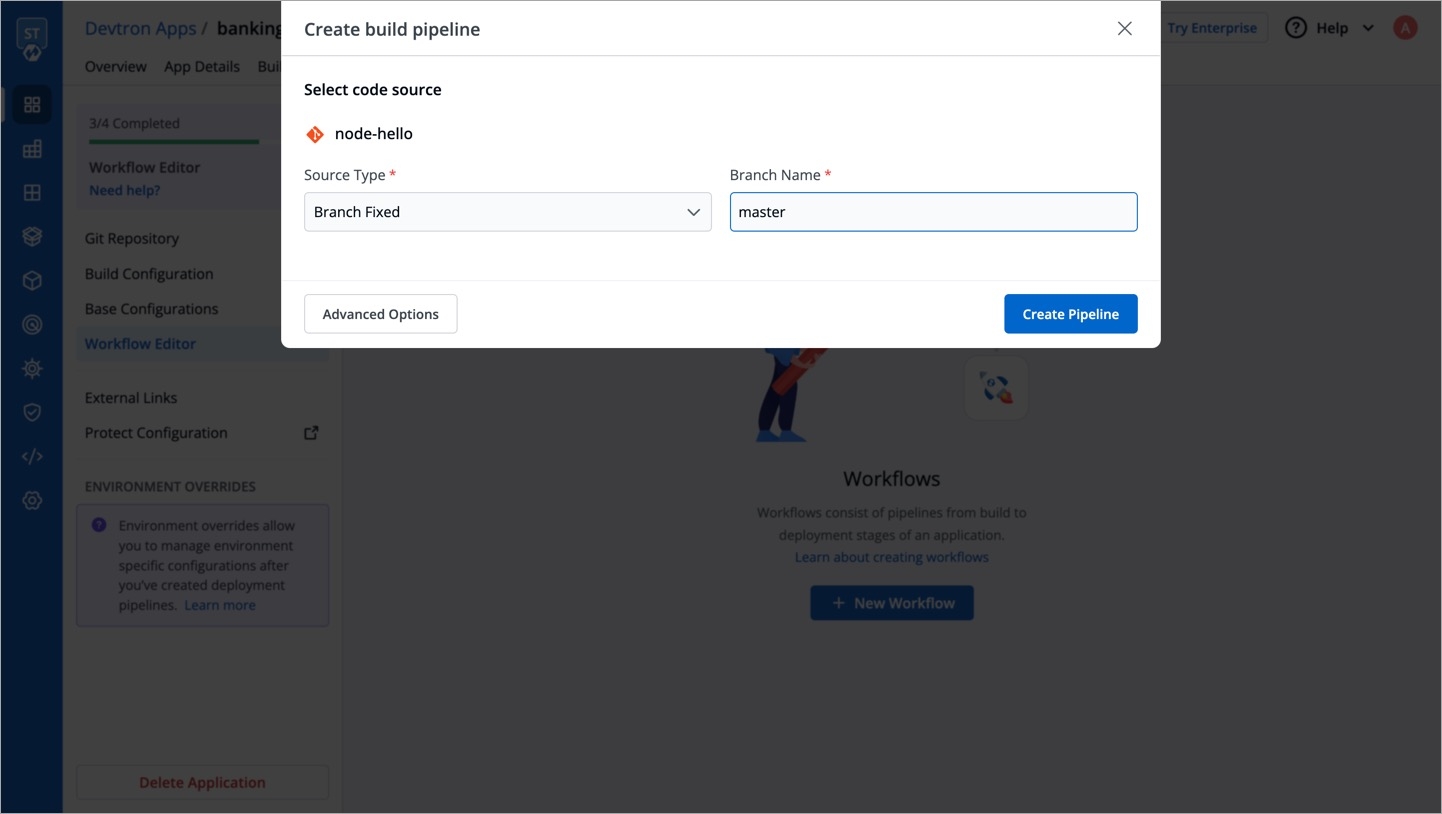
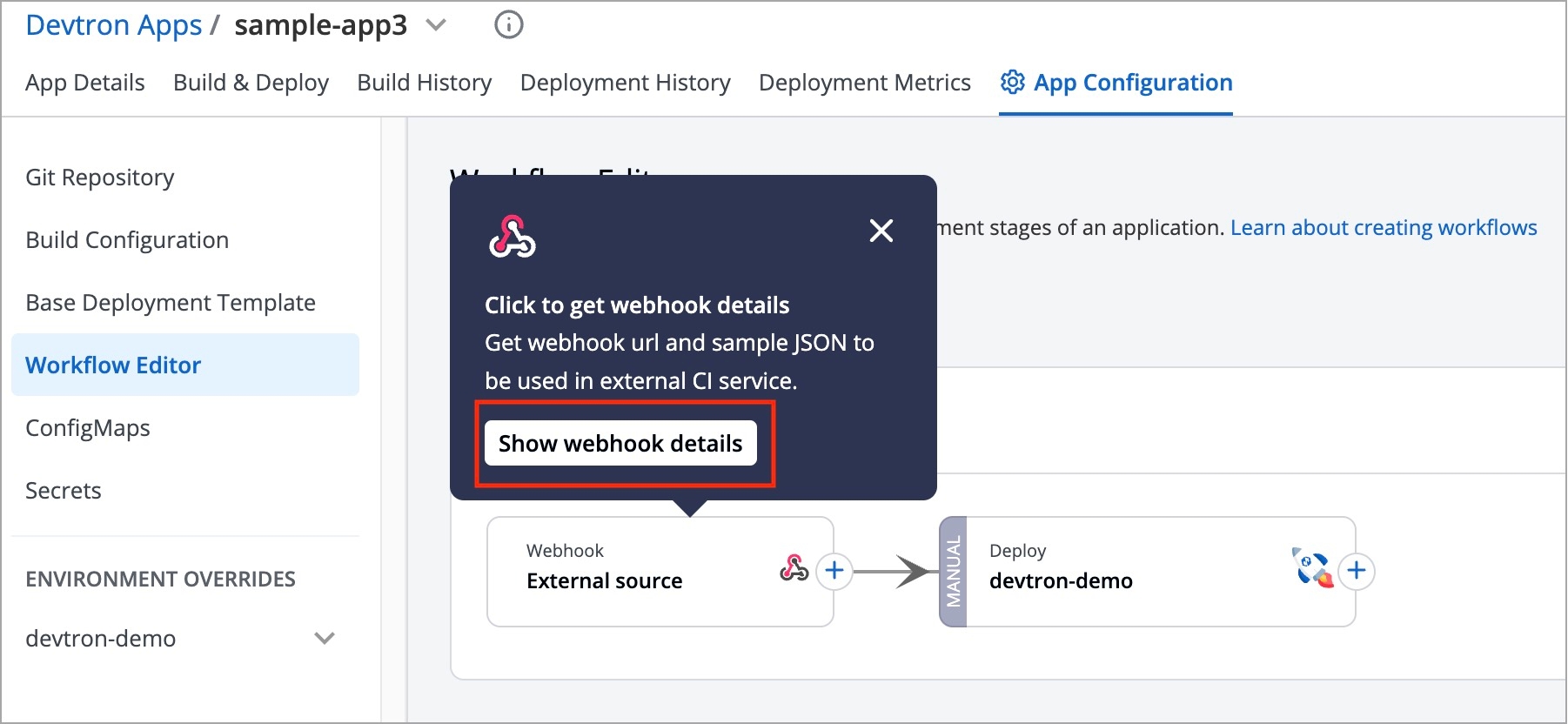
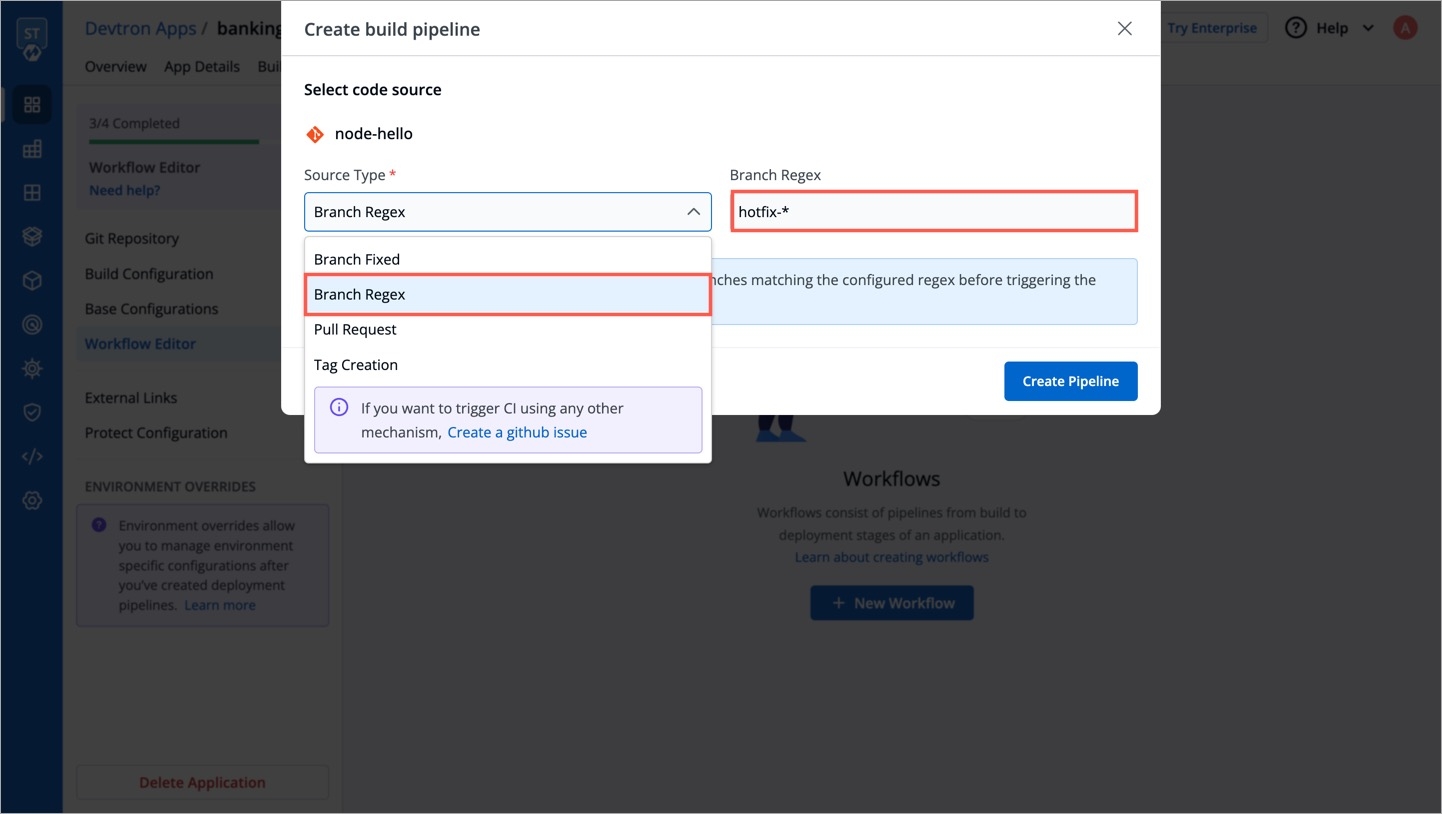
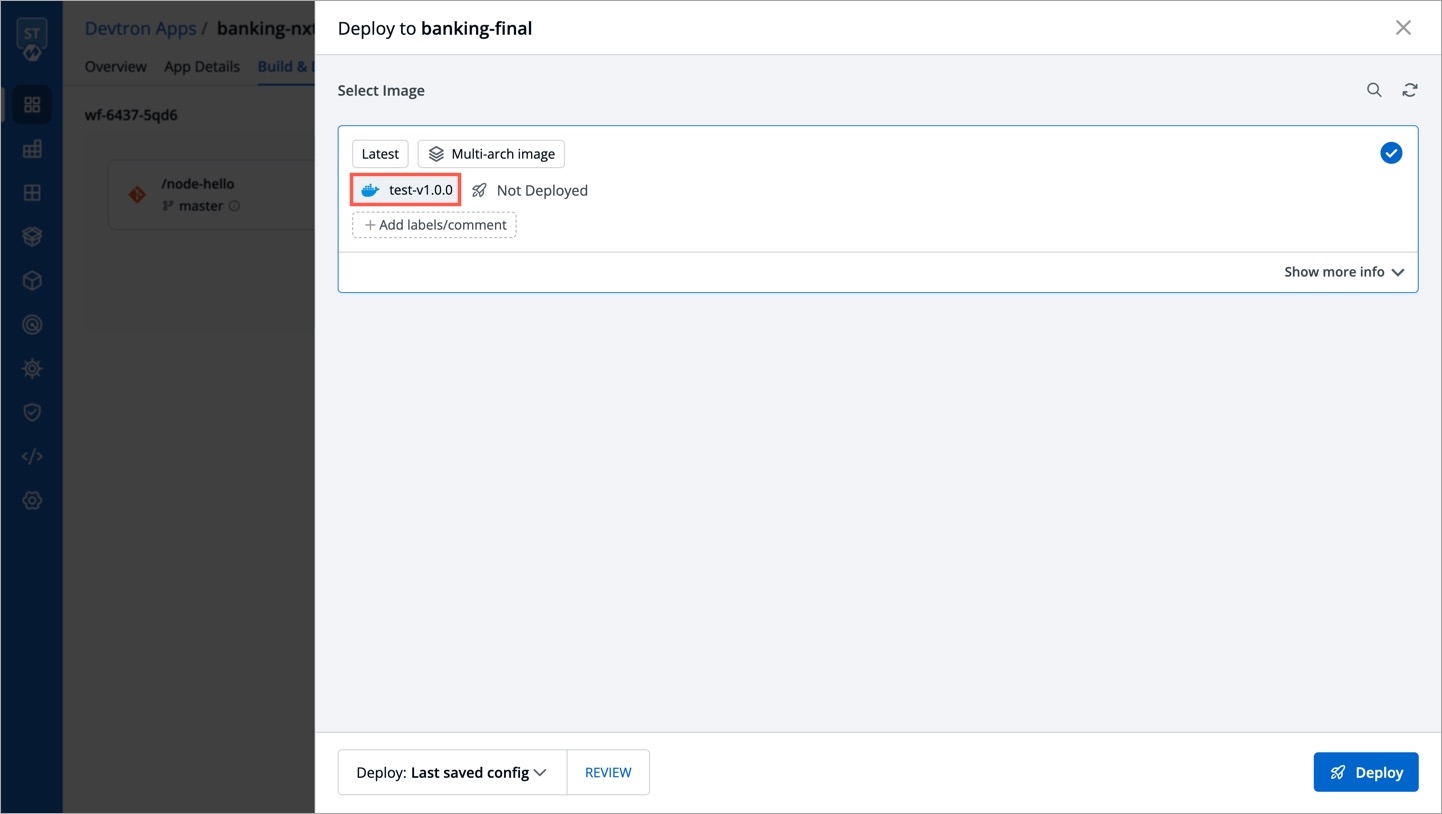
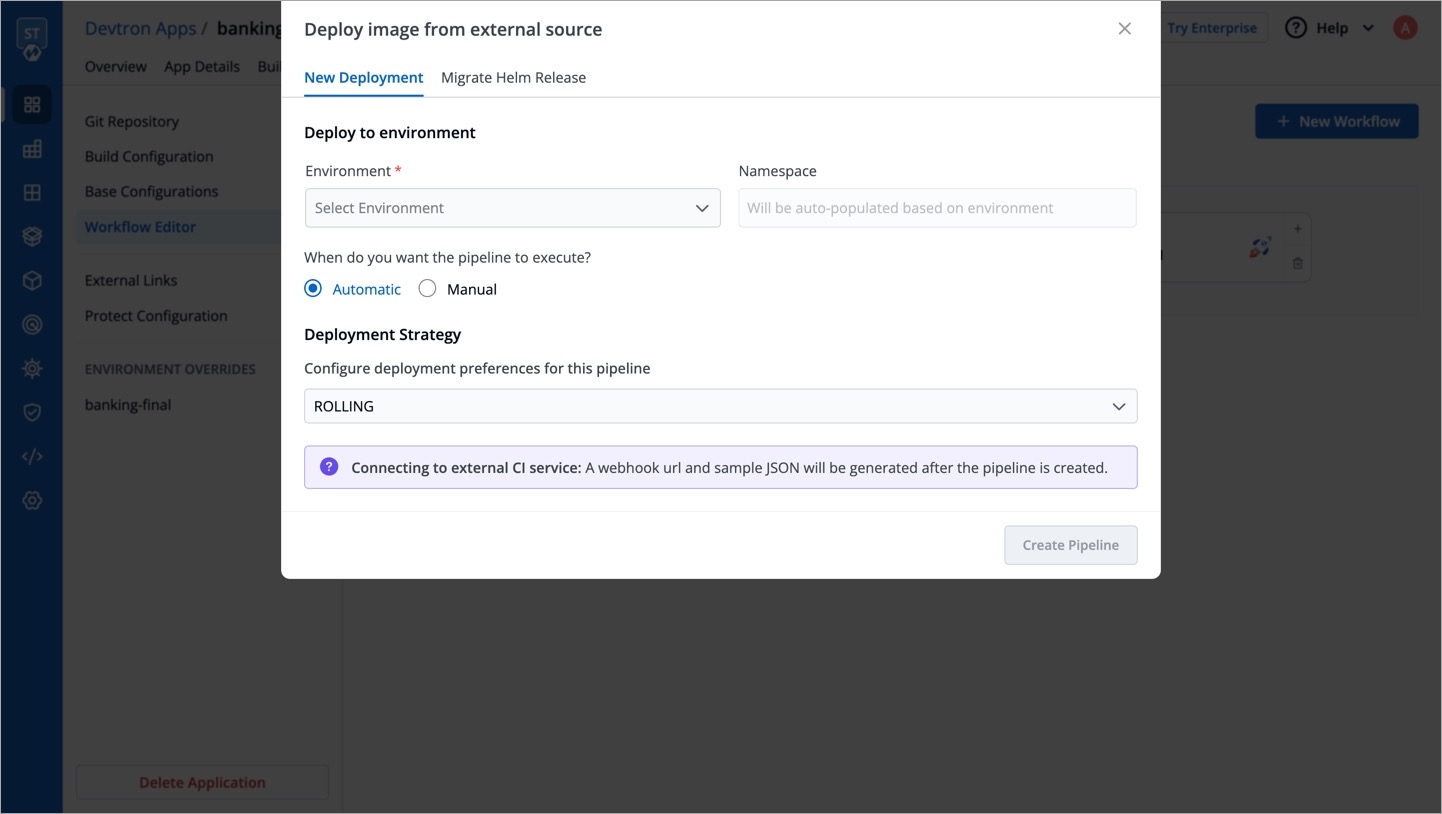
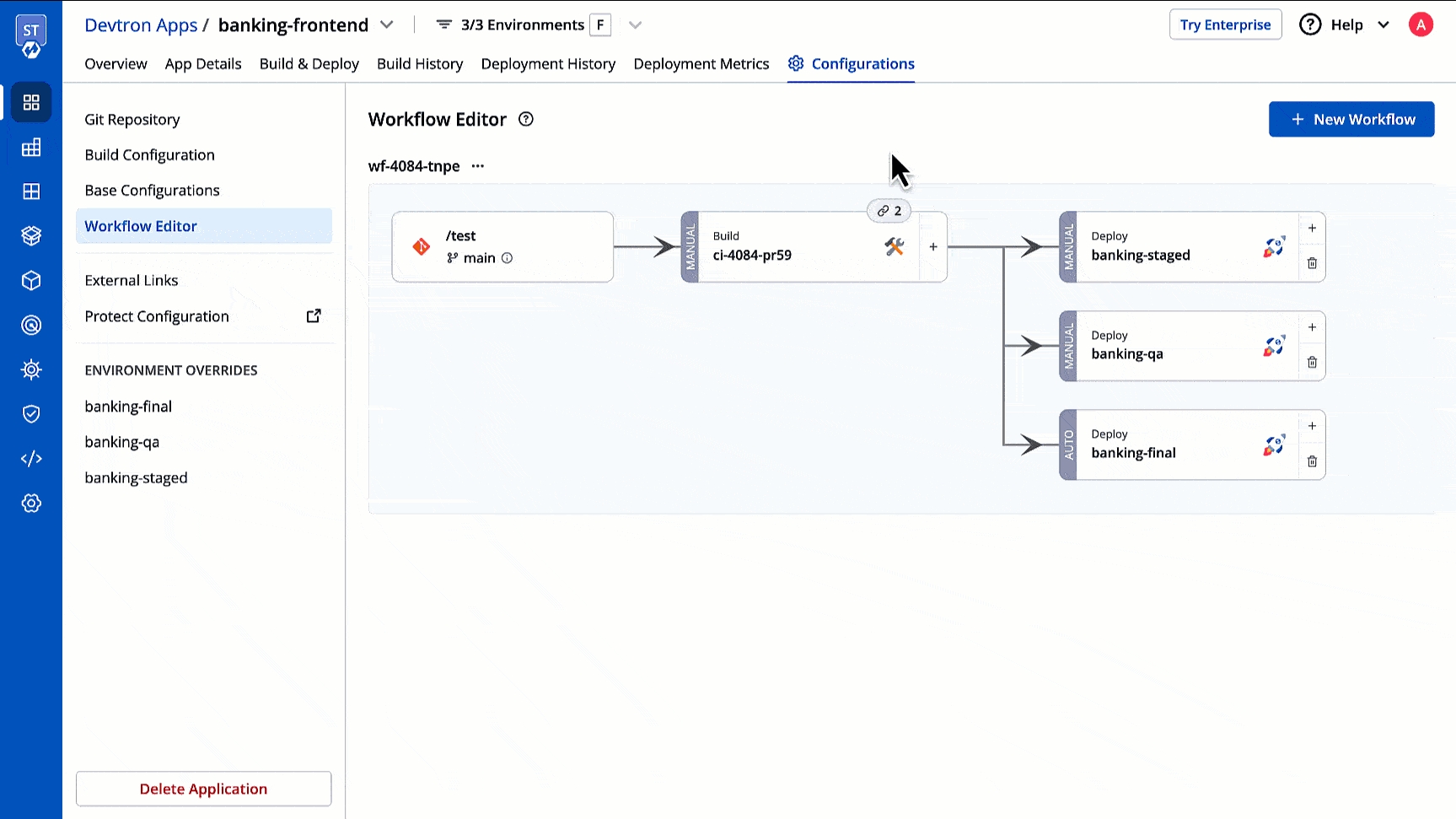
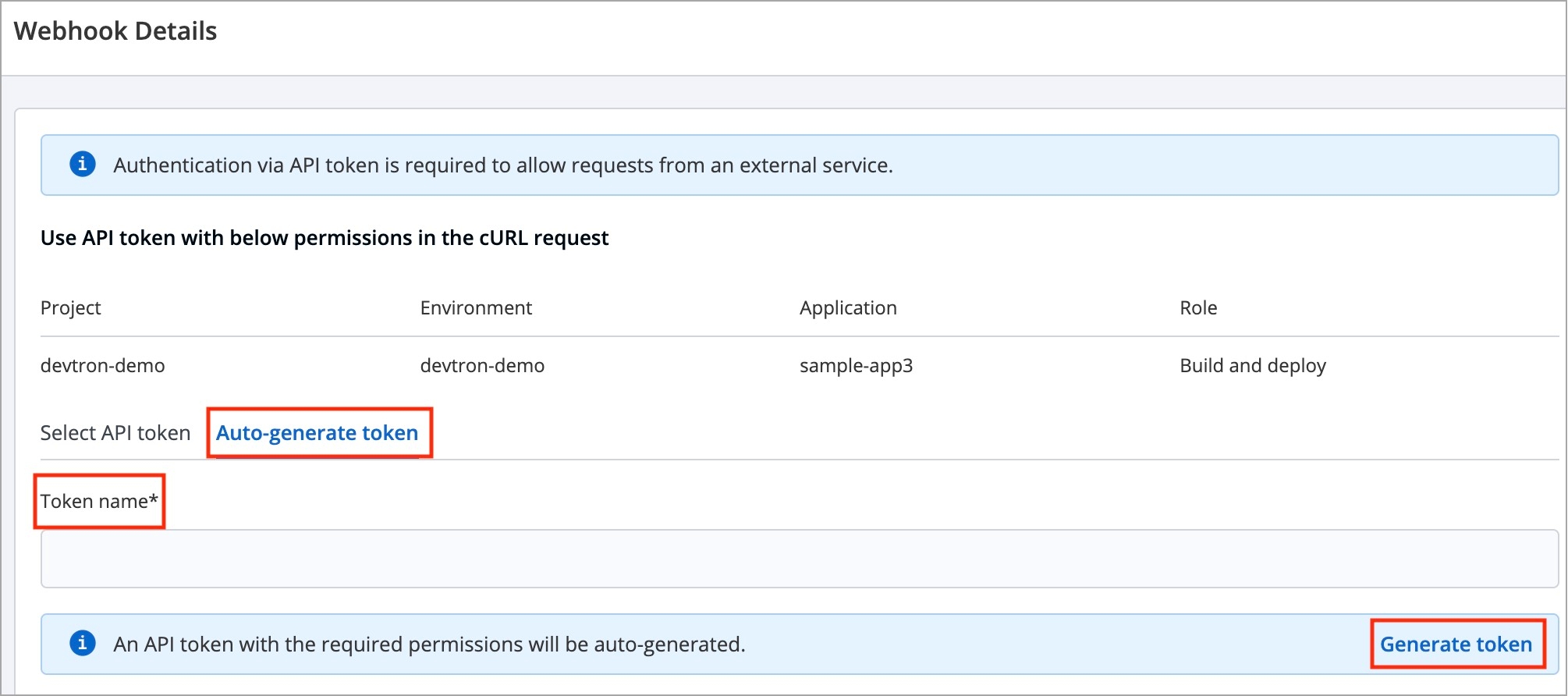
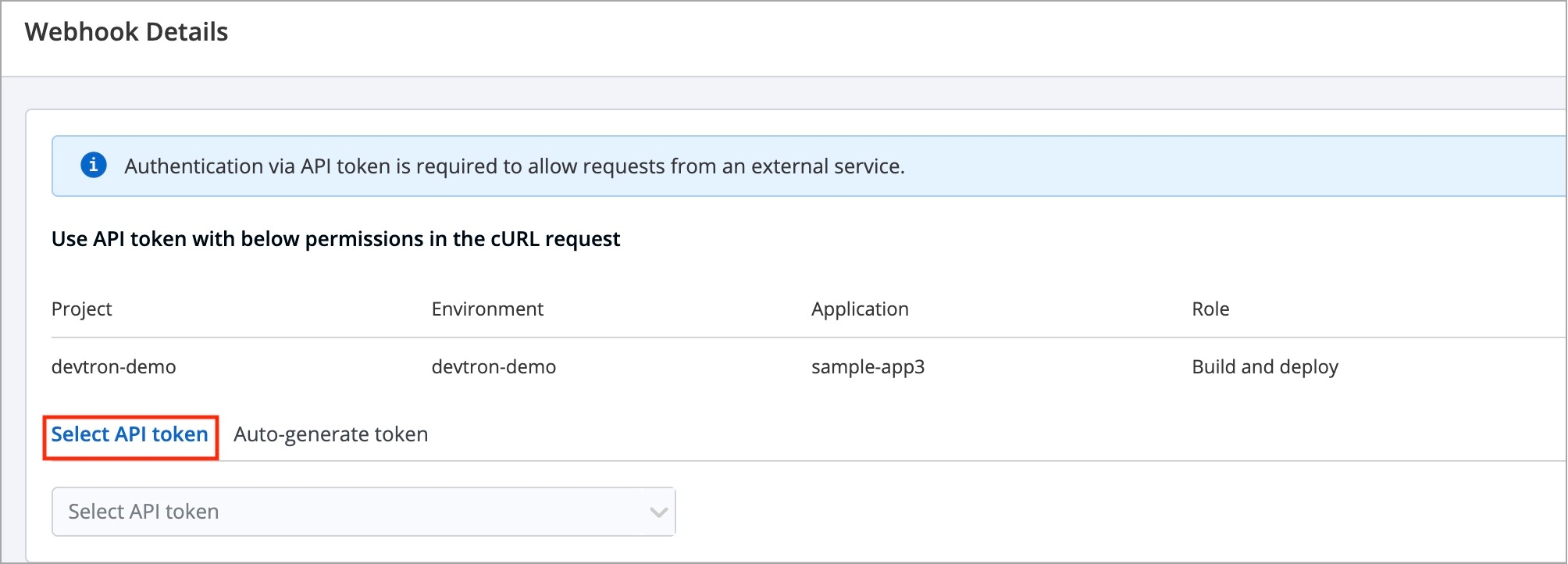
The StatefulSet chart in Devtron allows you to deploy and manage stateful applications. StatefulSet is a Kubernetes resource that provides guarantees about the ordering and uniqueness of Pods during deployment and scaling.
It supports only ONDELETE and ROLLINGUPDATE deployment strategy.
You can select StatefulSet chart when you want to use only basic use cases which contain the following:
Managing Stateful Applications: StatefulSets are ideal for managing stateful applications, such as databases or distributed systems, that require stable network identities and persistent storage for each Pod.
Ordered Pod Management: StatefulSets ensure ordered and predictable management of Pods by providing each Pod with a unique and stable hostname based on a defined naming convention and ordinal index.
Updating and Scaling Stateful Applications: StatefulSets support updating and scaling stateful applications by creating new versions of the StatefulSet and performing rolling updates or scaling operations in a controlled manner, ensuring minimal disruption to the application.
Persistent Storage: StatefulSets have built-in mechanisms for handling persistent volumes, allowing each Pod to have its own unique volume claim and storage. This ensures data persistence even when Pods are rescheduled or restarted.
Maintaining Pod Identity: StatefulSets guarantee consistent identity for each Pod throughout its lifecycle. This stability is maintained even if the Pods are rescheduled, allowing applications to rely on stable network identities.
Rollback Capability: StatefulSets provide the ability to rollback to a previous version in case the current state of the application is unstable or encounters issues, ensuring a known working state for the application.
Status Monitoring: StatefulSets offer status information that can be used to monitor the deployment, including the current version, number of replicas, and the readiness of each Pod. This helps in tracking the health and progress of the StatefulSet deployment.
Resource Cleanup: StatefulSets allow for easy cleanup of older versions by deleting StatefulSets and their associated Pods and persistent volumes that are no longer needed, ensuring efficient resource utilization.
Super-admins can lock keys in StatefulSet deployment template to prevent non-super-admins from modifying those locked keys. Refer Lock Deployment Configuration to know more.
This defines ports on which application services will be exposed to other services
ContainerPort:
- envoyPort: 8799
idleTimeout:
name: app
port: 8080
servicePort: 80
nodePort: 32056
supportStreaming: true
useHTTP2: trueenvoyPort
envoy port for the container.
idleTimeout
the duration of time that a connection is idle before the connection is terminated.
name
name of the port.
port
port for the container.
servicePort
port of the corresponding kubernetes service.
nodePort
nodeport of the corresponding kubernetes service.
supportStreaming
Used for high performance protocols like grpc where timeout needs to be disabled.
useHTTP2
Envoy container can accept HTTP2 requests.
EnvVariables: []EnvVariablesFromSecretKeys:
- name: ENV_NAME
secretName: SECRET_NAME
keyName: SECRET_KEY
It is used to get the name of Environment Variable name, Secret name and the Key name from which we are using the value in that corresponding Environment Variable.
EnvVariablesFromConfigMapKeys:
- name: ENV_NAME
configMapName: CONFIG_MAP_NAME
keyName: CONFIG_MAP_KEY
It is used to get the name of Environment Variable name, Config Map name and the Key name from which we are using the value in that corresponding Environment Variable.
To set environment variables for the containers that run in the Pod.
These are all the configuration settings for the StatefulSet.
statefulSetConfig:
labels:
app: my-statefulset
environment: production
annotations:
example.com/version: "1.0"
serviceName: "my-statefulset-service"
podManagementPolicy: "Parallel"
revisionHistoryLimit: 5
mountPath: "/data"
volumeClaimTemplates:
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
labels:
app: my-statefulset
spec:
accessModes:
- ReadWriteOnce
dataSource:
kind: Snapshot
apiGroup: snapshot.storage.k8s.io
name: my-snapshot
resources:
requests:
storage: 5Gi
limits:
storage: 10Gi
storageClassName: my-storage-class
selector:
matchLabels:
app: my-statefulset
volumeMode: Filesystem
volumeName: my-pv
- apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-logs
labels:
app: myapp
spec:
accessModes:
- ReadWriteMany
dataSourceRef:
kind: Secret
apiGroup: v1
name: my-secret
resources:
requests:
storage: 5Gi
storageClassName: my-storage-class
selector:
matchExpressions:
- {key: environment, operator: In, values: [production]}
volumeMode: Block
volumeName: my-pv
Mandatoryfields in statefulSetConfig is
statefulSetConfig:
mountPath: /tmp
volumeClaimTemplates:
- spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2GiHere is an explanation of each field in the statefulSetConfig :
labels
set of key-value pairs used to identify the StatefulSet .
annotations
A map of key-value pairs that are attached to the stateful set as metadata.
serviceName
The name of the Kubernetes Service that the StatefulSet should create.
podManagementPolicy
A policy that determines how Pods are created and deleted by the StatefulSet. In this case, the policy is set to "Parallel", which means that all Pods are created at once.
revisionHistoryLimit
The number of revisions that should be stored for each replica of the StatefulSet.
updateStrategy
The update strategy used by the StatefulSet when rolling out changes.
mountPath
The path where the volume should be mounted in the container.
volumeClaimTemplates: An array of volume claim templates that are used to create persistent volumes for the StatefulSet. Each volume claim template specifies the storage class, access mode, storage size, and other details of the persistent volume.
apiVersion
The API version of the PVC .
kind
The type of object that the PVC is.
metadata
Metadata that is attached to the resource being created.
labels
A set of key-value pairs used to label the object for identification and selection.
spec
The specification of the object, which defines its desired state and behavior.
accessModes
A list of access modes for the PersistentVolumeClaim, such as "ReadWriteOnce" or "ReadWriteMany".
dataSource
A data source used to populate the PersistentVolumeClaim, such as a Snapshot or a StorageClass.
kind
specifies the kind of the snapshot, in this case Snapshot.
apiGroup
specifies the API group of the snapshot API, in this case snapshot.storage.k8s.io.
name
specifies the name of the snapshot, in this case my-snapshot.
dataSourceRef
A reference to a data source used to create the persistent volume. In this case, it's a secret.
updateStrategy
The update strategy used by the StatefulSet when rolling out changes.
resources
The resource requests and limits for the PersistentVolumeClaim, which define the minimum and maximum amount of storage it can use.
requests
The amount of storage requested by the PersistentVolumeClaim.
limits
The maximum amount of storage that the PersistentVolumeClaim can use.
storageClassName
The name of the storage class to use for the persistent volume.
selector
The selector used to match a persistent volume to a persistent volume claim.
matchLabels
a map of key-value pairs to match the labels of the corresponding PersistentVolume.
matchExpressions
A set of requirements that the selected object must meet to be considered a match.
key
The key of the label or annotation to match.
operator
The operator used to compare the key-value pairs (in this case, "In" specifies a set membership test).
values
A list of values that the selected object's label or annotation must match.
volumeMode
The mode of the volume, either "Filesystem" or "Block".
volumeName
The name of the PersistentVolume that is created for the PersistentVolumeClaim.
If this check fails, kubernetes restarts the pod. This should return error code in case of non-recoverable error.
LivenessProbe:
Path: ""
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
failureThreshold: 3
httpHeaders:
- name: Custom-Header
value: abc
scheme: ""
tcp: truePath
It define the path where the liveness needs to be checked.
initialDelaySeconds
It defines the time to wait before a given container is checked for liveliness.
periodSeconds
It defines the time to check a given container for liveness.
successThreshold
It defines the number of successes required before a given container is said to fulfil the liveness probe.
timeoutSeconds
It defines the time for checking timeout.
failureThreshold
It defines the maximum number of failures that are acceptable before a given container is not considered as live.
httpHeaders
Custom headers to set in the request. HTTP allows repeated headers,You can override the default headers by defining .httpHeaders for the probe.
scheme
Scheme to use for connecting to the host (HTTP or HTTPS). Defaults to HTTP.
tcp
The kubelet will attempt to open a socket to your container on the specified port. If it can establish a connection, the container is considered healthy.
MaxUnavailable: 0The maximum number of pods that can be unavailable during the update process. The value of "MaxUnavailable: " can be an absolute number or percentage of the replicas count. The default value of "MaxUnavailable: " is 25%.
MaxSurge: 1The maximum number of pods that can be created over the desired number of pods. For "MaxSurge: " also, the value can be an absolute number or percentage of the replicas count. The default value of "MaxSurge: " is 25%.
MinReadySeconds: 60This specifies the minimum number of seconds for which a newly created Pod should be ready without any of its containers crashing, for it to be considered available. This defaults to 0 (the Pod will be considered available as soon as it is ready).
If this check fails, kubernetes stops sending traffic to the application. This should return error code in case of errors which can be recovered from if traffic is stopped.
ReadinessProbe:
Path: ""
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
failureThreshold: 3
httpHeaders:
- name: Custom-Header
value: abc
scheme: ""
tcp: truePath
It define the path where the readiness needs to be checked.
initialDelaySeconds
It defines the time to wait before a given container is checked for readiness.
periodSeconds
It defines the time to check a given container for readiness.
successThreshold
It defines the number of successes required before a given container is said to fulfill the readiness probe.
timeoutSeconds
It defines the time for checking timeout.
failureThreshold
It defines the maximum number of failures that are acceptable before a given container is not considered as ready.
httpHeaders
Custom headers to set in the request. HTTP allows repeated headers,You can override the default headers by defining .httpHeaders for the probe.
scheme
Scheme to use for connecting to the host (HTTP or HTTPS). Defaults to HTTP.
tcp
The kubelet will attempt to open a socket to your container on the specified port. If it can establish a connection, the container is considered healthy.
You can create ambassador mappings to access your applications from outside the cluster. At its core a Mapping resource maps a resource to a service.
ambassadorMapping:
ambassadorId: "prod-emissary"
cors: {}
enabled: true
hostname: devtron.example.com
labels: {}
prefix: /
retryPolicy: {}
rewrite: ""
tls:
context: "devtron-tls-context"
create: false
hosts: []
secretName: ""enabled
Set true to enable ambassador mapping else set false.
ambassadorId
used to specify id for specific ambassador mappings controller.
cors
used to specify cors policy to access host for this mapping.
weight
used to specify weight for canary ambassador mappings.
hostname
used to specify hostname for ambassador mapping.
prefix
used to specify path for ambassador mapping.
labels
used to provide custom labels for ambassador mapping.
retryPolicy
used to specify retry policy for ambassador mapping.
corsPolicy
Provide cors headers on flagger resource.
rewrite
used to specify whether to redirect the path of this mapping and where.
tls
used to create or define ambassador TLSContext resource.
extraSpec
used to provide extra spec values which not present in deployment template for ambassador resource.
This is connected to HPA and controls scaling up and down in response to request load.
autoscaling:
enabled: false
MinReplicas: 1
MaxReplicas: 2
TargetCPUUtilizationPercentage: 90
TargetMemoryUtilizationPercentage: 80
extraMetrics: []enabled
Set true to enable autoscaling else set false.
MinReplicas
Minimum number of replicas allowed for scaling.
MaxReplicas
Maximum number of replicas allowed for scaling.
TargetCPUUtilizationPercentage
The target CPU utilization that is expected for a container.
TargetMemoryUtilizationPercentage
The target memory utilization that is expected for a container.
extraMetrics
Used to give external metrics for autoscaling.
fullnameOverride: app-namefullnameOverride replaces the release fullname created by default by devtron, which is used to construct Kubernetes object names. By default, devtron uses {app-name}-{environment-name} as release fullname.
image:
pullPolicy: IfNotPresentImage is used to access images in kubernetes, pullpolicy is used to define the instances calling the image, here the image is pulled when the image is not present,it can also be set as "Always".
imagePullSecrets contains the docker credentials that are used for accessing a registry.
imagePullSecrets:
- regcredregcred is the secret that contains the docker credentials that are used for accessing a registry. Devtron will not create this secret automatically, you'll have to create this secret using dt-secrets helm chart in the App store or create one using kubectl. You can follow this documentation Pull an Image from a Private Registry https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/ .
This allows public access to the url, please ensure you are using right nginx annotation for nginx class, its default value is nginx
ingress:
enabled: false
# For K8s 1.19 and above use ingressClassName instead of annotation kubernetes.io/ingress.class:
className: nginx
annotations: {}
hosts:
- host: example1.com
paths:
- /example
- host: example2.com
paths:
- /example2
- /example2/healthz
tls: []Legacy deployment-template ingress format
ingress:
enabled: false
# For K8s 1.19 and above use ingressClassName instead of annotation kubernetes.io/ingress.class:
ingressClassName: nginx-internal
annotations: {}
path: ""
host: ""
tls: []enabled
Enable or disable ingress
annotations
To configure some options depending on the Ingress controller
path
Path name
host
Host name
tls
It contains security details
This allows private access to the url, please ensure you are using right nginx annotation for nginx class, its default value is nginx
ingressInternal:
enabled: false
# For K8s 1.19 and above use ingressClassName instead of annotation kubernetes.io/ingress.class:
ingressClassName: nginx-internal
annotations: {}
hosts:
- host: example1.com
paths:
- /example
- host: example2.com
paths:
- /example2
- /example2/healthz
tls: []enabled
Enable or disable ingress
annotations
To configure some options depending on the Ingress controller
path
Path name
host
Host name
tls
It contains security details
initContainers:
- reuseContainerImage: true
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
volumeMounts:
- mountPath: /etc/ls-oms
name: ls-oms-cm-vol
command:
- flyway
- -configFiles=/etc/ls-oms/flyway.conf
- migrate
- name: nginx
image: nginx:1.14.2
securityContext:
privileged: true
ports:
- containerPort: 80
command: ["/usr/local/bin/nginx"]
args: ["-g", "daemon off;"]Specialized containers that run before app containers in a Pod. Init containers can contain utilities or setup scripts not present in an app image. One can use base image inside initContainer by setting the reuseContainerImage flag to true.
Istio is a service mesh which simplifies observability, traffic management, security and much more with it's virtual services and gateways.
istio:
enable: true
gateway:
annotations: {}
enabled: false
host: example.com
labels: {}
tls:
enabled: false
secretName: example-tls-secret
virtualService:
annotations: {}
enabled: false
gateways: []
hosts: []
http:
- corsPolicy:
allowCredentials: false
allowHeaders:
- x-some-header
allowMethods:
- GET
allowOrigin:
- example.com
maxAge: 24h
headers:
request:
add:
x-some-header: value
match:
- uri:
prefix: /v1
- uri:
prefix: /v2
retries:
attempts: 2
perTryTimeout: 3s
rewriteUri: /
route:
- destination:
host: service1
port: 80
timeout: 12s
- route:
- destination:
host: service2
labels: {}istio
Istio enablement. When istio.enable set to true, Istio would be enabled for the specified configurations
gateway
Allowing external traffic to enter the service mesh through the specified configurations.
host
The external domain through which traffic will be routed into the service mesh.
tls
Traffic to and from the gateway should be encrypted using TLS.
secretName
Specifies the name of the Kubernetes secret that contains the TLS certificate and private key. The TLS certificate is used for securing the communication between clients and the Istio gateway.
virtualService
Enables the definition of rules for how traffic should be routed to different services within the service mesh.
gateways
Specifies the gateways to which the rules defined in the VirtualService apply.
hosts
List of hosts (domains) to which this VirtualService is applied.
http
Configuration for HTTP routes within the VirtualService. It define routing rules based on HTTP attributes such as URI prefixes, headers, timeouts, and retry policies.
corsPolicy
Cross-Origin Resource Sharing (CORS) policy configuration.
headers
Additional headers to be added to the HTTP request.
match
Conditions that need to be satisfied for this route to be used.
uri
This specifies a match condition based on the URI of the incoming request.
prefix
It specifies that the URI should have the specified prefix.
retries
Retry configuration for failed requests.
attempts
It specifies the number of retry attempts for failed requests.
perTryTimeout
sets the timeout for each individual retry attempt.
rewriteUri
Rewrites the URI of the incoming request.
route
List of destination rules for routing traffic.
pauseForSecondsBeforeSwitchActive: 30To wait for given period of time before switch active the container.
These define minimum and maximum RAM and CPU available to the application.
resources:
limits:
cpu: "1"
memory: "200Mi"
requests:
cpu: "0.10"
memory: "100Mi"Resources are required to set CPU and memory usage.
Limits make sure a container never goes above a certain value. The container is only allowed to go up to the limit, and then it is restricted.
Requests are what the container is guaranteed to get.
This defines annotations and the type of service, optionally can define name also.
service:
type: ClusterIP
annotations: {}volumes:
- name: log-volume
emptyDir: {}
- name: logpv
persistentVolumeClaim:
claimName: logpvcIt is required when some values need to be read from or written to an external disk.
volumeMounts:
- mountPath: /var/log/nginx/
name: log-volume
- mountPath: /mnt/logs
name: logpvc
subPath: employee It is used to provide mounts to the volume.
Spec:
Affinity:
Key:
Values:Spec is used to define the desire state of the given container.
Node Affinity allows you to constrain which nodes your pod is eligible to schedule on, based on labels of the node.
Inter-pod affinity allow you to constrain which nodes your pod is eligible to be scheduled based on labels on pods.
Key part of the label for node selection, this should be same as that on node. Please confirm with devops team.
Value part of the label for node selection, this should be same as that on node. Please confirm with devops team.
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule|PreferNoSchedule|NoExecute(1.6 only)"Taints are the opposite, they allow a node to repel a set of pods.
A given pod can access the given node and avoid the given taint only if the given pod satisfies a given taint.
Taints and tolerations are a mechanism which work together that allows you to ensure that pods are not placed on inappropriate nodes. Taints are added to nodes, while tolerations are defined in the pod specification. When you taint a node, it will repel all the pods except those that have a toleration for that taint. A node can have one or many taints associated with it.
args:
enabled: false
value: []This is used to give arguments to command.
command:
enabled: false
value: []It contains the commands for the server.
enabled
To enable or disable the command.
value
It contains the commands.
Containers section can be used to run side-car containers along with your main container within same pod. Containers running within same pod can share volumes and IP Address and can address each other @localhost. We can use base image inside container by setting the reuseContainerImage flag to true.
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
command: ["/usr/local/bin/nginx"]
args: ["-g", "daemon off;"]
- reuseContainerImage: true
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
volumeMounts:
- mountPath: /etc/ls-oms
name: ls-oms-cm-vol
command:
- flyway
- -configFiles=/etc/ls-oms/flyway.conf
- migrate prometheus:
release: monitoringIt is a kubernetes monitoring tool and the name of the file to be monitored as monitoring in the given case.It describes the state of the prometheus.
rawYaml:
- apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
type: ClusterIPAccepts an array of Kubernetes objects. You can specify any kubernetes yaml here and it will be applied when your app gets deployed.
GracePeriod: 30Kubernetes waits for the specified time called the termination grace period before terminating the pods. By default, this is 30 seconds. If your pod usually takes longer than 30 seconds to shut down gracefully, make sure you increase the GracePeriod.
A Graceful termination in practice means that your application needs to handle the SIGTERM message and begin shutting down when it receives it. This means saving all data that needs to be saved, closing down network connections, finishing any work that is left, and other similar tasks.
There are many reasons why Kubernetes might terminate a perfectly healthy container. If you update your deployment with a rolling update, Kubernetes slowly terminates old pods while spinning up new ones. If you drain a node, Kubernetes terminates all pods on that node. If a node runs out of resources, Kubernetes terminates pods to free those resources. It’s important that your application handle termination gracefully so that there is minimal impact on the end user and the time-to-recovery is as fast as possible.
server:
deployment:
image_tag: 1-95a53
image: ""It is used for providing server configurations.
It gives the details for deployment.
image_tag
It is the image tag
image
It is the URL of the image
servicemonitor:
enabled: true
path: /abc
scheme: 'http'
interval: 30s
scrapeTimeout: 20s
metricRelabelings:
- sourceLabels: [namespace]
regex: '(.*)'
replacement: myapp
targetLabel: target_namespaceIt gives the set of targets to be monitored.
dbMigrationConfig:
enabled: falseIt is used to configure database migration.
KEDA is a Kubernetes-based Event Driven Autoscaler. With KEDA, you can drive the scaling of any container in Kubernetes based on the number of events needing to be processed. KEDA can be installed into any Kubernetes cluster and can work alongside standard Kubernetes components like the Horizontal Pod Autoscaler(HPA).
Example for autosccaling with KEDA using Prometheus metrics is given below:
kedaAutoscaling:
enabled: true
minReplicaCount: 1
maxReplicaCount: 2
idleReplicaCount: 0
pollingInterval: 30
advanced:
restoreToOriginalReplicaCount: true
horizontalPodAutoscalerConfig:
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
- type: prometheus
metadata:
serverAddress: http://<prometheus-host>:9090
metricName: http_request_total
query: envoy_cluster_upstream_rq{appId="300", cluster_name="300-0", container="envoy",}
threshold: "50"
triggerAuthentication:
enabled: false
name:
spec: {}
authenticationRef: {}Example for autosccaling with KEDA based on kafka is given below :
kedaAutoscaling:
enabled: true
minReplicaCount: 1
maxReplicaCount: 2
idleReplicaCount: 0
pollingInterval: 30
advanced: {}
triggers:
- type: kafka
metadata:
bootstrapServers: b-2.kafka-msk-dev.example.c2.kafka.ap-southeast-1.amazonaws.com:9092,b-3.kafka-msk-dev.example.c2.kafka.ap-southeast-1.amazonaws.com:9092,b-1.kafka-msk-dev.example.c2.kafka.ap-southeast-1.amazonaws.com:9092
topic: Orders-Service-ESP.info
lagThreshold: "100"
consumerGroup: oders-remove-delivered-packages
allowIdleConsumers: "true"
triggerAuthentication:
enabled: true
name: keda-trigger-auth-kafka-credential
spec:
secretTargetRef:
- parameter: sasl
name: keda-kafka-secrets
key: sasl
- parameter: username
name: keda-kafka-secrets
key: username
authenticationRef:
name: keda-trigger-auth-kafka-credentialWinter Soldier can be used to
cleans up (delete) Kubernetes resources
reduce workload pods to 0
NOTE: After deploying this we can create the Hibernator object and provide the custom configuration by which workloads going to delete, sleep and many more. for more information check the main repo
Given below is template values you can give in winter-soldier:
winterSoilder:
enable: false
apiVersion: pincher.devtron.ai/v1alpha1
action: sleep
timeRangesWithZone:
timeZone: "Asia/Kolkata"
timeRanges: []
targetReplicas: []
fieldSelector: []Here,
enable
false,true
decide the enabling factor
apiVersion
pincher.devtron.ai/v1beta1, pincher.devtron.ai/v1alpha1
specific api version
action
sleep,delete, scale
This specify the action need to perform.
timeRangesWithZone:timeZone
eg:- "Asia/Kolkata","US/Pacific"
It use to specify the timeZone used. (It uses standard format. please refer )
timeRangesWithZone:timeRanges
array of [ timeFrom, timeTo, weekdayFrom, weekdayTo]
It use to define time period/range on which the user need to perform the specified action. you can have multiple timeRanges.
These settings will take action on Sat and Sun from 00:00 to 23:59:59,
targetReplicas
[n] : n - number of replicas to scale.
These is mandatory field when the action is scale
Default value is [].
fieldSelector
- AfterTime(AddTime( ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z'), '5m'), Now())
These value will take a list of methods to select the resources on which we perform specified action .
here is an example,
winterSoilder:
apiVersion: pincher.devtron.ai/v1alpha1
enable: true
annotations: {}
labels: {}
timeRangesWithZone:
timeZone: "Asia/Kolkata"
timeRanges:
- timeFrom: 00:00
timeTo: 23:59:59
weekdayFrom: Sat
weekdayTo: Sun
- timeFrom: 00:00
timeTo: 08:00
weekdayFrom: Mon
weekdayTo: Fri
- timeFrom: 20:00
timeTo: 23:59:59
weekdayFrom: Mon
weekdayTo: Fri
action: scale
targetReplicas: [1,1,1]
fieldSelector:
- AfterTime(AddTime( ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z'), '10h'), Now())Above settings will take action on Sat and Sun from 00:00 to 23:59:59, and on Mon-Fri from 00:00 to 08:00 and 20:00 to 23:59:59. If action:sleep then runs hibernate at timeFrom and unhibernate at timeTo. If action: delete then it will delete workloads at timeFrom and timeTo. Here the action:scale thus it scale the number of resource replicas to targetReplicas: [1,1,1]. Here each element of targetReplicas array is mapped with the corresponding elements of array timeRangesWithZone/timeRanges. Thus make sure the length of both array is equal, otherwise the cnages cannot be observed.
The above example will select the application objects which have been created 10 hours ago across all namespaces excluding application's namespace. Winter soldier exposes following functions to handle time, cpu and memory.
ParseTime - This function can be used to parse time. For eg to parse creationTimestamp use ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z')
AddTime - This can be used to add time. For eg AddTime(ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z'), '-10h') ll add 10h to the time. Use d for day, h for hour, m for minutes and s for seconds. Use negative number to get earlier time.
Now - This can be used to get current time.
CpuToNumber - This can be used to compare CPU. For eg any({{spec.containers.#.resources.requests}}, { MemoryToNumber(.memory) < MemoryToNumber('60Mi')}) will check if any resource.requests is less than 60Mi.
A security context defines privilege and access control settings for a Pod or Container.
To add a security context for main container:
containerSecurityContext:
allowPrivilegeEscalation: falseTo add a security context on pod level:
podSecurityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000You can use topology spread constraints to control how Pods are spread across your cluster among failure-domains such as regions, zones, nodes, and other user-defined topology domains. This can help to achieve high availability as well as efficient resource utilization.
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
autoLabelSelector: true
customLabelSelector: {}It gives the realtime metrics of the deployed applications
Deployment Frequency
It shows how often this app is deployed to production
Change Failure Rate
It shows how often the respective pipeline fails.
Mean Lead Time
It shows the average time taken to deliver a change to production.
Mean Time to Recovery
It shows the average time taken to fix a failed pipeline.
If you want to see application metrics like different HTTP status codes metrics, application throughput, latency, response time. Enable the Application metrics from below the deployment template Save button. After enabling it, you should be able to see all metrics on App detail page. By default it remains disabled.
Once all the Deployment template configurations are done, click on Save to save your deployment configuration. Now you are ready to create Workflow to do CI/CD.
Helm Chart json schema is used to validate the deployment template values.
The values of CPU and Memory in limits must be greater than or equal to in requests respectively. Similarly, In case of envoyproxy, the values of limits are greater than or equal to requests as mentioned below.
resources.limits.cpu >= resources.requests.cpu
resources.limits.memory >= resources.requests.memory
envoyproxy.resources.limits.cpu >= envoyproxy.resources.requests.cpu
envoyproxy.resources.limits.memory >= envoyproxy.resources.requests.memory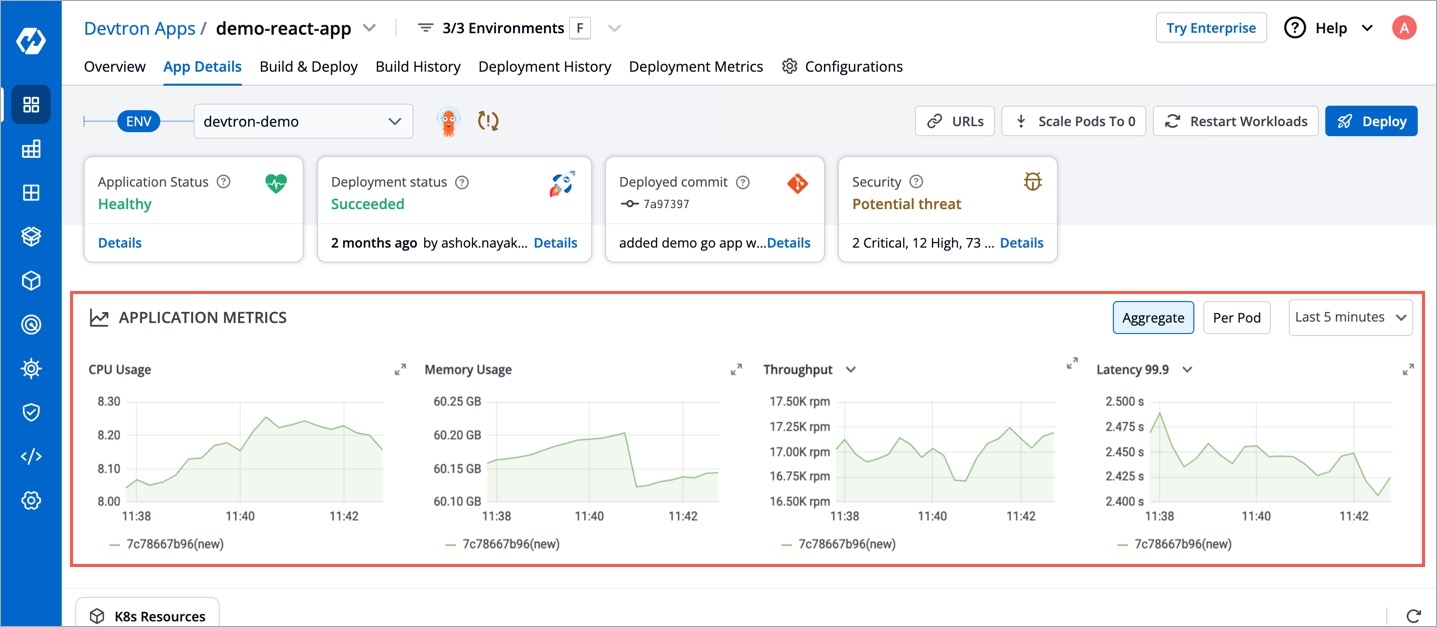
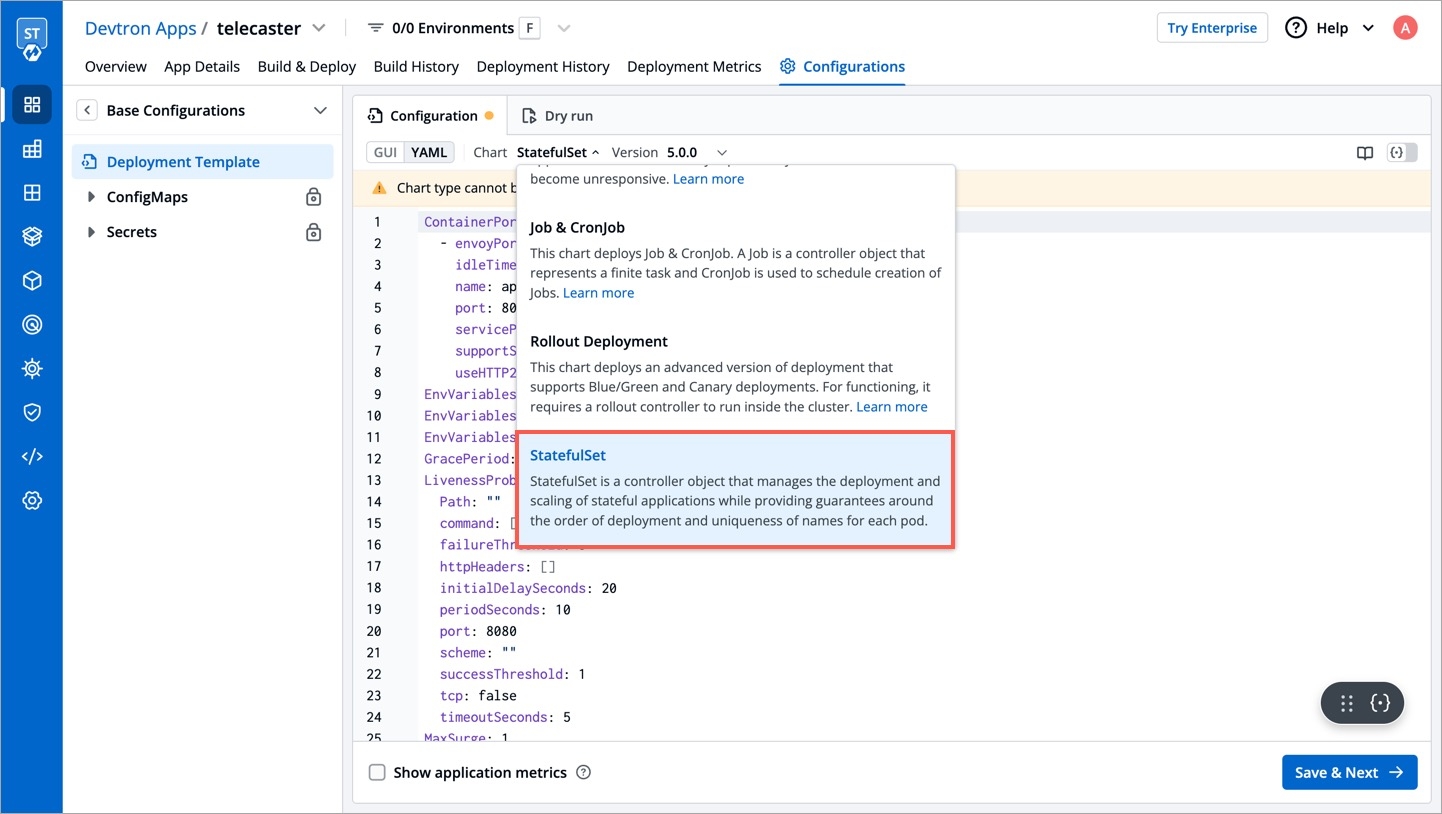
This chart creates a deployment that runs multiple replicas of your application and automatically replaces any instances that fail or become unresponsive. It does not support Blue/Green and Canary deployments.
This is the default deployment chart. You can select Deployment chart when you want to use only basic use cases which contain the following:
Create a Deployment to rollout a ReplicaSet. The ReplicaSet creates Pods in the background. Check the status of the rollout to see if it succeeds or not.
Declare the new state of the Pods. A new ReplicaSet is created and the Deployment manages moving the Pods from the old ReplicaSet to the new one at a controlled rate. Each new ReplicaSet updates the revision of the Deployment.
Rollback to an earlier Deployment revision if the current state of the Deployment is not stable. Each rollback updates the revision of the Deployment.
Scale up the Deployment to facilitate more load.
Use the status of the Deployment as an indicator that a rollout has stuck.
Clean up older ReplicaSets that you do not need anymore.
You can define application behavior by providing information in the following sections:
Chart version
Select the Chart Version using which you want to deploy the application. Refer section for more detail.
Basic Configuration
You can select the basic deployment configuration for your application on the Basic GUI section instead of configuring the YAML file. Refer section for more detail.
Advanced (YAML)
If you want to do additional configurations, then click Advanced (YAML) for modifications. Refer section for more detail.
Show application metrics
You can enable Show application metrics to see your application's metrics-CPU Service Monitor usage, Memory Usage, Status, Throughput and Latency.
Refer for more detail.
Super-admins can lock keys in deployment template to prevent non-super-admins from modifying those locked keys. Refer Lock Deployment Configuration to know more.
This defines ports on which application services will be exposed to other services
ContainerPort:
- envoyPort: 8799
idleTimeout:
name: app
port: 8080
servicePort: 80
nodePort: 32056
supportStreaming: true
useHTTP2: trueenvoyPort
envoy port for the container
idleTimeout
the duration of time that a connection is idle before the connection is terminated
name
name of the port
port
port for the container
servicePort
port of the corresponding kubernetes service
nodePort
nodeport of the corresponding kubernetes service
supportStreaming
Used for high performance protocols like grpc where timeout needs to be disabled
useHTTP2
Envoy container can accept HTTP2 requests
EnvVariables: []To set environment variables for the containers that run in the Pod.
EnvVariablesFromFieldPath:
- name: ENV_NAME
fieldPath: status.podIP (example)To set environment variables for the containers and fetching their values from pod-level fields.
If this check fails, kubernetes restarts the pod. This should return error code in case of non-recoverable error.
LivenessProbe:
Path: ""
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
failureThreshold: 3
httpHeaders:
- name: Custom-Header
value: abc
scheme: ""
tcp: truePath
It define the path where the liveness needs to be checked
initialDelaySeconds
It defines the time to wait before a given container is checked for liveliness
periodSeconds
It defines the time to check a given container for liveness
successThreshold
It defines the number of successes required before a given container is said to fulfill the liveness probe
timeoutSeconds
It defines the time for checking timeout
failureThreshold
It defines the maximum number of failures that are acceptable before a given container is not considered as live
httpHeaders
Custom headers to set in the request. HTTP allows repeated headers, you can override the default headers by defining .httpHeaders for the probe.
scheme
Scheme to use for connecting to the host (HTTP or HTTPS). Defaults to HTTP.
tcp
The kubelet will attempt to open a socket to your container on the specified port. If it can establish a connection, the container is considered healthy.
MaxUnavailable: 0The maximum number of pods that can be unavailable during the update process. The value of "MaxUnavailable: " can be an absolute number or percentage of the replicas count. The default value of "MaxUnavailable: " is 25%.
MaxSurge: 1The maximum number of pods that can be created over the desired number of pods. For "MaxSurge: " also, the value can be an absolute number or percentage of the replicas count. The default value of "MaxSurge: " is 25%.
MinReadySeconds: 60This specifies the minimum number of seconds for which a newly created Pod should be ready without any of its containers crashing, for it to be considered available. This defaults to 0 (the Pod will be considered available as soon as it is ready).
If this check fails, kubernetes stops sending traffic to the application. This should return error code in case of errors which can be recovered from if traffic is stopped.
ReadinessProbe:
Path: ""
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
failureThreshold: 3
httpHeaders:
- name: Custom-Header
value: abc
scheme: ""
tcp: truePath
It define the path where the readiness needs to be checked
initialDelaySeconds
It defines the time to wait before a given container is checked for readiness
periodSeconds
It defines the time to check a given container for readiness
successThreshold
It defines the number of successes required before a given container is said to fulfill the readiness probe
timeoutSeconds
It defines the time for checking timeout
failureThreshold
It defines the maximum number of failures that are acceptable before a given container is not considered as ready
httpHeaders
Custom headers to set in the request. HTTP allows repeated headers, you can override the default headers by defining .httpHeaders for the probe.
scheme
Scheme to use for connecting to the host (HTTP or HTTPS). Defaults to HTTP.
tcp
The kubelet will attempt to open a socket to your container on the specified port. If it can establish a connection, the container is considered healthy.
You can create PodDisruptionBudget for each application. A PDB limits the number of pods of a replicated application that are down simultaneously from voluntary disruptions. For example, an application would like to ensure the number of replicas running is never brought below the certain number.
podDisruptionBudget:
minAvailable: 1or
podDisruptionBudget:
maxUnavailable: 50%You can specify either maxUnavailable or minAvailable in a PodDisruptionBudget and it can be expressed as integers or as a percentage.
minAvailable
Evictions are allowed as long as they leave behind 1 or more healthy pods of the total number of desired replicas.
maxUnavailable
Evictions are allowed as long as at most 1 unhealthy replica among the total number of desired replicas.
You can create ambassador mappings to access your applications from outside the cluster. At its core a Mapping resource maps a resource to a service.
ambassadorMapping:
ambassadorId: "prod-emissary"
cors: {}
enabled: true
hostname: devtron.example.com
labels: {}
prefix: /
retryPolicy: {}
rewrite: ""
tls:
context: "devtron-tls-context"
create: false
hosts: []
secretName: ""enabled
Set true to enable ambassador mapping else set false
ambassadorId
used to specify id for specific ambassador mappings controller
cors
used to specify cors policy to access host for this mapping
weight
used to specify weight for canary ambassador mappings
hostname
used to specify hostname for ambassador mapping
prefix
used to specify path for ambassador mapping
labels
used to provide custom labels for ambassador mapping
retryPolicy
used to specify retry policy for ambassador mapping
corsPolicy
Provide cors headers on flagger resource
rewrite
used to specify whether to redirect the path of this mapping and where
tls
used to create or define ambassador TLSContext resource
extraSpec
used to provide extra spec values which not present in deployment template for ambassador resource
This is connected to HPA and controls scaling up and down in response to request load.
autoscaling:
enabled: false
MinReplicas: 1
MaxReplicas: 2
TargetCPUUtilizationPercentage: 90
TargetMemoryUtilizationPercentage: 80
extraMetrics: []enabled
Set true to enable autoscaling else set false
MinReplicas
Minimum number of replicas allowed for scaling
MaxReplicas
Maximum number of replicas allowed for scaling
TargetCPUUtilizationPercentage
The target CPU utilization that is expected for a container
TargetMemoryUtilizationPercentage
The target memory utilization that is expected for a container
extraMetrics
Used to give external metrics for autoscaling
You can use flagger for canary releases with deployment objects. It supports flexible traffic routing with istio service mesh as well.
flaggerCanary:
addOtherGateways: []
addOtherHosts: []
analysis:
interval: 15s
maxWeight: 50
stepWeight: 5
threshold: 5
annotations: {}
appProtocol: http
corsPolicy:
allowCredentials: false
allowHeaders:
- x-some-header
allowMethods:
- GET
allowOrigin:
- example.com
maxAge: 24h
createIstioGateway:
annotations: {}
enabled: false
host: example.com
labels: {}
tls:
enabled: false
secretName: example-tls-secret
enabled: false
gatewayRefs: null
headers:
request:
add:
x-some-header: value
labels: {}
loadtest:
enabled: true
url: http://flagger-loadtester.istio-system/
match:
- uri:
prefix: /
port: 8080
portDiscovery: true
retries: null
rewriteUri: /
targetPort: 8080
thresholds:
latency: 500
successRate: 90
timeout: nullenabled
Set true to enable canary releases using flagger else set false
addOtherGateways
To provide multiple istio gateways for flagger
addOtherHosts
Add multiple hosts for istio service mesh with flagger
analysis
Define how the canary release should progress and at what interval
annotations
Annotation to add on flagger resource
labels
Labels to add on flagger resource
appProtocol
Protocol to use for canary
corsPolicy
Provide cors headers on flagger resource
createIstioGateway
Set to true if you want to create istio gateway as well with flagger
headers
Add headers if any
loadtest
Enable load testing for your canary release
fullnameOverride: app-namefullnameOverride replaces the release fullname created by default by devtron, which is used to construct Kubernetes object names. By default, devtron uses {app-name}-{environment-name} as release fullname.
image:
pullPolicy: IfNotPresentImage is used to access images in kubernetes, pullpolicy is used to define the instances calling the image, here the image is pulled when the image is not present,it can also be set as "Always".
imagePullSecrets contains the docker credentials that are used for accessing a registry.
imagePullSecrets:
- regcredregcred is the secret that contains the docker credentials that are used for accessing a registry. Devtron will not create this secret automatically, you'll have to create this secret using dt-secrets helm chart in the App store or create one using kubectl. You can follow this documentation Pull an Image from a Private Registry https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/ .
serviceAccount:
create: false
name: ""
annotations: {}enabled
Determines whether to create a ServiceAccount for pods or not. If set to true, a ServiceAccount will be created.
name
Specifies the name of the ServiceAccount to use.
annotations
Specify annotations for the ServiceAccount.
the hostAliases field is used in a Pod specification to associate additional hostnames with the Pod's IP address. This can be helpful in scenarios where you need to resolve specific hostnames to the Pod's IP within the Pod itself.
hostAliases:
- ip: "192.168.1.10"
hostnames:
- "hostname1.example.com"
- "hostname2.example.com"
- ip: "192.168.1.11"
hostnames:
- "hostname3.example.com"This allows public access to the url, please ensure you are using right nginx annotation for nginx class, its default value is nginx
ingress:
enabled: false
# For K8s 1.19 and above use ingressClassName instead of annotation kubernetes.io/ingress.class:
className: nginx
annotations: {}
hosts:
- host: example1.com
paths:
- /example
- host: example2.com
paths:
- /example2
- /example2/healthz
tls: []Legacy deployment-template ingress format
ingress:
enabled: false
# For K8s 1.19 and above use ingressClassName instead of annotation kubernetes.io/ingress.class:
ingressClassName: nginx-internal
annotations: {}
path: ""
host: ""
tls: []enabled
Enable or disable ingress
annotations
To configure some options depending on the Ingress controller
path
Path name
host
Host name
tls
It contains security details
This allows private access to the url, please ensure you are using right nginx annotation for nginx class, its default value is nginx
ingressInternal:
enabled: false
# For K8s 1.19 and above use ingressClassName instead of annotation kubernetes.io/ingress.class:
ingressClassName: nginx-internal
annotations: {}
hosts:
- host: example1.com
paths:
- /example
- host: example2.com
paths:
- /example2
- /example2/healthz
tls: []enabled
Enable or disable ingress
annotations
To configure some options depending on the Ingress controller
path
Path name
host
Host name
tls
It contains security details
initContainers:
- reuseContainerImage: true
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
volumeMounts:
- mountPath: /etc/ls-oms
name: ls-oms-cm-vol
command:
- flyway
- -configFiles=/etc/ls-oms/flyway.conf
- migrate
- name: nginx
image: nginx:1.14.2
securityContext:
privileged: true
ports:
- containerPort: 80
command: ["/usr/local/bin/nginx"]
args: ["-g", "daemon off;"]Specialized containers that run before app containers in a Pod. Init containers can contain utilities or setup scripts not present in an app image. One can use base image inside initContainer by setting the reuseContainerImage flag to true.
pauseForSecondsBeforeSwitchActive: 30To wait for given period of time before switch active the container.
These define minimum and maximum RAM and CPU available to the application.
resources:
limits:
cpu: "1"
memory: "200Mi"
requests:
cpu: "0.10"
memory: "100Mi"Resources are required to set CPU and memory usage.
Limits make sure a container never goes above a certain value. The container is only allowed to go up to the limit, and then it is restricted.
Requests are what the container is guaranteed to get.
This defines annotations and the type of service, optionally can define name also.
service:
type: ClusterIP
annotations: {}volumes:
- name: log-volume
emptyDir: {}
- name: logpv
persistentVolumeClaim:
claimName: logpvcIt is required when some values need to be read from or written to an external disk.
volumeMounts:
- mountPath: /var/log/nginx/
name: log-volume
- mountPath: /mnt/logs
name: logpvc
subPath: employee It is used to provide mounts to the volume.
Spec:
Affinity:
Key:
Values:Spec is used to define the desire state of the given container.
Node Affinity allows you to constrain which nodes your pod is eligible to schedule on, based on labels of the node.
Inter-pod affinity allow you to constrain which nodes your pod is eligible to be scheduled based on labels on pods.
Key part of the label for node selection, this should be same as that on node. Please confirm with devops team.
Value part of the label for node selection, this should be same as that on node. Please confirm with devops team.
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule|PreferNoSchedule|NoExecute(1.6 only)"Taints are the opposite, they allow a node to repel a set of pods.
A given pod can access the given node and avoid the given taint only if the given pod satisfies a given taint.
Taints and tolerations are a mechanism which work together that allows you to ensure that pods are not placed on inappropriate nodes. Taints are added to nodes, while tolerations are defined in the pod specification. When you taint a node, it will repel all the pods except those that have a toleration for that taint. A node can have one or many taints associated with it.
args:
enabled: false
value: []This is used to give arguments to command.
command:
enabled: false
value: []It contains the commands for the server.
enabled
To enable or disable the command
value
It contains the commands
Containers section can be used to run side-car containers along with your main container within same pod. Containers running within same pod can share volumes and IP Address and can address each other @localhost. We can use base image inside container by setting the reuseContainerImage flag to true.
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
command: ["/usr/local/bin/nginx"]
args: ["-g", "daemon off;"]
- reuseContainerImage: true
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
volumeMounts:
- mountPath: /etc/ls-oms
name: ls-oms-cm-vol
command:
- flyway
- -configFiles=/etc/ls-oms/flyway.conf
- migrateContainer lifecycle hooks are mechanisms that allow users to define custom actions to be performed at specific stages of a container's lifecycle i.e. PostStart or PreStop.
containerSpec:
lifecycle:
enabled: false
postStart:
httpGet:
host: example.com
path: /example
port: 90
preStop:
exec:
command:
- sleep
- "10"containerSpec
containerSpec to define container lifecycle hooks configuration
lifecycle
Lifecycle hooks for the container
enabled
Set true to enable lifecycle hooks for the container else set false
postStart
The postStart hook is executed immediately after a container is created
httpsGet
Sends an HTTP GET request to a specific endpoint on the container
host
Specifies the host (example.com) to which the HTTP GET request will be sent
path
Specifies the path (/example) of the endpoint to which the HTTP GET request will be sent
port
Specifies the port (90) on the host where the HTTP GET request will be sent
preStop
The preStop hook is executed just before the container is stopped
exec
Executes a specific command, such as pre-stop.sh, inside the cgroups and namespaces of the container
command
The command to be executed is sleep 10, which tells the container to sleep for 10 seconds before it is stopped
prometheus:
release: monitoringIt is a kubernetes monitoring tool and the name of the file to be monitored as monitoring in the given case. It describes the state of the Prometheus.
rawYaml:
- apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
type: ClusterIPAccepts an array of Kubernetes objects. You can specify any kubernetes yaml here and it will be applied when your app gets deployed.
GracePeriod: 30Kubernetes waits for the specified time called the termination grace period before terminating the pods. By default, this is 30 seconds. If your pod usually takes longer than 30 seconds to shut down gracefully, make sure you increase the GracePeriod.
A Graceful termination in practice means that your application needs to handle the SIGTERM message and begin shutting down when it receives it. This means saving all data that needs to be saved, closing down network connections, finishing any work that is left, and other similar tasks.
There are many reasons why Kubernetes might terminate a perfectly healthy container. If you update your deployment with a rolling update, Kubernetes slowly terminates old pods while spinning up new ones. If you drain a node, Kubernetes terminates all pods on that node. If a node runs out of resources, Kubernetes terminates pods to free those resources. It’s important that your application handle termination gracefully so that there is minimal impact on the end user and the time-to-recovery is as fast as possible.
server:
deployment:
image_tag: 1-95a53
image: ""It is used for providing server configurations.
It gives the details for deployment.
image_tag
It is the image tag
image
It is the URL of the image
servicemonitor:
enabled: true
path: /abc
scheme: 'http'
interval: 30s
scrapeTimeout: 20s
metricRelabelings:
- sourceLabels: [namespace]
regex: '(.*)'
replacement: myapp
targetLabel: target_namespaceIt gives the set of targets to be monitored.
dbMigrationConfig:
enabled: falseIt is used to configure database migration.
These Istio configurations collectively provide a comprehensive set of tools for controlling access, authenticating requests, enforcing security policies, and configuring traffic behavior within a microservices architecture. The specific settings you choose would depend on your security and traffic management requirements.
istio:
enable: true
gateway:
enabled: true
labels:
app: my-gateway
annotations:
description: "Istio Gateway for external traffic"
host: "example.com"
tls:
enabled: true
secretName: my-tls-secret
virtualService:
enabled: true
labels:
app: my-service
annotations:
description: "Istio VirtualService for routing"
gateways:
- my-gateway
hosts:
- "example.com"
http:
- match:
- uri:
prefix: /v1
route:
- destination:
host: my-service-v1
subset: version-1
- match:
- uri:
prefix: /v2
route:
- destination:
host: my-service-v2
subset: version-2
destinationRule:
enabled: true
labels:
app: my-service
annotations:
description: "Istio DestinationRule for traffic policies"
subsets:
- name: version-1
labels:
version: "v1"
- name: version-2
labels:
version: "v2"
trafficPolicy:
connectionPool:
tcp:
maxConnections: 100
outlierDetection:
consecutiveErrors: 5
interval: 30s
baseEjectionTime: 60s
peerAuthentication:
enabled: true
labels:
app: my-service
annotations:
description: "Istio PeerAuthentication for mutual TLS"
selector:
matchLabels:
version: "v1"
mtls:
mode: STRICT
portLevelMtls:
8080:
mode: DISABLE
requestAuthentication:
enabled: true
labels:
app: my-service
annotations:
description: "Istio RequestAuthentication for JWT validation"
selector:
matchLabels:
version: "v1"
jwtRules:
- issuer: "issuer-1"
jwksUri: "https://issuer-1/.well-known/jwks.json"
authorizationPolicy:
enabled: true
labels:
app: my-service
annotations:
description: "Istio AuthorizationPolicy for access control"
action: ALLOW
provider:
name: jwt
kind: Authorization
rules:
- from:
- source:
requestPrincipals: ["*"]
to:
- operation:
methods: ["GET"]istio
Istio enablement. When istio.enable set to true, Istio would be enabled for the specified configurations
authorizationPolicy
It allows you to define access control policies for service-to-service communication.
action
Determines whether to ALLOW or DENY the request based on the defined rules.
provider
Authorization providers are external systems or mechanisms used to make access control decisions.
rules
List of rules defining the authorization policy. Each rule can specify conditions and requirements for allowing or denying access.
destinationRule
It allows for the fine-tuning of traffic policies and load balancing for specific services. You can define subsets of a service and apply different traffic policies to each subset.
subsets
Specifies subsets within the service for routing and load balancing.
trafficPolicy
Policies related to connection pool size, outlier detection, and load balancing.
gateway
Allowing external traffic to enter the service mesh through the specified configurations.
host
The external domain through which traffic will be routed into the service mesh.
tls
Traffic to and from the gateway should be encrypted using TLS.
secretName
Specifies the name of the Kubernetes secret that contains the TLS certificate and private key. The TLS certificate is used for securing the communication between clients and the Istio gateway.
peerAuthentication
It allows you to enforce mutual TLS and control the authentication between services.
mtls
Mutual TLS. Mutual TLS is a security protocol that requires both client and server, to authenticate each other using digital certificates for secure communication.
mode
Mutual TLS mode, specifying how mutual TLS should be applied. Modes include STRICT, PERMISSIVE, and DISABLE.
portLevelMtls
Configures port-specific mTLS settings. Allows for fine-grained control over the application of mutual TLS on specific ports.
selector
Configuration for selecting workloads to apply PeerAuthentication.
requestAuthentication
Defines rules for authenticating incoming requests.
jwtRules
Rules for validating JWTs (JSON Web Tokens). It defines how incoming JWTs should be validated for authentication purposes.
selector
Specifies the conditions under which the RequestAuthentication rules should be applied.
virtualService
Enables the definition of rules for how traffic should be routed to different services within the service mesh.
gateways
Specifies the gateways to which the rules defined in the VirtualService apply.
hosts
List of hosts (domains) to which this VirtualService is applied.
http
Configuration for HTTP routes within the VirtualService. It define routing rules based on HTTP attributes such as URI prefixes, headers, timeouts, and retry policies.
KEDA is a Kubernetes-based Event Driven Autoscaler. With KEDA, you can drive the scaling of any container in Kubernetes based on the number of events needing to be processed. KEDA can be installed into any Kubernetes cluster and can work alongside standard Kubernetes components like the Horizontal Pod Autoscaler(HPA).
Example for autosccaling with KEDA using Prometheus metrics is given below:
kedaAutoscaling:
enabled: true
minReplicaCount: 1
maxReplicaCount: 2
idleReplicaCount: 0
pollingInterval: 30
advanced:
restoreToOriginalReplicaCount: true
horizontalPodAutoscalerConfig:
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
- type: prometheus
metadata:
serverAddress: http://<prometheus-host>:9090
metricName: http_request_total
query: envoy_cluster_upstream_rq{appId="300", cluster_name="300-0", container="envoy",}
threshold: "50"
triggerAuthentication:
enabled: false
name:
spec: {}
authenticationRef: {}Example for autosccaling with KEDA based on kafka is given below :
kedaAutoscaling:
enabled: true
minReplicaCount: 1
maxReplicaCount: 2
idleReplicaCount: 0
pollingInterval: 30
advanced: {}
triggers:
- type: kafka
metadata:
bootstrapServers: b-2.kafka-msk-dev.example.c2.kafka.ap-southeast-1.amazonaws.com:9092,b-3.kafka-msk-dev.example.c2.kafka.ap-southeast-1.amazonaws.com:9092,b-1.kafka-msk-dev.example.c2.kafka.ap-southeast-1.amazonaws.com:9092
topic: Orders-Service-ESP.info
lagThreshold: "100"
consumerGroup: oders-remove-delivered-packages
allowIdleConsumers: "true"
triggerAuthentication:
enabled: true
name: keda-trigger-auth-kafka-credential
spec:
secretTargetRef:
- parameter: sasl
name: keda-kafka-secrets
key: sasl
- parameter: username
name: keda-kafka-secrets
key: username
authenticationRef:
name: keda-trigger-auth-kafka-credentialKubernetes NetworkPolicies control pod communication by defining rules for incoming and outgoing traffic.
networkPolicy:
enabled: false
annotations: {}
labels: {}
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978enabled
Enable or disable NetworkPolicy.
annotations
Additional metadata or information associated with the NetworkPolicy.
labels
Labels to apply to the NetworkPolicy.
podSelector
Each NetworkPolicy includes a podSelector which selects the grouping of pods to which the policy applies. The example policy selects pods with the label "role=db". An empty podSelector selects all pods in the namespace.
policyTypes
Each NetworkPolicy includes a policyTypes list which may include either Ingress, Egress, or both.
Ingress
Controls incoming traffic to pods.
Egress
Controls outgoing traffic from pods.
Winter Soldier can be used to
cleans up (delete) Kubernetes resources
reduce workload pods to 0
NOTE: After deploying this we can create the Hibernator object and provide the custom configuration by which workloads going to delete, sleep and many more. for more information check the main repo
Given below is template values you can give in winter-soldier:
winterSoldier:
enabled: false
apiVersion: pincher.devtron.ai/v1alpha1
action: sleep
timeRangesWithZone:
timeZone: "Asia/Kolkata"
timeRanges: []
targetReplicas: []
fieldSelector: []enabled
false,true
decide the enabling factor
apiVersion
pincher.devtron.ai/v1beta1, pincher.devtron.ai/v1alpha1
specific api version
action
sleep,delete, scale
This specify the action need to perform.
timeRangesWithZone:timeZone
eg:- "Asia/Kolkata","US/Pacific"
It use to specify the timeZone used. (It uses standard format. please refer )
timeRangesWithZone:timeRanges
array of [ timeFrom, timeTo, weekdayFrom, weekdayTo]
It use to define time period/range on which the user need to perform the specified action. you can have multiple timeRanges.
These settings will take action on Sat and Sun from 00:00 to 23:59:59,
targetReplicas
[n] : n - number of replicas to scale.
These is mandatory field when the action is scale
Default value is [].
fieldSelector
- AfterTime(AddTime( ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z'), '5m'), Now())
These value will take a list of methods to select the resources on which we perform specified action .
here is an example,
winterSoldier:
apiVersion: pincher.devtron.ai/v1alpha1
enabled: true
annotations: {}
labels: {}
timeRangesWithZone:
timeZone: "Asia/Kolkata"
timeRanges:
- timeFrom: 00:00
timeTo: 23:59:59
weekdayFrom: Sat
weekdayTo: Sun
- timeFrom: 00:00
timeTo: 08:00
weekdayFrom: Mon
weekdayTo: Fri
- timeFrom: 20:00
timeTo: 23:59:59
weekdayFrom: Mon
weekdayTo: Fri
action: scale
targetReplicas: [1,1,1]
fieldSelector:
- AfterTime(AddTime( ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z'), '10h'), Now())Above settings will take action on Sat and Sun from 00:00 to 23:59:59, and on Mon-Fri from 00:00 to 08:00 and 20:00 to 23:59:59. If action:sleep then runs hibernate at timeFrom and unhibernate at timeTo. If action: delete then it will delete workloads at timeFrom and timeTo. Here the action:scale thus it scale the number of resource replicas to targetReplicas: [1,1,1]. Here each element of targetReplicas array is mapped with the corresponding elements of array timeRangesWithZone/timeRanges. Thus make sure the length of both array is equal, otherwise the cnages cannot be observed.
The above example will select the application objects which have been created 10 hours ago across all namespaces excluding application's namespace. Winter soldier exposes following functions to handle time, cpu and memory.
ParseTime - This function can be used to parse time. For eg to parse creationTimestamp use ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z')
AddTime - This can be used to add time. For eg AddTime(ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z'), '-10h') ll add 10h to the time. Use d for day, h for hour, m for minutes and s for seconds. Use negative number to get earlier time.
Now - This can be used to get current time.
CpuToNumber - This can be used to compare CPU. For eg any({{spec.containers.#.resources.requests}}, { MemoryToNumber(.memory) < MemoryToNumber('60Mi')}) will check if any resource.requests is less than 60Mi.
A security context defines privilege and access control settings for a Pod or Container.
To add a security context for main container:
containerSecurityContext:
allowPrivilegeEscalation: falseTo add a security context on pod level:
podSecurityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000You can use topology spread constraints to control how Pods are spread across your cluster among failure-domains such as regions, zones, nodes, and other user-defined topology domains. This can help to achieve high availability as well as efficient resource utilization.
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
autoLabelSelector: true
customLabelSelector: {}It gives the realtime metrics of the deployed applications
Deployment Frequency
It shows how often this app is deployed to production
Change Failure Rate
It shows how often the respective pipeline fails
Mean Lead Time
It shows the average time taken to deliver a change to production
Mean Time to Recovery
It shows the average time taken to fix a failed pipeline
If you want to see application metrics like different HTTP status codes metrics, application throughput, latency, response time. Enable the Application metrics from below the deployment template Save button. After enabling it, you should be able to see all metrics on App detail page. By default it remains disabled.
Once all the Deployment template configurations are done, click on Save to save your deployment configuration. Now you are ready to create Workflow to do CI/CD.
Helm Chart json schema is used to validate the deployment template values.
The values of CPU and Memory in limits must be greater than or equal to in requests respectively. Similarly, In case of envoyproxy, the values of limits are greater than or equal to requests as mentioned below.
resources.limits.cpu >= resources.requests.cpu
resources.limits.memory >= resources.requests.memory
envoyproxy.resources.limits.cpu >= envoyproxy.resources.requests.cpu
envoyproxy.resources.limits.memory >= envoyproxy.resources.requests.memory
The Rollout Deployment chart deploys an advanced version of deployment that supports Blue/Green and Canary deployments. For functioning, it requires a rollout controller to run inside the cluster.
You can define application behavior by providing information in the following sections:
Super-admins can lock keys in rollout deployment template to prevent non-super-admins from modifying those locked keys. Refer Lock Deployment Configuration to know more.
Chart Version
Select the Chart Version using which you want to deploy the application.
Devtron uses helm charts for the deployments. And we are having multiple chart versions based on features it is supporting with every chart version.
One can see multiple chart version options available in the drop-down. you can select any chart version as per your requirements. By default, the latest version of the helm chart is selected in the chart version option.
Every chart version has its own YAML file. Helm charts are used to provide specifications for your application. To make it easy to use, we have created templates for the YAML file and have added some variables inside the YAML. You can provide or change the values of these variables as per your requirement.
If you want to see Application Metrics (as an example, Status codes 2xx, 3xx, 5xx; throughput, and latency etc.) for your application, then you need to select the latest chart version.
Note: Application Metrics are not supported for the Chart version older than 3.7 version.
Some of the use-cases which are defined on the Deployment Template (YAML file) may not be applicable to configure for your application. In such cases, you can do the basic deployment configuration for your application on the Basic GUI section instead of configuring the YAML file.
The following fields are provided on the Basic GUI section:
Port
The internal HTTP port.
HTTP Request Routes
Enable the HTTP Request Routes to define Host and Path. By default, it is in disabled state.
Host: Domain name of the server.
Path: Path of the specific component in the host that the HTTP wants to access.
You can define multiple paths as required by clicking Add path.
CPU
The CPU resource as per the application.
RAM
The RAM resource as per the application.
Environment Variables (Key/Value)
Define key/value by clicking Add variable.
Key: Define the key of the environment.
Value: Define the value of the environment.
You can define multiple env variables by clicking Add variable.
Click Save Changes.
If you want to do additional configurations, then click Advanced (YAML) for modifications.
Note: If you change any values in the Basic GUI, then the corresponding values will be changed in YAML file also.
This defines the ports on which application services will be exposed to other services.
ContainerPort:
- envoyPort: 8799
envoyTimeout: 15s
idleTimeout:
name: app
port: 8080
servicePort: 80
supportStreaming: true
useHTTP2: trueenvoyPort
envoy port for the container.
envoyTimeout
envoy Timeout for the container,envoy supports a wide range of timeouts that may need to be configured depending on the deployment.By default the envoytimeout is 15s.
idleTimeout
the duration of time that a connection is idle before the connection is terminated.
name
name of the port.
port
port for the container.
servicePort
port of the corresponding kubernetes service.
supportStreaming
Used for high performance protocols like grpc where timeout needs to be disabled.
useHTTP2
Envoy container can accept HTTP2 requests.
EnvVariables: []EnvVariables provide run-time information to containers and allow to customize how the application works and the behavior of the applications on the system.
Here we can pass the list of env variables , every record is an object which contain the name of variable along with value.
To set environment variables for the containers that run in the Pod.
IMP Docker image should have env variables, whatever we want to set.
EnvVariables:
- name: HOSTNAME
value: www.xyz.com
- name: DB_NAME
value: mydb
- name: USER_NAME
value: xyzBut ConfigMap and Secret are the preferred way to inject env variables. You can create this in App Configuration Section.
It is a centralized storage, specific to k8s namespace where key-value pairs are stored in plain text.
It is a centralized storage, specific to k8s namespace where we can store the key-value pairs in plain text as well as in encrypted(Base64) form.
IMP All key-values of Secret and CofigMap will reflect to your application.
If this check fails, kubernetes restarts the pod. This should return error code in case of non-recoverable error.
LivenessProbe:
Path: ""
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
failureThreshold: 3
command:
- python
- /etc/app/healthcheck.py
httpHeaders:
- name: Custom-Header
value: abc
scheme: ""
tcp: truePath
It define the path where the liveness needs to be checked.
initialDelaySeconds
It defines the time to wait before a given container is checked for liveliness.
periodSeconds
It defines how often (in seconds) to perform the liveness probe.
successThreshold
It defines the number of successes required before a given container is said to fulfil the liveness probe.
timeoutSeconds
The maximum time (in seconds) for the probe to complete.
failureThreshold
The number of consecutive failures required to consider the probe as failed.
command
The mentioned command is executed to perform the livenessProbe. If the command returns a non-zero value, it's equivalent to a failed probe.
httpHeaders
Custom headers to set in the request. HTTP allows repeated headers,You can override the default headers by defining .httpHeaders for the probe.
scheme
Scheme to use for connecting to the host (HTTP or HTTPS). Defaults to HTTP.
tcp
The kubelet will attempt to open a socket to your container on the specified port. If it can establish a connection, the container is considered healthy.
MaxUnavailable: 0The maximum number of pods that can be unavailable during the update process. The value of "MaxUnavailable: " can be an absolute number or percentage of the replicas count. The default value of "MaxUnavailable: " is 25%.
MaxSurge: 1The maximum number of pods that can be created over the desired number of pods. For "MaxSurge: " also, the value can be an absolute number or percentage of the replicas count. The default value of "MaxSurge: " is 25%.
MinReadySeconds: 60This specifies the minimum number of seconds for which a newly created Pod should be ready without any of its containers crashing, for it to be considered available. This defaults to 0 (the Pod will be considered available as soon as it is ready).
If this check fails, kubernetes stops sending traffic to the application. This should return error code in case of errors which can be recovered from if traffic is stopped.
ReadinessProbe:
Path: ""
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
failureThreshold: 3
command:
- python
- /etc/app/healthcheck.py
httpHeaders:
- name: Custom-Header
value: abc
scheme: ""
tcp: truePath
It define the path where the readiness needs to be checked.
initialDelaySeconds
It defines the time to wait before a given container is checked for readiness.
periodSeconds
It defines how often (in seconds) to perform the readiness probe.
successThreshold
It defines the number of successes required before a given container is said to fulfill the readiness probe.
timeoutSeconds
The maximum time (in seconds) for the probe to complete.
failureThreshold
The number of consecutive failures required to consider the probe as failed.
command
The mentioned command is executed to perform the readinessProbe. If the command returns a non-zero value, it's equivalent to a failed probe.
httpHeaders
Custom headers to set in the request. HTTP allows repeated headers,You can override the default headers by defining .httpHeaders for the probe.
scheme
Scheme to use for connecting to the host (HTTP or HTTPS). Defaults to HTTP.
tcp
The kubelet will attempt to open a socket to your container on the specified port. If it can establish a connection, the container is considered healthy.
Startup Probe in Kubernetes is a type of probe used to determine when a container within a pod is ready to start accepting traffic. It is specifically designed for applications that have a longer startup time.
StartupProbe:
Path: ""
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
failureThreshold: 3
httpHeaders:
- name: Custom-Header
value: abc
command:
- python
- /etc/app/healthcheck.py
tcp: falsePath
It define the path where the startup needs to be checked.
initialDelaySeconds
It defines the time to wait before a given container is checked for startup.
periodSeconds
It defines how often (in seconds) to perform the startup probe.
successThreshold
The number of consecutive successful probe results required to mark the container as ready.
timeoutSeconds
The maximum time (in seconds) for the probe to complete.
failureThreshold
The number of consecutive failures required to consider the probe as failed.
command
The mentioned command is executed to perform the startup probe. If the command returns a non-zero value, it's equivalent to a failed probe.
httpHeaders
Custom headers to set in the request. HTTP allows repeated headers,You can override the default headers by defining .httpHeaders for the probe.
tcp
The kubelet will attempt to open a socket to your container on the specified port. If it can establish a connection, the container is considered healthy.
This is connected to HPA and controls scaling up and down in response to request load.
autoscaling:
enabled: false
MinReplicas: 1
MaxReplicas: 2
TargetCPUUtilizationPercentage: 90
TargetMemoryUtilizationPercentage: 80
extraMetrics: []enabled
Set true to enable autoscaling else set false.
MinReplicas
Minimum number of replicas allowed for scaling.
MaxReplicas
Maximum number of replicas allowed for scaling.
TargetCPUUtilizationPercentage
The target CPU utilization that is expected for a container.
TargetMemoryUtilizationPercentage
The target memory utilization that is expected for a container.
extraMetrics
Used to give external metrics for autoscaling.
fullnameOverride: app-namefullnameOverride replaces the release fullname created by default by devtron, which is used to construct Kubernetes object names. By default, devtron uses {app-name}-{environment-name} as release fullname.
image:
pullPolicy: IfNotPresentImage is used to access images in kubernetes, pullpolicy is used to define the instances calling the image, here the image is pulled when the image is not present,it can also be set as "Always".
serviceAccount:
create: false
name: ""
annotations: {}enabled
Determines whether to create a ServiceAccount for pods or not. If set to true, a ServiceAccount will be created.
name
Specifies the name of the ServiceAccount to use.
annotations
Specify annotations for the ServiceAccount.
imagePullSecrets contains the docker credentials that are used for accessing a registry.
imagePullSecrets:
- regcredregcred is the secret that contains the docker credentials that are used for accessing a registry. Devtron will not create this secret automatically, you'll have to create this secret using dt-secrets helm chart in the App store or create one using kubectl. You can follow this documentation Pull an Image from a Private Registry https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/ .
the hostAliases field is used in a Pod specification to associate additional hostnames with the Pod's IP address. This can be helpful in scenarios where you need to resolve specific hostnames to the Pod's IP within the Pod itself.
hostAliases:
- ip: "192.168.1.10"
hostnames:
- "hostname1.example.com"
- "hostname2.example.com"
- ip: "192.168.1.11"
hostnames:
- "hostname3.example.com"This allows public access to the url. Please ensure you are using the right nginx annotation for nginx class. The default value is nginx.
ingress:
enabled: false
# For K8s 1.19 and above use ingressClassName instead of annotation kubernetes.io/ingress.class:
className: nginx
annotations: {}
hosts:
- host: example1.com
pathType: "ImplementationSpecific"
paths:
- /example
- host: example2.com
pathType: "ImplementationSpecific"
paths:
- /example2
- /example2/healthz
tls: []Legacy deployment-template ingress format
ingress:
enabled: false
# For K8s 1.19 and above use ingressClassName instead of annotation kubernetes.io/ingress.class:
ingressClassName: nginx-internal
annotations: {}
path: ""
host: ""
tls: []enabled
Enable or disable ingress
annotations
To configure some options depending on the Ingress controller
host
Host name
pathType
Path in an Ingress is required to have a corresponding path type. Supported path types are ImplementationSpecific, Exact and Prefix.
path
Path name
tls
It contains security details
This allows private access to the url, please ensure you are using right nginx annotation for nginx class, its default value is nginx
ingressInternal:
enabled: false
# For K8s 1.19 and above use ingressClassName instead of annotation kubernetes.io/ingress.class:
ingressClassName: nginx-internal
annotations: {}
hosts:
- host: example1.com
pathType: "ImplementationSpecific"
paths:
- /example
- host: example2.com
pathType: "ImplementationSpecific"
paths:
- /example2
- /example2/healthz
tls: []enabled
Enable or disable ingress
annotations
To configure some options depending on the Ingress controller
host
Host name
pathType
Path in an Ingress is required to have a corresponding path type. Supported path types are ImplementationSpecific, Exact and Prefix.
path
Path name
pathType
Supported path types are ImplementationSpecific, Exact and Prefix.
tls
It contains security details
initContainers:
- reuseContainerImage: true
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
volumeMounts:
- mountPath: /etc/ls-oms
name: ls-oms-cm-vol
command:
- flyway
- -configFiles=/etc/ls-oms/flyway.conf
- migrate
- name: nginx
image: nginx:1.14.2
securityContext:
privileged: true
ports:
- containerPort: 80
command: ["/usr/local/bin/nginx"]
args: ["-g", "daemon off;"]Specialized containers that run before app containers in a Pod. Init containers can contain utilities or setup scripts not present in an app image. One can use base image inside initContainer by setting the reuseContainerImage flag to true.
pauseForSecondsBeforeSwitchActive: 30To wait for given period of time before switch active the container.
These define minimum and maximum RAM and CPU available to the application.
resources:
limits:
cpu: "1"
memory: "200Mi"
requests:
cpu: "0.10"
memory: "100Mi"Resources are required to set CPU and memory usage.
Limits make sure a container never goes above a certain value. The container is only allowed to go up to the limit, and then it is restricted.
Requests are what the container is guaranteed to get.
This defines annotations and the type of service, optionally can define name also.
service:
type: ClusterIP
annotations: {}type
Select the type of service, default ClusterIP
annotations
Annotations are widely used to attach metadata and configs in Kubernetes.
name
Optional field to assign name to service
loadBalancerSourceRanges
If service type is LoadBalancer, Provide a list of whitelisted IPs CIDR that will be allowed to use the Load Balancer.
Note - If loadBalancerSourceRanges is not set, Kubernetes allows traffic from 0.0.0.0/0 to the LoadBalancer / Node Security Group(s).
volumes:
- name: log-volume
emptyDir: {}
- name: logpv
persistentVolumeClaim:
claimName: logpvcIt is required when some values need to be read from or written to an external disk.
volumeMounts:
- mountPath: /var/log/nginx/
name: log-volume
- mountPath: /mnt/logs
name: logpvc
subPath: employee It is used to provide mounts to the volume.
Spec:
Affinity:
Key:
Values:Spec is used to define the desire state of the given container.
Node Affinity allows you to constrain which nodes your pod is eligible to schedule on, based on labels of the node.
Inter-pod affinity allow you to constrain which nodes your pod is eligible to be scheduled based on labels on pods.
Key part of the label for node selection, this should be same as that on node. Please confirm with devops team.
Value part of the label for node selection, this should be same as that on node. Please confirm with devops team.
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule|PreferNoSchedule|NoExecute(1.6 only)"Taints are the opposite, they allow a node to repel a set of pods.
A given pod can access the given node and avoid the given taint only if the given pod satisfies a given taint.
Taints and tolerations are a mechanism which work together that allows you to ensure that pods are not placed on inappropriate nodes. Taints are added to nodes, while tolerations are defined in the pod specification. When you taint a node, it will repel all the pods except those that have a toleration for that taint. A node can have one or many taints associated with it.
args:
enabled: false
value: []This is used to give arguments to command.
command:
enabled: false
value: []
workingDir: {}It contains the commands to run inside the container.
enabled
To enable or disable the command.
value
It contains the commands.
workingDir
It is used to specify the working directory where commands will be executed.
Containers section can be used to run side-car containers along with your main container within same pod. Containers running within same pod can share volumes and IP Address and can address each other @localhost. We can use base image inside container by setting the reuseContainerImage flag to true.
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
command: ["/usr/local/bin/nginx"]
args: ["-g", "daemon off;"]
- reuseContainerImage: true
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
volumeMounts:
- mountPath: /etc/ls-oms
name: ls-oms-cm-vol
command:
- flyway
- -configFiles=/etc/ls-oms/flyway.conf
- migrate
prometheus:
release: monitoringIt is a kubernetes monitoring tool and the name of the file to be monitored as monitoring in the given case.It describes the state of the prometheus.
rawYaml:
- apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
type: ClusterIPAccepts an array of Kubernetes objects. You can specify any kubernetes yaml here and it will be applied when your app gets deployed.
GracePeriod: 30Kubernetes waits for the specified time called the termination grace period before terminating the pods. By default, this is 30 seconds. If your pod usually takes longer than 30 seconds to shut down gracefully, make sure you increase the GracePeriod.
A Graceful termination in practice means that your application needs to handle the SIGTERM message and begin shutting down when it receives it. This means saving all data that needs to be saved, closing down network connections, finishing any work that is left, and other similar tasks.
There are many reasons why Kubernetes might terminate a perfectly healthy container. If you update your deployment with a rolling update, Kubernetes slowly terminates old pods while spinning up new ones. If you drain a node, Kubernetes terminates all pods on that node. If a node runs out of resources, Kubernetes terminates pods to free those resources. It’s important that your application handle termination gracefully so that there is minimal impact on the end user and the time-to-recovery is as fast as possible.
server:
deployment:
image_tag: 1-95a53
image: ""It is used for providing server configurations.
It gives the details for deployment.
image_tag
It is the image tag
image
It is the URL of the image
servicemonitor:
enabled: true
path: /abc
scheme: 'http'
interval: 30s
scrapeTimeout: 20s
metricRelabelings:
- sourceLabels: [namespace]
regex: '(.*)'
replacement: myapp
targetLabel: target_namespaceIt gives the set of targets to be monitored.
dbMigrationConfig:
enabled: falseIt is used to configure database migration.
These Istio configurations collectively provide a comprehensive set of tools for controlling access, authenticating requests, enforcing security policies, and configuring traffic behavior within a microservices architecture. The specific settings you choose would depend on your security and traffic management requirements.
These Istio configurations collectively provide a comprehensive set of tools for controlling access, authenticating requests, enforcing security policies, and configuring traffic behavior within a microservices architecture. The specific settings you choose would depend on your security and traffic management requirements.
istio:
enable: true
gateway:
enabled: true
labels:
app: my-gateway
annotations:
description: "Istio Gateway for external traffic"
host: "example.com"
tls:
enabled: true
secretName: my-tls-secret
virtualService:
enabled: true
labels:
app: my-service
annotations:
description: "Istio VirtualService for routing"
gateways:
- my-gateway
hosts:
- "example.com"
http:
- match:
- uri:
prefix: /v1
route:
- destination:
host: my-service-v1
subset: version-1
- match:
- uri:
prefix: /v2
route:
- destination:
host: my-service-v2
subset: version-2
destinationRule:
enabled: true
labels:
app: my-service
annotations:
description: "Istio DestinationRule for traffic policies"
subsets:
- name: version-1
labels:
version: "v1"
- name: version-2
labels:
version: "v2"
trafficPolicy:
connectionPool:
tcp:
maxConnections: 100
outlierDetection:
consecutiveErrors: 5
interval: 30s
baseEjectionTime: 60s
peerAuthentication:
enabled: true
labels:
app: my-service
annotations:
description: "Istio PeerAuthentication for mutual TLS"
selector:
matchLabels:
version: "v1"
mtls:
mode: STRICT
portLevelMtls:
8080:
mode: DISABLE
requestAuthentication:
enabled: true
labels:
app: my-service
annotations:
description: "Istio RequestAuthentication for JWT validation"
selector:
matchLabels:
version: "v1"
jwtRules:
- issuer: "issuer-1"
jwksUri: "https://issuer-1/.well-known/jwks.json"
authorizationPolicy:
enabled: true
labels:
app: my-service
annotations:
description: "Istio AuthorizationPolicy for access control"
action: ALLOW
provider:
name: jwt
kind: Authorization
rules:
- from:
- source:
requestPrincipals: ["*"]
to:
- operation:
methods: ["GET"]istio
Istio enablement. When istio.enable set to true, Istio would be enabled for the specified configurations
authorizationPolicy
It allows you to define access control policies for service-to-service communication.
action
Determines whether to ALLOW or DENY the request based on the defined rules.
provider
Authorization providers are external systems or mechanisms used to make access control decisions.
rules
List of rules defining the authorization policy. Each rule can specify conditions and requirements for allowing or denying access.
destinationRule
It allows for the fine-tuning of traffic policies and load balancing for specific services. You can define subsets of a service and apply different traffic policies to each subset.
subsets
Specifies subsets within the service for routing and load balancing.
trafficPolicy
Policies related to connection pool size, outlier detection, and load balancing.
gateway
Allowing external traffic to enter the service mesh through the specified configurations.
host
The external domain through which traffic will be routed into the service mesh.
tls
Traffic to and from the gateway should be encrypted using TLS.
secretName
Specifies the name of the Kubernetes secret that contains the TLS certificate and private key. The TLS certificate is used for securing the communication between clients and the Istio gateway.
peerAuthentication
It allows you to enforce mutual TLS and control the authentication between services.
mtls
Mutual TLS. Mutual TLS is a security protocol that requires both client and server, to authenticate each other using digital certificates for secure communication.
mode
Mutual TLS mode, specifying how mutual TLS should be applied. Modes include STRICT, PERMISSIVE, and DISABLE.
portLevelMtls
Configures port-specific mTLS settings. Allows for fine-grained control over the application of mutual TLS on specific ports.
selector
Configuration for selecting workloads to apply PeerAuthentication.
requestAuthentication
Defines rules for authenticating incoming requests.
jwtRules
Rules for validating JWTs (JSON Web Tokens). It defines how incoming JWTs should be validated for authentication purposes.
selector
Specifies the conditions under which the RequestAuthentication rules should be applied.
virtualService
Enables the definition of rules for how traffic should be routed to different services within the service mesh.
gateways
Specifies the gateways to which the rules defined in the VirtualService apply.
hosts
List of hosts (domains) to which this VirtualService is applied.
http
Configuration for HTTP routes within the VirtualService. It define routing rules based on HTTP attributes such as URI prefixes, headers, timeouts, and retry policies.
Application metrics can be enabled to see your application's metrics-CPU Service Monitor usage, Memory Usage, Status, Throughput and Latency.
It gives the realtime metrics of the deployed applications
Deployment Frequency
It shows how often this app is deployed to production
Change Failure Rate
It shows how often the respective pipeline fails.
Mean Lead Time
It shows the average time taken to deliver a change to production.
Mean Time to Recovery
It shows the average time taken to fix a failed pipeline.
serviceAccountName: orchestratorA service account provides an identity for the processes that run in a Pod.
When you access the cluster, you are authenticated by the API server as a particular User Account. Processes in containers inside pod can also contact the API server. When you are authenticated as a particular Service Account.
When you create a pod, if you do not create a service account, it is automatically assigned the default service account in the namespace.
You can create PodDisruptionBudget for each application. A PDB limits the number of pods of a replicated application that are down simultaneously from voluntary disruptions. For example, an application would like to ensure the number of replicas running is never brought below the certain number.
podDisruptionBudget:
minAvailable: 1or
podDisruptionBudget:
maxUnavailable: 50%You can specify either maxUnavailable or minAvailable in a PodDisruptionBudget and it can be expressed as integers or as a percentage.
minAvailable
Evictions are allowed as long as they leave behind 1 or more healthy pods of the total number of desired replicas.
maxUnavailable
Evictions are allowed as long as at most 1 unhealthy replica among the total number of desired replicas.
envoyproxy:
image: envoyproxy/envoy:v1.14.1
configMapName: ""
resources:
limits:
cpu: "50m"
memory: "50Mi"
requests:
cpu: "50m"
memory: "50Mi"Envoy is attached as a sidecar to the application container to collect metrics like 4XX, 5XX, Throughput and latency. You can now configure the envoy settings such as idleTimeout, resources etc.
prometheusRule:
enabled: true
additionalLabels: {}
namespace: ""
rules:
- alert: TooMany500s
expr: 100 * ( sum( nginx_ingress_controller_requests{status=~"5.+"} ) / sum(nginx_ingress_controller_requests) ) > 5
for: 1m
labels:
severity: critical
annotations:
description: Too many 5XXs
summary: More than 5% of the all requests did return 5XX, this require your attentionAlerting rules allow you to define alert conditions based on Prometheus expressions and to send notifications about firing alerts to an external service.
In this case, Prometheus will check that the alert continues to be active during each evaluation for 1 minute before firing the alert. Elements that are active, but not firing yet, are in the pending state.
Labels are key/value pairs that are attached to pods. Labels are intended to be used to specify identifying attributes of objects that are meaningful and relevant to users, but do not directly imply semantics to the core system. Labels can be used to organize and to select subsets of objects.
podLabels:
severity: criticalPod Annotations are widely used to attach metadata and configs in Kubernetes.
podAnnotations:
fluentbit.io/exclude: "true"autoscaling:
enabled: true
MinReplicas: 1
MaxReplicas: 2
TargetCPUUtilizationPercentage: 90
TargetMemoryUtilizationPercentage: 80
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 4
periodSeconds: 15
selectPolicy: MaxHPA, by default is configured to work with CPU and Memory metrics. These metrics are useful for internal cluster sizing, but you might want to configure wider set of metrics like service latency, I/O load etc. The custom metrics in HPA can help you to achieve this.
waitForSecondsBeforeScalingDown: 30Wait for given period of time before scaling down the container.
If you want to see application metrics like different HTTP status codes metrics, application throughput, latency, response time. Enable the Application metrics from below the deployment template Save button. After enabling it, you should be able to see all metrics on App detail page. By default it remains disabled.
Once all the Deployment template configurations are done, click on Save to save your deployment configuration. Now you are ready to create Workflow to do CI/CD.
Helm Chart json schema is used to validate the deployment template values.
reference-chart_3-12-0
reference-chart_3-11-0
reference-chart_3-10-0
reference-chart_3-9-0
The values of CPU and Memory in limits must be greater than or equal to in requests respectively. Similarly, In case of envoyproxy, the values of limits are greater than or equal to requests as mentioned below.
resources.limits.cpu >= resources.requests.cpu
resources.limits.memory >= resources.requests.memory
envoyproxy.resources.limits.cpu >= envoyproxy.resources.requests.cpu
envoyproxy.resources.limits.memory >= envoyproxy.resources.requests.memoryPrerequisite: KEDA controller should be installed in the cluster. To install KEDA controller using Helm, navigate to chart store and search for keda chart and deploy it. You can follow this documentation for deploying a Helm chart on Devtron.
KEDA Helm repo : https://kedacore.github.io/charts
KEDA is a Kubernetes-based Event Driven Autoscaler. With KEDA, you can drive the scaling of any container in Kubernetes based on the number of events needing to be processed. KEDA can be installed into any Kubernetes cluster and can work alongside standard Kubernetes components like the Horizontal Pod Autoscaler(HPA).
Example for autoscaling with KEDA using Prometheus metrics is given below:
kedaAutoscaling:
enabled: true
minReplicaCount: 1
maxReplicaCount: 2
idleReplicaCount: 0
pollingInterval: 30
advanced:
restoreToOriginalReplicaCount: true
horizontalPodAutoscalerConfig:
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
- type: prometheus
metadata:
serverAddress: http://<prometheus-host>:9090
metricName: http_request_total
query: envoy_cluster_upstream_rq{appId="300", cluster_name="300-0", container="envoy",}
threshold: "50"
triggerAuthentication:
enabled: false
name:
spec: {}
authenticationRef: {}Example for autosccaling with KEDA based on kafka is given below :
kedaAutoscaling:
enabled: true
minReplicaCount: 1
maxReplicaCount: 2
idleReplicaCount: 0
pollingInterval: 30
advanced: {}
triggers:
- type: kafka
metadata:
bootstrapServers: b-2.kafka-msk-dev.example.c2.kafka.ap-southeast-1.amazonaws.com:9092,b-3.kafka-msk-dev.example.c2.kafka.ap-southeast-1.amazonaws.com:9092,b-1.kafka-msk-dev.example.c2.kafka.ap-southeast-1.amazonaws.com:9092
topic: Orders-Service-ESP.info
lagThreshold: "100"
consumerGroup: oders-remove-delivered-packages
allowIdleConsumers: "true"
triggerAuthentication:
enabled: true
name: keda-trigger-auth-kafka-credential
spec:
secretTargetRef:
- parameter: sasl
name: keda-kafka-secrets
key: sasl
- parameter: username
name: keda-kafka-secrets
key: username
authenticationRef:
name: keda-trigger-auth-kafka-credentialKubernetes NetworkPolicies control pod communication by defining rules for incoming and outgoing traffic.
networkPolicy:
enabled: false
annotations: {}
labels: {}
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 172.17.0.0/16
except:
- 172.17.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978enabled
Enable or disable NetworkPolicy.
annotations
Additional metadata or information associated with the NetworkPolicy.
labels
Labels to apply to the NetworkPolicy.
podSelector
Each NetworkPolicy includes a podSelector which selects the grouping of pods to which the policy applies. The example policy selects pods with the label "role=db". An empty podSelector selects all pods in the namespace.
policyTypes
Each NetworkPolicy includes a policyTypes list which may include either Ingress, Egress, or both.
Ingress
Controls incoming traffic to pods.
Egress
Controls outgoing traffic from pods.
Winter Soldier can be used to
cleans up (delete) Kubernetes resources
reduce workload pods to 0
NOTE: After deploying this we can create the Hibernator object and provide the custom configuration by which workloads going to delete, sleep and many more. for more information check the main repo
Given below is template values you can give in winter-soldier:
winterSoldier:
enabled: false
apiVersion: pincher.devtron.ai/v1alpha1
action: sleep
timeRangesWithZone:
timeZone: "Asia/Kolkata"
timeRanges: []
targetReplicas: []
fieldSelector: []enabled
false,true
decide the enabling factor
apiVersion
pincher.devtron.ai/v1beta1, pincher.devtron.ai/v1alpha1
specific api version
action
sleep,delete, scale
This specify the action need to perform.
timeRangesWithZone:timeZone
eg:- "Asia/Kolkata","US/Pacific"
It use to specify the timeZone used. (It uses standard format. please refer )
timeRangesWithZone:timeRanges
array of [ timeFrom, timeTo, weekdayFrom, weekdayTo]
It use to define time period/range on which the user need to perform the specified action. you can have multiple timeRanges.
These settings will take action on Sat and Sun from 00:00 to 23:59:59,
targetReplicas
[n] : n - number of replicas to scale.
These is mandatory field when the action is scale
Default value is [].
fieldSelector
- AfterTime(AddTime( ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z'), '5m'), Now())
These value will take a list of methods to select the resources on which we perform specified action .
here is an example,
winterSoldier:
apiVersion: pincher.devtron.ai/v1alpha1
enabled: true
annotations: {}
labels: {}
timeRangesWithZone:
timeZone: "Asia/Kolkata"
timeRanges:
- timeFrom: 00:00
timeTo: 23:59:59
weekdayFrom: Sat
weekdayTo: Sun
- timeFrom: 00:00
timeTo: 08:00
weekdayFrom: Mon
weekdayTo: Fri
- timeFrom: 20:00
timeTo: 23:59:59
weekdayFrom: Mon
weekdayTo: Fri
action: scale
targetReplicas: [1,1,1]
fieldSelector:
- AfterTime(AddTime( ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z'), '10h'), Now())Above settings will take action on Sat and Sun from 00:00 to 23:59:59, and on Mon-Fri from 00:00 to 08:00 and 20:00 to 23:59:59. If action:sleep then runs hibernate at timeFrom and unhibernate at timeTo. If action: delete then it will delete workloads at timeFrom and timeTo. Here the action:scale thus it scale the number of resource replicas to targetReplicas: [1,1,1]. Here each element of targetReplicas array is mapped with the corresponding elements of array timeRangesWithZone/timeRanges. Thus make sure the length of both array is equal, otherwise the cnages cannot be observed.
The above example will select the application objects which have been created 10 hours ago across all namespaces excluding application's namespace. Winter soldier exposes following functions to handle time, cpu and memory.
ParseTime - This function can be used to parse time. For eg to parse creationTimestamp use ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z')
AddTime - This can be used to add time. For eg AddTime(ParseTime({{metadata.creationTimestamp}}, '2006-01-02T15:04:05Z'), '-10h') ll add 10h to the time. Use d for day, h for hour, m for minutes and s for seconds. Use negative number to get earlier time.
Now - This can be used to get current time.
CpuToNumber - This can be used to compare CPU. For eg any({{spec.containers.#.resources.requests}}, { MemoryToNumber(.memory) < MemoryToNumber('60Mi')}) will check if any resource.requests is less than 60Mi.
A security context defines privilege and access control settings for a Pod or Container.
To add a security context for main container:
containerSecurityContext:
allowPrivilegeEscalation: falseTo add a security context on pod level:
podSecurityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000You can use topology spread constraints to control how Pods are spread across your cluster among failure-domains such as regions, zones, nodes, and other user-defined topology domains. This can help to achieve high availability as well as efficient resource utilization.
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
autoLabelSelector: true
customLabelSelector: {}